Curso de R:
Capitulo 6:Primeros ejemplos prácticos.
Bueno hasta ahora he tratado de mostraros algunas funciones de R para que empezarais a tomar contacto con la herramienta, no he trabajado con ningún ejemplo concreto a excepción del capítulo 5 donde os presenté la función t.test y sus argumentos con algún caso aplicado. Pues bien, en este capítulo voy a trabajar con ejemplos de todo lo que hemos visto hasta ahora para que sirva además de leve repaso.
Mi página existe desde finales de junio de 2002 y siempre he querido saber cual ha sido el número medio de visitas, geocities me ofrece estadísticas desde finales de julio así que voy a tomar como referencia el mes de agosto. La media de visitas a la página en el mes de agosto fueron:
> visitas<-scan() 1: 27 27 13 9 21 42 26 20 28 23 10 34 19 19 15 13 9 18: 10 17 22 17 9 21 4 9 20 20 31 21 30: 16 16 32: Read 31 items > mean(visitas) [1] 18.96774 |
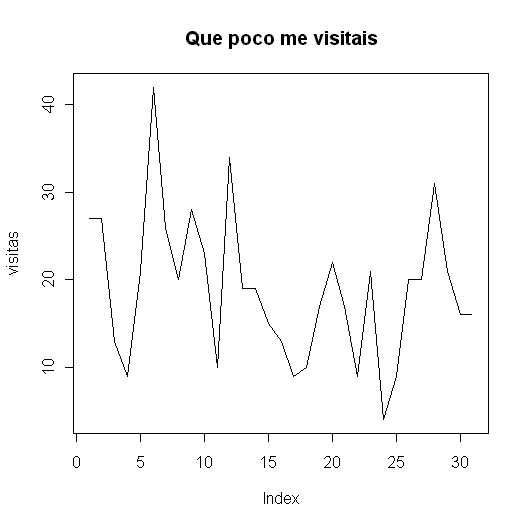
¡Sólo 19 visitas diarias a mi página! con lo que me la estoy currando, a ver si venís más de vez en cuando sólo para que vaya bien el contador. El caso es que tiene altos y bajos, vamos a verlo en un gráfico:
> plot (visitas,type="l",main="Que poco me visitais") |
Como vemos R conserva el orden ya que en el eje de ordenadas aparece index, para que la función plot una por líneas le añadimos type="l" y con main indicamos el título. Los gráficos no tienen una resolución gráfica excelente y además el trabajar con ellos es un poco engorroso pero son más que suficientes para presentar un informe escrito con cualquier editor de texto ya que basta con cortar y copiar.
Si quiero hacer un gráfico de sectores por las visitas por semana:
> semanas<-scan() 1: 31 31 31 31 5: 32 32 32 32 32 32 32 12: 33 33 33 33 33 33 33 19: 34 34 34 34 34 34 34 26: 35 35 35 35 35 35 32: Read 31 items > pie(visitas,col=semanas) |
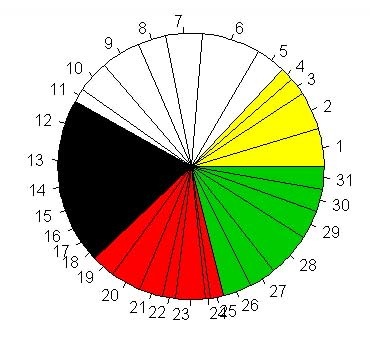
Se puede añadir leyenda con la función legend pero eso espero lo guardo para un capítulo posterior donde veremos otras funciones, como cambiar colores, ver varios gráficos en una sola ventana,...
Si quisiéramos hallar la varianza habríamos de crearnos la función ya que R calcula la cuasivarianza muestral, esto ya lo vimos en el capítulo 3. De todas formas el programa sería:
> varianza<-function(x) { ((length(x)-1)/length(x))*var(x) }
> varianza(visitas)
[1] 67.64412
> sqrt(varianza(visitas))
[1] 8.224605
|
Imaginemos ahora que tenemos un fichero ASCII que recoge llamadas a un número de ayuda. Queremos saber si el número de llamadas de los usuarios difiere según los turnos, las semanas o los días.
> llamadas<-read.table ("c:\datos\\calls.dat")
|
> llamadas
V1 V2 V3 V4
1 1 1 Mon 9
2 1 2 Mon 16
...
164 11 2 Fri 41
165 11 3 Fri 53
|
R indexa si no le indicamos lo contrario, además nombra las variables como V1, V2, V3 y V4. Si queremos nombrar las variables debemos emplear la función names.
> names(llamadas)<-c("Semanas", "Turno", "Dia", "Llamadas")
|
Es conveniente hacer un sumario para que podáis ver los valores que toman las variables que componen el conjunto de datos:
> summary(llamadas)
Semanas Turno Dia Llamadas
Min. : 1 Min. :1 Fri:33 Min. : 8.0
1st Qu.: 3 1st Qu.:1 Mon:33 1st Qu.: 67.0
Median : 6 Median :2 Thu:33 Median :129.0
Mean : 6 Mean :2 Tue:33 Mean :113.5
3rd Qu.: 9 3rd Qu.:3 Wed:33 3rd Qu.:153.0
Max. :11 Max. :3 Max. :550.0
|
También puede interesarnos sólo el saber el número medio de llamadas, para ello tenemos que acceder a la variable de un data frame, esto se hace con el símbolo $ después del nombre del objeto data frame:
> mean(llamadas$Llamadas) [1] 113.4545 |