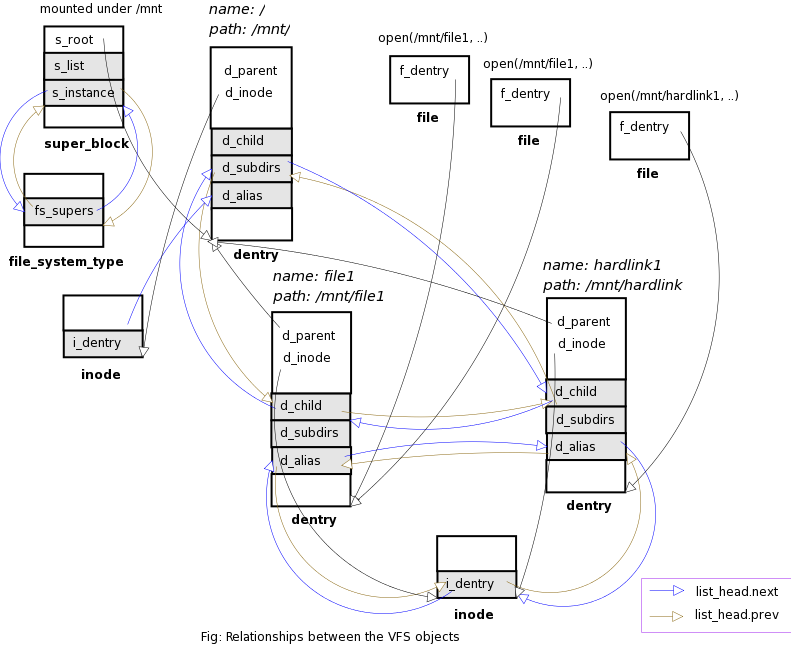
| File |
---> |
DEntry |
---> |
Inode |
| File
System
Type |
Super
Block |
Inode |
DEntry |
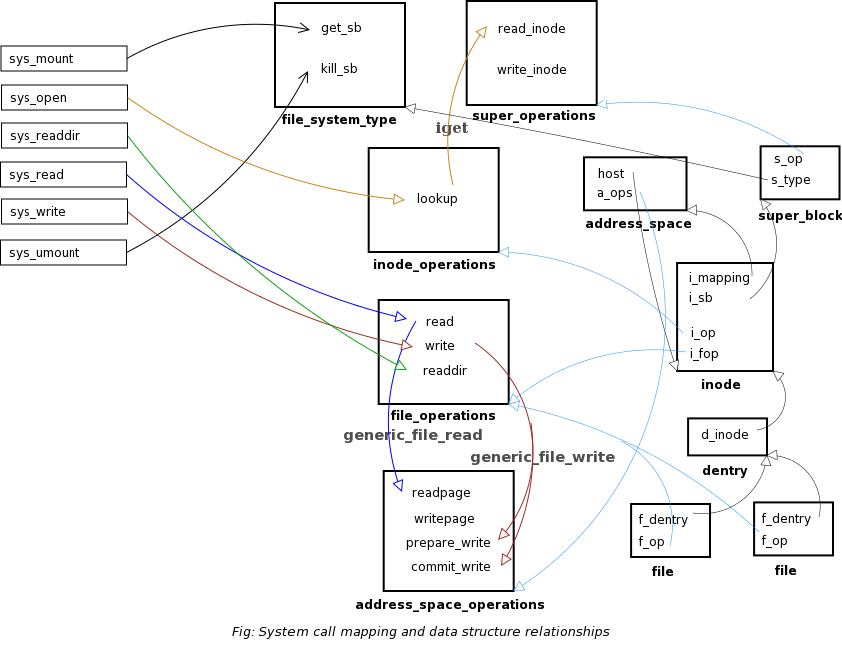
|
|
|
|
| Super
Operations |
File
Operations |
Inode
Operations |
Address
Space
Operations |
|
|
|
|
| static
struct file_system_type rkfs = { name: "rkfs", get_sb: rkfs_get_sb, kill_sb: rkfs_kill_sb, owner: THIS_MODULE }; int init_module(void) { int err; err = register_filesystem( &rkfs ); return err; } |
| static int rkfs_fill_super(struct super_block *sb, void *data, int silent) { sb->s_blocksize = 1024; sb->s_blocksize_bits = 10; sb->s_magic = RKFS_MAGIC; sb->s_op = &rkfs_sops; // super block operations sb->s_type = &rkfs; // file_system_type rkfs_root_inode = iget(sb, 1); // allocate an inode rkfs_root_inode->i_op = &rkfs_iops; // set the inode ops rkfs_root_inode->i_mode = S_IFDIR|S_IRWXU; rkfs_root_inode->i_fop = &rkfs_fops; if(!(sb->s_root = d_alloc_root(rkfs_root_inode))) { iput(rkfs_root_inode); return -ENOMEM; } return 0; } static struct super_block * rkfs_get_sb(struct file_system_type *fs_type, int flags, const char *devname, void *data) { /* rkfs_fill_super this will be called to fill the superblock */ return get_sb_single( fs_type, flags, data, &rkfs_fill_super); } |
| static struct
dentry * rkfs_inode_lookup(struct inode *parent_inode, struct dentry *dentry, struct nameidata *nameidata) { struct inode *file_inode; if(parent_inode->i_ino != rkfs_root_inode->i_ino) return ERR_PTR(-ENOENT); if(dentry->d_name.len != strlen("hello.txt") || strncmp(dentry->d_name.name, "hello.txt", dentry->d_name.len)) return ERR_PTR(-ENOENT); file_inode = iget(parent_inode->i_sb, FILE_INODE_NUMBER); if(!file_inode) return ERR_PTR(-EACCES); file_inode->i_size = file_size; file_inode->i_mode = S_IFREG|S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH; file_inode->i_fop = &rkfs_fops; // file_inode->i_fop d_add(dentry, file_inode); return NULL; } |
| int rkfs_f_readdir(
struct file
*file, void *dirent, filldir_t filldir ) { int err; struct dentry *de = file->f_dentry; printk( "rkfs: file_operations.readdir called\n" ); if(file->f_pos > 0 ) return 1; if(filldir(dirent, ".", 1, file->f_pos++, de->d_inode->i_ino, DT_DIR)|| (filldir(dirent, "..", 2, file->f_pos++, de->d_parent->d_inode->i_ino, DT_DIR))) return 0; if(filldir(dirent, "hello.txt", 9, file->f_pos++, FILE_INODE_NUMBER, DT_REG )) return 0; return 1; } |
| static int rkfs_readpage(struct file *file, struct page *page) { printk("RKFS: readpage called for page index=[%d]\n", (int)page->index); if(page->index > 0) { return -ENOSPC; } SetPageUptodate(page); memcpy(page_address(page), file_buf, PAGE_SIZE); if(PageLocked(page)) unlock_page(page); return 0; } |
| static int rkfs_commit_write(struct file *file, struct page *page, unsigned from, unsigned to) { struct inode *inode = page->mapping->host; loff_t pos = ((loff_t)page->index << PAGE_CACHE_SHIFT) + to; if(page->index == 0) { memcpy(file_buf, page_address(page), PAGE_SIZE); ClearPageDirty(page); } /* * No need to use i_size_read() here, the i_size * cannot change under us because we hold i_sem. */ if (pos > inode->i_size) { i_size_write(inode, pos); mark_inode_dirty(inode); } SetPageUptodate(page); return 0; } |
| static int rkfs_writepage(struct page *page, struct writeback_control *wbc) { printk("[RKFS] offset = %d\n", (int)page->index); memcpy(file_buf, page_address(page), PAGE_SIZE); ClearPageDirty(page); if(PageLocked(page)) unlock_page(page); return 0; } |
| ifneq
(${KERNELRELEASE},) obj-m += rkfs.o else KERNEL_SOURCE := /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) default: $(MAKE) -C ${KERNEL_SOURCE} SUBDIRS=$(PWD) modules clean : rm *.o *.ko endif |