SC207 Software Engineering
Term Paper 2002: Improving Size Estimates Using
Historical Data
Introduction
There are several estimation techniques and tools for
predicting the amount of time and effort needed to develop software systems. For
any estimates to be effective and as accurate as possible, the organization or
people doing the estimate must meet certain constraints and conditions. In the
following report, we will look into how we can improve size estimates by mining
historical data. This report describes our attempt to develop
guidelines for improving size estimates and how the counting of programming
elements might assist us in prediction of the code's ultimate size. We will be
also looking at a case study.
In this report, we will be looking at we are we going
to mine information from completed historical project data. This will enable us
to come up with an efficient and accurate estimate size of future work by
looking into historical past projects, which are similar. It also describes our
attempt to develop guidelines for improving size estimates.
Details
The paper consists of several topics discussed in the
SC207 lecture. The paper mainly talks about software size estimation. Cost
estimation and function-oriented analysis are also mentioned. It talks about the
various estimation techniques such as Cocomo, CocomoII, (SLIM) Software
Lifecycle Management, (SSM) Software Sizing Model, Delphi Methods and Function
Point Analysis. The new contribution is the effective estimating of code size
using data that we already know due to previous experience, i.e. mining of
historical project data.
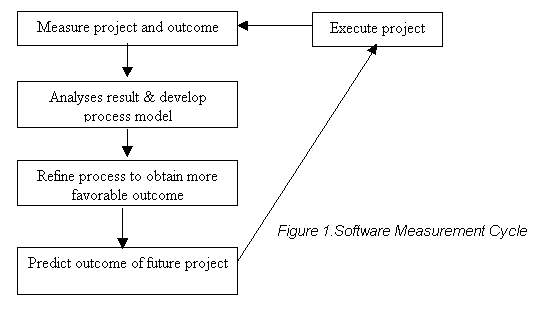
Measurements can be used to predict and estimate. By using past project metrics and other industry metrics, you can predict how long a project will take, how long a project will cost, and how much headcount will be needed. It will give you the information to control the development life cycle of your projects. Figure 1 shows the software estimation cycle.
We will look at a case study on one
of the project in Arco's Research and Technical Services department that was
done in year 1996. The development team uses historical data to improve their
estimation of the size of their project.
Case-study
Arco’s Research and Technical Services department
wanted to come up with an application framework that would help geoscientists
apply the gas and oil industry’s best exploration practices, integrate new
analysis techniques, come up with a user-programmable interface for evaluating
new research methods and accommodate readings and writing of various industry
data formats. They implemented this Direct Hydrocarbon Toolkit software using
objected oriented approach, using X/Motif-based C++ research and data-analysis
application. Their development team consists of four to nine full time
developers. The development team uses a consistent style of programming and upon
completion of the development, the DHI Toolkit consist of 81,000 source lines of
code (SLOC) of C++ and uses 190 components as shown in Table 1.
Table 1(Direct Hydrocarbon Toolkit
software package description)
|
Package |
Number of Components |
Description |
|
Abstract
business objects (Obj) |
16 |
Basic
abstract geoscience business objects, including projects,wells,well
logs,markers,zones, and semsmic data |
|
Concrete
business object input/output (I/O) |
15 |
Concrete
input/output behaviours for abstract business object persistence mechanism |
|
Data
import/export filters (Filter) |
14 |
Abstract
factories, strategies, and GUI components |
|
Application
data factory (Data) |
6 |
Abstract
data object factory providing GUI components for user data selection,
delivering observers of abstract business objects to application contexts |
|
Reusable
GUI components (Components) |
22 |
Reusable
unit labeling text fields, data selection components, and calculation
configuration components |
|
Application
support components (Prefs) |
15 |
User
preference, window layout, and session save/reinstantiation support |
|
Application
GUI (App) |
73 |
User
data display and editing, object property dialogs and calculation setup
dialogs |
There are few estimation techniques available to the
development team. However, the team faced a major problem in estimating size,
which is required for the estimation techniques they know. Furthermore, no one
was trained in function point analysis.
As the project neared completion, they examine how the
presence or absences of different programming element affect the code
volume. They first identify number of GUI elements, events and state changes
handled by a window, dialog, or objects, number of functions in class and
presence of reused components in code. Than, they count the elements listed
earlier that compared the counts to the number of physical lines of code in
the component. Component codes are counted line by line by visual
inspection. They create a tally of instantiated Motif Widgets, events and state
changes handled, class member functions, and automatic and allocated
instantiations of reused in house components. Every compilation unit is
considered a component, regardless of it containing one or multiple class
definitions. Software Engineering Institute definition checklist was utilized
for a logical source statement to determine component size. The checklist can be
modified to include statements to set or retrieve Motif Widget resources. Table
2 shows a sample checklist. Every component contains one or more classes.
Class member functions are common to all components and can be counted
easily. The slope of a package trend to its level in the architecture shows that
the amount of Source Lines of Code (SLOC) increases for higher level of
architecture. Trend relation indicate that size estimates based on the count of
member functions are more meaning for low-level packages as compared to higher
packages. User interface widgets are absent from lower level. Programming
elements are present in higher levels. They than concluded that the more things
in a program, the more the program does, the more that data contributes to
longer code. If they can count and included these things in the early process, a
better estimate of the code size of the software to be developed will be made.
Table 2: Sample Checklist
|
Definition Checklist for Source Statement Counts
|
|||
|
Definition
Name: Logical Source Statements, DHI Toolkit Date:
2002
Measurement
Unit: Logical Source Statements
Originator: Company name |
|||
|
Statement
type: When line contains more than one type, classify it as highest
precedence. |
|||
|
|
Order of Precedence |
Includes |
Excludes |
|
Executables
|
1 |
X |
|
|
Non
Executables |
|
|
|
|
Declarations |
2 |
X |
|
|
Complier directives |
3 |
X |
|
|
Comments |
4 |
|
X |
|
C++
clarifications |
|
|
|
|
Null
statement |
|
|
X |
Conclusion & Future Work
This article helps me understand that artifact counts
are related to size in varying degrees. It also suggests that providing more
information to an estimate increases the prediction’s reliability. The results
obtained can be affected by the developing condition, e.g. size of teams,
implementation of style of coding. It also helps me to understand better various
ways of software size estimation and these methods can be used in our labs.
The diagrams and notation used in the article are also
very helpful and informative. These visual ques help me understand better of the
research paper. With my current knowledge of Software Engineering, I am not able
to improve or modify on the ideas in the article given to me. However, the
results presented in the paper are very useful to the work that is going to be
carried out in the future.
Knowing these various methods can help me select the
best method of estimation for my lab project. After reading the article
and references, I learnt the following must be considered in order to have a
successful estimation of project. We can analyze similar, past
projects to generate the historical data needed to estimate the size of new
software projects. We cannot rely on memory as it is ineffective and leads to
poor estimates. To improve the accuracy of the estimate, the project team
members must be involved in the early stage. Experience is important in having a
good software size estimate (especially when large projects are involved). It
will be excellent if the project team consist of people who are experienced.
Initial size estimate have to be revised when new information becomes available.
A measurements program will allow you to compare your
organization to industry averages and best standards.
References
|
Author(s) |
Year |
Article |
Description |
How does it relate to main article |
|
Edmond
C. Prakash |
2002 |
Software
Engineering Notes |
Describes
concepts of software engineering |
Better
understanding the software engineering processes |
|
http://www.softwarems.com/index.html
|
N.A
|
Software
Management |
Describes
function points, measurements, process, project management, development,
technical staffing |
Better
understanding the software engineering processes. |
|
Addison
Wesley, J.Lakos |
1996 |
Large
Scale C++ Software Projects |
Describes
C++ software projects |
Better
understanding of software projects using C++. |
|
Tomayko,James
E |
1995 |
Sizing
Software |
Describes
the various sizing software techniques |
Know
how do the different methods of sizing software described in the main
article better. |
|
R.E
Park |
1992 |
Software
Size Measurement: A framework for counting Source Statements, Tech. Report |
Describes
the framework for counting source statements. |
Understand
the framework for counting source statements. |
Done
by: Sim Teck Wee William