When testing for significance of the results, we had assumed that the model errors
To test these assumptions, we have to analyse the residuals. A residual is the difference between the actual observation and the value that would be obtained from fitting the model to the sample data.
To obtain all the predicted values and residuals, we may use the Reversed Yate's algorithm:
For example,
| Column 3 of effect calculation |
In reverse order, replacing insignificants with zeroes |
Column 1 | Column 2 | Column 3 | Ypred in reverse order | Ypred in standard order |
|---|---|---|---|---|---|---|
| 5348.5 | 0 | 0 | 144 | 5358 | 669.75 | 692.5 |
| -134.5 | 0 | 144 | 5214 | 5426 | 678.25 | 633.75 |
| 7.5 | 100.5 | 0 | -57 | 5358 | 669.75 | 692.5 |
| -53.5 | 43.5 | 5214 | 5483 | 5426 | 678.25 | 633.75 |
| 43.5 | 0 | 0 | 144 | 5070 | 633.75 | 678.25 |
| 100.5 | 0 | -57 | 5214 | 5540 | 692.5 | 669.75 |
| 14.5 | -134.5 | 0 | -57 | 5070 | 633.75 | 678.25 |
| -46.5 | 5348.5 | 5483 | 5483 | 5540 | 692.5 | 669.75 |
Now, the residuals may be obtained by subtracting the predicted values from each observed value. For example, for run 3, the observed value is 705. Since the predicted value is 692.5, the residual is 12.5.
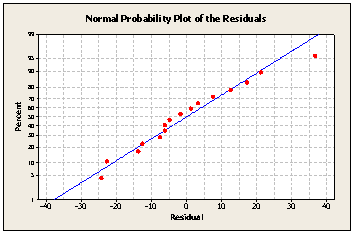
To test the normality assumption 1, we can construct a normal probability plot of the residuals.
To test the independence assumption 2, we may plot the residuals against the run order in which the experiment was performed. A pattern in this plot, such as sequences of positive and negative residuals, may indicate that the observations are not independent. This may mean that the run order was important, or that variables that change over time are important and have not been included in the design.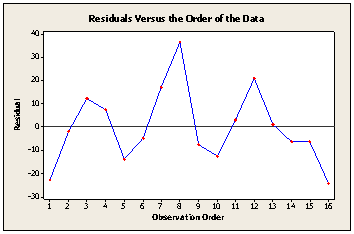
To check the assumption 3 of equal variances, plot the residuals against the predicted values (fitted values) and compare the spread in residuals. The variablity in the residuals should not depend in any way on the predicted value. When a pattern appears, like increasing variability with increase in predicted value, there may be a need for data transformation. Plotting the residuals against the factor levels also should show the same spread.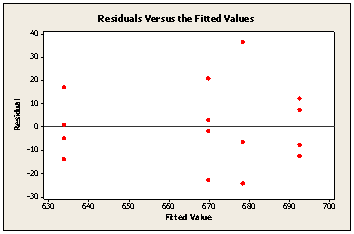
Reference:
Montgomery, Douglas C., "Introduction to Statistical Quality Control - Third Edition", John Wiley & Sons Inc., New York, 2001, pp.114-115.