|
MODULO I: ORGANIZACION DE LA CPU Y EL NIVEL LOGICO
1.1 Organizacion del CPU
1.2 Estructura de una instruccion en bajo nivel
1.3 Ejecucion de Instrucciones
1.4 Procesadores CISC y RISC
1.5 Instrucciones y Procesadores de nivel Paralelo
Descargar modulo
Introducción Volver
La organización de una computadora sencilla orientada hacia los buses se muestra en la figura 2-.1. La CPU (unidad central de procesamiento) es el “cerebro” de la computadora. SU función es ejecutar programas almacenados en la memoria principal buscando sus instrucciones y examinándolas para que después ejecutarlas una tras otra. Los componentes están conectados por un bus, que es una colección de alambres paralelos para transmitir direcciones, datos y señales de control. Los buses pueden ser externos a la CPU, cuando la conectan a la memoria y a los dispositivos de E/S, pero también internos, como veremos en breve.
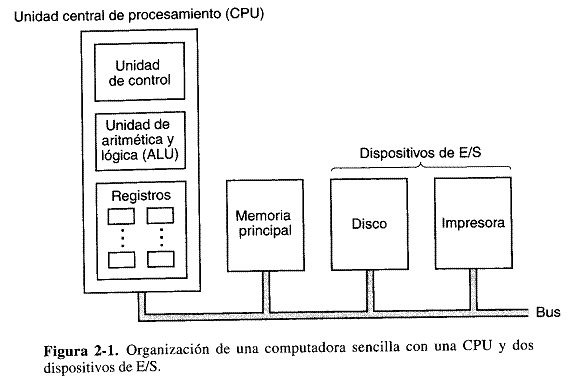
La CPU se compone de varias partes. La unidad de control se encarga de buscar instrucciones de la memoria principal y determinar su tipo. La unidad de aritmética y lógica realiza operaciones como suma y AND boleeano necesarias para ejecutar las instrucciones.
La CPU también contiene una memoria pequeña de alta velocidad que sirve para almacenar resultados temporales y cierta información de control. Esta memoria se compone de varios registros, cada unos de los cuales tiene cierto tamaño. Cada registro puede contener un número, hasta algún máximo determinado por el tamaño del registro. Los registros pueden leerse y escribirse a alta velocidad porque están dentro de la CPU.
El registro mas importante es el contador de programa (PC, program counter), que apunta a la siguiente instrucciones que debe buscarse par ejecutarse. El nombre “contador de programa” es un tanto engañoso porque no tiene nada que ver con contar, pero es un término de uso universal. Otro registro importante es el registro de instrucciones (IR, instruction register), que contiene la instrucciones que se esta ejecutando. Casi todas las computadoras tienen varios registros más, algunos de propósito general y otros para fines específicos.
1.1 Organización del CPU Volver
En la figura 2-2 se muestra con más detalle la organización interna de una parte de una CPU Von Neumann típica. Esta parte se llama camino de datos y consiste en los registros (generalmente de 1 a 32), la ALU (unidad de aritmética y lógica,) y varios buses que conectan a los componentes. Los registros se alimentan dos registros de entrada de la ALU, rotulados A y B en la figura. Estros registros contiene las entradas de la ALU mientras esta calculando. EL camino de datos es muy importante en todas las maquinas y lo examinaremos con gran detalle a todo lo largo del libro.
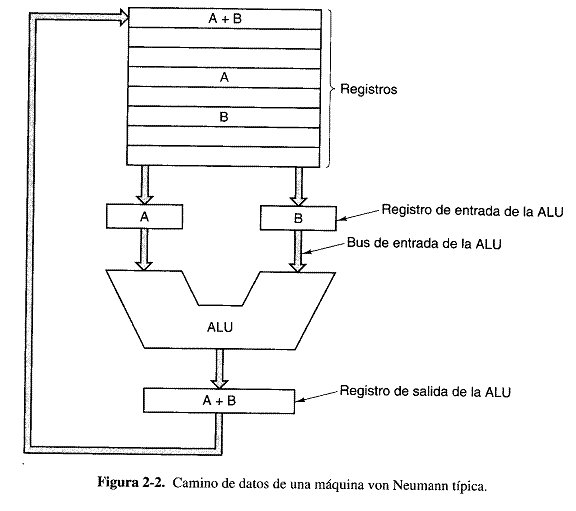
La ALU, suma, resta y realiza otras operaciones simples con sus entradas, y produce un resultado en el registro de salida. EL contenido de este registro de salida se envía a un registro, que posteriormente se escribe (es decir, se guarda) en memoria, si se desea. No todos los diseños tienen los registros A, B y de salida. EN el ejemplo se ilustra la suma.
Casi todas las instrucciones pueden dividirse en una de dos categorías: registros-memoria o registro-registro. Las instrucciones registro-memoria permiten buscar palabras de la memoria a los registros. Donde pueden utilizarse como entradas de la ALU en instrucciones subsecuentes, por ejemplo. (Las “palabras” son las unidades de datos que se transfieren entre la memoria y los registros. Una palabra podría ser un entero. Trataremos la organización de la memoria mas adelante en este capitulo. ) Otras instrucciones registros-memoria permiten almacenar el contenido de un registro en la memoria.
La otra clase de instrucciones es la de registro-registro. Una instrucciones registro-registro típica busca dos operándoos de los registros, los coloca en los registros de entrada de la ALU, realiza alguna operación de ellos (por ejemplo suma o AND booleano) y coloca el resultado en uno de los registros. El proceso de hacer pasar dos operándoos por la ALU y alienar el resultado se le llama ciclo de camino de datos y es el corazón de casi todas las CPU. En gran medida, este ciclo define lo que la maquina puede hacer. Cuanto más rápido es el ciclo de datos, mas rápidamente opera la maquina.
1.2 Ejecución de instrucciones
La CPU ejecuta cada instrucción en una serie de pasos pequeños. A grandes rasgos, los pasos son los siguientes:
- Buscar la siguiente instrucción de la memoria y colocarla en el registro de instrucciones.
- Modificar el contador de programa de modo que apunte a la siguiente instrucción.
- Determinar el tipo de la instrucción que se trajo.
- Si la instrucción utiliza una palabra de la memoria, determinar dónde está.
- Buscar la palabra, si es necesario, y colocarla en un registro de la CPU.
- Ejecutar la instrucción.
- Volver al paso 1 para empezar a ejecutar la siguiente instrucción.
Esta sucesión de pasos se conoce como el ciclo de buscaqueda-decodificacion-ejecucion, y es fundamental para el funcionamiento de todas las computadoras.
Esta descripción de cómo funciona una CPU se parece mucho a un programa escrito en español, La figura 2-3 muestra este programa informa escrito como método java (ósea, procedimiento) llama interpretar. La maquina se esta interpretando tiene dos registros que los programas de usuario pueden ver: el contador de programa (PC), para seguir la pista a la dirección siguiente instrucción que debe buscarse, y el acumulador (AC), para acumular resultados aritméticos. También tiene registros internos para retener la instrucción en curso durante su ejecución (Instr), el tipo de la instrucción en curso (instr_type), la dirección del operando de la instrucción (data_loc) y el operando mismo (data). Se supone que las instrucciones contienen una sola dirección de memoria. La posición de memoria direccionala contiene el operando; por ejemplo, el dato que debe sumarse al acumulador.
EL simple hecho de que sea posible escribir un programa capaz de imitar la función de una CPU demuestra que un programa no tiene que ejecutarse con una CPU de hardware que consiste en una caja llena de circuitos. EN vez de ello, el programa puede ejecutarse haciendo que otro programa busque, examine y ejecute sus instrucciones. Un programa (como el de la figura 2-3) que busca, examina y ejecuta las instrucciones e otro programa se llama intérprete.

Esta equivalencia entre procesadores en hardware e intérpretes tiene importantes implicaciones para la organizacion de las computadoras y el diseño de los sistemas de computación. Después de haber especificado el lenguaje maquina, L, para una computadora nueva, el equipo de diseño puede decidir si quiere construir un procesador eh hardware que ejecute directamente los programas en L o si prefiere escribir un interprete que interprete programas en L, si optan por escribir un interprete, también deberán crear una maquina en hardware que ejecute el interprete. También son posibles ciertas construcciones hibridas, con ejecución parcial en hardware y también algo de interpretación de software.
Un interprete descompone las instrucciones de su maquina objetivo en pasos pequeños. Por consiguiente, la maquina en la que el interprete se ejecuta puede ser mucho mas simple y menos costosa que un procesador en hardware para la maquina objetivo. Este ahorro es mas importante aun si la maquina objetivo tiene un gran número de instrucciones y estas son complicadas, con muchas opciones. EL ahorro se logra básicamente por la sustitución de hardware por software (el interprete)
1.4 Introducción RISC VS CISC Volver
Las primeras computadoras tenían conjuntos de instrucciones pequeños y sencillos, pero la búsqueda de computadoras más potentes llevo, entre otras cosas, a instrucciones individuales más potentes. Casi desde el principio se descubrió que con instrucciones más complejas a menudo era posible acelerar la ejecución de los programas, aunque las instrucciones individuales tardaran más en ejecutarse. Una instrucción de punto flotante es un ejemplo de instrucción más compleja. Otro ejemplo es el apoyo directo par acceder a los elementos de un arreglo. A veces la cosa era tan sencilla como observar que con frecuencia ocurrían las mismas dos instrucciones en sucesión, de modo que una sola instrucción podría realizar el trabajo de ambas.
Las instrucciones mas complejas eran mejores porque a veces hacían posible traslapar la ejecución de operaciones individuales o ejecutarlas en paralelo empleando diferente hardware. En las costosas computadoras de alto rendimiento el costo de este hardware adicionar podía justificarse fácilmente. Fue así como las computadoras de alto precio y mejor rendimiento comenzaron a tener mucho más instrucciones que las de bajo costo. Sin embargo, el creciente costo de la creación de software las necesidades de compatibilidad de las instrucciones hicieron necesario implementar instrucciones complejas incluso en las computadoras de bajo costo en las que el precio era mas importante que la velocidad.
Hacia fines de los cincuenta, IBM ( que entonces era la compañía que dominaba el campo de las computadoras) se había dado cuenta de las muchas ventajas, tanto para IBM como para sus clientes, que tenia que manejar una sola familia de maquinas, todas las cuales ejecutaban las mismas instrucciones. IBM introdujo el término arquitectura para describir este nivel de compatibilidad. Una nueva familia de computadoras tenía una sola arquitectura pero muchas implementaciones diferentes, todas las cuales podían ejecutar el mismo programa, la única diferencia era el precio y la velocidad. Pero como construir una computadora de bajo costo que pudiera ejecutar todas las complejas instrucciones de las maquinas de alto costo y mayor rendimiento?
La respuesta fue la interpretación. Esta técnica, inicialmente sugerida por wikes(1951), permitió diseñar computadoras sencillas, de bajo costo, capaces de ejecutar un gran número de instrucciones. EL resultado fue la arquitectura IBM system/360, una familia de computadoras compatibles que abarcaba casi dos órdenes de magnitud, tanto en precio como en capacidad. Solo se usaba una implementación directa en hardware (es decir, no interpretaba) en los modelos mas caros.
Las computadoras sencillas con instrucciones interpretadas también tenían otros beneficios. Las más importantes eran:
- La capacidad para corregir en el campo de instrucciones males implementados, o incluso subsanar deficiencias de diseño en el hardware básico.
- la oportunidad de añadir nuevas instrucciones con un costo mínimo, aunque después de haber entregado la maquina.
- diseño estructurado que permítete crear, programar, y documentar instrucciones complejas de forma eficiente.
Cuando el mercado de las computadoras hizo explosión en la década de los setenta, y la capacidad de las maquinas creció rápidamente, la demanda de computadoras de bajo costo favoreció los diseños que utilizaban interpretes. La capacidad para adaptar el hardware y el intérprete a un conjunto de instrucciones específico surgió como un diseño mucho muy económico para los procesadores. Al avanzar a pasos agigantados la tecnología subyacente de los semiconductores, las ventajas de costro sobrepasaron las oportunidades de lograr mayor rendimiento, y las arquitecturas basadas en intérpretes se convirtieron en una forma convencional de diseñar computadoras. Casi todas las computadoras nuevas diseñadas en los setenta, desde las mini computadoras hasta las mainframes, se basaron en interpretación.
Hacia finales de esa década, el uso de los procesadores simples que ejecutaban intérpretes se había extendido a todos los modelos, con excepción de los más costosos y rápidos como la cray-1 y la serie cyver de control data. El uso de un intérprete eliminaba las limitaciones de costro inherentes a las instrucciones complejas, y las arquitecturas comenzaron a explorar instrucciones más complejas, sobre todo las formas de especificar los operandos a utilizar.
La tendencia llego a su cenit con la computadora VAX de digital equipment corporation que tenia varios cientos de instrucciones y más de 200 formas distintas de especificar los operandos a usar en cada instrucción. Desafortunadamente, la arquitectura VAX se concibió desde el principio para implementarse con un intérprete, sin pensar mucho en la implementación de un modelo de alto rendimiento. Esta filosofía llevo a la conclusión de un gran número de Instrucciones de valor marginal que eran difícil de ejecutar de manera directa. Esta omisión resultado fatal para VAX, y en ultima instancia también para DEC (Compaq compró a DEC en 1998.
Si bien los primeros microprocesadores de 8 bits eran maquinas muy sencillas con conjuntos de instrucciones muy simples, para fines de la década de los años setenta incluso los microprocesadores habían adoptado diseños basados en intérpretes. Durante este periodo, uno de los principales retos que los diseñadores de microprocesadores enfrentaban era controlar la creciente complejidad que los circuitos hacían posible. Una ventaja importante del enfoque basado en intérpretes era la posibilidad de diseñar un procesador sencillo, dejando casi todo lo complejo para la memoria que contenía el intérprete. Así un diseño de hardware complejo podría convertirse en un diseño de software complejo.
El éxito de motorota 6800, que tenia un conjunto de instrucciones grande interpretado, el fracaso concurrente del zilog Z8000, el Z80 era mucho mas popular que el predesor historia de motorota como fabricante de chips y larga historia de Exxon (el dueño de Zilog) como compañía petrolera, no como fabricante de chips.
Otro factor que actuaba a favor de la interpretación durante esa era fue la existencia de memorias solo de lecturas rápidas, llamadas almacenes de control, para contener los intérpretes. Supongamos que una instrucción interpreta representativa del 68000 requeriría 10 instrucciones del intérprete, llamadas microinstrucciones, a 100ns cada una, u dos referencias a la memoria principal, a 500 ns cada una. El tiempo de ejecución total era entonces 2000ns, solo el doble de la rápida máxima que podía lograrse con ejecución directa. Si no se contara con un almacén de control, la instrucción habría tardado 6000 ns. Una reducción en la velocidad por un factor de 6 es mucho mas difícil de aceptar que una reducción por un factor de 2.
La CPU se compone de varias partes. La unidad de control se encarga de buscar instrucciones de la memoria principal y determinar su tipo. La unidad de aritmética y lógica realiza operaciones como suma y AND boleeano necesarias para ejecutar las instrucciones.
La CPU también contiene una memoria pequeña de alta velocidad que sirve para almacenar resultados temporales y cierta información de control. Esta memoria se compone de varios registros, cada unos de los cuales tiene cierto tamaño. Cada registro puede contener un número, hasta algún máximo determinado por el tamaño del registro. Los registros pueden leerse y escribirse a alta velocidad porque están dentro de la CPU.
El registro mas importante es el contador de programa (PC, program counter), que apunta a la siguiente instrucciones que debe buscarse par ejecutarse. El nombre “contador de programa” es un tanto engañoso porque no tiene nada que ver con contar, pero es un término de uso universal. Otro registro importante es el registro de instrucciones (IR, instruction register), que contiene la instrucciones que se esta ejecutando. Casi todas las computadoras tienen varios registros más, algunos de propósito general y otros para fines específicos.
1.4 RISC Vs CISC Volver
A finales de los setenta se efectuaron muchos experimentos con instrucciones muy complejas, que eran posibles gracias al intérprete. Los diseñadores trataron de salvar la “brecha semántica” entre lo que las maquinas podían hacer y lo que los lenguajes de programación de alto nivel requerían. A casi nadie se le ocurría diseñar maquinas mas sencillas, como ahora nadie piensa en diseñar sistemas operativos, redes, procesadores de textos, etc. Menos potentes (lo cual tal vez es lamentable).
Un Grupo que se opuso a la tendencia y trato de incorpora algunas de las ideas de seymour cray en una mini computadora de alto rendimiento fue el encabezado por John Cocke en IBM. Estos trabajos tuvieron como resultado una mini computadora experimental llamada 801. Aunque IBM nunca comercializo esta maquina y los resultados no se publicaron sino hasta varios años después (Radin, 1982), la información se filtro y otras personas comenzaron a investigar arquitecturas similares.
En 1980, un grupo de Berkeley dirigido por David Patterson y Carlo Sequin comenzó a diseñar chips de CPU VLSI que no utilizaban interpretación (patterson, 1985; patterson y sequin, 1983), ellos acuñaron el termino RISC para este concepto y llamaron a su chip de CPU RISC I, el cual fue seguido en poco tiempo por el RISC II. Un poco después, en 1981, del otro lado de la bahía de san francisco. En stanford, John Hennessy diseñó y fabricó un chip un tanto diferente al que llamó MIPS (hennessy, 1984), estos chips llegaron a convertirse en productos importantes desde el punto de vista comercial: SPARC Y MIPS, respectivamente.
Estos nuevos procesadores tenían diferencias significativas respecto a los procesadores comerciales de la época. Dado que estas nuevas CPU no tenían que ser compatibles con productos existentes, sus diseñadores estaban en libertad de escoger nuevos conjuntos de instrucciones que maximizaran el rendimiento total del sistema. Si bien el hincapié inicial fue en instrucciones simples que pudieran ejecutarse con rápidas, pronto se vio que la clave para un buen desempeño era diseñar instrucciones que pudieran emitirse (iniciarse) rápidamente. El tiempo real que unas instrucciones tardaba era menos importante que el número de instrucciones que podrían iniciarse por segundo.
En la época en que se estaba diseñando por primera vez estos sencillos procesadores característica que llamo la atención de todo el mundo fue el numero relativamente pequeño de instrucciones disponibles, por lo regular unas 50. Este numero era mucho menor que 200 a 300 que tenían computadoras establecidas como la DEC VAX y las grandes mainframes de IBM. De hecho, el acrónimo RISC significa Computadora de conjunto de instrucciones reducido, lo que contrasta con CISC, que significa computadora de conjunto de instrucciones complejos. Hoy día, poca gente piensa que el tamaño del conjunto de instrucciones se crucial, pero el nombre ha persistido.
Para no hacer muy larga la historia, se desencadeno una gran guerra de religión, con los partidarios de RISC atacando el orden establecido. Ellos aseguraban que la mejor forma de diseñar una computadora era tener un número reducido de instrucciones simples que se ejecutaran en un ciclo de camino de datos, buscar registros, combinarlos de alguna manera (por ejemplo, suma o AND) y almacenar el resultado en un registro nuevamente. Su argumento era que incluso si una maquina RISC gana. También vale la pena señalar que para esas fechas la rapidez de las memorias principales había alcanzado a la rapidez de los almacenes de control solo de lectura, así que el castigo por interpretación se había incrementado considerablemente, lo que favorecía a los maquinas RISC.
Podríamos pensar que en vista de las ventajas de velocidad de la tecnología RISC, las maquinas RISC (como la alpha de DEC) habrían sacado a las maquinas CISC (como la Intel Pentium) del mercado. No ha sucedido tal cosa, Por que?
En primer lugar, esta la cuestión de la compatibilidad con lo existente y los miles de millones de dólares que las compañías han invertido en software para la línea Intel. Segundo, aunque parezca sorprendente, Intel ha logrado aplicar las mimas ideas incluso en una arquitectura CISC. A partir de 486, las CPU de Intel contiene un núcleo RISC que ejecuta instrucciones mas simples (y casi siempre las mas comunes) en un solo ciclo del camino de datos, al tiempo que interpreta las instrucciones mas compleja de la forma CISC acostumbrada. El resultado neto es que las instrucciones comunes son rápidas, y las menos comunes son lentas. SI bien este enfoque hibrido no es tan rápido como un diseño RISC puro, ofrece un desempeño global competitivo y al mismo tiempo permite la ejecución de software viejo sin modificación.
La ALU, suma, resta y realiza otras operaciones simples con sus entradas, y produce un resultado en el registro de salida. EL contenido de este registro de salida se envía a un registro, que posteriormente se escribe (es decir, se guarda) en memoria, si se desea. No todos los diseños tienen los registros A, B y de salida. EN el ejemplo se ilustra la suma.
Casi todas las instrucciones pueden dividirse en una de dos categorías: registros-memoria o registro-registro. Las instrucciones registro-memoria permiten buscar palabras de la memoria a los registros. Donde pueden utilizarse como entradas de la ALU en instrucciones subsecuentes, por ejemplo. (Las “palabras” son las unidades de datos que se transfieren entre la memoria y los registros. Una palabra podría ser un entero. Trataremos la organización de la memoria mas adelante en este capitulo. ) Otras instrucciones registros-memoria permiten almacenar el contenido de un registro en la memoria.
1.5 Introducción Paralelismo Volver
Los arquitectos de computadoras se esfuerzan constantemente por mejorar el desempeño de las maquinas que diseñan. Una forma de hacerlo es aumentar la velocidad de reloj de los chips para que operen con mayor rapidez, pero para cada nuevo diseño existe un límite para lo que es posible lograr con los recursos disponibles en ese momento histórico. Por consiguiente, casi todos los arquitectos de computadoras recurren al paralelismo (hacer dos o mas cosas al mismo tiempo) para sacar el mayor provecho posible a una velocidad de reloj dada.
El paralelismo adopta dos formas generales: paralelismo en el nivel de instrucciones y paralelismo en el nivel de procesador. En el primero, de aprovecha el paralelismo dentro de las instrucciones individuales para lograr que la maquina ejecute mas instrucciones por segundo. En el segundo, múltiples CPU trabajan juntas en el mismo problema. Cada enfoque tiene sus propios meritos. En esta sección examinaremos el paralelismo en el nivel de instrucciones; en la que sigue veremos el paralelismo en el nivel procesadores.
Pipeline Volver
Es un método por el cual se consigue aumentar el rendimiento de algunos sistemas electrónicos digitales. Es aplicado, sobre todo, en microprocesadores.
El alto rendimiento y la velocidad elevada de los modernos procesadores, se debe, principalmente a la conjunción de tres técnicas:
- Arquitectura Harvard (arquitectura que propicia el paralelismo).
- Procesador tipo RISC.
- Segmentación.
Consiste en descomponer la ejecución de cada instrucción en varias etapas para poder empezar a procesar una instrucción diferente en cada una de ellas y trabajar con varias a la vez.
En el caso del procesador DLX podemos encontrar las siguientes etapas en una instrucción:
IF: búsqueda
ID: decodificación
EX: ejecución de unidad aritmético lógica
MEM: memoria
WB: escritura
Cada una de estas etapas de la instrucción usa en exclusiva un hardware determinado del procesador, de tal forma que la ejecución de cada una de las etapas en principio no interfiere en la ejecución del resto.
En el caso de que el procesador no pudiese ejecutar las instrucciones en etapas segmentadas, la ejecución de la siguiente instrucción sólo se podría llevar a cabo tras la finalización de la primera. En cambio en un procesador segmentado, salvo excepciones de dependencias de datos o uso de unidades funcionales, la siguiente instrucción podría iniciar su ejecución tras acabar la primera etapa de la instrucción actual.
Otro ejemplo de lo anterior, en el caso del PIC, consiste en que el procesador realice al mismo tiempo la ejecución de una instrucción y la búsqueda del código de la siguiente.
Superescalar Volver
Es el término utilizado para designar un tipo de microarquitectura de procesador capaz de ejecutar más de una instrucción por ciclo de reloj. El término se emplea por oposición a la microarquitectura escalar que sólo es capaz de ejecutar una instrucción por ciclo de reloj. En la clasificación de Flynn, un procesador superescalar es un procesador de tipo MIMD (multiple instruction multiple data). La microarquitectura superescalar utiliza el paralelismo de instrucciones además del paralelismo de flujo, éste último gracias a la estructura en pipeline. La estructura típica de un procesador superescalar consta de un pipeline con las siguientes etapas:
- lectura (fetch)
- decodificación (decode)
- lanzamiento (dispatch)
- ejecución (execute)
- escritura (writeback)
- finalización (retirement)
En un procesador superescalar, el procesador maneja más de una instrucción en cada etapa. El número máximo de instrucciones en una etapa concreta del pipeline se denomina grado, así un procesador superescalar de grado 4 en lectura (fetch) es capaz de leer como máximo cuatro instrucciones por ciclo. El grado de la etapa de ejecución depende del número y del tipo de las unidades funcionales.
Un procesador superescalar suele tener unidades funcionales independientes de los tipos siguientes :
- unidad aritmético lógica (ALU)
- unidad de lectura / escritura en memoria (Load/Store Unit)
- unidad de coma flotante (Floating Point Unit)
- unidad de salto (Branch unit)
Un procesador superescalar es capaz de ejecutar más de una instrucción simultáneamente únicamente si las instrucciones no presentan algún tipo de dependencia (hazard). Los tipos de dependencia entre instrucciones son :
- dependencia estructural, esta ocurre cuando dos instrucciones requieren el mismo tipo unidad funcional y su número no es suficiente.
- dependencia de datos, esta ocurre cuando una instrucción necesita del resultado de otra instrucción para ejecutarse, por ejemplo R1<=R2+R3 y R4<=R1+5.
- dependencia de escritura o falsa dependencia , esta ocurre cuando dos instrucciones necesitan escribir en la misma memoria, por ejemplo R1<=R2+R3 y R1<=R1+5.
La detección y resolución de las dependencias entre instrucciones puede ser estática (durante la compilación) o dinámica, es decir, a medida que se ejecuta un programa, generalmente durante la etapas de codificación y lanzamiento de las instrucciones.
La detección y resolución dinámica de las dependencias entre instrucciones suele realizarse mediante alguna variante del algoritmo de Tomasulo que permite la ejecución de instrucciones en un orden distinto al del programa también llamada ejecución en desorden .
La eficacia de un procesador superescalar viene limitada por un lado por la dificultad en suministrar al procesador suficientes instrucciones que puedan ser ejecutadas en paralelo y por otro lado por las prestaciones de la jerarquía de memorias.
Si las instrucciones de salto son un problema para los procesadores con pipeline en general, en el caso de los procesadores superescalares, el problema se multiplica ya que un parón en el pipeline tiene consecuencias en un número mayor de instrucciones.
Por esta razón, los fabricantes de procesadores recurren a técnicas de ejecución especulativa y diseñan algoritmos de predicción de saltos cada vez más sofisticados así como sistemas de almacenamiento de instrucciones por trazas (trace caches).
Las arquitecturas supersescalares adolecen de una estructura compleja y de un mal aprovechamiento de sus recursos debido en parte a la dificultad en encontrar suficientes instrucciones paralelizables. Una forma de obtnener un mayor número de instrucciones paralelizables es aumentar la ventana de instrucciones, es decir el conjunto de instrucciones que la unidad de lanzamiento considera como candidatas a ser lanzadas en un momento dado. Desafortunadamente la complejidad del procesador superescalar aumenta desproporcionadamente con respecto al tamaño de dicha ventana lo que se traduce por un ralentizamiento general del circuito. Otra forma de obtener más instrucciones paralelizables es manipulando instrucciones de más de un programa a la vez, lo que se conoce bajo el nombre de multitarea simultánea o multithreading simultáneo.
Mientras las primeras CPUs superescalares disponían de dos ALUs y una sola FPU, un procesador moderno como el incluye cuatro ALUs y dos FPUs, además de dos unidades SIMD. Si el despachador no es eficiente haciendo trabajar lo máximo posible a estas unidades, el rendimiento global del procesador se verá mermado.
La CDC 6600 de Seymour Cray, construida en 1965, es la primera arquitectura superescalar, siendo llevado el concepto a las microcomputadoras en las CPUs RISC. Esta posibilidad venía dada por la simpleza de los núcleos RISC, permitiendo meter más unidades de ejecución en un mismo chip. Esta fue una de las razones de la rapidez de los sistemas RISC frente a los más antiguos CISC durante las décadas de los 80 y los 90, pero a medida que los procesos de fabricación mejoraron y se pudieron meter más y más transistores en el mismo chip, hasta diseños complejos como el IA-32 pudieron ser supescalares.
La inmensa mayoría de las CPUs desarrolladas desde 1998 son superescalares.
Llegados a un punto en que la mejora sustancial de la unidad de control y despachamiento parece imposible, ya no parece que los diseños superescalares puedan dar más de sí. Una de las posibles soluciones es trasladar la lógica de despachamiento desde el chip hasta el compilador, que puede invertir mucho más tiempo en tomar las mejores decisiones posibles, ya que no tiene que operar en tiempo real como tenía que hacer el hardware de despachamiento. Este es el principio básico de los procesadores VLIW (Very Long Instruction Word), donde el paralelismo es explicitado por el formato de instrucción, también conocidos como superescalares estáticos
Procesamiento Paralelo Volver
El procesamiento paralelo es un término que se usa para denotar un grupo de técnicas significativas que se usan para proporcionar tareas simultáneas de procesamiento de datos con el fin de aumentar la velocidad computacional de un sistema de computadoras. En lugar de procesar cada instrucción en forma secuencial como es una computadora convencional, un sistema de procesamiento paralelo puede ejecutar procesamiento concurrente de datos para conseguir un menor tiempo de ejecución. Por ejemplo, cuando se ejecuta una instrucción en la ALU, puede leerse la siguiente instrucción de la memoria. El sistema puede tener 2 o mas ALUS y ser capaz de ejecutar dos o mas instrucciones al mismo tiempo. Además, el sistema puede tener dos o más procesadores operando en forma concurrente.
EL propósito del procesamiento paralelo es acelerar las posibilidades de procesamiento de la computadora y aumentar su eficiencia, esto es, la capacidad de procesamiento que puede lograrse durante un cierto intervalo de tiempo. La cantidades de circuitería aumenta con el procesamiento paralelo y, con el, también el costo del sistema. Sin embargo, los descubrimientos tecnológicos han reducido el costo de la circuetería a un punto en donde las técnicas de procesamiento paralelo son económicamente factibles.
El procesamiento paralelo puede considerarse de diversos niveles de complejidad. En el nivel mas bajo, distinguimos entre operaciones seriales y paralelas mediante el tipo de registros que utilizan. Los registros de corrimiento operan en forma serial un bit a la vez, mientras que los registros con carga paralela operan con todos los bits de la palabra en forma simultánea.
Puede obtenerse procesamiento paralelo a un nivel más alto de complejidad al tener múltiples unidades funcionales que ejecuten operaciones idénticas o diferentes, de manera simultánea. El procesamiento paralelo se establece al distribuir los datos entre las unidades funcionales múltiples. Por ejemplo, las operaciones aritmétiocas, lógicas y de corrimiento pueden separarse en tres unidades y dividirse los operandos a cada una, bajo la supervisión de una unidad de control.
Fig. 1 Procesador con unidades funcionales mútliples
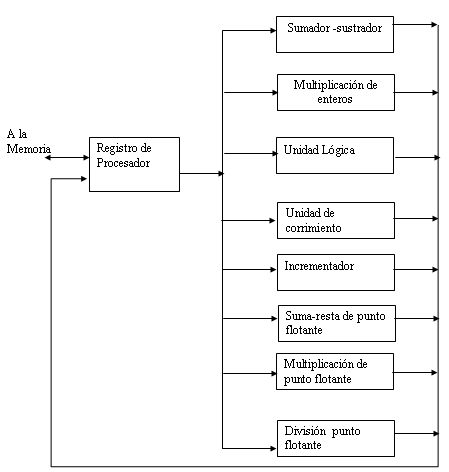
La Fig. 9-1. muestra una manera posible de separar la unidad de ejecución en 8 unidades funcionales que operan en paralelo. Los operando en los registros se aplican a una de las unidades, dependiendo de la operación especificada, mediante la instrucción asociada con los operandos.
La operación ejecutada en cada unidad funcional se indica en cada bloque del diagrama. El sumador y el multiplicador de enteros ejecutan las operaciones aritméticas con números enteros. Las operaciones de punto flotante se separan en tres circuitos que operan en paralelo. Las operaciones lógicas de corrimiento y de incremento pueden ejecutarse en forma concurrente sobre diferentes datos. Todas las unidades son independientes unas de otra, por lo que puede correrse un número mientras otro se incrementa. Por lo general, una organización multifuncional esta asociada con una unidad de control compleja para coordinar todas las agilidades entre los diferentes componentes.
Existen varias maneras de clasificar el procesamiento paralelo. Puede considerarse a partir de la organización interna de los procesadores, desde la estructura de interconexión entre los procesadores o desde del flujo d e información a través del sistema. Una clasificación presenta por M. J. Flynn considera la organización de un sistema de computadora mediante la cantidad de instrucciones y unidades de datos que se manipulan en forma simultánea. La operación normal de una computadora es recuperar instrucciones de la memoria y ejecutarlas en el procesador. La secuencia de instrucciones leídas de la memoria constituye un flujo de instrucciones. Las operaciones ejecutada sobre los datos en el procesador constituyen un flujo de datos.
El procesamiento paralelo puede ocurrir en el flujo de instrucciones, en el flujo de datos o en ambos. La clasificación de Flynn divide a las computadoras en cuatro grupo principales de la manera siguiente:
- Flujo de instrucción único, Flujo de datos único (SISD)
- Flujo de instrucción único, Flujo de datos Múltiple (SIMD)
- Flujo de instrucción Múltiple, Flujo de datos único (MISD)
- Flujo de instrucción Múltiple, Flujo de datos Múltiple (MIMD)
SISD. Representa la organización de una computadora única que contiene una unidad de control, una unidad de procesador y una unidad de memoria. Las instrucciones se ejecutan en forma secuencial y el sistema puede tener o no tener posibilidades de procesamiento paralelo. En este caso el procesamiento paralelo puede lograrse mediante unidades funcionales múltiples o mediante una arquitectura paralela.
SIMD. Representa una organización que influye muchas unidades de procesamiento bajo la supervisión de una unidad de control común. Todos los procesadores reciben la misma instrucción de la unidad de control, pero operan sobre diferentes conjuntos de datos. La unidad de memoria compartida debe de contener módulos múltiples para que pueda comunicarse con todos los procesadores simultáneamente. LA estructura MISD es sola de intereses teórico porque no se ha construido ningún sistema práctico utilizando esta organización. La organización MIMD se refiere a un sistema de computadoras capaz de procesar múltiples programas al mismo tiempo la mayoría de los sistemas de multicomputadoras y multiprocesador pueden clasificarse en esta categoría.
La clasificación de Flynn depende en la diferencia entre el desempeño de la unidad de control y el de la unidad de procesamiento de datos.
Enfatiza las características de desempeño del sistema de computadoras más que sus interconexiones estructurales y operacionales. Un tipo de procesamiento paralelo que no entra en la clasificación flynn es la arquitectura paralela (pipe-line) Las únicas dos categorías utilizadas de esta clasificación son los procesadores de arreglo SIMD, analizados en la sección 9-7 y MIMD.
El procesamiento por arquitectura paralela es una técnica de implantación en donde las suboperaciones aritméticas o las fases de un ciclo de instrucción de computadora se traslapan en su ejecución el procesamiento de vectores relaciona con los cálculos que implican vectores y matrices grandes. Los procesadores de arquitectura paralela ejecutan cálculos sobre arreglos de datos grandes.
Bibliografía
Tanenbaum Andrew S., Organización de computadoras, 5ta edición.
http://es.wikipedia.org/wiki/
http://www.elrinconcito.com/
MODULO II: ORGANIZACION DE LA MEMORIA EN UNA COMPUTADORA
2.1 Organizacion de la Memoria
2.2 Direccion de la Memoria
2.3 Ordenamiento de Byte
2.4 Mapeo de la Memroria en un Sistema de Computadora
Descargar modulo
2.1 Memoria Primaria
La memoria es la parte de la computadora en la que se almacenan programas y datos. Algunos especialistas en computaci ón (sobre todo los británicos) emplean el término almacén (store) o almacenamiento (storage) en lugar de memoria (memory), aunque cada vez se extiende más el uso de “almacenamiento” para referirse al almacenamiento en disco. Sin una memoria en la cual los procesadores puedan leer y escribir información, no existirían las computadoras digitales.
Bits
La unidad básica de memoria es el digito binario, llamado BIT. Un BIT puede contener un 0 o un 1; es la unidad más simple posible. (Un dispositivo que solo pudiera almacenar ceros difícilmente podría servir para construir un sistema de memoria; se requieren por lo menos dos valores.)
Suele decirse que las computadoras emplean aritmética binaria porque es “eficiente”. Lo que quiere decirse (aunque pocas veces se es consciente de ello) es que es posible almacenar información digital distinguiendo entre diferentes valores de alguna cantidad física continua, como un voltaje o corriente. Cuantos mas valores sea necesario distinguir, y menor separación haya entre valores adyacentes, menos confiable será la memoria. El sistema de numeración binario solo requiere distinguir entre los valores; por lo tanto, es el método más confiable para codificar información digital.
En la publicidad de algunas computadoras, como las mainframes IBM grandes, se alardea de que tiene aritmética decimal además de binaria. Este truco se logra utilizando 4 bits para almacenar un digito decimal empleando un código llamado BCD (Decimal codificado en binario). Cuatro bits se pueden combinar de 16 formas, diez de las cuales se usan para los dígitos del 0 al 9; seis combinaciones no se usan. A continuación se muestra el numero 1944
Decimal: 0001 1001 0100 0100 binario: 0000011110011000
Dieciséis bits en el formato decimal pueden almacenar los números del 0 al 9999, lo que da solo 10,000 combinaciones distintas. Es por eso que decimos que el almacenamiento binario es más eficiente.
Sin embargo, considere lo que sucedería si algún joven brillante ingeniero electrizo inventara un dispositivo electrónico altamente confiable que pudiera almacenar directamente dígitos del 0 al 9 dividiendo la región de 0 a 10 volts en 10 intervalos. Cuatro de estos dispositivos podrían almacenar cualquier número decimal del 0 al 9999, y podrían formar 10,000 combinaciones, también podrían usarse cuatro de esos dispositivos para almacenar numero binarios, pero solo empleando 0 y 1. En tal vaso, solo podrían almacenar 16 combinaciones. Con tales dispositivos, el sistema decimal obviamente es más eficiente.
2.2 Direcciones de memoria Volver
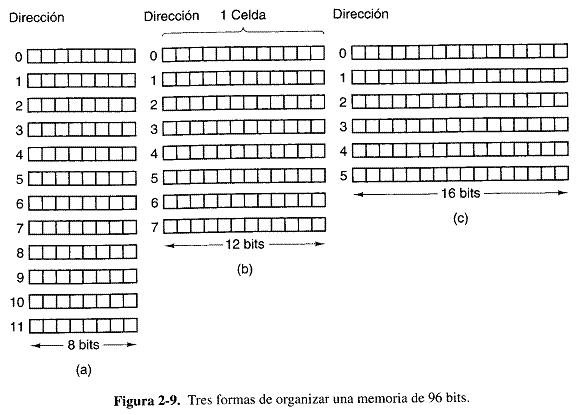
Las memorias consisten en varias celdas (o localidades), cada una de las cuales puede almacenar un elemento de información. Cada celda tiene un número, su dirección, con el cual los programas pueden referirse a ella. Si una memoria tiene n celdas, tendrán las direcciones 0 al n-1. Todas las celdas de una memoria contienen el mismo número de bits. Si una celda consta de k bits, podrá contener cualquiera de 2^k combinaciones de bits distintas. En la figura 2-9 se muestran tres diferentes organizaciones para una memoria de 96 bits. Observe que celdas adyacentes tienen direcciones consecutivas (por definición).
Las computadoras que emplean el sistema de numeración binario (incluidas las notaciones octal y hexadecimal para húmeros binarios) expresan las direcciones de memora como números binarios. Si una dirección tiene m bits, el numero máximo de celdas direccionales es 2^m. Por ejemplo, una dirección empleada para referirse a la memoria de la figura 2-9 (a) necesita al menos 4 bits para expresar todos los números del 0 al 11. En cambio, basta una dirección de 3 bits para las figuras 2-9(b) y (c). El número de bits de la dirección determina el número máximo de celdas direccionales directamente en la memoria y es independiente del número de bits por celda. Una memoria que tiene 2^12 celdas de 8 bits cada una, y una que tiene 2^12 celdas de 64 bits cada una, necesitan ambas direcciones de 12 bits.
En la figura 2-10 se da el número de bits por celda de algunas computadoras que más se han vendido comercialmente.
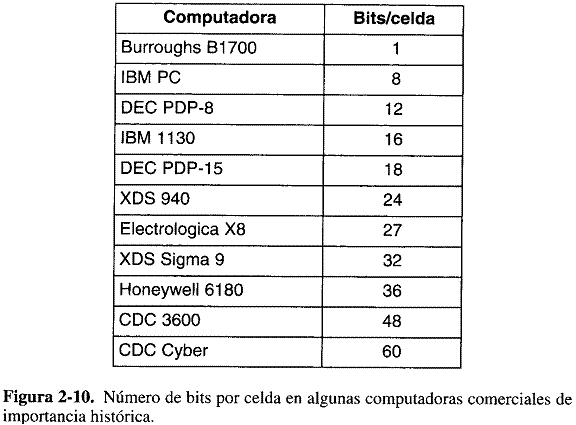
La importancia de la celda es que es la unidad de direcciónable más pequeña. En años recientes casi todos los fabricantes de computadoras han adoptado como estándar una celda de 8 bits, que recibe el nombre de byte. Los bytes se agrupan en palabras. Una computadora con palabras de 32 bits tiene 4 bytes/palabra, mientras que una con palabras de 64 bits tiene 8 bytes/palabra. La importancia de las palabras es que casi todas las instrucciones operan con palabras enteras; por ejemplo, suman dos palabras. Así, una maquina de 32 bits tiene registros de 32 bits e instrucciones para manipular palabras de 32 bits, mientras que una maquina de 64 bits tiene registros de 64 bits e instrucciones para transferir, sumar, restar y manipular de otras maneras palabras de 64 bits.
2.3 Ordenamiento de bytes Volver
Los bytes de una palabra pueden numerarse de izquierda a derecha o de derecha a izquierda. A primera vista podría parecer que esta decisión carece de importancia pero, como veremos en breve, tiene implicaciones importantes. En la figura 2-11(a) se muestra parte de la memoria de una computadora de 32 bits cuyos bytes se numeran de izquierda a derecha, como la SPARC o las grandes mainframes de IBM. En la figura 2-11(B) se aprecia la representación análoga de una computadora de 32 bits que usa numeración de derecha a izquierda, como la familia intel. El primer sistema, en el que la numeración comienza por el extremo “grande (es decir, de orden alto), se llama computadora big endian, en contraste con la litle endian de la figura 2-11(b). Estos términos provienen de la obra los viajes de gulliver.
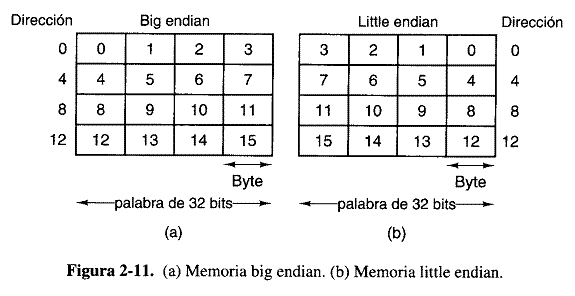
Es importante entender que tanto en los sistemas big endian como en los little endian, un entero de 32 bits con el valor numérico de, digamos, 6, se representa con los bits 110 en los tres bits de la extrema derecha (de orden bajo) de una palabra, con ceros en los 29 bits de la izquierda. EN el esquema big endian. Los bits 110 están en el byte 3 (o 7, u 11, etc), mientras que en el esquema little endian están en el byte 0 (o 4, u 8, etc), en ambos casos, la palabra contiene este entero tiene la dirección 0.
Si las computadoras solo almacenaran enteros, no habría problemas, pero muchas aplicaciones requieren una mezcla de enteros, cadenas de caracteres y otros tipos de datos. Considere, por ejemplo, un sencillo registro de personas que consiste en una cadena (nombre de empleado) y dos enteros (edad y numero de departamento). La cadena termina con uno o mas bytes 0 para llenar una palabra. La representación big endian para Jim Smith, de 21 años, del departamento 260 (1 X 256 + 4 = 260) se muestra en la figura 2.12 (a); la little endian, en la figura 2-12 (b).
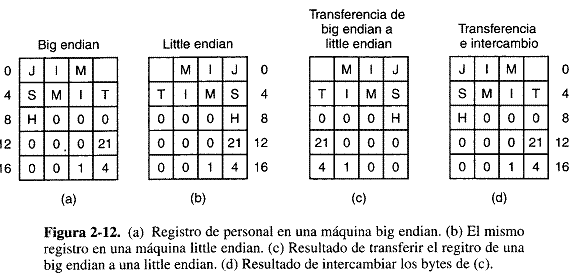
Ambas representaciones son excelentes y son congruentes internamente. Los problemas comienzan cuando una de las maquinas trata de enviar el registro a la otra por una red. Supongamos que la big endian envia el registro a la little endian byte por byte, comenzando con el byte 0 y terminando con el byte 19. (Seremos optimistas y supondremos que los bits de los bytes no se invierten durante la transmisión, pues ya tenemos suficientes problemas.) Así, el byte 0 de la big endian se coloca en el byte 0 de la memora de la little endian, y así sucesivamente, como se muestra en la figura 2-12 ©.
Cuando la little endian trata de imprimir el nombre, no hay problema, pero la edad parece como 21 X2 ^44, y el departamento es igualmente absurdo. Esta situación surge porque la transmisión invirtió el orden de los caracteres de una palabra, como debería, pero también invirtió los bytes de los enteros, como que no debió de hacer.
Usa solución obvia es hacer que el software invierta los bytes de una palabra después de efectuar el copiado. Esto conduce a la figura 2-12 (d) y hace que los dos enteros queden bien pero convierta la cadena en “MJITIMS” “H”. Esta inversión de la cadena ocurre porque al leerla, la computadora primeo lee el byte 0 (un espacio), luego el byte 1 (M), etc.
No existe una solución sencilla. Un remedio que funciona, pero es ineficiente, es incluir una cabecera frente a cada dato que indique que tipo de datos que sigue (cadena, entero u otro) y que longitud tiene. Esto permite al receptor efectuar solo las conversiones que sean necesarias. En todo caso, es evidente que la falta de un estándar para el ordenamiento de los bytes genera problemas innecesarios al intercambiar datos entre diferentes maquinas.
Bibliografia
- Tanenbaum Andrew S., Organización de computadoras, 5ta edición.
MODULO III: MODELO DE PROGRAMACION DE UN PROCESADOR
3.1 Registros Internos
3.2 Segmentos y direccionamiento
3.3 Tipos de Datos e Instrucciones
3.4 Formatos de Instruccion
3.5 Criterios de diseño para el Formato de Intruccion.
Descargar modulo
3.1 Registros
Todas las computadoras tienen algunos registros que son visibles en el nivel ISA. Su función es controlar la ejecución del programa, almacenar resultados temporales y otras cosas. En general, los registros visibles en el nivel de mircroarquitectura, como TOS y MAR en la figura 4-1, no son visibles en el nivel ISA. Sin embargo, unos cuantos de ellos, como el contador de programa y el apuntador de pila, son visibles en ambos niveles. Por otra parte, los registros visibles en el nivel ISA siempre son visibles en el nivel de micro arquitectura porque ahí es donde se implementan.
Los registros del nivel ISA se pueden dividir en dos categorías amplias: registros de propósito especial y registros de propósito general. Los primeros incluyen cosas como el contador de programa y el apuntador a la pila, además de otros registros con funciones especificas. En contraste los registros de propósito general sirven para guardar variables locales clave y los resultados intermedios de los cálculos. Su función principal es proporcionar acceso rápido a datos que se usan continuamente (básicamente para evitar accesos a la memoria). Las maquinas RISC, con sus CPU rápidas y memorias (relativamente) lentas, casi siempre tienen por lo menos 32 registros de propósito general, y la tendencia en los nuevos diseños de CPU es tener aun más.
En algunas maquinas los registros de propósito general son totalmente simétricos e intercambiables. Si todos los registros son equivalentes, un compilador puede R1 para contener un resultado temporal, pero igual podría usar R25. El registro escogido no importa.
En cambio, en otras maquinas algunos de los registros de propósito general podrían tener algo de especial. Por ejemplo, en el Pentium II hay un registro llamado EDX que se puede usar como registro general, pero también recibe la mitad del producto en una multiplicación y que contiene la mitad del dividendo en una división.
Aun si los registros de propósito peral son totalmente intercambiables, es común que el sistema operativo o los compiladores adopten convenciones sobre su uso. Por ejemplo, algunos registros podrían contener parámetros de procedimientos invocados y otros podrían usarse como registros de borrador. Si un compilador coloca una variable local importante en R! y luego invoca a un procedimiento de biblioteca que cree que R! es un registro de borrador que puede usar, cuando el procedimiento regrese, R1 podría contener basura. Si existen convenciones en el nivel de sistema sobre el uso de registros. Es recomendable que los compiladores y los programadores en lenguaje ensamblador se ajusten a ellas.
Además de los registros en el nivel ISA que los programas de usuario pueden ver, siempre hay una cantidad sustancial de registros de propósito especial que solo son accesibles en modo kernel. Estos registros controlan las diversas caches, memoria, dispositivos de E/S y otras características de hardware de la maquina. Solo el sistema operativo los usa, así que los compiladores y los usuarios no tienen que saber de ellos.
Un registro de control que es una especie de hibrido Kernel/usario es el registro de banderas o palabra de estado del programa (PSW), programa status Word). Este registro contiene diversos bits que la CPU necesita. Los bits más importantes son los códigos de condición. Estos bits se ajustan en cada ciclo de la ALU y reflejan la situación del resultado de la operación mas reciente. Entre los bits de condición mas comunes están.
- N – Se enciende si el resultado fue negativo
- Z – se enciende si el resultado fue cero.
- V – se enciende si el resultado causo un desbordamiento.
- C – se enciende si el resultado causó un acarreo de salida del bit de la extrema izquierda.
- A – se enciende si hubo un acarreo de salida del bit 3 (acarreo auxiliar).
- P – se enciende si el resultado tuvo paridad par.
Los códigos de condición son importantes porque las instrucciones de comparación y ramificación condicional (es decir, las instrucciones de salto condicional) los usan. Por ejemplo, la instrucción CMP generalmente resta dos operandos y estable los códigos de condición con base en la diferencia. Si los operandos son iguales, la diferencia será cero y se excederá el bit de código de condición z de la psw. Una instrucción BEQ (ramificar sin son iguales, Branco equal) subsecuente prueba el bit z y toma la rama si esta encendido.
La psw contiene mas que solo los códigos de condición, pero el contenido total varia de una maquina a otra. Otros campos comunes indican el modo de la maquina (es decir, de kernel o de usuario), un bit de rastreo (que sirve para depurar), el nivel de prioridad de la CPU y la habilitación de interrupciones. En muchos casos es posible leer la PSW en modo de usuario, pero algunos de los campos solo pueden modificarse en modo de kernel (por ejemplo, el bit de modo de usuario/kernel).
Instrucciones Volver
La característica principal del nivel de ISA es su conjunto de instrucciones maquina. Estas controlan lo que la maquina puede hacer. Siempre hay instrucciones LOAD y STORE (en una forma o en otra) para trasladar datos entre la memoria y los registros, e instrucciones MOVE para copiar datos entre los registros. Siempre se cuenta con instrucciones aritméticas, lo mismo que instrucciones booleanas e instrucciones para comparar datos y tomar una rama y otra según los resultados.
3.3 Tipos de datos Volver
Todas las computadoras necesitan datos. De hecho, la tarea principal de muchos sistemas de computadora es procesar datos financieros, comerciales, científicos, de ingeniería o de otro tipo. Los datos tienen que representarse de alguna forma específica dentro de la computadora. En el nivel Isa se emplean diversos tipos de datos, que explicaremos a continuación.
Una cuestión fundamental es si existe o no apoyo de hardware para un tipo de datos en particular. Apoyo de hardware significa que una o más instrucciones esperan datos en un formato dato, y el usuario no puede escoger un formato distinto. Por ejemplo, los contadores tiene el peculiar habito de escribir los números negativos con el signo menos a la derecha del numero, en lugar de la izquierda, donde lo ponente los especialistas en computación., suponga que, en un intento por impresionar a su jefe, el encargado de centro de computo de un bufete contable cambia todos los números de todas las computadoras de modo que el bit de la extrema derecha (en lugar del de la extrema izquierda) haga las veces de bit de signo. No cabe duda que el jefe quedaría muy impresionado… porque todo el software dejaría de funcionar correctamente. El hardware espera cierto formato para los enteros y no funciona correctamente si recibe algo distinto. Consideremos ahora otro bufete contable, uno que acaba de obtener un contrato par verificar la deuda federal (cuanto debe el gobierno federal a sus acreedores). No seria factible usar aritmética de 32 bits aquí porque los números en cuestión son mayores de 2^32 (unos 4000 millones). Una solución es usar dos enteros de 32 bits para que representar cada numero, lo que da 64 bits en total. Si la maquina no reconoce este tipo de números de doble precisión, todas las operaciones aritméticas que se realicen con ellos se tendrán que actuar en software, pero las dos partes pueden estar en cualquier orden porque al hardware no le importa. Este es un ejemplo de tipo de datos si apoyo de hardware y por tanto sin una representación obligatoria de hardware. En las secciones que siguen examinaremos los tipos de datos que tienen apoyo de hardware y que por ello requieren formatos específicos.
Tipos de datos numéricos Volver
Los tipos de datos se pueden dividir en dos categorías: numericos y no numéricos. El principal de los tipos numéricos es el tipo entero. Los enteros tienen diversas longitudes, como 8,16 ,32 y 64 bits. Los enteros cuentan cosas (por ejemplo, el numero de destornilladores que una ferretería tiene en existencia), identifica cosas (por ejemplo, números de cuenta bancarios) y muchos mas. Casi todas las computadoras modernas almacenan los enteros en notación binaria de complemento a los dos, aunque se han llegado a usar otros sistemas.
Algunas computadoras reconocen enteros sin signo además de enteros con signo. En el caso de los enteros sin signo, no hay bit de signo y todos los bits contienen datos. Este tipo de datos tiene la ventaja de contar con un bit extra de modo que, por ejemplo, una palabra de 32 bits puede contener un entero sin signo dentro del intervalo de 0 a 2^32-1. Inclusive. En números hasta 2^31-1 aunque, por supuesto, también puede manejar números negativos.
Si un número no se puede expresar como un entero, digamos 3.5, se usan números de punto flotante. Su longitud es de 32, 64 o a veces de 128 bits. Casi todas las computadoras cuentan con instrucciones para efectuar operaciones aritméticas de punto flotante, y mucha cuenta con registros distintos para contener operandos enteros y operandos de punto flotante.
Algunos lenguajes de programación, entre los que sobresale COBOL, permiten números decimales como tipo de datos. Las maquinas diseñadas para ejecutar con frecuencia programas en COBOL suelen manejar números decimales en hardware, por lo regular codificando un numero decimal en 4 bits y empaquetando dos números decimales en cada byte (formato decimal codificado en binario). Sin embargo, la aritmética no funciona correctamente con números decimales empaquetados, por lo que se requieren instrucciones especiales para corregir la aritmética decimal. Dichas instrucciones necesitan conocer el acarreo de salida del bit 3. Es por ello que el código de condición a menudo incluye un bit de acarreo auxiliar. Por cierto, tristemente famoso problema del año 2000 (Y2K) fue causado por programadores en COBOL que decidieron que seria más económico representar el año como dos dígitos decimales que como un número binario de 16 bits, vaya optimación.
Tipos de datos no numéricos Volver
Aunque las primeras computadoras en su mayoría se ganaban la vida triturando números, las computadoras modernas a menudo se usan para aplicaciones no numéricas, como procesamiento de textos o gestión de bases de datos. Para estas aplicaciones se requieren otros tipos de datos que en muchos casos cuentan con el apoyo de instrucciones en el nivel ISA. Es evidente que los caracteres son importantes aquí, aunque no todas las computadoras ofrecen apoyo de hardware para ellos. Los códigos de caracteres más comunes son ASCII y UNICODE, que manejan caracteres de 7 bits de 16 bits, respectivamente. Ambos se describieron en el capitulo 2. No es raro que el nivel ISA cuente con instrucciones especiales diseñadas para manejar cadena de caracteres, es decir, series consecutivas de caracteres. Estas cadenas en ocasiones se delimitan con un carácter especial al final. Como alternativa, puede incluirse un capo de longitud de cadena para saber donde termina esta. Las instrucciones pueden realizar funciones de copiado, búsqueda, edición y otras con cadenas.
Los valores boléanos también son importantes. Un valor booleano puede adoptar uno de dos valores: verdadero (trae) o falso (false). En teoría, un solo bit puede representar un valor booleano, con 0 como falso y 1 como verdadero (o viceversa). En la práctica se usa un byte o una palabra para cada valor booleano por que los bits individuales de un byte no tienen cada uno su propia dirección y por tanto el acceso a ellos no es fácil. Un sistema común sigue la convenció de que 0 significa falso y cualquier otra cosa significa verdadero.
La única situación en la que un valor booleano normalmente se representa con un bit es cuando existe un arreglo de ellos, de modo que una palabra de 32 bits puede contener 32 valores boléanos. Semejante estructura de datos se denomina mapa de bits y presenta en muchos contextos. Por ejemplo, se puede usar un mapa de bits para seguir la pista a los bloques libres de un disco. Si el disco tiene n bloques, el mapa de bits tiene n bits.
Nuestro ultimo tipo de datos es el apuntador, que es solo una dirección de maquina. Ya hemos visto muchos apuntadores. En las maquinas Mic-x, SP, PC, LV y CPP son ejemplos de apuntadores. Acceder a una variable que esta a una distancia fija de un apuntador, que es una funciona ILOAD, es de lo mas común en todas las maquinas.
3.4 Formato de instrucciones Volver
Una instrucción consiste en un código de operación generalmente acompañado por información adicional como la dirección de los operándoos y el destino de los resultados. El tema general de especificar dónde están los operandos (es decir, sus direcciones) se llama direccionamiento y nos ocuparemos de el ahora.
La figura 5-9 muestra varios posibles formatos para instrucciones de nivel 2. Las instrucciones siempre tienen un código de operación que indica lo que hace la instrucción. Puede haber cero, una, dos o tres direcciones presentes.
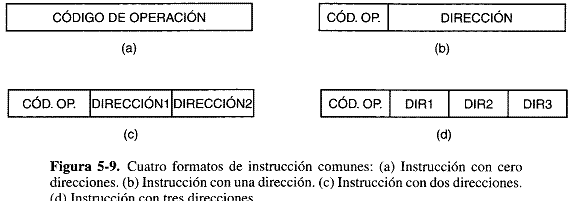
En algunas maquinas todas las instrucciones tiene la misma longitud; en otras podría haber muchas longitudes distintas. La longitud de las instrucciones puede ser menor, igual o mayor que la de una palabra. Exigir que todas las instrucciones tengan la misma longitud es más sencillo y facilita la descodificación, pero a menudo desperdicia espacio, ya que todas las instrucciones tienen que ser tan largas como la más larga. En la figura 5-10 se muestran algunas posibles relaciones entre la longitud de las instrucciones y de las palabras.
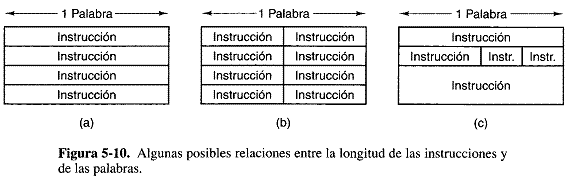
3.5 Criterio de diseño para las instrucciones Volver
Cuando un equipo de diseño de computadoras tiene que escoger los formatos de instrucciones para su maquina, debe considerar varios factores. No debemos subestimar la dificultad de esta decisión, la cual debe tomarse en una etapa temprana del diseño de una computadora nueva. Si la computadora tiene éxito comercial, el conjunto de instrucciones podría sobrevivir 20 años o más. La capacidad para añadir instrucciones nuevas y aprovechar otras oportunidades que surgen durante un tiempo largo tiene gran importancia, pero solo si la arquitectura –y la compañía que la construye –sobreviven el tiempo suficiente para que la arquitectura sea un éxito.
La eficiencia de una ISA dada depende en gran medida de la tecnología con que una computadora se va a implementar. Con los años, esta tecnología sufrirá grandes cambios, y en retrospectiva se vera que algunas de las decisiones de la ISA no fueron las mejores. Por ejemplo, si los accesos a la memoria son rápidos, un diseño basado en pila (Como JVM) es bueno, pero si son lentos entonces lo mejor es tener muchos registros (como en el UltraSPARC II). Los lectores de creen que esta decisión es fácil podrían tomar una hoja de papel y anotar sus predicciones para (1) una velocidad de reloj de CPU típica (2) un tiempo de acceso a RAM típico, para las computadoras de 20 años en el futuro. Doble bien la hoja de papel y guárdela 20 años. Luego desdóblela y léala. Quienes carezcan de humildad pueden olvidarse de la hoja de papel y simplemente publicar sus predicciones en Internet ahora.
Desde lego, aun los diseñadores con gran visión pueden tomar decisiones suboptimas. E incluso si pudieran tomar todas las decisiones correctas, también tienen que enfrentar el corto plazo. Si esta ISA elegante es un poco más costosa que sus competidoras actuales mucho menos atractivas, la compañía podría no sobrevivir el tiempo suficiente para que el mundo aprecie la elegancia de la ISA.
SI todo lo demás es igual, las instrucciones cortas son mejores que las largas. Un programa que consiste en n instrucciones de 16 bits ocupa la mitad del espacio de memoria que ocupa n instrucciones de 32 bits. En vista de la tendencia descendente de los precios de las memorias, este factor podría ser menos importante en el futuro, si no fuera por el hecho de que el software crece aun ritmo mas rápido que aquel con que bajan los precios de la memoria.
Además, minimizar el tamaño de las instrucciones podría hacerlas mas difíciles de decodificar o de traslapar. Por tanto, la reducción del tamaño de las instrucciones a la mínima debe compararse contra el tiempo que se requiere par decodificar y ejecutar las instrucciones.
Otra razón para minibar la longitud de las instrucciones ya es importante se vuelve mas importante a medida que aumenta la rapidez de los procesadores: el ancho de anda de la memoria (el numero de bits sobre segundo que la memoria puede proporcionar). El impresionante aumento en la rapidez de los procesadores tiene su origen en la incapacidad del sistema de memoria para proporcionar instrucciones y oreándoos al mismo ritmo que el procesado puede consumirlos. Cada memoria tiene un ancho de banda determinado por su tecnología y su diseño de ingeniería. El cuello de botella del ancho de banda aplica no solo a la memoria principal, sino también a todas las caches.
Si el ancho de banda de una cache de instrucciones es de t bps y la longitud media de las instrucciones es de r bits, la cache podrá suministrar cuando mas t/r instrucciones por segundo. Cabe señalar que este es un límite superior de la rapidez con que el procesador puede ejecutar instrucciones, aunque se están realizando investigaciones cuya meta es superar la barrera al parecer infranqueable. Es evidente que la rapidez con que se pueden ejecutar las instrucciones (es decir, la velocidad del procesador) podría estar limitada por la longitud de las instrucciones. El hecho de que las instrucciones sean más cortas implica un procesador más rápido. Dado que los procesadores modernos pueden ejecutar varias instrucciones en cada ciclo de reloj, es imperativo traer varias instrucciones en cada ciclo de reloj. Este aspecto de la cache de instrucciones hace que el tamaño de las instrucciones sea un criterio de diseño importante.
BibliografiaVolver
- Tanenbaum Andrew S., Organización de computadoras, 5ta edición.
MODULO IV: LENGUAJE DE PROGRAMACION DE LOS PROCESADORES
4.1 Ensambladores y Compiladores
4.2 MASM y DEBUG
4.3 Palabras Reservadas
4.4 Operadores y Directivas
4.5 Logica y Control de Programas
4.6 Interrupciones
4.7 Desarollo de Programas
Descargar modulo
4.1 Ensamblador
El término ensamblador se refiere a un tipo de programa informatico que se encarga de traducir un fichero fuente escrito en un lenguaje ensamblador, a un fichero objeto que contiene codigo maquina, ejecutable directamente por la máquina para la que se ha generado. El propósito para el que se crearon este tipo de aplicaciones es la de facilitar la escritura de programas, ya que escribir directamente en codigo binario, que es el único código entendible por la computadora, es en la práctica imposible. La evolución de los lenguajes de programación a partir del lenguaje ensamblador originó también la evolución de este programa ensamblador hacia lo que se conoce como programa compilador.
Un ensamblador es un programa que toma como datos un programa escrito en el lenguaje ensamblador y genera como resultado un programa en el lenguaje de maquina. El programa original, escrito en el lenguaje ensamblador se denomina programa fuente. El programa generado en el lenguaje de maquina se conoce como programa objeto.
El programa objeto generalmente no es un programa ejecutable directamente debido a que las direcciones alas cuales hace referencia son direcciones relativas y se ensambla a partir de la dirección 0. Tambien es factible que este programa utilice rutinas ya desarrolladas previamente y guardadas en la biblioteca del sistema computacional, las cuales tienen que ser añadidas y ligadas al programa objeto.
Cuando un programa objeto ya ha sido ligado con los subprogramas externos que utiliza, se convierte en un programa ejecutable, el cual puede ser cargado a memoria y ejecutable.
Funcionamiento
El programa lee el fichero escrito en lenguaje ensamblador y sustituye cada uno de los códigos mnemotécnicos que aparecen por su código de operación correspondiente en sistema binario.
Tipos de ensambladores
Podemos distinguir entre tres tipos de ensambladores:
1.-Ensambladores básicos.Son de muy bajo nivel, y su tarea consiste básicamente en ofrecer nombres simbólicos a las distintas instrucciones, parámetros y cosas tales como los modos de direccionamiento. Además, reconoce una serie de directivas (o meta instrucciones) que indican ciertos parámetros de funcionamiento del ensamblador.
2.-Ensambladores modulares, o macro ensambladores. Descendientes de los ensambladores básicos, fueron muy populares en las décadas de los 50 y los 60, antes de la generalización de los lenguajes de alto nivel. Hacen todo lo que puede hacer un ensamblador, y además proporcionan una serie de directivas para definir e invocar macroinstrucciones (o simplemente, macros).
3.-Ensambladores modulares 32-bits o de alto nivel. Son ensambladores que aparecieron como respuesta a una nueva arquitectura de procesadores de 32 bits, muchos de ellos teniendo compatibilidad hacia atrás pudiendo trabajar con programas con estructuras de 16 bits. Además de realizar la misma tarea que los anteriores, permitiendo también el uso de macros, permiten utilizar estructuras de programación más complejas propias de los lenguajes de alto nivel.
Lenguaje ensamblador
El lenguaje ensamblador es un tipo de lenguaje de bajo nivel utilizado para escribir programas informáticos, y constituye la representación más directa del código máquina específico para cada arquitectura de computadoras legible por un programador.
Fue usado ampliamente en el pasado para el desarrollo de software, pero actualmente sólo se utiliza en contadas ocasiones, especialmente cuando se requiere la manipulación directa del hardware o se pretenden rendimientos inusuales de los equipos.
Ensambladores
Un ensamblador crea código objeto traduciendo instrucciones mnemónicas a códigos operativos, e interpretando los nombres simbólicos para direcciones de memoria y otras entidades. El uso de referencias simbólicas es una característica básica de los ensambladores, evitando tediosos cálculos y direccionamiento manual después de cada modificación del programa. La mayoría de los ensambladores también incluyen facilidades para crear macros , a fin de generar series de instrucciones cortas que se ejecutan en tiempo real, en lugar de utilizar subrutinas.
Los ensambladores son por lo general más fáciles de programar que los compiladores de lenguajes de alto nivel, y han estado disponibles desde la década de 1950. Los ensambladores modernos, especialmente para arquitecturas basadas en RISC, como por ejemplo MIPS, SPARC y PA-RISC optimizan las instrucciones para explotar al máximo la eficiencia de segmentación del CPU.
Los ensambladores de alto nivel ofrecen posibilidades de abstracción que incluyen:
1.-Control avanzado de estructuras.
2.-Procedimientos de alto nivel, declaración de funciones.
3.-Tipos de datos que incluyen estructuras, registros, uniones, clases y conjuntos.
4.-Sofisticado procesamiento de macros.
Lenguaje ensamblador
Un programa escrito en lenguaje ensamblador consiste en una serie de instrucciones que corresponden al flujo de órdenes ejecutables que pueden ser cargadas en la memoria de una computadora. Por ejemplo, un procesador x86 puede ejecutar la siguiente instrucción binaria como se expresa en código maquina:
- Binario: 10110000 01100001 (Hexadecimal: 0xb061)
La representación equivalente en ensamblador es más fácil de recordar:
Esta instrucción significa:
- Mueva el valor hexadecimal 61 (97 decimal) al registro "al".
El mnemónico "mov" es un código de operación u "opcode" , elegido por los diseñadores de la colección de instrucciones para abreviar "move" (mover).- El opcode es seguido por una lista de argumentos o parámetros, completando una instrucción de ensamblador típica.
La transformación del lenguaje ensamblador en código máquina la realiza un programa ensamblador, y la traducción inversa la puede efectuar un desensamblador. A diferencia de los lenguajes de alto nivel, aquí hay usualmente una correspondencia 1 a 1 entre las instrucciones simples del ensamblador y el lenguaje máquina. Sin embargo, en algunos casos, un ensamblador puede proveer "pseudo instrucciones" que se expanden en un código de máquina más extenso a fin de proveer la funcionalidad necesaria. Por ejemplo, para un código máquina condicional como "si X mayor o igual que" , un ensamblador puede utilizar una pseudo instrucción al grupo "haga si menor que" , y "si = 0" sobre el resultado de la condición anterior. Los ensambladores más completos también proveen un rico lenguaje de macros que se utiliza para generar código más complejo y secuencias de datos.
Cada arquitectura de computadoras tiene su propio lenguaje de máquina, y en consecuencia su propio lenguaje ensamblador. Los ordenadores difieren en el tipo y número de operaciones que soportan; también pueden tener diferente cantidad de registros, y distinta representación de los tipos de datos en memoria. Aunque la mayoría de las computadoras son capaces de cumplir esencialmente las mismas funciones, la forma en que lo hacen difiere, y los respectivos lenguajes ensambladores reflejan tal diferencia.
Ejemplos de lenguaje ensamblador
El siguiente es un ejemplo del programa clásico Hola mundo escrito para la arquitectura de procesador x86 (bajo el sistema operativo DOS ).
.model small
.stack
.data
Cadena1 DB 'Hola Mundo.$'
.code
programa:
mov ax, @data
mov ds, ax
mov dx, offset Cadena1
mov ah, 9
int 21h
end programa
Compiladores
la funcion de un compilador es leer un programa escrito en un lenguaje, en este caso el lenguaje fuente, y lo traduce a un programa equivalente en otro lenguaje, el lenguaje objeto.
Un compilador es un programa que, a su vez, traduce un programa escrito en un lenguaje de programación a otro lenguaje de programación, generando un programa equivalente. Usualmente el segundo lenguaje es código de máquina, pero también puede ser simplemente texto. Este proceso de traducción se conoce como compilación.
La razón principal para querer usar un compilador es querer traducir un programa de un lenguaje de alto nivel, a otro lenguaje de nivel inferior (típicamente lenguaje de máquina). De esta manera un programador puede diseñar un programa en un lenguaje mucho más cercano a como piensa un ser humano, para luego compilarlo a un programa más manejable por una computadora.
Normalmente los compiladores están divididos en dos partes:
1.-Front End: es la parte que analiza el código fuente, comprueba su validez, genera el árbol de derivación y rellena los valores de la tabla de símbolos. Esta parte suele ser independiente de la plataforma o sistema para el cual se vaya a compilar.
2.-Back End: es la parte que genera el código máquina, específico de una plataforma, a partir de los resultados de la fase de análisis, realizada por el Front End.
Esta división permite que el mismo Back End se utilice para generar el código máquina de varios lenguajes de programación distintos y que el mismo Front End que sirve para analizar el código fuente de un lenguaje de programación concreto sirva para la generación de código máquina en varias plataformas distintas.
El código que genera el Back End normalmente no se puede ejecutar directamente, sino que necesita ser enlazado por un programa enlazador (linker).
Tipos de compiladores
Esta taxonomía de los tipos de compiladores no es excluyente, por lo que puede haber compiladores que se adscriban a varias categorías:
1.-Compiladores cruzados: generan código para un sistema distinto del que están funcionando.
2.-Compiladores optimizadores: realizan cambios en el código para mejorar su eficiencia, pero manteniendo la funcionalidad del programa original.
3.-Compiladores de una sola pasada: generan el código máquina a partir de una única lectura del código fuente.
4.-Compiladores de varias pasadas: necesitan leer el código fuente varias veces antes de poder producir el código máquina.
5.-Compiladores JIT (Just In Time): forman parte de un intérprete y compilan partes del código según se necesitan.
Pauta de creación de un compilador: En las primeras épocas de la informática, el software de los compiladores era considerado como uno de los más complejos existentes.
Los primeros compiladores se realizaron programándolos directamente en lenguaje máquina o en ensamblador. Una vez que se dispone de un compilador, se pueden escribir nuevas versiones del compilador (u otros compiladores distintos) en el lenguaje que compila ese compilador.
Actualmente existen herramientas que facilitan la tarea de escribir compiladores ó intérpretes informáticos. Estas herramientas permiten generar el esqueleto del analizador sintáctico a partir de una definición formal del lenguaje de partida, especificada normalmente mediante una gramática formal y barata, dejando únicamente al programador del compilador la tarea de programar las acciones semánticas asociadas.
¿Qué es un compilador?
Un traductor es cualquier programa que toma como entrada un textoescrito en un lenguaje, llamado fuente y da como salida otro texto en un lenguaje, denominado objeto.

Compilador
En el caso de que el lenguaje fuente sea un lenguaje de programacion de alto nivel y el objeto sea un lenguaje de bajo nivel (ensamblador o código de máquina), a dicho traductor se le denomina compilador. Un ensamblador es un compilador cuyo lenguaje fuente es el lenguaje ensamblador.
4.3 Palabras reservadas
Las palabras reservadas son aquellas propias del lenguaje de programación y estas no las podemos usar para darle nombres a nuestras constantes o variables. En el lenguaje ensamblador a estas palabras reservadas se le conocen como neumónicos, siendo estas una representación simbólica de un conjunto de instrucciones maquina, esto lleva a decir que el lenguaje ensamblador es la primera abstracción del lenguaje maquina sin llegar a hacer el ensamblador un lenguaje de alto nivel.
Esta característica es básica del lenguaje ensamblador. El usar mnemónicos en realización de programas y que estas sustituyan la tarea de estar haciendo tediosos cálculos en números binario, hexadecimal y direccionamientos a memoria de forma manual.
Como no todas las palabras reservadas del lenguaje ensamblador son usadas para una misma tarea en específico. Estas están dividas según su propósito. Esto nos lleva a dividir las palabras reservadas en categorías. Las categorías son las siguientes:
- Instrucciones
- Directivas
- Operadores
- Símbolos
Instrucciones
Las instrucciones son los enunciados de un programa, podría decirse que cada instrucción es un enunciado en el programa fuente. En ensamblador tenemos las instrucciones con 1 operando, con 2 operándoos y con operándos implícitos.
- Con dos operandos: LEA DX, CADENA.
- Con un operando: INC BX
- Con operando implícitos: POPF, PUSHF, RET, ETC.
Directivas
Estos tipos de palabras reservadas son similares a las instrucciones, pero a diferencia de estas, las directivas son propias del lenguaje ensamblador e independientes del microcontrolador que se utilice. Las directivas son necesarias para controlar el proceso de ensamblado; le dicen al ensamblador cuales son las secciones del programa, como definir las variables, para definir el tipo de procesador empleado así como la configuración de este, cómo asignar locaciones de memoria, como estructurar el programa, entre otras aplicaciones.
- Las siguientes son algunas de las directivas que encontraríamos en un programa sencillo: .MODEL SMALL, .STACK, .SEGMENT, .STARTUP, NOMBRE MACRO, ENDM, NOMBRE PROC, ENDP, .EXIT, END
Operadores
Dentro de La categoría de operadores tenemos los siguientes:
- Operadores aritméticos: ADD (+), SUB (-), MUL (*), DIV (/). etc.
Ejemplo: ADD AL, 32 ; sumará el número 23 al registro AL
- Operadores lógicos: AND, OR, XOR, NOT.
Ejemplo: MOV BL, (255 AND 128)
- Operadores relacionales: EQ (=), NE (!=), LT (<), GT (>), LE (<=), G (>=)
Ejemplo: VARIABLE EQU 100 ;esto quiere decir que variable = 100
- Operadores de retorno de valores: SEG, OFFSET
4.4 Operándos y directivas
Los operandos es un elemento de una instrucción a ejecutar y pueden haber des 0 hasta 2 operandos, en el siguiente ejemplo tenmos dos operandos
Ejemplo: mov al,'j'
En la anterior instrucción se esta pasando una letra al registro ("Al"), este es un registro de uso general.
En la anterior instrucciones tenemos dos operandos: uno es un registro ("AL") y el otro es una constante de tipo char ("J").
Las directivas son propias del lenguaje ensamblador, esto quiere decir que los lenguajes ensambladores se programaran con los mismos registros, entre algunos son: dx,ax,al,etc... pero las directivas cambiaran de ensamblador en ensamblador, por ejemplo la directiva para iniciar un programa en MASM es "END" y para llamar un procedimiento es "CALL nombre", mientras que en otro lenguaje ensamblador como ASM las directivas seran otras.
De una forma simplificada, para que no batalles tanto:
Ejemplo:
"CMP AL,0"
Operando: son los elementos de una instrucción, la anterior instrucción consta de dos operandos, pero los puede haber de 0, 1 y 2
Instrucción: es una linea de programación ejemplo "CMP AL,0"
Operadores: Los hay aritmeticos, relacionales, etc... ejemplo de operadores aritmeticos: "AND, DIV, SUB" que corresponde a "+,/,-" respectivamente.
Directivas: le dicen al Ensamblador cuáles son las secciones del programa, cómo definir las variables, y cómo estructurar el programa, entre otras aplicaciones. Estas palabras son propias de cada lenguaje ensamblador.
Ejemplos: END, .EXIT, STARTUP, .MODEL, .STACK, .SEGMENT. NOMBRE PROC, NOMBRE ENDP, CALL NOMBRE, ETC...
4.6 Interrupciones
Las interrupciones son cambios en el flujo de control causados no por el programa en ejecución si o por otra cosa, casi siempre relacionada con E/S. por ejemplo, un programa podría ordenar al disco que comience a transferir información, y que genera una interrupción apenas haya terminado la transferencia. Al igual que la trampa, la interrupción detiene el programa en ejecución y transfiere el control a un manejador de interrupciones, el cual realiza alguna acción apropiada. Cuando el manejador de interrupciones termina, devuelve el control al programa interrumpido. El proceso interrumpido se debe reiniciar en el mismo estado exactamente en el que estaba cuando ocurrió la interrupción, lo que implica restaurar todos los registros internos a su estado previo a la interrupción
La diferencia fundamental entre las trampas y las interrupciones es está: las trampas son sincrónicas con el programa y las interrupciones son asincrónicas. Si el programa se vuelve a ejecutar un millón de veces con las mismas entradas, las trampas volverán a ocurrir en el mismo punto en cada ocasión pero las interrupciones podrían variar, dependiendo, por ejemplo, del momento exacto en que una persona sentada ante una Terminal pulsa el retorno de carro. La razón de que las trampas sean reproducibles y las interrupciones no lo sean es que las primeras son causadas directamente por el programa, mientras que las segundas son, si acaso, indirectamente causadas por el programa.
4.7 Desarrollo de programas
Introducción
El desarrollo de programas en ensamblador requiere un conocimiento en detalle de la arquitectura del procesador y una meticulosidad extrema a la hora de decidir qué instrucciones y datos utilizar. Al trabajar con el lenguaje máquina del procesador, la comprobación de errores de ejecución es prácticamente inexistente. Si se ejecuta una instrucción con operandos incorrectos, el procesador los interpretará tal y como estipula su lenguaje máquina, con lo que es posible que la ejecución del programa produzca resultados inesperados.
Desafortunadamente no existe un conjunto de reglas que garanticen un desarrollo simple de los programas. Esta destreza se adquiere mediante la práctica y, más importante, mediante el análisis detenido de los errores, pues ponen de manifiesto aspectos de la programación que se han ignorado.
Las recomendaciones que se hacen para el desarrollo de programas en lenguaje de alto nivel adquieren todavía más relevancia en el contexto del lenguaje ensamblador. Sin ser de ninguna manera una lista exhaustiva, se incluyen a continuación las más relevantes.
- El valor de los registros y el puntero de pila antes de ejecutar la última instrucción del programa deben ser idénticos a los valores que tenían al comienzo.
- Se deben evitar las operaciones innecesarias. Por ejemplo, salvar y restaurar todos los registros independientemente de si son utilizados o no.
- Debido al gran número de instrucciones disponibles y a su simplicidad siempre existen múltiples forma de realizar una operación. Generalmente elige aquella que proporciona una mayor eficiencia en términos de tiempo de ejecución, utilización de memoria o registros, etc.
- Mantener un estilo de escritura de código que facilite su legibilidad. Escribir las etiquetas a principio de línea, las instrucciones todas a la misma altura (generalmente mediante ocho espacios), separar los operandos por una coma seguida de un espacio, etc.
- La documentación en el código es imprescindible en cualquier lenguaje de programación, pero en el caso del ensamblador, es crucial. Hacer uso extensivo de los comentarios en el código facilita la comprensión del mismo además de simplificar la detección de errores. Los comentarios deben ser lo más detallados posible evitando comentar instrucciones triviales. Es preferible incluir comentarios de alto nivel sobre la estructura global del programa y los datos manipulados.
- La mayor parte de errores se detectan cuando el programa se ejecuta. No existe una técnica concreta para detectar y corregir un error, pero se debe analizar el código escrito de manera minuciosa. En ensamblador un simple error en el nombre de un registro puede producir que un programa sea incorrecto.
Elementos necesarios para crear un programa
- Primero un editor para crear el programa fuente.
- Segundo un compilador que no es más que un programa que "traduce" el programa fuente a un programa objeto.
- Tercero un enlazador o linker, que genere el programa ejecutable a partir del programa objeto.
El editor puede ser cualquier editor de textos, como compilador el MASM (macro ensamblador de Microsoft) es el mas común, y como enlazador utilizaremos el programa link.
La extensión usada para que MASM reconozca los programas fuente en ensamblador es .ASM; una vez traducido el programa fuente, el MASM crea un archivo con la extensión .OBJ, este archivo contiene un "formato intermedio" del programa, llamado así porque aun no es ejecutable pero tampoco es ya un programa en lenguaje fuente. El enlazador genera, a partir de un archivo .OBJ o la combinación de varios de estos archivos, un programa ejecutable, cuya extensión es usualmente .EXE aunque también puede ser .COM, dependiendo de la forma en que se ensambló.
Pasos para crear un programa ejecutable
El primer paso, por tanto, para la obtención de un programa ejecutable es la creación de un fichero de texto que contenga el código.

Un programa consta de varias secciones separadas cada una de ellas por palabras clave que comienzan por el símbolo “.” En la imagen anterior se muestra la estructura de un programa en lenguaje ensamblador.
Segundo paso. Se dice que el masm solo puede soportar archivos con la extencion OBJ. Para este caso primero tenemos que utilizar el masm para crear un archivo intermedio que es llamado .obj, después tenemos que utilizar el programa link para que este cree el archivo ejecutable.
En las versiones mas recientes del masm no hace falta hacer estos dos pasos por separados. Con el masm6 podemos hacer estos dos pasos en uno solo. El masm se encargar de crear el archivo obj y el archivo exe.
En el masm6 abrimos el Promt y tecleeamos la dirección de la carpeta donde están todos los archivos del masm. Después tecleamos “ml” seguido del nombre del programa con la extensión .asm


Una vez dado enter se mostraran los resultados (ver la imagen), si hay errores, se mostrara el no de linea donde hay un error. SI el masm encuentra errores, entonces no se creara el ejecutable.
Programa objeto se debe pasar al MASM para crear el código intermedio, el cual queda guardado en un archivo con extensión .OBJ. El comando para realizar esto es:
Paso 3 Si todo se muestra como la imagen anterior, esto quiere decir que nuestro programa no tiene errores. También indica que se creo un archivo obj y un archivo ejecutable. Como ya tenemos nuestro archivo ejecutable, lo que necesitamos ahora es ejecutarlo. Entonces en la línea del Promt tecleamos el nombre del programa sin olvidar la extensión .exe. y correrá nuestro programa, en la siguiente imagen se muestra la ejecución de un programa ya previamente pasado por los dos pasos anteriores.
Bibliografia
Tanenbaum Andrew S., Organización de computadoras, 5ta edición.
www.wikipedia.org
http://html.rincondelvago.com
http://www.lacoctelera.com
http://148.202.148.5/cursos
http://micropic.wordpress.com
http://www.it.uc3m.es/ttao
http://www.legionarteydiseno.250x.com/
En la siguiente URL podemos encontrar todas las palabras que cuenta el lenguaje ensamblador
http://homepage.mac.com/eravila/asmix86a.html
UNIDAD V: OPERACION DEL SISTEMA
5.1 Concepto de Memoria Virtual
5.2 Implementacion de Paginas
5.3 Politicas de Reemplazo
5.4 Segmentacion
5.5 Implementacion de la Segmentacion
5.6 Instrucciones Virtuales
5.7 Procesamiento con Instrucciones Virtuales
Descargar Modulo
5.1Memoria virtual
En los albores de la computación, las memorias eran pequeñas y costosas. EL IBM 650, la principal computadora científica de su época (fines de la década de los cincuenta), solo tenía 2000 palabras de memoria. Uno de los primeros compiladores ALGOL 60 se escribió para una maquina que solo tenia 1027 palabras de memoria. Uno de los primeros sistemas de tiempo compartido trabajaba de forma muy satisfactoria en una PDP-1 con un tamaño total de memoria 4096 palabras de 18 bits para el sistema operativo y los programas de usuario combinados. En esos días el programador dedicaba gran parte de su tiempo a a lograr que sus programas cupieran en la diminuta memoria. En muchos casos era necesario usar un algoritmo que trabajaba mucho mas despacio que otro algoritmo mejor, simplemente por que el algoritmo mejor era demasiado grande; es decir, un programa que usaba el algoritmo mejor no cabía en la memoria de la computadora.
La solución tradicional a este problema era usar memoria secundaria, como un disco. El programador dividía el programa en varios fragmentos, llamados superposiciones, cada uno de los cuales cabían en la memoria. Para ejecutar el programa, se leía la primera superposición y se ejecutaba durante un rato. Cuando terminaba, leía la siguiente superposición y la invocaba, y así. El programador tenía la responsabilidad de dividir el programa en superposiciones, decidir en que lugar de la memoria secundaria se debía guardar cada superposición, encargarse del traslado de superposiciones entre la memoria principal y la memoria secundaria, y en general administrar el proceso de superponer sin ayuda de la computadora.
Invertido en la gestión de superposiciones. En 1961 un grupo de investigadores de Manchester, Inglaterra, propuso un método para realizar automáticamente el proceso de superponer, sin que el programador siquiera supiera que estaba ocurriendo (Fotheringham. 1961). Este , método, ahora conocido como memoria virtual, tenia la ventaja obvia de liberar al programador de una gran cantidad de molestas tareas de contabilidad, y se uso pro primera vez en los años 60s en varias computadoras, casi todas las asociadas a proyectos de investigación sobre diseño de sistemas de computo. Para cuando comenzó la década de los setenta casi todas las computadoras contaba n con memoria virtual. Ahora hasta las computadoras de un solo chip, incluidos el Pentium II y el UltraSPARC II, tiene sistemas de memoria virtual muy sofisticados.
5.2 Paginación
En sistemas operativos de computadoras, los sistemas de paginación de memoria dividen los programas en pequeñas partes o páginas. Del mismo modo, la memoria es dividida en trozos del mismo tamaño que las páginas llamados marcos de página. De esta forma, la cantidad de memoria desperdiciada por un proceso es el final de su última página, lo que minimiza la fragmentación interna y evita la externa.
En un momento cualquiera, la memoria se encuentra ocupada con páginas de diferentes procesos, mientras que algunos marcos están disponibles para su uso. El sistema operativo mantiene una lista de estos últimos marcos, y una tabla por cada proceso, donde consta en qué marco se encuentra cada página del proceso. De esta forma, las páginas de un proceso pueden no estar contiguamente ubicadas en memoria, y pueden intercalarse con las páginas de otros procesos.
En la tabla de páginas de un proceso, se encuentra la ubicación del marco que contiene a cada una de sus páginas. Las direcciones lógicas ahora se forman como un número de página y de un desplazamiento dentro de esa página. El número de página es usado como un índice dentro de la tabla de páginas, y una vez obtenida la dirección real del marco de memoria, se utiliza el desplazamiento para componer la dirección real. Este proceso es realizado en el hardware del computador.
De esta forma, cuando un proceso es cargado en memoria, se cargan todas sus páginas en marcos libres y se completa su tabla de páginas.
Veamos un ejemplo:
Número de marco |
Programa.#página |
Dirección física |
0 |
Programa A.0 |
1000:0000 |
1 |
Programa A.1 |
1000:1000 |
2 |
Programa A.2 |
1000:2000 |
3 |
Programa D.0 |
1000:3000 |
4 |
Programa D.1 |
1000:4000 |
5 |
Programa C.0 |
1000:5000 |
6 |
Programa C.1 |
1000:6000 |
7 |
Programa D.2 |
1000:7000 |
La tabla de la derecha muestra una posible configuración de la memoria en un momento dado, con páginas de 4Kb. La forma en que se llegó a este estado puede haber sido la siguiente:
Se tienen cuatro procesos, llamados A, B, C y D, que ocupan respectivamente 3, 2, 2 y 3 páginas.
1. El programa A se carga en memoria (se le asignan los marcos 0, 1 y 2)
2. El programa B se carga en memoria (se le asignan los marcos 3 y 4)
3. El programa C se carga en memoria (se le asignan los marcos 5 y 6)
4. El programa B termina, liberando sus páginas
5. El programa D se carga en memoria (se le asignan los marcos 3 y 4 que usaba el proceso B y el marco 7 que permanecía libre)
De esta forma, las tablas simplificadas de cada proceso se ven de esta forma:
Proceso A |
Página |
Marco |
0 |
1000:0000 |
1 |
1000:1000 |
2 |
1000:2000 |
Proceso B |
Página |
Marco |
- |
- |
- |
- |
Proceso C |
Página |
Marco |
0 |
1000:5000 |
1 |
1000:6000 |
Proceso D |
Página |
Marco |
0 |
1000:3000 |
1 |
1000:4000 |
2 |
1000:7000 |
Ahora consideremos qué sucede cuando un programa quiere acceder a su memoria. Si el programa A contiene una referencia a la memoria con dirección 20FE, se realizará el siguiente procedimiento. 20FE es 0010000011111110 en notación binaria (en un sistema de 16 bit), y en el ejemplo se están usando páginas de 4Kb de tamaño. Cuando la petición de la dirección de memoria 20FE es realizada, la Unidad de Gestión de memoria se ve de esta forma:
0010000011111110 = 20FE
{__}|__________|
| |
| v
v Posición de memoria dentro de la página (00FE)
Número de página (0010 = 2)
Al usar páginas de 4096 bytes, todas las ubicaciones dentro de una página pueden ser representadas por 12 bits, en el sistema binario (212=4096), lo que deja 4 bits para representar el número de página. Si las páginas hubieran sido de la mitad del tamaño (2048) se podrían tener 5 bits para el número de página, lo que significa que a menor tamaño de página se pueden tener tablas con más páginas.
Cuando el pedido de acceso a memoria es realizado, la MMU busca en la tabla de páginas del proceso que realizó el pedido por la relación en memoria física. En nuestro ejemplo, la página número 2 del proceso A corresponde al marco número 2 en memoria física, con dirección real 1000:2000, por lo tanto, la MMU devolverá la dirección del marco en memoria física, con el desplazamiento dentro de esa página: 1000:20FE.
5.3 Políticas de reemplazo
Como habíamos mencionado anterior al conjunto de páginas se les llama conjunto de trabajo, se puede mantener en la memoria a fin de reducir los fallos de páginas (se le llama así cuando no se encuentra una página en la memoria principal), sin embargo, los programadores casi nunca saben cuales páginas están en el conjunto de trabajo, por lo que el sistema operativo debe descubrir dicho conjunto dinámicamente. Cuando un programa hace referencia a una página que no esta en la memoria principal, la página requerida debe traerse del disco. Sin embargo, para que quepa generalmente es necesario enviar alguna otra pagina de vuelta al disco, se necesitan un algoritmo que decida cual pagina debe quitarse.
Probablemente no es una buena idea escoger al azar la página que se quitará. Si la página que contiene la instrucción que causó el fallo es que se escoge, ocurriría otro fallo de página tan pronto se intente traer la siguiente instrucción. Casi todos los sistemas Operativos tratan de predecir cuál de las páginas de la memoria es la menos útil en el sentido de que su ausencia tendría el efecto adverso menos sensible sobre el programa en ejecución, Una forma de hacerlo es predecir cuándo ocurrirá la siguiente referencia a cada página y quitar la página cuya siguiente referencia predicha es más lejana en el futuro. En otras palabras, en lugar de expulsar una página que se necesitará en poco tiempo, se trata de seleccionar una que se necesitará durante un buen tiempo. A continuación los algoritmos mas utilizados
Un algoritmo muy utilizado expulsa la página que se usó menos recientemente porque la probabilidad a priori de que no este en el conjunto de trabajo vigente es alto.
Ejemplo: Imagine un programa que se ejecuta un ciclo grande que se extiende sobre nueva paginas virtuales en una maquina que tiene espacio solo para ocho paginas en la memoria física. Una vez que el programa llega la pagina 7, el estado de la memoria principal seria como se muestra en la figura a. en algún momento se intenta traer una instrucción de la pagina virtual 8, lo que causa un fallo de pagina. Se debe tomar una desición acerca de cual página se expulsará. El algoritmo LRU escoge la pagina virtual 0 porque es la que se usó neváis recientemente. Se quita la pagina virtual 0 y se trae la pagina virtual 8 para sustituirla, y la situación es la que se muestra en la figura b.
Después de ejecutar las instrucciones de la pagina virtual 0, el programa salta al principio del ciclo, a la pagina virtual 0. Este paso causa otro fallo de página. La pagina virtual 0, que acaba de expulsarse, se tiene que volver a traer. El algoritmo LRU escoge la pagina 1 para expulsión, lo cual lleva a la situación de la figura c. el programa continuara en la pagina 0 durante un rato, y luego tratara de traer una instrucción de la pagina virtual 1, causando un fallo de página. Hay que volver a traer la página 1 y para ello se expulsará la pagina 2. Ya deberá ser obvio que el algoritmo LRU esta tomando la peor decisión en cada ocasión (otros algoritmos también fallan en condiciones similares). Sin embargo, si la memoria principal disponible es mayor que el tamaño del conjunto de trabajo, el algoritmo LRU tiende a minimizar el número de fallos de página.
Otro algoritmo de reemplazo de páginas es el FIFO, expulsa la página que se cargó menos recientemente, sin importar cuándo fue la última vez que se hizo referencia a ella. Cada marco de página tiene un contador. Inicialmente, todos los contadores contienen 0. Después de manejarse cada fallo de página, se incrementa en 1 el contador de cada página que actualmente está en la memoria, y el contador de la página que se acaba de traer se pone en 0. Cuando se hace necesario escoger una página para expulsarla, se escoge aquella cuyo contador es el más alto. Esto indica que la página correspondiente ha sido testigo del mayor número de fallos de página, y por lo tanto se cargó antes que cualquiera de las otras páginas que están en la memoria y tiene (con suerte) la mayor probabilidad a priori de no necesitarse más.
Conclusiones (Políticas de reemplazo)
- Las políticas se refieren a los métodos o algoritmos que se utilizan para remplazar las páginas entre memoria virtual y memoria principal.
- Los métodos más comunes son el URL y el FIFO.
- LRU remplaza la pagina que se haya utiliza menos recientemente, aunque causa fallos de paginas este algoritmo es útil si la memoria principal disponible es mayor que el tamaño del conjunto de trabajo, el algoritmo LRU tiende a minimizar el número de fallos de página.
- El algoritmo o método FIFO utiliza un contador para cada pagina en la cual cada vez que ocurre un fallo de pagina se va incrementando el contador, así pues, la pagina que tenga el mayor numero será la pagina mas vieja, por lo tanto es la pagina que se reemplazara.
5.4 Segmentació
La segmentación es un método que proporciona muchos espacios de direcciones totalmente independientes, estos son llamados segmentos. Cada segmento consiste en una sucesión de lineal de direcciones, de la 0 a alguna dirección máxima. La longitud de cada segmento puede ser cualquiera desde 0 hasta el máximo permitido. Diferentes segmentos pueden tener diferentes longitudes, y generalmente así es. Además, la longitud de los segmentos podría cambiar durante la ejecución. La longitud de un segmento de pila podría incrementarse cada vez que algo se mete en la pila y reducirse cada vez que algo se desempila. Este método es considerado entre una de las tres técnicas para el alto rendimiento y la velocidad de los modernos procesadores:
- Arquitectura Harvard (arquitectura que propicia el paralelismo).
- Procesador tipo RISC.
- Segmentación.
Puesto que cada segmento constituye un espacio de direcciones individual, los diferentes segmentos pueden crecer o encogerse de manera independiente, sin afectar a los otros. Si una pila en cierto segmento necesita más espacio de direcciones para crecer, puede tenerlo, porque no hay nada más en su espacio de direcciones con lo que pueda chocar. Desde luego, un segmento podría llenarse, pero los segmentos suelen ser muy grandes, y esto casi nunca sucede. Para especificar una dirección en esta memoria bidimensional segmentada, el programa debe proporcionar una dirección con dos partes: un número de segmento y una dirección dentro de ese segmento. En la siguiente figura se muestra una memoria segmentada que se usa para las tablas de compilador.
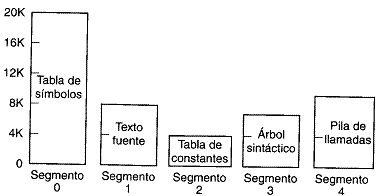
La segmentación también facilita compartir procedimientos o datos entre varios programas. Si una computadora tiene varios programas ejecutándose en paralelo, y todos usan ciertos procedimientos de biblioteca, seria un desperdicio de memoria principal proporcionar a cada uno su copia privada. Si se hace que cada procedimiento este en un segmento distinto, es fácil compartirlos y se elimina la necesidad de tener mas de una copia física de cualquier procedimiento compartido en la memoria principal. El resultado es un ahorro de memoria.
Cada segmento tiene una entidad lógica como por ejemplo puede tener un procedimiento, un arreglo o una pila. Los diferentes segmentos pueden tener diferentes tipos de protección. Un segmento de procedimiento podría especificarse como "solo para ejecución". Un arreglo de punto flotante podría especificarse como de Lectura/escritura. Este tipo de protección suele ser útil para detectar errores de programación.
Comparación entre paginación y segmentación
Consideración |
Paginación |
Segmentación |
¿El programador necesita saber que existe? |
NO |
SI |
¿Cuantos espacios de direcciones lineales hay? |
1 |
MUCHOS |
¿El espacio de direcciones virtual puede exceder el tamaño de la memoria? |
SI |
SI |
¿Es fácil utilizar tablas con tamaño variable? |
NO |
SI |
¿Por qué se inventó esta técnica? |
Para simular memorias grandes |
Para tener muchos espacios de direcciones |
La segmentación permite alcanzar los siguientes objetivos, estos objetivos ya se han discutido en las hojas anteriores
- Modularidad de programas
- Estructuras de datos de largo variable
- Protección
- Comparición
- Enlace dinámico entre segmentos
Ventajas de la segmentación
- El programador puede conocer las unidades lógicas de su programa, dándoles un tratamiento particular.
- Es posible compilar módulos separados como segmentos el enlace entre los segmentos puede suponer hasta tanto se haga una referencia entre segmentos.
- Debido a que es posible separar los módulos se hace más fácil la modificación de los mismos. Cambios dentro de un modulo no afecta al resto de los módulos.
- Es fácil el compartir segmentos.
- Es posible que los segmentos crezcan dinámicamente según las necesidades del programa en ejecución.
- Existe la posibilidad de definir segmentos que aun no existan. Así, no se asignara memoria, sino a partir del momento que sea necesario hacer usos del segmento. Un ejemplo de esto, serian los arreglos cuya dimensión no se conoce hasta tanto no se comienza a ejecutar el programa. En algunos casos, incluso podría retardar la asignación de memoria hasta el momento en el cual se referencia el arreglo u otra estructura de dato por primera vez.
Desventajas de la segmentación
- Hay un incremento en los costos de hardware y de software para llevar a cabo la implantación, así como un mayor consumo de recursos: memoria, tiempo de CPU, etc.
- Debido a que los segmentos tienen un tamaño variable se pueden presentar problemas de fragmentación externas, lo que puede ameritar un plan de reubicación de segmentos en memoria principal.
- Se complica el manejo de memoria virtual, ya que los discos almacenan la información en bloques de tamaños fijos, mientras los segmentos son de tamaño variable. Esto hace necesaria la existencia de mecanismos más costosos que los existentes para paginación.
- Al permitir que los segmentos varíen de tamaño, puede ser necesarios planes de reubicación a nivel de los discos, si los segmentos son devueltos a dicho dispositivo; lo que conlleva a nuevos costos.
- No se puede garantizar, que al salir un segmento de la memoria, este pueda ser traído fácilmente de nuevo, ya que será necesario encontrar nuevamente un área de memoria libre ajustada a su tamaño.
- La comparición de segmentos permite ahorrar memoria, pero requiere de mecanismos adicionales da hardware y software.
5.5 Ejemplo de la segmentación
Hay dos formas de implementar la segmentación: Intercambio y paginación. A continuación se va a hablar sobre el primer caso o modelo. En el primer modelo, cierto conjunto de segmentos está en la memoria, se trae ese segmento. Si no hay espacio para l, será preciso escribir primero en el disco uno o más segmentos (a menos que ya exista ahí una copia limpia, en cuyo caso puede abandonarse la copia que está en la memoria). En cierto sentido, el intercambio de segmentación es parecido a la paginación por demanda: los segmentos entran y salen conforme se van necesitando. Sin embargo, la implementación de la segmentación de la segmentación difiere de la de la paginación en un aspecto fundamental: las páginas tienen un tamaño fijo y los segmentos no.
En el siguiente ejemplo se presenta un fenómeno llamado Fragmentación externa que se da en la implementación de la segmentación en el "intercambio". En la siguiente figura se muestra un ejemplo de memoria física que inicialmente contiene cinco segmentos. Inciso a. Considere ahora que sucede si el segmento 1 se expulsa y se coloca en su lugar el segmento 7. Que es más pequeño. Llegamos a la configuración del inciso b. entre el segmento 7 y el segmento 2 hay un área desocupada, es decir, un hueco. Luego el segmento 4 es sustituido por el segmento 5, como la figura c, y el segmento 3 es sustituido por el segmento 6, como en la figura d. Después de un rato de funcionar el sistema, la memoria estará divida en varios trozos, algunos con segmentos y otros con huecos, a esto se le llama fragmentación externa. Para resolver estos espacios vacíos se utilizan varias técnicas y algoritmos (primer ajuste, mejor ajuste, peor ajuste)
Conclusiones (segmentación)
- Como podemos ver, existen dos implementaciones de la segmentación: intercambio y paginación. En este documento solo se tomo como ejemplo el intercambio.
- La paginación es una técnica de gestión de memoria en la cual el espacio de memoria se divide en secciones físicas de igual tamaño llamadas marcos de pagina, las cuales sirven como unidad de almacenamiento de información.
- La segmentación es un esquema de manejo de memoria mediante el cual la estructura del programa refleja su división lógica; llevándose a cabo una agrupación lógica de la información en bloques de tamaño variable denominados segmentos.
- Las estrategias más comunes para asignar espacios vacíos (huecos) son: primer ajuste, mejor ajuste, peor ajuste.
- La fragmentación es la memoria que queda desperdiciada al usar los métodos de gestión de memoria tal como la asignación.
Introducción E/S virtuales
ISA (Instruction set architecture), son instrucciones a nivel arquitectura (maquina) este nivel se ubica entre el nivel de microarquitectura y el sistema operativo. El nivel ISA es la interfaz entre el software y el hardware.
OSM (Operating system machine) se refiere al nivel que el sistema operativo implementa, el nivel máquina de sistema operativo. Las instrucciones del nivel OSM es el conjunto completo de instrucciones que pueden usar los programadores de aplicaciones; contiene casi todas las instrucciones del nivel ISA, así como el conjunto de instrucciones nuevas que el sistema operativo añade
5.6 Instrucciones de E/S virtuales
El conjunto de instrucciones en el nivel ISA (Instruction Set Arquitecture) es totalmente distinto del conjunto de instrucciones de la microarquitectura. Tanto las operaciones que pueden efectuarse como los formatos de las instrucciones son muy diferentes en los dos niveles. La existencia de unas cuantas instrucciones que son iguales es en esencial accidental. Estos dos tipos de instrucciones junto con las del nivel OSM son niveles para instrucciones de E/S virtuales.
En contraste, el conjunto de instrucciones del nivel OSM contiene casi todas las instrucciones del nivel ISA, con la adición de unas cuantas instrucciones nuevas pero importantes y la eliminaron de unas cuantas instrucciones que podrían ser perjudiciales. La entrada/salida es una de las áreas en la que los dos niveles difieren considerablemente. La razón de esta diferencia es sencilla: Un usuario que puede ejecutar las verdaderas instrucciones de E/S del nivel ISA podría leer datos confidenciales almacenados en cualquier parte del sistema, escribir en las terminales de otros usuarios y, en general, causar muchos estropicios además de ser una amenaza para la seguridad del sistema. Además, los programadores normales, que están en sus cabales no quieren efectuar ellos mismos la E/S en el nivel ISA porque es en extremo tedioso y complejo. Se efectúa asignando valores a campos y bits en diversos registros de dispositivos, esperando hasta que la operación se lleve a cabo, y verificando después que sucedió.
Como ejemplo de esto último, los discos por lo regular tienen bits de registros de dispositivos que detectan los siguientes errores, entre muchos otros:
1.- El brazo del disco no realizo correctamente la búsqueda.
2.- Se especifico memoria inexistente como buffer.
3.- La E/S de disco inicio antes de que terminara la anterior.
4.- Error de temporizacion al leer.
5.- Se direccionó un disco inexistente.
6.- Se direcciono un cilindro inexistente
7.- Se direcciono un sector inexistente.
8.- Error de suma de verificación al leer
9.- Error de verificación de escritura después de operación de escritura.
Cuando ocurre uno de estos errores, se enciende el bit correspondiente de un registro de dispositivo. Pocos usuarios quieren ocuparse de seguir la pista a todos estos bit`s de error y a una gran cantidad de información de estado adicional.
Una forma de organizar la E/S virtual es usar una abstracción llamada ARCHIVO. Un archivo consiste en una secuencia de bytes que se escriben en un dispositivo de E/S. Si el dispositivo de E/S es un dispositivo de almacenamiento el archivo se podrá leer posteriormente, si no es un dispositivo de almacenamiento no podrá leerse, cada uno de los diferentes archivos que contenga algún dispositivo de almacenamiento tiene diferentes longitudes y otras propiedades.
La abstracción de archivos permite organizar la E/S virtual de una forma sencilla. La E/S con archivos se efectúa con llamadas al sistema para abrir, leer, escribir y cerrar archivos. Antes de leer un archivo es preciso abrirlo para que permita al sistema operativo localizar el archivo en el disco y traer a la memoria la información necesaria para acceder a el.
Una ve que se ha abierto un archivo, puede leerse. La llamada al sistema READ debe tener, como mínimo, los siguientes parámetros:
1.- Una indicación de cual archivo abierto debe leerse.
2.- Un apuntador a un buffer en la memoria en que se colocaran los datos.
3.- El numero de bytes que se leerán.
La llamada READ coloca los datos solicitados en el buffer y por lo regular devuelve el numero de bytes que se leyeron realmente, que podría ser menor que el numero solicitado.
Todo archivo abierto tiene asociado un apuntador que indica cual byte se leerá a continuación, después de un READ, el apuntador se incrementa en el número de bytes leídos, por lo que READ´s consecutivos leen bloques consecutivos de datos del archivo. Por lo regular hay una forma de asignar a este apuntador un valor especifico para que los programas puedan acceder aleatoriamente a cualquier parte del archivo, cuando un programa termina de leer un archivo, puede cerrarlo para informar al sistema operativo que ya no usara el archivo y que puede liberar el espacio en tablas que se estaban usando para contener la información acerca del archivo.
Los sistemas operativos de mainframes tienen una idea mas sofisticada de lo que es un archivo, aquí un archivo puede ser una secuencia de registros lógicos, por ejemplo un registro lógico podría ser una estructura de datos que consiste en cinco elementos: Dos cadenas de caracteres, “nombre” y “supervisor”; dos enteros, “Departamento” y “Oficina” y u boleano “SexoEsFemenino”.
La instrucción de entrada virtual básica lee el siguiente registro del archivo especificado y lo coloca en la memoria principal a partir de una dicción especificada, como se ilustra en la figura, para realizar esta operación, hay que indicar a la instrucción virtual cual archivo debe leer y en que lugar de la memoria debe colocar el registro.
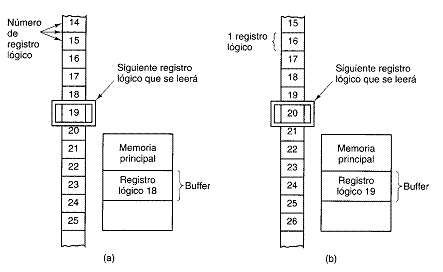
La figura muestra la lectura de un archivo donde (a) es antes de leer el registro 19, y (b) después de leer el registro 19.
La instrucción de salida básica escribe un registro lógico de la memoria en un archivo. Instrucciones write producen registros lógicos consecutivos en el archivo.
5.7Implementación de instrucciones de E/S Virtuales
Para entender cómo se implementan las instrucciones de E/S virtuales, es necesario examinar la organización y almacenamiento de los archivos. Una cuestión básica que debe resolverse con todos los sistemas de archivos es la asignación de almacenamiento. La unidad de asignación puede ser un solo sector de disco, pero es común que consisten en un bloque de sectores consecutivos.
Otra propiedad fundamental de una implementación de sistema de archivos es si un archivo se almacena en unidades de asignación consecutivas o no. en la figura 1 muestra un disco sencillo con una superficie que consiste en cinco pistas de 12 sectores cada una. La figura 1 (a) muestra un esquema de asignación en el que el sector es la unidad básica de asignación de espacio y un archivo consiste en sectores consecutivos. Es común usar la asignación consecutiva de bloques de archivos en los CD-ROM. La figura 1(b) muestra un esquema de asignación en el que el sector es la unidad básica de asignación pero en el que un archivo no tiene que ocupar sectores consecutivos. Este esquema es la norma en los discos duros.
Figura1. Estrategias de asignación de disco (a) Un archivo en sectores consecutivos como el CDROM, (b) un archivo en sectores no consecutivos como los discos duros
Existe una diferencia importante entre la forma como un programador de aplicaciones ve un archivo y la forma en que lo ve el sistema operativo. El programador ve el archivo como una secuencia lineal de bytes o palabras lógicas. El sistema operativo ve el archivo como una colección ordenada, aunque no necesariamente consecutiva, de unidades de asignación en el disco.
Para que el sistema operativo entrega el byte o el registro lógico n de algún archivo cuando se le solicite, debe tener algún método para localizar los datos. Si el archivo se asigna consecutivamente, el sistema operativo sólo tiene que conocer la posición de principio del archivo para poder calcular la posición del byte o registro lógico requerido.
Si el archivo no se asigna consecutivamente, no es posible calcular la posición de un byte o registro lógico arbitrario sólo a partir de la posición del principio del archivo. Para localizar cualquier byte o registro lógico se necesita una tabla llamada INDICE DE ARCHIVOS que da las unidades de asignación y sus direcciones de bloques de disco (como un UNIX) o como lista de registros lógicos, dando la dirección en disco y la distancia para cada uno. A veces cada registro lógico tiene una clave y los programas pueden referirse a un registro por su clave, en lugar de por su número de registro lógico. En este caso se requiere la segunda organización, en la que cada entrada contiene no solo la ubicación del registro en el disco, sino también su clave. Esta organización es común en las mainframes
Un Método alternativo para localizar las unidades de asignación de un archivo es organizar el archivo como lista enlazada, cada unidad de asignación contiene la dirección de su sucesora. Una forma de implementar este esquema de forma eficiente es guardar en la memoria principal la tabla con las direcciones de todas las sucesoras. Por ejemplo, en el caso de un disco con unidades de asignación de 64 K, el sistema operativo podría tener una tabla en la memoria con 64K entradas, cada una de las cuales da el índice de sus sucesoras.
Hasta ahora hemos hablada de archivos asignados consecutiva y no consecutivamente, pero no hemos explicado por qué se usan ambos tipos. La administración de bloques de los archivos asignados consecutivamente es más sencilla, pero cuando no se conoce por adelantado el tamaño máximo del archivo casi nunca es posible usar esta técnica. Si un archivo iniciara en el sector j y pudiera crecer hacia sectores consecutivos, podría toparse con otro archivo en el sector k y no tener más espacio para expandirse. Si el archivo no se asigna consecutivamente, esta situación no representa un problema, porque los bloques subsecuentes se pueden colocar en cualquier lugar del disco. Si un disco contiene varios archivos que están creciendo, y no se conoce el tamaño final de ningunos de ellos, almacenarlos como archivos consecutivos será imposible. A veces es posible cambiar de lugar un archivo existente, pero siempre es costoso.
Por otra parte, si se conoce por adelantado el tamaño máximo de todos los archivos como sucede cuando se graba un CD-ROM, el programa de grabación puede preasignar una serie de sectores cuya longitud es exactamente igual a la de cada archivo. Axial pues, si se va a colocar archivos con longitudes de 1200, 700,2000 y 9'' sectores en un CD-ROM, simplemente se inician en los sectores 0,1200, 1900 y 3900, respectivamente (si nos olvidamos de la tabla de contenido). Encontrar cualquier parte de cualquier archivo es fácil si se conoce el primer sector del archivo.
Para asignar espacio de disco a un archivo, el sistema operativo debe saber cuales bloques están disponibles y en cuáles ya están almacenados otros archivos. En el caso de un CD-ROM, el cálculo se efectúa de una vez por todas antes de la grabación, pero en el caso de un disco duro los archivos entrar y salen constantemente. Un método consiste en mantener una lista de todos los huecos, donde un hueco es cualquiera cantidad de unidades de asignación contiguas. Esta lista se llama lista libre. En la figura 2 (a) se ilustra la lista libre del disco de la figura 1.
Un método alternativo consiste en mantener un mapa de bits, con un bit por unidad de asignación, como se muestra en la figura 2 (b). Un bit 1 indica que la unidad de asignación ya está ocupada, y un bit 0 indica que está disponible
Figura2. Dos formas de llevar la contabilidad de los sectores disponibles (a) una lista libre, (b) un mapa de bits.
EL primer método tiene la ventaja de que facilita la localización de un hueco de cierto tamaño, pero tienen la desventaja de que el tamaño de la lista es variable. A medida que se crean y destruyen archivos, la longitud de la lista fluctúa, característica que es indeseable. El mapa de bits tiene la ventaja de tener un tamaño constante. Además para modificar la situación de una unidad de asignación, de disponible a ocupada, sólo se requiere modificar un bit, Por otra parte, no es fácil encontrar un bloque de un tamaño dado. Ambos métodos requiere que, cuando se asigna o borra cualquier archivo del disco, la lista o tabla de asignación se actualice.
Bibliografía
Tanenbaum Andrew S., Organización de computadoras, 5ta edición.
www.wikipedia.org
Stallings William, Sistemas Operativos, Cuarta edición, Editorial Prentice Hall
fuente: www.elrincondelmanga.com
|
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}