OBJETIVO
• Aprender a generar o realizar un analizador léxico y el estudio del mismo.
• Distinguir entre la sintaxis y la semántica de un lenguaje.
• El objetivo es realizar un analizador léxico que nos ayude a comprender el contenido de la materia de Lenguajes y Autómatas y poner en práctica los conocimientos adquiridos.
INTRODUCCIÓN
En 1946 se desarrolló el primer ordenador digital. En un principio, estas máquinas ejecutaban instrucciones consistentes en códigos numéricos que señalan a los circuitos de la máquina los estados correspondientes a cada operación. Esta expresión mediante códigos numéricos se llamó Lenguaje Máquina, interpretado por un secuenciador cableado o por un microprograma. Pero los códigos numéricos de las máquinas son engorrosos. Pronto los primeros usuarios de estos ordenadores descubrieron la ventaja de escribir sus programas mediante claves más fáciles de recordar que esos códigos numéricos; al final, todas esas claves juntas se traducían manualmente a Lenguaje Máquina. Estas claves constituyen los llamados lenguajes ensambladores, que se generalizaron en cuanto se dio el paso decisivo de hacer que las propias máquinas realizaran el proceso mecánico de la traducción. A este trabajo se le llama ensamblar el programa.
Dada su correspondencia estrecha con las operaciones elementales de las máquinas, las instrucciones de los lenguajes ensambladores obligan a programar cualquier función de una manera minuciosa e iterativa. De hecho, normalmente, cuanto menor es el nivel de expresión de un lenguaje de programación, mayor rendimiento se obtiene en el uso de los recursos físicos (hardware). A pesar de todo, el lenguaje ensamblador seguía siendo el de una máquina, pero más fácil de manejar.
FORTRAN (FORmulae TRANslator). Fue el primer lenguaje considerado de alto nivel. Se introdujo en 1957 para el uso de la computadora IBM modelo 704. Permitía una programación más cómoda y breve que lo existente hasta ese momento, lo que suponía un considerable ahorro de trabajo. Surgió así por primera vez el concepto de un traductor, como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de que el lenguaje a traducir es un lenguaje de alto nivel y el lenguaje traducido de bajo nivel, se emplea el término compilador.
Existe gran variedad de lenguajes fuente y lenguajes objeto. Un lenguaje objeto puede ser otro lenguaje de programación o un lenguaje máquina de cualquier computador, pudiendo tener éste uno o varios procesadores.
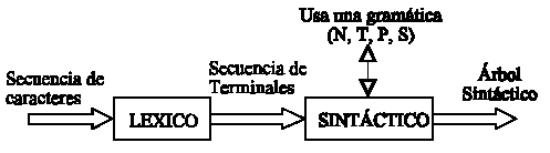
Este trabajo estudia la primera fase de un compilador, es decir, su análisis lexicográfico, o más concisamente análisis léxico, envolviendo otro aspecto de un compilador. Las técnicas utilizadas para construir analizadores léxicos también se pueden aplicar a otras áreas, como, por ejemplo, a lenguajes de consulta y sistemas de recuperación de información. En cada aplicación, el problema de fondo es la especificación y diseño de programas que ejecuten las acciones activadas por palabras que siguen ciertos patrones dentro de las cadenas a reconocer. Por otro lado, una herramienta software que automatiza la construcción de analizadores léxicos permite que personas con diferentes conocimientos utilicen la concordancia de patrones en sus propias áreas de aplicación.
DEFINICIÓN.
Se encarga de buscar los componentes léxicos o palabras que componen el programa fuente, según unas reglas o patrones. La entrada del analizador léxico podemos definirla como una secuencia de caracteres.
gramática (N, T, P, S)
N ::= Símbolos no terminales.
T ::= Símbolos terminales
P ::= Reglas de producción
S ::= Axioma inicial
El analizador léxico tiene que dividir la secuencia de caracteres en palabras con significado propio y después convertirlo a una secuencia de terminales desde el punto de vista del analizador sintáctico, que es la entrada del analizador sintáctico.
El analizador léxico reconoce las palabras en función de una gramática regular de manera que sus NO TERMINALES se convierten en los elementos de entrada de fases posteriores.
Funciones del analizador léxico
El analizador léxico es la primera fase de un compilador. Su principal función consiste en leer los caracteres de entrada y elaborar como salida una secuencia de componentes léxicos que utiliza el analizador sintáctico para hacer el análisis. Esta interacción, suele aplicarse convirtiendo al analizador léxico en una subrutina o corrutina del analizador sintáctico. Recibida la orden "Dame el siguiente componente léxico" del analizador sintáctico, el analizador léxico lee los caracteres de entrada hasta que pueda identificar el siguiente componente léxico.
Otras funciones que realiza:
• Eliminar los comentarios del programa.
• Eliminar espacios en blanco, tabuladores, retorno de carro, etc, y en general, todo aquello que carezca de significado según la sintaxis del lenguaje.
• Reconocer los identificadores de usuario, números, palabras reservadas del lenguaje,..., y tratarlos correctamente con respecto a la tabla de símbolos (solo en los casos que debe de tratar con la tabla de símbolos).
• Llevar la cuenta del número de línea por la que va leyendo, por si se produce algún error, dar información sobre donde se ha producido.
• Avisar de errores léxicos. Por ejemplo, si @ no pertenece al lenguaje, avisar de un error.
• Puede hacer funciones de preprocesador.
DESARROLLO
Análisis de UN programa fuente
El análisis consta de tres fases:
• Análisis lineal (o léxico): Se lee la cadena de caracteres de izquierda a derecha agrupando componentes léxicos, que son secuencias de caracteres que tienen un significado como agrupación.
• Análisis jerárquico (o sintáctico) : En el que los caracteres o componentes léxicos se agrupan jerárquicamente en colecciones anidadas.
• Análisis semántico : Se realizan comprobaciones para asegurar que los componentes se ajustan de un modo significativo.
• AnÁlisis lÉxico
Realiza el análisis léxico. Dada la expresión:
posición := inicial + velocidad * 60
Se obtendrían los siguientes componentes léxicos:
- El identificador posición
- El símbolo de asignación :=
- El identificador inicial
- El símbolo de suma
- El identificador velocidad
- El símbolo de multiplicación
- El número 60
• Análisis sintáctico
Es un análisis de tipo jerárquico. Los componentes léxicos del programa fuente se agrupan en frases gramaticales que el compilador utiliza para sintetizar la salida. Las frases se representan mediante un árbol de análisis sintáctico.
La estructura jerárquica de un programa normalmente se expresa utilizando reglas recursivas. Por ejemplo, podemos dar las siguientes reglas para construir expresiones:
1. Cualquier identificador es una expresión,
2. Cualquier número es una expresión,
3. Si expresión1 y expresión2 son dos expresiones, entonces también lo son:
a) Expresión1 + expresion2
b) Expresion1 * expresion2
c) (expresion1)
La división entre análisis léxico y análisis sintáctico puede ser arbitraria. Un factor a considerar es si una construcción es inherentemente recursiva o no. Las construcciones léxicas no requieren recursión, mientras que la construcciones sintácticas suelen requerirla. No se requiere recursión para reconocer los identificadores, que se agrupan en una tabla, llamada tabla de símbolos.
• Análisis semántico
La fase de análisis semántico revisa el código fuente para tratar de encontrar errores semánticos y reúne información sobre los tipos para la fase posterior de generación de código.
También se lleva a cabo la verificación de tipos. En el análisis semántico se realizan comprobaciones de los tipos permitidos por un operador; en caso de que no coincidan con los permitidos se generará un error o se realizarán las operaciones de conversión necesarias (coerción).
• Análisis en formadores de texto.
Los formadores o formateadores de texto realizan un análisis considerando una jerarquía de cajas: regiones rectangulares que se contienen elementos léxicos. Un ejemplo de éste es TEX.
Las fases de un compilador:
Las principales fases son:
Análisis léxico,
Análisis sintáctico,
Análisis semántico,
Generación de código intermedio,
Optimización,
Generación de código objeto.
La tabla de símbolos
Una tabla de símbolos es una estructura de datos que contiene una entrada por cada identificador, cada una con los atributos:
• Nombre,
• Tipo,
• Ámbito,
Y se trata de un procedimiento o función también:
• Número de argumentos,
• Tipos de los argumentos,
• Paso por parámetro o referencia,
• Tipo que devuelve.
La mayoría de los atributos son establecidos durante el análisis semántico.
Detección de errores:
Cada fase puede encontrar errores. Cuando se encuentra un error, la fase que lo ha detectado tiene de alguna forma que recuperarse para poder seguir con el análisis. De esta forma se quiere conseguir que el compilador reporte la máxima cantidad de errores.
Cada fase detecta un tipo de error:
• Léxico: la cadena de entrada no conforma ningún componente léxico,
• Sintáctico: los componentes léxicos incumplen alguna regla sintáctica,
• Semántico: una construcción no tiene el significado semántico apropiado.
Herramientas para la construcción de compiladores
Algunas de estas herramientas son las siguientes:
Generadores de analizadores sintácticos. Producen analizadores sintácticos, normalmente a partir de una entrada fundamentada en una gramática independiente de contexto.
Generadores de analizadores léxicos. Generan automáticamente analizadores léxicos, por lo general, a partir de una especificación basada en expresiones regulares. La estructura básica del resultado es un autómata finito.
Dispositivos de traducción dirigida por la sintaxis. Estos producen grupos de rutinas que recorren el árbol de análisis sintáctico generando código intermedio. La idea básica es que se asocian una o más traducciones con cada nodo del árbol y cada traducción se define partiendo de traducciones en sus nodos vecinos en el árbol.
Generadores automáticos de código. Tales herramientas toman un conjunto de reglas que definen la traducción de cada operación del lenguaje intermedio al lenguaje máquina para la máquina objeto. Las reglas deben incluir suficiente detalle para poder manejar distintos métodos de acceso a los datos.
Dispositivos para el análisis de flujo de datos. Consiste en la recolección de información sobre la forma en que se transmiten los valores de una parte de un programa a cada una de las otras partes.
Proceso de especificación del analizador léxico
1. Obtener el conjunto de elementos léxicos (tokens) considerado en el lenguaje diseñado en la práctica anterior.
2. Confeccionar la tabla de tokens, la cual deberá recoger la siguiente información:
• Token.
• Código asignado al token.
3. Confeccionar las especificaciones LEX y el correspondiente analizador de léxico. Igualmente, deberá añadirse la especificación LEX necesaria, junto con su expresión regular correspondiente, para el tratamiento de los comentarios asociados al código fuente de cualquier programa en nuestro lenguaje, de manera que se detecten dichos comentarios.
4. Completar la tabla de tokens elaborada en el punto 2, de manera que se añada para cada token el patrón elaborado en la especificación LEX, mostrándose por tanto la siguiente información:
• Token.
• Patrón.
• Código asignado al token.
5. Probar el analizador léxico elaborado con distintos ficheros que contendrán los correspondientes programas de prueba.
Necesidad del analizador léxico
Un tema importante es el porqué se separan los dos análisis lexicográfico y sintáctico, en vez de realizar sólo el análisis sintáctico, del programa fuente, cosa perfectamente posible aunque no plausible. Algunas razones de esta separación son:
Un diseño sencillo es quizás la consideración más importante. Separar el análisis léxico del análisis sintáctico a menudo permite simplificar una u otra de dichas fases. El analizador léxico nos permite simplificar el analizador sintáctico.
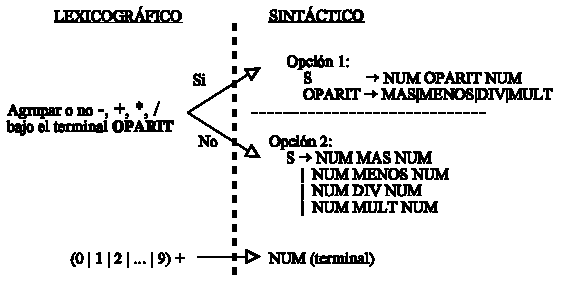
Si el sintáctico tuviera la gramática de la Opción 1 , el lexicográfico sería:
Opción 1:
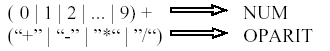
Si en cambio el sintáctico toma la Opción 2, el lexicográfico sería:
Opción 2:
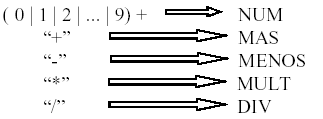
Es más, si ni siquiera hubiera análisis léxico, el propio análisis sintáctico vería incrementado su número de reglas:
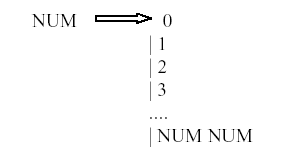
A modo de conclusión, diremos que tenemos dos gramáticas, una que se encarga del análisis léxico y otra que se encarga del análisis sintáctico. ¿Que consideramos componente básico?, ¿Donde ponemos el punto divisor de qué se encarga cada gramática?. Si las divisiones se hacen muy pequeñas estamos complicando la gramática, por ejemplo, en la opción 2, la gramática sintáctica se nos complica un poco. Seguiremos dos reglas para que no se nos complique. La primera es que tendremos que hacer divisiones de forma que no perdamos información, esto quedará más claro en capítulos posteriores, y nos veremos ayudados por el concepto de atributo . La segunda es que por regla general el analizador lexicográfico debe de encargarse de la parte que involucra una gramática regular (que nosotros expresaremos mediante expresiones regulares).
Se mejora la eficiencia del compilador. Un analizador léxico independiente permite construir un procesador especializado y potencialmente más eficiente para esa función. Gran parte del tiempo se consume en leer el programa fuente y dividirlo en componentes léxicos. Con técnicas especializadas de manejo de buffers para la lectura de caracteres de entrada y procesamiento de componentes léxicos se puede mejorar significativamente el rendimiento de un compilador.
Se mejora la portabilidad del compilador. Las peculiaridades del alfabeto de entrada y otras anomalías propias de los dispositivos pueden limitarse al analizador léxico. La representación de símbolos especiales o no estándares pueden ser aisladas en el analizador léxico.
Otra razón por la que se separan los dos análisis es para que el analizador léxico se centre en el reconocimiento de componentes básicos complejos.
En éste lenguaje los espacios en blancos no son significativos fuera de los comentarios y de un cierto tipo de cadenas, de modo que supóngase que todos los espacios en blanco eliminables se suprimen antes de comenzar el análisis léxico.
El analizador ha tenido que mirar más allá de la propia palabra a reconocer haciendo lo que se denomina lookahead (o prebúsqueda).