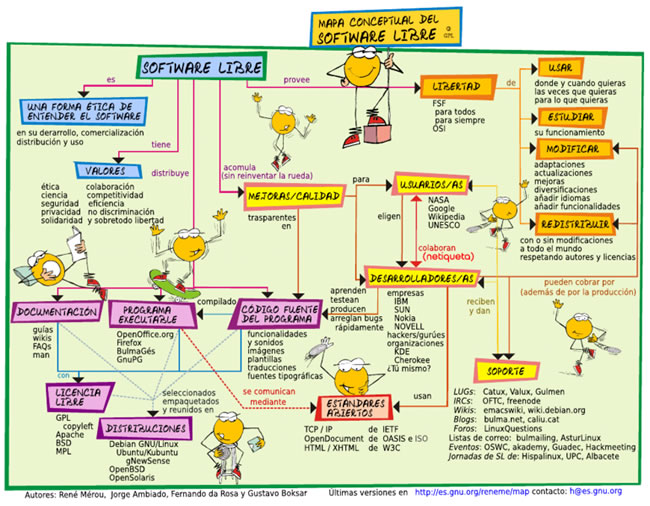
Que es Software Libre
Según Wikipedia Software libre (free software) es la denominación del software que brinda libertad a los usuarios sobre su producto adquirido y por tanto, una vez obtenido, puede ser usado, copiado, estudiado, modificado y redistribuido libremente. Siguiendo un poco con este concepto tenemos que Según la Free Software Foundation, el software libre se refiere a la libertad de los usuarios para ejecutar, copiar, distribuir, estudiar, cambiar y mejorar el software; de modo más preciso, se refiere a cuatro libertades de los usuarios del software: la libertad de usar el programa, con cualquier propósito; de estudiar el funcionamiento del programa, y adaptarlo a las necesidades; de distribuir copias, con lo que puede ayudar a otros; de mejorar el programa y hacer públicas las mejoras, de modo que toda la comunidad se beneficie (para la segunda y última libertad mencionadas, el acceso al código fuente es un requisito previo).
Libertades del Software Libre
De acuerdo con la definición, el software es "libre" si garantiza las siguientes libertades:
Libertad 0 |
Libertad 1 |
Libertad 2 |
Libertad 3 |
Ejecutar el programa con cualquier propósito (privado, educativo, público, comercial, militar, etc.) |
Estudiar y modificar el programa (para lo cual es necesario poder acceder al código fuente) |
Copiar el programa de manera que se pueda ayudar al vecino o a cualquiera |
Mejorar el programa y publicar las mejoras |
Es importante señalar que las libertades 1 y 3 obligan a que se tenga acceso al código fuente. |
La "libertad 2" hace referencia a la libertad de modificar y redistribuir el software libremente licenciado bajo algún tipo de licencia de software libre que beneficie a la comunidad. |
El software libre suele estar disponible gratuitamente, o a precio del coste de la distribución a través de otros medios; sin embargo no es obligatorio que sea así, por ende no hay que asociar software libre a "software gratuito" (denominado usualmente freeware), ya que, conservando su carácter de libre, puede ser distribuido comercialmente ("software comercial"). Análogamente, el "software gratis" o "gratuito" incluye en algunas ocasiones el código fuente; no obstante, este tipo de software no es libre en el mismo sentido que el software libre, a menos que se garanticen los derechos de modificación y redistribución de dichas versiones modificadas del programa.
Para concluir con este termino, no se debe confundir software libre con "software de dominio público". Éste último es aquél que no requiere de licencia, pues sus derechos de explotación son para toda la humanidad, porque pertenece a todos por igual. Cualquiera puede hacer uso de él, siempre con fines legales y consignando su autoría original. Este software sería aquél cuyo autor lo dona a la humanidad o cuyos derechos de autor han expirado, tras un plazo contado desde la muerte de éste, habitualmente 70 años. Si un autor condiciona su uso bajo una licencia, por muy débil que sea, ya no es dominio público.
Fuente: Mapa conceptual del software libre
URL: http://es.wikipedia.org/wiki/Imagen:Mapa_conceptual_del_software_libre_2.png
Autor: René Mérou, Jorge Ambiado, Fernando da Rosa, Gustavo Boksar
Cual es la diferencia entre Postgres y ORACLE
Antes de iniciar las diferencias, veamos este cuadro de Información general acerca de algunas Bases de Datos:
Siguiendo con lo referente al tema, antes de identificar dichas diferencias veamos el concepto general de cada uno de estos acrónimos.
Wikipedia define a PostgreSQL, "como un servidor de base de datos relacional orientada a objetos de software libre, liberado bajo la licencia BSD".
Como muchos otros proyectos open source, el desarrollo de PostgreSQL no es manejado por una sola compañía sino que es dirigido por una comunidad de desarrolladores y organizaciones comerciales las cuales trabajan en su desarrollo. Dicha comunidad es denominada el PGDG (PostgreSQL Global Development Group).
Siguiendo el mismo lineamiento de la información ofrecida por Wikipedia quien define a Oracle como un sistema de gestión de base de datos relacional (o RDBMS por el acrónimo en inglés de Relational Data Base Management System), fabricado por Oracle Corporation".
Se considera a Oracle como uno de los sistemas de bases de datos más completos, destacando su:
- Soporte de transacciones.
- Estabilidad.
- Escalabilidad.
- Es multiplataforma.
Ha sido criticado por algunos especialistas la seguridad de la plataforma, y las políticas de suministro de parches de seguridad, modificadas a comienzos de 2005 y que incrementan el nivel de exposición de los usuarios. En los parches de actualización provistos durante el primer semestre de 2005 fueron corregidas 22 vulnerabilidades públicamente conocidas, algunas de ellas con una antigüedad de más de 2 años.
Aunque su dominio en el mercado de servidores empresariales ha sido casi total hasta hace poco, recientemente sufre la competencia del Microsoft SQL Server de Microsoft y de la oferta de otros RDBMS con licencia libre como PostgreSQL, MySql o Firebird. Las últimas versiones de Oracle han sido certificadas para poder trabajar bajo Linux.
Luego de saber la conceptualización de cada uno de ellos, pasemos al tema de Las Diferencias entre PostgreSQL y ORACLE. Las cuales se secundan según la información suministrada por Ernesto Hernández (Agosto, 2005) quien expresa en su publicación los siguientes ítems que a continuación se listan:
a. PostgreSQL es una base de datos Objeto Relacional, mientras que
Oracle es sólo una base de datos Relacional. Oracle no tiene la
infraestructura OR y la simula con productos adicionales.
b. Oracle tiene consultas en paralelo, que PostgreSQL aún no tiene.
c. PostgreSQL tiene cinco lenguajes de programación procedurales,
algunos sumamente especializados y avanzados como PL/perl y PL/R,
mientras que Oracle sólo tiene uno.
d. PostgreSQL amplía el concepto de programación procedural para
soportar funciones en cualquier parte (como procedimiento, como tabla,
como operador, como selector, como filtro), mientras que Oracle sólo
permite usarlas como procedimiento. Oracle simula parcialmente el
comportamiento proveyendo paquetes, pero no tienen el alcance de
PostgreSQL.
e. PostgreSQL soporta nativamente tipos de datos no escalares, con sus
operadores, y ofrece la posibilidad de crear tus propios tipos de datos
y operadores. Oracle requiere comprar software adicional y no puedes
desarrollar tus propios tipos.
f. PostgreSQL puede crear índices lineales (B-Tree), presénciales (Hash)
y espaciales (R-Tree). Oracle sólo puede los dos primeros, se recomienda
que no uses el segundo, y si quieres el tercer tipo tienes que comprar
software adicional. En PostgreSQL tienes la posibilidad de escribir tus
propias rutinas para construcción de índices, con Oracle no.
g. Oracle tiene muchísimos más parámetros de configuración que
PostgreSQL, muchos de ellos son secretos, no están documentados, y sólo
los conoce la gente de soporte de Oracle que los utiliza para ayudarte
solamente si tienes el contrato de mantenimiento al día.
h. PostgreSQL tiene 5 lenguajes procedurales a diferencia de oracle que solo tiene 1.
i. PostgreSQL (licencia BSD), Oracle (licencia comercial). Además de eso para tener acceso a Oracle Profesional tendría que piratearlo a diferencia de PostgreSQL que basto con un emerge para probarlo en mi sistema.
Más aún, PostgreSQL es software libre, Oracle es privativo y caro (Fíjate lo que significa Oracle al revés).
Por lo demás, ambos tienen soporte para las mismas cosas (SQL, métodos
de conexión desde el cliente), son capaces de manipular bases de datos
de dimensiones enormes y tienen excelente robustez y escalabilidad
transaccional ya que ambas aplican mecanismos que no están basados en
locks.
Fortalezas y Debilidades PostgresSQL
Fortalezas:
Según la información provista por Ralfm (Junio, 2007) se dice que PostgreSQL ofrece muchas ventajas para las compañías o negocio, respecto siempre a otros sistemas de bases de datos. Los cuales se desglosan así:
Instalación Ilimitada:
Es frecuente que las bases de datos comerciales sean instaladas en más servidores de lo que permite la licencia. Algunos proveedores comerciales consideran a esto la principal fuente de incumplimiento de licencia. Con PostgreSQL, nadie puede demandarlo por violar acuerdos de licencia, puesto que no hay costo asociado a la licencia del software.
Esto tiene varias ventajas adicionales:
- Modelos de negocios más rentables con instalaciones a gran escala.
- No existe la posibilidad de ser auditado para verificar cumplimiento de licencia en ningún momento.
- Flexibilidad para hacer investigación y desarrollo sin necesidad de incurrir en costos adicionales de licenciamiento.
Mejor Soporte que los Proveedores Comerciales:
Además de nuestras ofertas de soporte, tenemos una importante comunidad de profesionales y entusiastas de PostgreSQL de los que su compañía puede obtener beneficios y contribuir.
Ahorros Considerables en Costos de Operación:
Nuestro software ha sido diseñado y creado para tener un mantenimiento y ajuste mucho menor que los productos de los proveedores comerciales, conservando todas las características, estabilidad y rendimiento.
Además de esto, nuestros programas de entrenamiento son reconocidamente mucho más costo-efectivos, manejables y prácticos en el mundo real que aquellos de los principales proveedores comerciales.
Estabilidad y Confiabilidad Legendarias:
En contraste a muchos sistemas de bases de datos comerciales, es extremadamente común que compañías reporten que PostgreSQL nunca ha presentado caídas en varios años de operación de alta actividad. Ni una sola vez. Simplemente funciona.
Extensible:
El código fuente está disponible para todos sin costo. Si su equipo necesita extender o personalizar PostgreSQL de alguna manera, pueden hacerlo con un mínimo esfuerzo, sin costos adicionales. Esto es complementado por la comunidad de profesionales y entusiastas de PostgreSQL alrededor del mundo que también extienden PostgreSQL todos los días.
Multiplataforma
PostgreSQL está disponible en casi cualquier Unix (34 plataformas en la última versión estable), y una versión nativa de Windows está actualmente en estado beta de pruebas.
Diseñado para Ambientes de Alto Volumen:
PostgreSQL usa una estrategia de almacenamiento de filas llamada MVCC para conseguir una mucho mejor respuesta en ambientes de grandes volúmenes. Los principales proveedores de sistemas de bases de datos comerciales usan también esta tecnología, por las mismas razones.
Herramientas Gráficas de Diseño y Administración de Bases de Datos
Existen varias herramientas gráficas de alta calidad para administrar las bases de datos (pgAdmin , pgAccess) y para hacer diseño de bases de datos (Tora , Data Architect).
Características Técnicas que PostgreSQL Ofrece:
- Cumple completamente con ACID
- Cumple con ANSI SQL
- Integridad referencial
- Replicación (soluciones comerciales y no comerciales) que permiten la duplicación de bases de datos maestras en múltiples sitios de replica
- Interfaces nativas para ODBC, JDBC, C, C++, PHP, Perl, TCL, ECPG, Python y Ruby
- Reglas
- Vistas
- Triggers
- Unicode
- Secuencias
- Herencia
- Outer Joins
- Sub-selects
- Una API abierta
- Procedimientos almacenados
- Soporte nativo SSL
- Lenguajes procedurales
- Respaldo en caliente
- Bloqueo a nivel mejor-que-fila
- Índices parciales y funcionales
- Autentificación Kerberos nativa
- Soporte para consultas con UNION, UNION ALL y EXCEPT
- Extensiones para SHA1, MD5, XML y otras funcionalidades
- Herramientas para generar SQL portable para compartir con otros sistemas compatibles con SQL
- Sistema de tipos de datos extensible para proveer tipos de datos definidos por el usuario, y rápido desarrollo de nuevos tipos
- Funciones de compatibilidad para ayudar en la transición desde otros sistemas menos compatibles con SQL
Debilidades
Son pocas las desventajas que se pueden obtener de PostgreSQL, sin embargo, es adecuado para sistemas de información OLTP (OnLine Transaction Processing) de todos los tamaños, para aplicaciones OLAP (OnLine Analitical Processing), como Data Warehouses y Data Mining, PostgreSQL no es la mejor alternativa. Perez, David (S/F)
A continuación se listas algunas desventajas:
- Tamaño máximo de una base de datos Ilimitado
- Tamaño máximo de una tabla 64TB
- Tamaño máximo de un registro Ilimitado para la versión 7.1 o posteriores
- Tamaño máximo de un campo 1GB para a versión 7.1 o posteriores
- Máximo No. de registros una tabla Ilimitado
- Máximo No. de columnas una tabla 1600
- Máximo No. de índices una tabla Ilimitado
Naturalmente, estos valores no son en verdad ilimitados, porque dependen de recursos como el sistema operativo, espacio en disco, memoria, entre otros.
Ubuntu, Apache. Características.
Ubuntu
Según Wikipedia, Ubuntu, es una distribución Linux que ofrece un sistema operativo predominantemente enfocado a computadoras de escritorio aunque también proporciona soporte para servidores. Es una de las más importantes distribuciones de GNU/Linux a nivel mundial.
A continuación se mencionan las características más notables y sobresalientes, así como las que merecen una exposición:
Primarias
Ubuntu está basado en la distribución Debian GNU/Linux y soporta oficialmente dos arquitecturas de hardware: Intel x86, AMD64. Sin embargo ha sido portada extraoficialmente a cinco arquitecturas más: PowerPC,SPARC (versión "alternate"),IA-64, Playstation y HP PA-RISC.
Al igual que casi cualquier distribución basada en Linux, Ubuntu es capaz de actualizar a la vez todas las aplicaciones instaladas en la máquina a través de repositorios, a diferencia de otros sistemas operativos comerciales, donde esto no es posible.
Esta distribución ha sido y está siendo traducida a numerosos idiomas, y cada usuario es capaz de colaborar voluntariamente a esta causa, a través de Internet.
Los desarrolladores de Ubuntu se basan en gran medida en el trabajo de las comunidades de Debian, GNOME y KDE (como es el caso de las traducciones).
Secundarias
- Basada en la distribución Debian GNU/Linux.
- Disponible oficialmente para 2 arquitecturas: Intel x86, AMD64
- Portada extraoficialmente a 5 arquitecturas más: PowerPC,1 2 SPARC (versión "alternate"),3 4 IA-64,5 6 Playstation 37 8 y HP PA-RISC.9
- Al igual que casi cualquier distribución basada en Linux, Ubuntu es capaz de actualizar a la vez todas las aplicaciones instaladas en la máquina a través de repositorios, a diferencia de otros sistemas operativos comerciales, donde esto no es posible.
- Esta distribución ha sido y está siendo traducida a numerosos idiomas, y cada usuario es capaz de colaborar voluntariamente a esta causa, a través de Internet.10
- Posee una gran colección de aplicaciones prácticas y sencillas para la configuración de todo el sistema, a través de una interfaz gráfica útil para usuarios que se inician en Linux.
- Los desarrolladores de Ubuntu se basan en gran medida en el trabajo de las comunidades de Debian, GNOME y KDE (como es el caso de las traducciones).
- Cualquier usuario que conozca el idioma inglés y tenga una conexión a Internet, es capaz de presentar sus ideas para las futuras versiones de Ubuntu en la página wiki oficial de la comunidad del proyecto.11
- En Febrero de 2008 se puso en marcha la página "Brainstorm"12 que permite a los usuarios proponer sus ideas y votar las del resto. También se informa de cuales de las ideas propuestas se están desarrollando o están previstas.
- Las versiones estables se liberan cada 6 meses y se mantienen actualizadas en materia de seguridad hasta 18 meses después de su lanzamiento.
- La nomenclatura de las versiones no obedece principalmente a un orden de desarrollo, se compone del dígito del año de emisión y del mes en que esto ocurre. La versión 4.10 es de octubre de 2004, la 5.04 es de abril de 2005, la 5.10 de octubre de 2005, la 6.06 es de junio de 2006, la 6.10 es de octubre de 2006, la 7.04 es de abril de 2007, la 7.10 es de octubre de 2007 y la 8.04 es de abril de 2008.
- El entorno de escritorio oficial es Gnome y se sincronizan con sus liberaciones. Existen versiones con KDE y otros escritorios, que pueden añadirse una vez instalado el Ubuntu oficial con Gnome.
- Para centrarse en solucionar rápidamente los bugs, conflictos de paquetes, etc. se decidió eliminar ciertos paquetes del componente main, ya que no son populares o simplemente se escogieron de forma arbitraria por gusto o sus bases de apoyo al software libre. Por tales motivos inicialmente KDE no se encontraba con más soporte de lo que entregaban los mantenedores de Debian en sus repositorios, razón por la que se sumó la comunidad de KDE distribuyendo la distro llamada Kubuntu.
- De forma sincronizada a la versión 6.06 de Ubuntu, apareció por primera vez la distribución Xubuntu, basada en el entorno de escritorio XFce.
- El navegador web oficial es Mozilla Firefox.
- El sistema incluye funciones avanzadas de seguridad y entre sus políticas se encuentra el no activar, de forma predeterminada, procesos latentes al momento de instalarse. Por eso mismo, no hay un firewall predeterminado, ya que no existen servicios que puedan atentar a la seguridad del sistema.
- Para labores/tareas administrativas en terminal incluye una herramienta llamada sudo (similar al Mac OS X), con la que se evita el uso del usuario root (administrador).
- Mejora la accesibilidad y la internacionalización, de modo que el software está disponible para tanta gente como sea posible. En la versión 5.04, el UTF-8 es la codificación de caracteres en forma predeterminada.
- No sólo se relaciona con Debian por el uso del mismo formato de paquetes deb, también tiene uniones muy fuertes con esa comunidad, contribuyendo con cualquier cambio directa e inmediatamente, y no solo anunciándolos. Esto sucede en los tiempos de lanzamiento. Muchos de los desarrolladores de Ubuntu son también responsables de los paquetes importantes dentro de la distribución Debian.
- Ubuntu no cobra honorarios por la suscripción de mejoras de la "Edición Enterprise".
- Ubuntu está opcionalmente disponible en DVD, para evitar su dependencia de Internet.
Para complementar dichas características tenemos a guada pedia (Febrero, 2005) quien presentas:
- Proyecto libre 100%. Pese a estar esencialmente patrocinado por una empresa, la distribución se declara públicamente 100% libre y perteneciente a la comunidad Ubuntu.
- Basado en Debian.
- Amplio equipo de desarrollo (38 empleados de Canonical + multitud de voluntarios).
- Gran aceptación entre la comunidad del software libre.
- Dirigida al escritorio de propósito general.
- Detección y configuración de hardware de las más avanzadas y actualizadas.
- Orientada a los distintos lenguajes del mundo y a facilitar y agilizar su traducción.
- Pensada desde el principio para la fácil creación de distribuciones derivadas (herramientas colaborativas ínter-distribuciones presentes en Launchpad, la suite de herramientas de desarrollo/mantenimiento/traducción de Ubuntu).
- Acuerdos de colaboración establecidos con Gnome y con otros “upstream developers”.
- Integración en la maquinaria de depuración de Debian y de algunos “upstream developers”.
- Ciclo de liberación definido:
- Una versión cada 6 meses
- Primera versión de prueba a las 6 semanas
- Una versión de prueba cada 2 semanas
- Versión preview a -1 mes
- Versión “release candidate” a -1 semana
- Actualizaciones críticas y de seguridad durante 18 meses para cada versión
- Línea de trabajo para hacer Ubuntu conforme a LSB 2.0
Apache
Según la información contemplada en la ciberaula (2006) se presenta La historia de Apache se remonta a febrero de 1995, donde empieza el proyecto
del grupo Apache, el cual esta basado en el servidor Apache httpd de la
aplicación original de NCSA. El desarrollo de esta aplicación original se estancó
por algún tiempo tras la marcha de Rob McCool por lo que varios webmaster siguieron
creando sus parches para sus servidores web hasta que se contactaron vía
email para seguir en conjunto el mantenimiento del servidor web, fue ahí cuando
formaron el grupo Apache. Fueron Brian Behlendorf y Cliff Skolnick quienes a
través de una lista de correo coordinaron el trabajo y lograron establecer un espacio
compartido de libre acceso para los desarrolladores.
Aquella primera versión y sus sucesivas evoluciones y mejoras alcanzaron
una gran implantación como software de servidor inicialmente solo para sistemas
operativos UNIX y fruto de esa evolución es la versión para Windows".
A continuación se mencionan las características más notables y sobresalientes, así como las que merecen una exposición:
- Corre en una multitud de Sistemas Operativos, lo que lo hace prácticamente universal.
- Apache es una tecnología gratuita de código fuente abierto. El hecho de ser gratuita es importante pero no tanto como que se trate de código fuente abierto. Esto le da una transparencia a este software de manera que si queremos ver que es lo que estamos instalando como servidor , lo podemos saber, sin ningún secreto, sin ninguna puerta trasera ;).
- Apache es un servidor altamente configurable de diseño modular. Es muy sencillo ampliar las capacidades del servidor Web Apache. Actualmente existen muchos módulos para Apache que son adaptables a este, y están ahí para que los instalemos cuando los necesitemos. Otra cosa importante es que cualquiera que posea una experiencia decente en la programación de C o Perl puede escribir un modulo para realizar una función determinada.
- Apache trabaja con gran cantidad de Perl, PHP y otros lenguajes de script. Perl destaca en el mundo del script y Apache utiliza su parte del pastel de Perl tanto con soporte CGI como con soporte mod perl. También trabaja con Java y páginas jsp. Teniendo todo el soporte que se necesita para tener páginas dinámicas.
- Apache te permite personalizar la respuesta ante los posibles errores que se puedan dar en el servidor. Es posible configurar Apache para que ejecute un determinado script cuando ocurra un error en concreto.
- Tiene una alta configurabilidad en la creación y gestión de logs. Apache permite la creación de ficheros de log a medida del administrador, de este modo puedes tener un mayor control sobre lo que sucede en tu servidor .
Postgres con Linux. Características.
PostgreSQL es una base de datos relacional, distribuida bajo licencia BSD y con su código fuente disponible libremente. Es el motor de bases de datos de código abierto más potente del momento y en sus últimas versiones empieza a no tener que envidiarle nada a otras bases de datos comerciales. Sus características técnicas la hacen una de las bases de datos más potentes y robustas del mercado. Su desarrollo comenzó hace más de 15 años, y durante este tiempo, estabilidad, potencia, robustez, facilidad de administración e implementación de estándares han sido las características que más se han tenido en cuenta durante su desarrollo. En los últimos años se han concentrado mucho en la velocidad de proceso y en características demandadas en el mundo empresarial. PostgreSQL se puede ejecutar en la gran mayoría de sistemas operativos existentes en la actualidad, entre ellos Linux y UNIX en todas sus variantes (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) y Windows.
Según la investigación de Cristian Fabres A. (s/f) quien presenta de manera directa, una noción básica de lo que es trabajar con Postgres en Linux.
Específicamente se trabaja con una la versión de Postgres 7.2.1
en un Red Hat 7.3
(psql -V)
La versión del Kernel es la 2.4.18-0.13.
(uname –r)
Se supone que ya se instalo Postgres correctamente.
Lo primero que hay que hacer es subir el servicio de Postgres para que podamos conectarnos a la base de datos (BdD).
Hay dos formas de levantar el servicio, una es levantarlo directamente pero solo queda el servicio arriba hasta que apaguemos la maquina.
Para esto hacemos lo siguiente:
[root@localhost etc]# cd /etc/rc.d/init.d/postgresql Start
En el directorio anterior lo que se hace es correr un script en el cual el primer parámetro es el script a ejecutar y el segundo parámetro es lo que hace el script, si la opción es Start, inicia el servicio, si la opción es stop se detiene el servicio, la opción restart detiene e inicia el servicio.
La primera vez que ejecutemos este script se va a demorar un poco más de lo normal, porque va a verificar que exista la BdD y va a crear una serie de archivos en el siguiente path:
/var/lib/pgsql.
Estos archivos son creados siempre que no existan, si el servicio ya fue levantado con anterioridad, los archivos ya fueron creados y el servicio se levanta más rápido. De hecho es una buena opción para limpiar todas las bases de datos (por si hubiera habido algun problema), borrar todos los archivos de la ruta /var/lib/pgsql para luego levantar el servicio y se crean los archivos de nuevo con las opciones originales.
Ojo que si tomamos esta opción se van a borrar todas las instancias de Bases de Datos que existen hasta ese momento.
La otra forma de levantar el servicio de postgres es que siempre que prendamos nuestro linux, se levante como un servicio mas, lo que resulta muy comodo, así se configura el script una vez y siempre queda levantado como un servicio mas. Para esto tenemos que hacer dos pasos, ver en que nivel se levanta nuestro linux y poner el script en el directorio correspondiente (o mejor dicho el link en el directorio correspondiente).
Para saber en que modo estamos arrancando nuestro linux tenemos que editar el archivo /etc/inittab, y hay que ver un parámetro en una fila en particular.
Un ejemplo de este archivo es el siguiente:
# Default runlevel. The runlevels used by RHS are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:3:ini tdefault:
Las filas que comienzan con un #, casi siempre son comentarios (por no decir siempre), por lo tanto si las modificamos no hacen nada o ningún cambio contra este script. La fila que no esta comentada (“id:3:ini tdefault:”) en el segundo parámetro tiene un numero 3 y significa que el sistema Linux arranca en este modo. Los comentarios que están arriba nos indican todos los modos en los cuales se puede levantar el sistema operativo,
0: es para apagar la maquina, 1 es el modo single user, y así sucesivamente hasta el modo 6.
Por lo general el parámetro esta en 3 o en 5. Para cada modo existe un directorio en particular en el cual dice el orden y la cantidad de scripts que se tienen que subir. Por ejemplo si estamos en el modo de arranque 3, el directorio que contiene todos los script a subir es “/etc/rc.d/rc3.d”. Si hacemos un “cd /etc/rc.d/rc3.d” y luego un "ls" para ver el contenido nos vamos a dar cuenta que, básicamente, hay dos tipos de archivos, los que comienzan con una “S” y los que comienzan con una “K”, seguidos por dos caracteres que son unos números y luego el nombre del script a ejecutar.
Los que comiencen con una “S” son los servicios que se van a subir para el modo en cuestión. Por lo tanto si hacemos un "ls" en el directorio /etc/rcd./rc3.d y nos da como resultado:
K12mysqld
K15httpd
….
….
S05kudzu
S06reconfig
S08ip6tables
….
La lista anterior nos dice que los servicios kudzu, reconfig y el ip6tables se suben cuando el Linux se inicia en el servicio 3, ya que el listado es del directorio /etc/rc.d/rc3.d.
El número sirve para indicar el orden de subida de los servicios, o sea, el servicio kudzu sube primero, después el servicio reconfig y luego el servicio ip6tables. Lo lógico seria que ahora busquemos algún script que contenga o se llame *postgresql* para ver si existe como “S” o como “K”.
Si el archivo que encontramos existe como “K97postgresql” lo que tendremos que hacer es cambiarlo por “S97postgresql” para que se cargue automáticamente cada vez que se inicie el linux (se hace con el comando "mv").
El número no tiene porque ser 97, podría ser cualquier otro, pero uno razonablemente alto para que otros servicios más básicos se carguen, por lo tanto lo mejor es cargar el script con un número alto. La mejor opción es que encontremos el archivo como "S97postgresql", en este caso no hacemos nada, porque el servicio ya fue cargado para este modo (3).
Lo más probable es que si tratamos de buscar este script que tenga algo con postgresql (find /etc/rc.d/rc3.d –name *postgres*) pero no lo vamos a encontrar ni como “S” o “K”, pero podemos crear el script o mejor dicho, podemos crear el enlace donde se encuentra el script.
Para esto, si estamos parados en el directorio /etc/rc.d/rc3.d/ podemos escribir lo siguiente:
ln -s ./../init.d/postgresql S97postgresql
Lo que hace el comando anterior es crear un link al archivo /etc/rc.d/init.d/postgresql y crea un archivo al directorio /etc/rc.d/rc3.d/ con el nombre de archivo S97postgresql.
Por lo tanto ya tenemos nuestro script en el modo 3.
Cuando parta nuestro linux no tendremos que levantar el servicio; porque como ya creamos el archivo con el link anterior se levantara automáticamente.
Si queremos reiniciar nuestro servicio, parar o comenzar podremos hacer lo siguiente:
/etc/rc.d/rc3.d/S97postgresql start (para hacer partir el servicio)
/etc/rc.d/rc3.d/S97postgresql stop (para detener el servicio)
/etc/rc.d/rc3.d/S97postgresql restart (para detener y hacer partir el servicio)
Es básicamente lo mismo que hacíamos antes con el script original:
/etc/rc.d/init.d/S97postgresql start (para hacer partir el servicio)
/etc/rc.d/init.d/S97postgresql stop (para detener el servicio)
/etc/rc.d/init.d/S97postgresql restart (para detener y hacer partir el servicio)
En estricto rigor el servicio esta arriba, y si digitamos "psql", el programa va a responder, el punto esta en que postgres no ha levantado ningún puerto o socket para hacer transmisiones vía TCP/IP.
La pregunta es ¿y bueno cual es el problema?:
el problema reside en que si queremos conectarnos desde PHP con Apache por ejemplo, no vamos a poder porque en las funciones de conexión de PHP pide el numero IP de la maquina en la cual hacemos la conexión al servidor donde aloja Postgres.
Para resolver este tema hay que editar el script donde hicimos anteriormente el link, o sea podemos editar el archivo que se encuentra en:
/etc/rc.d/rc3.d/S97postgresql o en /etc/rc.d/INIT.d/postgresql
(cualquier camino que tomemos para editar el archivo da lo mismo porque las dos rutas conducen al mismo archivo). Por ultimo hay que editar una fila en particular la cual es:
su –l postgres –s /bin/sh –c “/usr/bin/pg_ctl –D $PGDATA –p /usr/bin/postmaster start > /dev/null 2>&1” < /dev/null
Y cambiarla por:
su –l postgres –s /bin/sh –c “/usr/bin/pg_ctl –o “-i” –D $PGDATA –p /usr/bin/postmaster start > /dev/null 2>&1” < /dev/null
Se agregaron las opciones “-o “-i””.
Con este cambio hay que reiniciar el servicio nuevamente para que tenga efectos en Postgres:
/etc/rc.d/init.d/S97postgresql restart
para probar si el socket esta arriba escribimos el comando netstat –nat el cual da como resultado:
Proto Recv-Q Send-Q Local Addres Foreign Address state
…..
Tcp 0 0 0.0.0.0:5432 0.0.0.0:* listen
…..
El servicio esta arriba y atiende en el Puerto 5432. Y listo, nuestro servicio de postgres ya esta arriba y funcionando.
Como Seria el Análisis y Diseño de un Sistema de Información Usando Postgres
SQL
SQL se ha convertido en el lenguaje de consulta relacional más popular. El nombre "SQL" es una abreviatura de Structured Query Language (Lenguaje de consulta estructurado). En 1974 Donald Chamberlain y otros definieron el lenguaje SEQUEL (Structured English Query Language) en IBM Research. Este lenguaje fue implementado inicialmente en un prototipo de IBM llamado SEQUEL-XRM en 1974-75. En 1976-77 se definió una revisión de SEQUEL llamada SEQUEL/2 y el nombre se cambió a SQL.
IBM desarrolló un nuevo prototipo llamado System R en 1977. System R implementó un amplio subconjunto de SEQUEL/2 (now SQL) y un número de cambios que se le hicieron a (now SQL) durante el proyecto. System R se instaló en un número de puestos de usuario, tanto internos en IBM como en algunos clientes seleccionados. Gracias al éxito y aceptación de System R en los mismos, IBM inició el desarrollo de productos comerciales que implementaban el lenguaje SQL basado en la tecnología System R.
Durante los años siguientes, IBM y bastantes otros vendedores anunciaron productos SQL tales como SQL/DS (IBM), DB2 (IBM), ORACLE (Oracle Corp.), DG/SQL (Data General Corp.), y SYBASE (Sybase Inc.).
SQL es también un estándar oficial hoy. En 1982, la American National Standards Institute (ANSI) encargó a su Comité de Bases de Datos X3H2 el desarrollo de una propuesta de lenguaje relacional estándar. Esta propuesta fue ratificada en 1986 y consistía básicamente en el dialecto de IBM de SQL. En 1987, este estándar ANSI fue también aceptado por la Organización Internacional de Estandarización (ISO). Esta versión estándar original de SQL recibió informalmente el nombre de "SQL/86". En 1989, el estándar original fue extendido, y recibió el nuevo nombre, también informal, de "SQL/89". También en 1989 se desarrolló un estándar relacionado llamado Database Language Embedded SQL (ESQL).
Los comités ISO y ANSI han estado trabajando durante muchos años en la definición de una versión muy ampliada del estándar original, llamado informalmente SQL2 o SQL/92. Esta versión se convirtió en un estándar ratificado durante 1992: International Standard ISO/IEC 9075:1992, Database Language SQL. SQL/92 es la versión a la que normalmente la gente se refiere cuando habla de «SQL estándar». Se da una descripción detallada de SQL/92 en Date and Darwen, 1997. En el momento de escribir este documento, se está desarrollando un nuevo estándar denominado informalmente como SQL3. Se plantea hacer de SQL un lenguaje de alcance completo (e Turing-complete language), es decir, serán posibles todas las consultas computables, (por ejemplo consultas recursivas). Esta es una tarea muy compleja y por ello no se debe esperar la finalización del nuevo estándar antes de 1999.
El Modelo de Datos Relacional
Como mencionamos antes, SQL es un lenguaje relacional. Esto quiere decir que se basa en el modelo de datos relacional publicado inicialmente por E.F.Codd en 1970. Daremos una descripción formal del modelo de datos relacional más, pero primero queremos dar una mirada desde un punto de vista más intuitivo.
Una base de datos relacional es una base de datos que se percibe por los usuarios como una colección de tablas (y nada más que tablas). Una tabla consiste en filas y columnas, en las que cada fila representa un registro, y cada columna representa un atributo del registro contenido en la tabla. La Base de Datos de Proveedores y Artículos muestra un ejemplo de base de datos consistente en tres tablas.
SUPPLIER es una tabla que recoge el número (SNO), el nombre (SNAME) y la ciudad (CITY) de un proveedor.
PART es una tabla que almacena el número (PNO) el nombre (PNAME) y el precio (PRICE) de un artículo.
SELLS almacena información sobre qué artículo (PNO) es vendido por qué proveedor (SNO). Esto sirve en un sentido para conectar las dos tablas entre ellas.
Ejemplo 1. La Base de Datos de Proveedores y Artículos
SUPPLIER SNO | SNAME | CITY SELLS SNO | PNO
-----+---------+-------- -----+-----
1 | Smith | London 1 | 1
2 | Jones | Paris 1 | 2
3 | Adams | Vienna 2 | 4
4 | Blake | Rome 3 | 1
3 | 3
4 | 2
PART PNO | PNAME | PRICE 4 | 3
-----+-------------+--------- 4 | 4
1 | Tornillos | 10
2 | Tuercas | 8
3 | Cerrojos | 15
4 | Levas | 25
|
Las tablas PART y SUPPLIER se pueden ver como entidades y SELLS se puede ver como una relación entre un artículo particular y un proveedor particular.
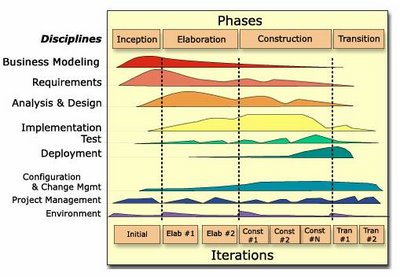
El Proceso Unificado de Desarrollo de Software (RUP)
Es el Proceso Unificado es un proceso de software genérico que puede ser utilizado para una gran cantidad de tipos de sistemas de software, para diferentes áreas de aplicación, diferentes tipos de organizaciones, diferentes niveles de competencia y diferentes tamaños de proyectos.
Este provee un enfoque disciplinado en la asignación de tareas y resposabilidades dentro de una organización de desarrollo. Su meta es asegurar la producción de software de muy alta calidad que satisfaga las necesidades de los usuarios finales, dentro de un calendario y presupuesto predecible.
El Proceso Unificado tiene dos dimensiones
- Un eje horizontal que representa el tiempo y muestra los aspectos del ciclo de vida del proceso a lo largo de su desenvolvimiento.
- Un eje vertical que representa las disciplinas, las cuales agrupan actividades de una manera lógica de acuerdo a su naturaleza.
La primera dimensión representa el aspecto dinámico del proceso conforme se va desarrollando, se expresa en términos de fases, iteraciones e hitos.
La segunda dimensión representa el aspecto estático del proceso: cómo es descrito en términos de componentes del proceso, disciplinas, actividades, flujos de trabajo, artefactos y roles.
El Proceso Unificado se basa en componentes (component-based), lo que significa que el sistema en construcción está hecho de componentes de software interconectados por medio de interfaces bien definidas (well-defined interfaces).
El Proceso Unificado usa el Lenguaje de Modelado Unificado (UML) en la preparación de todos los planos del sistema. De hecho, UML es una parte integral del Proceso Unificado, fueron desarrollados a la par.
Los aspectos distintivos del Proceso Unificado están capturados en tres conceptos clave: dirigido por casos de uso (use-case driven), centrado en la arquitectura (architecture-centric), iterativo e incremental. Esto es lo que hace único al Proceso Unificado.
El Proceso Unificado es dirigido por casos de uso
Un sistema de software se crea para servir a sus usuarios. Por lo tanto, para construir un sistema exitoso se debe conocer qué es lo que quieren y necesitan los usuarios prospectos.
El término usuario se refiere no solamente a los usuarios humanos, sino a otros sistemas. En este contexto, el término usuario representa algo o alguien que interactúa con el sistema por desarrollar.
Un caso de uso es una pieza en la funcionalidad del sistema que le da al usuario un resultado de valor. Los casos de uso capturan los requerimientos funcionales. Todos los casos de uso juntos constituyen el modelo de casos de uso el cual describe la funcionalidad completa del sistema. Este modelo reemplaza la tradicional especificación funcional del sistema. Una especificación funcional tradicional se concentra en responder la pregunta: ¿Qué se supone que el sistema debe hacer? La estrategia de casos de uso puede ser definida agregando tres palabras al final de la pregunta: ¿por cada usuario? Estas tres palabras tienen una implicación importante, nos fuerzan a pensar en términos del valor a los usuarios y no solamente en términos de las funciones que sería bueno que tuviera. Sin embargo, los casos de uso no son solamente una herramienta para especificar los requerimientos del sistema, también dirigen su diseño, implementación y pruebas, esto es, dirigen el proceso de desarrollo.
Aún y cuando los casos de uso dirigen el proceso, no son elegidos de manera aislada. Son desarrollados a la par con la arquitectura del sistema, esto es, los casos de uso dirigen la arquitectura del sistema y la arquitectura del sistema influencia la elección de los casos de uso. Por lo tanto, al arquitectura del sistema y los casos de uso maduran conforme avanza el ciclo de vida.
El Proceso Unificado está centrado en la arquitectura
El papel del arquitecto de sistemas es similar en naturaleza al papel que el arquitecto desempeña en la construcción de edificios. El edificio se mira desde diferentes puntos de vista: estructura, servicios, plomería, electricidad, etc. Esto le permite al constructor ver una radiografía completa antes de empezar a construir. Similarmente, la arquitectura en un sistema de software es descrita como diferentes vistas del sistema que está siendo construido.
El concepto de arquitectura de software involucra los aspectos estáticos y dinámicos más significativos del sistema. La arquitectura surge de las necesidades de la empresa, tal y como las interpretan los usuarios y otros stakeholders, y tal y como están reflejadas en los casos de uso. Sin embargo, también está influenciada por muchos otros factores, tales como la plataforma de software en la que se ejecutará, la disponiblidad de componentes reutilizables, consideraciones de instalación, sistemas legados, requerimientos no funcionales (ej. desempeño, confiabilidad). La arquitectura es la vista del diseño completo con las características más importantes hechas más visibles y dejando los detalles de lado. Ya que lo importante depende en parte del criterio, el cual a su vez viene con la experiencia, el valor de la arquitectura depende del personal asignado a esta tarea. Sin embargo, el proceso ayuda al arquitecto a enfocarse en las metas correctas, tales como claridad (understandability), flexibilidad en los cambios futuros (resilience) y reuso.
¿Cómo se relacionan los casos de uso con la arquitectura? Cada producto tiene función y forma. Uno sólo de los dos no es suficiente. Estas dos fuerzas deben estar balanceadas para obtener un producto exitoso. En este caso función corresponde a los casos de uso y forma a la arquitectura. Existe la necesidad de intercalar entre casos de uso y arquitectura. Es un problema del “huevo y la gallina”. Por una parte, los casos de uso deben, cuando son realizados, acomodarse en la arquitectura. Por otra parte, la arquitectura debe proveer espacio para la realización de todos los casos de uso, hoy y en el futuro. En la realidad, ambos arquitectura y casos de uso deben evolucionar en paralelo.
El Ciclo de Vida
Concepción: aquí empieza el proyecto con el desarrollo de los casos de uso y la identificación de riesgos.
Elaboración: Elaboración de planes, se completan los casos de uso y se eliminan los riesgos.
Construcción: desarrollo del proyecto y elaboración del manual de usuario, el cual estará dividido en varias iteraciones.
Implementación: Instalación, entrenamiento de usuarios.
Elaborar un Plan de Migración de ORACLE a Postgre para una Empresa Administrativa.
La primera ley de la ingeniería de sistemas de Bersoft dice Sin importar en qué momento del ciclo de vida del sistema nos encontremos, el sistema cambiará y el deseo de cambiarlo persistirá a lo largo de todo el ciclo de vida.. Es un hecho destacado por numerosos investigadores y profesionales que los sistemas informáticos deben evolucionar para adecuarse a los siempre cambiantes requisitos del entorno. Las estadísticas indican que entre el 65% y el 75% de las fuerzas vivas relacionadas con el mundo de la informática y aproximadamente el 80% de los gastos totales del software se dedican al mantenimiento del software existente.
Idealmente, a la hora de introducir una modificación en una aplicación informática se debe seguir un proceso (por ejemplo el ISO/IEEE 12207) en el cual sea identificada la razón del cambio, se analice cómo afecta el cambio a introducir en la aplicación, para posteriormente realizar los cambios allí donde sean necesarios, finalizando con una exhaustiva fase de pruebas que demuestre que la modificación no ha introducido errores. Todo el proceso anterior debe estar bajo un estricto control de cambios que recoja todos los documentos que se generan y almacene las diferentes versiones.
Lamentablemente, muchas empresas simplifican el proceso anterior reduciéndolo, en la mayoría de los casos, a un análisis de la modificación para posteriormente aplicarla directamente al código sin excesivas pruebas y menor documentación.
Según Internautica, Migrar de una plataforma de bases de datos puede ser difícil y puede consumir mucho tiempo debido a las diferencias en estándares entre vendedores. Se debe establecer una metodología de migración de bases de datos en la cual se trabaje con el cliente para mover sus bases de datos de una plataforma a la otra.
La metodología para la migración de bases de datos debe permitir analizar las arquitecturas de bases de datos, planear las rutinas necesarias de migración, realizar la migración necesaria de los datos existentes y verificar que fue satisfactoriamente completada.
Los consultores de bases de datos deben trabajar de cerca con el equipo interno de proyectos para crear un plan de migración que sea rápido y de bajo costo. Se Identifican los riesgos potenciales y el plan de mitigación asociado, se minimiza el costo de migración y rápidamente se migra la base de datos, permitiendo una reducción en la cantidad de tiempo que el sistema esta abajo durante la transición.
Pasos Generales de la Migración de Bases de Datos

Pasos Generales Migración de Base de Datos Oracle a PostgreSQL
Fuente: Elaboración Propia.
- Análisis preliminar de la estructura de la base de datos en el Servidor Oracle, para tener una visión clara sobre la complejidad de la misma, y de los recursos a utilizar.
- Desde el servidor ORACLE, se exporta la estructura de las tablas y la data almacenada, por medio de un volcamiento hacia archivos SQL.
- Debido a la incompatibilidad de los leguajes y sintaxis para los procedures y triggers de ambas base de datos, se debe convertir dichos recursos por medio de desarrollo propio o utilizando herramientas de terceros.
- Desde el Servidor de Pruebas de PostgreSQL, se importan las estructuras, datos y funciones convertidas desde el servidor ORACLE.
- Paralelamente, se deben realizar los desarrollos y modificaciones necesarias en la aplicación o sistema que use la base de datos ORACLE, para que pueda usar la base de datos de prueba PostgreSQL.
- Una vez enlazados (Sistema-PostgreSQL), se deben realizar las validaciones necesarias para comprobar el éxito de las modificaciones al sistema, así como la migración de la Base de datos.
- Si las validaciones fueron exitosas, se puede proceder a realizar la puesta a producción del servidor PostgreSQL, con la data recién migrada, previa copia ó duplicación antes de realizar las mismas.


{kind=link}