Enlace Local # 8
UNIDAD 2 TEORÍA DE PEQUEÑAS MUESTRAS
En este capítulo se presentan tres nuevos modelos estadísticos: el llamado t de Student, el modelo de la Chi-cuadrado ( χ2 ) y el modelo F de Fisher. Los tres no requieren ya más del supuesto de un tamaño muestral grande. Ahora con dos o más mediciones se puede trabajar; por eso se usa la expresión Teoría de pequeñas muestras para este tema. El empleo de cualquiera de ellos es enteramente similar al visto en el capítulo anterior. Cambia la manera de calcular el estadígrafo de comparación y su respectiva tabla de valores críticos de la distribución muestral. En este enlace mostraremos el modelo de Student.
Mientras que el modelo de la t se aplica a medias y proporciones, los dos últimos se usan para el estudio de las desviaciones o dispersiones. También se la llama Teoría Exacta del Muestreo, pues ahora no hay que efectuar la aproximación DS2 . σ² ya que el valor muestral viene en la fórmula de cálculo del estadígrafo de comparación, en lugar del poblacional. Eso hace que no sea necesario efectuar una estimación y se tiene una mayor exactitud que con la gaussiana. Es importante destacar que los tres modelos son válidos tanto para pequeñas como para grandes muestras. Esto amplía el campo de aplicación del modelo de Gauss. Además, al no tener que hacer tantas pruebas disminuye el costo y se gana en tiempo. Todas estas ventajas tienen una contrapartida: se pierde un poco de precisión pues, como se verá, el intervalo de confianza se hace más grande para un mismo caso. Estos modelos se prefieren al de Gauss porque sus ventajas valen la pena, al precio de perder un poco de precisión. Se mostrará su empleo tanto para el caso de una sola muestra de mediciones como para la comparación de dos muestras o grupos de mediciones.

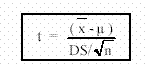
Sea un estadígrafo t calculado para la media con la relación
Figura 2.1: La distribución de Student
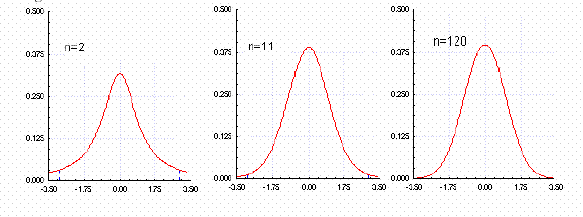
Si de una población normal, o aproximadamente normal, se extraen muestras aleatorias e independientes y a cada una se le calcula dicho estadígrafo usando los valores muestrales de la media
y el desvío estándar, entonces se obtiene una distribución muestral t que viene dada por la fórmula de Student. En realidad, fue obtenida por R. A. Fisher y la bautizó Student en honor a W. S. Gosset, quien usaba ese seudónimo para poder publicar sus trabajos en la revista Biometrika. Esta función matemática tiene un parámetro que la define en forma unívoca: el número de grados de libertad υ= n-1 (donde n es el tamaño muestral). El concepto matemático de υ está relacionado con la cantidad de observaciones independientes que se hagan y se calcula con el tamaño muestral n, menos la cantidad k de parámetros poblacionales que deban ser estimados a través de ellas. O sea: υ = n.k. Si se observa la ecuación superior, se ve que el único parámetro poblacional
que figura es μ, por lo tanto k = 1 y así resulta υ = n.1. Cuando el tamaño muestral es mayor que 30 la distribución de Student se aproxima mucho a la de Gauss, en el límite ambas son iguales.
Es decir que la función Student tiende asintóticamente a la función de Gauss.
Para cada grado de libertad hay una tabla de valores que pueden obtenerse variando el nivel de significación, parecida a la de Gauss. Sería muy engorroso tener una hoja con la tabla para cada grado de libertad. Esto se soluciona de dos formas: una es usando computadoras para resolver los cálculos (programas estadísticos como Mini-Tab, SPSS, Statistica, Excel, etc.). La otra y más común, es preparar una tabla donde en cada fila se coloquen encolumnados los valores críticos más usuales para cada valor de grados de libertad. Como interesan únicamente los valores pequeños, se listan correlativamente de 1 a 30 y luego algunos como 40, 60, 120 e ∞. Este último tendrá los valores vistos para la normal. Así, en una sola hoja se presentan los valores útiles para el empleo de este modelo, como se muestran en el Tabla 5 del Anexo con las tablas estadísticas.
La distribución de Student, al igual que la de Gauss, es simétrica respecto al origen de coordenadas y se extiende desde – ∞ hasta + ∞. Pero a diferencia de la normal, puede adoptar diferentes formas dependiendo del número de grados de libertad. Por ejemplo, la que tiene un solo grado de libertad (n = 2 y υ = 1), se desvía marcadamente de la normal, como se puede ver en la Figura 13.1 anterior. Luego, a medida que los grados van aumentando, se acerca cada vez más, hasta igualarla en el infinito. Se puede ver esto en las tablas y en la Figura 2. Los valores críticos de la Tabla Student, para una confianza del 95 % y dos colas, para 1, 5, 10, 30 y ∞ grados de libertad son 12,71; 2,57; 2,23; 2,04 y 1,96 respectivamente. Estos valores críticos se denotan con sus dos parámetros así: tα ; υ = t0,05 ; ∞ = 1,96 = zα.
Los intervalos de confianza para esta distribución se arman en forma análoga a la vista para el caso de Gauss. Con la única diferencia en cómo se calcula el valor crítico tα;υ en lugar de zα.

De nuevo, el par de valores ( μ e ; σe ) se saca de la Tabla 4, con la salvedad que ahora no se usa más la aproximación DS . σ; pues en el cálculo de t se emplea DS directamente. Esto hace que el modelo sea más exacto que el de Gauss. Generalmente, este modelo se aplica al caso de la media, proporciones y sus diferencias o sumas. Para una estimación con 30 o más grados de libertad, se pueden usar tanto el modelo de Gauss, como el de Student. El intervalo es casi igual, salvo que en este último el valor crítico es mayor. En efecto, si se tienen 31 muestras, t = 2,09, mientras que z = 1,96. Esto hace mayores a los intervalos obtenidos con Student que sus equivalentes
gaussianos. Por eso, se dice que el modelo Student tiene menor precisión que el de Gauss.
La teoría de decisiones se usa en forma análoga, empleando los intervalos de confianza visto más arriba. Pero para poder aplicar este modelo se deben tener en cuenta los requisitos siguientes:
1) Las muestras fueron extraídas de una población normal o aproximadamente normal.
2) La selección de las muestras se hizo en forma aleatoria.
3) Las muestras son independientes entre sí.
Si alguno de ellos no se cumple, las conclusiones que se obtengan no son válidas. Los supuestos se pueden resumir así: para poder usar Student, se deben tener muestras normales, aleatorias e independientes. Notar que el error estándar de estimación es SE (e)= σe.
Los casos más frecuentes en la práctica son:
w Student para medias muestrales
En este caso e =.x luego: μe = μ y SE (e) = σe = DS / n . Por lo tanto el valor de comparación se calcula con:
Ejemplo 1) Se desea saber si un instrumento de medición cualquiera está calibrado, desde el punto de vista de la exactitud. Para ello se consigue un valor patrón y se lo mide 10 veces (por ejemplo: una pesa patrón para una balanza, un suero control para un método clínico, etc.). Suponiendo que el resultado de estas mediciones arroja una media de 52,9 y un desvío de 3, usando un patrón de valor 50, se debe determinar si el instrumento está calibrado y la estimación de su error sistemático, si es que se prueba su existencia (no se usan unidades para generalizar este ejemplo).
= 50 el ìHo : instrumento está calibrado en exactitud
50 no está ≠ ìH1 : calibrado. Hay un error sistemático
Se trata de un ensayo de dos colas ídonde hay = 10 – 1 = 9 grados de libertad. De la Tabla 4 se obtienen los 9 ;2,262, para el 99% de t 0,01 =9 ;valores críticos para el 95% de t 0,05 4,781. Lo que permite =9 ;3,25 y para un nivel del 99,9% es t 0,001 = establecer las zonas de aceptación y rechazo:
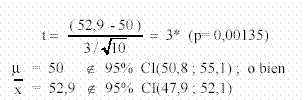
Dibujando las zonas con los valores críticos, el valor de t cae en la de rechazo para el 95% y no alcanza para las otras. La conclusión es que se ha probado la existencia de un error sistemático con una confianza del 95%. Y se estima con:
![]()
Ejemplo 2) Se midió colesterol total a 11 pacientes varones adultos escogidos al azar los resultados obtenidos arrojan una media de 235 mg/dl y un desvío estándar de 35 mg/dl. Ensayar la hipótesis de que se mantienen por debajo del valor límite de referencia ( 220mg/dl ).
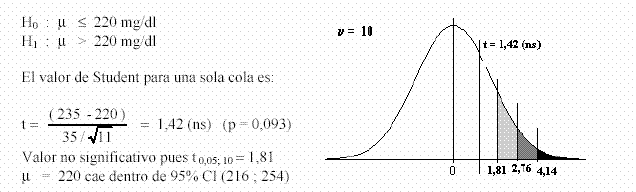
Para el caso de una cola, el valor de tablas para el 95% debe ser el que está en la Tabla 4 para el 90% en dos colas. La idea es que el 10% en dos colas significa el 5% en cada = 10, el límite para íuna, por la simetría de la curva de Student. Luego, para el 95% será t = 1,812 en una cola y t = 2,228 para dos colas. En la figura de más arriba se han marcado los límites del 99% y del 99,9% para una sola cola, a los efectos didácticos. La conclusión es que no puede rechazar la hipótesis nula, por lo que debe considerarse un colesterol total admisible desde el punto de vista clínico, por estar por debajo del límite de referencia.
w Student para proporciones
En este caso e = P y μp = μ = π luego
con ![]()
se puede obtener el valor del estadígrafo de comparación con la relación:
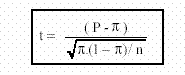
Ejemplo1) Un analgésico de plaza, afirma en su propaganda que alivia el dolor en el 90% de los casos antes de la primer hora luego de su ingesta. Para validar esa información, se hace un experimento en 20 individuos con cefalea. Se observa que fue efectivo en 15 de ellos.
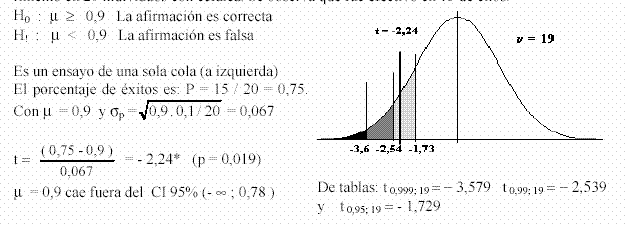
El resultado obtenido es significativo (t = - 2,24 *). Pero la evidencia no alcanza para rechazar la hipótesis a los niveles del 99% y 99,9%. Se la rechaza al nivel de 95% únicamente. Si bien no es tan terminante, se puede afirmar que la aseveración es falsa con un 95% de confianza.
w Student para dos muestras independientes
El modelo de Student también se puede usar cuando se desean comparar dos muestras entre sí, para detectar si hay diferencia significativa entre ellas, debido a algún factor analizado. En primer lugar se analizará el caso de dos muestras independientes como: aplicar dos tipos de remedios a dos grupos de pacientes escogidos al azar, o las mediciones repetidas de una misma magnitud, etc. El otro caso, cuando las muestras no son independientes sino apareadas, se verá en el próximo tema. Una vez más, los supuestos para poder aplicar este modelo se resumen en: para poder comparar con Student, las dos muestras deben ser normales, aleatorias e independientes.
Se sacan muestras aleatorias e independientes, de dos poblaciones normales. La idea es averiguar si ambas muestras provienen de la misma población o de poblaciones diferentes. Con eso se puede ver si el efecto de los “tratamientos” aplicados a las muestras es apreciable, en cuyo caso las muestras parecerán provenir de diferentes poblaciones. Se usa en los casos donde se compara el efecto de una droga aplicada a un grupo de pacientes, contra otro grupo al cual se le suministra un placebo. También para comparar dos técnicas clínicas y detectar si hay diferencias, por ejemplo: dos marcas comerciales de plaza, dos instrumentos de medición, dos individuos, dos técnicas diferentes (la nueva contra la vieja), dos protocolos, etc. Con estas comparaciones se pueden realizar muchos controles internos en el laboratorio para hacer calibraciones, medir eficacia, etc. Hay una limitación: solo se pueden comparar dos muestras entre sí a la vez y no más. Para el caso de tener más de dos muestras, se recurre a los modelos de ANOVA.
w Comparación de medias
Para estos casos, el valor de Student para validaciones de medias se calcula con:
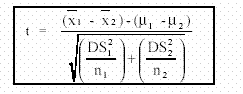
El cual se contrasta con tα; υ donde υ = n1 + n2 - 2 grados de libertad. Hay casos particulares como (a) las muestras son de igual tamaño y (b) son homocedásticas (tienen igual varianza). En ambos casos se simplifican las fórmulas de cálculo.
Ejemplo 1) Se aplica un medicamento a 15 pacientes que padecen cierta enfermedad, escogidos al azar, y un placebo a 20 pacientes. En el primer grupo, la desaparición del estado febril se observa a las 19 horas de tratamiento en promedio (con un desvío de 2 hs.). En el grupo control, la mejoría se observa en promedio las 25 horas con un desvío de 3 horas. Decidir si el medicamento modifica el tiempo de curación.
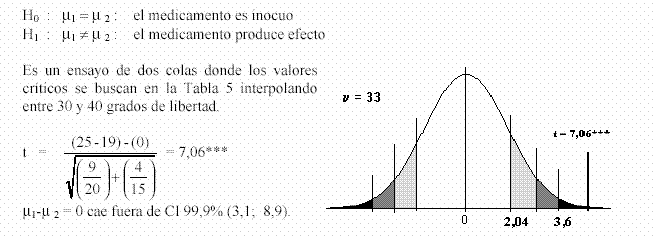
Como el valor hallado de t es mucho más grande que el valor crítico de tablas para 33 grados de libertad: tα ; υ = t 0,999; 33 = 3,44 (ensayo de dos colas y un 99,9% de confianza), la conclusión es: se obtuvieron resultados altamente significativos ( t = 7,06 *** ) como para rechazar la hipótesis nula. Se tiene una prueba científica del efecto del medicamento.
Ejemplo 2) Se desea verificar si hay diferencia en las mediciones a través de dos métodos clínicos diferentes. Se toma una muestra de suero lo suficientemente grande como para obtener 10 alícuotas. Se distribuyen al azar 5 alícuotas para cada método. Efectuadas las mediciones, con el primero se tuvo una media de 85 mg/dl con un desvío de 8 mg/dl. Mientras que con el segundo se tuvo una media de 83 mg/dl con un desvío de 6 mg/dl.
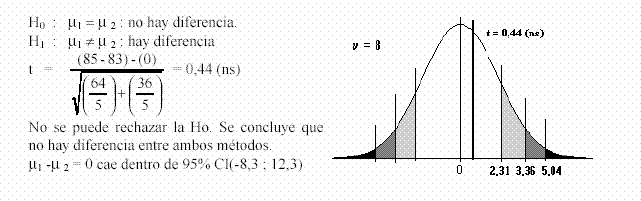
w Comparación de proporciones
Para estos casos, el valor de Student para validaciones de proporciones se calcula la misma fórmula, pero reemplazando los valores esperados con

Contrastando con el valor de tablas dado por tα;υ; con υ= n1 + n2 -2 grados de libertad.
Ejemplo) Se escogen al azar dos grupos formados por 20 individuos cada uno, entre los que padecen cierta alergia. Se administra una droga curativa al primer grupo y se observa una mejoría en 15 de los casos. Al segundo grupo se le administra un placebo y mejoran 13 de ellos. Ensayar la hipótesis que la droga sirve para curar ese tipo de alergia. Se emplean las hipótesis siguientes:
H0 : μ1-2 = 0 las diferencias observadas se deben al azar. H1 : μ1-2 ≠ 0 la droga produce efecto. Si se supone que ambas muestras fueron extraídas de la misma población, y por lo tanto no hay diferencias entre las muestras observadas (H0) μ1-2 = 0, eso significa que el porcentaje de curados en dicha población será π = π1 = π2 y habrá que estimarlo con los datos muestrales, calculando la proporción ponderada con: p = ( total de curados en las muestras / total muestral ) = (15+13) / 40 = 0,7. Entonces, sacando factor común en la fórmula de la varianza, esta resulta: SE2(π) = π (1.π).[ ) / 1 ( ) / 1 ( 2 1 n n + ] = π (1.π) [2 / n] =(0,7 . 0,3) (2/20) = 0,021
Y es SE(π) = 0,145; de los datos del problema surgen P1 =15/20 = 0,75 y P2 = 13/20 = 0, 65 t = ( 0,75 – 0,65 ) / (0,021)1/2= 0,69 < t0,95 ; 38=2,02. μ1-2 = 0 cae dentro de 95% CI(-0,19 ; +0,39) Un resultado no significativo. Las diferencias observadas no se deben a la droga sino al azar.
w Test de equivalencia biológica
Hay ocasiones donde la Ho no busca establecer si hay o no diferencia entre dos muestras, como las del ejemplo anterior, sino que se trata de establecer si un método clínico o tratamiento nuevo es lo suficientemente bueno como para reemplaza al que se venía usando hasta entonces, el método viejo. Las ventajas de este nuevo método pueden ser: un costo menor, más rápido, menos dañino o peligroso para el paciente, etc. La cuestión básica aquí es ver si, en promedio, la diferencia entre ambos es menor que un cierto valor límite para la magnitud estudiada. Es decir que tal diferencia no implique una inferioridad del nuevo método, desde un punto de vista clínico. Para estos casos la Ho : La diferencia entre ambos promedios es mayor o igual al valor aceptable y la alternativa es H1 : Esta diferencia de medias es menor al valor crítico; en cuyo caso ambos métodos pueden ser considerados clínicamente equivalentes. La idea es que, si se rechaza la Ho se puede usar el método nuevo en lugar del viejo y aprovechar las ventajas que este posee. Pero la decisión se basa más en consideraciones médicas que estadísticas. Entonces, si se trata de magnitudes continuas, se puede usar el test de Student para comparar la diferencia de las dos medias contra el valor crítico δ o máximo aceptable desde el punto de vista clínico. El planteo se hace así: Ho : μV – μN = . > δ. Donde μV es el valor poblacional que se obtiene con el método viejo y μN con el método nuevo, . es la diferencia real entre ambos métodos y δ es la diferencia máxima admisible entre ambos métodos. De esta manera, cuando Ho pueda rechazarse se tendrá evidencia suficiente como para efectuar el reemplazo, esto es cuando H1 : μV – μN = . < δ.
Se trata de un ensayo de una sola cola. Pero cuando se trate de ver si en valor absoluto la diferencia entre ambos métodos no supere a un cierto valor δ, porque aquí no interesa tanto que sea menor, sino que también interesa que no sea mayor (dependiendo de la magnitud clínica analizada); entonces la Ho será : μV – μN = . = δ y el ensayo será de dos colas. Análogo al visto en el punto anterior. Para ilustrar este procedimiento se usará un ejemplo tomado de la obra de Armitage
Ejemplo) Sea el índice cardíaco CI (respuesta cardiaca normalizada para la superficie del cuerpo) el cual se mide con un procedimiento invasivo como es el colocar un catéter en el corazón del paciente llamado Termo-dilución (el método viejo) y la unidad de medición son litros por minuto tomado por m2 de superficie del cuerpo humano. Se ha propuesto una nueva manera de medir esa magnitud con una técnica no invasiva, llamada el método de la Bioimpedancia, en la cual se le adosa un instrumento al cuerpo de paciente en forma externa, y mide en forma eléctrica el valor del CI usando una escala adecuada (el método nuevo). El criterio clínico de aceptación es: el nuevo método se considerará equivalente al viejo cuando, en promedio, el valor obtenido difiera en un 20% respecto al promedio aceptado de 2,75 l / min. / m2 para el método del catéter. Esto significa que el 20% de tal valor es δ = 0,55. Luego el planteo se hace así:
Ho : .μV – μN . = ... > δ = 0,55 o lo que es lo mismo (μV – μN ) = δ = 0,55
H1 : .μV – μN . = ... < δ = 0,55 cuyo equivalente es (μV – μN ) = δ ≠ 0,55
Se toma una muestra de N = 96 individuos a los cuales se le aplica el método nuevo, los valores encontrados fueron un promedio de 2,68 l / min. / m2, y un desvío estándar de 0,26 l / min. / m2 luego será:
La conclusión final es que se puede usar el método nuevo en lugar del viejo, con una gran ventaja para el paciente, pues ahora ya no tendrá que ser cateterizado para efectuarle su medición del índice cardíaco. A este procedimiento estadístico aparecido en los últimos años en Medicina se lo conoce también con el nombre de test de equivalencias médicas o biológicas.
w Student para dos muestras apareadas
El modelo de Student se puede usar para el caso especial de muestras apareadas, esto es, cuando se le efectúan dos tratamientos a la misma muestra; por ejemplo, del tipo antes–después donde al mismo individuo se lo mide dos veces para ver el efecto del tratamiento realizado, o el caso de método nuevo contra el método viejo, donde al mismo grupo de pacientes se le hacen dos mediciones a cada uno, la del método de rutina habitual y una extra con el nuevo método a probar para decidirse entre ambos. La idea básica es como sigue: se sacan n muestras aleatorias e independientes de una población normal. A cada muestra se le aplican dos “tratamientos” A y B diferentes y lo que interesa detectar es si producen algún efecto apreciable. Este caso es muy diferente al anterior si bien las muestras son independientes entre sí, los tratamientos no lo son, porque a un mismo individuo se le aplican ambos tratamientos. Entonces, la misma persona aparecerá dos veces en los resultados: uno en el grupo A y el otro en el grupo B. El truco para resolver este problema de la independencia es trabajar con la diferencia de los resultados de cada par de mediciones efectuadas: d = xA - xB. Luego se tendrán n diferencias d1; d2; d3...dn, que son independientes entre sí, puesto que cada valor di corresponde a un solo individuo. Luego, se le aplica el modelo Student para una sola muestra, ensayando la hipótesis de que no hay 0 =d ìdiferencias entre ambos grupos. O sea, efectuando la hipótesis: H0 : resultará:
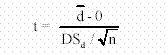
La hipótesis alternativa implica un efecto diferente para cada grupo H1 : μd ≠ 0. Si se prueba que el valor esperado del promedio de las diferencias es diferente de cero, entonces el tratamiento aplicado produce un efecto demostrable. Para aclarar estas ideas se presenta el siguiente caso:
Ejemplo) Se escogen 5 pacientes al azar, del grupo que concurre diariamente al Laboratorio de Análisis Clínicos a efectuarse una determinación de Uremia. Las muestras extraídas se miden con el procedimiento habitual y además con una nueva técnica clínica que se desea probar. Ver si hay diferencia entre ambas técnicas. Los resultados expresados en g/l fueron:
