黄兄你好,
小弟有如下数题百思不得其解,恳请指点。
Assignment3
3 ; 6; 12(ii);14;15;16;17
还有几个关于SET的概念:
A∪B
= { Q(x)→P(Q)} =
![]() ??
??
![]() ∪B = { P(Q)→Q(x)}
=
∪B = { P(Q)→Q(x)}
=
![]() ??
??
Possibility
Hi Dr. Ford,
It is a naive thought and I hope you have time to give me some hints as to this lenghy, trivial puzzle to me.
It always bothers me a lot when I planned in c++ to design a class of logic object which describes any proposition as an object of this class. In my intuition, this class is to store all characteristics of a proposition such as the language expression of the proposition, the truth value, the possible logic operations rule like "and", "or" etc. It seems quite simple for me at beginning to overload the operator to implement logic operations.
But then I run into a puzzle, it seems that I can never assign truth value to a certain proposition as almost all proposition's truth value is uncertain. For example, "Today is colder than yesterday". I never know if this proposition is true or false as "today" and "yesterday" is undefined and the truth value varies when "today" is changing. What's worse, if I don't check the weather data from certain source like weather forecast, message from others, or try it by myself etc., I will have no way to settle the truth value of this proposition. And even I do all checking, still there will be some reason, I might give the wrong value, such as I checked wrong data, people lied to me, I have a fever.... So, I began to think all proposition is undefined with their truth value unless I explicitly assign one for it.
Yet it changed my view when we look at the proposition like "2 is bigger than 1" which is always true with no need to justify. I try to figour out that some propositions are describing "facts", some are describing "rules",and some are dealing with "hyperthesis" etc. However, it is still not a convincing explanation to me though I cannot tell why.
I am taking a statistic course "STAT 249" which greatly surprises me by applying many similar methods of logical operations. It hints me that maybe every proposition is indeed having a certain possibility to be true or false. Say "today is colder than yesterday" is only having roughly 50% of chance to be correct. Yet "2 is bigger than 1" is 100% of chance to be correct. Then we might define all proposition to be a kind of function of time t: proposition p--->f(t) where the range of function f(t) is either 1 or 0, or in other word true or false. For some proposition like "2 is bigger than 1" always has value of 1 for any value of t, that is always true for all time. And for other propositions, the value of function is varying between 1 and 0, that is sometimes true and sometimes false depending the domain of time t. This seems to explain well for my puzzle. Even for the most trouble one---truth simbol like "true" and "false", it gives a perfect solution: they are simply const function with value of 1 and 0 respectively for all possible time t.
Anyway there seems to be another approach to solve the problem with "2 is bigger than 1" by dissecting the proposition into several more propositions like: p= {"it is 2"}, q = {"it is 1"} , r ={"first is bigger than second"};
Then we can define: (p^q)-->r
For proposition like "today is colder than yesterday", it will be very complicated to change it into more propositions:
p = {temperature of today}; q= {temperature of yesterday};
r = {the first is bigger than second} ; s = {the first is colder than second}
Then we can define: r(p, q) --->s(p,q)
And this solution is not uniformal but maybe practical. It requires too much analysis for language itself. So it may not be practical for computer compared with the "statistic view" of truth value.
In my view, it is always a similar for human to recognize if a proposition is true or not by collecting some sample with experiments or observations at very early stage. As the accumulation of result of this proposition or hyperthesis goes up, the man counts the possibility or the number of truth value of that proposition. Then the truth value of a certain proposition is established on basis of "possibilities". So, it is also a good way to describe all propositions in this way to imitate the process of human being.
Thank you for your time and I am waiting for your advice.
关于数字显示的方法及其除法
Hi,
我的问题是怎样显示一个数字呢?我能想到的办法就是用连续除以10,将余数存入stack,直到商为0。再从stack中将余数一一取出,加30h显示。可是,我碰到一些问题:
1。8位和16位除法不同,我必须根据被除数大小采用两种不同的除法。所以,在作16位除法时我每次都要去判断结果是8位还是16位,以便采用不同的除法。这样会有问题吗?
2。我在codeview里无法trace,因为我运行时候总是报divide overflow的错误,后来我在dos环境里,直接运行cv去debug,一步步都ok,甚至结果都看到了,是正确的。可是,codeview里还是不能运行,直接运行exe文件还是报divide overflow的错误。我想知道,作除法时,怎样判断divide overflow的?是看flag 寄存器的某一个标志位吗?
谢谢。
黄清浙
.DOSSEG
.MODEL SMALL
.STACK 100H
.DATA
ARRAY DB 115,125,125,140,110
MSG DB "IT IS 3!", "$"
BUFFER DB 10 DUP(?)
.CODE
START:
MOV AX, @DATA
MOV DS, AX
MOV AX,
OFFSET ARRAY
PUSH AX
MOV AX, 5
PUSH AX
CALL SUMARRAY
XOR AX, AX
POP AX
MOV BL, 10
XOR CX, CX
;MOV AH, 0
CMP AH, 0
JNE DOUBLEDIVIDE
DIVIDE:
DIV BL
XOR DX, DX
MOV DL, AH
MOV AH, 0
ADD DL, 30H
PUSH DX
; STORE RESULT IN STACK
INC CX
; COUNTER +1
CMP AL, 0
JE
ENDDIVIDE
JMP DIVIDE
DOUBLEDIVIDE:
DIV BX
ADD DL, 30H
PUSH DX
INC CX
CMP AX, 0
JE ENDDIVIDE
JMP DOUBLEDIVIDE
ENDDIVIDE:
POP DX;
MOV AH, 02H
INT 21H
LOOP
ENDDIVIDE
ENDQUICK:
MOV AX, 4C00H
INT 21H
SUMARRAY PROC NEAR
GETPARAM:
PUSH BP;
MOV BP, SP
PUSH BX;
PUSH CX
PUSH DX
PUSH AX
MOV CX, [BP+4] ;ARRAY
SIZE
MOV BX, [BP+6] ; ARRAY
ADD
MOV DX, 0; SUM
SUMLOOP:
MOV AX, [BX]
MOV AH, 0
ADD DX, AX
ADD BX, 1;
LOOP SUMLOOP;
MOV [BP+6], DX; PUSH RESULT IN
STACK
POP AX
POP DX
POP CX
POP BX
POP BP
RET 2;
SUMARRAY ENDP
END START
Nick Huang
Qustion:
黄兄你好,
小弟有如下数题百思不得其解,恳请指点。
Assignment3
3 ; 6; 12(ii);14;15;16;17
还有几个关于SET的概念:
A∪B
= { Q(x)→P(Q)} =
![]() ??
??
![]() ∪B = { P(Q)→Q(x)}
=
∪B = { P(Q)→Q(x)}
=
![]() ??
??
Answer:
1. Assignment3 No.3: 这个题目的意思是确定f是否为onto.在确定是否为onto时候其实我们更关心的是co-domain里是否每一个元素都有包括在function f里面。显然,这道题里面的自变量有两个,m,n。我们要确定的是这两个子变量所组成的函数的值是否覆盖了整个自然数。例如,iii)f(m,n) = |m|+|n| 很明显的,他的值是非负的,所以,一定没有覆盖所有的自然数。经验就是,讨论是否onto时候,主要关心的是co-domain的值,至于domain不要被他的复杂所迷惑。
2。Assignment3 no.6: 这个题目的意思是求组合函数。在学了关系(relation)以后,可以更好的理解,如f@g,假如我们把f,g看作关系(函数本身就是一种关系)那么就表示为从关系g的起始集合里的某个元素a对应g的终止集合里的某个元素b,同时这个元素b恰好是关系f的起始集合里的元素,那么关系f里b所对应的终止集合的元素c就和a组成了一种新的关系,这个新的关系就是组合关系f@g。
请注意,这里是g的起始元素到f的终止元素,和记号f@g的顺序正好相反。
回到函数,f@g就是表示函数g是函数f的自变量,也就是复合函数,所以,你只需要把函数f的自变量用函数g来替换就可以了。
3。A3 no. 12ii) a congruent b(mod m) ==> gcd(a,m)==gcd(b,m)
这个题目有几种思路。 最简单的是应用欧几里德算法的一个推论(p178) a = bq+r ==>gcd(a,b)==gcd(b,r)
从题目知:m|a - b(congruent定义)==> exist q(a- b = qm) (整除的定义)==〉exist q(a= b + qm)(移项)
==〉gcd(a,b) = gcd(b,m) (运用上述的推论)
solution中实际上给出了一个对推论的简单证明:
a - qm 和 a - m有同样的divisor(可以找一找书上的定理或者简单证明如下:
exist x(x|a and x|m)(假设a和m有同样的divisor的话) ==>exist x exist q(x|a-qm and x|m)
(这个是定理,p154 corollary,就是m=1,n=-q的情况.)
==> gcd(a,m) == gcd(a-qm,m)(因为gcd是公约数中最大的一个而已。)
在运用题目的部分:
m|a - b(congruent定义)==> exist q(a- b = qm) (整除的定义)==〉exist q(b= a- qm)(移项)
所以, gcd(a,m) = gcd(a-qm, m) = gcd(b, m)(把b=a-qm代入)
4。 A3 no. 14.:这个题目的证明很繁杂,solution的思路也比较难想到,我的证明想法就是tutor的提示,先考虑n是否能被5整除,就是n=5k如果能被5整除可以很容易去证明底数是80的那个(当然你还是要用到题目要求的n市奇数的条件,所以你要进一步假设k是奇数k=2h+1,所以n=5(2h+1) = 10h+5)
当n不能被5整除时候,分4种情况:余数分别是1,2,3,4,同时类似地让n还是奇数,比如余数为2时候,n=5k+2,这时候k只能是奇数n才能是奇数,所以,n=5(2h+1)+2 = 10h+7。这样你再参考以下solution的方法判断奇偶数,就可以了。
5。 A3 no. 15:这些题目你要参考tutorial的笔记,要点就是比如第二题:x~2 congruent 3(mod 4)这一步有一个隐含的结论就是{x~2 mod 4|x is integer} =={x~2 mod 4| x =0, 1,2,3}, 就是说x平方除以4的余数等于x取0,1,2,3所得的余数一样,这个证明,你可以看一下tutorial的笔记,或者你记住这个结论也应该可以吧。
6。A3 no. 16:这个题目前面1,2的证明应该很简单,全部是根据floor, ceil的定义。第3,4的证明我觉得solution的反证法不好,因为,考虑的情况应该有4种,很麻烦,不如我的证明法简单易懂。
7。A3 no. 17:这个题目证明有很多小题,你对那一题不清楚呢?或者,星期一早上到H-513碰头再说吧。
8。 A∪B
= { Q(x)→P(Q)} =
![]() (这里有一点错误,第一个B应该为B的补集--complement,你是从哪里拷贝的?我还真没有办法找到这样的图片来改正。哈哈。)
(这里有一点错误,第一个B应该为B的补集--complement,你是从哪里拷贝的?我还真没有办法找到这样的图片来改正。哈哈。)
![]() ∪B = { P(Q)→Q(x)}
=
∪B = { P(Q)→Q(x)}
=
![]()
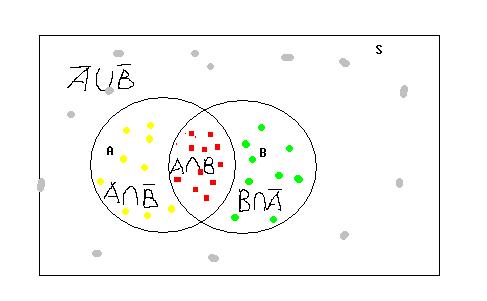
简单的证明可以帮助你理解:
假定 P(x) <==>(def) x in A; Q(x) <==> (def) x in B
x in A U not B <==> all x( x in A or not x in B) <==> all x[not Q(x) or P(x)]
<==> all x[Q(x) --> P(x)] (注意这里都是逻辑关系,我只是说了如果有一个元素x属于这个集合的话就相当于逻辑上的相应关系。)
而集合是可以有逻辑关系来定义的。比如:{x| (x in A) or (not x in B)}就定义了上述集合。
而从集合的运算我们又可以得到:![]() (我贴不出了,相信你明白的。)
(我贴不出了,相信你明白的。)
所以,我的经验就是,集合是集合,逻辑是逻辑,符号和关系只是类似,并不能混用,但是两者又有联系,集合可以用逻辑来定义,逻辑可以用集合来表现,更好理解。
最后一个就是exclusive or,你可以在图上的红点和灰点看出来。
这是我的备忘录,将来学comp229再来解决:在固定指令集中,fetch总是可以取到完整的一条指令。可是,在不定指令集中
怎么才能取到下一条完整指令?该取多少bytes?
这个问题解决了:问朱春明同学,他说的很好,我们就取最长的指令好了,有什么关系?反正纪录的是下一条指令的首地
址。好!
问题:
您好!有个加密问题想请教您,比如rijindael 是256bit 加密的,如果我的password是8位或100位,是否破解时间一样(用穷举法)。这里所指的258bit是怎样一种概念,是否最长password为256位。
我的解答:
逻辑仅仅是征途上的航标灯???
假如给我们一棵搜索树,每个节点代表一个逻辑判断,从一个已知真伪的节点出发根据一系列的所谓“逻辑”关系去试图到达某一个目的节点,这个过程我们通常称作“逻辑推理”。从广义的搜索来看,逻辑的与或仅仅是节点之间相对关系。
例如,所谓“或”说的是当你到达某一个节点继续前进有一系列子节点供选择时候,从“或”中任意选一个都可以继续。
所谓“与”说的是当你达到某一个节点继续前进有一系列子节点供选择时候,必须要同时选择这些子节点才可以继续前进,可是,我们真的有“分身术”同时走多个路径吗?
这其中似乎蕴含着某种深奥的东西,绝非“串联,并联”这么肤浅。
![]()
![]()
![]()