


Next: SIMULATION RESULTS
Up: Adaptive Equalization of Non-linear
Previous: COMPLEX RADIAL BASIS FUNCTION
Let
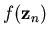 2 denote the CRBFN
output corresponding to input
2 denote the CRBFN
output corresponding to input 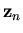 at time n as given by
at time n as given by
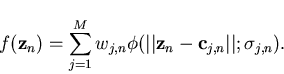 |
(3) |
Here the subscript n denotes the time index, wj,n denotes the complex
valued CRBFN weight at time n,
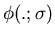 is the basis function
parameterized by
is the basis function
parameterized by 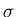 .
Also let dn and
.
Also let dn and
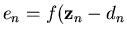 )
denote the complex valued desired response and error at time n
respectively. The training set consists of a number of pairs of inputs and
desired response
)
denote the complex valued desired response and error at time n
respectively. The training set consists of a number of pairs of inputs and
desired response
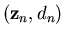 .
The SG algorithm takes the
instantaneous gradient of the squared error ||en||2 and moves the
network parameters in the opposite direction of their respective
gradients. Thus a network parameter
.
The SG algorithm takes the
instantaneous gradient of the squared error ||en||2 and moves the
network parameters in the opposite direction of their respective
gradients. Thus a network parameter 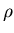 of the network (which can be a
weight, a center, or a spread parameter) is adapted at time n according to
of the network (which can be a
weight, a center, or a spread parameter) is adapted at time n according to
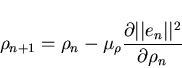 |
(4) |
where 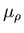 controls the speed of adaptation.
controls the speed of adaptation.
The SG algorithm does not guarantee convergence to globally optimal
network parameters. However , it does appear to converge to a reasonable
solutions in practice. The method can be used as a single-stage learning
algorithm if training data are only sequentially available or as the
second-stage method of a two-stage algorithm where centers and spread
parameters are predetermined by a method such as OLS or a clustering
technique. For the single pass case, centers can be initialized by, for
example, forming them with the first few training samples.
The SG algorithm has certain advantages over existing methods :
- 1.
- All free network parameters are adapted simultaneously, usually
yielding improved overall solutions. The method can also provide greater
robustness to poor initial choices of parameters, especially the centers.
- 2.
- The algorithm is well suited for on-line adaptive signal
processing unlike block processing algorithms such as the Moody-Darken or
the OLS algorithms. It is also computationally quite feasible.
There are variety of basis functions used in RBF's but we have selected
specifically the Gaussian basis functions as they are the most popular and
widely used. Another argument in favour of them is that the noise which
lies around the mean of the desired cluster is generally Gaussian. The
network with M basis functions gives the output
at time n as
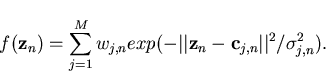 |
(5) |
Since there are always some outliers, which will lie far away from the
signal constellation we had proposed to normalize (5)
[11]. So the equation gets modified as
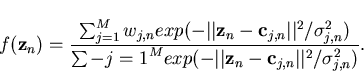 |
(6) |
with
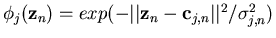 ,
the SG algorithm adapts the network parameters according to
(7)-(9), as shown below.
,
the SG algorithm adapts the network parameters according to
(7)-(9), as shown below.
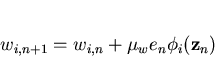 |
(7) |
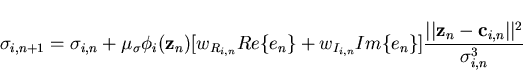 |
(8) |
![\begin{displaymath}{\bf c}_{i,n+1}={\bf c}_{i,n}+\mu_c\phi_i({\bf z}_n)\left[ \f...
...n}}Im\{e_n\}Im\{{\bf z_n-c}_{i,n}\}}
{\sigma_{i,n}^2} \right]
\end{displaymath}](img31.gif) |
(9) |
Since Gaussians are fast-decaying functions, it can be assumed that not all
basis function units contribute significantly to the network output. Hence,
instead of training all the hidden nodes, one could train only a selected
number of basis function nodes with the largest output values. When the
input dimension is high, it is the adaptation of the centers that requires
the most computation. Computation can be significantly reduced if, for
example, at each training iteration only one center is adaptively moved
while the weights and the
parameters are adapted for all nodes.
Next: SIMULATION RESULTS
Up: Adaptive Equalization of Non-linear
Previous: COMPLEX RADIAL BASIS FUNCTION
Temp DNS admin
1999-02-03