


|
|
|
|
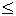 q; соответственно, признак класса
B - это условие
z, для которого выполнены неравенства p1(z)
q и p2(z) > Q.
Проще говоря, мы требуем, чтобы в области истинности z
была, так сказать, куча объектов одного из классов. Незначительным усложнением
будет использование Qi и qi
вместо Q и q.
q; соответственно, признак класса
B - это условие
z, для которого выполнены неравенства p1(z)
q и p2(z) > Q.
Проще говоря, мы требуем, чтобы в области истинности z
была, так сказать, куча объектов одного из классов. Незначительным усложнением
будет использование Qi и qi
вместо Q и q.
Условие z бесполезно, если
Q и p2(z)
> q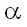 .
.
Опишем теперь критерий проверки нулевой гипотезы.
Вероятность того, что условие z истинно на k объектах из mi объектов i-го класса равняется
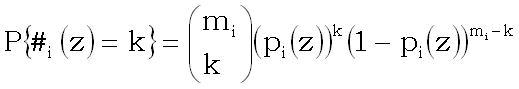 .
.
Отсюда следует, что
P{#i(z) 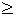 Ai}
= 1 - B(mi, Ai-1,pi(z))
= B(mi, mi-Ai,
1-pi(z)),
Ai}
= 1 - B(mi, Ai-1,pi(z))
= B(mi, mi-Ai,
1-pi(z)),
где B(k,s,p) - кумулятивная функция биномиального распределения, т.е. вероятность того, что в k испытаниях, в каждом из которых вероятность "успеха" равняется p, будет наблюдено не более s "успехов".
Если p(z)Q,
то
B(mi, mi-Ai,
1-pi(z))
B(mi, mi-Ai,
1-Q).
Отсюда следует, что критические значения Ai и ai для проверки указанных частей нулевой гипотезы определяются соотношениями
B(mi, mi-ai,
1-q) /2
B(mi, mi-ai-1,
1-q),
(5.1)
B(mi, mi-Ai,
1-Q) /2
B(mi, mi-Ai,
1-Q),
(5.2)
в противном случае объявляем его бесполезным.
Остается еще решить, как выбирать пороги q и Q.
Представляется очень естественным в качестве нижнего порога q выбирать вероятность истинности условия в предположении, что объекты соответствующего класса распределены в факторном пространстве равномерно. Для условия ранга r эта вероятность равняется 2r. Это же значение можно взять в качестве "первого приближения" и для вероятности Q. Если результаты перебора покажут, что полезных условий много, значение Q можно увеличить (а q уменьшить) и провести новый цикл перебора (сиречь обучения).
В случае, когда ситуация описывается второй из рассмотренных в предыдущем
разделе моделью, можно предложить несколько более развернутые соображения
о выборе порогов. Легко показать, что оптимальная классификация, основывающаяся
лишь на априорных вероятностях классов, состоит в том, чтобы все объекты
относить к классу с большей априорной вероятностью, причем вероятность
ошибки такого априорного решающего правила равна I0
= min {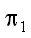 ,
, 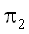 }.
Для каждого условия z можно оценить вероятность p(A|z)
= p{
}.
Для каждого условия z можно оценить вероятность p(A|z)
= p{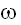
 A | z() = 1}
и аналогичную вероятность p(B|z). Как и раньше, объекты,
на которых z выполнено, нужно относить к классу с
наибольшей апостериорной вероятностью. Вероятность ошибки такого апостериорного
решающего правила равна
Iz
= min{p(A|z), p(B|z)}. Потребуем, чтобы апостериорное решающее правило,
основанное на признаке класса, ошибалось не чаще, чем априорное, т.е. чтобы
было выполнено неравенство Iz
< I0. При >
оно удовлетворяется, если для признаков первого класса выполнено p1(z)
> p2(z), а для признаков второго
класса - более жесткое неравенство p1(z)
<p2(z).
Отсюда следует, что при >
условие
z естественно считать полезным, если
A | z() = 1}
и аналогичную вероятность p(B|z). Как и раньше, объекты,
на которых z выполнено, нужно относить к классу с
наибольшей апостериорной вероятностью. Вероятность ошибки такого апостериорного
решающего правила равна
Iz
= min{p(A|z), p(B|z)}. Потребуем, чтобы апостериорное решающее правило,
основанное на признаке класса, ошибалось не чаще, чем априорное, т.е. чтобы
было выполнено неравенство Iz
< I0. При >
оно удовлетворяется, если для признаков первого класса выполнено p1(z)
> p2(z), а для признаков второго
класса - более жесткое неравенство p1(z)
<p2(z).
Отсюда следует, что при >
условие
z естественно считать полезным, если
q2
q1 и
p2(z) > Q2,q2
и Q2
q1.
и выбираются
их оценки по обучающей выборке, а в качестве "первого приближения" для
qi
- снова величины 2-r. Критические области
определяются соотношениями
/2
< B(mi, mi-ai-1,
1-qi),
/2
< B(mi, mi-Ai-1,
1-Qi).Заметим теперь, что при оценке полезности условия мы оперируем вероятностями pi(z), хотя свойства условия, позволяющие нам называть его признаком класса, естественнее формулируются в терминах апостериорных вероятностей классов. Так, условие z естественно называть признаком класса A, если p(A|z) > p(B|z). Несмотря на то, что вероятности p(A|z) и p(B|z) имеют смысл лишь в рамках модели с случайными маргиналами, расширив толкование цели поиска описания, мы можем обосновать выбор порогов qi в обеих рассмотренных моделях.
Неравенство p(A|z) > p(B|z) выполнено тогда и только тогда, когда
p(z|A)
> (1-)p(z|B),
(6)
- априорная вероятность класса A. Предположим теперь,
что применять найденные признаки мы собираемся при другой априорной вероятности
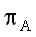 класса
A.
Очевидно, что при этом, вообще говоря, условие может перестать быть признаком
класса. Другими словами, не при всяких p(z|A) и p(z|B)
неравенство (6) выполнено при любом значении .
Более того, легко видеть, что неравенство (6) выполнено при любом значении
класса
A.
Очевидно, что при этом, вообще говоря, условие может перестать быть признаком
класса. Другими словами, не при всяких p(z|A) и p(z|B)
неравенство (6) выполнено при любом значении .
Более того, легко видеть, что неравенство (6) выполнено при любом значении
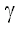 тогда и только тогда, когда p(z|B) = 0. Таким образом,
если мы собираемся использовать найденные признаки при произвольных априорных
вероятностях классов, мы должны положить q2
= 0. Предположим теперь, что найденные описания будут применяться
лишь при >.
Нетрудно показать, что при этом неравенство (6) будет выполнено тогда и
только тогда, когда
)
p(z|B)p(z|A).)
q2
Q1 и уж заведомо (1-)
q2.
тогда и только тогда, когда p(z|B) = 0. Таким образом,
если мы собираемся использовать найденные признаки при произвольных априорных
вероятностях классов, мы должны положить q2
= 0. Предположим теперь, что найденные описания будут применяться
лишь при >.
Нетрудно показать, что при этом неравенство (6) будет выполнено тогда и
только тогда, когда
)
p(z|B)p(z|A).)
q2
Q1 и уж заведомо (1-)
q2.

|
|

Вы можете попасть на эту страницу по одному из следующих адресов:
http://learn.at/infoscope/AI/patt_rec/feat_sel/FSelect2.html
http://read.at/infoscope/AI/patt_rec/feat_sel/FSelect2.html
http://now.at/infoscope/AI/patt_rec/feat_sel/FSelect2.html
Дата последней модификации: 10 октября 2000 г.