Enlace Local # 6
El objetivo principal de la estadística inferencial es la estimación, esto es que mediante el estudio de una muestra de una población se quiere generalizar las conclusiones al total de la misma. Como vimos en la sección anterior, los estadísticos varían mucho dentro de sus distribuciones muestrales, y mientras menor sea el error estándar de un estadístico, más cercanos serán unos de otros sus valores.
Existen dos tipos de estimaciones para parámetros; puntuales y por intervalo. Una estimación puntual es un único valor estadístico y se usa para estimar un parámetro. El estadístico usado se denomina estimador.
Una estimación por intervalo es un rango, generalmente de ancho finito, que se espera que contenga el parámetro.
La inferencia estadística está casi siempre concentrada en obtener algún
tipo de conclusión acerca de uno o más parámetros (características
poblacionales). Para hacerlo, se requiere que un investigador obtenga datos
muestrales de cada una de las poblaciones en estudio. Entonces, las conclusiones
pueden estar basadas en los valores calculados de varias cantidades muestrales .
Po ejemplo, representamos con ![]() (parámetro) el verdadero promedio de resistencia a la ruptura de conexiones de
alambres utilizados para unir obleas de semiconductores. Podría tomarse una
muestra aleatoria de 10 conexiones para determinar la resistencia a la ruptura
de cada una, y la media muestral de la resistencia a la ruptura
(parámetro) el verdadero promedio de resistencia a la ruptura de conexiones de
alambres utilizados para unir obleas de semiconductores. Podría tomarse una
muestra aleatoria de 10 conexiones para determinar la resistencia a la ruptura
de cada una, y la media muestral de la resistencia a la ruptura
![]() se podía emplear para sacar una
conclusión acerca del valor de
se podía emplear para sacar una
conclusión acerca del valor de ![]() .
De forma similar, si
.
De forma similar, si ![]() es la
varianza de la distribución de resistencia a la ruptura, el valor de la varianza
muestral s2 se podría utilizar pra inferir algo acerca de
es la
varianza de la distribución de resistencia a la ruptura, el valor de la varianza
muestral s2 se podría utilizar pra inferir algo acerca de
![]() .
.
Cuando se analizan conceptos generales y métodos de inferencia es conveniente
tener un símbolo genérico para el parámetro de interés. Se utilizará la letra
griega ![]() para este propósito.
El objetivo de la estimación puntual es seleccionar sólo un número, basados en
datos de la muestra, que represente el valor más razonable de
para este propósito.
El objetivo de la estimación puntual es seleccionar sólo un número, basados en
datos de la muestra, que represente el valor más razonable de
![]() .
.
Una muestra aleatoria de 3 baterías para calculadora podría presentar
duraciones observadas en horas de x1=5.0, x2=6.4 y x3=5.9.
El valor calculado de la duración media muestral es
![]() = 5.77, y es razonable considerar
5.77 como el valor más adecuado de
= 5.77, y es razonable considerar
5.77 como el valor más adecuado de
![]() .
.
Una estimación puntual de un parámetro
![]() es un sólo número que se puede
considerar como el valor más razonable de
es un sólo número que se puede
considerar como el valor más razonable de
![]() . La estimación puntual se
obtiene al seleccionar una estadística apropiada y calcular su valor a partir de
datos de la muestra dada. La estadística seleccionada se llama estimador
puntual de
. La estimación puntual se
obtiene al seleccionar una estadística apropiada y calcular su valor a partir de
datos de la muestra dada. La estadística seleccionada se llama estimador
puntual de ![]() .
.
El símbolo![]() (theta sombrero)
suele utilizarse para representar el estimador de
(theta sombrero)
suele utilizarse para representar el estimador de
Ejemplo:
En el futuro habrá cada vez más interés en desarrollar aleaciones de Mg de bajo costo, para varios procesos de fundición. En consecuencia, es importante contar con métodos prácticos para determinar varias propiedades mecánicas de esas aleaciones. Examine la siguiente muestra de mediciones del módulo de elasticidad obtenidos de un proceso de fundición a presión:
44.2 43.9 44.7 44.2 44.0 43.8 44.6 43.1
Suponga que esas observaciones son el resultado de una muestra aleatoria. Se desea estimar la varianza poblacional
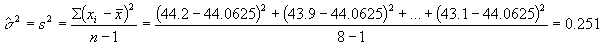
En el mejor de los casos, se encontrará un estimador
![]() para el cual
para el cual![]() siempre.
Sin embargo,
siempre.
Sin embargo, ![]() es una función de
las Xi muestrales, por lo que en sí misma una variable aleatoria.
es una función de
las Xi muestrales, por lo que en sí misma una variable aleatoria.
![]() + error de
estimación
+ error de
estimación
entonces el estimador preciso sería uno que produzca sólo pequeñas diferencias de estimación, de modo que los valores estimados se acerquen al valor verdadero.
Propiedades de un Buen Estimador
Insesgado.- Se dice que un estimador puntual![]() es un estimador insesgado de
es un estimador insesgado de
Eficiente o con varianza mínima.- Suponga que
![]() 1 y
1 y
![]() 2 son dos estimadores
insesgados de
2 son dos estimadores
insesgados de
Entre todos los estimadores de
En otras palabras, la eficiencia se refiere al tamaño de error estándar de la estadística. Si comparamos dos estaíisticas de una muestra del mismo tamaño y tratamos de decidir cual de ellas es un estimador mas eficiente, escogeríamos la estadística que tuviera el menor error estándar, o la menor desviación estándar de la distribución de muestreo.
Tiene sentido pensar que un estimador con un error estándar menor tendrá una mayor oportunidad de producir una estimación mas cercana al parámetro de población que se esta considerando.
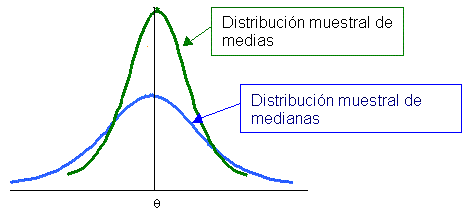
Como se puede observar las dos distribuciones tienen un mismo valor en el parámetro sólo que la distribución muestral de medias tiene una menor varianza, por lo que la media se convierte en un estimador eficiente e insesgado.
Coherencia.- Una estadística es un estimador coherente de un parámetro de población, si al aumentar el tamaño de la muestra se tiene casi la certeza de que el valor de la estadística se aproxima bastante al valor del parámetro de la población. Si un estimador es coherente se vuelve mas confiable si tenemos tamaños de muestras mas grandes.
Suficiencia.- Un estimador es suficiente si utiliza una cantidad de la información contenida de la muestra que ningún otro estimador podría extraer información adicional de la muestra sobre el parámetro de la población que se esta estimando.
Es decir se pretende que al extraer la muestra el estadístico calculado contenga toda la información de esa muestra. Por ejemplo, cuando se calcula la media de la muestra, se necesitan todos los datos. Cuando se calcula la mediana de una muestra sólo se utiliza a un dato o a dos. Esto es solo el dato o los datos del centro son los que van a representar la muestra. Con esto se deduce que si utilizamos a todos los datos de la muestra como es en el caso de la media, la varianza, desviación estándar, etc; se tendrá un estimador suficiente.
Un estimado puntual, por ser un sólo número, no proporciona por sí mismo
información alguna sobre la precisión y confiabilidad de la estimación. Por
ejemplo, imagine que se usa el estadístico
![]() para calcular un estimado puntual
de la resistencia real a la ruptura de toallas de papel de cierta marca, y
suponga que
para calcular un estimado puntual
de la resistencia real a la ruptura de toallas de papel de cierta marca, y
suponga que ![]() = 9322.7. Debido a la
variabilidad de la muestra, nunca se tendrá el caso de que
= 9322.7. Debido a la
variabilidad de la muestra, nunca se tendrá el caso de que
![]() =
=
Una interpretación correcta de la "confianza de 95%" radica en la interpretación frecuente de probabilidad a largo plazo: decir que un evento A tiene una probabilidad de 0.95, es decir que si el experimento donde A está definido re realiza una y otra vez, a largo plazo A ocurrirá 95% de las veces. Para este caso
el 95% de los intervalos de confianza calculados contendrán a
![]() .
.
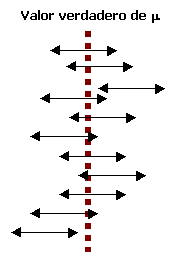
Esta es una construcción repetida de intervalos de confianza de 95% y se
puede observar que de los 11 intervalos calculados sólo el tercero y el último
no contienen el valor de ![]() .
.
De acuerdo con esta interpretación, el nivel de confianza de 95% no es tanto un enunciado sobre cualquier intervalo en particular, más bien se refiere a lo que sucedería si se tuvieran que construir un gran número de intervalos semejantes.
Encontrar z a partir de un nivel de confianza
Existen varias tablas en las cuales podemos encontrar el valor de z, según sea el área proporcionada por la misma. En esta sección se realizará un ejemplo para encontrar el valor de z utilizando tres tablas diferentes.
Ejemplo:
Encuentre el valor de z para un nivel de confianza del 95%.
Solución 1:
Se utilizará la tabla que tiene el área bajo la curva de -![]() hasta z. Si lo vemos gráficamente sería:
hasta z. Si lo vemos gráficamente sería:
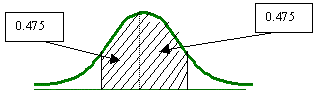
El nivel de confianza bilateral está dividido en partes iguales bajo la curva:
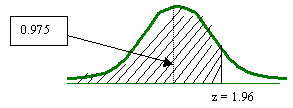
En base a la tabla que se esta utilizando, se tendrá que buscar el área de 0.975, ya que cada extremo o cola de la curva tiene un valor de 0.025.
Por lo que el valor de z es de 1.96.
Solución 2:
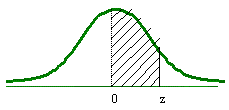
Si se utiliza una tabla en donde el área bajo la curva es de 0 a z:
En este caso sólo se tendrá que buscar adentro de la tabla el área de 0.475 y el resultado del valor de z será el mismo, para este ejemplo 1.96.
Solución 3:
Para la tabla en donde el área bajo la curva va desde z hasta
![]() :
:
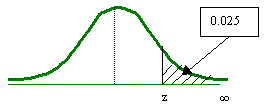
Se busca el valor de 0.025 para encontrar z de 1.96.
Independientemente del valor del Nivel de Confianza este será el procedimiento a seguir para localizar a z. En el caso de que no se encuentre el valor exacto se tendrá que interpolar.
Es conocido de nosotros durante este curso, que en base a la distribución
muestral de medias que se generó en el tema anterior, la formula para el calculo
de probabilidad es la siguiente:
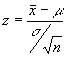 . Como en este caso no
conocemos el parámetro y lo queremos estimar por medio de la media de la
muestra, sólo se despejará
. Como en este caso no
conocemos el parámetro y lo queremos estimar por medio de la media de la
muestra, sólo se despejará ![]() de la
formula anterior, quedando lo siguiente:
de la
formula anterior, quedando lo siguiente:

De esta formula se puede observar que tanto el tamaño de la muestra como el
valor de z se conocerán. Z se puede obtener de la tabla de la distribución
normal a partir del nivel de confianza establecido. Pero en ocasiones se
desconoce ![]() por lo que en esos
casos lo correcto es utilizar otra distribución llamada "t" de student si la
población de donde provienen los datos es normal.
por lo que en esos
casos lo correcto es utilizar otra distribución llamada "t" de student si la
población de donde provienen los datos es normal.
Para el caso de tamaños de muestra grande se puede utilizar una estimación
puntual de la desviación estándar, es decir igualar la desviación estándar de la
muestra a la de la población (s=![]() ).
).
Ejemplos:
Solución:
La estimación puntual de ![]() es
es![]() = 2.6. El valor de z para
un nivel de confianza del 95% es 1.96, por lo tanto:
= 2.6. El valor de z para
un nivel de confianza del 95% es 1.96, por lo tanto:
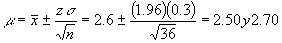
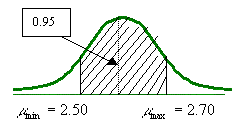
Para un nivel de confianza de 99% el valor de z es de 2.575 por lo que el intervalo será más amplio:
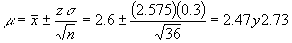
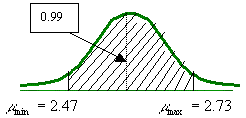
El intervalo de confianza proporciona una estimación de la presición de
nuestra estimación puntual. Si
![]() es realmente el valor
central de intervalo, entonces
es realmente el valor
central de intervalo, entonces
![]() estima
estima
![]() sin error. La mayor parte de
las veces, sin embargo,
sin error. La mayor parte de
las veces, sin embargo, ![]() no
será exactamente igual a
no
será exactamente igual a ![]() y
la estimación puntual es errónea. La magnitud de este error será el valor
absoluto de la diferencia entre
y
la estimación puntual es errónea. La magnitud de este error será el valor
absoluto de la diferencia entre
![]() y
y
![]() , y podemos tener el nivel de
confianza de que esta diferencia no excederá
, y podemos tener el nivel de
confianza de que esta diferencia no excederá
![]() .
.
Como se puede observar en los resultados del ejercicio se tiene un error de estimación mayor cuando el nivel de confianza es del 99% y más pequeño cuando se reduce a un nivel de confianza del 95%.
Solución:
![]()
Con un nivel de confianza del 96% se sabe que la duración media de los focos que produce la empresa está entre 765 y 765 horas.
Solución:
En este ejercicio se nos presentan dos situaciones diferentes a los ejercicios anteriores. La primera que desconoce la desviación estándar de la población y la segunda que nos piden un intervalo de confianza unilateral.
El primer caso ya se había comentado y se solucionará utilizando la desviación estándar de la muestra como estimación puntual de sigma.
Para el intervalo de confianza unilateral, se cargará el área bajo la curva hacia un solo lado como sigue:
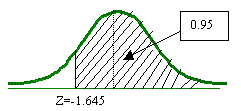
![]()
Esto quiere decir que con un nivel de confianza de 95%, el valor de la media
está en el intervalo (16.39, ![]() ).
).