![]()
![]()
|
Term |
Термин |
Определение |
| alignment |
совмещение;
синхронизация |
Расположение строк x и y, при котором их "интересные" части располагаются одна под другой. Как правило, это достигается соответствующей установкой индексов строк. |
| alphabet | алфавит | Конечное множество символов, называемое также классом символов, из которых построены все рассматриваемые строки. Говорят о строках над заданным алфавитом. Впрочем, часто говорят и о строках в алфавите. |
| catenation | катенация | То же, что и конкатенация. Лично мне последний термин привычнее. |
| character | литера | Элемент алфавита, буква, символ. То, из чего состоят строки. |
| concatenation | конкатенация |
Конкатенация строк x и y – это строка xy, получаемая присоединением y к x. Конкатенация AB двух языков A и B определяется как
AB = {xy : x 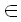 A & yB} A & yB}
то есть является множеством строк, сформированных конкатенацией всех строк из A со всеми строками из B. Не странно ли, что в практическом программировании конкатенацию всегда считают сложением, а не умножением? См. степень. |
| don't care symbol; wild card | джокер | "Универсальный" символ, который при сравнении строк можно сопоставить с любым символом алфавита. |
| edit distance | расстояние редактирования |
Метрика, измеряющая расстояния между двумя строками, не обязательно одинаковой длины, которая задается минимальным числом вставок, удалений и замен символов, требуемых для преобразования одной строки в другую, причем вставки и удаления входят в результат с весом 1, замены – с весом 2.
См. тж. расстояние Левенштейна. |
| empty string | пустая строка |
Строка 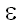 , строка нулевой длины. , строка нулевой длины. |
| exponentiation | (возведение в) степень |
По аналогии между умножением и конкатенацией строк, возведение в степень определяется следующим образом: x0 = , xi = xi-1x для целого i. Таким образом, x1 = x, x2 = xx, x3 = xxx и т.д.
Самая возможность подобных обозначений объясняет, почему при анализе строк конкатенацию удобнее считать умножением. |
| Fibonacci string | строка Фибоначчи | Строка, принадлежащая последовательности, элементы которой задаются следующими соотношениями f1 = B, f2 = A, fn = fn-1fn-2, n > 2. Пример: f5 = ABAAB. |
| Hamming distance | расстояние Хемминга | Метрика, измеряющая расстояние между двумя строками одинаковой длины; равна числу различающихся символов, стоящих в строках на местах с одинаковыми номерами. Например, расстояние Хемминга между строками master и pastes равно 2. |
| indel | вставуд | Операция вставки/удаления. Применяется при определении расстояний редактирования. |
| Kleene closure | замыкание Клини |
Замыкание Клини языка A – язык A*, сформированный объединением степеней языка A, от нулевого порядка и выше, то есть:
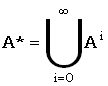 . .
|
| language | язык | Множество строк над заданным алфавитом. |
| length | длина | Длина строки x – число |x| символов в ней. |
| Levenshtein distance | расстояние Левенштейна | Метрика, измеряющая расстояния между двумя строками, не обязательно одинаковой длины, которая задается минимальным числом вставок, удалений и замен символов, требуемых для преобразования одной строки в другую, например, расстояние Левенштейна между zeitgeist и preterit равно 6. Является частным случаем расстояния редактирования: все преобразования входят в результирующую сумму с единичными весами. |
| matching | сопоставление | В случаях, когда нужно искать вхождения образца в текст, принято говорить о сопоставлении строк. Мне не удалось найти лучший термин. |
| mismatching symbol | отвергающий символ |
Предположим, что производится сопоставление образца p[1…m] с подстрокой t[i…i+m] текста. Если сопоставление началось слева и провалилось на k-м шаге, т.е. символ p[k]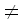 t[i+k-1], то k-й символ образца называется отвергающим. Символ t[i+k-1] также, конечно, является отвергающим. t[i+k-1], то k-й символ образца называется отвергающим. Символ t[i+k-1] также, конечно, является отвергающим.
|
| match heuristic | эвристика совпадения |
Одна из двух эвристик в алгоритме Бойера-Мура и его родственниках. Сдвиг определяется структурой образца.
См. тж. эвристика вхождения. |
| occurrence heuristic | эвристика вхождения |
Одна из двух эвристик, используемых в алгоритме Бойера-Мура и его родственниках. Сдвиг определяется отвергающим символом.
См. тж. эвристика совпадения. |
| pattern | образец; шаблон |
Образец – цепочка над фиксированным алфавитом 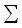 , которую нужно найти в заданном тексте, составленном из символов . Если образец задает сразу целую совокупность цепочек, слово pattern переводится как шаблон. Как правило, он задается на некотором языке, например, языке регулярных выражений. , которую нужно найти в заданном тексте, составленном из символов . Если образец задает сразу целую совокупность цепочек, слово pattern переводится как шаблон. Как правило, он задается на некотором языке, например, языке регулярных выражений.
|
| period | период | Слово w – период слова u, если имеется натуральное k, такое, что wk=u. |
| positive closure | положительное замыкание |
Язык A+, сформированный объединением конкатенаций языка A от первого порядка и выше, то есть:
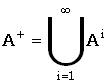
и есть положительное замыкание языка A. См. тж. замыкание Клини. |
| prefix | префикс; начало слова | Префикс строки x – ее начало, строка, полученная удалением нуля или более символов с конца x, например, рыба является префиксом строки рыбаки. Собственный префикс x – это префикс ненулевой длины, не совпадающий с самой строкой x. |
| proper | собственный | Термин proper употребляется в сочетании с терминами substring, subsequence, suffix, subset и т.д. Таким образом, получаем словосочетания собственная подстрока, собственный суффикс, собственное подмножество. Обозначает часть объекта, не совпадающую с самим объектом. |
| reverse | обращение | Для слова w=w[0]w[1]…w[k-2]w[k-1] задается так: wR=w[k-1]w[k-2]...w[1]w[0]. |
| square | квадрат |
Квадрат строки x – строка x2, состоящая из двух непустых повторяющихся строк, например, тартар. Аналогично определяются куб и прочие степени. Для облегчения восприятия между повторениями иногда ставят дефис, получая всем известные "гав-гав-гав" и "кря-кря".
См. тж. возведение в степень. |
| string | строка; цепочка |
Строка над заданным алфавитом – конечное множество символов этого алфавита, записанных последовательно. В некоторых контекстах термины предложение и слово используются как синонимы термина строка. Обратите внимание, что как , так и x являются (правда, несобственными) префиксами, суффиксами, подстроками и подпоследовательностями строки x.
|
| string search | анализ строк | Термин анализ строк используется здесь в довольно общем смысле и обозначает целый класс задач – таких, как локализация заданных подстрок, выделение длиннейших общих подстрок, вычисление расстояний между строками и т.д. |
| string-to-string correction problem | задача построчного сравнения | Возникает при сравнении файлов. |
| subsequence | подпоследовательность | Подпоследовательность строки x – строка, получаемая удалением из x нуля или более символов, не обязательно смежных. Например, строка nnnaa является подпоследовательностью строки ginnungagap. Собственная (proper) подпоследовательность x – это непустая подпоследовательность, не равная самой x. Обратите внимание на то, что guinna не является подпоследовательностью. |
| subset | подмножество |
Множество A, каждый элемент которого является также элементом множества B. Обозначение: A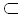 B. B.
|
| substring | подстрока; подцепочка | Подстрока строки x – строка, получаемая удалением нуля и более символов из начала и конца x (то есть удалением префикса и суффикса), например, gna является подстрокой ragnarok. Собственная подстрока x – это непустая подстрока x, не равная x. |
| suffix | суффикс; конец слова | Суффикс строки x – строка, полученная удалением нуля или более символов из начала x, например, asill является суффиксом yggdrasill. Собственный суффикс x – это непустой суффикс, не равный x. |
| supersequence | надпоследовательность | Надпоследовательность строки x – любая строка y, такая, что x является подпоследовательностью y, например, facetious является надпоследовательностью aeiou. |
| union | объединение |
Объединение A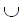 B языков A и B – это язык, содержащий все строки как из A, так и из B, то есть: AB = {x : x A}{x : xB}. B языков A и B – это язык, содержащий все строки как из A, так и из B, то есть: AB = {x : x A}{x : xB}.
|

Вы можете попасть на эту страницу по одному из следующих адресов:
http://learn.at/infoscope/string_search/glossary/index.html
http://now.at/infoscope/string_search/glossary/index.html
http://read.at/infoscope/string_search/glossary/index.html
Дата последней модификации: 14 сентября 2000 г.