![]()
![]()
В данном тексте я иллюстрирую взаимодействие сезонного разложения временного ряда и регрессионных моделей. Данные содержат 64 наблюдения — ежедневно измерялось количество посетителей кафе, записывались средние по месяцам (источник данных пожелал остаться неизвестным). Посмотрим, что можно сказать о перспективах кафе. Для анализа данные переведены в формат SPSS. В приложении показано, как в SPSS получить основные результаты.
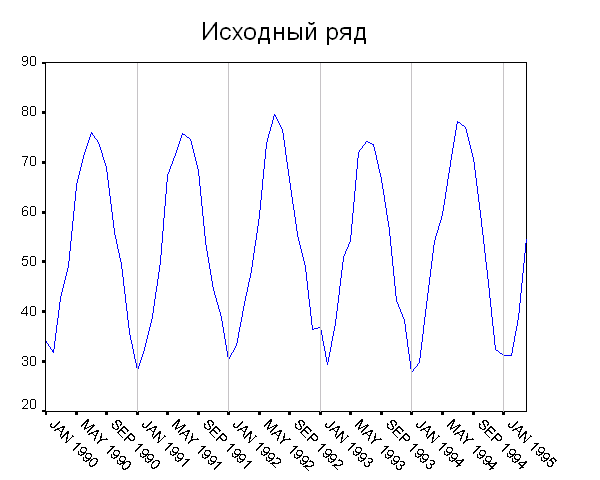
Естественно, начинать нужно с всегда рекомендуемого визуального анализа
(рис. 1).
Пожалуй, единственное, что я здесь вижу – это явственную
сезонную компоненту. При этом, поскольку дисперсия ряда вроде бы не
зависит от текущего уровня, здесь, видимо, подходит аддитивная
модель, согласно которой
yt = Tt +
St +
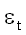 ,
где Tt – тренд,
St – сезонная
компонента,
– ошибка. Для
разделения ряда на компоненты использована процедура SPSS Seasonal
Decomposition (сезонная декомпозиция).
,
где Tt – тренд,
St – сезонная
компонента,
– ошибка. Для
разделения ряда на компоненты использована процедура SPSS Seasonal
Decomposition (сезонная декомпозиция).
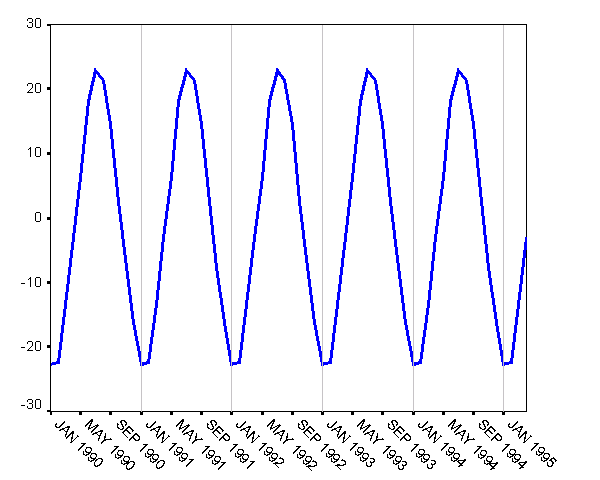
Рассмотрим, прежде всего, график сезонной компоненты (рис. 2). Посмотрите-ка: похоже, что наибольшее количество клиентов в наше кафе приходят летом, наименьшее – под Новый Год! Наше кафе торгует прохладительными напитками и мороженым?
Рис. 1. Среднее количество клиентов в день по месяцам
Рис. 2. Чем торгует наше кафе? Почему максимумы летом?
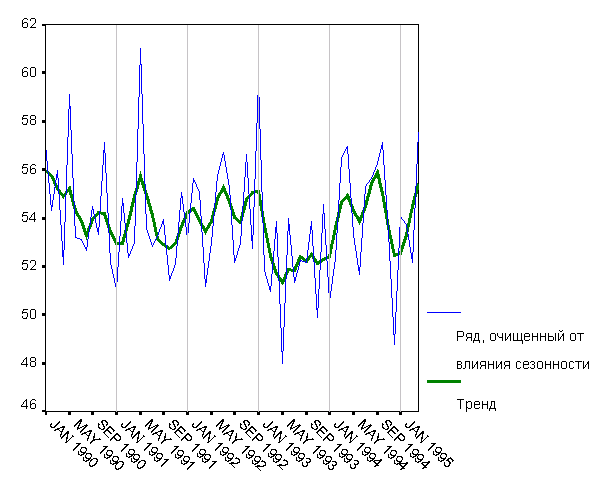
Рис. 3. Аддитивная модель сезонной декомпозиции
Рассмотрим теперь график, на котором представлены тренд ряда и ряд с исключенной сезонностью (рис. 3). Видно что-нибудь, кроме того, что данные с исключенной сезонной компонентой демонстрируют довольно сильную вариабельность?
Можем ли мы сказать что-нибудь полезное о тренде? Прежде всего, хочется заметить, что тренд, по-видимому, не линеен. Попробуем поискать наилучшую зависимость тренда от времени. Для этого использована процедура SPSS Curve Estimation, позволяющая оценить сразу несколько одномерных регрессий.
В нижеследующей таблице представлены результаты подгонки:
Dependent
Mth
Rsq
d.f.
F
Sigf
b0
b1
b2
b3
тренд
LIN
.048
62
3.11
.083
54.306
-.014
тренд
POW
.118
62
8.27
.006
55.287
-.008
тренд
INV
.138
62
9.93
.002
53.637
3.039
тренд
QUA
.163
61
5.95
.004
55.226
-.097
.0013
тренд
CUB
.167
60
4.00
.012
55.028
-.062
-.00006
.000014
Рис. 4. Результаты подгонки нескольких одномерных регрессий
Мы видим, что, как и ожидалось, линейная модель не значима, а кубическая модель значима на уровне 0.05 и не значима на уровне 0.01. Мы не будем рассматривать их далее. Итак, нам предстоит выбирать среди следующих трех моделей:
гипербола (inv): клиенты = 53.637 + 3.039/N
квадрат (qua):
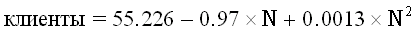
степень (pow):
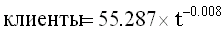
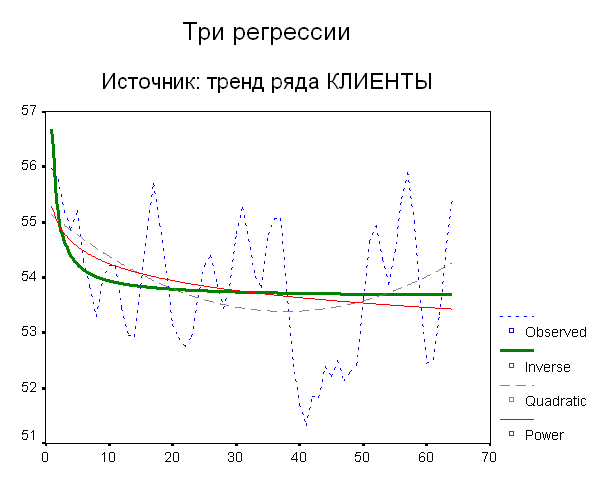
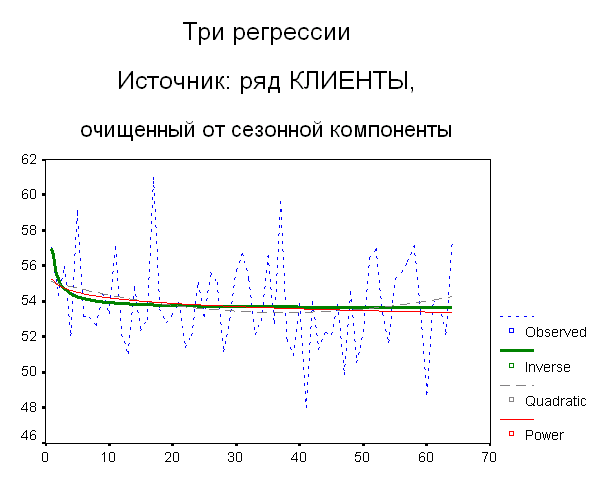
Модели представлены здесь в порядке возрастания показателя качества, которым служит коэффициент детерминации (столбец Rsq). На рис. 5 (а) представлены графики найденных зависимостей. Дополнительным подтверждением разумности примененной процедуры выделения тренда хочется считать то, что аналогичные регрессии для исходного ряда, «очищенного» от влияния сезонности, приведенные на рис. 5 (б), полностью аналогичны.
(а)
(б)
Рис. 5. Три регрессионные модели для:
(а) выделенного тренда;
(б) исходного ряда, очищенного от сезонной компоненты
Посмотрите, мы получили модели на любой вкус. Гиперболическая модель (inv) говорит, что среднее количество клиентов, а, значит, и прибыль, постепенно уменьшаясь, приближается к некоему минимуму, квадратичная (qua) утверждает, что худшее позади и началось время успеха и постепенного роста благосостояния, степенная же модель (pow) предсказывает медленное, но неуклонное сползание в финансовую пропасть.
Какую же модель выбрать? Ну, конечно, этот вопрос лежит за пределами статистики. Но все-таки, чего ожидать в ближайшем будущем? Ведь от ответа зависят и ближайшие планы владельца кафе. В самом деле, если верна inv-модель, нужно что-то менять, чтобы количество клиентов начало возрастать, если принять pow-модель, нужно срочно начинать санационные мероприятия. Квадратичная же модель позволяет, пусть временно, попочивать на лаврах. Так какую же модель выбрать?
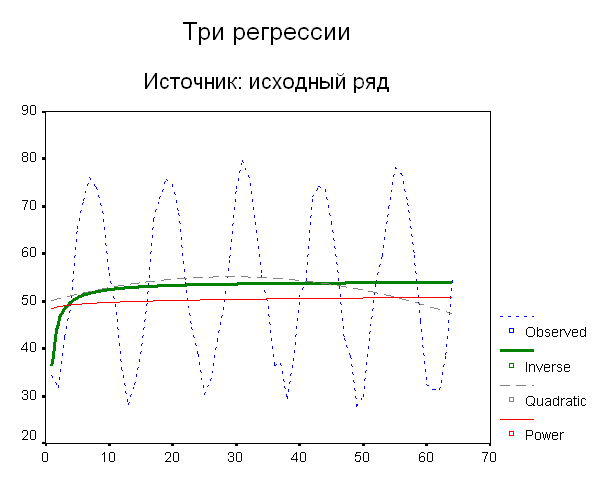
Чтобы еще ухудшить жизнь читателя, я предлагаю в дополнение к диаграмме, приведенной на рис. 5 (а), рассмотреть еще результаты работы той же процедуры Curve Estimation, примененные к исходным данным, до освобождения их от сезонной компоненты. Видите совсем разное поведение аппроксимирующих кривых? Так какую же модель выбрать?
Рис. 6. Результаты работы процедуры Curve Estimation на исходных данных
Здесь показано, каким образом в SPSS можно получить некоторые из приведенных результатов.
Наши данные начинаются в январе 1990 г. и кончаются в апреле 1995 г. Выбираем в меню
Data
Define Dates…
В появившемся диалоговом окне (рис. 7) устанавливаем
Cases Are: Years, months
First Case is:
Year: 1990
Month: 1
После нажатия кнопки OK будут созданы переменные year_, month_, date_ с очевидной семантикой.
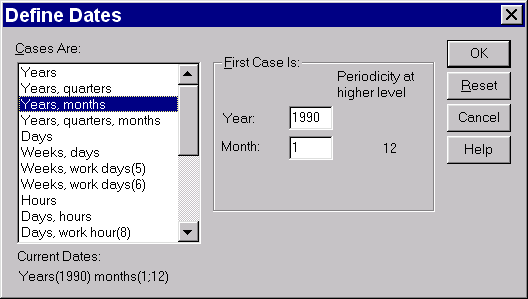
Рис. 7. Диалоговое окно «Задание начальной даты»
Нужные нам значения в файле cafe.sav содержит переменная клиенты. Выбираем в меню
Graphs
Sequence… (рис. 8)
 Variables:клиенты
Time Axis Labels: date_
Variables:клиенты
Time Axis Labels: date_
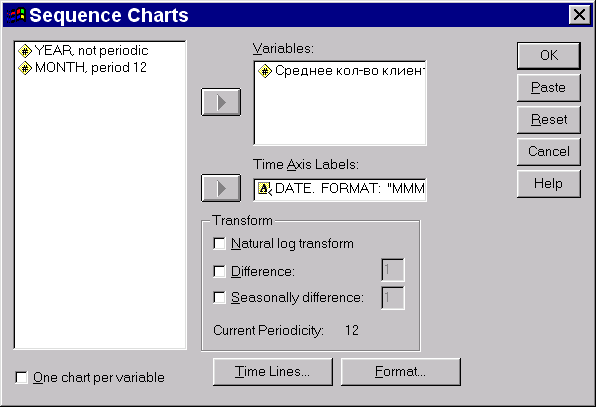
Рис. 8. Диалоговое окно «График последовательности»
Выбираем в меню
Statistics
Time Series
Seasonal Decomposition…
Variables:клиенты
Model
 Additive
Additive
В результате будут созданы следующие переменные:
Для этого применим процедуру Curve Estimation, которая позволяет построить сразу несколько одномерных регрессий:
Statistics
Regression
Curve Estimation…
Dependent: клиенты
Independent: time
Models:
 Inverse
Quadratic
Power
Inverse
Quadratic
Power
Вот как выглядит соответствующее диалоговое окно:
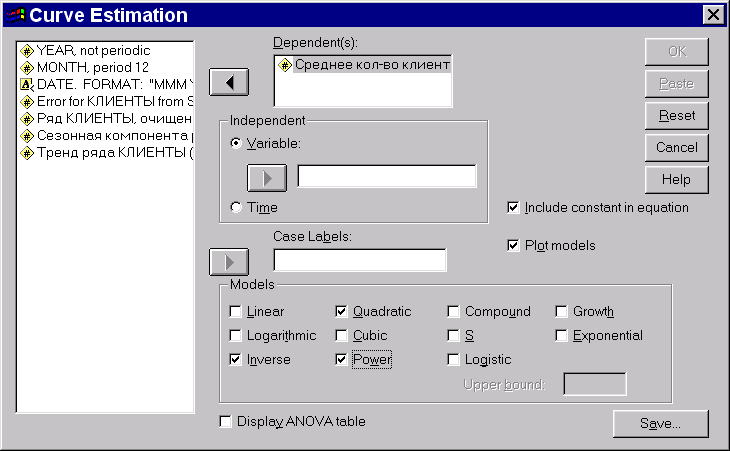
Рис. 9. Заполненное диалоговое окно процедуры Curve Estimation

Вы можете попасть на эту страницу по одному из следующих адресов:
http://learn.at/infoscope/Statistics/data_analysis/case_studies/cafe/index.html
http://read.at/infoscope/Statistics/data_analysis/case_studies/cafe/index.html
http://now.at/infoscope/Statistics/data_analysis/case_studies/cafe/index.html
Дата последней модификации: 20 сентября 2000 г.