Introducción
Se construirá un programa "xecnx.exe"
que tome páginas HTML de avisos económicos y extraigan un documento en formato
XML con la información relevante al documento.
El programa debe ser capaz de extraer toda la información de cada anuncio económico. También debe manejar la codificación que es usual en este tipo de avisos.
Se utilizarán las siguientes páginas de Internet para realizar el trabajo como referencia:
Esta documentación se puede consultar vía Internet a través de la siguiente dirección:
http://www.geocities.com/mlvcr3/Tarea_Programada_01.html
Para descargar los archivos con la solución:
http://www.geocities.com/mlvcr3/896061-A24496_TP01.zip
Metodología
Análisis de los formatos de las diferentes páginas con el fin de discriminar información.
Trabajo de manera conjunta en la etapa de definición y estructura básica de la solución.
La etapa de integración se hará de manera conjunta al igual que la realización de las pruebas y la edición de los respectivos manuales (manual de usuario y manual de programador).
Análisis del Problema
La funcionalidad de la aplicación radica en recopilar solamente la información pertinente a los anuncios económicos, sin tomar en cuenta el formato de la página ni otros vínculos con otro tipo de importancia.
La extracción de la información se hará a partir de archivos guardados con extensión HTML y no propiamente leídas desde servidores. En el caso del página de clasificados del diario la extra, el código fuente es de extensión “php”, aun así el programa esta diseñado para aceptar cualquier nombre de archivo presente en la carpeta principal, pero el análisis esta orientado aun archivo de formato HTML, específicamente la del diario La Extra.
Los valores de entrada corresponden a los archivos HTML que se obtuvieron de la página del diario la extra de la sección de económicos.
La salida es un archivo XML con la estructura jerárquica. El usuario deberá incluir todos los documentos HTML que desea analizar y el programa generará un documento con la información de estos.
Se creará una estructura de datos que almacenará la información extraída del archivo ingresado, en dicha estructura se clasificará la información, para luego generar el archivo salida, esto mediante un diccionario construido previamente.
Abstracción
Diagrama de Clases
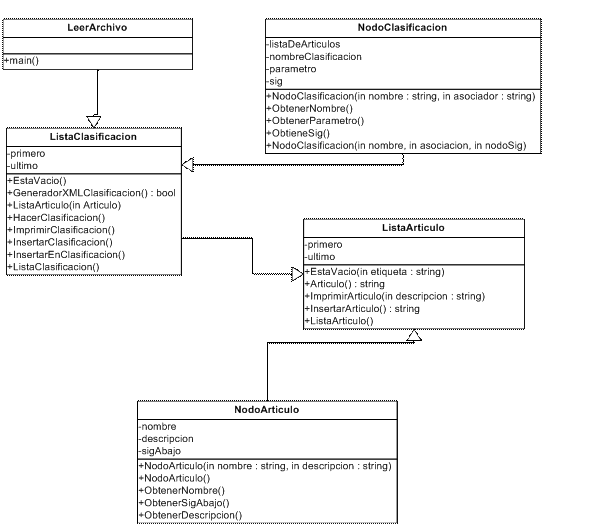
Descripción de cada clase
Clase LeerArchivo
Descripción: hace la extracción y análisis del texto solicitado para que este pueda luego ser insertado en la estructura de datos. Contiene el método principal que permite la manipulación de toda la aplicación.
Métodos:
public static void main(String[] args): manipula la construcción del diccionario que es creado a partir de un archivo llamado “TipoClasificación.txt”. Encuentra el inicio y el final del bloque de clasificados. Analiza el archivo “php”. Crea el archivo “preClasificados.txt” ya depurado. Construye el archivo XML
Requiere: que el o los archivos HTML existan.
Clase ListaClasificacion
Descripción: permite la creación de la estructura de datos que contendrá las clasificaciones de los anuncios.
Atributos:
primero: apuntador a la primera clasificación.
ultimo: apuntador a la última clasificación.
Métodos:
EstaVacio(): determina si la lista contiene algún anuncio o esta vacía.
Requiere: que la lista exista.
Retorna: true si la lista esta vacía y false si no.
GeneradorXMLClasificacion(): recorrer la lista de clasificaciones y la concatena a una cadena de caracteres. Hace un llamado a GeneradorXMLArticulo() de la clase ListaArticulo para obtener los anuncios asociados.
Requiere: la existencia de clasificaciones en la lista.
Retorna: la cadena de caracteres con las clasificaciones y los anuncios.
HacerClasificacion(): crea una lista de clasificaciones. Almacena el nombre de la clasificación. Almacena los descriptores de esa clasificación (diccionario).
Requiere: que el archivo “TipoClasificacion.txt” exista.
ImprimirClasificacion(): Imprime la clasificación y sus anuncios.
Requiere: que la lista de clasificaciones exista.
InsertarClasificacion(): Inserta cada clasificación
Requiere: Requiere: que el archivo “TipoClasificacion.txt” exista.
InsertarEnClasificacion(): Inserta cada anuncio en su respectiva clasificación
Requiere: que la lista de clasificaciones exista.
ListaClasificacion(): Constructor de la clase clasificación
Clase NodoClasificación
Descripción: permite crear una instancia de tipo clasificación
Atributos:
listaDeArticulos: apuntador a la lista de Articulos
nombreClasificación: permite almacenar el nombre de la clasificación.
parametro: vector que almacena los
descriptores de la descripción
sig: apuntador a la siguiente clasificación
Métodos:
NodoClasificación(string nombre, asociador): constructor de la clase clasificación cuando no hay nodos
NodoClasificación(string nombre, asociador, sigNodo): constructor de la clase clasificación cuando hay nodos insertados
ObtenerNombre(): retorna el nombre de la clasificación.
Requiere: que la clasificación exista.
Retorna: la clasificación
ObtenerParametro(): retorna el vector que contiene que contiene el diccionario de cada clasificación.
Requiere: que la descripción exista.
ObtieneSig(): retorna la siguiente Clasificación.
Requiere: que el anuncio exista.
Retorna: un puntero a la siguiente clasificación
Clase ListaArticulo
Descripción: permite la creación de la estructura de datos que contendrá los anuncios econòmicos
Atributos:
primero: apuntador al primer artículo.
ultimo: apuntador al último artículo.
Métodos:
EstaVacio(): determina si la lista contiene algún anuncio o esta vacía.
Requiere: que la lista exista.
Retorna: true si la lista esta vacía y false si no.
GeneradorXMLArticulo(): recorrer la lista de anuncios y la concatena a una cadena de caracteres.
Requiere: la existencia de anuncios en la lista.
Retorna: la cadena de caracteres con los anuncios.
ImprimirArticulo(): imprime toda la lista de artículos.
Requiere: la existencia de anuncios en la lista.
InsertarArticulo(): inserta un anuncio en la lista de artículos.
Requiere: que la lista exista.
ListaArticulo(): constructor de la clase.
Clase NodoArtículo
Descripción: permite crear una instancia de tipo artículo
Atributos:
nombre: permite almacenar el nombre del artículo
descripción: permite almacenar la descripción del artículo.
sigAbajo: apuntador al siguiente articulo
Métodos:
NodoArticulo(string nombre, descripcion): constructor de la clase articulo cuando no hay nodos
NodoArticulo(string nombre, descripción,sigAbajo): constructor de la clase articulo cuando hay nodos insertados
ObtenerNombre(): retorna el nombre del anuncio.
Requiere: que el anuncio exista.
Retorna: el anuncio
ObtenerSigAbajo(): retorna el siguiente anuncio.
Requiere: que el artículo exista.
Retorna: el nodo al siguiente artículo
ObtenerDescripción(): retorna la descripción del anuncio.
Requiere: que el anuncio exista.
Retorna: el anuncio
La solución esta orientada a la estructura muy particular de la página del diario La Extra es eficiente para ella mas, si la estructura del código varía la aplicación no funcionaría de manera correcta, si la cantidad anuncios crece el tiempo de procesamiento aumenta. El orden de duración sería aproximadamente O(n2)
Descripción de algoritmos complejos
Algoritmo Insertar En Clasificación
Lee el archivo preclasificados
Mientras (existan líneas en el archivo) {
PosicionarseEnElPrimeroDeLista
Mientras (halla clasificacion por revisar y no pueda ubicar a anuncio en clasificacion){
Mientras (no encuentre palabra en diccionario) {
Si (no encuentre la palabra) {
buscarSiguientePalabra
}Si palabra fue encontrada
indicarPalabraEncontrada
}
}
Si (palabraEncontrada) {
InsertarAnuncioEnClasificacion();
}Si no encontró palabra en diccionario
Avanzar a la siguiente Clasificación
}
}
Si (no se pudo ubicar a anuncio){
ponerAnuncioEnCategoríaGeneral();
}
}
Cerrar Archivo de Preclasificados
}
Compilador Usado
El programa fue desarrollado en lenguaje Java.
La versión del compilador utilizado es Java JBuilder Enterprise X.
Pasos para realizar el proceso de compilación:
- Descargar la aplicación desde la pagina Web:
- Entrar al programa JBuilder
- Dentro del programa de JBuilder, en el menú Archivo elegir la opción Abrir Proyecto y buscar en la carpeta Traductor el archivo “Traducto.jpx”
- Presione Abrir
- En
la barra de herramientas presione el botón Ejecutar Proyecto

Manual de Usuario
- Entrar al programa JBuilder (previamente instalado en su computadora).
- Presione el botón Play que se encuentra en la barra de herramientas
- Dentro del programa de JBuilder, en el menú Archivo elegir la opción Abrir Proyecto y buscar en la carpeta Traductor el archivo “Traducto.jpx”
- Presione Abrir
- En
la barra de herramientas presione el botón Ejecutar Proyecto
- Se le presentará la siguiente pantalla:
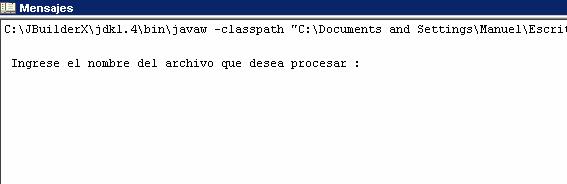
- Digite el nombre del archivo con su extensión que desea procesar
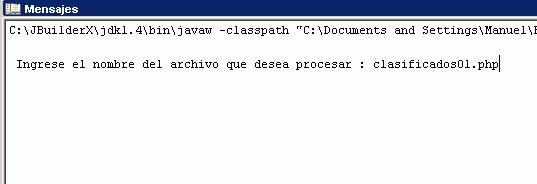
- Presione la tecla Enter y aguarde a que inicie el procesamiento del archivo
- En pantalla aparecerá un mensaje indicando que los anuncios fueron acomodados
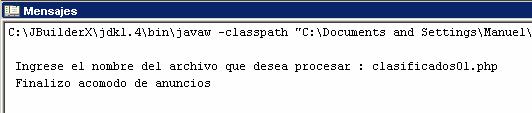
- Seguidamente se mostrará la secuencia de líneas que están siendo procesadas
- Por último el programa indicará que finalizó el procesamiento
- Verifique que el archivo indicado se creó en la raíz de la carpeta Traductor
Datos de Prueba
La salida del programa debe ser un archivo de formato XML y que muestre los anuncios extraídos de manera clasificada.
A continuación se presentan el procesamiento de 3 archivos extraídos de la página del diario extra que corresponden a las fechas 2007_01_19_clasificados01.php.htm, 2007_02_19_clasificados01.php.htm y 2007_03_19_clasificados01.php.htm, que corresponden a los archivos de entrada.
Las salidas de acuerdo a cada archivo son:
Código Fuente
package
traductor;
import
java.io.*;
import
java.util.*;
public
class LeerArchivo {
//Manipula la construcción del diccionario que es creado a partir de un archivo
//llamado “TipoClasificación.txt” donde se encuentran las diferentes clasificaciones
//con sus correspondientes palabras que describen cada una de ellas y que permite
//comparar dichas palabras con cada anuncio para discernir cuales corresponden a cada uno
public static void main(String[] args) throws
IOException {
String archivoOriginal = new String();
//Construye el diccionario con las clasificaciones de los diversos anuncios
//Lo llena con una jerarquía para los anuncios
ListaClasificacion miLista = new ListaClasificacion();
miLista.HacerClasificacion();
BufferedReader in = new BufferedReader(new
InputStreamReader(System.in));
System.out.print("\n Ingrese el nombre del archivo que desea procesar : ");
archivoOriginal = in.readLine();
//Leer el código de la página HTML que será el archivo de entrada
BufferedReader archivoEntrada = new
BufferedReader(new FileReader(archivoOriginal));
//Variables para el manejo del contenido del archivo leído
String archivoLeidoParcial,
archivoLeidoCompleto = new String(); //
//Determina el inicio del bloque de texto con los clasificados
String textoInicioC ="Inicia texto noticia";
//Determina el final del bloque de texto con los clasificados
String textoFinalC = "Cierra Texto Noticia";
//Verifica si se encontraron los bloques buscados
boolean encontrarInicio=false;
boolean encontrarFinal = false;
//Busca el inicio de la sección de clasificados
//Lee mientras no llegue a línea nula
while (((archivoLeidoParcial = archivoEntrada.readLine()) != null)&& (encontrarInicio==false)) {
//Si encuentra el bloque indicado
if (archivoLeidoParcial.indexOf(textoInicioC) != -1){
//Se sale del ciclo al encontrar el inicio de clasificados
encontrarInicio = true;
}
}
//Busca el final de la sección de clasificados y va concatenando la información leída
while (((archivoLeidoParcial = archivoEntrada.readLine()) != null) && (encontrarFinal==false)) {
//Si no ha llegado al final de los clasificados concatena la línea leída
if (archivoLeidoParcial.indexOf(textoFinalC) == -1){
archivoLeidoCompleto += archivoLeidoParcial;
}else{
//Se sale del ciclo al encontrar el final de los clasificados
encontrarFinal = true;
}
}
//Cierra el archivo que se indicó como entrada
archivoEntrada.close();
//Se establecen los "tokens" que contiene el archivo
//Esto ayuda a eliminar espacios en blanco que sean innecesarios
StringTokenizer st = new
StringTokenizer(archivoLeidoCompleto);
//Almacena el texto que se va construyendo con tildes y caracteres especiales
//quitando espacios en blanco y etiquetas que no correspondan al formato XML
String textoAnalizado= new String();
//Cada hilera de caracteres o "token" identificado dentro del texto
String tokenLeido = new String();
//Variables para la manipulación y edición de tokens
int tamanoToken=0; // Tamaño de un token
int posTokenInicio=0; // Inicio de un token
String partePalInicial=""; // Prefijo de un token
String partePalFinal=""; // Sufijo de un token
//Hacer mientras hayan palabras(tokens) que leer
while (st.hasMoreTokens()) {
//Leer el siguiente token (hilera de caracteres)
tokenLeido=st.nextToken();
//Si dentro de la hilera leída se encuentra la hilera "0000"
if((tokenLeido.indexOf("0000"))!=-1){
//Si la hilera "0000" está al comienzo del token leído
if (tokenLeido.startsWith("0000")) {
//Se substituye la hilera leída por un salto de línea.
textoAnalizado += '\n';
//Si la hilera "0000" está en otra parte del token leído
}else {
//La hilera "0000" corresponde a un monto de dinero
//Caso excepcional de un monto sin separador con , o .
if((tokenLeido.indexOf("¢"))!=-1){
posTokenInicio=tokenLeido.indexOf("¢");
partePalInicial=tokenLeido.substring(0,posTokenInicio);
partePalFinal=tokenLeido.substring(posTokenInicio+6);
tokenLeido=partePalInicial+"¢"+partePalFinal;
}
//Caso presentado en un número telefónico contiene una hilera "0000"
//seguido de <br> al final del token
if(tokenLeido.endsWith("<br>")){
tamanoToken=tokenLeido.length();
tokenLeido=tokenLeido.substring(0,tamanoToken-4);
}
//La hilera leída se agrega al texto analizado dejando un espacio en blanco
textoAnalizado += tokenLeido+" ";
}
//El token leído no contiene la hilera "0000"
}else{
//Si la hilera leida no es igual a "<br>" o "<BR>"
if(!(tokenLeido.equalsIgnoreCase("<br>"))){
//Si la hilera leida no es igual a "<p>" o "</p>" o "<P>" o "</P>"
if(((tokenLeido.indexOf("<p>"))==-1) &&
((tokenLeido.indexOf("</p>"))==-1)) {
//Antes de agregar la palabra verifica si termina en <br> para quitárselo
if(tokenLeido.endsWith("<br>")){
tamanoToken=tokenLeido.length();
tokenLeido=tokenLeido.substring(0,tamanoToken-4);
}
//Se analizan tildes y caracteres especiales
//Se reemplaza "á" por una a tildada
//Busca la hilera "á" dentro del token
while((tokenLeido.indexOf("á"))!=-1){
//Se identifica la posicion dentro del token donde comienza la hilera buscada
posTokenInicio=tokenLeido.indexOf("á");
//Se extrae una sub-hilera desde el comienzo del token hasta donde comienza la hilera buscada
partePalInicial=tokenLeido.substring(0,posTokenInicio);
//Se extrae una sub-hilera desde el final de la hilera buscada hasta el final del token
partePalFinal=tokenLeido.substring(posTokenInicio+8);
//Concatena las dos sub-hileras con el caracter que substituye la hilera encontrada
tokenLeido=partePalInicial+"á"+partePalFinal;
}
//Se reemplaza "é" por una e tildada
//Busca la hilera "é" dentro del token
while((tokenLeido.indexOf("é"))!=-1){
posTokenInicio=tokenLeido.indexOf("é");
partePalInicial=tokenLeido.substring(0,posTokenInicio);
partePalFinal=tokenLeido.substring(posTokenInicio+8);
tokenLeido=partePalInicial+"é"+partePalFinal;
}
//Se reemplaza "í" por una i tildada
//Busca la hilera "í" dentro del token
while((tokenLeido.indexOf("í"))!=-1){
posTokenInicio=tokenLeido.indexOf("í");
partePalInicial=tokenLeido.substring(0,posTokenInicio);
partePalFinal=tokenLeido.substring(posTokenInicio+8);
tokenLeido=partePalInicial+"í"+partePalFinal;
}
//Se reemplaza "ó" por una o tildada
//Busca la hilera "ó" dentro del token
while ( (tokenLeido.indexOf("ó")) != -1) {
posTokenInicio = tokenLeido.indexOf("ó");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "ó" + partePalFinal;
}
//Se reemplaza "ú" por una u tildada
//Busca la hilera "ú" dentro del token
while ( (tokenLeido.indexOf("ú")) != -1) {
posTokenInicio = tokenLeido.indexOf("ú");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "ú" + partePalFinal;
}
//Se reemplaza "¢" por signo de moneda
//Busca la hilera "¢" dentro del token
while (
(tokenLeido.indexOf("¢")) != -1) {
posTokenInicio =
tokenLeido.indexOf("¢");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 6);
tokenLeido = partePalInicial + "¢" + partePalFinal;
}
//Se reemplaza "ñ" por signo eñe minúscula
//Busca la hilera "ñ" dentro del token
while ( (tokenLeido.indexOf("ñ")) != -1) {
posTokenInicio = tokenLeido.indexOf("ñ");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "ñ" + partePalFinal;
}
//Se reemplaza "Ñ" por signo eñe mayúscula
//Busca la hilera "Ñ" dentro del token
while ( (tokenLeido.indexOf("Ñ")) != -1) {
posTokenInicio = tokenLeido.indexOf("Ñ");
partePalInicial = tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "Ñ" + partePalFinal;
}
//Se reemplaza "¿" por signo de interrogación de apertura
//Busca la hilera "¿" dentro del token
while (
(tokenLeido.indexOf("¿")) != -1) {
posTokenInicio =
tokenLeido.indexOf("¿");
partePalInicial = tokenLeido.substring(0,
posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "¿" + partePalFinal;
}
//Se reemplaza "È" por E mayúscula
//Busca la hilera "È" dentro del token
while (
(tokenLeido.indexOf("È")) != -1) {
posTokenInicio =
tokenLeido.indexOf("È");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "E" + partePalFinal;
}
//Se reemplaza "À" por A mayúscula
//Busca la hilera "À" dentro del token
while ( (tokenLeido.indexOf("à")) != -1) {
posTokenInicio =
tokenLeido.indexOf("à");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "á" + partePalFinal;
}
//Se reemplaza "ì" por una i tildada
//Busca la hilera "ì" dentro del token
while (
(tokenLeido.indexOf("ì")) != -1) {
posTokenInicio =
tokenLeido.indexOf("ì");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "í" + partePalFinal;
}
//Se reemplaza "ò" por una o tildada
//Busca la hilera "ò" dentro del token
while (
(tokenLeido.indexOf("ò")) != -1) {
posTokenInicio = tokenLeido.indexOf("ò");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "ó" + partePalFinal;
}
//Se reemplaza "Í" por I mayúscula
//Busca la hilera "Í" dentro del token
while ( (tokenLeido.indexOf("Í")) != -1) {
posTokenInicio = tokenLeido.indexOf("Í");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "I" + partePalFinal;
}
//Se reemplaza "Ú" por U mayúscula
//Busca la hilera "Ú" dentro del token
while ( (tokenLeido.indexOf("Ú")) != -1) {
posTokenInicio = tokenLeido.indexOf("Ú");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "U" + partePalFinal;
}
//Se reemplaza "Á" por A mayúscula
//Busca la hilera "Á" dentro del token
while ( (tokenLeido.indexOf("Á")) != -1) {
posTokenInicio = tokenLeido.indexOf("Á");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal = tokenLeido.substring(posTokenInicio
+ 8);
tokenLeido = partePalInicial + "A" + partePalFinal;
}
//Se reemplaza "É" por E mayúscula
//Busca la hilera "É" dentro del token
while ( (tokenLeido.indexOf("É"))
!= -1) {
posTokenInicio =
tokenLeido.indexOf("É");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "E" + partePalFinal;
}
//Se reemplaza "¡" por signo de exclamación de apertura
//Busca la hilera "¡" dentro del token
while ( (tokenLeido.indexOf("¡")) != -1) {
posTokenInicio = tokenLeido.indexOf("¡");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 7);
tokenLeido = partePalInicial + "¡" + partePalFinal;
}
//Se reemplaza "’" por comilla simple
//Busca la hilera "’" dentro del token
while ( (tokenLeido.indexOf("’")) != -1) {
posTokenInicio = tokenLeido.indexOf("’");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 7);
tokenLeido = partePalInicial + "'" + partePalFinal;
}
//Se reemplaza "“" por comillas dobles
//Busca la hilera "“" dentro del token
while ( (tokenLeido.indexOf("“")) != -1) {
posTokenInicio = tokenLeido.indexOf("“");
partePalInicial = tokenLeido.substring(0,
posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 7);
tokenLeido = partePalInicial + '\"' + partePalFinal;
}
//Se reemplaza "”" por comillas dobles
//Busca la hilera "”" dentro del token
while ( (tokenLeido.indexOf("”")) != -1) {
posTokenInicio = tokenLeido.indexOf("”");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 7);
tokenLeido = partePalInicial + '\"' + partePalFinal;
}
//Se reemplaza "ü" por diéresis
//Busca la hilera "ü" dentro del token
while ( (tokenLeido.indexOf("ü")) != -1) {
posTokenInicio = tokenLeido.indexOf("ü");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 6);
tokenLeido = partePalInicial + "ü" + partePalFinal;
}
//Se reemplaza "º" por signo de grados
//Busca la hilera "º" dentro del token
while ( (tokenLeido.indexOf("º")) != -1) {
posTokenInicio = tokenLeido.indexOf("º");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 6);
tokenLeido = partePalInicial + "º" + partePalFinal;
}
//Se reemplaza "Ó" por O mayúscula
//Busca la hilera "Ó" dentro del token
while ( (tokenLeido.indexOf("Ó")) != -1) {
posTokenInicio = tokenLeido.indexOf("Ó");
partePalInicial =
tokenLeido.substring(0, posTokenInicio);
partePalFinal =
tokenLeido.substring(posTokenInicio + 8);
tokenLeido = partePalInicial + "O" + partePalFinal;
}
//Después de substituir caracteres especiales
//La hilera leída es una palabra válida dentro de un anuncio
textoAnalizado += tokenLeido + " ";
} //Final if de la hilera leida no es igual a "<p>" o "</p>" o "<P>" o "</P>"
} //Final if de Si la hilera leida no es igual a "<br>" o "<BR>"
} //Cierra elseif de búsqueda de hilera "0000"
} //Final de while de tokenizar
System.out.println("Finalizo acomodo de anuncios\n");
//Se reutiliza variable para realizar concatenación para crear archivo XML
archivoLeidoCompleto = "";
//Escribe en un archivo de texto los anuncios clasificados parcialmente analizados
PrintWriter escribirAcomodado = new
PrintWriter(new BufferedWriter(new
FileWriter("preClasificados.txt")));
//Graba en el archivo de salida el contenido del texto analizado (anuncios publicitarios)
escribirAcomodado.println(textoAnalizado);
//Cierra el archivo que contiene los anuncios clasificados
escribirAcomodado.close();
//Leer el archivo que contiene el listado de los anuncios clasificados
BufferedReader preClasif = new
BufferedReader(new FileReader(
"preClasificados.txt"));
//Mientras lee el archivo con los clasificados, crea estructura XML agregando etiquetas correspondientes
//Reutilizando la variable de archivoLeidoParcial
while ( (archivoLeidoParcial = preClasif.readLine()) != null) {
//Cada anuncio lo delimita dentro de la etiqueta de anuncio
archivoLeidoCompleto += "<anuncio>" + archivoLeidoParcial + "</anuncio>" +
'\n';
}
//Cierra el archivo XML que se ha generado
preClasif.close();
System.out.println("Se graba archivo de preClasificados.txt");
miLista.InsertarEnClasificacion();
//miLista.ImprimirClasificacion();
try {
textoAnalizado = "";
//Encabezado característico de un archivo XML
String archivoXMLinicio =
"<?xml version=" + '\"' + "1.0" + '\"' +
" encoding=" + '\"' + "iso-8859-1" + '\"' + "?>" + '\n'
+ "<!-- Anuncios clasificados del Diario Extra -->" + '\n'
+ "<Clasificados>" + '\n'
+ "<Listado_General>" + '\n';
//Cierre del archivo XML
String archivoXMLfinal = "</Listado_General>" + '\n'
+ "<Listado_Especifico>" + '\n' + "Todavía no catalogado" +
"</Listado_Especifico>" + '\n' + "</Clasificados>" + '\n';
//Crea el archivo XML
PrintWriter escribirXML = new
PrintWriter(new BufferedWriter(new
FileWriter(archivoOriginal+".xml")));
//Graba en el archivo de salida el contenido del texto analizado (anuncios publicitarios)
textoAnalizado = archivoXMLinicio + miLista.GeneradorXMLClasificacion() + archivoXMLfinal;
//Escribe en el archivo XML el resultado de todas las concatenaciones
escribirXML.println(textoAnalizado);
//Cierra el archivo que contiene los anuncios publicitarios
escribirXML.close();
System.out.println("Se graba archivo "+archivoOriginal+".xml");
}
catch (EOFException e) {
System.out.println("Final de
Stream");
}
} //Fin de main
}
package traductor;
//Clase que permite manipular la lista de anuncios (articulos) economicos
public class ListaArticulo {
private NodoArticulo primero; //apuntador al primer elemento de la lista
private NodoArticulo ultimo; //apuntador al ultimo elemento de la lista
//Constructo de la clase artìculo
public ListaArticulo() {
primero = ultimo = null; //Como no hay elementos primero y ultimo apuntan a null
}
//Permite insertar un elemento en la lista de artìculos al inicio de la lista
//Recibe el nombre del articulo y la descripcion
public void InsertarArticulo (String nombreA, String descripcionA) {
if (EstaVacio()) { //si no hay elementos
primero = new NodoArticulo(nombreA, descripcionA);
ultimo = primero;
}else { //si hay elementos en la lista
primero = new NodoArticulo(nombreA, descripcionA,primero); //inserta al inicio
}
}
//Imprime la lista de articulos en la lista tanto el nombre como la descripcion
public void ImprimirArticulo() {
NodoArticulo temp = primero; //temp es un puntero que permite moverse por la lista
while (temp != null) { //Mientra no encuentre el final de la lista
System.out.print(temp.ObtenerNombre() + "\n"); //despliega el nombre
System.out.print(temp.ObtenerDescripcion() + "\n"); //despliega la descripcion
temp = temp.sigAbajo; //Se mueve al siguiente articulo
}
}
public String GeneradorXMLArticulo() {
NodoArticulo temp = primero; //temp es un puntero que permite moverse por la lista
String cadenaArticulos = "";
while (temp != null) { //Mientra no encuentre el final de la lista
cadenaArticulos += "\t<anuncio>"+"\n\t"+temp.ObtenerNombre()+"\n</anuncio>\n";
// System.out.print(temp.ObtenerDescripcion() + "\n"); //despliega la descripcion
temp = temp.sigAbajo; //Se mueve al siguiente articulo
}
return cadenaArticulos;
}
//Verifica si la lista esta vacia, si es asì retorna true sino false
public boolean EstaVacio() {
return primero == null;
}
}
package
traductor;
import
java.io.*;
import java.util.*;
//Clase que permite incluir en una lista las clasificaciones de los anuncios
//y procesar dicha lista para poder insertar los anuncios en las clasificaciones
public class ListaClasificacion {
int TAM_DICCIONARIO = 25;
private NodoClasificacion primero; //apuntador al primer nodo de la lista
private NodoClasificacion ultimo; //apuntador al ultimo nodo de la lista
//Constructor de la clase
public ListaClasificacion() {
primero = ultimo = null; //No hay elementos en la lista
}
//Crea un nodo donde inserta el nombre de la clasificacion y su correspondiente
//diccionario (asociacion)
//La asociacion son un conjunto de palabras que describen a la Clasificacion
public void InsertarClasificacion (String nombreC, String asociacion[]) {
if (EstaVacio()) { //Si no hay elementos en la lista
primero = new NodoClasificacion(nombreC, asociacion); //Inserta al inicio
ultimo = primero;
}else { //Si hay elementos en la lista
primero = new NodoClasificacion(nombreC, asociacion,primero);
}
}
//Imprime la Clasificacion con sus correspondientes anuncios
public void ImprimirClasificacion() {
NodoClasificacion temp = primero;
while (temp != null) {
System.out.print(temp.ObtenerNombre() +
"\n");
temp.listaDeArticulos.ImprimirArticulo();
temp = temp.sig;
}
}
//Genera la clasificacion del XML
public String GeneradorXMLClasificacion() {
NodoClasificacion temp = primero;
String clasificacionGenerada = "";
while (temp != null) {
clasificacionGenerada += "<"+temp.ObtenerNombre()+">"+"\n"+temp.listaDeArticulos.GeneradorXMLArticulo()+"</"+temp.ObtenerNombre()+">\n";
temp = temp.sig;
}
return clasificacionGenerada;
}
//Verifica si la lista esta vacia
public boolean EstaVacio() {
return primero == null;
}
//Lee desde un archivo llamado "TipoClasificacion.txt" las diferentes
//clasificaciones y sus descriptores y los inserta en una lista
public void HacerClasificacion() throws
IOException {
//Lee el archivo y lo asigna a la variable "archivo"
BufferedReader archivo = new BufferedReader(new
FileReader("TipoClasificacion.txt"));
//Variables para el manejo del contenido del archivo leído
String clasificacionLeida = new String();
String nombreClasificacion;
String parametro[] = new String[TAM_DICCIONARIO];
//Limpia vector
for (int i = 0; i<TAM_DICCIONARIO;i++) {
parametro[i] = "ñññññññññññññññ";
}
//Recorre cada linea del "archivo" para poder extraer la clasificacion
//y sus descriptores
while ((clasificacionLeida = archivo.readLine()) != null) {
StringTokenizer token = new StringTokenizer(clasificacionLeida);
// token.countTokens();
nombreClasificacion = token.nextToken();
int palabra = 0;
//Mientras existan palabras en el diccionario
while (token.hasMoreTokens()) {
parametro[palabra]= token.nextToken();
palabra++;
}
//Inserta la clasificacion y los descriptores en una lista
//los descriptores se insertan en un vector
InsertarClasificacion(nombreClasificacion,parametro);
//Limpia vector, se asume que no hay descriptores que sean lineas de letra ñ
for (int i = 0;
i<TAM_DICCIONARIO;i++) {
parametro[i] = "ñññññññññññññññ";
}
}
archivo.close(); //cierra el archivo
}
//A la lista de clasificaciones inserta una nueva lista que almacena por cada clasificacion
//los anuncios que correspondan a esta comparandola con el diccionario que tiene cada
//clasificacion
public void InsertarEnClasificacion() throws IOException {
//Lee el archivo preclasificados
BufferedReader archivoPreclasificado = new
BufferedReader(new FileReader("preClasificados.txt"));
//Representa a los anuncios publicados
String anuncioLeido = new String();
int lin=1;
//Se comienza a revisar a partir del primer nodo de la lista de Clasificacion
//asignandolo a un nodo que permita moverse por la lista
NodoClasificacion nodoTemporal = primero;
while ((anuncioLeido = archivoPreclasificado.readLine()) != null) {
System.out.print("Anuncio procesado "+lin+'\n');
lin++;
//Si el anuncio se incluye en una clasificacion se inicializa de nuevo
//el apuntador al primer elemento para que revise si el siguiente anuncio
//tambien se encuentra en esa clasificacion
nodoTemporal = primero;
//Indice que permite moverse por el vector que se encuentra en la lista de clasificaciones
//para poder compararse con alguna palabra que se encuentra en el anuncio
int palabraIndice = 0;
//Dice si el anuncio pertenece a una clasificacion
boolean encontrado = false;
//Permite recorrer cada una de las clasificaciones
while ((nodoTemporal!=ultimo)&&(encontrado==false)){
//Permite recorrer el diccionario
while ((palabraIndice < TAM_DICCIONARIO) && (encontrado == false)) {
//Revisa si alguna de las palabras del anuncio están en el diccionario
//de la clasificacion que se esta revisando
if (anuncioLeido.indexOf(nodoTemporal.parametro[palabraIndice])==-1) {
//System.out.print("Revisando clasificacion: "+nodoTemporal.nombreClasificacion+'\n');
//System.out.print(" comparando con: "+nodoTemporal.parametro[palabraIndice]+'\n');
palabraIndice++; //Si no corresponde a la primera palabra del diccionario avanza a la siguiente
}else { //Si alguna palabra del anuncio corresponde a alguna del diccionario
encontrado = true;
}
}
// Si no termino de recorrer el arreglo de palabras para hacer la clasificacion
// quiere decir que si se puede clasificar el anuncio
if (encontrado==true) {
nodoTemporal.listaDeArticulos.InsertarArticulo(anuncioLeido,"");
}else{ //Si el anuncio no corresponde a la actual Clasificacion
nodoTemporal=nodoTemporal.sig;
}
//Se inicializa el indice del arreglo para reiniciar la busqueda
palabraIndice=0;
}
// Si el aviso clasificado no se pudo insertar en una categoría específica.
// Se inserta en una denominada "VARIOS"
if(nodoTemporal==ultimo){
nodoTemporal.listaDeArticulos.InsertarArticulo(anuncioLeido,"");
}
}
archivoPreclasificado.close(); //cierra el archivo de PreClasificados
}
}
package traductor;
//Clase que contiene la definicion y manipulacion de los nodos de la Lista
//de Articulos
public class NodoArticulo {
protected String nombreArticulo = new String(); //almacena el nombre del anuncio
protected String descripcionArticulo = new String(); //almacena la descripcion del anuncio
protected NodoArticulo sigAbajo; //apuntador al siguiente anuncio
//constructores
public NodoArticulo(String nombreA, String descripcionA) {
this.nombreArticulo = nombreA;
this.descripcionArticulo = descripcionA;
sigAbajo = null;
}
//Constructor que para asignar un articulo si la lista tiene elementos
public NodoArticulo(String nombreA, String descripcionA,NodoArticulo sigNodoAbajo) {
this.nombreArticulo = nombreA;
this.descripcionArticulo = descripcionA;
this.sigAbajo = sigNodoAbajo;
}
//Devuelve el nombre del anuncio
public String ObtenerNombre() {
return nombreArticulo;
}
//Devuelve la descripcion del anuncio
public String ObtenerDescripcion() {
return descripcionArticulo;
}
//Devuelve el siguiente anuncio
public NodoArticulo ObtieneSigAbajo() {
return sigAbajo;
}
}
package traductor;
//Clase que manipula las clasificaciones
public class NodoClasificacion {
int TAM_DICCIONARIO = 25;
protected String nombreClasificacion; //almacena el nombre de la clasificacion
protected String parametro[] = new String[TAM_DICCIONARIO]; //almacenael diccionario
protected NodoClasificacion sig; //apuntador a la siguiente clasificacion
protected ListaArticulo listaDeArticulos; //apuntador a la lista de articulos
//constructores
public NodoClasificacion(String nombreC, String asociador[]) {
this.nombreClasificacion = nombreC;
for (int i=0;i<TAM_DICCIONARIO;i++)
this.parametro[i] = asociador[i];
sig = null;
//Por cada clasificacion crea su correspondiente lista de articulos
ListaArticulo unaLista = new ListaArticulo();
this.listaDeArticulos = unaLista;
}
//Constructor que sirve cuando hay mas clasificaciones
public NodoClasificacion(String nombreC, String asociador[],NodoClasificacion sigNodo) {
this.nombreClasificacion = nombreC;
for (int i = 0; i<TAM_DICCIONARIO;i++) {
this.parametro[i] = asociador[i];
}
this.sig = sigNodo;
//Por cada clasificacion crea su correspondiente lista de articulos
ListaArticulo unaLista = new ListaArticulo();
this.listaDeArticulos = unaLista;
}
//Devuelve el nombre de la clasificacion
public String ObtenerNombre() {
return nombreClasificacion;
}
//Devuelve el diccionario de la clasificacion
public String ObtenerParametro() {
String hilera = "";
for (int i = 0; i<TAM_DICCIONARIO;i++) {
hilera += parametro[i]+", ";
}
return hilera;
}
//Devuelve la siguiente clasificacion
public NodoClasificacion ObtieneSig() {
return sig;
}
}
Bibliografía
Deitel & Deitel. ¿Cómo Programar en Java?, 5th Edición. McGraw Hill Año de publicación: 2003
Aho, Alfred. Hopocroft, John, Ullman Jeffrey. Estructuras de datos y algoritmos. 1era Edición. Addison Wesley. 1998