Projet de fin d'études
Master Professionnel OPExEtude, classification par spectroscopie proche infra rouge (NIR) des produits cosmétiques
Juan ROSAS
Cédric LACOUR
Résultats
La première phase de notre projet porte sur l’étude des produit cosmétiques (crèmes, émulsions, laits, cires, etc.) est la caractérisation par spectroscopie proche infrarouge (NIR).
Les études ont été menées sur deux appareils proche infrarouge NIR, ensuite on analyse les spectres avec chaque appareil:
Etude sur spectromètre BUCHI NIRFlex N-400
L’objectif est donc :
De classer les échantillons en fonction de leur type par des méthodes de projection.
1) Présentation de quelques spectres IR
a) Les spectres proche IR
La spectroscopie proche IR (NIR) est une méthode rapide, non destructive de caractérisation et de quantification. La figure 20 représente spectres caractéristiques en proche IR d’un conservateur (POB), le flacon vide et un échantillon afin de pouvoir avoir une idée de l’influence de l’absorption IR du matériel du flacon et un conservateur.
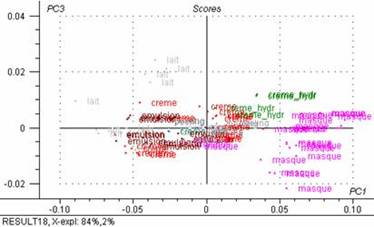
Figure 20 : Spectres NIR
2) Traitement des spectres
a) Objectifs
L’analyse en composantes principales est réalisé afin de :
Visualiser et simplifier un ensemble important de données sur un grand nombre d’individus.
Quantifier le pourcentage d’information utile par opposition au bruit et aux variations non expliquées contenues dans les données.
Repérer les variables les plus porteuses d’information
L’ACP est la base de plusieurs méthodes de classification (SIMCA) et de régression (PLS, PCR). Les 42 échantillons des produits cosmétiques (crèmes, émulsions, lait, cires, etc.) ont été mesurés trois fois sur le spectromètre infrarouge BUCHI NIRFlex N-400.
Le traitement des données par la méthode d’analyse en composantes principales vise à prédire un échantillon quelconque son appartenance à la classe du produit en fonction de son spectre infrarouge.
b) Préparation l’étude
1.- Les corrections spectrales
Les échantillons (figure 21) donnent des spectres différents du fait :
De la répartition hétérogène des particules
De leurs différences de concentration d’eau
De l’effet d’échantillonnage (tassement)
Tous ces problèmes rendent difficiles l’extraction des informations contenues dans les données.
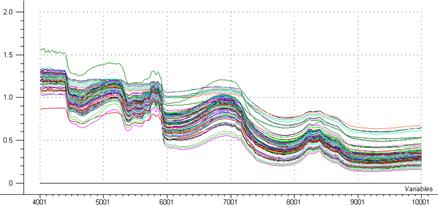
Figure 21: spectres proche IR de l’ensemble des échantillons
L’ACP impose donc un traitement correctif préalable de tous nos spectres. Différents type de traitements vont permettre de réduire les bruit introduit par tous les effets listés précédemment. L’ensemble des corrections citées ci-dessous ont été testées dans cet objectif.
- La correction MSC (Multiplicative Scatter Correction)
La MSC réduit les effets multiplicatifs ou additifs pour éviter qu’ils ne dominent l’information contenue dans les données. Chaque spectre est modélisé par rapport à un spectre moyen (figure 22)
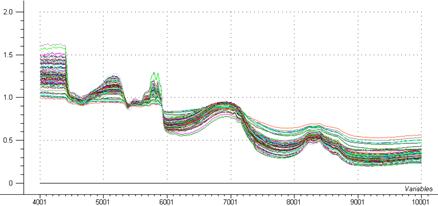
Figure 22: traitement de l’ensemble des spectres par MSC
- Le lissage et la dérivation
Le lissage élimine le bruit en calculant des mobiles sur tout le spectre. Le bruit est considéré comme aléatoire : on calcule une moyenne sur les longueurs d’ondes proches. Théoriquement l’allure des spectres est améliorée. Cependant, il faut trouver un compromis car en utilisant les lissages, les commets des pics contenant les informations sont écrasés.
Les dérivées, toujours précédées d’un lissage, sont souvent employées en spectroscopie NIR pour accentuer les différences spectrales. Le logiciel The Unscambler propose deux méthodes de dérivation :
Savitsky-golay (approximation polynômiale)
Norris (algorithme)
La figure présente les transformations apportées par ce type de correction sur les spectres.
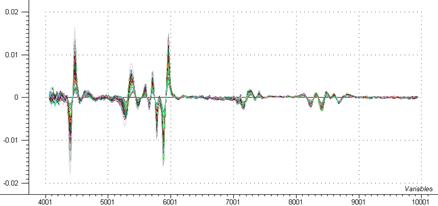
Figure 23: Spectres proche IR dérivés par la méthode de Savitsky.Golay
- La normalisation
Le logiciel The Unscrambler propose 3 types de normalisation :
Mean normalization
Chaque ligne de la matrice de données est divisée par sa moyenne. Les facteurs dont l’influence est cachée sont ainsi neutralisés. Ceci revient donc à remplacer les variables originelles par un profil centré autour de 1. l’aire sous les courbes devient la même pour tous les échantillons. Cette transformation à pour objectifs :
D’exprimer les résultats dans la même unité chaque échantillon
De négliger la quantité utilisée pour l’analyse des échantillons
Maximum normalization
Chaque ligne de la matrice est divisée par sa valeur maximum.
Range normalization
Chaque ligne de la matrice est divisée par son étendue
Les trois types de normalisation ont été testés afin de retenir la meilleure transformation.
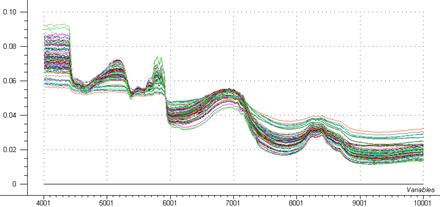
Figure 24: Normalisation du spectre
- La correction de la ligne de base (baseline offset)
Cette transformation à pour but de ramener tous les échantillons à la ligne de base, comme le montre le graphique de la figure 25.
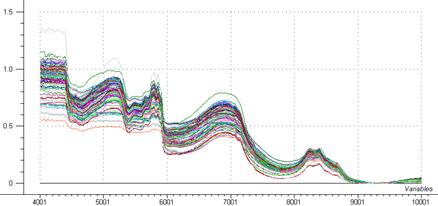
Figure 25: transformation de la ligne de base
c) discrimination des différences des produits cosmétiques
La démarche suive pour la différenciation des échantillons est la suivante :
Construction du tableau de données sous Excel et après exportation sous « The Unscrambler »
Visualisation de l’ensemble des données
Observation du tableau
Graphique des spectres
Retrait de spectres présentant des anomalies spectrales
Correction des spectres. La transformation retenue est une association des corrections suivantes :
Correction MSC sur le background
Réduction de la zone spectrale aux longueurs d’ondes : 4416-7980 cm-1 (zones de recombinaison des vibrations fondamentales caractéristiques)
Range normalisation sur la zone spectrale précédemment citée
Correction de ligne de base
Unit vector normalisation
La figure 26 représente les spectres obtenus après correction, spectres sur lesquels sera réalisée L’ACP.
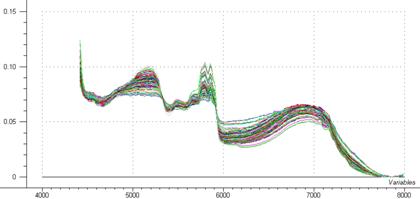
Figure 26: Spectre NIR après correction
3) Réalisation de L’ACP
a) Détection d’éventuels spectres atypiques
On regarde les résidus et on supprime tout spectre atypique jusqu’à obtenir une distribution homogène.
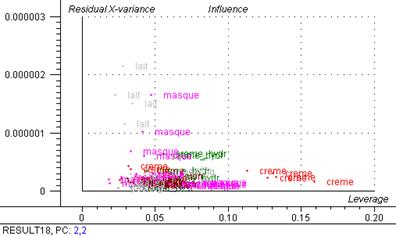
Figure 27 : Graphique d’influence
Après élever les données aberrantes on obtient le graphique d’influence dont la faible variance résiduelle ainsi que les leviers peu élevés ne mettent pas en évidence de spectres atypiques
b) Détermination du nombre de composantes principales à retenir
Le choix du nombre de composantes principales est effectué à partir de la figure représentant l’évolution de la variance expliquée en fonction du nombre de composantes principales.
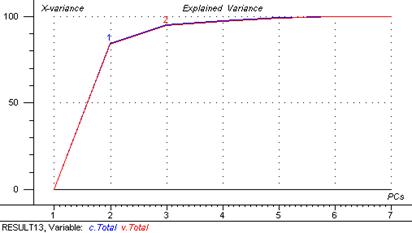
Figure 28 : graphique de la variance expliquée
Suite à l’analyse de ce graphique trois composantes principales ont été retenues. Elles expliquent 98,6 % de la variance totale.
c) Séparation des échantillons en fonction des variables qualitatives
L’objectif ici est d’identifier d’éventuels groupes d’individus par projection de ces derniers sur les composantes principales retenues (figures 29, 30 et 31)
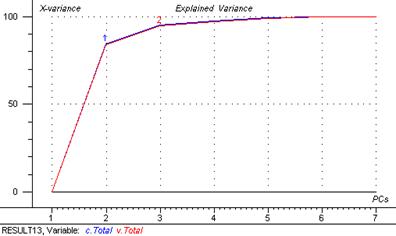
Figure 29 : Graphiques de scores : 2ème composante principale exprimée en fonction de la première.
Après l’ACP on vois trois groupes bien différences (figure 29) les groupe des masques sur l’axe 1, un gros groupe qui varie en fonction du quantité d’eau et un groupe des crèmes sur l’axe 2.
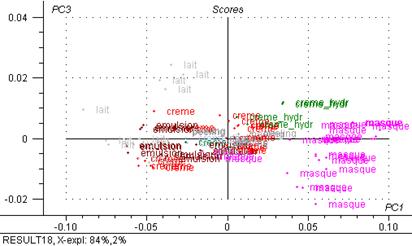
Figure 30 : Graphiques de scores : 3ème composante principale exprimée en fonction de la première.
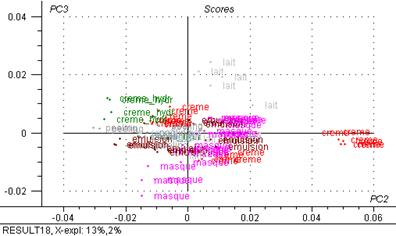
Figure 31 : Graphiques de scores : 3ème composante principale exprimée en fonction de la deuxième.
Le graphique de scores met en évidence des groupes d’individus :
Avec 84 % de la variance totale expliquée, l’axe 1 différencie les masques d’un gros groupe des crèmes, émulsions, lait, cires, etc. en fonction de quantité d’eau.
Avec 13 % de la variance totale expliquée, l’axe 2 différencie les crèmes
Avec 2 % de la variance totale expliquée, l’axe 3 différencie les laits du groupe de masques et d’un gros groupe (crèmes, émulsions, peeling)
Alors, comme la quantité d’eau est la principale différence entre les produits, on a pris les intervalles des spectres du 4700 – 5400 cm-1 et 5900 – 7000cm-1 qui correspondent aux pics de l’eau.
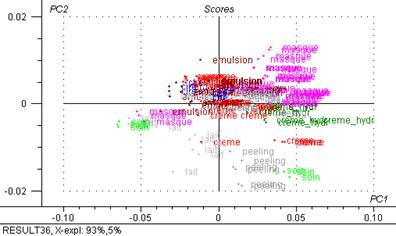
Figure 32: Graphiques de scores : 2ème composante principale exprimée en fonction de la première (4700 – 5400 cm-1)
Sur la figure 32 on peut voir la formation de deux groupes principalement (masques, lait-peeling) un gros groupe au centre d’axes c’est pas de tout différenciée, pour le faire on regarde les autres axes.
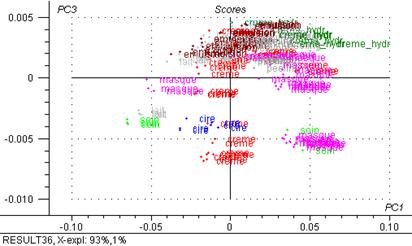
Figure 33: 3ème composante principale exprimée en fonction de la première (4700 – 5400 cm-1)
Sur la figure 33 on voit la formation de un groupe sur l’axe 2 (crèmes et cire) et un groupe de masques expliqué par l’axe 1, on peut percevoir aussi qu’il y a un groupe qui comprend les crèmes hydratantes, les émulsions, les laits, etc. qui sont expliqué par l’axe 1 et l’axe 2.
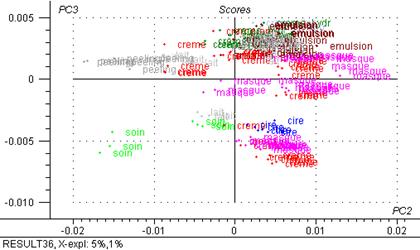
Figure 34: 3ème composante principale exprimée en fonction de la deuxième (4700 – 5400 cm-1)
Sur la figure 34 on voit l’explication d’un groupe peeling par l’axe 1, et un groupe (masques, cire, crèmes soin et laits) expliqué par l’axe 2, on voit encore la formation d’un groupe mixte (émulsions, crèmes, masques)
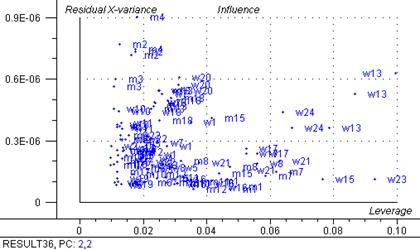
Figure 35: Graphique d’influence (4700 – 5400 cm-1)
La variance résiduelle (figure 35) est de mois 0,9 E-06
Après avoir vu l’intervalle 4700 – 5400 cm-1 on a fait une ACP pour l’intervalle 5900 à 7000 cm-1. Sur la figure 36 on ne voit pas clairement des groupes bien définis, on cherche alors sur les autres axes.
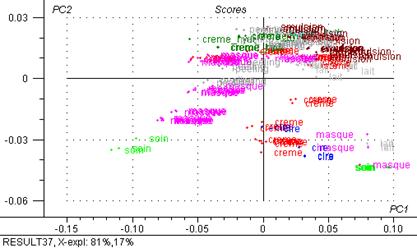
Figure 36 : 2ème composante principale exprimée en fonction de la première (5900 à 7000 cm-1)
Sur la figure 38 on voit n groupe bien expliqué par l’axe 2 (masques) et un groupe bien expliqué par l’axe 3 (peeling et laits).
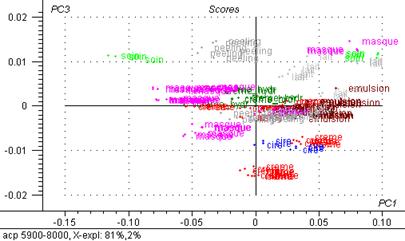
Figure 37: 3ème composante principale exprimée en fonction de la première (5900 à 7000 cm-1)
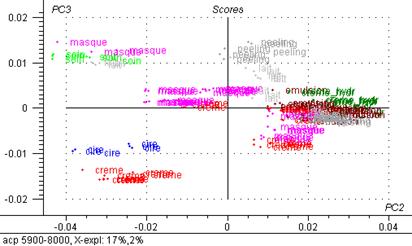
Figure 38: 3ème composante principale exprimée en fonction de la deuxième (5900 à 7000 cm-1)
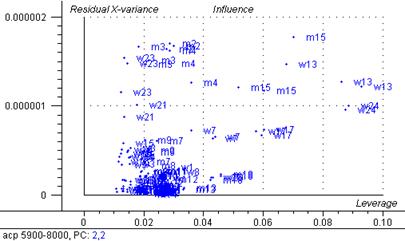
Figure 39 : Graphique d’influence (5900 à 7000 cm-1)
L’ACP a donc permis de différencier les crèmes, du fait des très faibles variations spectrales entres les spectres NIR.
d) Spectres obtenues avec le spectromètre UV-Visible
La totalité des spectres des échantillons ont été préparés en triplicat. Les résultats obtenus sont résumés dans la figure 40, comme on peut apercevoir il faut faire un prétraitement des spectres.
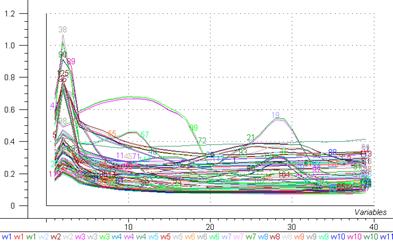
Figure 40: Spectres UV-visible avant prétraitement
Pour différencier les crèmes a partir des spectres UV visible on a fait la même démarche que pour la différenciation des échantillons par NIR.
Pour la correction des spectres, la transformation retenue est une association des corrections suivantes :
Correction MSC sur le background
Réduction de la zone spectrale aux longueurs d’ondes : 400-700 cm-1 (zone visible)
Range normalisation sur la zone spectrale précédemment citée
Correction de ligne de base
Unit vector normalization
La figure 41 représente les spectres obtenus après correction, spectres sur lesquels sera réalisée L’ACP.
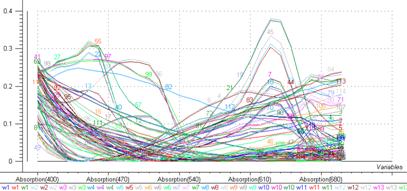
Figure 41: Spectres UV-visible après prétraitement
L’ACP réalisé sur les spectres prétraités a donnée les graphiques des scores suivants :
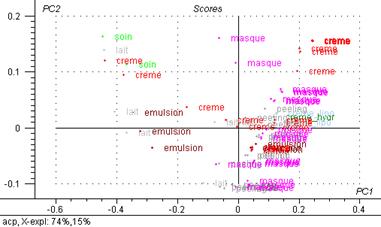
Figure 42 : 2ème composante principale exprimée en fonction de la première.
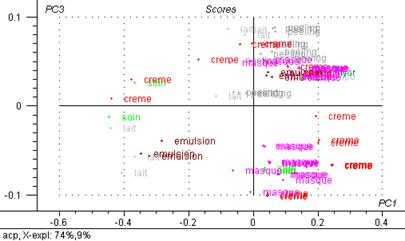
Figure 43: 3ème composante principale exprimée en fonction de la première.
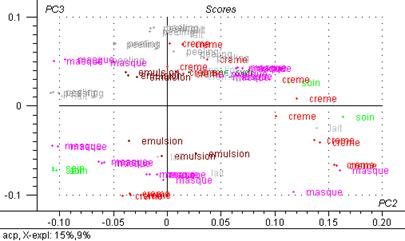
Figure 44: 3ème composante principale exprimée en fonction de la deuxième.
4) Traitement des spectres par PLS
Après avoir effectué les principaux types de corrections de spectres (correction de ligne de base, correction MSC…) par le logiciel The Unscrambler, différentes régressions PLS sur des sélections plus ou moins importantes de longueurs d’onde ont été réalisées.
D’abord on a réalisé une régression PLS1 discriminante pour chaque groupe :
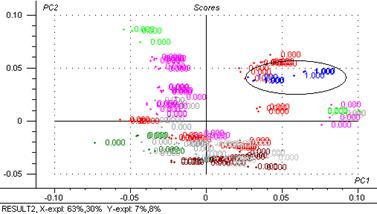
Figure 45: régression PLS1 discriminante pour les cires
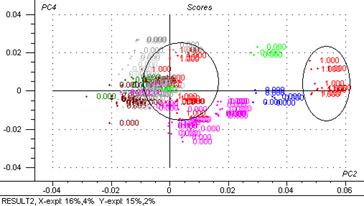
Figure 46: régression PLS1 discriminante pour les crèmes
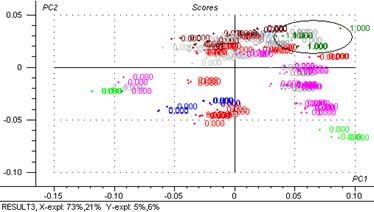
Figure 47: régression PLS1 discriminante pour les crèmes hydratantes
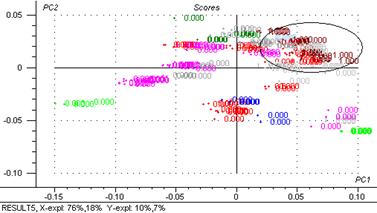
Figure 48: régression PLS1 discriminante pour les émulsions
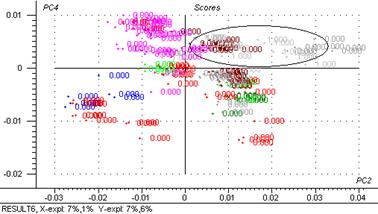
Figure 49: régression PLS1 discriminante pour les peelings
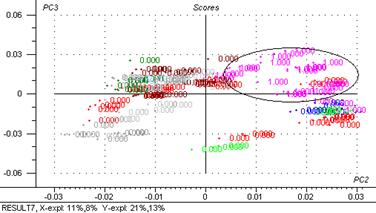
Figure 50: régression PLS1 discriminante pour les masques
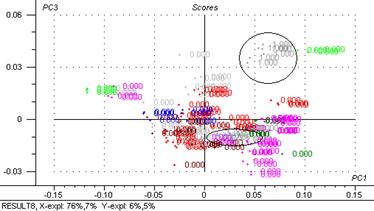
Figure 51: Régression PLS1 discriminante pour les laits
Après avoir regardé la PLS1 discriminante pour chaque groupe cosmétique, on a fait une régression PLS2 (X= spectres NIR, Y= spectres UV-visible), et on a obtenu :
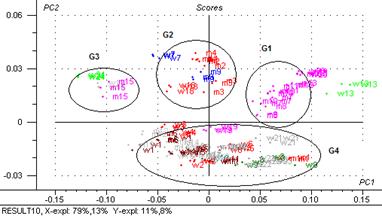
Figure 52: Régression PLS2 (PC1vsPC2)
Comme on peut apercevoir dans la figure, la PLS2 sépare quatre groupes G1 (masques), G2 (crèmes massage et cires hydratantes), G3 (laits, soin après soleil et masque contour yeux) et un gros groupe G4 (crèmes, émulsions, peelings)
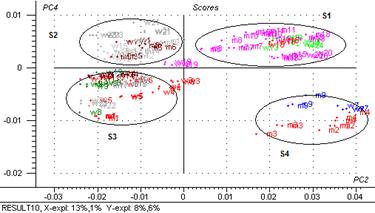
Figure 53: régression PLS2 (PC2vsPC4)
Comme on peut apercevoir dans la figure, la PLS2 PC2 vs. PC4 sépare quatre groupes S1 (masques), S2 (laits et peelings), S3 (crèmes hydratantes, émulsions) et S4 (cire de bain, crèmes massage, crèmes modelage)
Conclusion
L’ACP a démontré que on peut classifier produits cosmétiques à partir de leurs spectres NIR et les séparer en fonction de la quantité de l’eau présente dans chaque échantillon.
La PLS a montré qu’il y a une relation entre les spectres NIR et les spectres UV-visible, ce que résulte évident car les produits cosmétiques ont présenté différent coloration. Ce qui permet de faire une classification et prédiction de produits cosmétiques a partir de données NIR.
L’ACP et la PLS ont montré que les groupes les mieux expliqués et classés sont les masques, les peelings et les laits. Certains produits présentent la même quantité d’eau ce qui justifie la présence d’un groupe mixte (émulsions, crèmes, crèmes hydratantes, etc.) difficile à séparer.
Etude sur spectromètre Nicolet Nexus FT-IR
Mise en forme des données
-On s’assurera dans un premier temps que les données sont bien exprimées en « absorbance » et non en « reflectance ».
-Les échantillons sont représentés par leur appartenance à une classe et par les différentes valeurs sur spectrales sur une plage allant de 4000 cm-1 à 10000 cm-1.
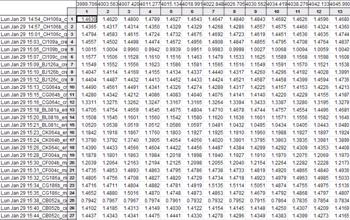
Fig 1 : Données brutes
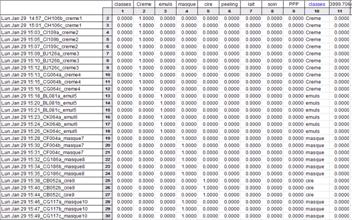
Fig 2 : Données classées
L’appartenance au groupe est représentée par un « 1 »
-Afin que l’analyse des données soit plus précise, on définit une fourchette du spectre à analyser.
Dans notre cas de 4000 à 6000 cm-1. La zone restante est inexploitable.
On verra par la suite que ce spectre peut être encore réduit car il contient les données du tube en plastique (entre 5700 et 5900 cm-1)
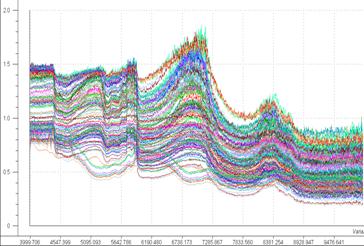
Fig 3 : Spectres Original
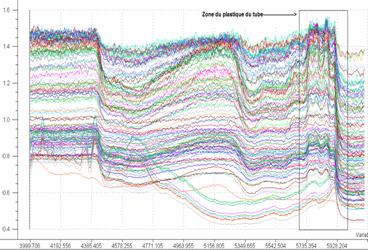
Fig 4 : Spectre réduit
Prétraitements des spectres
Comme on l’observe sur les spectres ci-dessus, le signal est très mauvais. Ainsi pour améliorer leur qualité et pouvoir faciliter l’analyse, il sera nécessaire de pratiquer des prétraitements sur les spectres (Dérivées S.Golay, MSC, Normalize, Baseline, SNV…)
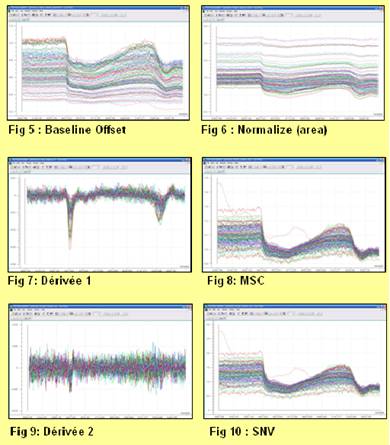
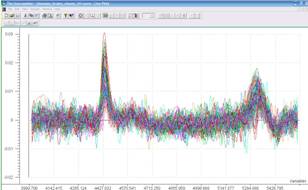
Fig 11 : Dérivée 1 + Normalize (area)(Traitement utilisé)
Analyse en Composante Principale.
Une fois l’acquisition terminée, il est important d’examiner la collection de spectres d’étalonnage. Certains échantillons peuvent être « anormaux », c’est à dire présenter des anomalies. Cela peut provenir de plusieurs raisons :
- échantillon est de nature différente de la collection d’étalonnage (par exemple, si la poudre utilisée pour l’acquisition ne provient que d’un morceau d’aubier).
- l’appareil de mesure n’a pas correctement fonctionné lors de l’acquisition du spectre.
- Il s’est produit une erreur de manipulation qui entache d’erreur la valeur de référence.
Tous ces phénomènes ont la même conséquence : l’échantillon n’est pas homogène à la collection d’étalonnage et peut être une source d’erreur. Il est alors considéré comme «outliers » et doit être retiré du lot. Une Analyse en Composantes Principales (ACP) sur les spectres du lot d’échantillonnage permet de déceler les échantillons dont la variabilité est non homogène au groupe d’échantillons.
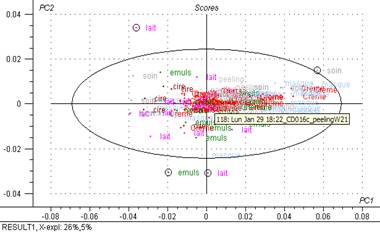
Fig 15 : Graphique des scores (T2 hotelling)
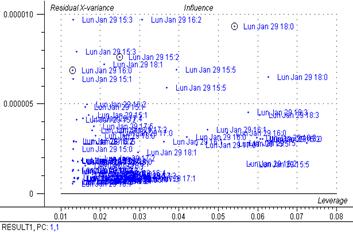
Fig 16 : Graphique des résidus
Au regard du graphique des « scores » et des « résidus » certains points (4) se trouvent hors de l’ellipse du T2 de Hotelling. Mais au risque d’erreur de 5% on peut garder ces 4 points (sur 127) dans l’analyse et ne pas les considérer comme des « outliers » lorsque l’on prend en compte 1 ou 2 composante(s). MasqueW9c pourrait être exclu pour 4 composantes. Or, par l’intermédiaire du graphique des « Loadings » on peut déterminer que seul une composante est utile (PC1 explique 26% des variables). Cette composante permet de mettre en évidence 2 pics dans les spectres dont l’un (droite) correspondrait à l’eau.
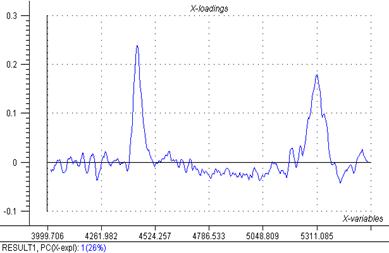
Fig 17: X-Loadings
PLS discriminante.
Une PLS est effectuée pour chaque type de produits (Crème, émulsion, masque, cire, peeling, lait, soin).
Après Leverage correlation, Full cross validation et Test set on validera les modèles jugés justes afin d’étudier la classification des différents produits
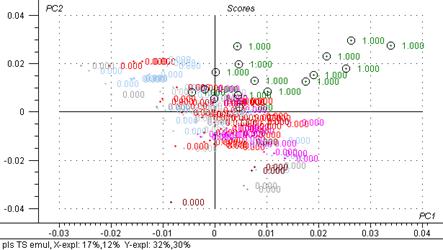
Fig 18: PLS Emulsion
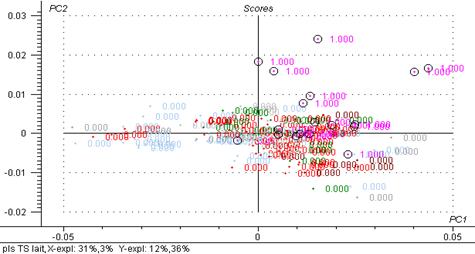 Fig 19: PLS Lait
Fig 19: PLS Lait
Grâce à cette analyse des premiers groupes apparaissent expliqués par une (voir deux) composantes. Les groupes qui ressortent sont les cires, les émulsions et les laits.
Les masques et les soins solaires sont assez disparates. Les crèmes et les peelings quant à eux se mélangent avec les autres types de produits et ne se différencient pas des autres groupes.
Si l’on observe le graphique des X-Loadings on remarque que les groupes ne se différencient pas par leur composition mais plus par leur quantité en eau.
Le graphique « Predicted vs Measured » permet également de comparer le groupe étudié au groupe total.
Classification.
Pour confirmer les résultats obtenus avec les PLS discriminantes, il est conseillé de faire une classification à l’aide des modèles validés précédemment.
L’étude des modules « Model distance » (estimation de la distance des échantillons au modèle) et « Discrimination power » (variabilité entre les spectres de chaque modèle) dans Unscrambler a permis de mettre en évidence un groupe bien distinct (Emulsion et Lait), il semblerait également que les modèles des peelings, cires et soins soient très proches. Les résultats dispersés des crèmes sont ici confirmés et ne font pas partie d’un groupe spécial. Ceci est surement du à l’étendue de la gamme de crème qui était à notre disposition (liquide, visqueuse…). Les masques semblent eux se rapprochés des crèmes et des soins.
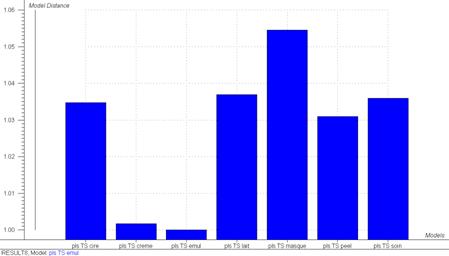
Fig 20: Model Distance
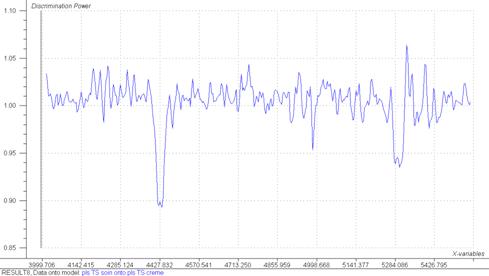
Fig 21: Discrimination power
Pour conclure sur cette classification à partir des résultats des Nexus, on peut définir 3 groupes plus ou moins distincts :
-Emulsion/Lait/(Crème).
-Masque/soin/crème.
-Peeling/cire/ (soin).