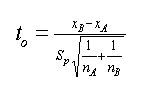 .
. Suppose we wish to compare the performance of two methods in ability to attain a quality characteristic x.
Let us call the old method A and new method B. We carry out nA tests with method A and nB tests with method B. Of course, these experiments should be randomized. That is, we should not run all tests with A first and then all tests with B or vice versa. Instead, we could toss a coin sequentially, and test with A whenever we got Head in our sequence or in some such random order mixing up As and Bs. Thus the actual run order could be A A B A B B A etc. If it is possible to carry out all the tests simultaneously, then also we should randomize to break up the effect of any lurking factors.
Let xA be the average of the nA readings of x (the usual notation is xbar for the average, but the bar has been omitted for easy coding in html) and xB the average of nB readings of x. Let SA2 be the variance of the nA readings of method A and SB2 the variance of the nB readings of method B. It is always better if nA = nB >= 8, ie the number of tests in each method should be equal and there should be at least 8 tests in each method.
Our aim is to improve x. If xB is lower than xA, it is easy: we cannot conclude that method B is better; we give the benefit of doubt to the old method. But if xB is greater than xA, we are in a dilemma: Is the new method better, or is the increase just due to chance?
So we need to compare the increase in x due to change in method with the experimental error.
We can prepare boxplots for method A and method B side by side on the x axis, with a common scale on the y axis. Comparing the differences in mean with the variability in the data, we can take a decision. If a quantitative decision is desired, we have to carry out further analysis.
To obtain a measure of the experimental error, assuming that the experimental error variation does not depend on the method (see the page on residual analysis, for how to test this assumption), we calculate the pooled variance Sp2 = [(n-1)SA2 + (n-1)SB2] /[nA+nB-2].
By dividing the observed effect xB - xA by the standard error of the difference in means, we obtain the standardized effect as .
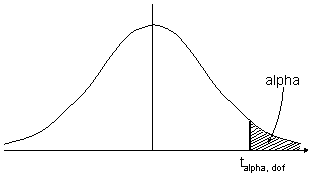 We compare this to with tcrit, the critical value of the t distribution from tables, choosing an area in the right tail corresponding to the level of significance alpha (commonly 0.05) and the appropriate degrees of freedom nA+nB-2.
We compare this to with tcrit, the critical value of the t distribution from tables, choosing an area in the right tail corresponding to the level of significance alpha (commonly 0.05) and the appropriate degrees of freedom nA+nB-2.
If to > tcrit, we can conclude that the new method is significantly better than the old.
Example:
A company has formulated a new gasoline. We would like to test whether the octane number of the new gasoline is better than that of the old. An experiment was conducted and the new gasoline gave the results 89.5, 91.5, 91.0, 89.0, 91.5, 92.0, 92,0, 90.5, 90.0 and 91.0. The old gasoline gave results 89.5, 90.0, 91.0, 91.5, 92.5, 91.0, 89.0, 89.5, 91.0, 92.0. Of course these results were not obtained in this order, but a random order.
We have xA = 90.70, SA2 = 1.34, xB = 90.80, SB2 = 1.07, nA = 10, nB = 10.
SP2 = 1.21; SP = 1.10; to = 0.20, tcrit = 1.734 for a right tail area of 0.05 and 18 degrees of freedom. Since t0 < tcrit, the new gasoline is not a significant improvement.
Reference:
Montgomery, Douglas C., "Introduction to Statistical Quality Control Third Edition", John Wiley & Sons Inc, 2001, pp.101-103.