![]()
Самый первый и самый важный шаг при построении АРПСС-модели - определение порядка дифференцирования, необходимого для того, чтобы превратить ряд в стационарный. Как правило, дифференцировать нужно до тех пор, пока мы не получим ряд, благонравно флуктуирующий вокруг явного среднего, автокорреляционная функция (АКФ) которого быстро убывает, стремясь к нулю сверху или снизу. Если у ряда наблюдается медленный тренд или другие отклонения, либо если его АКФ положительна при достаточно больших значениях аргумента (число 10 уже достаточно велико), ряд, видимо, нужно продифференцировать еще раз. Мы назовем это первым правилом выбора АРПСС-модели:
Правило 1: Если автокорреляционная функция ряда положительна при значении аргумента, равном k, этот ряд, по-видимому, понадобится продифференцировать не менее k раз.Дифференцирование уменьшает коррелированность: если корреляции исходного ряда строго положительны, то (несезонное дискретное) дифференцирование уменьшает их или даже делает отрицательными. Повторное дифференцирование еще уменьшает автокорреляции.
Если значение АКФ в точке k значимо отрицательно (отрицательные значения АКФ не меньше 0.5 по абсолютной величине!), это вполне может означать, что ряд передифференцирован. На первый взгляд такой ряд может выглядеть вполне случайным. Приглядитесь внимательнее к графику: у передифференцированного ряда последовательные значения слишком часто меняют знак: плюс-минус-плюс-минус... - такое поведение не случайно!
Правило 2: Если автокорреляционная функция отрицательна или равна нулю при значении аргумента, равном k-1, ряд не нуждается в дифференцировании порядка, превосходящего k. Если значения автокорреляционной функции меньше или равны -0.5, ряд, по-видимому, передифференцирован.Еще один признак возможной передифференцированности - увеличение стандартного отклонения с ростом порядка дифференцирования. Это и станет нашим третьим правилом:
Правило 3: Оптимальный порядок дискретной производной - тот, при котором минимально стандартное отклонение.Первые два правила не всегда позволяют сколько-нибудь точно определить нужный порядок дифференцирования. Ниже мы увидим, что "умеренную недодифференцированность" можно скомпенсировать добавлением АР-членов, а "умеренную передифференцированность" - добавлением СС-членов. Иногда можно построить две модели, которые соответствуют данным примерно одинаково: модель, в которой порядок дифференцирования равен 0 или 1 и имеются АР-члены, и модель с большим порядком дифференцирования и СС-членами. Выбор между двумя такими моделями может основываться на ваших личных предпочтениях о виде нестационарности исходного ряда - другими словами, что вы предпочитаете: отсутствие фиксированного среднего или постоянный средний тренд.
Правило 4: Модель без дифференцирования предполагает, что исходный ряд стационарен. В модели с первой производной предполагается, что у исходного ряда имеется константный тренд (примером является случайное блуждание). В модели с второй производной предполагается, что тренд ряда не постоянен во времени (пример - случайный тренд).При выборе порядка дифференцирования следует принимать во внимание роль константы в модели, если, конечно, она включена. Константа представляет среднее ряда в моделях без дифференцирования, линейный тренд в моделях с производными первого порядка, нелинейный полиномиальный тренд в моделях с производными более высокого порядка. Как правило, предполагается, что производные второго и более высокого порядка элиминируют тренд, так что в подобные модели константу не включают. В модели без дифференцирования или с производной первого порядка константу часто включают. Таким образом, мы получаем:
Правило 5: В модели без дифференцирования константу, как правило, включают - в них она соответствует среднему ряда. В модели с производными второго и более высокого порядка константу, как правило, не включают. В модели с производной первого порядка константу следует включить в случае, если у производной имеется тренд.
(а) |
(б) |
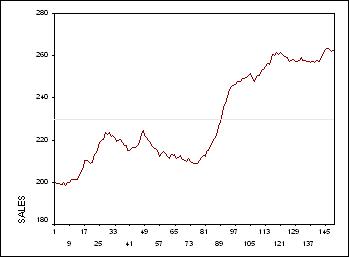
Ясно, что ряд нужно продифференцировать по крайней мере один раз. Первая
производная ряда представлена на рис.2.
(а) |
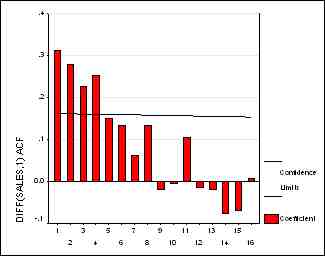
(б) |
Обратите внимание на то, что продифференцированный ряд уже похож на
стационарный - в нем не виден тренд, он демонстрирует явственную тенденцию
возвращаться к своему среднему, быть может, чуть-чуть слишком лениво. У
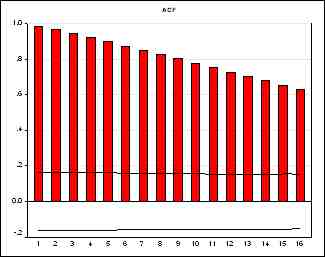
АКФ на рис. 2(б) достаточно мало положительных значений, хотя, конечно,
хотелось бы, чтобы их было еще меньше. Из нижеследующих дескриптивных статистик
мы видим, что и стандартное отклонение среднего сильно уменьшилось - с
21.48 до 1.44.
|
M
|
N
|
150
|
|
Минимум
|
198,60
|
|
|
Максимум
|
263,30
|
|
|
Среднее
|
229,9780
|
|
|
Стд. отклонение
|
21,4797
|
|
|
DIFF(M,1)
|
N
|
149
|
|
Минимум
|
-2,70
|
|
|
Максимум
|
4,80
|
|
|
Среднее
|
,4201
|
|
|
Стд. отклонение
|
1,4440
|
|
|
N валидных
|
N
|
149
|
Поскольку тренд у ряда DIFF(M,1) отсутствует, а количество положительных автокорреляций достаточно мало, можно считать его стационарным. На всякий
случай посмотрим, что получится, если мы возьмем еще одну производную:
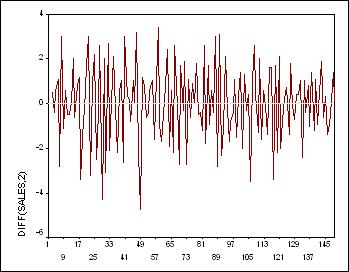 |
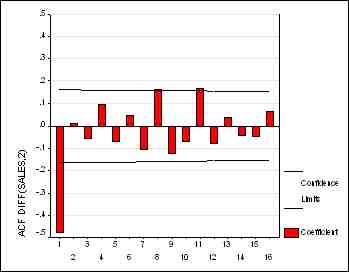 |
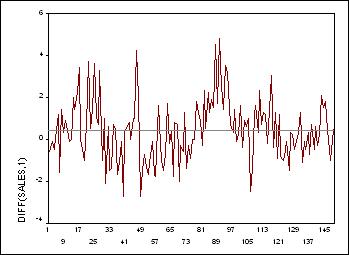
Посмотрите: мы видим упоминавшиеся выше признаки передифференцированности:
значения ряда слишком часто меняют знак, а на графике АКФ мы видим одно
большое отрицательное значение, близкое к -0.5, при лаге, равном 1. Кроме
того, и стандартное отклонение возросло от 1.444 до 1.698:
|
M
|
N
|
150
|
|
Минимум
|
198,60
|
|
|
Максимум
|
263,30
|
|
|
Среднее
|
229,9780
|
|
|
Стд. отклонение
|
21,4797
|
|
|
DIFF(M,2)
|
N
|
148
|
|
Минимум
|
-4,70
|
|
|
Максимум
|
3,40
|
|
|
Среднее
|
7,432E-03
|
|
|
Стд. отклонение
|
1,6977
|
|
|
N валидных
|
N
|
148
|
Итак, нам следует начать с ряда, продифференцированного один раз. Конечно, исследование на этом не заканчивается: вполне может оказаться, что при добавлении АР- или СС-членов нам понадобится другой порядок производной ряда. Или может оказаться, что для долговременного прогноза свойства модели с другим порядком производной окажутся более согласующимися с интуитивными представлениями (мы еще поговорим об этом). Однако, в качестве первого приближения мы пока можем считать подходящей производную первого порядка.
Как известно, частная корреляция между двумя переменными - это та часть корреляции между ними, которую не удается объяснить их корреляциями с выбранным множеством других переменных. Например, если мы исследуем регрессию переменной Y на X1, X2 и X3, то частная корреляция между Y и X3 равняется корреляции между ними, оставшейся после того, как исключена их корреляция с X1 и X2.
Частная корреляция вычисляется как корреляция между остатками регрессии Y на X1, X2 и регрессии X3 на X1, X2. Она равна также корню квадратному из уменьшения дисперсии, которое возникает в результате добавления X3 к регрессии Y на X1, X2.
Автокорреляционная функция, АКФ, вычисляется как последовательность корреляций между рядом и им же, сдвинутым на 1, 2, ... временных точек, лагов. Автокорреляция при лаге 1 есть коэффициент корреляции между Yt и Yt-1, который равняется - ведь ряд стационарен! - коэффициенту корреляции между Yt-1 и Yt-2. (Собственно, это свойство и позволяет говорить об автокорреляционной функции и вычислять ее значения описанным образом.) Однако, если коррелированны Yt и Yt-1, а также Yt-1 и Yt-2, то естественно думать, что Yt и Yt-2 также коррелированны. (На самом-то деле, автокорреляция при лаге 2 равняется квадрату корреляции при лаге 1.) Таким образом, корреляция при лаге 1 "вызывает" корреляцию при лаге 2, а, соответственно, и при больших лагах. Потому-то и оказывается полезной частная автокорреляционная функция, ЧАКФ. Ее значение при лаге 1 совпадает с обычной автокорреляцией, отличия начинаются с лага 2. Значение ЧАКФ при лаге 2 равняется корреляции рядов Yt и Yt-2, причем считается исключенной их корреляция с рядом Yt-1. Аналогично, ЧАКФ при лаге 3 равняется корреляции рядов Yt и Yt-3, причем считается исключенной их корреляция с рядами Yt-1 и Yt-2.
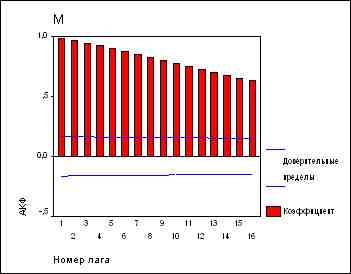
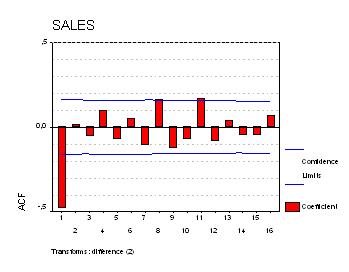
Вернемся к ряду М. Вот как выглядят АКФ и ЧАКФ этого ряда:
(a) |
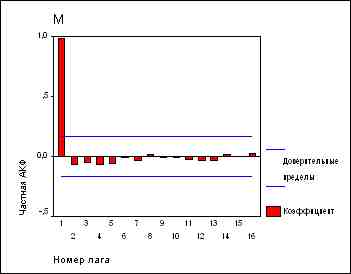
(b) |
Частные автокорреляции при всех лагах можно вычислить, подгоняя последовательность авторегрессионный моделей с увеличивающимся числом членов. В частности, частная автокорреляция при лаге k равняется k-му коэффициенту AR(k) в авторегрессионной модели с k членами. То же самое по другому: если мы возьмем переменную Y и рассмотрим ее регрессию на переменные LAG(Y,1), LAG(Y,2), ..., LAG(Y,k), то коэффициент при переменной LAG(Y,j), как раз и будет равен j-й частной автокорреляции. Таким образом, вы можете определить нужное количество AR-членов, просто глядя на ЧАКФ ряда: если значения ЧАКФ значимы до лага k, а после него незначимы, следует начинать с авторегрессионной модели порядка k.
Наш ряд демонстрирует в точности описанное поведение: у его ЧАКФ пик при лаге 1 и более нет значимых значений. Это говорит нам, что если ряд не дифференцировать, то следует использовать модель AR(1). Однако, в данном конкретном случае такая модель эквивалентна однократному дифференцированию, поскольку коэффициент при AR(1)-члене (который равняется высоте пика ЧАКФ при лаге 1) почти в точности равняется 1. Действительно, рассмотрим уравнение AR(1) модели:
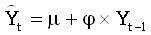 .
.
Если коэффициент 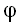 при AR(1)-члене равен
1, то уравнение говорит нам, что первая (дискретная) производная ряда равна
константе, т.е. что уравнение задает, на самом деле, модель случайного
блуждания с линейным сносом:
при AR(1)-члене равен
1, то уравнение говорит нам, что первая (дискретная) производная ряда равна
константе, т.е. что уравнение задает, на самом деле, модель случайного
блуждания с линейным сносом:
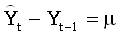
ЧАКФ ряда M говорит нам, что если мы не хотим дифференцировать ряд, то нам следует использовать модель AR(1), которая оказывается эквивалентной модели с первой производной. Другими словами, ряд M на самом деле нужно продифференцировать - это "стационаризует" его.
Признаки AR и MA. Если ЧАКФ резко обрывается, а АКФ убывает достаточно медленно (т.е. имеет значимые пики при достаточно больших лагах), мы говорим, что "стационаризованный" ряд демонстрирует AR-признаки, имея в виду, что наблюдаемые свойства автокорреляций ряда легко объясняются добавлением AR-членов, и трудно - добавлением MA-членов. Как правило, AR-признаки вызываются положительной автокорреляцией при лаге 1, т.е. обычно возникают в слегка недодифференцированных рядах. Причиной этого является то, что AR-член ведет себя в уравнении, как "частная производная". Например, в AR(1)-моделях он ведет себя как первая производная, если коэффициент при нем равен 1, и как частная производная, если коэффициент находится между 0 и 1. Таким образом, если ряд слегка недодифференцирован, т.е. если нестационарность, вызванная положительной автокорреляцией, не полностью элиминирована, AR-член "попросит" частную производную проявиться как AR-признак. Итак, мы приходим к следующему эмпирическому правилу:
Правило 6: Если ЧАКФ продифференцированного ряда резко обрывается в точке k и/или значение автокорреляции в точке k-1 положительно, т.е. если ряд выглядит слегка "недодифференцированным", следует попробовать добавить к модели авторегрессионный член. Значение аргумента k, после которого ЧАКФ "обрывается", - первый кандидат на порядок авторегрессионной части модели.В принципе любую автокорреляционную картину можно смоделировать, добавляя в модель "стационаризованного" ряда достаточное количество авторегрессионных членов; ЧАКФ помогает нам определить их примерное число. Однако, это не всегда приводит к простейшей модели: иногда лучше добавлять СС-члены. Автокорреляционная функция для СС-членов играет ту же роль, которую для АР-членов играет ЧАКФ: значения АКФ говорят нам, сколько примерно СС-членов понадобится. Если значения АКФ значимы до лага k (после они незначимы), в модели, по-видимому, уместно использовать k СС-членов. В таких случаях говорят, что стационаризованный ряд демонстрирует "СС-признаки", имея в виду, что характер автокорреляций легче объясняется добавлением СС-членов, чем добавлением АР-членов.
СС-признаки, как правило, связывают с отрицательными автокорреляциями при лаге 1. Другими словами, они часто возникают в слегка передифференцированных рядах. Это можно объяснить тем, что СС-члены могут частично уравновесить дифференцирование в модели. В самом деле, вспомним, что модель ARIMA(0,1,1) без константы эквивалентна обычному экспоненциальному сглаживанию. Уравнение такой модели:
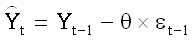 ,
,
где СС(1)-коэффициент 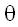 соответствует
1-
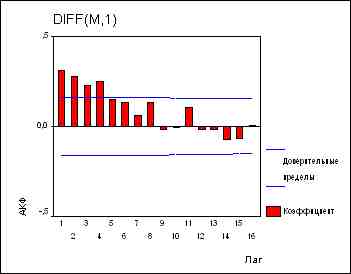
соответствует
1-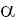 в экспоненциальном сглаживании. Если коэффициент при СС(1)-члене равен
1, в соответствующей модели экспоненциального сглаживания =0, так что
эта модель в качестве прогноза предлагает константу, поскольку модельное
значение не корректируется. Это означает, что когда СС(1)-коэффициент равен
1, модель на самом деле аннулирует дифференцирование, а это приводит к
тому, что прогноз экспоненциально сглаженной модели "приклеивается"
к последнему наблюдению. С другой стороны, если СС(1)-коэффициент равен
0, модель сводится к модели случайного блуждания, т.е. оставляет только
дифференцирование. Таким образом, если СС(1)-коэффициент больше 0, можно
сказать, что мы слегка уменьшили порядок дифференцирования. Если ряд уже
передифференцирован,
т.е. если наблюдаются отрицательные автокорреляции, он "попросит" слегка
уменьшить порядок дифференцирования, продемонстрировав СС-признаки. (Обратите
внимание на высокую степень нестрогости всех этих рассуждений!) Итак, мы
приходим к следующему эмпирическому правилу:
в экспоненциальном сглаживании. Если коэффициент при СС(1)-члене равен
1, в соответствующей модели экспоненциального сглаживания =0, так что
эта модель в качестве прогноза предлагает константу, поскольку модельное
значение не корректируется. Это означает, что когда СС(1)-коэффициент равен
1, модель на самом деле аннулирует дифференцирование, а это приводит к
тому, что прогноз экспоненциально сглаженной модели "приклеивается"
к последнему наблюдению. С другой стороны, если СС(1)-коэффициент равен
0, модель сводится к модели случайного блуждания, т.е. оставляет только
дифференцирование. Таким образом, если СС(1)-коэффициент больше 0, можно
сказать, что мы слегка уменьшили порядок дифференцирования. Если ряд уже
передифференцирован,
т.е. если наблюдаются отрицательные автокорреляции, он "попросит" слегка
уменьшить порядок дифференцирования, продемонстрировав СС-признаки. (Обратите
внимание на высокую степень нестрогости всех этих рассуждений!) Итак, мы
приходим к следующему эмпирическому правилу:
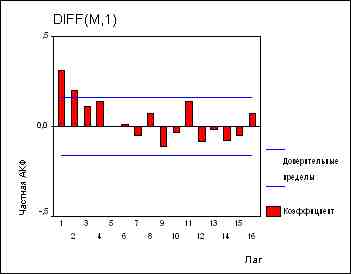
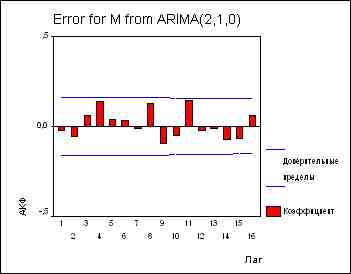
Правило 7: Если АКФ продифференцированного ряда резко обрывается и/или значение АКФ в точке k-1 отрицательно, т.е. ряд выглядит слегка передифференцированным, следует ввести в модель СС-члены. Значение аргумента k, при котором АКФ обрывается, - первый кандидат на порядок СС-части модели.Модель ARIMA(2,1,0) для ряда М. Мы уже определили, что ряд М требуется продифференцировать (по крайней мере) один раз. АКФ и ЧАКФ производной выглядят так:
 |
 |
 |
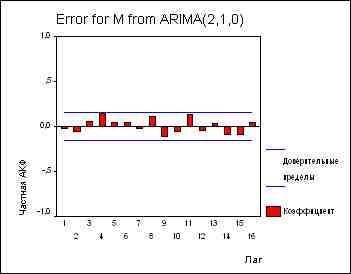 |
Автокорреляции в самых важных лагах - лагах 1 и 2 - "ушли", отсутствуют сколько-нибудь выраженные закономерности при больших лагах. На графике остатков мы наблюдаем, тем не менее, не вполне удовлетворяющую нас тенденцию: ряд "блуждает" вокруг среднего,
Однако, из результатов, выдаваемым процедурой ARIMA, мы видим, что модель, тем не менее, ведет себя вполне удовлетворительно. Оба АР-коэффициента значимо отличаются от нуля. Единичный корень не грозит нашей модели, поскольку сумма АР-коэффициентов (.248 + .199=.447) достаточно далека от 1. В целом, довольно хорошая модель!
MODEL: MOD_7 Model Description: Variable: M Regressors: NONE Non-seasonal differencing: 1 No seasonal component in model. Parameters: AR1 ________ < value originating from estimation > AR2 ________ < value originating from estimation > CONSTANT ________ < value originating from estimation > 95,00 percent confidence intervals will be generated. Split group number: 1 Series length: 150 No missing data. Melard's algorithm will be used for estimation. Termination criteria: Parameter epsilon: ,001 Maximum Marquardt constant: 1,00E+09 SSQ Percentage: ,001 Maximum number of iterations: 10 Initial values: AR1 ,24929 AR2 ,20046 CONSTANT ,41376 Marquardt constant = ,001 Adjusted sum of squares = 267,56021 Conclusion of estimation phase. Estimation terminated at iteration number 1 because: Sum of squares decreased by less than ,001 percent. FINAL PARAMETERS: Number of residuals 149 Standard error 1,3529082 Log likelihood -255,04718 AIC 516,09437 SBC 525,10621 Analysis of Variance: DF Adj. Sum of Squares Residual Variance Residuals 146 267,55893 1,8303607 Variables in the Model: B SEB T-RATIO APPROX. PROB. AR1 ,24850814 ,08096306 3,0694015 ,00255794 AR2 ,19880504 ,08101270 2,4539985 ,01530411 CONSTANT ,41382162 ,19898260 2,0796875 ,03930264 The following new variables are being created: Name Label FIT_1 Fit for M from ARIMA, MOD_7 CON ERR_1 Error for M from ARIMA, MOD_7 CON LCL_1 95% LCL for M from ARIMA, MOD_7 CON UCL_1 95% UCL for M from ARIMA, MOD_7 CON SEP_1 SE of fit for M from ARIMA, MOD_7 CON 30 new cases have been added. |
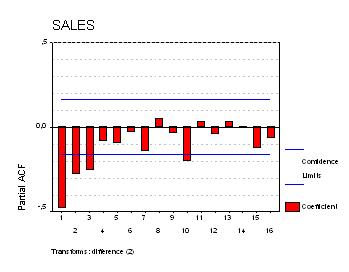
Тренд в долговременном прогнозе возникает из-за того, что в модель входят (несезонная) производная и константа - модель, таким образом, является случайным блужданием со сносом, аппроксимируемым двумя АР-членами. Итак, уравнение модели выглядит следующим образом:
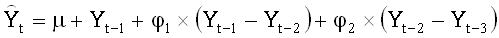 ,
,
где 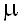 - константа, равная .41382162,
а 1 и 2
- коэффициенты при АР-членах, равные соответственно .24850814
и .19880504 (см. приведенные выше результаты работы процедуры
ARIMA).
- константа, равная .41382162,
а 1 и 2
- коэффициенты при АР-членах, равные соответственно .24850814
и .19880504 (см. приведенные выше результаты работы процедуры
ARIMA).
|
|
|
|
|
| D1.M |
|
|
|
 |
 |
|
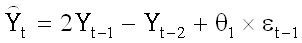 ,
,
где 1 - коэффициент при
МА(1)-члене. Взгляните на это соотношение внимательнее! Узнаете экспоненциальное
сглаживание? Коэффициент 1
равняется 2*(1-), где - весовой коэффициент
из модели экспоненциального сглаживания. Поскольку 1
= 0.75, экспоненциальное сглаживание с около 0.63 должно примерно так
же соответствовать данным. Оказывается, оптимальное значение
равно примерно 0.61, что не слишком далеко от 0.63.
--------
Все три модели ведут себя примерно одинаково в обучающем периоде, а в экзаменационном ARIMA(2,1,0) выглядит чуточку лучше. Основываясь только на приведенных статистических результатах, трудно остановиться на какой-либо одной модели. Однако, если мы посмотрим на график, мы увидим, что ARIMA(0,2,1) без константы (которая, как мы видели, во всем существенном совпадает с моделью экспоненциального сглаживания) сильно отличается от ARIMA(2,1,0).
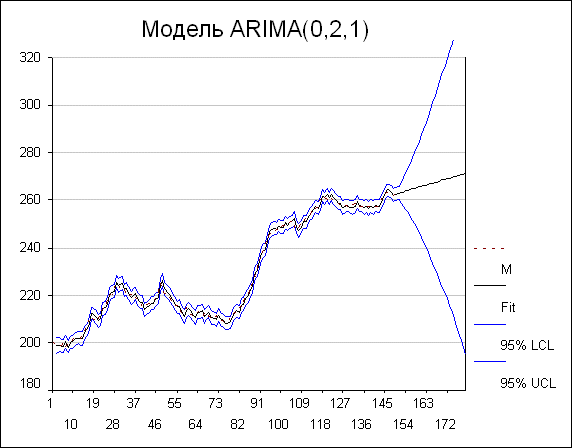
Мы видим, что у прогноза имеется тренд, который несколько меньше, чем тренд предыдущей модели - поскольку тренд у конца ряда слегка меньше среднего тренда ряда. Зато доверительные границы растут намного быстрее. Модель с производной второго порядка предполагает, что тренд ряда изменяется со временем, поэтому ближайшее будущее с "точки зрения" этой модели намного менее определенно, чем с "точки зрения" модели с производной первого порядка.
Правило 8: Вполне может случиться, что АР- и СС-члены взаимно "аннигилируют". Поэтому, если вы подгоняете смешанную модель, не поленитесь исследовать модель, в которой на 1 меньше АР-членов, а также модель, в которой на 1 меньше СС-членов. Это особенно важно, когда процесс подгонки исходной модели требует много итераций; 10 итераций - это уже много.По этой причине при идентификации модели АРПСС не применимо пошаговое исключение. Другими словами, вы не можете включить лишние АР- и СС-члены, а потом исключать по одному те из них, при которых коэффициенты окажутся незначимыми. Вместо этого следует использовать пошаговое включение, добавляя нужные члены в соответствии с поведением АКФ и ЧАКФ.
Правило 9: Если в АР-части модели имеется единичный корень, т.е. если сумма АР-коэффициентов равна 1, следует уменьшить на единицу число АР-членов и увеличить на единицу порядок дифференцирования.Аналогично, говорят, что у СС(1)-модели имеется единичный корень, когда СС(1)-коэффициент в точности равен 1. В подобной ситуации СС(1)-член точно "отменяет" одно дифференцирование; другими словами, следует уменьшить СС-порядок модели на 1 и на 1 уменьшить порядок дифференцирования. При работе с СС-моделями более высокого порядка о единичном корне говорят, когда сумма СС-коэффициентов в точности равна 1.
Правило 10: Если в СС-части модели имеется единичный корень, т.е. если сумма СС-коэффициентов равна 1, следует уменьшить на 1 число СС-членов и уменьшить на 1 порядок дифференцирования.Если, например, вы подгоняете модель линейного экспоненциального сглаживания (т.е. ARIMA(0,2,2)), в то время, как достаточным было бы простое экспоненциальное сглаживание (т.е. ARIMA(0,1,1)), то вы вполне можете получить два СС-коэффициента, сумма которых близка к 1. Уменьшив СС-порядок и порядок дифференцирования на 1 каждый, вы и получите более адекватную модель простого экспоненциального сглаживания. Модель прогноза с единичным корнем в оцененных СС-коэффициентах иногда называют необратимой, имея в виду, что остатки такой модели нельзя рассматривать как оценки "истинного" случайного шума, лежащего в основе анализируемого временного ряда.
Другим симптомом единичного корня является неестественный характер прогноза. Если график долговременного прогноза временного ряда выглядит странно, например, его тренд имеет "взрывной" характер, следует проверить коэффициенты модели - нет ли там единичного корня.
Правило 11: Если долговременный прогноз оказывается в каком бы то ни было смысле неустойчивым или странным, следует проверить коэффициенты модели на присутствие единичного корня.Обратите внимание на то, что ни одна из этих проблем не возникла в рассмотренных здесь моделях. Объяснение совсем простое - мы тщательно подбирали подходящий порядок дифференцирования и количества АР- и СС-членов. Идентификация модели основывалась на графиках АКФ и ЧАКФ.
Сезонная модель АРПСС обозначается так: ARIMA(p,d,q)* (P,D,Q), где P - количество сезонных АР(САР)-членов, D - порядок сезонной производной, Q - количество сезонных СС(ССС)-членов.
При идентификации сезонной модели прежде всего определите, нужна ли в модели сезонная производная? Нельзя ли "обменять" ее на обычную (несезонную) производную? Может быть, стоит использовать сезонную производную вместо обычной? Принять это решение вам помогут графики АКФ и ЧАКФ для всех возможных комбинаций сезонной и несезонной производных нулевого и первого порядков. Предупреждения: никогда не пользуйтесь сезонной производной порядка выше 1; никогда не пользуйтесь моделями, в которых сумма порядков сезонной и несезонной производных больше 2.
Если сезонная зависимость достаточно сильна и устойчива (скажем, значения высоки летом и малы зимой или наоборот), то, по-видимому, следует включить в модель сезонную производную вне зависимости от того, включена ли в модель обычная, несезонная, производная. Если этого не сделать, сезонная компонента будет убывать при долговременном прогнозе. Итак, добавим к нашему списку правил следующее:
Правило 12: Если ряд демонстрируют достаточно явственную и устойчивую сезонную компоненту, следует включить в модель сезонную производную. Не используйте сезонные производные порядка, большего 1; не пользуйтесь моделями, у которых сумма порядков сезонной и несезонной производных больше двух.Сезонные АР- и СС-проявления схожи с их несезонными аналогами. Различие проявляется только в том, что на графиках АКФ и ЧАКФ они отстоят друг от друга на лаг s.
Например, у чистого процесса ССС(1) мы найдем пики АКФ при лагах s, 2s, 3s и т.д., а ЧАКФ равна нулю после лага s.
У чистого процесса САР(1) мы, напротив, увидим пики ЧАКФ при лагах s, 2s, 3s и т.д., а после лага s равна нулю АКФ.
Признаки САР наблюдаются, как правило, когда автокорреляции в лагах s, 2s, 3s и т.д. положительны, а признаки ССС - когда они отрицательны. Таким образом,
Правило 13: Если автокорреляции в сезонных точках положительны, попробуйте включить в модель САР-члены. Если же эти автокорреляции отрицательны, включайте в модель ССС-члены. Не смешивайте САР- и ССС-члены в модели, избегайте включения более одного из них.Как правило, достаточно, чтобы модель была либо САР(1), либо ССС(1). Модели с САР(2) или с ССС(2) встречаются редко, еще реже у вас хватит данных, чтобы оценить коэффициенты подобных моделей. В самом деле, чтобы оценить коэффициенты, вам понадобится 4-5 сезонных периода. Таким образом, как правило, рассматриваются модели АРПСС лишь с небольшим числом параметров; таким образом, наиболее популярной сезонной моделью АРПСС оказывается ARIMA(0,1,1)*(0,1,1), т.е. модель АР(1)*ССС(1) с сезонной и несезонной производными. Узнали модель сезонного экспоненциального сглаживания?

Дата последней модификации: 25 октября 2000 г.