![]()
Asignatura: Estadística 1 - Participantes: Nancy
Zambrano, Karina Maita, Raquel Rojas, Deneisy Contreras, Javier Páez
Garrido y Franklin Lezama. Profesor:
Sandy Quintero.
Las ciencias al
evolucionar pierden sus rasgos primitivos, se transforman, dividen y aun
cambian de nombre. Como sistema
científico que es, la estadística ha sufrido igual proceso y para
comprender su estado actual y su campo de actividad necesitamos conocer algo de
su historia.
Introducción a la estadística descriptiva.
Conceptos. Tipos de variables. Clasificación de variables.
Introducción
Se
considera fundador de la estadística a Godofredo Achenwall (1719 – 1772), profesor y
economista alemán quien, siendo profesor de
La
Estadística es utilizada como: tecnología al servicio de las
ciencias donde la variabilidad y la incertidumbre forman parte de su
naturaleza; se ocupa en general de fenómenos observables. La Ciencia se
desarrolla observando hechos, formulando leyes que los explican y realizando
experimentos para validar o rechazar dichas leyes, los modelos que crea la
ciencia son de tipos deterministas o aleatorios (estocástico)
Definición
La descripción
estadística se realiza sobre un conjunto o un grupo de elementos de los
cuales se desea estudiar algún fenómeno y consiste en
tabular las Variables, representarlas gráficamente y llevar a cabo
resúmenes estadísticos.
Campo de aplicación de la estadística
La
teoría general de la estadística es aplicable a cualquier campo
científico en el cual se hacen observaciones. Es obvio, que en cada una de ellas se
desarrollan procedimientos
específicos, como aplicaciones particulares o variantes de la
teoría general. Las primeras aplicaciones de la estadística
fueron los asuntos de gobierno, luego las utilizaron las
compañías de seguro y los empresarios de juegos de azar,
después siguieron los comerciantes, los industriales, los educadores,
etc. En la actualidad resulta difícil indicar profesiones que no empleen la estadística.
Estadística
descriptiva.
Analiza
metódicamente los datos, simplificándolos y presentándolos
en forma clara; eliminando la confusión característica de los
datos preliminares.
Permite
la elaboración de cuadros, gráficos e índices bien
calculados; suficientemente claros, como para disipar las dudas y la
oscuridad de los datos masivos.
Se
limita a DESCRIBIR los datos que se analizan, sin hacer INFERENCIAS en cuanto a datos no incluidos en la
muestra.
Tipos de variables
Variables es una
característica que puede tener diferentes valores en los distintos
elementos o individuos de un conjunto;
se clasifican en variables discretas y variables continuas.
a.- Variable Discreta o Discontinua.
Son aquellas que dentro de determinado
rango, su medición puede dar lugar a un sólo valor.
Ejemplos:
Números de estudiantes
graduados en Yacambú en el año 2000.
Números de hijos en una
familia.
b.- Variable Continua.
Son aquellas que pueden tomar todos
los valores posibles dentro de un intervalo dado, es de carácter
infinitesimal.
-Peso de una persona.
- La edad de una persona.
2.-Distribución
de frecuencias. Concepto. Formulas. Ejemplos.
Es un método estadístico para estudiar el comportamiento
de un conjunto de datos, y consiste en ordenarlos en intervalos de clase
indicando el número de datos comprendidos en cada clase.
Con esto se renuncia al conocimiento de los detalles de
las individualidades a cambio de conocer el comportamiento del conjunto, que es
lo que interesa en estadística.
Rango.
En todo conjunto de valores estadísticos hay valores extremos: el menor
de todos y el mayor de todos; la diferencia entre estos valores extremos se
llama rango y en él están distribuidos todos los demás
valores del conjunto; por esto también se llama recorrido.
Número
de intervalos de clase. No hay normas definidas respecto al
número de clases que deben utilizarse en una distribución de
frecuencias; sobre esto podemos decir que escoger bien el número de
clases es un arte en el que priman la experiencia y la intuición. Si los
intervalos de clase son muy pocos, se pierden detalles; y si son muchos, aparte
de lo dispendioso del trabajo, se manifiestan irregularidades que no permiten
apreciar claramente un
patrón de comportamiento. En todo caso la mayoría de
análisis recomiendan no menos de 5 ni más de 18 intervalos de
clase. Por regla general, los
intervalos de clase son iguales,
pero si esto no es posible entonces será forzoso usar intervalos de
diferentes anchuras e intervalos
abiertos.
|
Tipos de frecuencias |
|
|
Absolutas |
Relativas |
|
fi
(simple) |
p = proporcional =
fi / N |
|
Fa
(acumulada) |
% = porcentajes =
(fi / N) x 100 |
|
|
Razón
= (fi / N) x n {`x' de cada n} |
Ejemplo:
Organizar datos en una
distribución de frecuencias
El
Dr. Castro es el decano de la facultad de administración y desea
determinar cuánto estudian los alumnos en ella. Selecciona una muestra
aleatoria de 30 estudiantes y determina el número de horas por semana
que estudia cada uno: 15.0, 23.7, 19.7, 15.4, 18.3, 23.0, 14.2, 20.8, 13.5,
20.7, 17.4, 18.6, 12.9, 20.3, 13.7, 21.4, 18.3, 29.8, 17.1, 18.9, 10.3, 26.1,
15.7, 14.0, 17.8, 33.8, 23.2, 12.9, 27.1, 16.6.
Organice los datos en una distribución de frecuencias.
Considere
las clases 8-12 y 13-17. Las marcas de clase son 10 y 15. El intervalo de clase
es 5 (13 - 8).
|
Horas de Estudio |
Frecuencia, f |
|
8-12 |
1 |
|
13-17 |
12 |
|
18-22 |
10 |
|
23-27 |
5 |
|
28-32 |
1 |
|
33-37 |
1 |
Sugerencias para elaborar una
distribución de frecuencias.
Los intervalos de clase usados en la distribución de frecuencias deben ser iguales.
Determine un intervalo de clase
sugerido con la fórmula:
i = (valor más alto - valor más bajo)/número de
clases.
Use el intervalo de clase calculado
sugerido para construir la distribución de frecuencias. Nota: este es un
intervalo de clase sugerido; si el intervalo de clase calculado es 97, puede
ser mejor usar 100.
Cuente el número de valores en
cada clase.
3.-
Distribución de frecuencias agrupadas. Concepto. Formulas. Ejemplos.
Una vez definida la
distribución de Frecuencia como el “conjunto de valores que puede
presentar una variable junto con sus frecuencias”, decimos que
según la naturaleza de la variable, las distribuciones de frecuencias
pueden ser:
Agrupadas
en Intervalos: que es cuando la variable es continua o cuando
es discreta pero con elevado número de valores. En esta situación
se agrupan dichos valores en intervalos o clases. Los intervalos se notan:
ei-1-ei es intervalo i-ésimo.
Se llama amplitud del intervalo a la
distancia que existe entre los extremos, y se nota ai
ai = ei -ei-1
Se llama marca de clase al punto medio de un intervalo. Este punto es
importante porque es el representante del intervalo. Se nota xi:
xi = (ei + ei-1)/2
Se llama densidad de frecuencia de un intervalo a la frecuencia correspondiente
a cada unidad de la variable en dicho intervalo, se nota di:
di = ni /ai
Los intervalos se suelen tomar abiertos por la izquierda y cerrados por la
derecha, salvo el primero que se toma cerrado por los dos lados. En este tipo
de distribuciones se pierde parte de la información al agruparlas en
intervalos, ya no se puede hablar de valores concretos sino de intervalos.
Cuanto mayor sea la amplitud de los intervalos menos intervalos habrá, y
por tanto menos precisión tendremos. En cambio, cuanto menor sea la
amplitud de los intervalos menos intervalos habrá, y mayor será la
precisión, sin embargo la distribución será mas grande y
más difícil de manejar.
Ejemplo:
En una Comunidad X, se toma una
muestra del “ Peso” de varones adultos en edad comprendida de
71.9, 63.9, 62.3, 72.5, 78.0,
70.7, 71.4, 60.5, 60.9, 68.2, 88.5, 76.1, 82.1, 63.7, 79.8, 67.5, 50.1, 69.5,
66.1, 47.3, 72.1, 59.8, 93.7, 80.7, 61.2, 64.3, 53.7, 74.7, 96.3, 73.2.
Se construye una tabla de
frecuencias agrupando los datos en clases de la misma amplitud.
Solución:
Se ordenan los datos de menor a
mayor.
47.3, 50.1, 53.7, 59.8, 60.5, 60.9,
61.2, 62.3, 63.7, 63.9, 64.3, 66.1, 67.5, 68.2, 69.5, 70.7, 71.4, 71.9, 72.1,
72.5, 73.2, 74.7, 76.1, 78.0, 79.8, 80.7, 82.1, 88.5, 93.7, 96.3.
Como los valores extremos son 47.3 y 96.3 y el número de clases
aconsejado para estos datos es 6 (aplicando la fórmula de
Sturges), tomaremos 6 intervalos de amplitud 10, la tabla queda
estructurada de la siguiente manera:
|
clases |
Marcas de
clase |
frecuencias
absolutas de
clase ½acumuladas |
Frecuencias
relativas de
clase ½acumuladas |
||
|
45 -55 55 -65 65 -75 75 -85 85 -95 95 -105 |
50 60 70 80 90 100 |
3 8 11 5 2 1 |
3 11 22 27 29 30 |
0.1 0.266 0.366 0.166 0.066 0.033 |
0.1 0.366 0.733 0.900 0.966 1 |
|
|
|
|
|
|
|
30
0.997»1
4.-
Medidas de posición central. Concepto. Tipos. Formulas. Principales
medidas. Ejemplos.
Nos dan un centro de la distribución de frecuencias, es un
valor que se puede tomar como representativo de todos los datos. Hay diferentes
modos para
definir el "centro" de las observaciones en un conjunto de datos. Por
orden de importancia, son:
MEDIA: (media aritmética o simplemente media). Es el promedio
aritmético de las observaciones, es decir, el cociente entre la suma de
todos los datos y el número de ellos. Si xi
es el valor de la variable y ni su frecuencia, tenemos que:
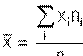
Si los datos están agrupados
utilizamos las marcas de clase, es decir ci en vez de
xi.
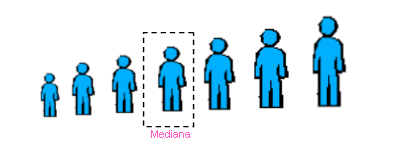
MEDIANA (Me): es el valor que separa por la mitad las
observaciones ordenadas de menor a mayor, de tal forma que el 50% de estas son
menores que la mediana y el otro 50% son mayores. Si el número de
datos es impar la mediana será el valor central, si es par tomaremos
como mediana la media aritmética de los dos valores centrales.
MODA
(M0): es el valor de la variable que
más veces se repite, es decir, aquella cuya frecuencia absoluta es
mayor. No tiene porque ser única.

|
5.- Medidas
de posición no central. Concepto. Tipos. Formulas. Principales
medidas. Ejemplos. |
Las medidas de posición no centrales buscan dar una
idea de donde se encuentra el grueso de la distribución de
frecuencias y se utilizan para
cuantificar su grado de dispersión.
Tipos
Los
cuantiles son valores de la distribución que la dividen en
partes iguales, es decir, en intervalos, que comprenden el mismo número
de valores, su robustez depende del valor de p: cuanto más cercano a 0 o
a 1, menos robusto es; cuanto más cercano a 0.5, más robusto es,
se utilizan para situar a la distribución y para dar una idea de su
dispersión.
Existe un valor en cual coinciden los cuartiles, los
deciles y percentiles es cuando son iguales a
Cuartiles: son 3 valores que distribuyen la
serie de datos, ordenada de forma creciente o decreciente, en cuatro tramos
iguales, en los que cada uno de ellos concentra el 25% de los resultados.
Deciles: son 9 valores que distribuyen la
serie de datos, ordenada de forma creciente o decreciente, en diez tramos
iguales, en los que cada uno de ellos concentra el 10% de los resultados.
Percentiles: son 99 valores que distribuyen la
serie de datos, ordenada de forma creciente o decreciente, en cien tramos
iguales, en los que cada uno de ellos concentra el 1% de los resultados.
Formulas
El cálculo para los cuartiles
se determina a través de la siguiente expresión:
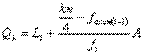
Ejemplo:
Medidas de Posición central
Un
estudiante con las siguientes notas en un lapso:
17,15,16,16,16,14,16,17,10,12,16 y 16
![]() La media de la nota de de este
estudiantes será de:
La media de la nota de de este
estudiantes será de:
X= 17,15,16,16,16,14,16,17,10,12,16
y 16 = 15
12
Otra medida de tendencia central es la moda, siendo
éste el valor de la variable que presenta una mayor frecuencia, en este caso la nota que mas se repite
es 16, es
6.- Medidas
de dispersión. Tipos. Formulas. Principales medidas. Ejemplos.
Las medidas de tendencia central tienen como objetivo el sintetizar los datos en un valor
representativo, las medidas de dispersión nos dicen hasta que punto estas medidas de
tendencia central son representativas como síntesis de la
información. Las medidas de dispersión cuantifican la
separación, la dispersión, la variabilidad de los valores de la
distribución respecto al valor central. Distinguimos entre medidas de dispersión
absolutas, que no son comparables entre diferentes muestras y las relativas que
nos permitirán comparar varias muestras.
MEDIDAS DE DISPERSIÓN
ABSOLUTAS
VARIANZA ( s2 ): es el promedio del cuadrado de las
distancias entre cada observación y la media aritmética del
conjunto de observaciones.
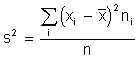
Haciendo operaciones en la
fórmula anterior obtenemos otra fórmula para calcular la
varianza:
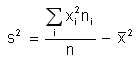
Si los datos están agrupados
utilizamos las marcas de clase en lugar de Xi.
DESVIACIÓN TÍPICA (S): La varianza viene dada por las mismas unidades que la variable pero
al cuadrado, para evitar este problema podemos usar como medida de
dispersión la desviación típica que se define como la
raíz cuadrada positiva de la varianza
![]()
Para estimar la desviación
típica de una población a partir de los datos de una muestra se
utiliza la fórmula (cuasi desviación típica):
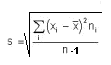
RECORRIDO O RANGO MUESTRAL (Re). Es la diferencia entre el valor de las observaciones
mayor y el menor. Re = xmax - xmin
MEDIDAS DE DISPERSIÓN RELATIVAS
COEFICIENTE DE VARIACIÓN DE
PEARSON: Cuando se
quiere comparar el grado de dispersión de dos distribuciones que no
vienen dadas en las mismas unidades o que las medias no son iguales se utiliza
el coeficiente de variación de Pearson que se define como el cociente
entre la desviación típica y el valor absoluto de la media
aritmética
![]()
CV representa el número de veces que la
desviación típica contiene a la media aritmética y por lo
tanto cuanto mayor es CV mayor es la dispersión y menor la
representatividad de la media.
7.- Medidas de forma: grado de
concentración. Concepto. Tipos. Formulas. Principales medidas. Ejemplos.
Las medidas de forma permiten conocer
que forma tiene la curva que representa la serie de datos de la muestra.
Resumidamente, podemos estudiar las siguientes características de la
curva:
a) Concentración: mide si los
valores de la variable están más o menos uniformemente repartidos
a lo largo de la muestra.
b) Asimetría: mide si la curva tiene una forma simétrica, es
decir, si respecto al centro de la misma (centro de simetría) los
segmentos de curva que quedan a derecha e izquierda son similares.
c) Curtosis: mide si los valores de la distribución están
más o menos concentrados alrededor de los valores medios de la muestra.
Formulas
a) Concentración
Para medir el nivel de
concentración de una distribución de frecuencia se pueden
utilizar distintos indicadores, entre ellos el Índice de Gini.
Este índice se calcula
aplicando la siguiente fórmula:
|
IG = |
S (pi - qi) |
|
---------------------------- |
|
|
S pi |
|
|
(i toma valores
entre 1 y n-1) |
|
En donde pi mide el porcentaje
de individuos de la muestra que presentan un valor igual o inferior al de xi.
|
pi = |
n1 + n2 + n3 + ...
+ ni |
|
|
---------------------------- |
x 100 |
|
|
n |
|
Mientras que qi se calcula
aplicando la siguiente fórmula:
|
qi = |
(X1*n1) + (X2*n2)
+ ... + (Xi*ni) |
|
|
----------------------------------------------------- |
x 100 |
|
|
(X1*n1) + (X2*n2)
+ ... + (Xn*nn) |
|
El Índice Gini (IG)
puede tomar valores entre 0 y 1:
IG = 0 :
concentración mínima. La muestra está uniformemente
repartida a lo largo de todo su rango.
IG = 1
: concentración máxima. Un sólo valor de la muestra
acumula el 100% de los resultados.
El índice de Gini Mide
el grado en que la distribución del ingreso (o del consumo) entre
individuos u hogares de un país de una distribución en
condiciones de perfecta igualdad. Un valor de cero representa igualdad
perfecta, y de 100, desigualdad total
Es el instrumento de uso más
generalizado para medir y comparar la desigualdad distributiva de recursos u
eventos.
Ejemplo:
A continuación se presenta un
ejemplo del cálculo del coeficiente de Gini usando los valores de la
mortalidad infantil de 5 países del área andina en 1997. Los
datos para este ejemplo se presentan en la tabla 1a y la tabla 1b. La curva de Lorenz se muestra en
Los pasos a seguir para el
cálculo del coeficiente de Gini son los siguientes:
- Ordenar
las unidades geográficas por la variable de salud de la peor
situación a la mejor
- Transformar
la tasa en variable continua (calcular el número de muertes
infantiles para cada unidad geográfica)
- Calcular
las proporciones para las dos variables
- Calcular
las proporciones acumuladas para las dos variables
- Graficar
la curva de Lorenz representando en el eje “X” la
proporción acumulada de la población y en el eje
“Y” la proporción acumulada del número de
eventos de la variable de salud.
- Calcular
el coeficiente de Gini utilizando la formula de Brown.
- Interpretación:
- Coeficiente
de Gini : El valor de 0,2 no es un valor alto por estar más
próximo del cero que del uno. No obstante este coeficiente debe
analizarse en términos comparativos. Habría que comparar
este valor con el de otras unidades geográficas para el mismo
indicador.
- Curva de
Lorenz: Se lee en la curva que 30% de las muertes en menores de un
año ocurrieron en 20% de la población de nacidos vivos.
Tabla 1a: País, PNB per
capita, tasa de mortalidad infantil (TMI), número de nacidos vivos y
número de muertes infantiles, proporción de la población
de nacidos vivos y proporción de las muertes
|
País |
PNB per capita 1996 |
TMI |
Nacidos vivos (1,000) |
Muertes |
Proporción nacidos vivos |
Proporción |
|
Bolivia |
2.860 |
59 |
250 |
14.750 |
0,09 |
0,17 |
|
Perú |
4.410 |
43 |
621 |
26.703 |
0,24 |
0,31 |
|
Ecuador |
4.730 |
39 |
308 |
12.012 |
0,12 |
0,14 |
|
Colombia |
6.720 |
24 |
889 |
21.336 |
0,34 |
0,24 |
|
Venezuela |
8.130 |
22 |
568 |
12.496 |
0,22 |
0,14 |
|
Total |
|
33 |
2.636 |
87.297 |
1 |
1 |
Tabla 1b: Proporción acumulada
de la población de nacidos vivos, proporción acumulada de las
muertes infantiles y etapas para el cálculo del coeficiente de Gini
|
País |
Prop. acum. |
Prop. acum. |
Yi+1 + Yi (A) |
Xi+1 -Xi (B) |
A * B |
|
|
Bolivia |
0,09 |
0,17 |
0,17 |
0,09 |
0,09 |
|
|
Perú |
0,33 |
0,48 |
0,65 |
0,24 |
0,15 |
|
|
Ecuador |
0,45 |
0,62 |
1,10 |
0,12 |
0,13 |
|
|
Colombia |
0,78 |
0,86 |
1,48 |
0,33 |
0,50 |
|
|
Venezuela |
1 |
1 |
1,86 |
0,22 |
0,40 |
|
|
Total |
|
|
|
|
1,20 |
|
|
Coeficiente de Gini: 0,2 |
|
|||||
|
Proporción acumulada de
muertes en menores de 1 año |
|
|
|
Proporción acumulada de
nacidos vivos |
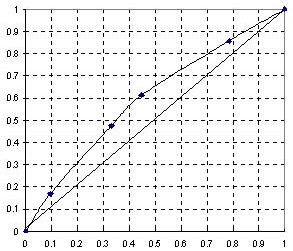
Fuente: Preparado por los Dres. Carlos Castillo-Salgado, Cristina
Schneider, Enrique Loyola, Oscar Mujica y los Lic. Anne Roca y Tom Yerg del
Programa Especial de Análisis de Salud (SHA) de
8.-Medidas de forma: Coeficiente de Asimetría.
Concepto. Tipos. Formulas. Principales medidas. Curvas. Ejemplos.
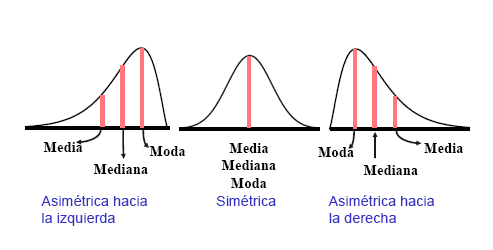
MEDIDA DE ASIMETRÍA
Diremos que una distribución
es simétrica cuando su mediana, su moda y su media aritmética
coinciden.
Diremos que una distribución
es asimétrica
a la derecha si las frecuencias (absolutas o relativas) descienden
más lentamente por la derecha que por la izquierda.
Si las frecuencias descienden
más lentamente por la izquierda que por la derecha diremos que la
distribución es asimétrica a la izquierda.
Existen varias medidas de la
asimetría de una distribución de frecuencias. Una de ellas es el Coeficiente de
Asimetría de Pearson:
![]()
Su valor es cero cuando la
distribución es simétrica, positivo cuando existe
asimetría a la derecha y negativo cuando existe asimetría a la
izquierda.
9.-Medidas de forma: Coeficiente de Curtosis. Concepto.
Tipos de distribuciones. Formulas. Curvas. Ejemplos.
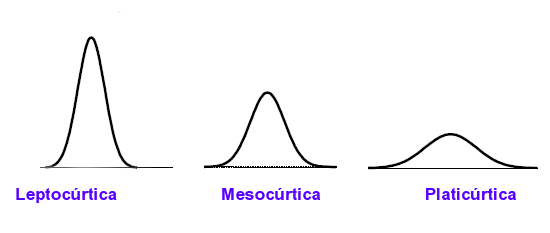
Miden la
mayor o menor cantidad de datos que se agrupan en torno a la moda. Se
definen 3 tipos de distribuciones según su grado de curtosis:
Distribución mesocúrtica:
presenta un grado de concentración medio alrededor de los valores
centrales de la variable (el mismo que presenta una distribución
normal). Distribución leptocúrtica: presenta un elevado
grado de concentración alrededor de los valores centrales de la variable.
Distribución platicúrtica: presenta un reducido grado de
concentración alrededor de los valores centrales de la variable.
EJEMPLO
El número de diás
necesarios por 10 equipos de trabajadores para terminar 10 instalaciones de
iguales características han sido: 21, 32, 15, 59, 60, 61, 64, 60, 71, y
80 días. Calcular la media, mediana, moda, varianza y desviación típica.
SOLUCIÓN:
La media:
suma de todos los valores de una variable dividida entre el número total
de datos de los que se dispone:
![]()
La mediana:
es el valor que deja a la mitad de los datos por encima de dicho valor y a la
otra mitad por debajo. Si ordenamos los datos de mayor a menor observamos la
secuencia:
15, 21, 32, 59, 60, 60,61, 64, 71,
80.
Como quiera que en este ejemplo el
número de observaciones es par (10 individuos), los dos valores que se
encuentran en el medio son 60 y 60. Si realizamos el cálculo de la media
de estos dos valores nos dará a su vez 60, que es el valor de
la mediana.
La moda:
el valor de la variable que presenta una mayor frecuencia es 60
La varianza S2:
Es la media de los cuadrados de las diferencias entre cada valor de la variable
y la media aritmética de la distribución.
|
Sx2= |
|
La desviación
típica S: es la raíz cuadrada de la
varianza.
![]()
S = √ 427,61 = 20.67
El rango: diferencia entre el valor de las
observaciones mayor y el menor
80
- 15 = 65 días
El coeficiente de
variación: cociente
entre la desviación típica y el valor absoluto de la media
aritmética
CV = 20,67/52,3 = 0,39
10.-Distribuciones Bidimensionales. Concepto.
Representación de los datos. Formulas. Ejemplos.
Infografía y Bibliografía
GOMEZ RONDON, Francisco. Estadística Metodologica.
Ediciones Fragor, 1993.
Portus Govinden, Lincoyán.
Introducción a
www.cca.org.mx/dds/cursos/estadistica/html/m12/indice_gini.htm
http://www.liccom.edu.uy/bedelia/cursos/metodos/material/estadistica/med_pos.html
http://155.210.58.160/asignaturas/15909/ficheros/Tema2_notas4.pdf
http://perso.wanadoo.es/mercadoteknia/Statdoc1.htm
http://endrino.cnice.mecd.es/~jhem0027/estadistica/estadistica02.htm
http://nutriserver.com/Cursos/Bioestadistica/Distribuciones_Bidimensionales.html
http://www.aulafacil.com/CursoEstadistica/Lecc-6-est.htm
http://www.cyta.com.ar/biblioteca/bddoc/bdlibros/guia_estadistica/modulo_1.htm