![]()
![]()
Данные об авиаперевозках
В данном тексте анализируются данные о пассажирских перевозках на международных авиалиниях (месячные итоги в тысячах пассажиров) с января 1949 по декабрь 1960. В течение этого времени наблюдался поразительный рост активности коммерческих авиалиний. Соответственно, ряд демонстрирует возрастающий тренд; и, конечно, количество пассажиров подвержено сезонным колебания. Данные использованы в основополагающей книжке Бокса и Дженкинса под именем ряда G; конечно, вы можете скачать их.
Анализ производится с помощью пакета SPSS. Хотя я предполагаю некоторое знакомство с ним, для всех сколько-нибудь нетривиальных случаев я в приложении описываю необходимую последовательность действий. Кроме того, те, кто по какой-либо причине не могут или не любят читать тексты "он-лайн", могут скачать этот же текст в в формате RTF.
Как водится, мы начинаем с визуального анализа имеющихся данных. Из графика на рис. 1 мы непосредственно усматриваем три свойства нашего ряда:
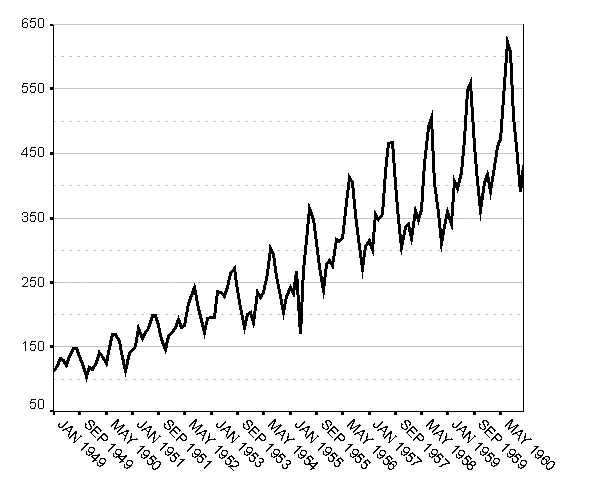
Рис. 1. Данные об авиаперевозках
Таким образом, естественно начать с модели, основанной на сезонном разложении нашего ряда. Поскольку сезонные колебания возрастают, первой следует исследовать мультипликативную декомпозицию. Мы построим линейную аппроксимацию тренда, выделенного декомпозицией, после чего умножим ее на выделенную сезонную компоненту, получив, таким образом, самую первую модель нашего ряда.
Поскольку наши модели необходимо проверять, разобьем период наблюдения на два интервала (часто и их называют периодами; я буду пользоваться этими терминами как синонимами) – обучающий и контрольный. Оценивать параметры модели мы будем на обучающем интервале (с января 1949 года по декабрь 1959), а проверять построенные модели – на контрольном интервале (январь-декабрь 1960 года).
В этом разделе мы рассмотрим две модели: мультипликативную декомпозицию исходного ряда G и аддитивную декомпозицию его логарифма. Сравнение остатков обеих моделей позволит нам выбрать лучшую из них.
График ряда, приведенный на рис. 1, демонстрирует возрастание амплитуд сезонных колебаний, что является прямым показанием к использованию мультипликативной сезонной декомпозиции. Не забудем выделить обучающий интервал (см. приложение), после чего запустим декомпозицию.
Вывод 1. Результаты процедуры Seasonal Decomposition
| The following new variables are being created: | |
| Name | Label |
| ERR_1 | Error for G from SEASON, MOD_1 MUL EQU 12 |
| SAS_1 | Seas adj ser for G from SEASON, MOD_1 MUL EQU 12 |
| SAF_1 | Seas factors for G from SEASON, MOD_1 MUL EQU 12 |
| STC_1 | Trend-cycle for G from SEASON, MOD_1 MUL EQU 12 |
Поскольку я собираюсь строить модель и для логарифма переменной G, я переименую эти переменные, заменив в их «именах по умолчанию» цифру 1 на G; таким образом, в дальнейшем я буду ссылаться на переменные SAS_G, STC_G и т.д.
|
(а) |
Seasonal Index Period (* 100)1 91,094 2 88,375 3 100,971 4 96,373 5 98,279 6 111,437 7 123,152 8 121,639 9 105,864 10 92,113 11 80,354 12 90,349 (б) |
Рис. 2. Период сезонной компоненты (мультипликативная декомпозиция G)
На графике рис. 2(а) мы видим один период сезонной компоненты, полученной сезонной декомпозицией с мультипликативной моделью; на рис. 2(б) приведены сами значения. Пики в точках, соответствующих маю и июлю-августу, трудно объяснить тягой простых американцев к очередным трудовым свершениям.
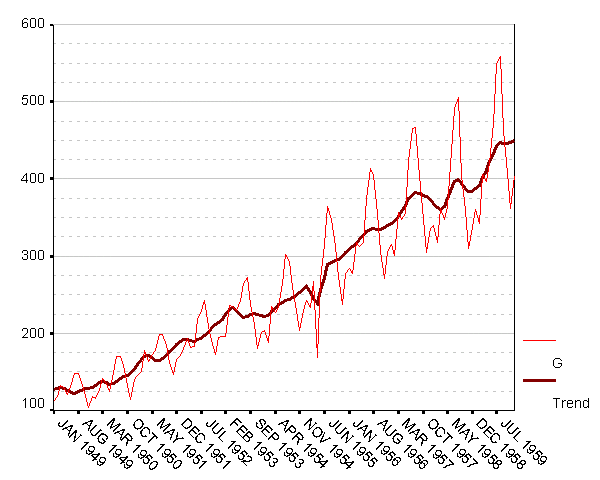
Рис. 3. Ряд G и его тренд
На графике рис. 3 представлены значения исходного ряда G и STC_G – его трендовой компоненты. Рассмотрим возможные модели тренда. Для этого «напустим» на него процедуру Curve Estimation (я заодно решил проверить и регрессии для исходного ряда).
Вывод 2. Результаты процедуры Curve Estimation
| Dependent | Mth | Rsq | df | F | Sigf | b0 | b1 | b2 |
| STC_G | LIN | ,977 | 130 | 5575,13 | ,000 | 92,1310 | 2,5472 | |
| STC_G | QUA | ,987 | 129 | 4759,21 | ,000 | 113,923 | 1,5714 | ,0073 |
| G | LIN | ,838 | 130 | 670,82 | ,000 | 91,5775 | 2,5588 | |
| G | QUA | ,845 | 129 | 352,63 | ,000 | 112,967 | 1,6010 | ,0072 |
Первое, что мы видим: модели, построенные для исходного ряда и выделенного тренда, практически одинаковы, что можно интерпретировать, как (пусть лишь косвенное) свидетельство адекватности использованной модели декомпозиции. Поскольку, кроме того, коэффициенты детерминации для моделей тренда выше, чем для моделей исходного ряда, дальше обсуждаются лишь модели тренда.
Коэффициенты детерминации для запрошенных моделей довольно близки: для линейной модели R2 = 0.977, для квадратичной R2 = 0.987. Поскольку всегда предпочтительнее использовать более простую модель, предлагается использовать линейную модель, которая задается следующим уравнением:
Lt = 92,1310 + 2,5472*t.
Если теперь через St обозначить периодическую компоненту, то модель для нашего ряда будет выглядеть следующим образом: Gt = Lt * St.
Перед тем, как вычислить эти модельные значения, вспомним, что мы работаем не на всем интервале и не забудем «вернуться» к полному интервалу наблюдений. Не забудем, кроме того, что у SAF_G не хватает последних 12 значений, – добавим их.
Чтобы вычислить новую переменную, содержащую значения модели, выберем в меню Transform пункт Compute. В появившемся диалоговом окне в поле Target Variable введем имя новой переменной LIN_G, а в поле Numeric expression введем (92.1310 + 2.5472*$casenum)*saf_g. Плоды трудов представлены на нижеследующем графике.
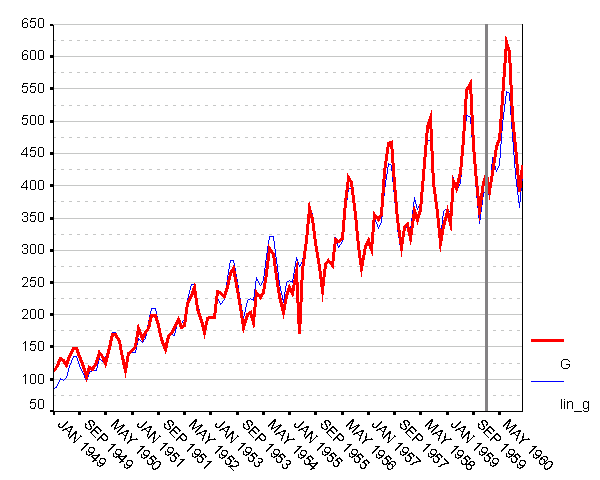
Рис. 4. Исходный ряд и его «мультипликативно-регрессионная» модель
То, что мы видим на рис. 4, выглядит вполне достойно. Конечно, для пущей убедительности неглупо было бы рассмотреть остатки и их статистики, но основные недостатки модели видны и невооруженным глазом. Во-первых, модель недостаточно хорошо отслеживает тонкие особенности поведения ряда: сравните, например, ряд и его модель в апреле 1955 года. Во-вторых, что лично мне представляется даже более важным, амплитуды колебаний у ряда растут быстрее, чем у модели. В следующем разделе мы посмотрим, можно ли исправить ситуацию применением логарифмического преобразования.
Читателю, не удовлетворенному решением использовать линейную модель тренда, я предлагаю испробовать отвергнутую квадратичную.
Мы начинаем с вычисления переменной LG, содержащей значения натурального логарифма исходного ряда G, после чего не забудем опять ограничиться интервалом обучения и запустим аддитивную сезонную декомпозицию (в приложении описаны телодвижения, необходимые для того, чтобы сделать это в SPSS).
Вывод 3. Результаты процедуры Seasonal Decomposition
| The following new variables are being created: | |
| Name | Label |
| ERR_2 | Error for LN_G from SEASON, MOD_1 ADD EQU 12 |
| SAS_2 | Seas adj ser for LN_G from SEASON, MOD_1 ADD EQU 12 |
| SAF_2 | Seas factors for LN_G from SEASON, MOD_1 ADD EQU 12 |
| STC_2 | Trend-cycle for LN_G from SEASON, MOD_1 ADD EQU 12 |
Снова переименуем переменные – заменим суффикс 2 на LG.
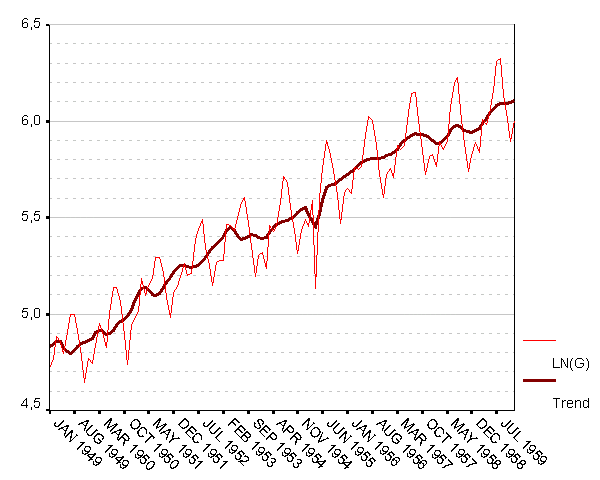
Рис. 5. Ряд lg и его тренд – аддитивная сезонная декомпозиция
На этом графике мы приводим ряд LG, полученный логарифмированием значений исходного ряда G, и STC_LG – трендовой компоненты ряда LG, полученной в результате его сезонной декомпозиции. Похоже, трендовая компонента выглядит «более линейной», чем раньше. Чтобы подкрепить свои ощущения числами, снова (слово «снова» здесь и ниже в этом разделе относится к аналогичным действиям, проделанным для ряда G в предыдущем разделе) «напустим» на наши данные процедуру Curve Estimation (и снова заодно проверим регрессии как для исходного ряда LG, так и для его тренда STC_LG).
Вывод 4. Результаты процедуры Curve Estimation для ряда LG
| Dependent | Mth | Rsq | d.f. | F | Sigf | b0 | b1 | b2 |
| LG | LIN | ,884 | 130 | 991,05 | ,000 | 4,8009 | ,0103 | |
| LG | QUA | ,888 | 129 | 512,05 | ,000 | 4,7401 | ,0130 | -2,E-05 |
| STC_LG | LIN | ,983 | 130 | 7713,48 | ,000 | 4,7999 | ,0103 | |
| STC_LG | QUA | ,988 | 129 | 5183,15 | ,000 | 4,7408 | ,0129 | -2,E-05 |
Мы снова видим – модели, построенные для исходного ряда и выделенного тренда, практически одинаковы. Совпадение опять можно интерпретировать, как свидетельство адекватности использованной модели декомпозиции. Опять коэффициенты детерминации для моделей тренда выше, чем для моделей исходного ряда, так что мы опять будем работать лишь с моделями, построенными для тренда.
Коэффициенты детерминации для запрошенных моделей опять очень близки: для линейной модели R2 = 0.983, а для квадратичной R2 = 0.988. Поэтому для тренда предлагается использовать линейную модель, которая задается следующим уравнением:
Lt =4.7999 + 0.0103*t.
Снова обозначая периодическую компоненту через St, получаем следующую модель нашего ряда: LGt = Lt + St.
Снова не забудем дополнить циклическую компоненту последними 12-ю значениями и вернуться к работе со всеми наблюдениями, после чего вычислим переменную LIN_LG, задав в поле Numeric expression выражение exp(4.7999 + 0.0103*$casenum + SAF_LG).
На нижеследующем рисунке приведен график (ср. с графиком на рис. 4), иллюстрирующий плоды наших трудов.
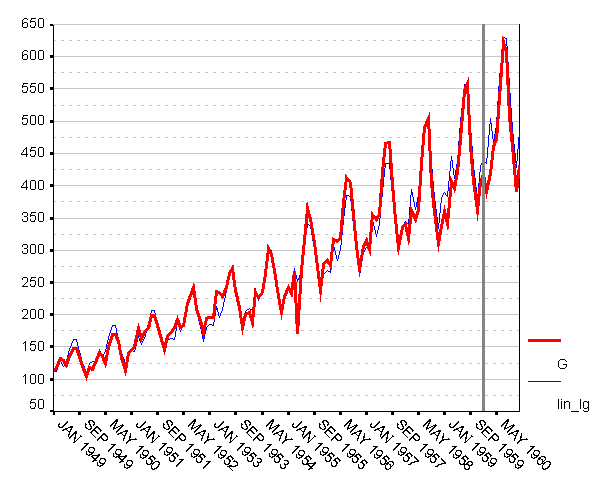
Рис. 6. Исходный ряд и его «аддитивно-регрессионная» модель
Из графиков на рис. 4 и 6 я могу усмотреть лишь, что обе «сезонно-декомпозиционные» модели ведут себя примерно так же, как и моделируемый ряд. Лично мне кажется, что аддитивно-сезонная модель ведет себя чуточку лучше. Чем бы это подкрепить ощущения?
Первое, что необходимо сделать, – рассмотреть остатки этих моделей. Сначала – график, конечно. Уже описанным способом создадим переменную RES_G, равную разности между исходным рядом G и его моделью LIN_G, и переменную RES_LG – разность между G и LIN_LG. На нижеследующем рисунке приведен график, изображающий эти две переменные.
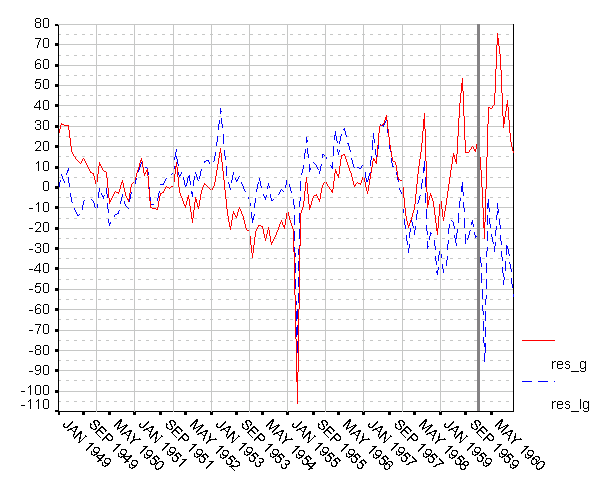
Ничего такого уж особенного на этом графике, вроде бы, не видно; обращает на себя внимание лишь глубокий минимум обеих кривых в точке, соответствующей апрелю 1955, да то, что справа от выделенной перпендикулярной линии (январь 1960) вариабельность обеих кривых, кажется, возрастает. Стандартные регрессионные предположения не выполняются для обеих кривых:
Быть может, удастся выбрать модель, рассмотрев дескриптивные статистики обеих кривых? Нет, меньший размах RES_LG «компенсируется» большим средним RES_G, меньшая асимметрия RES_G – ее большим эксцессом. Увы, обычные дескриптивные статистики не позволяют сказать, что одна из кривых «лучше».
Таблица 1. Дескриптивные статистики
|
|
|
Статистика |
Стд. ошибка |
|
RES_G |
N |
144 |
|
|
|
Размах |
181,37 |
|
|
|
Среднее |
2,8265 |
|
|
|
Стд. откл. |
20,6222 |
|
|
|
Дисперсия |
425,277 |
|
|
|
Асимметрия |
-0,320 |
0,202 |
|
|
Эксцесс |
5,596 |
0,401 |
|
RES_LG |
N |
144 |
|
|
|
Размах |
124,14 |
|
|
|
Среднее |
-3,1105 |
|
|
|
Стд. откл. |
19,8356 |
|
|
|
Дисперсия |
393,450 |
|
|
|
Асимметрия |
-1,140 |
0,202 |
|
|
Эксцесс |
2,889 |
0,401 |
Я был бы рад, если бы заинтересованный читатель нашел статистику, позволяющую выбрать из этих двух моделей лучшую.
В данном приложении описывается, как в SPSS получить некоторые из приведенных здесь графиков и результатов.
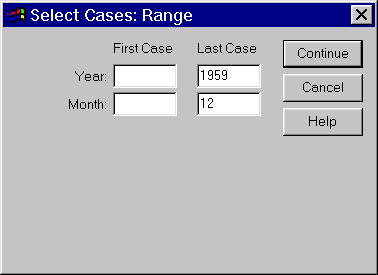
Чтобы ограничить оценку модели обучающим периодом, отбросим точки последнего года:
Data
![]() Based on time or case range
Based on time or case range
Range...
Last Case
Вот какое диалоговое окно должно получиться:
Не забудем, что когда нам понадобится проверять результаты на всех имеющихся данных, нужно будет отменить наложенное ограничение:
Data
![]() All cases
All cases
Выберите в меню
Statistics
Чтобы запустить процедуру сезонной декомпозиции ряда G, в появившемся диалоговом окне перенесите переменную G в список обрабатываемых, задайте мультипликативную модель:
![]() Variable(s): G
Variable(s): G
![]() Multiplicative
Multiplicative
Чтобы запустить сезонную декомпозицию ряда LG, в появившемся диалоговом окне перенесите в список обрабатываемых переменную LG и выберите аддитивную модель:
![]() Variable(s): LG
Variable(s): LG
![]() Additive
Additive
График на рис. 3(а) получен редактированием графика переменной SAF_G. Чтобы получить сам график выберите в меню
Graphs
После этого кликните по графику дважды, чтобы войти в режим редактирования. В режиме редактирования выберите в меню
Series
В появившемся окне оставьте лишь метки, относящиеся к одному году – остальные пометьте (не забудьте про клавишу Shift) и перенесите в подокно Omit. После этого не поленитесь отредактировать оставшиеся метки, убрав из них номер года.
Чтобы вычислить новую переменную LG, содержащую логарифмы значений исходного ряда G, выберем в меню Transform пункт Compute. В появившемся диалоговом окне в поле Target Variable введем имя новой переменной LG, в списке Function выберем LN и перенесем эту функцию в поле Numeric expression. В качестве аргумента зададим G.
Диалоговое окно Compute предлагает практически неограниченный ассортимент преобразований исходных переменных.
Процедура Curve Estimation предназначена для быстрой подгонки нескольких одномерных регрессионных зависимостей. Задав зависимую и независимую переменную (ею может быть и «время», т.е., попросту говоря, порядковый номер измерения), мы помечаем одну или несколько из набора доступных зависимостей. В результате получаем запрошенные регрессии, коэффициент детерминации для каждой из них и график с регрессионными кривыми. Можно запросить также вывод таблиц ANOVA.
Чтобы запустить процедуру для переменных STC_G и G, задайте
Statistics
![]() Dependent(s): STC_G, G
Dependent(s): STC_G, G
Independent
![]() Time
Time
Models
![]() Linear
Linear
![]() Quadratic
Quadratic
Процедура Descriptives позволяет получить стандартный набор статистик, описывающих распределение переменной. Чтобы запустить эту процедуру, выберите
Statistics
В появившемся диалоговом окне переместите в список Variables интересующие вас переменные, после чего кликните по кнопке Options... и выберите подходящие статистики.

На эту страницу можно попасть по одному из следующих адресов:
http://learn.at/infoscope/Statistics/data_analysis/case_studies/Airlines/index.html
http://read.at/infoscope/Statistics/data_analysis/case_studies/Airlines/index.html
http://now.at/infoscope/Statistics/data_analysis/case_studies/Airlines/index.html
Дата последней модификации: 18 сентября 2000 г.