Phonemic English
The author did typical single-letter
and digraph frequency counts on a small (~855 char's) corpus of Hamptonese.
Since the number of vowels and consonants point to phonemic English, he
tried to solve it as such.
Hamptonese has a large set
of "stroke" characters, characters organized around a stroke like /
. The author noticed that almost all the characters identified by
the Sukhotin algorithm as vowels are not stroke characters.
Therefore, the author redesignated all stroke characters as vowels.
There are no word spaces in Hamptonese.
The author prepared a 4500
character corpus of phonetic English, using text from:
By distinguishing lower- and upper-case letters, the author
used BITRANS TO make a one phoneme per letter version of a text in "Fanetiks".
u is the schwa, vowels in lower case are lax and vowels in upper case are
tense. A is a as in "hat". D is dh, thus "the" -> "Du".
The rest should be fairly clear.
The change was made in two steps, with the BITRANS script
ftk2st1.txt
used to change the Fanetik units of multiple Roman letters into a one character
per phoneme notation. The second BITRANS script st12st2.txt
changed the previous notation into one using only upper- and lower- case
Roman letters.
Note that BITRANS scripts are in the MS-DOS character set
and will not appear accurately in the ISO character used on Web pages.
The resulting phonemic English corpus and statistics:
From examination of the single-letter frequencies and digram
frequencies of Hamptonese and phonemic English, the author wrote the following
BITRANS script which changes transcribed Hamptonese to fit the statistics
of the phonemic English corpus.
This table shows how the substitutions were made:
| Symbol |
Character |
Vowel/
Consonant |
Phonemic
English
Substitution |
Pronunciation |
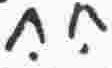 |
v |
vowel |
u |
|
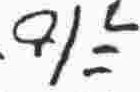 or
or 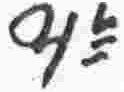 |
y |
consonant |
n |
|
 |
p |
consonant |
t |
|
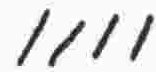 |
i |
vowel |
a |
|
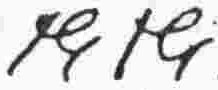 |
r |
consonant |
r |
|
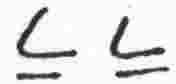 |
l |
vowel |
i |
|
 |
n |
vowel |
e |
|
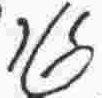 |
k |
vowel |
A |
|
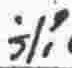 |
d |
consonant |
s |
|
 |
u |
consonant |
D |
|
 |
f |
consonant |
I |
|
 |
c |
consonant |
d |
|
 |
h |
consonant |
l |
|
 |
w |
vowel |
E |
|
 |
z |
consonant |
k |
|
 |
s |
consonant |
z |
|
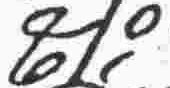 |
x |
consonant |
w |
|
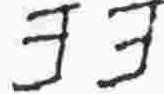 |
e |
vowel |
o |
|
 |
o |
vowel |
O |
|
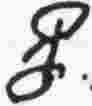 |
g |
vowel |
U |
|
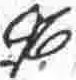 |
j |
? |
* |
|
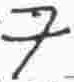 |
m |
consonant |
m |
|
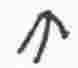 |
T |
consonant |
y |
|
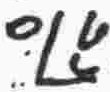 |
U |
consonant |
p |
|
 |
q |
vowel |
ay |
|
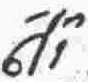 |
D |
consonant |
b |
|
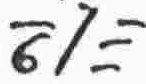 |
Y |
consonant |
v |
|
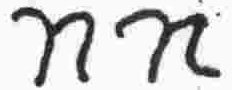 |
a |
vowel |
Y |
|
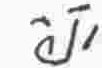 |
J |
? |
* |
|
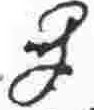 |
b |
? |
* |
|
 |
t |
consonant |
f |
|
The results were disappointing. Here is the overall
converted Hamptonese text:
Here is the result for page 92 (text only)::
otunEununu
nAnArAniI
ArnnunUonua
onanutunununu
tunununnArnwa
kAnturaonua
kaIwrnunua
wnuDununura
Untuitunuru
rtufkatinu
tuwrDutunu
tinuDwaena
wenianiniDi
nuweueuDnini
naekaIwAia
erkawrunu
erkaIIkaylm
tuDltunununu
ntituernwui
ninaIwnnwwu
wnntunununuI
Enrnueernununa
neEEtEtuDuEti
lktunioenunt
mlnunueruEi
lssstuDIsusu
Especially interesting is the comparison between the
two tables of the Ten Commandments, on pages p9 and p10:
page p10 page p9
--------------------- -------------- Bible
J-num line text line text Citation
----- ---- -------- ---- -------- --------------
--- top viD top viD(?)
I 2 kUlh 2L kUvh
II 3 wphDv 3L wphxv
III 4 Thrjv --- ------
IV 5 Tfvyv 4L fvyv
V 6 Thpvdo 5L khpv{?}do
VI 7 Tkwddv 6L cdddv{?} I no other gods
VII 8 Twwkvp 7L wwkpv II no graven images
VIII 9 Tnrrrvp 8L cnrrrvp III no name of God in vain
IX 10 chpkp 9L whpkp IV remember the Sabbath
--- --- ----- 10L fvyv V honor father & mother
X 11 wsodnp 2R ksodny{?}p
XI 12 kjgvhs 3R udvhs
XII 13 uJhos 4R khos
XIII 14 Tjvso 5R jvso
XIV 15 Tmolv 6R molv VI no murder
XV 16 Tyygosv 7R yyd{?}osv VII no adultery
XVI 17 Tnvgv 8R Dvgv VIII no stealing
XVII 18 Tgyonv 9R KgcoYv IX no false witness
XVIII 19 kgyol 10R Ugccol X no coveting
XIX 20 khDvp bot UhDvp
---- 21 viD --- ---
Although there are clearly the same "words" at corresponding
positions in the tables, they are not at all recognizable as English. If
Hamptonese were a straightforward phonemic English script, we would have
seen recognizable English. This would have been like solving a newspaper
cryptogram. Since this has failed, the author sees two possible further
hypotheses, which we shall discuss on the pages Gullah
and Idiolect .
|
