[15,] -1 -2 #a los buenos coches les
[16,] -4 -5 # c,uesta unirse
[17,] -21 11
[18,] -26 9
[19,] 7 14
[20,] -3 15
[21,] -18 17
[22,] 12 16
[23,] 10 13
[24,] 6 21
[25,] 18 23
[26,] 19 22
[27,] 24 25
[28,] 20 26
[29,] 27 28
Curso de R:
Capitulo 10: Análisis de conglomerados (cluster) I.
El proposito del análisis de conglomerados (cluster en terminología inglesa) es el agrupar las observaciones de forma que los datos sean muy homogéneos dentro de los grupos (mínima varianza) y que estos grupos sean lo más heterogéneos posible entre ellos (máxima varianza). De este modo obtenemos una clasificación de los datos multivariante con la que podemos comprender mejor los mismos y la población de la que proceden. Podemos realizar análisis cluster de casos, un análisis cluster de variables o un análisis cluster por bloques si agrupamos variables y casos. El análisis cluster se puede utilizar para:
Nosotros vamos a estudiar el análisis cluster de casos para el que podíamos partir de un análisis de componentes principales para evitar introducir variables no relevantes, puede servirnos de ejemplo el análisis de componentes principales que se realizó en el capítulo 9.
Ejemplo 10.1:
De nuevo empleo los ejemplos para introducir la metodología del análisis. Recordemos que realizamos un análisis de componentes principales a un conjunto de datos donde aparecían las carácterísticas de técnicas de distintos coches, a partir de la matriz de correlaciones se vió que con una componente podíamos explicar el 88% de la varianza total del conjunto de datos. Pues ahora vamos a realizar sobre el valor que toma esta componente para cada observación un análisis de agrupamiento. Primero de todo creamos el conjunto de datos sobre el que vamos a trabajar:
> x<-as.matrix(conjunto) |
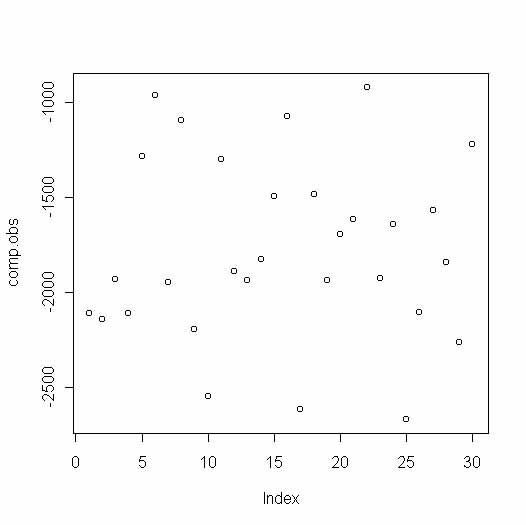
Tenemos un conjunto de datos con 30 observaciones y una variable. En todo análisis cluster existen dos fases; en una primera fase a parir de los datos construimos una matriz de distancias o similaridades y después relaizamos el proceso de agrupación de individuos. Como paso previo es interesante realizar una representación gráfica de los datos para ver si se puede reconocer algún grupo:
No parecen que se formne grupos diferenciados pero prosigamos para ver si podemos aplicar una regla de agrupamiento. Disponemos de dos técnicas de formación de cluster: técnicas jerárquicas aglo:merativas de formación de conglomerados y técnicas no jerárquicas. En este ejemplo vamoa a emplear la técnica jerárquica que consiste en considerar en primera instancia cada observación como un cluster y posteriormente agrupar las obsevarciones más "similares", las observaciones que menos disten las unas de las otras, por eso lo primero que debemos hacer es calcularnos una matriz de distancias entre pares de observaciones. En este punto hago un inciso para explicar un aspecto de R que no había comentado hasta ahora. Con R podemos hacer multitud de análisis estadísticos y además existe un grupo de programadores que colaboran con más paquetes y más programas. Para poder emplear estos paquetes es necesario tenerlos en una librería library que en mi caso está en: C:\Archivos de programa\R\rw1051\library En esta librería tengo todos los paquetes de los que puedo disponer, pero cuando tu abres una sesión de R es necesario que carges el paquete que vas a emplear. Para hacer esto está la función library(nombre_librería) o bien abrimos el menú Packages de R y seleccionamos el paquete que queremos utilizar. Os he contado esto porque para realizar el análisis cluster necesitamos cargar en paquete mva:
> library(mva) |
Ya estamos en disposición de poder empezar a realizar los cálculos pertinentes para nuestro análisis. Como hemos dicho antes lo primero es calcular la matriz de distancias y para ello tenemos la función dist:
> matriz.distancias<-dist(comp.obs) |
Hemos creado una matriz diagonal de 30x30 a partir de la matriz de componente principales donde vienen recogidas las distancias. Por defecto dist calcula la distancia euclídea entre observaciones, si ejecutáis ?dist el archivo de ayuda os presenta las distintas distancias que se pueden calcular. Una vez obtenida esta matriz hemos de emplear la función hclust(<matriz_de_distancias>,method). En method indicamos por que método queremos que R realice los agrupamientos, veamos gráficamente los métodos más comunes:
|
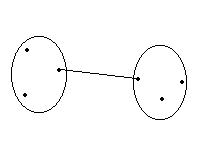
Cluster simple method="single" |
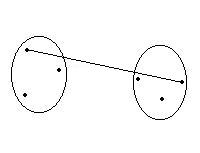
Cluster completo method="complete" |
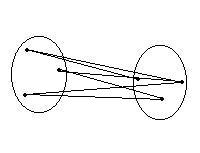
Cluster promedio method="centroid" |
También tenemos el método Ward que es una técnica inferencial de formación de conglomerados que se basa en la minimización de la suma de cuadrados dentro de los cluster que se pueden formar. Por defecto el método que tieene hclust en "complete". Veamos como funciona hclust:
> clusterI<-hclust(matriz.distancias) |
Hemos creado un objeto clusterI que contiene 7 variables a partir de las cuales realizaremos el análisis. R nos ha hecho las tareas de cálculo pero ahora somos nosotros los que tenemos que continuar determinando cuantos grupos se deben tomar y como analizar los grupos creados. Comenzamos "atacando" el objeto clusterI creado viendo la variable merge. Esta variable merge indica como se han ido formando los cluster:
> attach(clusterI) |
Esto nos ofrece una idea de la forma en la que se van uniendo, pero no podemos establecer una regla de unión entre observaciones, nos sería más útil ordenar el conjunto de datos de menor a mayor de forma que pudieramos hacer una regla de unión entre observaciones (recordemos que cuanto menor es el valor de la componente más potente y más grande es el coche) y de este modo podíamos ver intuitivamente la forma que tienen de unirse los datos. Para ordenar los datos empleamos la función sort:
> ordenado<-sort(comp.obs) |
Parece que los coches de gama media se unen enseguida, insistimos en que la componente principal ofrecía una medida de la potencia-prestaciones-tamaño de los coches, cuanto menor era la componente más potente, más rápido y más grande era el coche. Pues como decíamos los gama media se unen con facilidad, también ocurre esto con los coches más pequeños que son los siguientes en agruparse, por último son los coches "buenos" los que se van agrupando. Poco a poco los gama media se acercan a los coches buenos dejando de lado a las observaciones superiores a la 20ª como se puede ver en los pasos [18] con observaciones 24,25,26; [23] con observaciones 27,28,29,30 y [24] cuyas observaciones son 22,23,18,21,19,20 posteriormente en [25] y [27] se unen. Determinar el número de cluster con esta variable merge es bastante complicado por eso no puede servir mejor para analizar como se van creando los grupos. ¿Cómo determinar el número de cluster? En mi opinión la mejor manera es el análisis gráfico, el dendograma que es un gráfico de formación de cluster, para hacerlo se emplea la función plot.hclust(clusterII):
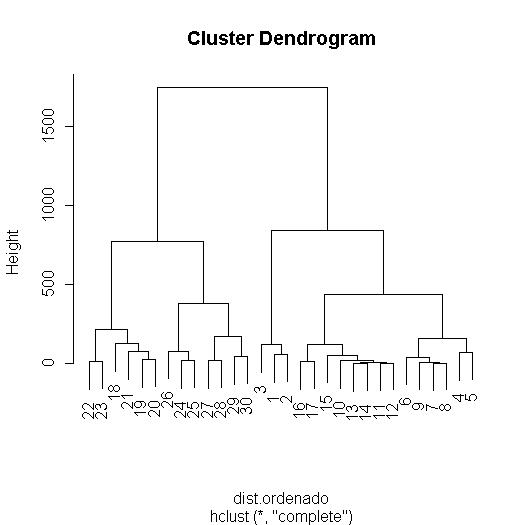
Este dendograma creo que puede admitir dos cortes que os expongo de manera gráfica para que me entendais mejor, los cortes los he realizado yo con el paint de windows, ya os explicaré como se puede hacer con R:
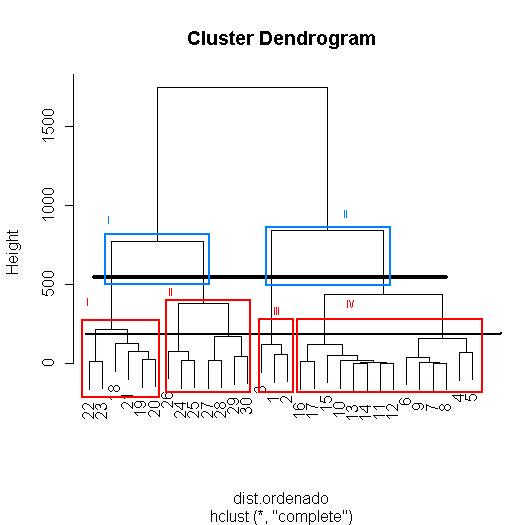
Estas son las 2 opciones que yo planteo: en la primera opción se puede por un lado formar dos grupos donde tendríamos los coches medianos-grandes donde las observaciones 1, 2 y 3 parece que les cuesta unirse (son coches muy potentes y grandes) y donde las observaciones de 4 a la 16 son muy parecidos; y por el otro lado tenemos los coches utilitarios (observaciones de la 18 a la 30) que si se pueden considerar bastante parecidos entre sí aunque los hay un poco mejores. La segunda opción sería el hacer los cuatro grupos donde el grupo I encuadraría a los coches "menos malos" el grupo II a lo "malos", el grupo III a los "mejores" y el grupo IV a los "buenos".
Este es el análisis mediante el método completo, veamos el dendograma para el método promedio:
> clusterIII<-hclust(dist.ordenado,method="centroid") |
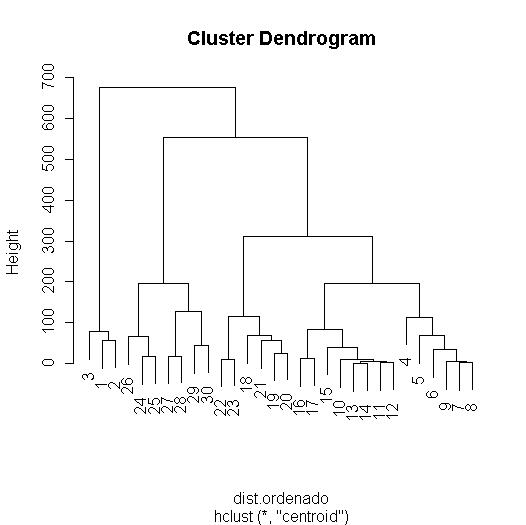
A la vista de este gráfico también podemos hacer tres grupos, además por este método se distinguen muy claramente las tres primeras observaciones como los mejores coches quedando más unidos los coches "menos malos" con los "buenos" con lo que se podía establecer un grupo que podían ser los utilitarios dentro de los cuales los hay mejoresy peores... Bueno de todas formas ya os he introducido a la metodología del análisis cluster con R así que debéis de ser vosotros los que hagais vuestro estudio y os planteéis vuestros objetivos y la forma de trabajar.
Capítulo
10: Análisis
de conglomerados (cluster) II.