![]()
![]()
На сайте http://lib.stat.cmu.edu/DASL/DataArchive.html располагается большой архив данных, предназначенных для иллюстрации применения статистических методов. В данном тексте один из приведенных там наборов данных использован для иллюстрации применения кластерного анализа. Эти данные впервые рассмотрены в работе Weber, A. (1973), Agrarpolitik im Spannungsfeld der internationalen Ernaehrungspolitik, Institut fuer Agrarpolitik und marktlehre, Kiel. Затем они цитировались в
В данном тексте я демонстрирую, что:
Для анализа данные переведены в формат SPSS. Конечно, вы можете скачать их и в обычном текстовом формате.
Данные отражают потребление протеина из 9 групп пищи в 25 европейских странах. Обратите внимание: данные относятся к началу 70-х гг., так что СССР еще здравствует, Германия разделена, а часть Европы относится к так называемому социалистическому лагерю. В файле имеются следующие переменные с очевидной семантикой значений: страна, говядина, птица, яйца, молоко, рыба, каши, крахмал (Крахмалосодержащая пища), орехи, фр.овощи. Попробуем выявить, имеются ли естественно выделяемые группы среди 25 стран, а также связь между потреблением мяса и потреблением других продуктов.
Кластерный анализ методом полных связей (furthest neighbor, метод ближайшего из отдаленнейших) по всем девяти переменным дает разбиение стран на вполне интерпретируемые группы. Обратите внимание: поскольку размах переменных различен (значения переменной яйца меняются от 1 до 5, значения переменной каши колеблются вокруг 40), переменные нормализованы, используется z-преобразование. Если кластеризовать без преобразования переменных и/или другим методом, то полученное решение не всегда поддается столь же естественной интерпретации. Попробуйте, например, метод единичных связей (nearest neighbor, метод отдаленнейшего из ближайших).

Рис.1. Распределение стран по шести кластерам
Метод главных компонент тех же девяти переменных позволяет выделить четыре основных источника вариабельности (рис. 2). Первую компоненту можно интерпретировать как меру суммарного потребления пищи. Вторую, третью и четвертую – как потребление говядины, птицы и рыбы соответственно.
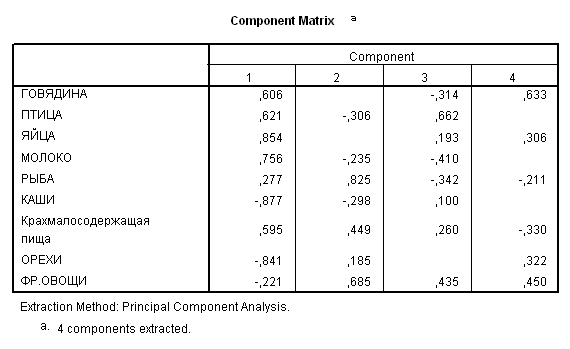
Рис. 2. Результаты применения метода главных компонент
Analyse
Classify
Hierarchical Cluster…
 Variable(s):говядина, птица …
Label Cases by:страна
(рис. 3)
Variable(s):говядина, птица …
Label Cases by:страна
(рис. 3)
Кликните кнопку Method, после чего в списке Cluster Method выберите Furthest neighbor. Вы должны получить окно, изображенное на рис. 4. Кликните кнопку Continue, и вы вернетесь в основное диалоговое окно процедуры. Теперь кликните в нем кнопку Save:
Save…Single solution: 6 clusters (рис. 5)
Вернувшись в основное диалоговое окно, кликните кнопку OK. В результате выполнения процедуры, в редакторе данных появится новая переменная clu6_1. Чтобы получить распределение стран в соответствии с ее значениями, отсортируем наблюдения в порядке убывания ее значений (рис. 6), после чего запустим процедуру Summarize Cases (рис. 7). Быть может, вы получите чуть другую кодировку групп (скажем, наша группа 1 появится у вас под номером 6), но разбиение наблюдений на группы будет тем же.
Analyze
Data Reduction
Factor…
Variable(s):говядина,птица…
(рис. 8)
Extraction…
Method: principal components
Number of factors: 4
(рис. 9)
Options:
 Suppress absolute values less than: 0.10
(рис. 10)
Suppress absolute values less than: 0.10
(рис. 10)
Рис. 3. Основное диалоговое окно процедуры «Иерархический кластерный анализ»
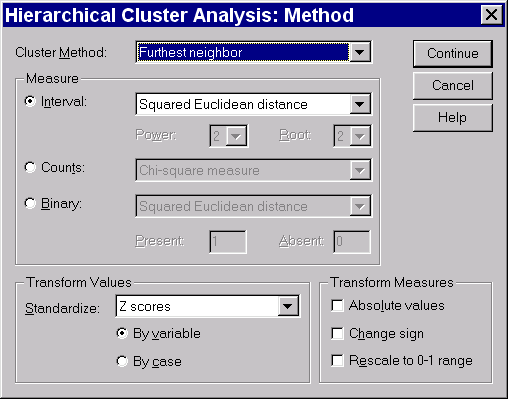
Рис. 4. Выбрана кластеризация методом полных связей
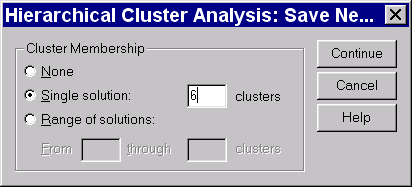
Рис. 5. Сохранить в переменной разбиение на 6 кластеров
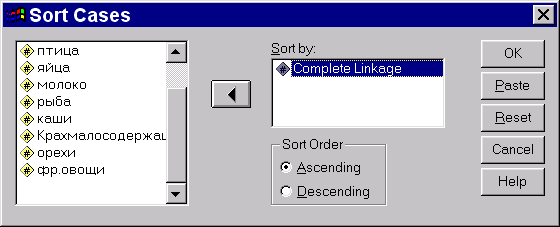
Рис. 6. Сортируем наблюдения по переменной clu6_1
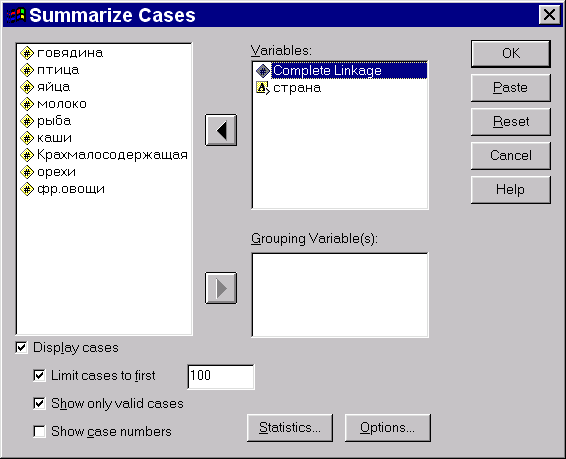
Рис. 7. Получим список значений переменных
для отсортированных наблюдений
Рис. 8. Основное диалоговое окно процедуры «Факторный анализ»
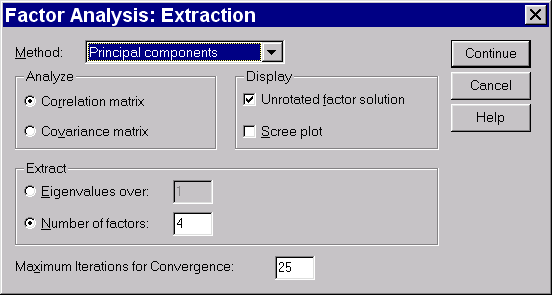
Рис. 9. Выбор метода в факторном анализе

Рис. 10. Зададим опции вывода

Вы можете попасть на эту страницу по одному из следующих адресов:
http://learn.at/infoscope/Statistics/data_analysis/case_studies/protein/index.html
http://read.at/infoscope/Statistics/data_analysis/case_studies/protein/index.html
http://now.at/infoscope/Statistics/data_analysis/case_studies/protein/index.html
Дата последней модификации: 20 сентября 2000 г.