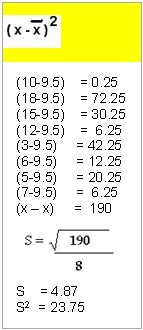|
 |
| |
|
| 7. Medidas de Tendencia
Central13 |
7.1 Media
7.1.1 Media para un conjunto de datos
no agrupados |
| |
|
Este
parámetro lo usamos con tanta cotidianidad que nos será muy familiar, aunque
también aprenderemos algunas propiedades y mostraremos un teorema sumamente
importante.
Si
tenemos el siguiente conjunto de datos y deseamos encontrar un valor que
represente a todo el conjunto, seguramente lo primero que vendrá a nuestra
mente es sumar todos los valores y dividirlos entre el número total de datos.13
Ejemplo: Número de alumnados en la clase de Educación Física.
10, 9, 8,
10, 9, 9, 10, 9, 10, 9
Este valor, promedio aritmético, es conocido como la media y es una de las medidas de
tendencia central ya que representa un valor con respeto a toda la información. |
| |
Ejemplo para el cálculo de la media.
Sean los siguientes valores las calificaciones de la asignatura de
Educación Física de estudiantes de primer año:
10 |
8 |
6 |
7.5 |
7 |
7.5 |
8 |
9.5 |
10 |
10 |
8 |
6 |
9 |
10 |
7.5 |
6 |
9.5 |
10 |
6.5 |
8 |
6 |
6 |
9 |
10 |
7 |
8 |
9.5 |
5 |
8 |
7.5 |
Sumando los valores de las 30 calificaciones y dividiéndolas entre los
30 datos obtendremos:
Por lo que la media de las calificaciones obtenidas por el grupo
considerado es igual a 8.
Para datos agrupados la expresión de la media cambia ligeramente, como
se muestra a continuación.
|
| |
7.1.2 Media para un conjunto de datos
agrupados.
La media para datos agrupados es la siguiente:
Donde es el total de datos, m es el número total de clase y es
la frecuencia de datos. La definición es claramente entendida como una extensión
de la definición que dimos para datos no agrupados, ya que es lógico suponer
que datos que se repiten con una frecuencia pueden simplificar la suma por
supuesto que los índices de la segunda suma con respecto a la primera corren
con respecto a menor número, es decir, con respecto al número de agrupamientos m.
Ejemplo:
Goles anotados por el
Querétaro durante la temporada. Sean
los siguientes datos 1, 1, 2, 2, 4, 4, 5, 2, 3, 2, 3, 4, 1, 2, 1. La media para dichos datos es aproximadamente igual a
2.4666
Para la obtención de la media cuando las frecuencias están
sujetas a la elección de clase bajo los métodos mostrados, se realiza de igual
manera, la única diferencia existe en determinar el valor como el punto medio
de cada estatura, veamos el siguiente ejemplo:
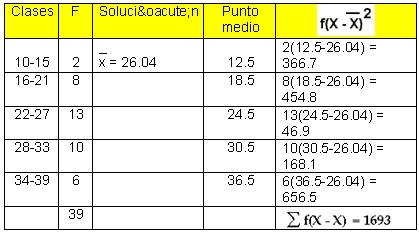
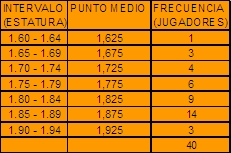
Tabla de frecuencias reportadas por un equipo de baloncesto
con respecto a la estatura de los jugadores.
|
| |
|
 |
| |
|
7.2
Moda13
7.2.1 Moda para datos
agrupados |
| |
|
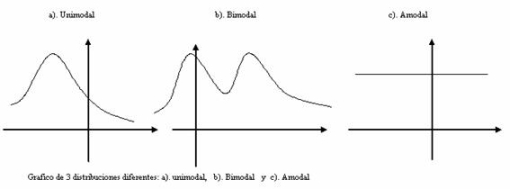
La moda es la medida que se relaciona con la frecuencia con
la que se representa el dato o los datos con mayor incidencia, por lo que se
considera la posibilidad de que exista más de un moda para un conjunto de
datos. La notación más frecuente es la siguiente: Moda y esta medida se
puede aparecer tanto para datos cualitativos como cuantitativos. Se dice que
cuando un conjunto de datos tiene una moda la muestra es unimodal, cuando tiene
dos modas bimodal, cuando la muestra contiene mas de un dato repetido se dice
que es multimodal y un último caso es cuando ningún dato tiene una frecuencia,
en dicho caso se dice que la muestra es amodal.
Ejemplos:
1.- Determinar la moda del siguiente conjunto de datos:
a) 1,2,3,3,4,5,6,7,7,3,1,9,3
2.- La moda de este conjunto de datos es igual a 3 y se
considera unimodal:
b) 1,2,3,4,4,5,2,1,3,4,2,-3,4,6,3,3
3.- Las modas de este conjunto de datos son 3 y 4 ya que
ambas tienen la mas alta frecuencia, por lo que la muestra es binomial.
c)
1,2,3,4,5,6,7,8,9
4.- La muestra no contiene ningún dato repetido por lo que se
considera que la muestra es a modal.
Gráficamente eso se puede reflejar mediante el análisis de un
histograma de frecuencias.
 |
| |
|
7.2.2 Moda para datos
agrupados
Para determinar la moda para datos agrupados en clases de
igual tamaño su cálculo se puede realizar de la siguiente forma:
Donde: Aunque la expresión se ve un poco diferente en
realidad se trata de una misma ecuación.
Ejemplo:
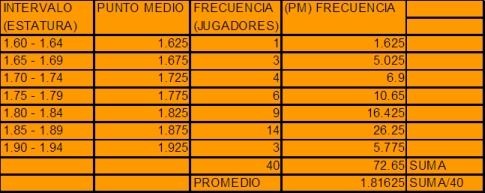
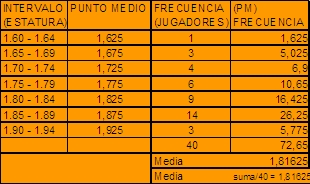
Tabla de frecuencias reportadas por un equipo de baloncesto
con respecto a la estatura de los jugadores.
|
| |
|
 |
| |
|
7.3 Mediana13
7.3.1 Mediana para
datos no agrupados
La mediana de un conjunto finito es aquel valor que divide al
conjunto en dos partes iguales, de forma que el número de valores mayor o igual
a la mediana es igual al número de valores menores o igual a estos. Su
aplicación se ve limitada ya que solo considérale orden jerárquico de los datos
y no alguna propiedad propia de los datos, como es en el caso de la media.
A continuación se muestran los criterios para construir la
mediana. Se puede construir los siguientes criterios:
Lo primero que se requiere es
ordenar los datos en de forma ascendente o descendente, cualquiera de los dos
criterios conduce al mismo resultado.
Sean ordenados los datos en orden ascendente.
Si el número de valores es impar, la
mediana es el valor medio, el cual corresponde al dato.
Cuando el número de valores en el
conjunto es par, no existe un solo valor
Medio, si no que existen dos valores
medios, en tal caso, la mediana es el promedio de los valores, es decir, la
mediana es numéricamente igual.
Podemos describir algunas propiedades para la mediana:
1.- Es única.
2.- Es simple.
3.- Los valores extremos no tienen efectos importantes sobre
la mediana, lo que si ocurre con la media.13
Ejemplo:
Dados los siguiente datos: 1,2,3,4,0,1,4,3,1,1,1,1,2,1,3 para la obtención de la mediana se deberán de ordenar. Tomemos el criterio de orden ascendente con lo que tendremos:
0,1,1,1,1,1,1,1,2,2,3,3,3,4,4
Por otro lado el número de datos es igual a 15 datos, siendo el número de datos impar se elige el dato que se encuentra a la mitad, una vez ordenados los datos, en este caso es 1.
7.3.2 La mediana para datos agrupados.
La extensión para el cálculo de la mediana en el caso de datos agrupados es realizada a continuación:
Donde:
Md = Mediana.
Li = Limite inferior o frontera o inferior de donde se encuentra la mediana, la forma de calcularlo es a través de encontrar la posición. En ocasiones en el intervalo donde se encuentra la mediana de conoce como intervalo mediano.
n= Número de observaciones o frecuencia total.
F acum. = frecuencia acumulada anterior al intervalo mediano
F mediana = Frecuencia del intervalo mediano.
A= Amplitud del intervalo en el que se encuentra la mediana.
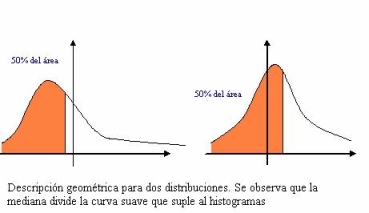
Geométricamente la mediana se encuentra en el valor X que divide al histograma en dos partes de áreas iguales.13
|
| |
|
|
| |
|
FORMULARIO
Medidas de tendencia central
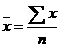 Para datos no Agrupados Para datos no Agrupados |
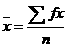 Para datos Agrupados Para datos Agrupados |
Donde: 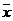 es la medida muestral. es la medida muestral.
x es cada uno de los datos (no agrupados) o la marca de clase (agrupados)
f es la frecuencia absoluta de cada Clase
n es el número de datos (tamaño de la muestra) |
|
| |
|
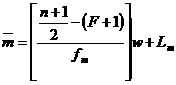 Para datos agrupados. Para datos agrupados. |
Donde: 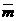 es la mediana de la muestra. es la mediana de la muestra.
n es el número total de los elementos de la distribución
F es la suma de todas las frecuencias de clase anteriores a la clase mediana
fm es la frecuencia de la clase mediana (que contiene el dato intermedio)
w es el ancho de intervalo de clase.
Lm es el limite inferior del intervalo de clase mediano.
|
|
| |
|
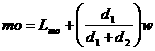 Para datos agrupados Para datos agrupados |
Donde: 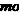 es la moda de la muestra es la moda de la muestra
Lmo es el limite inferior de la clase modal.
d1 es la frecuencia de la clase modal menos la frecuencia de la anterior
d2 es la frecuencia de la clase modal menos la frecuencia de la clase siguiente
w2 es el ancho del intervalo de la clase modal |
|
| |
|
MEDIDAS DE DISPERSIÓN 17
Existe otro tipo de medidas que indican la tendencia de los datos a dispersarse respecto al valor central.
Algunas de las medidas de dispersión más usuales son:
a) Rango, amplitud o recorrido (R)
b) Desviación estándar (S , muestral; s , poblacional ).
c) Varianza (S² , s² )
d) Desviación media (DM).
e) Coeficiente de Variación (C. V.) |
| |
|
7.4 Rango
Es la diferencia entre el dato mayor y el dato menor.
R= X máx. - Xmín. |
| |
|
7.5 Desviación estándar.
La desviación estándar o desviación tipo se define como la raíz cuadrada de los cuadrados de las desviaciones de los valores de la variable respecto a su media. 17
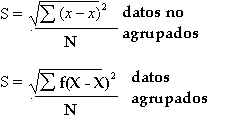 |
| |
|
7.6 Varianza.
Es el cuadrado de la desviación estándar.
EJEMPLO:
Hallar la desviación estándar y la varianza de la siguiente serie de datos.
10, 18, 15, 12, 3,6,5,7
SOLUCION:
 |
| |
|
|
| |
|
EJEMPLO:
Hallar la desviación estándar y la varianza para la siguiente distribución de frecuencias.
|
| |
|
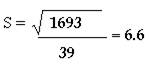
S 2= 43.4 |
| |
|
7.7 Desviación media.
Se conoce también como promedio de desviación. Para una serie de N valores se Puede calcular a través de la siguiente expresión:
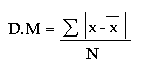
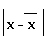 = Valor absoluto de las desviaciones de los x valores, respecto de la media. = Valor absoluto de las desviaciones de los x valores, respecto de la media.
Y para datos agrupados se tiene:
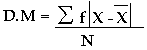
EJEMPLO:
Hallar la desviación media de: 4,6,12,16,22.
 |
| |
|
EJEMPLO:
Hallar la desviación media en la siguiente distribución de frecuencias.17
SOLUCION:
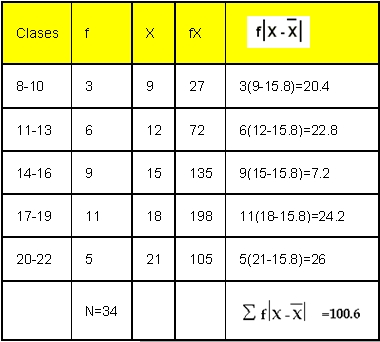
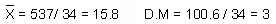 |
| |
|
7.8 Coeficiente de Variación.
Es la relación que existe entre la S y la X, expresada en términos de porcentaje y se expresa:
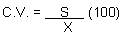
EJEMPLO:
Hallar el coeficiente de variación de una serie de datos cuya S= 2 y
X = 16.
SOLUCION:
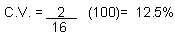 |
| |
|
FORMULARIO
Medidas de dispersión
| |
Rango = valor de la observación más alta – valor de la observación más pequeña
Rango = valor del límite inferior de la 1er clase – valor del límite superior de la última clase.
|
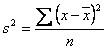 Para datos no agrupados.
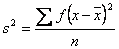 Para datos agrupados.
Donde: s2 es la varianza de la muestra
x es cada uno de los datos (no agrupados) o la marca de clase (agrupados)
es la media muestral
f es la frecuencia absoluta de cada clase
n es el número total de datos (tamaño de la muestra)
|
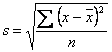 Para datos no agrupados.
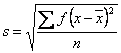 Para datos agrupados.
Donde: s es la desviación estándar de la muestra
x es cada uno de los datos (no agrupados) o la marca de clase (agrupados)
es la media muestral
f es la frecuencia absoluta de cada clase
n es el número total de datos (tamaño de la muestra)
|
Donde: c.v. es el coeficiente de variación de la muestra
s es la desviación estándar de la muestra
es la media muestral |
| |
|

 Tipos de Datos
Tipos de Datos