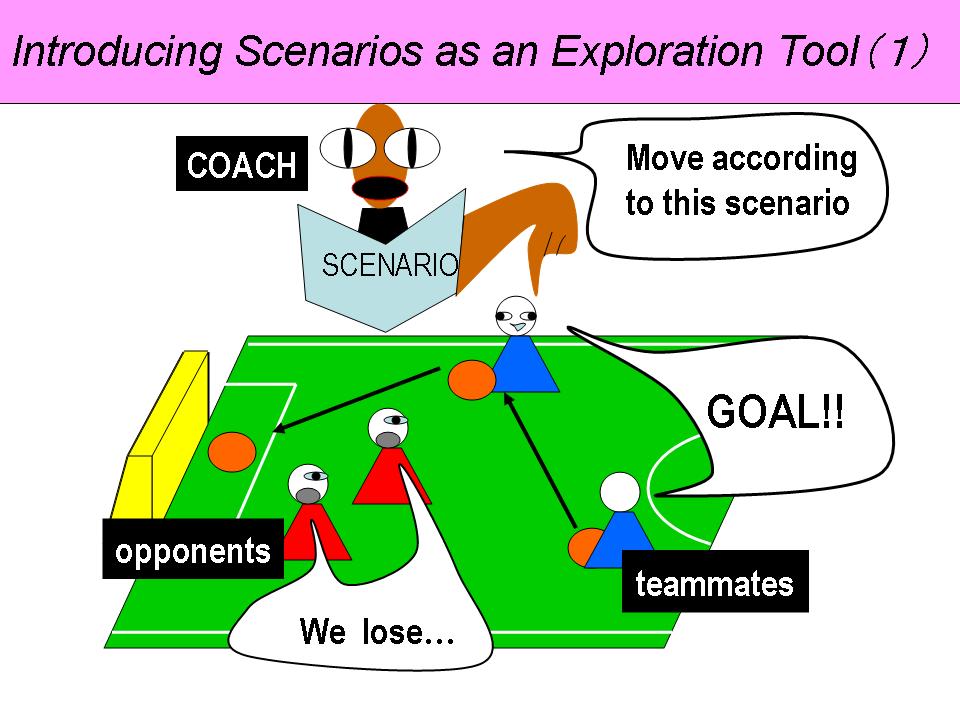
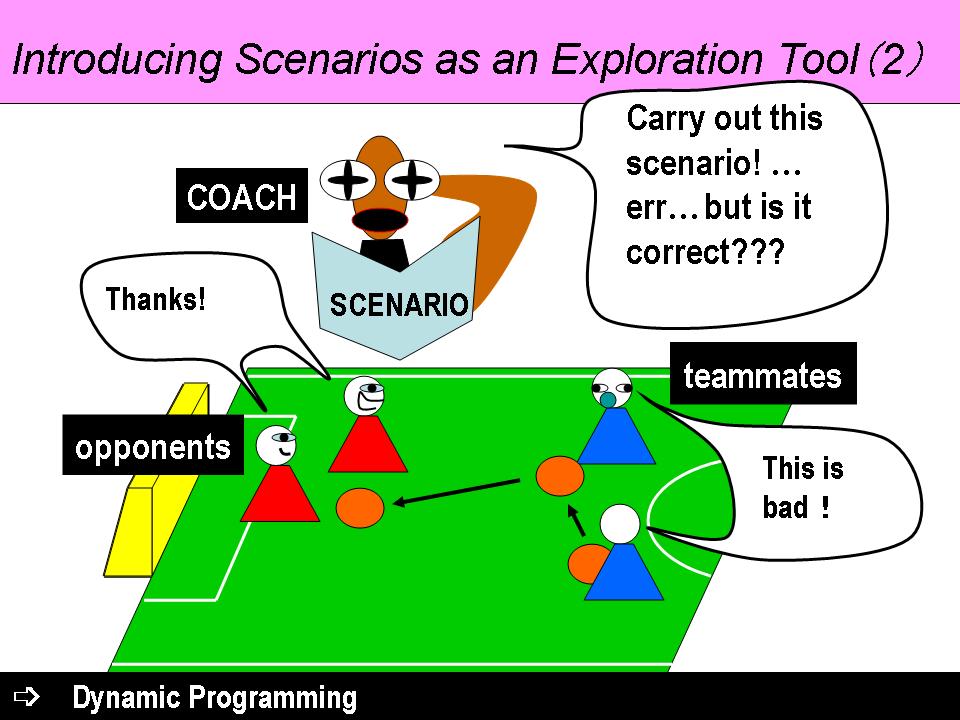
|
At first sight, this may seem a simple act for the coach, unfortunately the coach sometimes gives out flawed and incorrect commands. To put it more accurately, scenario commands by the coach can only be of practical use at a particular state of the team-mate robots. In order to refine and to discard incorrect commands, the coach itself needs to undergo learning, which is the main point of this research. By applying the Dynamic Programming to the learning of the coach, more refined commands can be obtained, and we are on our way to building an efficient, accurate coaching system which can acquire team play. |
|