色即是空,空即是色?
Some doubts about empty set...
Hi
Professor,
I
checked textbook and feel a bit confusing about empty set. On page 83, they gave
answer for power set of both empty set Φ and {Φ}:
P(Φ)
= {Φ}.
P({Φ})
= {Φ, {Φ}};
So, my doubt is:
1.
What is {Φ}?
Is it a set that only have one element Φ? No, because
they treat Φ and {Φ}
differently.
2.
What is the size of Φ and {Φ}? Or |Φ|==??
|{Φ}| == ??
3.
Can we say that in this world there is actually no such set that its size
is zero? As even Φ is a subset of Φ, right?
4.
According to your theory in class:
if ┌(x∈S)
then |P(S ∪ {x})| = 2 |P(S)|
However, in the
case that S = {Φ},
then
P({Φ})
= {Φ, {Φ}};
//according to textbook page 82.
|
P({Φ})|
= 2;
And
if ┌(x=Φ)
then
P(S
∪
{x}) = {Φ,
{Φ}, {x},
//1 element
{Φ,{Φ}},
{Φ,x}, {{Φ}, x},
//2 elements
{Φ,
{Φ}, x}}
//3 elements
= 7
5.
However, even
if we regard {Φ}
as an illegal expression, everything still doesn't seem to be explainable:
P(Φ) = {Φ};
and
its size is 1
P({x})
= {Φ,
{x}} and
its size is 2
But
how about following:
P({x})
= {Φ,
{x}, {Φ, x}}
and its size should be 3???
Or
just simply because we regard {x} as {Φ,x}
implicitly?
I had trouble reading some of the characters in your message.
So I will write "E" for the empty set.
>> I checked textbook and feel a bit confusing about empty set. On page
>> 83, they gave answer for power set of both empty set E and {E}:
>>
>> P(E) = {E}.
>>
>> P({E}) = {E, {E}};
This is correct.
>> So, my doubt is:
>>
>> 1. What is {E}? Is it a set that only have one element E?
Yes; x in {E} <==> x = E.
>> No, because they said they treat E and {E} differently.
This is incorrect. E and {E} are different, and {E} has exactly one member.
>> 2. What is the size of E and {E}? Or |E|==?? |{E}| == ??
|E| = 0, |{E}| = 1.
>> 3. Can we say that in this world there is actually no such set
>> that its size is zero? As even E is a subset of E, right?
No; the empty set has size zero.
E has no members.
E has one (and only one) subset, namely, E itself.
>> 4. According to your theory in class:
>>
>> if x not in S then |P(S U {x})| = 2 |P(S)|
>>
>> However, in the case that S = {E}, then
>>
>> P({E}) = {E, {E}}; //according to textbook page 82.
>>
>> | P({E})| = 2;
That is correct.
>> And if 漏掳(x=E) then
I am not able to read the line above; I assume S = {E, {E}}.
>> P(S U {x}) = {E, {E}, {x}, //1 element
>>
>> {E,{E}}, {E,x}, {{E}, x}, //2 elements
>>
>> {E, {E}, x}} //3 elements
>>
>> = 7
Actually, S U {x} = {E, {E}, x}. Therefore
P(S U {x}) = {
E, \\ 0 elements
{E}, {{E}}, {x} \\ 1 element
{E,{E}}, {E,x}, {{E},x} \\ 2 elements
{E, {E}, x} \\ 3 elements
},
so |P(S U {x})| = 8.
>> 5. However, even if we regard {E} as a illegal expression,
>> everything seems to be explainable:
>>
>> P(E) = {E}; and its size is 1
>>
>> P({x}) = {E, {x}} and its size is 2
>>
>> But how about following:
>>
>> P({x}) = {E, {x}, {E, x}} and its size should be 3???
{E,x} is not a subset of {x}, so {E,x} is not a member of P({x}).
>> Or just simply because we regard {x} as {E,x} implicitly?
That is incorrect; |{x}| = 1, |{E,x}| = 2, so {x} =/= {E,x}.
-- FORD
还是不明白
Hi Professor,
Thank you so much for your prompt reply. However, I am still not very convincing about some points:
1. You introduced {{E}} and I tried to deduct as following:
P({{E}}) == {
E, {E}, {{E}}, {{{E}}}
{E,{E}}, {E, {{E}}}, {{E}, {{E}}
{E,{E},{{E}}}
}
Is it right? if it is right what is size of {{E}}? |{{E}}| ==???1???
2. By intuition, I always feel something is not quite right, but I cannot think very clearly. And I guess one of the problem
is the definition of sets and elements. They are actually like recursive. On page 77 and 78, when sets is defined, they
introduce element or object. And when element or object is defined they also mentioned set. This remind me the definination in
C++, if you define like following, it won't pass even you give a forward definition "class Element;" before class set is
defined.
Although there is technich in C++ to walk around this kind of problem by defining "Element" as pointer "Element*". But still
I think this may give to some trouble.
#include <iostream>
using namespace std;
class Element;
class Set
{
private:
Element element;
};
class Element
{
private:
Set set;
};
int main()
{
return 0;
}
TO:
Hi Dr. Ford,
I am not sure if the question 16_4 in assignment is correct or not. As I prove that question IV of No. 16 should be same as III such that "ah>n+1 or bk>n+1" instead of "ah>=n+1 or bk>= n+1". Because question IV and III are actually one question, there should not be difference on the "equal" sign. By intuition of logic, we cannot get both III and IV with one has ">=" and the other has ">" only. And following is my proof:
as 1/a + 1/b = 1 and conclusion from question II that h+k = n+1
we have: h+k = n+1 = n(1/a+1/b) + (1/a+1/b) ==>h-(n/a + 1/a) = -(k - (n/b + 1/b))
as a, b are irrational number, (1+n)/a and (1+n)/b are surely irrational number ==>
h <> (n/a + 1/a) and k <> (n/b+1/b) since h, k are integers
so: h-(n/a + 1/a) = -(k - (n/b + 1/b)) is a non-zero number.
No matter the number is positive or negative, (h-(n/a + 1/a))and (k - (n/b + 1/b)) will always has different sign.
==> [h-(n/a + 1/a) > 0 and k - (n/b + 1/b)<0] or [h-(n/a + 1/a)<0 and k - (n/b + 1/b)>0]
==> [ah> n+1 and bk<n+1] or [ah<n+1 and bk> n+1] since a, b are positive
==> [either ah<n+1 or bk< n+1] and [either ah>n+1 or bk>n+1] {distribution law}
After all, as a,b are irrational numbers, there will not be "equal" sign in either case.
I hope you can look into it and see if I am correct or not.
Thank you for your patience.
Qingzhe Huang
FROM:
>> I am not sure if the question 16_4 in assignment is correct or not.
Don't worry, it is correct.
>> As I prove that question IV of No. 16 should be same as III such that >> "ah>n+1 or bk>n+1" instead of "ah>=n+1 or bk>= n+1".
I agree that it is not possible to have ah = n + 1 or bk = n + 1. Once you have made this observation, it is enough to show that ah > n + 1 or bk > n + 1 to finish part (iv) of problem 16.
>> (h-(n/a + 1/a))and (k - (n/b + 1/b)) will always has different sign.
Correct.
>> ==> [h-(n/a + 1/a) > 0 and k - (n/b + 1/b) < 0] or >> [h-(n/a + 1/a) < 0 and k - (n/b + 1/b) > 0]
Correct.
==> [ah > n+1 and bk < n+1] or [ah < n+1 and bk > n+1]
Correct.
==> [ah < n+1 or bk < n+1] or [ah > n+1 or bk > n+1]
Correct, but I don't see what the "distribution law" has to do with it. (And where did the and's go?) From a truth table you get
(p and not q) or (not p and q) <==> (p or q) and (not p or not q).
Since we know ah = n+1 <==> FALSE and bk = n+1 <==> FALSE, this gives
[ah > n+1 and bk < n+1] or [ah < n+1 and bk > n+1]
<==> [ah < n+1 or bk < n+1] and [ah > n+1 or bk > n+1].
^^^
This way you have done parts (iii) and (iv) of problem 16 simultaneously.
Very nice!
-- FORD
TO:
Hi Dr. Ford,
Thank you for your mail and I am sorry for my miss-typing "and" with "or" at the last step of proof. Thank you for your correcting my mistakes.
As for the solution of assignment 2, I found a lot of doubts which made me more and more confusing. And I hope I can ask your advice Tuesday afternoon. However, in case that it is not possible, I think I need to ask you now by mail as following:
1. In no. 5--ii) it is required to use an indirect proof to prove that
"for all n(n=even --> square(n)=even number)"
In the solution, I cannot understand its 3rd step from "not exist m( square(n)= 2m )==>
not exist k (square(n) = 2x2 square(k))"...
I don't know why we can conclude that m = 2square(k), does it mean we assume the to-be-proved-proof which is "if square(n) is even number then n is even number"? I found out in text book on page72 example 35 is very similarly despicting this kind of error: "circular reasoning". Is it? If not what is meaning of that step?
2. In no. 9, it is very obviously that the conclusion is wrong, but why do we consider the reasoning is correct? Does it mean that all our mathematic proof are step-by-step implications instead of step-by-step equivalence?
As on the question, step 2 is actually not equivalent to step 1 as squaring both sides will give negative value to x, however, in step 1, x is supposed to be non-negative. So, I think from step1 to step2 is an implication which means the solution set of step1 is a subset of solution set of step2. Is it right?
I also found a similar example in textbook on page 71 example 31. In the example, by dividing both sides with a 0 will lead a false conclusion or to produce a bigger solution set to original question. And in all cases, the incremented part of solution set is false. Is it right?
Thank you for your time and patience.
Qingzhe Huang
>> 1. In no. 5--ii) it is required to use an indirect proof to prove that >> >> "for all n(n=even --> square(n)=even number)" >> >> In the solution, I cannot understand its 3rd step from >> "not exist m(square(n)= 2m )==> >> >> not exist k (square(n) = 2x2 square(k))"... >> >> I don't know why we can conclude that m = 2square(k), does it mean we >> assume the to-be-proved-proof which is "if square(n) is even number >> then n is even number"? I found out in text book on page72 example 35 >> is very similarly despicting this kind of error: "circular reasoning". >> Is it? If not what is meaning of that step? Let P(n) <==> not exists m (n^2 = 2 m), Q(n) <==> not exists m (n^2 = 2 * 2 k^2). Then P(n) <==> (n^2)/2 is not an integer; Q(n) <==> (n^2)/2 is not twice the square of an integer. P(n) is not a statement about m. Q(n) is not a statement about k. We cannot conclude that m = 2k^2. It should be clear that if (n^2)/2 is not an integer then (n^2)/2 is not twice the square of an integer (which is what the proof says). >> 2. In no. 9, it is very obviously that the conclusion is wrong, but >> why do we consider the reasoning is correct? Does it mean that all our >> mathematic proof are step-by-step implications instead of step-by-step >> equivalence? Yes, each step is an implication, not an equivalence. In particular, (1) ===> (2), but (2) =/=> (1). So what we have proved is sqrt(2 x^2 - 1) = x ===> (x = 1) or (x = -1), which is correct. Of course, another step is needed: x = 1 ===> sqrt(2 x^2 - 1) = x, x = -1 ===> sqrt(2 x^2 - 1) =/= x which shows that x = 1 is the only solution. >> As on the question, step 2 is actually not equivalent to step 1 as >> squaring both sides will give negative value to x, however, in step 1, >> x is supposed to be non-negative. So, I think from step1 to step2 is >> an implication which means the solution set of step1 is a subset of >> solution set of step2. Is it right? Yes, that is exactly right. >> I also found a similar example in textbook on page 71 example 31. In >> the example, by dividing both sides with a 0 will lead a false >> conclusion or to produce a bigger solution set to original question. >> And in all cases, the incremented part of solution set is false. Is it >> right? To be precise, (a - b)(a + b) = b(a - b) =/=> a + b = b because (a - b)(a + b) = b(a - b) =/=> a + b = b <==> not [ (a - b)(a + b) = b(a - b) ===> a + b = b ] <==> not forall a,b [ (a - b)(a + b) = b(a - b) ---> a + b = b ] <==> exists a,b not [ (a - b)(a + b) = b(a - b) ---> a + b = b ] <==> exists a,b [ (a - b)(a + b) = b(a - b) and a + b =/= b ] which is true because (1 - 1)(1 + 1) = 1(1 - 1), but 1 + 1 =/= 1. There is a theorem about the real numbers that says (x =\= 0) and (x y = x z) ===> (y = z) but there is no theorem that says (x y = x z) ===> (y = z). -- FORD
TO:
Hi Dr. Ford,
Thank you for your mail and I finally understand what is meaning in no. 5.
However, I am still a little picky about the assumption at step2:
Let P(n) <==> not
exists m (n^2 = 2 m),
Q(n) <==> not exists k (n^2 = 2 * 2 k^2).
It is true that
not (2|n~2) ==>not(4|n~2)
but can we
not (2|n~2) ==>not exist k(n~2 = 2x2x k~2) ???
Because if n~2 is not divided by 2 it definitely cannot be divided by 4, but it doesnot necessarily need to say n~2 is not equal to 4 times k square. Of course apart 4 it must be a square number such as k. But we just cannot jump to this conclusion that it-must-be-a-square-number, right?(of course it is true, but it maybe unnecessary to need that square number as long as we know it is a number that cannot be divided by 4 either. and this is enough.)
We start from the assumption that n~2 is an odd number, we cannot jump to conclusion that it cannot be a number with 4x k~2 as we don't know if the rest part of n~2 apart from 4 is a square number or not. For example, even we start from an assumption that an even number say 24, still we can say there doesnot exist a number k that 24 = 4x k~2, but in this case what is difference between two assumptions that a number is even or odd. Right?
Sorry for bothering with these trivial details again.
Qingzhe Huang
>> It is true that >> >> not (2|n~2) ==>not(4|n~2) >> >> but can we >> >> not (2|n~2) ==>not exist k(n~2 = 2x2x k~2) ??? It is clear that exists k (n^2 = 2x2xk^2) ==> 2 | n^2, the contrapositive of which is not (2 | n^2) ==> not exists k (n^2 = 2x2xk^2) which must also be true. -- FORD
A proof of correctness of mathematical induction
Well-ordering axiom for Natural Numbers:
S in N ^ S=\= emptySet ==> S has a least element such that
Exist x in S for all y in S (x<=y) (or in other words you can find a the least number in this set)
Corollery(Mathematical Induction)
P(0)^ all k(not P(k) V P(k+1)) ==> for all n( P(n))
How to prove this? Use indirect proof or in other words, contrapositive method to prove:
not (for all n(P(n)) ==> not ( P(0)^ all k(not P(k) V P(k+1)))
Let S = {n: not P(n)} then
n in S <==> not P(n)
Observe: S = emptyset <==> for all n ( P(n) )
Assume m is the least element of S:
case 1: m =0 ==> m in s ==> not P(0)
case 2: m>0 ==>( P(m -1)^ not P(m)) (as m is the least of S, m-1 not in S, P(m-1)==true and P(m) = false)
So, exist n not P(n) ==> not P(0) V exist k(P(k) ^ not P(k+1))
Proved. <==> Q.E.D.
(The above is a note from lecture of Dr. Ford.)
我的想法。。。
我一直想写一个综合的逻辑类:在一个Domain内每个逻辑对象及其Complement与所有其他Domain内的对象及其各自的Complement之间的关系所组成的
一个矩阵,这应当是所有可能的逻辑关系的总和。我们在对一个概念作定义时候总是要首先定义概念的内涵和外延,概念的外延不同,内涵也常常跟着
改变,这就是歧义(ambuiguaty)的原因。所以我常常想面向对象的的逻辑对象应当在对象内部有一个机制来定义对象的外延,怎样定义呢?最方便
的就是通过定义对象的Complement,一旦对象建立,他的Complement也要建立,自然对象所在的范围自然就建立乐,否则你是定义不出Complement。
Under the two hypotheses
H
1 : The soup is not satisfactory or the appetizer is not adequate;H
2 : If the dessert is delicious then the soup is satisfactory;which of the following conclusions are valid?
i) The soup is satisfactory or the dessert is not delicious.
ii) The dessert is not delicious if the appetizer is adequate.
iii) The dessert is not delicious or the soup is not satisfactory.
iv) The appetizer is not adequate if the dessert is not delicious.
v) If the appetizer is not adequate then either the dessert is not delicious or
the soup is satisfactory.How can we solve this kind of problems? Dr. Ford suggests that a truth table will be used to analysis.
Of course truth table can solve almost all problems but it is just not so efficient at all.
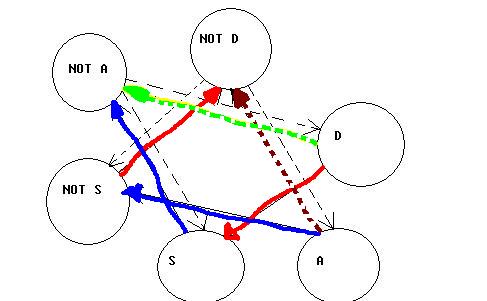
See figure above, let us define as following:
S(x) == soup is satisfactory
D(x) == dessert is delicious
A(x) == apetitizer is adequate.
Then
Hypothesis 1 <==> H1 <==> [not S V not A] <==> [S ==> not A] <==> [A ==> not S] (implication &contrapositive)
See the blue arrow, it is the relation between "S and not A", and "A and not S".
Hypothesis 2 <==> H2 <==> [not D V S] <==> [D ==> S] <==> [not S ==> not D] (implication &contrapositive)
See the red arrow, it is the relation between "not D and S" , and "D and S".
From the hypothesis, we can have some corolleries:
1. [[D ==> S] ^ [S ==> NOT A]] ==> [D ==> NOT A] (This is like transferring, see green arrow.)
2. NOT A ==> [ D ^ S ] (Do you see any connection between 1 and 2? )
3. [[A==>NOT S] ^ [NOT S ==> NOT D]] ==> [A ==> NOT D] (This is similar as 1, see brown arrow.)
4. NOT D ==> [A ^ NOT S]
How to determine if a relation is transitive through matrix?
Condition: Particularly we concentrate to relation R on set A.
Definition of transitive: [for ALL a,b,c [(a,b) in R AND (b,c) in R ==> (a,c) in R] ] ==> R is transitive
Using matrix to represent R:
c1 c2 c3 c4
r1 0 0 0 0
r2 0 0 0 1 this is row 2, col 4
row3,col2 r3 0 1 0 1 their crossing points is row 3,col 4
r4 0 0 0 0
Suppose element row i, col j or [i,j] =1 , then the transitive relation requires that there is an element such that row j,
col k or [j, k] =1 AND element row i, col k or [i,k] = 1.
What does this mean? It means that for each element [i,j], if on row j there is any 1 elements [j,k], their crossing point
element [i,k] must be 1.
Why don't we define the Reflexive as "Pure" Reflexive?
I think the Reflexive relation defined in text is not very impressive. On the contrary, the Diagonal A is more like the
Reflexive which I consider to be. So, why don't we consider Diagonal A as "Pure Reflexive"?
Let's define "Pure" Reflexive as following:
Pure Reflexive == {(a,b)| a = b}
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
What connections between "Pure" Reflexive, Symmetric and Transitive?
A. R is Reflexive ==> R is Symmetric and R is Transitive.
(Here I personally defined Reflexive as "Pure" Reflexive or Diagonal == {(a,b)| a = b} which is more reasonable.)
Proof: R is Pure Reflexive ==> R = {(a,b)| a=b} ==> (a,b) in R and (b,a) in R ==> R is symmetric
==> for all a,b,c[(a,b) in R and (b,c) in R --> (b,c) in R] ==> R is transitive.
B. "pure" Reflexive is the destination of both Symmetric and Transitive after R^n.
Proof: Symmetric will converge to Diagonal (Pure Reflexive) after R^2:
R is Symmetric ==> for all a, b [(a,b) in R --> (b,a) in R] ==> for all a,b[(a,b) in R and (b,a) in R -->(a,a) in R^2]
Proof: Transitive will converge to Diagonal (Pure Reflexive) after R^n:
R is Transitive ==> for all a,b,c[ (a
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Hi Professor,
You wrote on blackboard that the proof of following theorem is very important, so I try to prove it and I will be grateful
if you have time to check for me if it is correct or not.
i) To prove: If R is a equivalence relation on set A then R = for all a in A( U [a] x [a] )
Proof:
Let S = all a in A ( U [a]x[a] ), so it is to prove R is a subset of S and S is a subset of R.
1. for all a,b [ (a,b) in R ] ==> b in [a] by definition of equivalence class; -----------(A)
as R is equivalence relation ==> (a, a) in R ==> a in [a] -----------(B)
(A)^(B) ==> (a,b) in [a]x[a] ==> (a,b) in S (as [a]x[a] is one of equivalence classes for R)
==> R is a subset of S
2. for all (a,b) in S ==> exist c( (a,b) in [c]x[c]) ==> a, b both in [c] ==> (c,a) in R and (c,b) in R
==> (a,c) in R ==> (a,b) in R ==> S is a subset of R
Q.E.D.
ii) To prove: R is a equivalence relation on set A <==> R = U SxS where S in P and P is some partition of A
Proof:
It is to prove that LHS ==> RHS and RHS ==> LHS
1. Let's prove LHS ==> RHS first. Use theorem that the equivalence class of R is a partition of A and let the
partition of equivalence class of R be Q.
Let's prove that for LHS ==> all S in Q that R = U SxS.
It is to prove that R is a subset of U SxS and U SxS is a subset of R.
1.1. for (a,b) in R ==> (a,a) in R ==> a in [a] of R and b in [a] of R ==> (a,b) in [a]x[a] ==> (a,b) in U SxS
==> R is a subset of U SxS
1.2. for (a,b) in U SxS ==> exist c ( (a,b) in [c]x[c] where [c] is one equivalence class of R) ==> a in [c] and b in [c]
==> (c,a) in R and (c,b) in R ==> (a,c) in R ==> (a,b) in R ==> U SxS is a subset of R
1.1 and 1.2 ==> R = U SxS ==> [LHS ==> RHS]
2. Let's prove RHS ==> LHS now.
2.1. for all a in A ==> exist S( a in S where S in P and P is some partition of A) ==> (a,a) in SxS
==> for all a in A[ (a,a) in R] ==> R is reflexive
2.2. for all (a,b) in RHS ==> exist S [(a,b) in SxS where S is subset of some partition P of A] ==>
a in S and b in S ==> (b,a) in SxS ==> (b,a) in R and (a,b) in R ==> R is symmetric
2.3. for all a,b,c where (a,b) in RHS and (b,c) in RHS ==> a,b in X and b,c in Y where X,Y is subset of some partition
P of set A ==> b in X and b in Y ==> X = Y ==> a,b,c in X ==> (a,c) in XxX ==> (a,c) in R
==> R is transitive
2.1. and 2.2. and 2.3. ==> R is equivalence relation ==> [RHS ==> LHS]
Q.E.D.
Thank you for your patience and have a nice day
Qingzhe Huang
Proof of Assignment5 Q3:
Hi Professor,
I think it over and realize it is not a correct proof even I prove it that in the path between a,b there will be repeating
elements because the repeating elements will not necessarily be a and b. According to definition of path, the elements in
path can be repeated and therefore the length may not be the shortest one. So, I have first prove that the length of path
between a and b cannot be shorter than n and only after this can I invoke Lemma 1 on p501 that "when a <> b, the length
cannot exceed n-1" to lead a contradiction to finish the proof. The following is my new version of proof:
To prove R* = R U R^2 U R^3 ... U R^(n-1) U D -------- (R* stands for connectivity relation,D stands for Diagonal A)
It is equivalent to prove that (a,b) in R* ==> (a,b) in [R U R^2 ...U R^(n-1)] or (a,b) in D
Let's prove by contradiction:
Assume (a,b) in R* and (a,b) not in [R U R^2...U R^(n-1)] and (a,b) not in D
As |A| = n ==> R* = R U R^2 ...U R^(n-1) U R^(n)
==> (a,b) in R^(n) and (a,b) not in [R U R^2...U R^(n-1)] and (a,b) not in D -------------------(1)
==> There is a path of length n in R such that
x0, x1,x2...xn in A and (x0,x1) in R,(x1,x2) in R...(xn-1, xn) in R and a = x0, b=xn
Now we will prove the length of this path cannot be shorter than n:
If the length of path can be shorter as m < n, then (a,b) in R^m which is contraction to result(1). So, the path is already
the shortest one with length of n. However, according to Lemma 1 on p501, when a<>b, the length of path cannot exceed n-1.
Therefore, a must be equal b. Then (a,b) in D and this is a contradiction.
Q.E.D.
Are they equivalent definition for closure?
Hi professor,
I am reviewing my old notes of your class and found your version of definition of closure is slightly different from textbook.
Here is your definition:
1. R is a subset of R(Hat).
2. R(Hat) has a property P.
3. If S has property P and R is subset of S and S is subset of R(Hat) then S=R(Hat)
Then R(Hat) is closure of R with respect to property P
Here is definition from textbook:
1. S has property P.
2. R is subset of S.
3. for all relation R'( R' has property P and R is subset of R' --> S is subset of R')
Then S is closure of R with respect to property P.
I wonder if these two definition are equivalent? Because what I understand from reading textbook is that closure is the smallest
possible relation that both has the property P and also containing relation R. It is like the lower bound of all such relations.
But your definition gives me impression that the lower bound and higher bound of R with property P is converge to same. Is it right?
And is it always true that we can find such a closure?
Also in your proof for transitive closure, you use the definition of textbook instead what you used in proving reflexive and
symmetric closure. For example, is it true that all transitive relations which contains R are equal to its transitive closure of R?
Thank you for your time in advance,
Qingzhe Huang
So these definitions are (apparently) not equivalent.
>> Here is your definition: >> 1. R is a subset of R(Hat). >> 2. R(Hat) has a property P. >> 3. If S has property P and R is subset of S and S is subset of R(Hat) then >> S=R(Hat) >> Then R(Hat) is closure of R with respect to property P >> Here is definition from textbook: >> 1. S has property P. >> 2. R is subset of S. >> 3. for all relation R'( R' has property P and R is subset of R' --> S is >> subset of R') >> Then S is closure of R with respect to property P. Let's make the notation in the two definitions consistent. P(S) means "relation S has property P". C is the closure of relation R with respect to property P. F1: R subset C F2: P(C) F3: P(T) and R subset T and T subset C ==> T = C R1: P(C) R2: R subset C R3: P(T) and R subset T ==> C subset T Obviously R3 ==> F3, but it is not clear that (F1 and F2 and F3) ==> R3. So these definitions are (apparently) not equivalent. The textbook definition (R1 and R2 and R3) is the correct one. Statement F3 should not appear in a definition of closure. Statement F3 would be used in proving that the closure must be unique. If C1 and C2 both satisfy R1 and R2 and R3, then each of C1 and C2 is a subset of the other, so they are equal. >> ... what I understand from reading textbook is that closure is the > smallest possible relation that both has the property P and also >> containing relation R. It is like the lower bound of all such relations. That is exactly right. -- FORD
A new shortcut
A2Q16: To prove [A∩C=Ф]∧[B∩C=Ф]∧[A∪C=B∪C] ==> [A=B]
[A∪C=B∪C] ==> (A∪C)∩A = (B∪C)∩A ==> A = (A∩B)∪(A∩C) = (A∩B)∪Ф = A∩B (1)
[A∪C=B∪C] ==> (A∪C)∩B = (B∪C)∩B ==> (A∩B)∪(B∩C) = B ==> B = (A∩B)∪Ф = A∩B (2)
(1) + (2) ==> A = B
Q.E.D.
The proof is much clear and elegant, isn't it?
Let f(x) = x mod n where n is positive constant bigger than 1, x is integer
then f(xy) = f(f(x)f(y))
Proof:
assume x = pn +r, y = qn + s then f(x) = r, f(y)= s;
Then f(xy) = xy mod n = (pn+r)(qn+s) mod n = (pqn^2 + pns + qnr + rs) mod n = rs mod n (since all other term has factor n)
and f(f(x)f(y)) = [(x mod n)(y mod n)] mod n = rs mod n (because by definition x mod n = r, y mod n =s)
So, it is proved. Q.E.D.
How to find inverse function of encryption?
>> Regarding encryption and decryption on textbook page166, I am trying to >> write a simple function in c++ using the method on book. I use the >> encryption function of f(p)= (ap+b) mod 26 >> but I am stuck in decryption. I simply cannot think a invertable function >> of f(p). Can you give me some hint for this problem? You should look ahead to page 189 and read about Fermat's Little Theorem. Let m = 26. For f to be invertible it is necessary and sufficent that gcd(a,m) = 1. Assuming gcd(a,m) = 1, let c = a^11 mod m and let g(y) = (cy-cb) mod m. Then g is the inverse function of f. (You can use Fermat's Little Theorem to prove it.) -- FORD
Pls note that a^11 stands for "inverse of a mod m" which puzzle me for a couple of days. As I thought it is exponent 11 which
is meaningless.
Why should we use Fermat's Little Theorem?
Hi professor,
Thank you so much for your reply! It really helps me to understand and I already finished my program with RSA encryption method.
By the way, in your mail you said:
>For f to be invertible it is necessary and sufficent that gcd(a,m) = 1.
>
>Assuming gcd(a,m) = 1, let c = a^11 mod m and let g(y) = (cy-cb) mod m.
>
>Then g is the inverse function of f. (You can use Fermat's Little Theorem
>to prove it.)
And I thought for a couple of days and cannot make connection with Fermat's Little Theorem. However, I think I can prove it easily with definition of inverse of "a mod m".
Given f(p) = (ap + b) mod m
assume c = a~ is inverse of a mod m, gcd(a, m) =1 then to prove
g(y) = (cy - cb) mod m is inverse function of f(p).
proof:
f(p) = (ap+b) mod m ==> f(p) = (ap+b) (mod m) {=stands for congruent}
==> f(p) - b = [ap+b-b] (mod m) {=stands for congruent} (1)
by definition of inverse of "a mod m" acp = 1p (mod m), times c at both sides of (1) and we have
c( f(p) - b) = p (mod m) ==> p mod m = (cf(p) - cb) mod m
so, p = (cf(p) - cb) mod m
Because we can choose appropriate m to make p = p mod m.
So, f(y) = (cy - cb) mod m is indeed inverse function of f(p). And I am not sure about what you refer to with "Fermat's Little Theorem", can you be more specific?
Thank you for your time.
Qingzhe Huang
Little detail about RSA decryption
-----What a simple sentence means!
In textbook P193, the proof for C^d = M (mod pq) is not very clear and I thought it for a whole night in dream.
It is originally in book like following:
...
C^d = M (mod p) (1)
and
C^d = M (mod q). (2)
Since gcd(p,q) = 1, it follows by the Chinese Remainder Theorem that
C^d = M (mod pq).
But the problem is how it follows by Chinese Remainder Theorem(CRT)? We all know that according to CRT that
X = a1 (mod m1)
X = a2 (mod m2)
...
X = ak (mod mk)
If m1, m2, ...mk are pairwise relatively prime there will be a simultaneous solution of
X = a1*M1*y1 + a2*M2*y2 +...ak*Mk*yk
where Mk is m/mk and m = m1*m2...*mk, yk is the inverse of Mk mod mk. (see page186)
What's more there will be countless solution of X but all of them are unique congruent to m. In other words,
X = a1*M1*y1 + a2*M2*y2 +...ak*Mk*yk (mod m)
This is CRT, so let's try to solve (1) and (2) by CRT.
m =p*q, m1 = p, m2 =q , M1 = m/m1 = p*q/p = q, M2= m/m2 = p*q/q = p a1 = M, a2 = M, y1 is inverse of q mod p,
y2 is inverse of p mod q
As C^d is already the solution, so
C^d = a1*M1*y1 + a2*M2*y2 = M*q*y1 + M*p*y2
The problem arise here: how to find out y1,y2? And how do we get C^d = M (mod pq)?
It seems quite difficult, right?
However, let's recall CRT: the solution is a unique modulo to m=p*q. If I change (1) and (2) like following:
M = C^d (mod p) (3)
and
M = C^d (mod q). (4)
What do you find? M and C^d are both simultaneous solution already! So, they must be MODULO TO p*q, that is
C^d = M (mod pq).
This is exactly what "Since gcd(p,q) = 1, it follows by the Chinese Remainder Theorem that..." means!!!
A simple sentence means a lot!
Actually the problem above is able to give a simple proof even without using CRT:
It can be generalized as following:
To prove that S = M (mod p) ^ S = M (mod q) ==> S = M (mod p*q) where S, M are integers and p,q are prime number
Proof:
S = M (mod p) ==> S*q = M*q (mod p*q) (1)
S = M (mod q) ==> S*p = M*p (mod p*q) (2)
(1) + (2) ==> S(p+q) = M(p+q) (mod p*q) ==> p*q |(S-M)(p+q) (3)
If we can prove gcd(p*q, p+q) = 1, then we can prove p*q| S-M which implies S = M (mod p*q)
So, let's prove gcd(p*q, p+q) = 1 by contradiction:
Assume gcd(p*q, p+q) = k>1 ==> k|p*q and k|p+q
As we know p,q are prime number, k|p*q ==> k|p or k|q ==> k = q or k=p
Let's randomly assume k=p chosen from two cases, this implies that k|p+q <==> p|p+q ==> p = -q (mod p)
since p, q are all prime this leads to a contradiction.
So, we proved gcd(p*q, p+q) =1 then we proved
S = M (mod p) ^ S = M (mod q) ==> S = M (mod p*q)
And it is way other then using Chinese Remainder Theorem.
Is this a proof of Fermat's Little Theorem?(No! It is wrong.)
(these are some rough idea which turn out to be wrong later while I was trying to prove Fermat's Little
theorem.)
1.
To prove a^p = 1 (mod p) where p is prime
let's assume a^1 = q1 (mod p) where q1 is modulo of a modulo p
then a^2 mod p = ((a mod p)*(a mod p)) mod p
or in general, a^k mod p = ((a^k-1 mod p)*(a^1 mod p)) mod p for some integer k
So, we can have: ( q[k] stands for variable q with index k, or qk)
a^1 = q[1] (mod p)
a^2 = q[1]*q[1] = q[2] (mod p)
a^3 = q[2]*q[1] = q[3] (mod p)
...
a^p-1 = q[k-2]*q[1] = q[p-1] (mod p)
a^p = q[p-1]*q[1] = q[p] (mod p)
2. Originally I thought a^k mod p will be different for all k such that 1<k<p where p is prime. Then we can assert that at point
of k = p, there will be a repeat of whatever number among 1<k<p. Because every number modulo p will have only p different outcome.
Since p is prime and does not divides a, there will be no 0. So there will be at most p-1 different outcome. So, there will be one
repeating point after k varies from 1 till p.
However, it turn out my conjecture is wrong! Even p is a prime, the outcome is not necessarily different between 1 and p-1. There
are repeating before p.
A recursive formulae of number of partitions in a set
Question: For a set S with n elements, how many different partitions can S have?
Solution:(n>0)
Select one element x from S, for any partition in S, x will be either in a subset with 0 or 1 or 2... or n-1 other elements. In general, x is combined with i
other elements, that is n-1 choose i, and the rest of n-1-i elements will have f(n-1-i) different partitions. Then the total number of partition of set of n elements
is the summation of this 0,1,2,...n-1 cases.
f(0) = 1
f(1) = 1xf(0) = 1
f(2) = 1xf(1) + 1xf(0) = 1+1 =2
f(3) = 1xf(2) + 2xf(1) +1xf(0) = 1x2 + 2x1 +1x1 = 5
f(4) = 1xf(3) + 3xf(2) + 3xf(1) + 1xf(0) = 1x5 + 3x2 + 3x1 +1 = 15
...
I tested it with a small C++ program which runs out a result like following:
for n = 0 the number of partition is:1
for n = 1 the number of partition is:1
for n = 2 the number of partition is:2
for n = 3 the number of partition is:5
for n = 4 the number of partition is:15
for n = 5 the number of partition is:52
for n = 6 the number of partition is:203
for n = 7 the number of partition is:877
for n = 8 the number of partition is:4140
for n = 9 the number of partition is:21147
for n = 10 the number of partition is:115975
for n = 11 the number of partition is:678570
for n = 12 the number of partition is:4213597
for n = 13 the number of partition is:27644437
for n = 14 the number of partition is:77914768
for n = 15 the number of partition is:87994816
for n = 16 the number of partition is:167925467
for n = 17 the number of partition is:167951632
for n = 18 the number of partition is:167951633
for n = 19 the number of partition is:671806533
The number increases so fast that my computer takes too long time to give out result beyond 30.
How to prove gcd(a,b)=gcd(a+b,a)?
The problem
A string that contains 0s,1s and 2s is called a ternary string. Find the number of ternary strings that contain
no consecutive 0s.(The original problem is to find string that DOES contain consecutive 0s. But it is almost same
question as you can find it by using 3^n to minus it. Understand?)
The original question is to find recursive relation for consecutive 0's, then why go such a long way to find "NON-CONSECUTIVE 0'S"?
Let's define
P(n) = { ternary strings of length n that has at least two consecutive 0's} and our goal is to find out size of P(n) or |P(n)|, right?
Q(n) = { ternary string of length n that has non-consecutive 0's}
Apparently a ternary string of length n is the union of P(n)UQ(n). Hence, 3^n = |P(n)| + |Q(n)|
Then it is obviously P(n) comes from by adding a number at end of n-1 ternary string:
case1: The n-1 string is a string that has at least two consecutive 0's, or P(n-1), then adding one more bit holds the property. So, we have 3 choices to add
the last number to the end of n-1 string---0,1 and 2. That is 3x|P(n-1)|
case2: The n-1 string is a string that has non-consecutive 0's, or Q(n-1).
subcase1: The Q(n-1) string is ended with 1 or 2: It is impossible to make a string with consecutive 0's by adding one number at end. However, it is
useful for us to calculate. Try to observe that this "n-1 string without consecutive 0's ended with 1 or 2" is coming from "n-2 string without consecutive
0's" by adding either 1 or 2, or 2x|Q(n-2)|.
subcase2: The n-1 string is ended with 0: We have one choice by adding a 0 at end to make it a consecutive-0s-string.
Along with subcase1, we know the number of this case is |Q(n-1)| - 2x|Q(n-2)|
Therefore we get two function:
|P(n)| = 3x|P(n-1)| + |Q(n-1)| - 2x|Q(n-2)|
3^n = |P(n)| + |Q(n)|
Solve them we get:
|P(n)| = 3^(n-1) - 2x3^(n-2) + 2x|P(n-2)| + 2x|P(n-1)|
Problem. Let G be a planar graph with n vertices, e edges,
r regions, and k connected components.
Prove or disprove that r-e+v=k+1.
Solution:
We know for each connected graph, there is a Euler Formula. So, for the k connected components, each one satisfy
the Euler Formula.
Let's define
r(n) = number of regions in nth components.
e(n) = number of edges in nth components.
v(n) = number of vertices in nth components.
Then according to Euler Formula, r(n) - e(n) + v(n) = 2 where n=1,2,...k (1)
And we know the sum of v(n) for n=1,2,...k is equal to v. Because the graph G is the union of all k components. So the sum of e(n) is equal to e. However, for the sum of r(n), the k components counts the common outside region k times. That is r = sum of r(n) - (k-1).
So, we sum up the (1) for all k components, we get
[r+(k-1)] - e + v = 2xk
==> r - e + v = k+1
Q.E.D.
some questions about your solution in graph
Here is the two questions:
1. How many non-isomorphic directed simple graphs are there with 2 vertices?
4. Show that connected graph with n vertices has at least n-1 edges.
A doubt about the basis proof of mathematical induction
So it is said.
So it is written.
Hotmail wrote:
> Hi sir,
>
> I am not sure if we can use a vacuous proof for the basis of
> mathematical induction.
> Say, we have a proposition P(n)==>Q(n). But we choose a base n such
> that P(n) is false. That is the hypothesis is false and the proposition
> is definitely true. Can we do the basis proof of mathematical induction
> like this?
Suppose you have a proposition A(n) : "P(n)-->Q(n)".
Suppose you want to prove that A(n) is true for all n>0.
Regardless of your method of proof you must show, either explicitly
or implicitly, that
A(1), A(2), A(3), ...., A(k), ..., for all k>0.
> Because what I understand for mathematical induction is that we must at
> least find an element to be true for the problem set.
True.
> Since we are using
> this vacuous proof, we actually find no case to be true for the proof,
> right?
Not necessarily.
>
> I invented a simple proposition like this:
> "For all nature number n, if n>=2 then n>1."
So A(n): "(n>=2)-->(n>1)"
> Basis: when n=1, the hypothesis is false, the proposition is true.
BASIS: A(1) is vacuously true.
INDUCTION HYPOTHESIS: Assume A(n) is true for n>1 (NOT for n>=1).
PROVE: A(n)-->A(n+1) is true.
> Assume: for some number k>=1 that the proposition holds. That is
> k>1. (At this stage, it already puzzles me. k>=1 ==> k>1????)
> Then: when n = k+1, k+1>k ==> k+1>1 (according to hypothesis k>1,
> and the transitive property of unequality)
> Q.E.D.
>
You should prove: [(n>=2)-->(n>1)]==> [(n+1>=2)-->(n+1>1)]
Please read: How to read and do proofs, by Daniel Solow,
ISBN: 0471866458
Best wishes,
Sadegh Ghaderpanah
Comp 239/1 AA
Let's define expression like following:
Assume P is a set then we use P' to denote complement of P. (Because my favorite bar cannot be typed here.)
Conjecture: |A - B| = |A| - |B| (1)
Solution (or ideas): Of course it is not true, as even primary student can figure out that |3-5| !=|3| -|5|.
But this is from the concept of absolution of algebra, how is set?
It is true only if B is a subset of A. Is it same as |A|>|B|?
No! In set scope, NO PROPERTY CAN BE COMPARED UNLESS THEY FALL IN SAME SET. It is same thing to consider that
an elephant has more legs than a monkey's eyes!
Proof: suppose B is a subset of A, or B U C = A for some set of C where C is another subset of A
{I use 'U' stands for Union.}
We can carefully choose C such that C is disjoint with B or in other words,C = B' where the universal set is
A. Then the formula (1) is quite obviously true:
LHS = |AnB'| = |B'| = |C|
RHS = |BUC| - |B| = |BUB'| - |B| = |B| + |B'| - |BnB'|| - |B| = |B'| = |C|
Because we can use the basic rule of size of union: |PUQ| = |P|+|Q|+|PnQ|
{I use 'n' stands for intersection.}
Is this assumed to be a proof?
And what is the profound meaning of this simple formula? It implies that arithmetic is a kind of reflection
of set. Is arithmetic alone? Haha, anything, anywhere, anytime, it is like the Matrix. Besides matrix is only
an expressing method of relation of elements in a set.
A rough explanation of strong form of mathematical induction
In text P249(Discrete mathematical 5th edition), a definition of strong form of mathematical induction was
given:
Basis: P(1) is true;
Inductive: It is shown that [P(1)^P(2)^...^P(k)]--> P(k+1) is true for every positive integer k.
It puzzled me for a long time! Since the usual strong form of MI is that if you need two assumption, just
prove two basis, if three assumptions are needed, prove three. For example, first prove P(1), P(2),P(3) is
true, then assume P(k),P(k+1), P(k+2) is true, try to prove that P(k+3) is true. It seems irrelevant with
the definition of text. Because the definition seems only requires one P(1) to be true.
But NOTICE that it is required for EVERY k to be true in the inductive step!
Suppose k=1, it is equivalent to say that P(1)-->P(2)
Suppose k=2, it is equivalent to say that [P(1)^P(2)]-->P(3)
Suppose k=3, it is equivalent to say that [P(1)^P(2)^P(3)]-->P(4)
...
We know that P(1) is true, so P(2) is also true by P(1)-->P(2). On and on... P(k) is also true.
But I observed it implies: P(1)-->[P(2)-->[P(3)-->[...P(k-1)-->P(k)]...]]
![]()
![]()
![]()