


Next: SIMULATION
Up: INTERFERENCE MITIGATION USING ADAPTIVE
Previous: .
The training of the radial basis function is basically the positioning of
centres at desired positions or desired states.Although, the desired
signal states are initially unknown, they are the cluster means, in
the observation states. Learning can therefore be achieved efficiently
using a supervised or decision directed clustering algorithm and this has
been investigated in [6]. When co-channel interference is also
present then a simple supervised clustering is not sufficient, so there
has to be a two stage procedure and this needs that the supervised
clustering procedure is followed by unsupervised clustering procedure. The
supervised clustering procedure is
Because of the underlying data structure, a rapid convergence of this
supervised clustering procedure is guaranteed, and the algorithm is very
simple and robust. The supervised/decision directed clustering algorithm
infers which desired signal state appears. Suppose that the ith desired
signal state occurs. The noise-free observation state that actually
appears must be within the ith group of the l noise free observation
state states. The unsupervised algorithm then searches through the this
group to find the state that actually appears and to adjust the
corresponding RBF accordingly.
The unsupervised clustering computes squared distances
between the centres and the data vector y(k), selects a minimum squared
distance and moves the corresponding centre closer to y(k). if the ith
desired signal state appears at k, the computational procedure of the
unsupervised clustering algorithm is given as
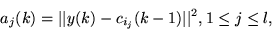 |
(7) |
![\begin{displaymath}j^*=arg[min\{a_j(k), i \leq j \leq l \}],
\end{displaymath}](img35.gif) |
(8) |
|
cij(k) = cij(k-1)+gc(y(k)-cij(k-1)).
|
(9) |
where gc is the learning rate for the centres.
It should be emphasized that the above combined clustering algorithm is
all that is required to adapt an RBF network in the case of equiprobable
symbols. If the assumption of equiprobable events is violated, then the
weights of the RBF network can be adapted using the following LMS type
algorithm.
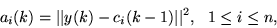 |
(10) |
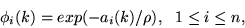 |
(11) |
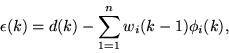 |
(12) |
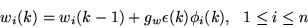 |
(13) |
where ci is the centre of RBF, wi is the weight of RBF, 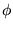 is
the basis function, gc is the learning rate for centres, gw is the
learning rate for weights,
is
the basis function, gc is the learning rate for centres, gw is the
learning rate for weights, 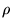 is the width of RBF,
is the width of RBF, 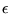 is the
error in the
approximation.
is the
error in the
approximation.
For complex signals, the stochastic gradient (SG) algorithm gives better
results. The SG algorithm does not guarantee convergence to globally
optimum network parameters, however it does appear to converge to
reasonable solutions in practice. The method can be used as a single-stage
learning algorithm if training data are only sequentially available or as
the second stage method of two stage algorithm where centers are spread
parameters and are predetermined by a method such as the OLS or clustering
technique. The advantage of SG algorithm is that all the free network
parameters are adapted simultaneously, usually yielding improved overall
solutions. Also, the algorithm is well-suited for on-line adaptive signal
processing. The SG algorithm for CRBFN is as follows.
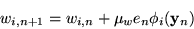 |
(14) |
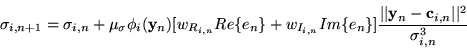 |
(15) |
![\begin{displaymath}{\bf c}_{i,n+1}={\bf c}_{i,n}+\mu_c\phi_i({\bf y}_n)\left[ \f...
...n}}Im\{e_n\}Im\{{\bf y_n-c}_{i,n}\}}
{\sigma_{i,n}^2} \right]
\end{displaymath}](img44.gif) |
(16) |
where w are the weights, e is the error, 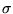 is the width,
is the width,
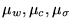 are the learning rates of weights, centres, and width
respectively
are the learning rates of weights, centres, and width
respectively
Next: SIMULATION
Up: INTERFERENCE MITIGATION USING ADAPTIVE
Previous: .
Temp DNS admin
1999-02-04