


|
|
|
|
Принадлежность к классу A или классу B разделяет объекты обучающей выборки на два подмножества; количества элементов в них обозначим через m1 и m2, пусть M = m1+m2 обозначает объем обучающей выборки.
Пусть pi(z) есть вероятность того, что условие z истинно на произвольно взятом объекте i-го класса. Количества #i(z) объектов i-го класса из обучающей выборки, на которых z истинно, а, следовательно, и общее количество #(z) объектов, на которых z истинно, являются случайными величинами, причем функционально связанными: #(z) = #1(z)+#2(z).
Связь между случайными величинами #(z) и #i(z)
позволяет считать, что объекты обучающей выборки, на которых z
истинно, получены в два шага: сначала были выбраны значения K
случайной величины #(z) и
k1
случайной величины #1(z),
затем из mi объектов i-го
класса случайным выбором без возвращения отобраны ki
объектов. Взаимоотношения между рассмотренными множествами обычно представляют
в виде таблицы
2 2, так называемой таблицы сопряженности:
2, так называемой таблицы сопряженности:
|
|
|
|
|
| z |
|
|
|
 |
|
|
|
| Всего |
|
|
|
Условие z ничего не говорит о принадлежности объекта к классу и, следовательно, бесполезно, если можно считать, что все K объектов, на которых z истинно, получены из M объектов обучающей выборки случайным выбором без возвращения, при котором каждый объект имеет одну и ту же вероятность быть извлеченным. При этом #1(z) будет случайной величиной, распределение которой, как известно, задается формулой:
(2) 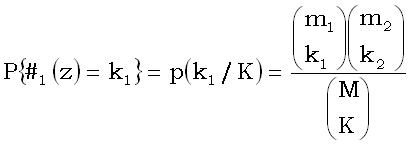 .
.
Эти вероятности, определенные при 0 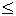 k1K,
0 k1m1,
0
k2m2, составляют так называемое гипергеометрическое
распределение.
k1K,
0 k1m1,
0
k2m2, составляют так называемое гипергеометрическое
распределение.
Если отбор K объектов действительно производился случайно и независимо от их принадлежности к классу A или классу B, то E#1(z) = Km1/M (символом E обозначается взятие математического ожидания) и поэтому
E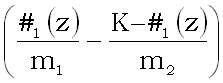 =
0.
=
0.
Легко видеть, что последнее соотношение эквивалентно равенству p1(z) = p2(z), которое и будем в данном разделе считать определением бесполезности условия. Если условие z бесполезно, что при фиксированном значении K случайная величина #1(z) подчиняется гипергеометрическому распределению (2), а соответствующая таблица сопряженности называется незначимой (в противном случае - значимой). Для обоснования критерия проверки значимости таблицы сопряженности необходимо более точно описать способ, которым она была получена, в частности, как были получены ее маргиналы m1 и m2.
При фиксированном объеме M обучающей выборки в задачах распознавания есть две возможности в отношении чисел m1 и m2. Во-первых, они могут быть фиксированы - фактически в этом случае обучающая выборка состоит из двух независимых выборок из двух разных распределений. Фиксация m1 и m2 применяется, например, в тех случаях, когда объекты одного из классов встречаются редко - при этом в соответствующую выборку включают все зарегистрированные наблюдения. Такая ситуация характеризуется лишь вероятностями pi(z) и гипотеза о равенстве двух вероятностей называется гипотезой однородности.
Во-вторых, m1 и m2
могут быть случайными величинами, как это имеет место, когда выборка объема
M
берется из генеральной совокупности, из которой объекты классов A
и B поступают с априорными вероятностями 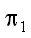 и
и 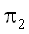 соответственно.
В этом случае p1(z)
можно интерпретировать, как условную вероятность P{z(
соответственно.
В этом случае p1(z)
можно интерпретировать, как условную вероятность P{z(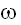
 A}, соответственно, p2(z)
- как условную вероятность P{z()
= 1 |
B}.
A}, соответственно, p2(z)
- как условную вероятность P{z()
= 1 |
B}.
Кроме того, определены вероятности p(Az) и p(Bz),
p(z)
и т.д. Равенство p1(z) =
p2(z) при этом эквивалентно равенству
p(Az)
= p(z),
где p(z) = p1(z)
+ p2(z)
= pi(z), т.е. бесполезность условия
означает здесь независимость дихотомий, представленных в таблице сопряженности.
Соответствующую гипотезу называют гипотезой независимости.
В данном случае наличие двух совершенно разных статистических моделей не сильно усложняет дело, поскольку известно (см., например, [Хальд, 1956]), что равномерно наиболее мощным критерием проверки нулевой гипотезы p1(z) = p2(z) для обеих моделей является критерий Фишера, к описанию применения которого мы и переходим.
Рассмотрим сначала альтернативу p1(z) > p2(z), которую естественно интерпретировать, как полезность условия z для описания класса A. Для каждого K мы можем определить критическую область как совокупность всевозможных пар k1,k2, удовлетворяющих соотношениям вида
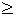 CK,
k2 = K - k1,
CK | K}
CK,
k2 = K - k1,
CK | K}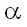 < p{#1(z) >= CK - 1 | K},
K M), получаем критическую
область, вероятность попадания в которую точек k1, k2
для обеих моделей не превосходит
(при условии, конечно, что верна нулевая гипотеза о бесполезности). Другими
словами, уровень значимости критерия, задаваемого этой критической областью,
не превосходит. истинный же уровень значимости зависит от вида модели и
значений характеризующих ее параметров и может иногда, особенно для малых
k1, k2
быть значительно меньше .
< p{#1(z) >= CK - 1 | K},
K M), получаем критическую
область, вероятность попадания в которую точек k1, k2
для обеих моделей не превосходит
(при условии, конечно, что верна нулевая гипотеза о бесполезности). Другими
словами, уровень значимости критерия, задаваемого этой критической областью,
не превосходит. истинный же уровень значимости зависит от вида модели и
значений характеризующих ее параметров и может иногда, особенно для малых
k1, k2
быть значительно меньше .
На практике, конечно, не обязательно искать критическую область в сколько-нибудь
явном виде. Для проверки гипотезы
p1(z)
= p2(z) против альтернативы p1(z)
> p2(z) на основе наблюденных частот
k1/m1 и
k2/m2,
нужно исследовать, выполняется ли неравенство k1
CK для K = k1
+ k2. Однако, если
k1
CK, то p{k1
CK|K} ,
так что для проверки гипотезы о бесполезности достаточно вычислить вероятность
k1|
k1 + k2}
(5).
Сказанное подытожим следующим образом: условие z
является признаком класса A, если вероятность (5)
не превосходит ; если же она больше , то условие
z бесполезно.
Описанный критерий стандартным способом превращается в двусторонний. Условие z полезно для класса A, если
p{#1(z)k1
| k1 + k2}/2;
оно полезно для класса B, если
p{#1(z) < k1
| k1 + k2}/2;
оно бесполезно, если ни то, ни другое не выполнено. В явном виде критические
области задаются соотношениями
p{#1(z) C1(K)
| K}/2
< p{#1(z) C1(K) - 1 | K};
p{#1(z) < C2(K)
| K} /2
< p{#1(z) C2(K)
+ 1 | K}.
То же самое можно выразить по-другому: условие z
является признаком класса A, если k1
C1(K), признаком класса B,
если k1 < C2(K),
и бесполезно, если C2(K)
k1 < C1 (K).

|
|

Вы можете попасть на эту страницу по одному из следующих адресов:
http://learn.at/infoscope/AI/patt_rec/feat_sel/FSelect1.html
http://read.at/infoscope/AI/patt_rec/feat_sel/FSelect1.html
http://now.at/infoscope/AI/patt_rec/feat_sel/FSelect1.html
Дата последней модификации: 10 октября 2000 г.