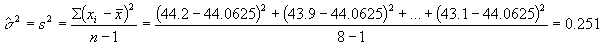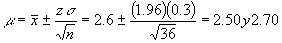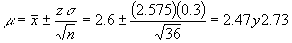La estimación de parámetros
El objetivo de la estimación de parámetros es inferir, partiendo de la estadística (la media) de una muestra, el parámetro de la población, teniendo en cuenta el error de muestreo.
El intervalo de confianza se puede interpretar como el intervalo en que inferimos que se encuentra la media de la población de donde proviene la muestra.
DEFINICIONES IMPORTANTES
Un estimador es una fórmula o proceso usando datos de la muestra para estimar un parámetro de la población.
Un estimado es un valor específico o rango de valores usados para aproximar un parámetro de la población.
Un punto estimado es un valor simple (o punto) usado para aproximar un parámetro de la población.
DEFINICIÓN DE INTERVALOS DE CONFIANZA
Un intervalo de confianza (o intervalo de estimado) es un rango (o intervalo) de valores usados para estimar el valor verdadero del parámetro de la población.
DEFINICIÓN DE GRADOS DE CONFIANZA
Los grados de confianza es la probabilidad 1 – α (frecuentemente expresada como el valor del porciento equivalente) que es la frecuencia relativa de veces que el intervalo de confianza actualmente contiene el parámetro de la población, presumiendo que el proceso de estimación es repetido un número grande de veces. (El grado de confianza es también llamado el nivel de confianza o el coeficiente de confianza.)
En la estadística hay dos formas principales de inferir:
- Estimación y
- Prueba de hipótesis
La estimación parte desde suponer un modelo estadístico para la distribución de la característica que nos interesa en la población. Esta característica es, generalmente, numérica y distinguimos a las variables en continuas y discretas.
Si nos interesa el rendimiento o eficiencia de los trabajadores, tendremos el tiempo de realización de una tarea específica (variable continua).
Si nos interesará el número y tipo de errores cometidos en la factura (variable discreta).
En el primero nos interesa la opinión que mediremos como favorable o desfavorable (variable discreta = número de personas a favor o en contra).
Si tiene Ud. inclinaciones más poéticas, recuerde a la reina de las hadas y su problema de enamorarse del primero que vea al despertar; ahí tenemos el mismo tipo de situación: el amado será guapo o no guapo, y el parámetro desconocido es la ``densidad'' de guapos alrededor de la reina dormida.
Para estimar partimos de un modelo probabilística de cómo se distribuye la característica en la población o de cómo se realizó el muestreo. Este modelo incluye cantidades que desconocemos y que llamamos parámetros
Por ejemplo, en la encuesta para saber la opinión de los clientes, el número de clientes a favor es un parámetro, y la probabilidad de que obtengamos al azar a una persona que está a favor es la proporción de personas a favor en la población (que desconocemos). Esto se parece al lío de la reina de las hadas.
Para los tiempos de realización de la tarea, en el tercer ejemplo, podemos suponer una distribución normal con una media y una desviación estándar desconocidas; nuestro interés se centraría en el valor del promedio de la población.
De la muestra estimamos los valores de los parámetros en la población y esto lo hacemos:
- mediante un valor fijo y entonces decimos que tenemos un estimador puntual o
- mediante un intervalo de posibles valores y le llamamos estimación por intervalo o intervalo de confianza.
Los métodos de estimación puntual pueden tener varias características estadísticas entre las que sobresalen:
- Insesgamiento. Que el valor del parámetro coincida con el valor promedio del estimador. Esta propiedad la tienen la mayoría de los estimadores usados en la práctica.
- Consistencia. Que el valor de la muestra se acerque al valor del parámetro al aumentar el tamaño de la muestra.
- Suficiencia. Que el estimador use toda la información que la muestra contiene respecto al parámetro de interés.
- Eficiencia. Que el estimador tenga menor variabilidad que otro posible.
Estimación puntual
Provee un solo valor, un valor concreto para la estimación.
Un estimador puntual es simplemente un estadístico (media aritmética, varianza, etc.) que se emplea para estimar parámetros (media poblacional, varianza poblacional, etc.).
Por ejemplo, cuando obtenemos una media aritmética a partir de una muestra, tal valor puede ser empleado como un estimador para el valor de la media poblacional.
Algunos autores comparan los estimadores con los lanzamientos en una diana: el círculo central sería el valor real del parámetro.
Hablaremos de nivel de confianza 1-α cuando en el intervalo se encuentre el valor del estimador con probabilidad 1-α.Observa que la probabilidad de error (no contener al parámetro) es α.
En general el tamaño del intervalo disminuye con el tamaño muestral y aumenta con 1-α.
En todo intervalo de confianza hay una noticia buena y otra mala:
La buena: hemos usado una técnica que en % alto de casos acierta.
La mala: no sabemos si ha acertado en nuestro caso.
Por intervalo
Determina dos valores (límites de confianza) entre los que acepta puede estar el valor del estimador.
Métodos de estimación puntual
Método de los momentos
Método de máxima verosimilitud
Método de mínimos cuadrados
Hemos visto que un estimador de la media poblacional es la media muestral y de la varianza poblacional es la seudovarianza muestral. Pero, ¿cómo determinar un estimador cuando no se trata de la media o la varianza?
Por ejemplo, supongamos una población con función densidad:
¿Cómo estimar el parámetro θ?
Método de los momentos
Si una distribución tiene k parámetros, el procedimiento consiste en calcular los primeros k momentos muestrales de la distribución y usarlos como estimadores de los correspondientes momentos poblacionales.
La media poblacional es el primer momento de la distribución alrededor del origen. La media muestral es el promedio aritmético de las observaciones muestrales x1, x2, ..., xn. El método de los momentos toma a la media muestral como una estimación de la media poblacional.
De la misma manera, la varianza de una variable aleatoria es 2 y se denomina segundo momento alrededor de la media. La varianza muestral s2 se usa como un estimador de la varianza poblacional de la distribución.
Recordemos que el momento muestral centrado en el origen
de orden r se define como:
Para el ejemplo anterior, los momentos de primer orden centrados
en el origen de la población y la muestra son respectivamente:
Luego podemos usar como estimador:
Igualando:
Método de máxima verosimilitud
Sea X una variable aleatoria cuya distribución de probabilidad depende del parámetro desconocido .
Sea la función de densidad de probabilidad de la población f(x, ). Se toma una muestra aleatoria x1, x2, ..., xn de observaciones independientes y se calcula la densidad conjunta de la muestra: la función de verosimilitud y se expresa como:
Si de una población cualquiera hemos obtenido una muestraparticular, es razonable pensar que la muestra obtenida era
la que mayor probabilidad tenía de ser escogida.
Valor del estimador máxima verosimilitud
Función máxima verosimilitud
Si los valores posibles de son discretos, el procedimiento es evaluar L(x, ) para cada valor posible y elegir el valor de para el cual L alcanza su máximo.
Por otro lado, si L(x, ) es diferenciable se puede maximizar L sobre el rango de valores posibles de obteniéndose condiciones de primer y segundo orden.
En la práctica es más fácil maximizar el logaritmo de la función de verosimilitud. Como la función logaritmo es una transformación monótona, maximizar L(x, ) es equivalente a maximizar Ln(L(x, )).
Ejemplo: Sea una urna con bolas rojas y blancas en proporcionesdesconocidas. Extraemos 10 bolas con reemplazo (n = 10) y
obtenemos 3R y 7B. Llamemos p a la proporción de R en la urna.
Soluciones: p = 0 p = 1 p = 3/10
Imposible porque hemos extraído 3R
Imposible porque hemos extraído 7B
Que además hace máxima la función L(p)
Volvamos al ejemplo:Construimos la función máxima verosimilitud
Extraemos logaritmos a ambos lados
Derivamos e igualamos a cero para encontrar el máximo de la función
Observemos que no coincide con el estimador que nos propone el método de los momentos.
Propiedades deseables en los estimadores
Ausencia de sesgo
Consistencia
Eficiencia
Suficiencia
Los dos procedimientos que repasamos hace un momento (más el método de mínimos cuadrados que veremos luego) eligen a la media muestral como estimador del parámetro . Sin embargo, otras veces obtenemos estimadores distintos para el mismo parámetro, como ocurre con 2. O como hemos visto para el caso del parámetro del ejemplo.
En esos casos, ¿cuál es el mejor estimador?
1. Estimador insesgado. Diremos que es un estimador insesgado de si:
Vimos que la media muestral es un estimador insesgado de la media poblacional.
Vimos que la varianza muestral no es un estimador insesgado de la varianza poblacional, es sesgado.
Recuerda que construimos la cuasivarianza que sí es un estimador insesgado de la varianza poblacional.
se llama sesgo de
Sea una población N( , ) y construyamos los estimadores de
varianza: varianza muestral y cuasivarianza muestral.
Vimos que si la población es normal, entonces el estimador:
Propiedades en muestras grandes
Muchos estimadores no tienen buenas propiedades para muestras pequeñas, pero cuando el tamaño muestral aumenta, muchas de las propiedades deseables pueden cumplirse. En esta situación se habla de propiedades asintóticas de los estimadores.
Como el estimador va a depender del tamaño de la muestra vamos a expresarlo utilizando el símbolo
Por ejemplo, el sesgo puede depender del tamaño de la muestra. Si el sesgo tiende a cero cuando el tamaño de la muestra crece hasta infinito decimos que el estimador es asintóticamente insesgado.
Ausencia de sesgo asintótica
Definición: Un estimador se dice que es asintóticamente insesgado si
o equivalentemente:2. Consistencia. Se dice que un estimador es consistente si se cumple que
Es decir, a medida que se incrementa el tamaño muestral, el estimador se acerca más y más al valor del parámetro. La “consistencia” es una propiedad asintótica.
Tanto la media muestral como la cuasivarianza son estimadores consistentes. La varianza muestral es un estimador consistente de la varianza poblacional, dado que a medida que el tamaño muestral se incrementa, el sesgo disminuye.
o
Ejemplo: supongamos que la población es no normal y de media
desconocida. Construyamos estadísticos media muestral:
Para cada tamaño muestral n tenemos:
Por el teorema de Chebychev:
La media muestral es un estimador
consistente de la media poblacional.
3. Eficiencia. Utilizar las varianzas de los estimadores insesgados como una forma de elegir entre ellos.
Si , decimos que es un estimador insesgado eficiente o de varianza mínima para , si cualquier otro estimador insesgado de , digamos , verifica que:
La varianza de una variable aleatoria mide la dispersión alrededor de la media. Menor varianza para una variable aleatoria significa que, en promedio, sus valores fluctúan poco alrededor de la media comparados con los valores de otra variable aleatoria con la misma media y mayor varianza. Menor varianza implica mayor precisión y entonces el estimador que tenga menor varianza es claramente más deseable porque, en promedio, está mas cerca del verdadero valor de .Sean y dos estimadores insesgados del parámetro .
Si Var ( ) < Var ( ) decimos que es más eficiente que .
El cociente Var ( ) / Var ( ) se llama eficiencia relativa.
Entre todos los estimadores insesgados de , el que tenga menor varianza es el estimador insesgado de mínima varianza. Pero, ¿cómo podemos encontrarlo?
Cota de Cramér-Rao:Sea una población con densidad de probabilidad f(x, ), entonces se cumple que:
Si un estimador tiene una varianza que coincide con la cota de Cramér-Rao se dice que es un estimador eficiente.
Si además en insesgado, se dice que es un estimador de eficiencia absoluta o completa.
Ejemplo: Sea una población que se distribuye normalmente con desviación típica conocida y media desconocida. Como estimador utilizaremos la media muestral.
Sabemos que la distribución del estimador es también una normal con la misma media y varianza . Luego el estimador es insesgado: b( ) = 0. Calculemos la cota de Cramér-Rao (CCR).
Eficiencia asintótica
Cuando trabajamos con estimadores consistentes el rango de valores de para el cual un estimador es más eficiente que otro disminuye a medida que n crece. En el límite cuando n tiene a infinito la distribución de todos los estimadores consistentes colapsa en el verdadero parámetro . Entonces deberíamos preferir aquel estimador que se aproxime más rápidamente (es decir, aquel cuya varianza converge más rápido a cero)
En términos intuitivos, un estimador consistente es asintóticamente eficiente si para muestras grandes su varianza es menor que la de cualquier otro estimador consistente.
Definición: un estimador consistente se dice que es asintóticamente eficiente si para cualquier otro estimador el
4. Suficiencia. Diremos que es un estimador suficiente del parámetro si dicho estimador basta por sí solo para estimar . Si el conocimiento pormenorizado de los elementos la muestra no añade ninguna información sobre .
Ejemplo: Supongamos una población binomial de la que
desconocemos la proporción = p. Extraemos una muestra
de tamaño n = 50.
Estimador suficiente, p aprox. 35/50.
Error cuadrático medio (ECM)
Consideremos dos estimadores, uno insesgado y el otro es sesgado pero con una varianza bastante menor, de modo que en promedio puede estar más cerca de la verdadera media que el estimador insesgado.
En esta situación podríamos admitir algo de sesgo con la intención de obtener una mayor precisión en la estimación (menor varianza del estimador).
Una medida que refleja este compromiso (“trade off”) entre ausencia de sesgo y varianza es el ECM.
El error cuadrático medio de un estimador se define como ECM ( ) = E[( - )2] . Esto es la esperanza de la desviación al cuadrado del estimador con respecto al parámetro de interés.
Si , son dos estimadores alternativos de y ECM ( ) < ECM ( ) entonces se dice que es eficiente en el sentido del ECM comparado con . Si los dos son insesgados, entonces es más eficiente.
Entre todos los posibles estimadores de , aquel que tenga el menor ECM es el llamado estimador de mínimo error cuadrático medio.
ECM = Var( ) + sesgo2.
es decir que el ECM es igual a la suma de la varianza más el sesgo al cuadrado.
sesgo 2Compromiso
entre varianza y sesgo de los estimadores.
Variable aleatoria
Constante
Ejemplos: Supongamos una población de la que conocemos
la media y la varianza (= 100). Tomemos muestras n = 10.
Consideremos los dos estimadores de la media siguientes:
Dependiendo de la media de la población nos interesará tomar un estimador u otro.
Los estimadores máximo verosímiles son:
Asintóticamente insesgados
Asintóticamente normales
Asintóticamente eficientes
Invariantes bajo transformaciones biunívocas
Si estimador suficiente, es suficiente
Propiedades de los estimadores de máxima verosimilitud
La importancia de la estimación en áreas pequeñas en encuestas por muestreo se va incrementando cada vez
más, debido a la creciente demanda de todos los sectores de la población en la obtención de estimadores
confiables en áreas pequeñas. La propuesta de este estudio es investigar metodologías para la construcción de
estimadores intercensales de varias características de la población residente en áreas pequeñas.
Estimadores directos para áreas pequeñas son, en muchas ocasiones muy inestables, debido principalmente a
muestras pequeñas (o ninguna muestra) tomadas en estas áreas. Estimadores con menos variabilidad pueden
ser obtenidos, pidiendo información de áreas relacionadas, esto conduce al desarrollo de métodos alternativos
tales como estimadores sintéticos, la mejor predicción insesgada empírica (EBLUP), estimadores de Bayes
empíricos (EB) y de Bayes Jerárquicos.
Parámetros y estimadores.
Una población queda caracterizada a través de ciertos valores denominados parámetros, que describen las principales propiedades del conjunto.
Un parámetro es un valor fijo (no aleatorio) que caracteriza a una población en particular. En general, una parámetro es una cantidad desconocida y rara vez se puede determinar exactamente su valor, por la dificultad práctica de observar todas las unidades de una población. Por este motivo, tratamos de estimar el valor de los parámetros desconocidos a través del empleo de muestras. Las cantidades usadas para describir una muestra se denominan estimadores o estadísticos muestrales.
Ahora bien, es razonable pensar que si tomamos diferentes muestras de la misma población y calculamos los diferentes estadísticos de cada una, esos valores van a diferir de muestra a muestra. Por lo tanto, un estadístico no es un valor fijo, sino que presenta las siguientes características:
- Puede tener varios resultados posibles.
- No se puede predecir de antemano su valor.
Estas son las condiciones que definen a una variable aleatoria. Un estadístico, entonces, es una variable aleatoria, función de las observaciones muestrales.
A los estadísticos muestrales se los designa con las letras latinas (x, s2), o letras griegas "con sombrero" (m ^, s ^2).
Si un estadístico es una variable aleatoria, entonces es posible determinar su distribución de probabilidades y calcular sus principales propiedades.
Ejemplo:
En el futuro habrá cada vez más interés en desarrollar aleaciones de Mg de bajo costo, para varios procesos de fundición. En consecuencia, es importante contar con métodos prácticos para determinar varias propiedades mecánicas de esas aleaciones. Examine la siguiente muestra de mediciones del módulo de elasticidad obtenidos de un proceso de fundición a presión:
44.2 43.9 44.7 44.2 44.0 43.8 44.6 43.1
Suponga que esas observaciones son el resultado de una muestra aleatoria. Se desea estimar la varianza poblacional
. Un estimador natural es la varianza muestral:
En el mejor de los casos, se encontrará un estimador
para el cual
siempre. Sin embargo,
entonces el estimador preciso sería uno que produzca sólo pequeñas diferencias de estimación, de modo que los valores estimados se acerquen al valor verdadero.
Propiedades de un Buen Estimador
Insesgado.- Se dice que un estimador puntual
si
, para todo valor posible de
para estimar la media poblacional
, se sabe que la
, por lo tanto la media es un estimador insesgado.
Eficiente o con varianza mínima.- Suponga que
Entre todos los estimadores de
En otras palabras, la eficiencia se refiere al tamaño de error estándar de la estadística. Si comparamos dos estaíisticas de una muestra del mismo tamaño y tratamos de decidir cual de ellas es un estimador mas eficiente, escogeríamos la estadística que tuviera el menor error estándar, o la menor desviación estándar de la distribución de muestreo.
Tiene sentido pensar que un estimador con un error estándar menor tendrá una mayor oportunidad de producir una estimación mas cercana al parámetro de población que se esta considerando.
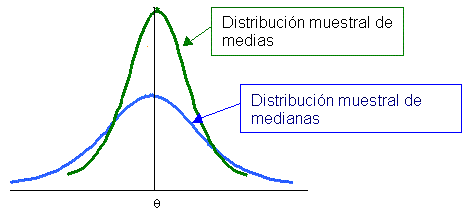
Como se puede observar las dos distribuciones tienen un mismo valor en el parámetro sólo que la distribución muestral de medias tiene una menor varianza, por lo que la media se convierte en un estimador eficiente e insesgado.
Coherencia.- Una estadística es un estimador coherente de un parámetro de población, si al aumentar el tamaño de la muestra se tiene casi la certeza de que el valor de la estadística se aproxima bastante al valor del parámetro de la población. Si un estimador es coherente se vuelve mas confiable si tenemos tamaños de muestras mas grandes.
Suficiencia.- Un estimador es suficiente si utiliza una cantidad de la información contenida de la muestra que ningún otro estimador podría extraer información adicional de la muestra sobre el parámetro de la población que se esta estimando.
Es decir se pretende que al extraer la muestra el estadístico calculado contenga toda la información de esa muestra. Por ejemplo, cuando se calcula la media de la muestra, se necesitan todos los datos. Cuando se calcula la mediana de una muestra sólo se utiliza a un dato o a dos. Esto es solo el dato o los datos del centro son los que van a representar la muestra. Con esto se deduce que si utilizamos a todos los datos de la muestra como es en el caso de la media, la varianza, desviación estándar, etc; se tendrá un estimador suficiente.
Un estimado puntual, por ser un sólo número, no proporciona por sí mismo información alguna sobre la precisión y confiabilidad de la estimación. Por ejemplo, imagine que se usa el estadístico
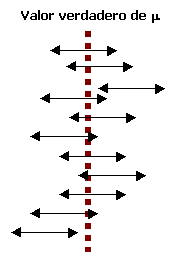
Una interpretación correcta de la "confianza de 95%" radica en la interpretación frecuente de probabilidad a largo plazo: decir que un evento A tiene una probabilidad de 0.95, es decir que si el experimento donde A está definido re realiza una y otra vez, a largo plazo A ocurrirá 95% de las veces. Para este caso
el 95% de los intervalos de confianza calculados contendrán a
Esta es una construcción repetida de intervalos de confianza de 95% y se puede observar que de los 11 intervalos calculados sólo el tercero y el último no contienen el valor de
De acuerdo con esta interpretación, el nivel de confianza de 95% no es tanto un enunciado sobre cualquier intervalo en particular, más bien se refiere a lo que sucedería si se tuvieran que construir un gran número de intervalos semejantes.
Encontrar z a partir de un nivel de confianza
Existen varias tablas en las cuales podemos encontrar el valor de z, según sea el área proporcionada por la misma. En esta sección se realizará un ejemplo para encontrar el valor de z utilizando tres tablas diferentes.
Ejemplo:
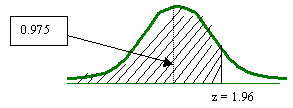
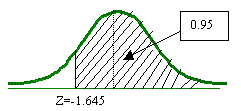
Encuentre el valor de z para un nivel de confianza del 95%.
Solución 1:
Se utilizará la tabla que tiene el área bajo la curva de -
hasta z. Si lo vemos gráficamente sería:
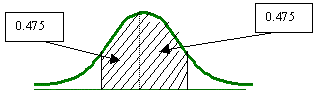
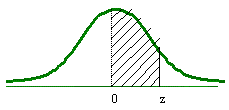
El nivel de confianza bilateral está dividido en partes iguales bajo la curva:
En base a la tabla que se esta utilizando, se tendrá que buscar el área de 0.975, ya que cada extremo o cola de la curva tiene un valor de 0.025.
Por lo que el valor de z es de 1.96.
Solución 2:
Si se utiliza una tabla en donde el área bajo la curva es de 0 a z:
En este caso sólo se tendrá que buscar adentro de la tabla el área de 0.475 y el resultado del valor de z será el mismo, para este ejemplo 1.96.
Solución 3:
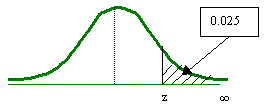
Para la tabla en donde el área bajo la curva va desde z hasta
Se busca el valor de 0.025 para encontrar z de 1.96.
Independientemente del valor del Nivel de Confianza este será el procedimiento a seguir para localizar a z. En el caso de que no se encuentre el valor exacto se tendrá que interpolar.
Es conocido de nosotros durante este curso, que en base a la distribución muestral de medias que se generó en el tema anterior, la formula para el calculo de probabilidad es la siguiente:
. Como en este caso no conocemos el parámetro y lo queremos estimar por medio de la media de la muestra, sólo se despejará
De esta formula se puede observar que tanto el tamaño de la muestra como el valor de z se conocerán. Z se puede obtener de la tabla de la distribución normal a partir del nivel de confianza establecido. Pero en ocasiones se desconoce
por lo que en esos casos lo correcto es utilizar otra distribución llamada "t" de student si la población de donde provienen los datos es normal.
Para el caso de tamaños de muestra grande se puede utilizar una estimación puntual de la desviación estándar, es decir igualar la desviación estándar de la muestra a la de la población (s=
Ejemplos:
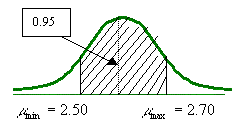
- Se encuentra que la concentración promedio de zinc que se saca del agua a partir de una muestra de mediciones de zinc en 36 sitios diferentes es de 2.6 gramos por mililitro. Encuentre los intervalos de confianza de 95% y 99% para la concentración media de zinc en el río. Suponga que la desviación estándar de la población es 0.3.
Solución:
La estimación puntual de
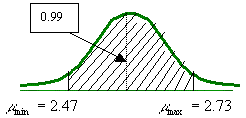
Para un nivel de confianza de 99% el valor de z es de 2.575 por lo que el intervalo será más amplio:
El intervalo de confianza proporciona una estimación de la presición de nuestra estimación puntual. Si
.
Como se puede observar en los resultados del ejercicio se tiene un error de estimación mayor cuando el nivel de confianza es del 99% y más pequeño cuando se reduce a un nivel de confianza del 95%.
- Una empresa eléctrica fabrica focos que tienen una duración aproximadamente distribuida de forma normal con una desviación estándar de 40 horas. Si una muestra de 30 focos tiene una duración promedio de 780 horas, encuentre un intervalos de confianza de 96% para la media de la población de todos los focos que produce esta empresa.
Solución:
Con un nivel de confianza del 96% se sabe que la duración media de los focos que produce la empresa está entre 765 y 765 horas.
- La prueba de corte sesgado es el procedimiento más aceptado para evaluar la calidad de una unión entre un material de reparación y su sustrato de concreto. El artículo "Testing the Bond Between Repair Materials and Concrete Substrate" informa que, en cierta investigación, se obtuvo una resistencia promedio muestral de 17.17 N/mm2, con una muestra de 48 observaciones de resistencia al corte, y la desviación estándar muestral fue 3.28 N/mm2. Utilice un nivel de confianza inferior del 95% para estimar la media real de la resistencia al corte.
Solución:
En este ejercicio se nos presentan dos situaciones diferentes a los ejercicios anteriores. La primera que desconoce la desviación estándar de la población y la segunda que nos piden un intervalo de confianza unilateral.
El primer caso ya se había comentado y se solucionará utilizando la desviación estándar de la muestra como estimación puntual de sigma.
Para el intervalo de confianza unilateral, se cargará el área bajo la curva hacia un solo lado como sigue:
Esto quiere decir que con un nivel de confianza de 95%, el valor de la media está en el intervalo (16.39,
Estimando la media poblacional: Muestras Pequeñas
Suposiciones:
n ≤ 30
La muestra es una muestra simple aleatoria.
La muestra es de una población normalmente distribuida.
En el desarrollo de intervalos de confianza para estimaciones de µ, hay dos casos: (1) cuando la desviación estándar de la población σ es conocida; y (2) cuando σ es desconocida.
Caso 1 (σ es conocida): Este primer caso es grandemente irreal, porque si no se conoce el valor de la media poblacional µ y se está tratando de estimar ese valor, se puede apostar seguramente que no se sabrá el valor de la desviación estándar de la población σ.
Caso 2 (σ es desconocida): El segundo caso, donde σ es desconocida es más realista y práctico. Ahora, en vez de usar la distribución normal, se usará la distribución t (“Student t distribution”) desarrollada por Gosset (1876-1937).
Distribución t
Si la distribución de una población es esencialmente normal (aproximadamente en forma de campana), entonces la distribución de
es esencialmente una distribución t para todas las muestras de tamaño n. La distribución t es usada para encontrar valores críticos denotados por:
6
|
DEFINICIÓN DE GRADOS DE LIBERTAD |
|
El número de grados de libertad para un conjunto de data simple es el número de valores muestrales que pueden variar después de que ciertas restricciones hayan sido impuestas a todos los valores de la data. grados de libertad = n – 1 |
Margen de error E para una estimación de µ:
[Basados en una σ desconocida y una muestra aleatoria pequeña simple (n ≤ 30) de una población normalmente distribuida]
donde tα/2 tiene n – 1 grados de libertad.
Intervalo de confianza para la estimación de µ:
[Basados en una σ desconocida y una muestra aleatoria pequeña simple (n ≤ 30) de una población normalmente distribuida]
donde
Propiedades importantes de la Distribución t:
1. La distribución t (su gráfica) es diferente para tamaños de muestras diferentes.
2. La distribución t tiene la misma simetría general de campana como la distribución normal estándar, pero esta refleja la variabilidad mayor que es esperado con muestras pequeñas.
3. La distribución t tiene una media de t = 0 (como la distribución normal estándar que tiene una media de z = 0).
4. La desviación estándar de la distribución t varía con el tamaño de la muestra, pero es mayor que 1, poco semejante a la distribución normal estándar que tiene σ = 1.
5. Según el tamaño de la muestra n aumenta, la distribución t se acerca a la distribución normal estándar. Para valores de (n > 30), las diferencias son muy pequeñas, que se puede usar los valores críticos z en vez de desarrollar una tabla mucho más grande de valores críticos t.
7 Condiciones para usar la Distribución t:
1. La muestra es pequeña (n ≤ 30); y
2. la desviación estándar σ es desconocida; y
3. la población principal tiene una distribución que es esencialmente normal.