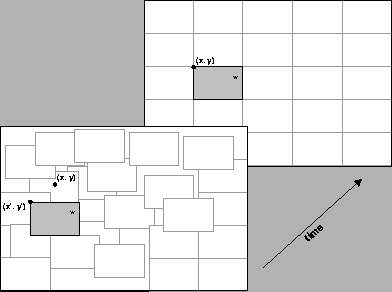
Considering the block of the current frame with its upper-left corner at the position (x,y), the search is done in a restricted area around the pel (x,y) of the previous frame, as it is assumed that the block translations are small from frame to frame. Exhaustive search, checking every possible displacement in the search region, is the simplest approach, while more sophisticated approaches, as logarithmic or three-step search are also applied.
The matching criterion is usually the minimisation of a norm applied to the
luminance values of the two blocks. It does not need to be applied to the
chrominance values as well, as these do not provide additional information about
motion. The
whole process, depicted in Figure 2.3, is summarised:
![\begin{gather*}\forall (dx,dy) \in W,\ \ \mbox{find the vector}\ [dx,dy]^T \\
...
... L}_{(x,y) \in w} [\mbox{\em cur}(x,y),\mbox{\em prev}(x+dx,y+dy)]
\end{gather*}](img7.gif)
where cur stands for the current frame's block, prev for the
previous frame's block, w is the block area, W is the search area, and
dx, dy are the horizontal and vertical displacements of the
reference block. The most commonly used norms are the sum of absolute
differences or
![]() ,
and the sum of squared differences or
,
and the sum of squared differences or
![]() .
.
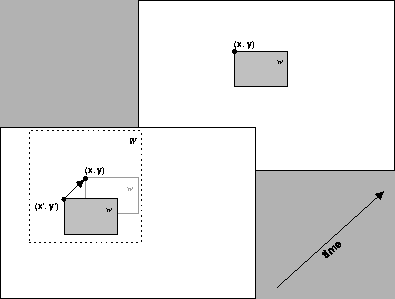
If the best-matching block has its upper-left corner at the position
(x',y') on the previous frame, the motion vector
![]() represents the estimated displacement of this block in order to overlap the
block (x,y) of the current frame.
represents the estimated displacement of this block in order to overlap the
block (x,y) of the current frame.
The collection of all motion vectors of a specific frame, called the vector field, is a motion descriptor of the video sequence. Block matching is a special case of motion estimation, as it only deals with translational motion, and does not cope well with rotational motion. However, the simplicity of the algorithm, and the compliance of most video sequences with its smooth motion assumption, has made the industry to adopt it in most video compression standards.
Block matching is a moderately processor-intensive procedure, and it is done only at the encoding stage. At the decoder, motion compensation takes place, which comprises displacing the previous frame's blocks according to the received vector field. This task is much less processor demanding and it is easily implemented in hardware.