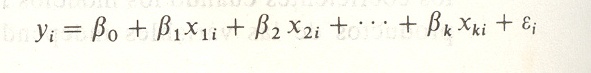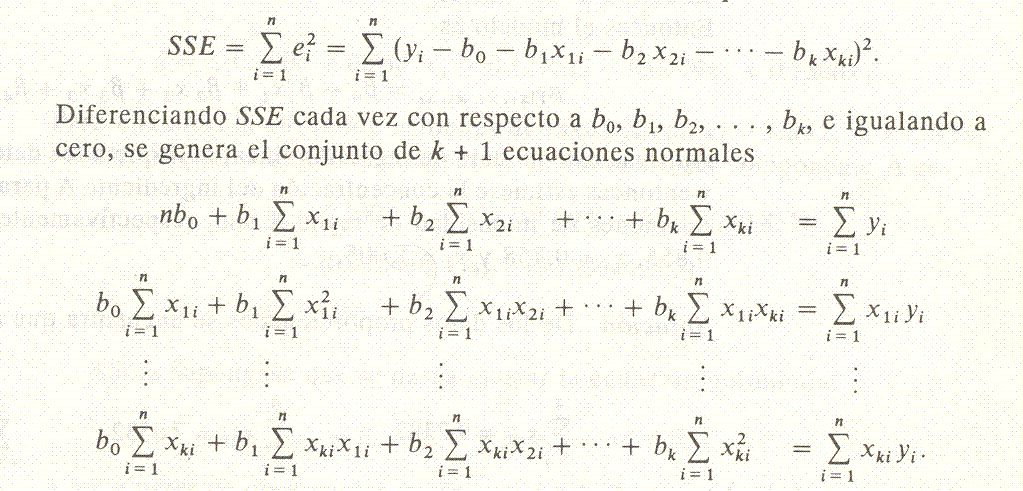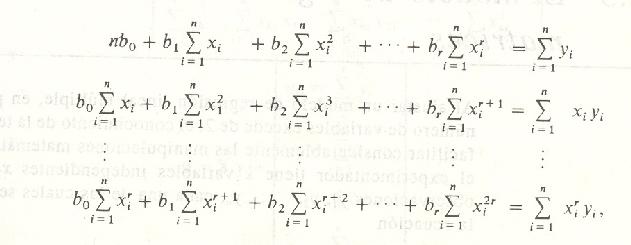3. Estimación de Parámetros de
Regresión
3. Estimación de Parámetros de
Regresión
3. Estimación de Parámetros de
Regresión
![]()
Estimación de los parámetros de la recta de regresión. El primer problema a abordar es obtener los estimadores de los parámetros de la recta de regresión, partiendo de una muestra de tamaño n, es decir, n pares (x1, Y1) , (x2, Y2), ..., (xn, Yn); que representan nuestra intención de extraer para cada xi un individuo de la población o variable Yi .
Una vez realizada la muestra, se dispondrá de n pares de valores o puntos del plano (x1, y1) , (x2, y2), ..., (xn, yn). El método de estimación aplicable en regresión, denominado de los mínimos cuadrados, permite esencialmente determinar la recta que "mejor" se ajuste o mejor se adapte a la nube de n puntos. Las estimaciones de los parámetros de la recta de regresión obtenidas con este procedimiento son:
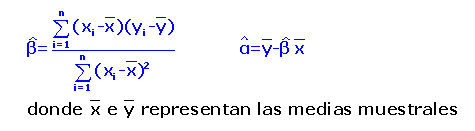
Por tanto la recta de regresión estimada será:
![]()
Estimación de los coeficientes
En esta sección se obtendrán los estimadores de mínimos cuadrados de los parámetros βo, β1, . . . , βk ajustando el modelo de regresión lineal múltiple
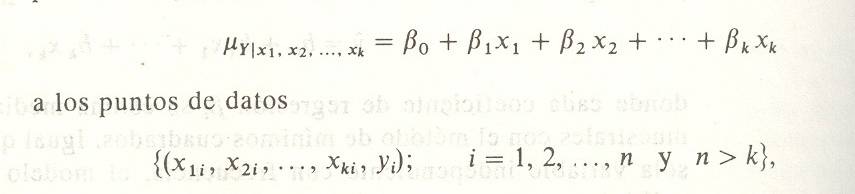
donde yi es la respuesta observada para los valores x1i , x2i ,. . . , xki de las k variables independientes x1 , x2, . . . , Cada observación (x1i , x2i. . . ,xki yi,) satisface la ecuación
o
donde E i y ei son los errores aleatorio y residual, respectivamente, asociados con la respuesta Yi. Al utilizar el concepto de mínimos cuadrados para llegar a los estimadores de b0, b1, . . . , bk, se minimiza la expresión
Estas ecuaciones se pueden resolver para ba, b¡, b2, . . . , bk por ualquier método apropiado para resolver sistemas de ecuaciones lineales.
Ejemplo En química analítica, el análisis de los rayos X fluorescentes es una herramienta para estimar porcentajes de ingredientes en mezclas con multitud de componentes. Con frecuencia, la estimación de concentraciones depende en gran medida de la habilidad del usuario para ajustar los modelos de regresión adecuados. En el documento "Corrections for Matrix Effects in X-Ray Fluorescence Analysis Using Multiple Regression Methods", publicado en Analytical Chemistry (Vol. 37, 1965), se probaron cuatro suspensiones para propulsión que contenían cuatro ingredientes. Las concentraciones de los componentes variaba e,n las suspensiones para producir estándares del tipo de calibración. Los datos son como sigue:
y
X1
X2
X3
X4
0.5514
1.1240
0.8980
0.8219
0.9906
0.4426
0.9285
0.8872
0.9308
0.9944
0.5631
1.1214
0.8030
0.7668
1.1221
0.5624
1.1635
0.8706
0.9272
0.9832
0.4505
0.9415
0.8064
0.9026
1.1127
0.5290
1.0712
0.8404
0.8662
1.0836
0.4702
0.9561
0.8731
0.8206
1.0290
0.5001
1.0186
0.8431
0.8346
1.0591
0.25
0.9039
0.8314
0.7596
1.0994
La respuesta yi es la concentración medida de un ingrediente A. El valor medido x1 'es la "relación de intensidad" asociada con el ingrediente A, y los valores x2, x3 y x4 son las relaciones de intensidad para los componentes adicionales en la suspensión. Como resultado de los efectos de mejora y absorción, la respuesta y se pronostica mejor después de realizar la regresión en contra de los valores de intensidad asociados con todos los componentes. Entonces el modelo es
La solución de este conjunto de ecuaciones da las estimaciones únicas
bo = -0.3004, b1 = 0.5387, b2 = 0.1770,
b3 = -0.0704, b4 = 0.1506.
Por lo tanto, la ecuación de regresión es
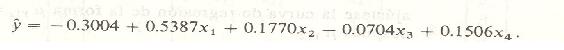
Para una mezcla cuyas intensidades de rayos X son x1 = 1.091, x2 = 0.855, x3 = 0.758 y x4 = 1.005, la concentración estimada del componente A es
y = - 0.3004 + (0.5387)( 1.091) + (0.1770)(0.855)
-(0.0704)(0.758) + (0.1506)(1.005)
= 0.5366.
Ahora supóngase que se desea ajustar l ecuación polinomial
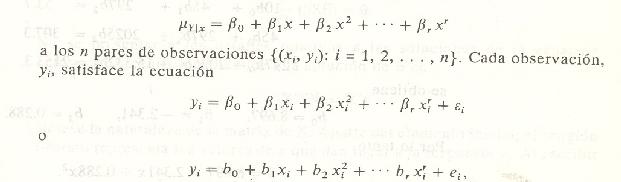
donde r es el grado del polinomio, y Ei Y ei el error y el residual aleatorios asociados con la respuesta Yi' Aquí el número de pares, n, debe ser al menos tan grande como r + 1, el número de parámetros a ser estimados. Nótese que el modelo polinomial puede considerarse un caso especial del modelo más general de regresión lineal múltiple donde se hacen xl = x, x2 = x2, . . . , xr, = Xr. Las ecuaciones normales asumen la forma
las cuales se resuelven igual que antes para b0. b1, . . . br.
Ejemplo. Dada la tabla
x
0
1
2
3
4
5
6
7
8
9
y
9.1
7.3
3.2
4.6
4.8
2.9
5.7
7.1
8.8
10.2
Tipos de estimación estadística
Estimación de parámetros:
Un problema importante de la inferencia estadística es la estimación de parámetros de la población, brevemente parámetros (tales como la media y la variación de la población), de los correspondientes estadísticos muéstrales, o simplemente estadísticos (tales como la media y la variación de la muestra).
Estimaciones sin sesgo:
Si la media de las dispersiones de muestreo con un estadístico es igual que la del correspondiente parámetro de la población, el estadístico se llamara estimador sin sesgo, del parámetro; si no, si no se llama estimador sesgado. Los correspondientes valores de tal estadístico se llaman estimación sin sesgo, y estimación con sesgo respectivamente.
Ejemplo 1: la media de las distribuciones de muestreo de medias e, media de la población. Por lo tanto, la media muestral es una estimación sin sesgo de la media de la población.
Ejemplo 2. Las medias de las distribuciones de muestreo de las variables es:
Para ver el grafico seleccione la opción ¨Bajar trabajo¨ del menú superior
Encontramos, de manera que es una estimación sin sesgo de. Sin embargo, s es una estimación sesgada de. En términos de esperanza podríamos decir que un estadístico es instigado porque Para ver el grafico seleccione la opción ¨Bajar trabajo¨ del menú superior
Estimación Eficiente:
Si las distribuciones de muestreo de dos estadísticos tienen la misma media(o esperanza), el de menor varianza se llama un estimador eficiente de la media, mientras que el otro se llama un estimador ineficiente, respectivamente.
Si consideramos todos los posibles estadísticos cuyas distribuciones de muestreo tiene la misma media, aquel de varianza mínima se llama aveces, el estimador de máxima eficiencia, ósea el mejor estimador.
Ejemplo:
Las distribuciones de muestreo de media y mediana tienen ambas la misma media, a saber, la media de la población. Sin embargo, la varianza de la distribución de muestreo de medias es menor que la varianza de la distribución de muestreo de medianas. Por tanto, la media muestral da una estimación eficiente de la media de la población, mientras la mediana de la muestra da una estimación ineficiente de ella.
De todos los estadísticos que estiman la media de la población, la media muestral proporciona la mejor( la más eficiente) estimación.
En la practica, estimaciones ineficientes se usan con frecuencia a causa de la relativa sencillez con que se obtienen algunas de ellas.
Estimaciones de punto y estimaciones de intervalo, su fiabilidad:
Una estimación de un parámetro de la población dada por un solo numero se llama una estimación de punto del parámetro. Una estimación de un parámetro de la población dada por dos puntos, entre los cuales se pueden considerar encajado al parámetro, se llama una estimación del intervalo del parámetro.
Las estimaciones de intervalo que indican la precisión de una estimación y son por tanto preferibles a las estimaciones de punto
Ejemplo:
Si decimos que una distancia sé a medido como 5.28 metros (m), estamos dando una estimación de punto. Por otra parte, si decimos que la distancia es 5.28 ± 0.03 m, (ósea, que esta entre 5.25 y 5.31 m), estamos dando una estimación de intervalo
El margen de error o la percepción de una estimación nos informa su fiabilidad.
Estimaciones De Intervalos De Confianza Para Parámetros De Población:
Sean y la media y la desviación típica (error típico) de la distribución de muestreo de un estadístico S. Entonces, si la distribución de muestreo de s es aproximadamente normal (que como hemos visto es cierto para muchos estadísticos si el tamaño de la muestra es N³30), podemos esperar hallar un estadisco muestral real S que este en los intervalos alrededor del 68.27 %, 95.45% y 99.7 % del tiempo restante, respectivamente.
La tabla 1. Corresponde a los niveles de confianza usados en la practica. Para niveles de confianza que no aparecen en la tabla, los valores Zc se pueden encontrar gracias a las tablas de áreas bajo la curva normal.
Nivel de confianza
99.7 % 99% 98% 96% 95.45% 95% 90% 80% 6827% 50%
Zc
3.00 2.58 2.33 2.05 2.00 1.96 1.645 1.28 1.00 0.6745
Intervalos de confianza para la media:
Si el estadístico s de la media de la muestra, entonces los limites de confianza respectivamente. Mas en general los limites de confianza para estimar la media de la población m viene dado por usando los valores de
Si el muestreo de la población es infinita por lo tanto viene dado por:
Para ver el grafico seleccione la opción ¨Bajar trabajo¨ del menú superior
Si el muestro es sin reposición de una población de tamaño Np.
Ejemplo
Halar laos limites de confianza de 98% y 90%.para los diámetros de una bolsa
Solución:
Sea Z =Zc tal que al área bajo la curva normal a la derecha sea 1% . Entonces , por simetría el área del lado izquierdo de Z=-Zc . como el área total bajo la curva es 1, Zc= 0.49 por lo tanto, Zc=2.33. luego el limite de confianza es 98% son X= ±2.33s¤ÖN=0.824± 2.33(0.042/ Ö200)=0.824 ±0.069 cm.
Generalmente, la desviación típica de la población no es conocida. Así pues , para obtener los limites usamos la estimación s o S es satisfactorio si N>=30, si a aproximación es pobre y debe de empleare la teoría de pequeñas muestras.
3.Cálculo del tamaño de la muestra
A la hora de determinar el tamaño que debe alcanzar una muestra hay que tomar en cuenta varios factores: el tipo de muestreo, el parámetro a estimar, el error muestral admisible, la varianza poblacional y el nivel de confianza. Por ello antes de presentar algunos casos sencillos de cálculo del tamaño muestral delimitemos estos factores.
Parámetro. Son las medidas o datos que se obtienen sobre la población.
Estadístico. Los datos o medidas que se obtienen sobre una muestra y por lo tanto una estimación de los parámetros.
Error Muestral, de estimación o standard. Es la diferencia entre un estadístico y su parámetro correspondiente. Es una medida de la variabilidad de las estimaciones de muestras repetidas en torno al valor de la población, nos da una noción clara de hasta dónde y con qué probabilidad una estimación basada en una muestra se aleja del valor que se hubiera obtenido por medio de un censo completo. Siempre se comete un error, pero la naturaleza de la investigación nos indicará hasta qué medida podemos cometerlo (los resultados se someten a error muestral e intervalos de confianza que varían muestra a muestra). Varía según se calcule al principio o al final. Un estadístico será más preciso en cuanto y tanto su error es más pequeño. Podríamos decir que es la desviación de la distribución muestral de un estadístico y su fiabilidad.
Nivel de Confianza. Probabilidad de que la estimación efectuada se ajuste a la realidad. Cualquier información que queremos recoger está distribuida según una ley de probabilidad (Gauss o Student), así llamamos nivel de confianza a la probabilidad de que el intervalo construido en torno a un estadístico capte el verdadero valor del parámetro.
Varianza Poblacional. Cuando una población es más homogénea la varianza es menor y el número de entrevistas necesarias para construir un modelo reducido del universo, o de la población, será más pequeño. Generalmente es un valor desconocido y hay que estimarlo a partir de datos de estudios previos.