




Partnership




SETI@home: un esperimento di elaborazione con risorse pubbliche
di David P. Anderson, Jeff Cobb, Eric Korpela, Matt Lebofsky, Dan Werthimer
(Space Sciences Laboratory , University of California at Berkeley)
Tratto da Communications of the ACM, Vol. 45 No. 11, November 2002, pp. 56-61.
Traduzione di Edoardo Rocca e Bruno Moretti Turri IK2WQA, SETI ITALIA G. Cocconi
SETI@home utilizza i computer nelle case e negli uffici intorno al mondo per analizzare i segnali dei radiotelescopi.
Questo approccio, sebbene presenti alcune difficoltà, ha fornito una potenza di calcolo senza precedenti
ed ha condotto ad un coinvolgimento unico del pubblico nella Scienza.
Descriviamo la progettazione e la realizzazione di SETI@home e discutiamo la sua attinenza a futuri sistemi distribuiti.
Introduzione
SETI (Search for ExtraTerrestrial Intelligence) è un' area scientifica il cui obiettivo è rilevare
la vita intelligente fuori dalla Terra (SHO98). Un approccio, conosciuto come radio SETI,
utilizza i radiotelescopi per ricevere segnali radio a banda stretta dallo spazio.
Detti segnali, notoriamente, non sono presenti in natura, per cui una scoperta della loro presenza
fornirebbe un'evidenza di tecnologia extraterrestre (COC59).
I segnali dei radiotelescopi consistono principalmente di rumore (noise), provocato da sorgenti celesti
e dall'elettronica del ricevitore, e segnali artificiali come stazioni TV, radar e satelliti.
I moderni progetti radio SETI analizzano i dati in modo digitale.
Generalmente questa analisi implica tre fasi:
1. Calcolare la variazione nel tempo della potenza nello spettro dei segnali
2. Cercare segnali candidati utilizzando strutture di riconoscimento sugli spettri di potenza.
3. Eliminare segnali candidati che sono probabilmente naturali o artificiali.
Maggiore potenza di calcolo permette alle ricerche di coprire grandi intervalli di frequenza
con maggiore sensibilità. Radio SETI ha un appetito insaziabile per la potenza di calcolo.
I precedenti progetti radio SETI hanno utilizzato supercomputer dedicati, localizzati presso
il telescopio, per effettuare l' analisi dei dati. Nel 1995, David Gedye propose di effettuare
questa analisi radio SETI utilizzando un supercomputer virtuale composto da un grande
numero di computer connessi ad internet ed ha organizzato il progetto SETI@home
per esplorare questa idea. SETI@home non ha trovato segni di vita extraterrestre.
Ma, insieme a progetti di calcolo distribuito e progetti di raccolta dati collegati,
è riuscito a stabilire la fattibilità del calcolo con risorse pubbliche
(così detto in quanto le risorse di calcolo sono fornite dal pubblico generale).
Il calcolo con risorse pubbliche non è nè una panacea nè una passeggiata.
Per molte attività, l'enorme potenza di calcolo implica una larghezza di banda in rete enorme
e la larghezza di banda è di solito cara o limitata.
Questo fattore ha limitato l'intervallo di frequenza esaminato da SETI@home,
poiché un intervallo più ampio implica più bits al secondo.
Comparato ad altri progetti radio SETI, SETI@home copre una gamma di frequenza più stretta
ma effettua un analisi più approfondita di quella gamma (vedi Tabella 1).

La prima sfida per SETI@home era quella di trovare un buon radiotelescopio.
La scelta ideale era il telescopio di Arecibo, Puerto Rico, il più grande e più sensibile
radiotelescopio del mondo. Arecibo è utilizzato per varie ricerche astronomiche
ed atmosferiche e noi non abbiamo potuto ottenere di utilizzarlo in esclusiva per un lungo periodo.
Tuttavia, nel 1997 il progetto U.C. Berkeley SERENDIP ha sviluppato una tecnica
per installare in parallelo (piggybacking) un'antenna secondaria ad Arecibo [WER97].
Come l'antenna principale traccia un punto fisso nel cielo (sotto il controllo di altri ricercatori),
l'antenna secondaria attraversa un arco che copre l'intera zona di cielo visibile al telescopio.
Questa sorgente di dati può essere utilizzata per un'indagine del cielo che comprende miliardi di stelle.
Ci siamo accordati per consentire a SETI@home di condividere la sorgente dati di SERENDIP.
A differenza di SERENDIP, noi dovevamo distribuire i dati attraverso Internet.
A quel tempo, il collegamento Internet di Arecibo era un modem a 56Kbps,
cosicché decidemmo di registrare i dati su nastri removibili (DLT da 35GB, i più grandi
disponibili all'epoca), spedirli da Arecibo al nostro laboratorio alla U.C. Berkeley
e distribuire i dati dai nostri server
Decidemmo di registrare i dati a 5 Mbps (5 Megabits/s).
Questa velocità era sufficientemente bassa da riempire un nastro in 16 ore,
rendendo possibile distribuire i dati successivamente, attraverso il collegamento ad Internet
a 100 Mbps del nostro laboratorio. Ma insufficiente per un'accurata analisi scientifica dei dati.
Con un campionamento complesso a 1 bit questa velocità fornisce una banda di frequenza di 2,5 MHz,
sufficiente per trattare spostamenti Doppler per velocità relative fino a 260 km/sec o all'incirca
la velocità di rotazione galattica (i segnali radio sono spostati per Effetto Doppler in proporzione
alla velocità del mittente rispetto a quella deldestinatario).
Come molti altri progetti radio SETI, abbiamo centrato la nostra banda sulla linea dell' idrogeno
(1,42 GHz), all'interno di un intervallo di frequenza dove le trasmissioni artificiali sono vietate
da un trattato internazionale.
Il modello computazionale di SETI@home è semplice.
I dati dei segnali sono divisi in unità di lavoro di dimensione fissa che vengono distribuiti,
per mezzo di Internet, a un programma client che gira su numerosi computer.
Il programma client calcola un risultato (un gruppo di segnali candidati), lo restituisce al server
e ottiene un'altra unità di lavoro. Non c'è alcuna comunicazione fra client.
SETI@home effettua un calcolo ripetuto: ogni unità di lavoro è trattata più volte.
Questo ci consente di rilevare e scartare i risultati dovuti a processori difettosi e utenti maligni.
Un livello di "ridondanza" da due a tre è adeguato per questo scopo.
Generiamo unità di lavoro ad una velocità fissa e non rifiutiamo mai un client che richieda il lavoro,
cosicché il livello di ridondanza aumenta con il numero di client e la loro velocità media.
Queste quantità sono aumentate molto durante la vita del progetto.
Abbiamo tenuto il livello di ridondanza all'interno dell'intervallo chiesto modificando il client
per effettuare più elaborazioni per unità di lavoro.
Il compito di creare e distribuire unità di lavoro è affidato ad un complesso di server situati
nel nostro laboratorio (vedi Figura 1). Le ragioni che ci hanno indotto a centralizzare le funzioni
del server erano largamente pragmatiche: ad esempio, è minimizzata la gestione del nastro.
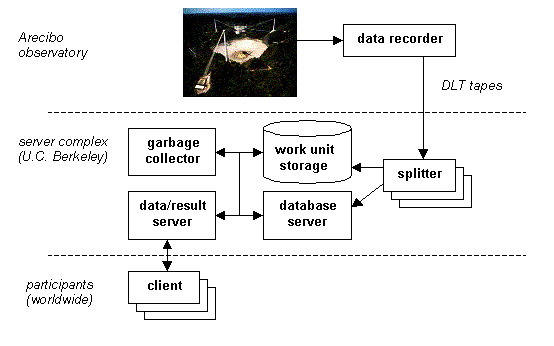
Figura 1: la distribuzione dei dati
Le unità di lavoro sono create dividendo il segnale a 2,5 MHz in 256 bande di frequenza,
ognuna larga circa 10 KHz. Ogni banda è quindi divisa in segmenti da 107 secondi
sovrapposti nel tempo di 20 secondi. Questo assicura che i segnali che cerchiamo
(i quali durano fino a 20 secondi, vedi sotto) siano contenuti per intero in almeno un'unità
di lavoro. Le unità di lavoro risultanti sono da 350 KB - sufficienti a tenere un computer
medio impegnato per almeno un giorno, ma sufficientemente piccole da poterle scaricare
con un modem lento in pochi minuti.
Utilizziamo un database relazionale per memorizzare le informazioni sui nastri,
sulle unità di lavoro, i risultati, gli utenti ed altri aspetti del progetto.
Abbiamo sviluppato un server multithread dati/risultati per distribuire le unità di lavoro
ai clients. Utilizza un protocollo basato su HTTP per consentire che macchine protette
da firewall possano contattarlo.
Le unità di lavoro sono fatte pervenire nell'ordine di quello inviato meno di recente.
Un programma garbage collector rimuove le unità di lavoro dal disco,
azzerando un indicatore di presenza sul disco nei loro database.
Abbiamo fatto esperimenti seguendo due politiche:
* Cancellare unità di lavoro per le quali N risultati siano stati ricevuti, dove N è il nostro
obiettivo di ridondanza. Se il deposito di unità di lavoro si riempie, si blocca la produzione
di unità di lavoro e il rendimento del sistema cala.
* Cancellare le unità di lavoro che sono state inviate M volte, dove M è leggermente
più alto di N. Questo elimina il summenzionato collo di bottiglia, ma fa in modo che
alcune unità di lavoro non diano mai risultati. Questa frazione può essere resa
arbitrariamente piccola aumentando M. Attualmente seguiamo questa politica.
Mantenere operativo il sistema dei server è stata la parte più difficile e più onerosa
di SETI@home. Le cause di malfunzionamenti, sia hardware che software,
sono arrivati a sembrare illimitati. Ci siamo indirizzati verso un'architettura che
minimizza le dipendenze fra i sottosistemi server. Per esempio, il server dei dati/risultati
può essere gestito in modo che, invece di utilizzare il database per numerare le unità
di lavoro da inviare, ottiene queste informazioni da un file su disco.
Questo ci consente di distribuire i dati anche quando il database è down.
Il client ottiene ripetutamente un'unità di lavoro dal server di dati/risultati, lo analizza
e restituisce il risultato (una lista di segnali candidati) al server. Ha bisogno solo di
un collegamento Internet durante la comunicazione con il server.
Il client (screensaver) può essere configurato per calcolare solo quando il suo pc-ospite
è inattivo o calcolare costantemente ad una priorità bassa.
Il programma scrive periodicamente i suoi progressi in un file su disco e legge questo file
all' avvio; perciò l'analisi non è interrotta anche se la macchina è spenta frequentemente.
L'analisi di un'unità di lavoro implica il calcolo della potenza del segnale come una funzione
della frequenza e del tempo, e quindi cercare numerosi tipi di strutture in questa funzione
di potenza: gli spikes (lampi brevi), i Gaussians (segnali a banda stretta con 20 secondi
di sviluppo della Gaussiana, corrispondenti al movimento dell'antenna del telescopio
nell'attraversare un punto sul cielo), Pulses (segnali pulsati) segnali Gaussiani pulsati
con arbitrari periodo, fase e ciclo, e Triplets (triplette) tre lampi equamente spaziati
alla stessa frequenza; - un semplice segnale pulsato).
Segnali la cui potenza e qualità superano certe soglie sono registrate nel file di output.
Due parametri che variano (KOR01):
Rateo di spostamento Doppler. Se il mittente di un segnale di fissata frequenza
accelera relativamente al ricevente (es. per il moto del suo pianeta rispetto alla Terra)
il segnale ricevuto si sposta in frequenza. E' meglio rilevare questo segnale in modo
da annullare lo spostamento nei dati originali, poi guardare la costanza in frequenza
del segnale. Lo spostamento in frequenza è sconosciuto; noi testiamo 31.555 diversi
spostamenti, coprendo l' intervallo delle accelerazioni fisicamente probabili.
Risoluzione in frequenza. Noi copriamo 15 risoluzioni in frequenza che vanno
da 0,075 a 1.220,7 Hz. Questo incrementa la sensibilità verso un segnale modulato,
di frequenza superiore all'intervallo.
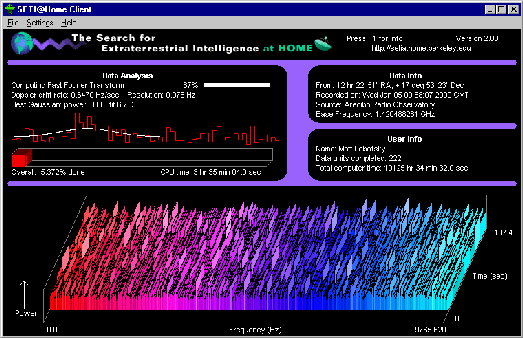
Figura 2: Il display di SETI@home mostra la potenza dello spettro
attualmente elaborata (in basso) e la Gaussiana migliore (sinistra).
Il programma client di SETI@home è scritto in C++.
Il codice consiste di una struttura indipendente dalla piattaforma di calcolo distribuita
(6.423 righe), componenti con le implementazioni specifiche per la piattaforma,
quali la libreria dei grafici (2.058 righe nella versione di UNIX),
il codice SETI-specifico di analisi di dati (6.572 righe) ed il codice di grafici
SETI-specifico (2.247 righe).
Il client e' stato preparato per 175 piattaforme differenti. Gli strumenti di GNU,
compreso il gcc ed autoconf, hanno notevolmente facilitato questa operazione.
Effettuiamo le versioni di Windows, di Macintosh e di SPARC/Solaris noi stessi;
tutto l'altro porting è fatto dai volontari.
Il client può funzionare come processo a bassa priorità, come applicazione del GUI,
o come screensaver. Per sostenere questi modi differenti sulle piattaforme multiple,
usiamo un' architettura in cui un processo fa la comunicazione e l'elaborazione dei dati,
un secondo processo maneggia le interazioni del GUI e un terzo processo
(forse in una area separata) restituisce i grafici basati su una struttura di dati a memoria condivisa.
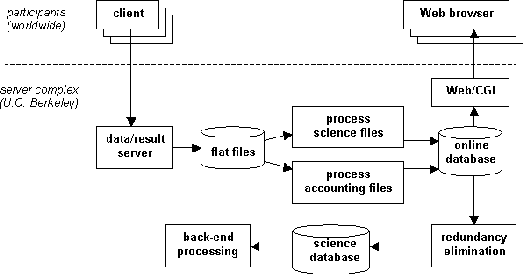
Figura 3: La raccolta e analisi dei risultati.
I risultati sono restituiti al server di SETI@home, in cui sono registrati ed analizzati (si veda figura 3).
Il trattamento dei risultati consiste di due processi:
* Scientifica: Il data/server scrive il risultato su di un archivio del disco.
Un programma legge questi archivi, creando i record del segnale e di risultato nel database.
Per ottimizzare il rendimento, parecchie copie di questo programma funzionano simultaneamente.
* Contabilità: Per ogni risultato, il server scrive un'entrata nel log che descrive l'utente del risultato,
il relativo TEMPO CPU e così via. Un programma legge questi archivi di log; accumula
in una cache l'aggiornamento di tutti i dati (utente, team, paese, tipo di CPU e così via).
Ogni pochi minuti invia questa cache al database.
Bufferizzando gli aggiornamenti negli archivi su disco, il server può recuperare i periodi
di guasto e di sovraccarico del database.
Finalmente, ogni unità di lavoro ha un certo numero di risultati nel database.
Un programma di eliminazione di sovrabbondanza esamina ogni gruppo di risultati ridondanti -
che possono differire nel numero di segnali e parametri di segnale - e usa una politica
approssimativa di consenso per scegliere un risultato "canonico" per quell'unità di lavoro.
I risultati canonici sono copiati in un database separato.
La fase finale, processo di back-end, consiste di parecchi punti.
Per verificare il sistema, controlliamo per vedere se c'è il segnale di prova ricevuto dal telescopio.
I segnali artificiali (RFI) sono identificati ed eliminati.
Cerchiamo i segnali con frequenza e coordinate celesti simili rilevate in tempi differenti.
Questi "segnali ripetuti", così come i segnali unici di sufficiente merito, sono studiati più a fondo,
potenzialmente pronti ad un cross-check finale da altri progetti di radio SETI secondo
un protocollo accettato (DOP90).
La risposta del pubblico a SETI@home
Abbiamo annunciato i programmi per SETI@home nel 1998 e 400.000 persone si sono
preregistrate durante l'anno successivo. Nel maggio 1999 abbiamo rilasciato le versioni
Windows e Macintosh del client. In una settimana circa 200.000 persone aveva trasferito
e fatto funzionare il client dal sistema centrale verso il proprio e questo numero si è sviluppato
a più 3,83 milioni fino a luglio 2002.
Umanità di 226 paesi partecipa a SETI@home; circa la metà negli Stati Uniti.
Nei 12 mesi iniziati nel luglio 2001 i partecipanti a SETI@home hanno elaborato
221 milioni di unità di lavoro. Il rendimento medio durante quel periodo era 27,36 TeraFLOPS.
In generale, il calcolo ha realizzato 1,7^21 calcoli in virgola mobile, il record del più grande calcolo.
SETI@home conta soprattutto sulle notizie dei mass-media e del passa parola per attrarre
i partecipanti. Il nostro sito Web (http://setiathome.berkeley.edu) spiega il progetto,
permette agli utenti di trasferire il programma dal sistema centrale verso il proprio
e fornisce le notizie scientifiche e tecniche.
Il sito Web mostra le statistiche (basate sulle unità del lavoro elaborate) per gli individui
e per gruppi quali i paesi e dominii di email. Gli utenti possono formare team che competono
all'interno delle categorie; esistono 97.000 team. La concorrenza (fra individui, team,
proprietari di tipi differenti di calcolatore e così via) ha contribuito ad attrarre e mantenere
i partecipanti. In più, gli utenti sono riconosciuti sul sito Web e sono ringraziati da email
quando passano certi traguardi nelle unità di lavoro calcolate.
Abbiamo provato a promuovere una Comunità di SETI@home in cui gli utenti possono
scambiare informazioni ed opinioni. Il sito Web permette agli utenti di inserire il profilo
ed immagini di se stesso ed ha un sondaggio in linea con le domande riguardo alla demografia,
a SETI ed al calcolo distribuito (dei 95.000 utenti che hanno completato questo sondaggio,
per esempio, 93% sono maschi). Abbiamo aiutato nella creazione di un newsgroup, sci.astro.seti,
dedicato in gran parte a SETI@home. Gli utenti hanno creato vari software dipendenti,
quali i server di scarico dei dati ed i sistemi per la visualizzazione grafica del progresso di lavoro.
Il nostro sito Web contiene i collegamenti a questi contributi.
Gli utenti hanno tradotto il sito Web in 30 lingue.
Abbiamo lavorato per impedire che il nostro programma client fungesse da vettore per i virus
e finora siamo riusciti: il nostro download-server (per quanto sappiamo) non è stato violato
ed il nostro client non veicola virus. Ci sono stati due attacchi considerevoli ed il nostro web
server si è compromesso; gli hackers, per esempio, non sono riusciti ad installare cavalli di Troia
nella pagina del download. Più tardi, sfruttando un difetto di disegno nel nostro protocollo
client/server, gli hackers hanno ottenuto alcuni indirizzi email di utenti. Abbiamo riparato il difetto,
ma non prima che migliaia di indirizzi venissero rubati. In più, un utente ha sviluppato un virus
propagato per email che trasferisce ed installa SETI@home da un calcolatore infettato,
che configurava il client per l'accreditamento al suo account di SETI@home.
Ciò potrebbe essere evitato richiedendo un'immisione manuale nel processo di installazione.
Per contro, abbiamo dovuto proteggere SETI@home dai partecipanti disonesti e cattivi.
Ci sono stati molti casi, anche se soltanto una frazione molto piccola dei partecipanti è implicata.
Un esempio relativamente benigno: alcuni utenti hanno modificato il client eseguibile per
migliorare le relative prestazioni su processori specifici. Non ci siamo fidati della precisione
di tali modifiche e non abbiamo voluto che SETI@home fosse usato nelle "guerre al banco prova"
di conseguenza abbiamo adottato una politica per vietare le modifiche.
Abbiamo scoperto e sconfitto molti trucchi per ottenere l' accreditamento di lavoro non fatto.
Altri utenti hanno trasmesso deliberatamente risultati errati.
Queste attività sono difficili da evitare se gli utenti possono fare funzionare il programma client
con un debugger, analizzare la relativa logica ed ottenere dati crittografati (MOL00).
Il nostro controllo di sovrabbondanza, insieme alla tolleranza di errore dei calcoli,
è sufficiente per risolvere il problema; altri meccanismi sono stati proposti (SAR01).
Conclusioni
IL calcolo con risorse pubbliche conta sulla potenza inutilizzata dei personal computer,
con tempo di CPU al minimo. L'idea di usare questi cicli per il calcolo distribuito
è stata proposta dal Worm computation project a Xerox PARC,
che ha usato le stazioni di lavoro all'interno di un laboratorio di ricerca (SHO82)
e successivamente è stata esplorata dai progetti accademici quale il Condor.
Il calcolo su grande scala con risorsa pubblica è diventato fattibile con lo sviluppo
di Internet negli anni 90.
Due progetti importanti di calcolo distribuito precedono SETI@home.
The Great Internet Mersenne Prime Search (GIMPS), che cerca i numeri primi,
ha cominciato nel 1996. Distributed.net, che dimostra la forza bruta della decriptazione,
ha cominciato nel 1997. Le applicazioni più recenti includono Folding@home
e la scoperta di medicine (the Intel-United Devices Cancer Research Project).
Parecchi sforzi sono in corso per sviluppare le strutture per usi diversi della risorsa
pubblica e altri calcoli distribuiti su grande scala. I progetti collettivamente chiamati
The Grid stanno sviluppando sistemi per la spartizione delle risorse fra gli organismi
di ricerca ed accademici (FOS99). Aziende private quali la Platform Computing,
Entropia e United Devices stanno sviluppando sistemi per il calcolo distribuito
e memorizzazione sia in organizzazione che presso privati.
Ad un livello più generale, la risorsa pubblica di calcolo è una funzione
"peer-to-peer paradigm", che consiste nello spostare le funzioni dai server centrali
alle stazioni di lavoro e ai pc domestici (ORA01).
Quali processi sono più adatti al calcolo distribuito? Esaminiamo alcuni fattori.
In primo luogo, il processo dovrebbe avere un alto rapporto calcoli/dati prodotti.
Ogni unità di dati di SETI@home ha bisogno di 3,9 trilioni di calcoli in virgola mobile,
o circa 10 ore su un Pentium II da 500 MHz, tuttavia coinvolge soltanto un download
di 350KB e un upload di 1 KB. Questo alto rapporto mantiene il traffico della rete
del server ad un livello trattabile ed impone un carico minimo alla rete del client.
Le applicazioni come rappresentazione grafica richiedono grandi dati per il calcolo dell'unità,
forse rendendoli inadatti al calcolo della risorsa pubblica.
Tuttavia, le riduzioni dei costi di larghezza di banda affievoliranno questi problemi
e le tecniche del multicast possono ridurre il costo quando una gran parte dei dati è costante.
In secondo luogo, i processi con parallelismo indipendente sono più facili da maneggiare.
L'elaborazione dell'unità di lavoro di SETI@home è indipendente, in modo che i computer
del partecipante non devono mai aspettare per comunicare con un'altro.
Se un calcolatore si guasta mentre elabora un'unità di lavoro, questa è trasmessa ad un altro
calcolatore. La risorsa pubblica di calcolo, con i relativi frequenti guasti del calcolatore
e sconnessioni della rete, non è facilmente sfruttabile da applicazioni che richiedono
la frequente sincronizzazione e comunicazione tra nodi. Tali applicazioni, al momento,
sono elaborate usando metodi sia hardware-based come i multiprocessori a memoria
ripartita sia software-based mediante cluster computing, quali PVM (SUN90).
Tuttavia, meccanismi di schedulazione capaci di gestire tali processi in macchine
collegate in rete possono eliminare queste difficoltà.
In terzo luogo, i processi che tollerano gli errori sono più adatti al calcolo distribuito.
Per esempio, se un'unità di lavoro di SETI@home è analizzata in modo errato o per niente,
interessa parzialmente l'obiettivo generale.
Ancora, l'omissione è rimediata quando il telescopio esplora lo stesso punto nel cielo.
Per concludere, un progetto di calcolo distribuito deve attrarre i partecipanti.
Ci sono attualmente molti calcolatori collegati ad Internet per circa 100 progetti simili
a SETI@home e progetti interessanti ed utili sono stati proposti come il modello climatico
globale e la simulazione ecologica. Per attirare i partecipanti, crediamo che i progetti
debbano spiegare e giustificare i loro obiettivi e fornire le prospettive di progresso
locale e globale. Un mezzo eccellente per visualizzare tutto questo sono gli Screensaver grafici,
che forniscono anche una forma di marketing virtuale.
Il successo dei progetti di calcolo distribuito avrà i benefici subordinati di incrementare
il counvolgimento del pubblico alla scienza e di democratizzare, in egual misura,
la distribuzione delle risorse di ricerca.
Ringraziamenti
SETI@home è stato concepito da David Gedye.
Woody Sullivan, Craig Kasnov, Kyle Granger, Charlie Fenton, Hiram Clawson,
Peter Leiser, Eric Heien, e Steve Fulton hanno contribuito alle idee di SETI@home.
Ringraziamenti ai nostri partecipanti e ringraziamenti a The Planetary Society,
Sun Microsystems, the U.C. DiMI program, Fujifilm, Quantum, Informix, Network Appliances,
ed alle altre organizzazioni ed individui che hanno sostenuto SETI@home.
Torna ad Articoli scientifici
Torna alla home
Copyright © 2004 University of California
Versione Italiana Copyright © 2004 Bruno Moretti Turri