


|
|
|
|
Будем считать, что подобная составная процедура ошибается, если
хотя бы в одной из проверок будет допущена ошибка первого рода; другими
словами, возникнет хотя бы один предрассудок. Если потребовать, чтобы вероятность
ошибки составной процедуры не превосходила 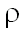 ,
то каждое условие достаточно проверять с уровнем значимости
,
то каждое условие достаточно проверять с уровнем значимости 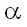
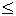 /L (так называемая поправка Бонферрони).
/L (так называемая поправка Бонферрони).
Указанная связь между уровнями значимости
и и количеством
L
проверяемых условий позволяет получить оценку объема обучающей выборки,
необходимого для организации отбора полезных условий. С этой целью рассмотрим
соотношения (5), выделяющие критическую область для принятия гипотезы о
наличии "кучи". Величина B(mi,
mi-Ai,
1-Q) монотонно убывает с ростом
Ai
и минимальна при Ai = mi. Поэтому,
если
/2,то проверять гипотезу о наличии "кучи" бессмысленно - у нас попросту
недостаточно данных для того, чтобы отвергнуть нулевую гипотезу (об ее
отсутствии). Таким образом, получаем, что должно выполняться неравенство
B(mi, 0, 1-Q) =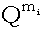 /2=/
2L,
/2=/
2L,
откуда
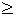 (lg()
- lg L - lg 2)/ lg(Q). (7)
(lg()
- lg L - lg 2)/ lg(Q). (7)
Например, если
= 0.01 и Q=0.75, то при L = 10,
100,
1000
и
10000 величина
mi
должна быть не меньше 27,
35,
43
и 51 соответственно. Обратим еще внимание на то, что
если данных достаточно, чтобы отвергнуть гипотезу pi(z)
Q, то их заведомо хватит на то, чтобы отвергнуть гипотезу pi(z)qQ.
Неравенство (7) позволяет также связать объем обучающей выборки с размерностью
факторного пространства, в котором работает кора. Пусть, например, полезные
ищутся среди условий ранга r. Если количество (напомним,
бинарных) факторов равно n, то 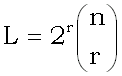 .
Отсюда и из неравенства (7) получаем
.
Отсюда и из неравенства (7) получаем
mi(lg
- lg 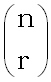 -
(r+1) lg 2)/ lg Q.
-
(r+1) lg 2)/ lg Q.
Поскольку при больших n, как известно, 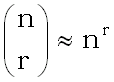 ,
имеем
,
имеем
mi(lg
- r lg n - (r+1) lg 2)/ lg Q.
Интересно, что член r lg n в полученном соотношении имеется и в оценках необходимого объема обучающей выборки, полученных Б.Н.Вапником [Вапник, 1972; Вапник, Червоненкис, 1974].
Аналогичные неравенства можно получить и из соотношений, выделяющих
критическую область для проверки гипотезы о значимости таблицы сопряженности
(разд. 1). Действительно, при фиксированном
K гипотезу
о незначимости можно отвергнуть только в случае, когда
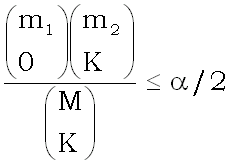 .
.
Величина в левой части неравенства минимальна при K =
m2, откуда получаем, что минимальное требование к m1
и m2 для проверки гипотезы с уровнем значимости
состоит в следующем:
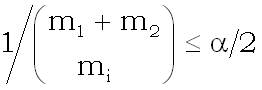 .
.
Снова заменяя 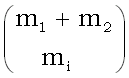 на
на 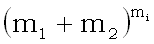 , получаем
, получаем
min (m1, m2)
lg(m1+m2)
lg - lg 2.
(8)
Повторяя проведенные ранее рассуждения, снова получаем, что для обучения алгоритма кора необходимо, чтобы было выполнено неравенство
min (m1, m2)
lg(m1+m2)
r lg n + r lg 2 - lg .
Впрочем, при разумных значениях параметров неравенство (8) предъявляет к mi более мягкие требования, чем (7).
Окончательной оценкой найденного описания является построенное по нему решающее правило, которое в исходной коре полностью определяется составленными описаниями классов и заключается в (равновесном) голосовании признаков. Это решающее правило относит объект к тому классу, за который подано наибольшее количество "голосов". Голосом за класс считается признак этого класса, выполненный на объекте.
Ясно, что с ростом объема обучающей выборки растет надежность оценки
качества найденного решающего правила при любых разумных определениях надежности
и качества; точные результаты, конечно, зависят от принятых определений.
В.Н.Вапник [Вапник, 1972; Вапник, Червоненкис, 1974; Вапник, 1979] предложил
считать решающее правило надежным, если его истинная вероятность ошибки
R
не слишком уклоняется от оценки 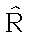 этой вероятности по обучающей выборке. Более точно, от решающего правила
требуется, чтобы было выполнено
этой вероятности по обучающей выборке. Более точно, от решающего правила
требуется, чтобы было выполнено
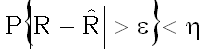 ,
(9)
,
(9)
где 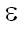 и
и  - параметры, характеризующие надежность. Поскольку заранее неизвестно,
какое из правил нужно будет оценивать, приходится выбирать объем обучающей
выборки таким, при котором неравенство (9) выполнено одновременно для всех
возможных решающих правил.
- параметры, характеризующие надежность. Поскольку заранее неизвестно,
какое из правил нужно будет оценивать, приходится выбирать объем обучающей
выборки таким, при котором неравенство (9) выполнено одновременно для всех
возможных решающих правил.
Однако, при таком подходе "единицей измерения" объема обучающей выборки во всех интересных случаях ставятся тысячи объектов. Из-за этого в реальных задачах исследователь редко бывает удовлетворен надежностью решающего правило, которую обещает ему теория, и потому всегда испытывает его на экзаменационной выборке. Но тогда можно и выводы делать лишь о проверяемом правиле!
Разделим совокупность всех решающих правил на два множество: одно из
них содержит лишь решающие правила с вероятностью ошибки, меньшей 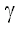 (назовем его элементы допустимыми), другое - все остальные. Теперь наша
задача состоит в том, чтобы определить, допустимо ли найденное решающее
правило. Выберем в качестве нулевой гипотезы недопустимость и будем проверять
ее на экзаменационной выборке с уровнем значимости .
Критическое значение
(назовем его элементы допустимыми), другое - все остальные. Теперь наша
задача состоит в том, чтобы определить, допустимо ли найденное решающее
правило. Выберем в качестве нулевой гипотезы недопустимость и будем проверять
ее на экзаменационной выборке с уровнем значимости .
Критическое значение 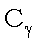 определяется соотношениями
определяется соотношениями
B(e, C, )
< B(e, C-1, ),
где e - объем экзаменационной выборки. Правило
объявляется недопустимым, если допущенное им количество ошибок больше или
равно . Вероятность
ошибки первого рода естественно интерпретируется как надежность оценки
R.
Теми же рассуждениями, что и в предыдущем разделе, получаем неравенство
e lg/ lg(1-).
Скажем, если = 0.01
и = 0.1, то e
20, а если = 0.01,
то e 200 и т.д.

|
|

Вы можете попасть на эту страницу по одному из следующих адресов:
http://learn.at/infoscope/AI/patt_rec/feat_sel/FSelect3.html
http://read.at/infoscope/AI/patt_rec/feat_sel/FSelect3.html
http://now.at/infoscope/AI/patt_rec/feat_sel/FSelect3.html
Дата последней модификации: 10 октября 2000 г.