


|
|
|
|
Широкий класс алгоритмов распознавания, формирования понятий, выявления закономерностей и т.п. связан с поиском областей в факторном пространстве, в каждой из которых объекты одного из классов появляются чаще объектов других классов. В алгоритмах, работающих с непрерывными факторами (дискриминантный анализ, методы "обобщенного портрета" и т.д.) эта идея замаскирована вычислением корреляционных матриц, векторов средних и проч. В явном виде эта идея часто выражена в так называемых комбинаторных алгоритмах, работающих в дискретных факторных пространствах: производится перебор областей факторного пространства, по обучающей выборке оцениваются вероятности появления в них объектов разных классов и по полученным оценкам из них отбираются полезные. Алгоритмы отличаются друг от друга видом рассматриваемых областей, определениями их полезности, способами использования полезных областей.
Типичным примером является знаменитый алгоритм кора [Бонгард, 1967; Вайнцвайг, 1972], послуживший идейным источником множества комбинаторных алгоритмов распознавания. Кора работает с бинарными факторами (принимающими значения 0 и 1). Рассматриваемые области задаются предикатами вида
(1)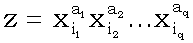 ,
,
т.е. являются конъюнкциями предикатов 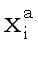 ,
где a может равняться 0 или 1, причем
,
где a может равняться 0 или 1, причем 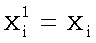 ,
, 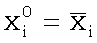 ,
а предикат xi истинен в точке факторного
пространства тогда и только тогда, когда ее
i-я
координата равна 1, а
,
а предикат xi истинен в точке факторного
пространства тогда и только тогда, когда ее
i-я
координата равна 1, а 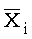 есть логическое отрицание предиката xi.
Предикаты вида (1) будем называть условиями, а число q - рангом
условия.
есть логическое отрицание предиката xi.
Предикаты вида (1) будем называть условиями, а число q - рангом
условия.
Обучение в алгоритме "кора" заключается в построении описаний классов.
Каждое описание - это список признаков класса, т.е. условий ранга не выше
заданного, истинных (говорят также, выполненных) на большом числе объектов
описываемого (своего) класса и на малом числе - вне его. В случае двухклассовой
задачи распознавания это требование принимает следующую форму: условие
является признаком первого класса, если #1(z)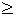 A1 и #2(z)< a1, где #i(z)
- количество объектов i-го класса из обучающей
выборки, на которых условие z выполнено, а
A1 и a1
- заранее выбранные пороги. Аналогично определяются признаки второго
класса.
A1 и #2(z)< a1, где #i(z)
- количество объектов i-го класса из обучающей
выборки, на которых условие z выполнено, а
A1 и a1
- заранее выбранные пороги. Аналогично определяются признаки второго
класса.
Одна из опасностей при построении описания - возможность возникновения так называемых предрассудков, т.е. отбора условий, удовлетворяющих предъявленным требованиям лишь на обучающей выборке и оказывающихся бесполезными за ее пределами. По-видимому, первым, кто обратил внимание на эту проблему, был М.М.Бонгард [Бонгард, 1967]; ему же принадлежит и термин "предрассудок".
Ясно, что увеличивая пороги Ai и уменьшая ai, мы уменьшаем вероятность возникновения предрассудков. Однако, актуальной остается проблема выбора порогов, гарантирующих, что вероятность появления хотя бы даже одного предрассудка не превосходит заданной величины. В работе [Голендер, Розенблит, 1975] предложен один из возможных подходов, эксплуатирующий фактически идею "хаотизации" (или "перемешивания") И.Ш.Пинскера [Пинскер, 1973]. Перемешивание используется для определения достаточности объема обучающей выборки при поиске решающего правила из заданного класса. Принцип основан на случайном распределении объектов обучающей выборки по классам, при котором учитываются лишь априорные вероятности классов, если они доступны. Если после этого в результате обучения будет найдено достаточно хорошее решающее правило, считается, что объем обучающей выборки недостаточен для надежного выбора. В работе В.Е.Голендера и А.Б.Розенблита предложено по "перемешанным" выборкам оценить распределения каких-либо характеристик условий и отбирать признаки, используя пороги, при выборе которых учтены эти распределения. Этот подход, содержательно вполне оправданный, остается, тем не менее, вполне эвристическим и не позволяет получить оценку вероятности проникновения предрассудков в совокупность отобранных условий.
В данной работе (по-видимому, впервые) предлагается статистический подход, позволяющий придать понятию "предрассудок" точный формальный смысл. Совсем кратко подход можно описать следующим образом. Среди всевозможных условий отбираются те, которые можно назвать полезными. Выберем пару альтернативных гипотез, в которой нулевая гипотеза соответствует бесполезности условия и построим критерий проверки нулевой гипотезы. Тогда предрассудок - это условие, на котором допущена ошибка первого рода, и вероятность появления предрассудка не превосходит уровня значимости критерия, используемого для проверки гипотезы.
Подход раскрывается на нескольких парах альтернативных гипотез, формализующих различные аспекты представлений о полезности. В разделе 2 рассмотрены слабейшие требования к признаку: должны различаться вероятности истинности условия на объектах разных классов. В следующем разделе это требование ужесточается: в области истинности условия должно быть "много" объектов одного класса и совсем "мало" объектов другого. В разделе 4 устанавливается связь между уровнем значимости критерия, количеством проверяемых условий и вероятностью проникновения предрассудка в число признаков. Полученные соотношения позволяют указать оценку необходимого для поиска объема обучающей выборки. В разделе 5 получена нижняя граница объема обучающей выборки, необходимого для достижения заданной надежности оценки вероятности ошибки решающего правила, соответствующего построенному описанию.

|
|

Дата последней модификации: 10 октября 2000 г.