![]()
Estadística – Trabajo 2
Profesor: Sandy López
Realizado por:
Deneise Contreras, Nancy Zambrano, Raquel Rojas, Karina
Maita, Javier Páez y Franklin Lezama
Análisis Bivariable Lineal
Asociación entre
variables
Si dos
variables evolucionan modo tal que en alguna medida se siguen entre ellas,
podemos decir que existe una asociación
o covarianza estadística entre
ellas. Por ejemplo, la altura y peso de la gente están estadísticamente
asociadas: aunque el peso de nadie esté causado por su altura ni la altura por
el peso es, no obstante, habitual que las personas altas pesen más que las
personas bajas. Por otro lado los datos habitualmente incluyen también
excepciones, lo que significa que una asociación estadística es inherentemente estocástica.
La
ciencia de la estadística ofrece numerosos métodos para revelar y presentar las
asociaciones entre dos y hasta más variables. Los medios más simples son los
medios de presentación gráfica y tabulación. La intensidad de la asociación
entre variables puede también describirse como una estadística especial, como
el coeficiente de contingencia
Si, al
analizar los datos, se descubre alguna asociación entre las variables, el
investigador quisiera a menudo saber la razón de esta asociación en el mundo
empírico, es decir él quisiera explicar
esta asociación. Cuando las medidas se han hecho de una serie de estos
fenómenos, es usual que una serie de medidas, llamada variable independiente, se
hace así de la causa presumida, y una otra serie de medidas, la variable dependiente, del
efecto presumido en el fenómeno.
Nota que
no hay métodos en el análisis estadístico para la tarea de descubrir la
explicación causal para una asociación estadística. Una fuerte correlación
entre, digamos, A y B, puede deberse a cuatro razones
alternativas:
- A es la causa de B.
- B es la causa de A.
- Tanto A como B son causadas por C.
- A y B no tienen nada que ver con uno al
otro. Su asociación en los datos analizados está una coincidencia.
El
investigador debe encontrar así la causalidad o la otra explicación para la
asociación de las variables en alguna otra parte que en las medidas. En muchos
casos, la teoría original del investigador puede proporcionar una explicación;
si no, el investigador debe usar su sentido común para clarificar la causa.
A
continuación mencionamos algunos métodos usuales de análisis estadístico que
pueden usarse al estudiar la interdependencia entre una o más variables. Los
métodos han sido dispuestos siguiendo a qué escala de medición corresponden la
mayor parte de las variables.
|
Meta de análisis |
||||
|
Presentar datos y su structura a grandes
rasgos |
||||
|
Medir la fuerza de la asociación entre dos variables |
||||
|
- |
||||
|
- |
- |
|||
|
Encontrar qué variables entre varios son asociadas: |
Calcular contingences o correlaciones
para todos los pares de variables ; análisis factorial |
|||
|
Transcribir una asociación estadística en una función matemática: |
- |
- |
||
Tabulación
La tabulación es una forma habitual de presentar las asociaciones entre
dos o más variables. Una tabla tiene la ventaja de que en ella puede disponerse
bien una cantidad extensa de datos y se conservan las cifras exactas. Una
desventaja es que una tabla grande no es ilustrativa: raras veces revela algo
más que las más obvias regularidades o interdependencias entre datos.
Presentación gráfica
Los productos, como objetos de estudio, son presentados con frecuencia
como imágenes, que son una forma de presentación gráfica. 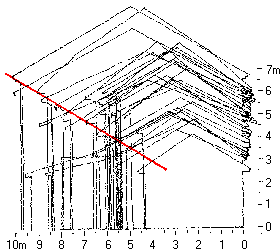 Si el investigador desea resaltar algunos
rasgos comunes o patrones generales que ha encontrado en un grupo de objetos,
puede combinar varios objetos en un gráfico, como en la figura de la izquierda.
En el diagrama, Sture Balgård
muestra cómo los edificios viejos en Härnösand siguen
proporciones uniformes de anchura y altura (la línea roja) con sólo algunas
excepciones. Al inventar métodos ilustrativos de presentación de los hallazgos
del estudio de productos, la más seria restricción es la imaginación del
investigador.
Si el investigador desea resaltar algunos
rasgos comunes o patrones generales que ha encontrado en un grupo de objetos,
puede combinar varios objetos en un gráfico, como en la figura de la izquierda.
En el diagrama, Sture Balgård
muestra cómo los edificios viejos en Härnösand siguen
proporciones uniformes de anchura y altura (la línea roja) con sólo algunas
excepciones. Al inventar métodos ilustrativos de presentación de los hallazgos
del estudio de productos, la más seria restricción es la imaginación del
investigador.
 Con frecuencia, no obstante, la apariencia
del objeto en sí no es importante y sólo interesan los valores numéricos
de sus mediciones. Si se considera así, lo primero que debiéramos plantearnos
al elegir el tipo de gráficos es cuál es la estructura que queremos mostrar de
los datos. Por supuesto tenemos que no "mentir con ayuda de la
estadística", pero siempre es admisible elegir un estilo de presentación
realce los patrones importantes al eliminar o dejar en segundo plano las
relaciones y estructuras que no nos interesan.
Con frecuencia, no obstante, la apariencia
del objeto en sí no es importante y sólo interesan los valores numéricos
de sus mediciones. Si se considera así, lo primero que debiéramos plantearnos
al elegir el tipo de gráficos es cuál es la estructura que queremos mostrar de
los datos. Por supuesto tenemos que no "mentir con ayuda de la
estadística", pero siempre es admisible elegir un estilo de presentación
realce los patrones importantes al eliminar o dejar en segundo plano las
relaciones y estructuras que no nos interesan.
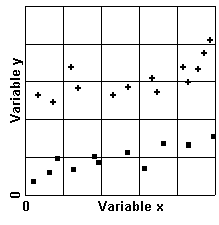
Si
nuestros datos consisten en solamente unas pocas mediciones, es posible
mostrarlos todos como un diagrama de dispersión. Podemos exhibir los
valores de dos variables sobre los ejes de abscisas y ordenadas, y
adicionalmente unas cuantas variables más utilizando los colores o formas de
los puntos. En el diagrama de la derecha, la variable z tiene dos valores que
se indican respectivamente por un cuadrado y un signo +.
Si la
variación es demasiado pequeña para que aparezca claramente, podemos darle
énfasis eliminando partes de una o ambas escalas. Simplemente eliminamos la
parte que no nos interesa, sea por la parte superior o por la inferior. La
parte descartada debe estar vacía de valores medidos empíricamente. Para
asegurarnos que el lector se da cuenta de la operación, es mejor mostrarlo no
sólo en las escalas, sino también en la cuadrícula de fondo del diagrama.
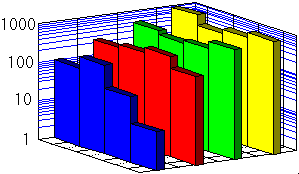 Por otro lado, si el rango de variación de
nuestros datos es muy amplio, podemos plantearnos usar una escala
logarítmica en uno o ambos ejes (véase el diagrama de la izquierda). La
escala logarítmica es apropiada solamente en una escala de proporción.
Por otro lado, si el rango de variación de
nuestros datos es muy amplio, podemos plantearnos usar una escala
logarítmica en uno o ambos ejes (véase el diagrama de la izquierda). La
escala logarítmica es apropiada solamente en una escala de proporción.
Si
tenemos cientos de mediciones, es probable que no queramos mostrarlas todas en
forma de diagrama de dispersión. Una posibilidad en este caso es clasificar los
casos y presentarlos como un histograma.
El histograma puede adaptarse para presentar hasta cuatro o cinco variables.
Podemos hacer esto variando las anchuras de las columnas, sus colores, sus
tramados y por una representación tridimensional (fig. de la izda.). Todas estas variaciones se crean fácilmente con un
programa de hoja de cálculo como Excel, pero no deben ser usadas sólo como
adorno.
Los patrones que rellenan o marcan las columnas del histograma pueden
ser elegidos de forma que simbolicen una de las variables. Por ejemplo, las
columnas que describen el número de automóviles pueden estar formadas por una
pila de automóviles unos sobre otros. Esto es correcto, con tal de que no
variemos el tamaño de los símbolos usados en un histograma. De otro
modo, la interpretación se le haría difícil al lector (¿se vincula el número de
automóviles a la longitud, el área o el volumen de los símbolos de los
automóviles?)
El
investigador suele estar interesado en las relaciones de dos o más
variables antes que en las parejas de mediciones tomadas separadamente. La
forma normal de presentar dos o más variables interdependientes es la curva.
Esto implica una variable continua (es decir, en que el número de
posibles valores es infinito).
No
debemos producir una curva a partir de mediciones que no son valores de la misma
variable. Por ejemplo, los atributos de un objeto son variables diferentes.
Ejemplos de ello son las evaluaciones personales que los investigadores suelen
reunir con la ayuda de escalas semánticas diferenciales del tipo de la mostrada
abajo:
|
Estime las características de su dormitorio. |
||||||||
|
Claro |
_ |
_ |
_ |
_ |
_ |
_ |
_ |
Oscuro |
|
Ruidoso |
_ |
_ |
_ |
_ |
_ |
_ |
_ |
Tranquilo |
|
Limpio |
_ |
_ |
_ |
_ |
_ |
_ |
_ |
Sucio |
|
Grande |
_ |
_ |
_ |
_ |
_ |
_ |
_ |
Pequeño |
 Carecería ahora de sentido el presentar las
distintas evaluaciones del dormitorio como un solo "perfil" como en
el diagrama de la izquierda (aunque encontremos con frecuencia este tipo de
presentaciones ilógicas en informes de investigación.)
Carecería ahora de sentido el presentar las
distintas evaluaciones del dormitorio como un solo "perfil" como en
el diagrama de la izquierda (aunque encontremos con frecuencia este tipo de
presentaciones ilógicas en informes de investigación.)
Si queremos a toda costa poner el acento en que las variables han de ir juntas
(por ejemplo porque todas son evaluaciones del mismo objeto), un método
apropiado podría ser, por ejemplo, un grupo de histogramas (como el de la
derecha).

Todos
los diagramas mostrados arriba pueden combinarse con mapas y otras
presentaciones topológicas Por ejemplo, la variación en las diferentes áreas
del país suele mostrarse como un cartograma
que distinga los diferentes distritos con distintos colores o tramas. Otra
forma es el cartopictograma en que pequeños
diagramas de sectores ("de tarta" o "queso") o de columnas
han sido colocados en el mapa. Las conexiones entre distintas áreas suele ser
con frecuencia mostradas con filas cuyo grosor indica el número de conexiones.
Una obra útil y concisa en español sobre el
uso de diagramas para análisis estadístico es: Antonio Alaminos,
Gráficos, Madrid, Centro de Investigaciones Sociológicas, 1993 (Col.
Cuadernos metodológicos, nº 7)
En los estudios de regresión y correlación
muchas veces se trata solo el caso de variables cuantitativas (ingresos,
salarios, precios, etc.) Con variables de tipo cualitativo se puede construir
tablas de contingencia. Las tablas de contingencia son una de las herramientas
más antiguas y conocidas de la estadística, por lo que su utilización rutinaria
puede llevar aparejada una cierta despreocupación, que es contraria al cuidado
y meticulosidad con el que siempre deben analizarse los datos, sin abandonarnos
a la tarea simple de introducir datos en un programa informático y limitarnos a
transcribir mecánicamente los resultados obtenidos, sin mayor análisis,
restringiendo además nuestra mirada a los resultados con los que estamos
familiarizados, y olvidándonos del resto de información que quizás no
entendemos. A través de éstas se puede estudiar la independencia estadística
entre los distintos atributos.
Si dos atributos son dependientes, se pueden
construir una serie de coeficientes que nos midan el grado asociación o
dependencia entre los mismos.
Partimos
de la tabla de contingencia en la que existen r modalidades del atributo A y s
del atributo B. El total de observaciones será:
La independencia estadística se dará entre
los atributos si:
si esta expresión no se cumple, se dirá que
existe un grado de asociación o dependencia entre los atributos.
El valor ' ij n es
la frecuencia absoluta conjunta teórica que existiría si los 2 atributos fuesen
independientes
El valor ij n es
la frecuencia absoluta conjunta observada
El coeficiente de asociación o contingencia
es el llamado Cuadrado de Contingencia, que es un indicador del grado de
asociación:
El campo
de variación va desde cero (cuando existe independencia y ' ij
n = ij n), hasta determinados valores positivos, que
dependerá de las magnitudes de las frecuencias absolutas que lo componen.
Este
inconveniente de los límites variables se eliminará con el empleo del
Coeficiente de contingencia de Pearson:
Varía
entre cero y uno.
Cuanto
más se aproxime a 1 más fuerte será el grado de asociación entre los dos
atributos.
•
Estudio de la asociación entre dos atributos - Para tablas de contingencia 2 x
2 Sean A y B dos variables cualitativas o atributos tales que presentan 2 modalidades
cada una. La tabla de contingencia correspondiente es la siguiente:
Si
finalmente podemos concluir que los dos atributos están asociados, se pueden
plantear dos preguntas:
1ª)
¿Cual es la intensidad de la asociación entre los dos atributos?
2ª)
¿Cual es la dirección de la asociación detectada?
• Asociación perfecta entre dos atributos
Ocurre cuando, al menos, una de las modalidades de uno de los atributos queda
determinada por una de las modalidades del otro atributo. Esto ocurre cuando
existe algún cero en la tabla
2 x 2.
La asociación perfecta puede ser:
a) Asociación perfecta y estricta
Ocurre cuando dada modalidad de uno de los
atributos queda inmediatamente determinada la modalidad del otro. Es decir,
cuando 0 22 11 = = n n ó 0 21 12 = = n n
Ejemplo:
Con estos datos sabemos que si un individuo
es hombre el tipo de trabajo será temporal y si es mujer su contrato será
indefinido.
• Asociación perfecta e implícita de tipo 2
Ocurre cuando:
1º) Si se toma la modalidad de un atributo
queda determinada la modalidad del otro atributo al que pertenece la
observación.
2º) Si se toma la otra modalidad, no queda
determinada la modalidad del otro atributo al que pertenece la observación.
Es
decir, esta asociación se produce cuando alguna de las frecuencias observada es
cero.
Si la
persona observada es mujer sabremos que su contrato es indefinido; si es varón
puede ser indefinido o temporal.
- Si el
contrato analizado es temporal pertenecerá a un hombre; si es un contrato
indefinido, podrá ser de un hombre o una mujer.
•
También podemos delimitar si la asociación es positiva o negativa:
-
Asociación
positiva Cuando se verifica que:
a) La modalidad 1 del atributo A está
asociada a la modalidad 1 del atributo B
b) La modalidad 2 del atributo A está
asociada a la modalidad 2 del atributo B.
-
Asociación negativa: Cuando se verifica que:
a) La
modalidad 1 del atributo A está asociada a la modalidad 2 del atributo B b) La modalidad 2 del atributo A esta asociada a la
modalidad 1 del atributo A. Para medir el sentido de la asociación entre dos
atributos emplearemos el indicador Q de Yule:
• Tablas
de contingencia R x S Para determinar la intensidad de dicha asociación,
calculamos
Existirá
una mayor intensidad en la asociación entre 2 variables a medida que el
indicador adopte valores próximos a 1.
Modelos de regresión bivariable
lineal
ANÁLISIS DE REGRESIÓN
Modelo de regresión Bivariable lineal
En el modelo de regresión bivariable lineal, una variable Y dependiente, o “explicada, se relaciona con
una variable X independiente, o “explicativa”, por la siguiente
expresión:
yi
= α + βxi + ui,
Donde α y β son los parámetros de regresión
desconocidos llamados coeficientes de regresión de población, y ui es el “trastorno” al azar o
residual.
Se designan las variables como dependientes o independientes, esto
se refiere al significado matemático o funcional de dependencia; no
implica dependencia estadística ni causa y efecto. Pero, finalmente, las tres
interpretaciones de dependencia serán abarcadas en el análisis de regresión.
La relación de dependencia lineal definida por yi
= α + βxi + ui, consta de dos partes: la parte
sistemática identificada por α + βxi y la parte estocástica identificada por ui. Esto recuerda que es un
modelo probabilista, en vez de determinista.
La naturaleza estocástica del modelo de regresión implica que el valor
de Y nunca puede ser predicho exactamente como un caso determinista. La
incertidumbre relativa a Y es atribuible a la presencia de ui, que,
siendo una variable aleatoria, imparte aleatoriedad a Y.
Ejemplo:
No se puede esperar que robles de la
misma edad (xi) tengan la misma
altura (yi), debido a la influencia
de fuerzas “causales”. Además de esta interpretación del término casual
como una aleatoriedad inherente a la conducta, tienen mérito otros dos puntos
de vista. A veces, surge ui
por la exclusión de otras variables explicativas
importantes y relevantes en el modelo. Esto conduce al análisis de
regresión múltiple. En ocasiones, el error de medición en Y
es la causa de ui. En una
aplicación particular del análisis de regresión, cualquiera de estas razones
podría ser la interpretación razonable de ui,
o cualquier par de estas razones, o las tres razones juntas.
Como una digresión, podría preguntarse cómo se maneja el error de
medición en X, ahora que el error de medición en Y ya
se ha mencionado. La respuesta es que yi
= α + βxi + ui,
no permite
error de medición en X. Pero hay otros modelos que lo permiten. A pesar
de esta limitación en yi = α
+ βxi + ui, sigue siendo un modelo muy útil.
Cualquiera que sea la forma en que se
interprete ui, está claro
que la completa especificación del modelo de regresión incluye no solo la forma
de la ecuación de regresión, sino también una expresión de cómo son
determinados los valores de la variable independiente y una especificación de
la distribución de ui, por
probabilidades. La especificación completa de lo que se llama modelo clásico de
regresión lineal simple la hace el siguiente conjunto de supuestos:
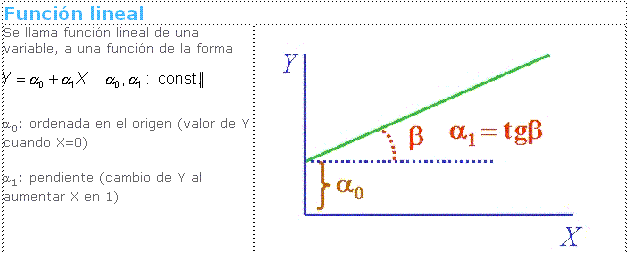
1.- La variable independiente X
es fija. El término "fijo" está en contraste directo con la
noción de “estocástico". La expresión "valores fijos de X"
significa que X tiene valores que son fijados (es decir, escogidos o
predeterminados) por el investigador. El supuesto independiente-variable-fijo
implica que para cada valor fijo de X, xi,
hay una distribución de valores Y por probabilidades,
llamada subpoblación de Y.
Consideremos la variable bidimensional (X,Y) , y sea E(Y/X) la regresión del promedio de Y
sobre X , cuya forma dependerá de la relación existente entre las variables. En
este capítulo nos limitaremos a las funciones de regresión que son lineales en
los parámetros (o coeficientes).
Si la distribución de (X,Y)
es Normal bivariada, entonces las funciones
condicionales de probabilidad son también normales; es decir: dado un valor
fijo X=x , la variable Y se distribuye en forma normal con media E(Y/X) =
α + β.X y con variancia V(Y/X) = σ2/y(1 - p2 )−= σ2
constante, lo que significa, que no depende del valor X=x.
La diferencia que existe entre el valor que toma la variable Y (dado que
X=x) y la esperanza condicional E(Y/x) se denomina
residuo , desvío o error , y representa la parte aleatoria . En otras palabras,
si (xi ,
yi ) es el valor que asume la variable bidimensional
(X,Y), el residuo será = yεi - E(Y/xi ) , y por lo tanto
yi = E(Y/xi ) +
εi .
MODELO DE REGRESIÓN BIVARIABLE LINEAL
Considerando una relación lineal entre las variables, esto significa que
yi= α + β.xi+εi
Donde α + β.xi = E(Y/xi ) es la parte sistemática o determinística
(sólo depende del valor x ), y es la parte aleatoria sobre la cual se
establecerán condiciones o restricciones que determinan el comportamiento de la
variable Y. Este modelo supone que para cada valor fijo x ,
existe una distribución de valores de la variable Y . ε
En este modelo identificamos las siguientes componentes:
α y β: parámetros poblacionales
X : variable "explicativa"
Y : variable "explicada"
ε : error residual
Este residuo ε se compone esencialmente de errores casuales, debida
a la propia aleatoriedad de cada individuo, pudiendo además incluir errores de
medición de los yi , como también deficiencias del
modelo debidas, por ejemplo, a otras variables que no han sido consideradas en
dicho modelo . En otras palabras, εi es la parte de yi
que no está explicada por la regresión lineal de Y sobre xi .
Este modelo supone una distribución Normal de los errores o residuos,
con media E(ε) = 0 y variancia constante V(ε
) = σ2 , característica que recibe el nombre de homocedasticidad
y significa que la variancia de Y no depende del valor que tome la variable X .
Es decir:
εi ~N (0,σ2)
Estimación de parámetros de
regresión
Estimación de los parámetros de la recta de regresión. El primer problema a abordar es obtener los
estimadores de los parámetros de la
recta de regresión, partiendo de una muestra de tamaño n, es
decir, n pares (x1, Y1) , (x2, Y2),
..., (xn, Yn);
que representan nuestra intención de extraer para cada xi
un individuo de la población o variable Yi
.
Una vez realizada la muestra, se
dispondrá de n pares de valores o puntos del plano (x1, y1) , (x2,
y2), ..., (xn, yn). El método de estimación aplicable en
regresión, denominado de los mínimos cuadrados, permite esencialmente
determinar la recta que "mejor" se ajuste o mejor se adapte a la nube
de n puntos. Las estimaciones de los parámetros de la recta de regresión
obtenidas con este procedimiento son:

Por tanto la recta de regresión
estimada será:
![]()
Un ejemplo. La recta de regresión representada
corresponde a la estimación obtenida a partir de 20 pares de observaciones: x
representa la temperatura fijada en un recinto cerrado e Y el ritmo
cardíaco de un vertebrado.
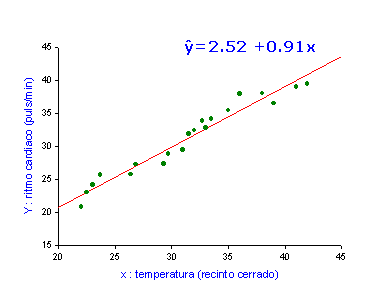
Estimación de
los parámetros del modelo.
En
el modelo de regresión lineal simple hay tres parámetros que se deben estimar:
los coeficientes de la recta de regresión, ![]() 0 y
0 y ![]() 1; y la
varianza de la distribución normal,
1; y la
varianza de la distribución normal, ![]() 2.
2.
El
cálculo de estimadores para estos parámetros puede hacerse por diferentes
métodos, siendo los más utilizados el método de máxima verosimilitud y el método de
mínimos cuadrados.
Método de máxima
verosimilitud.
Conocida
una muestra de tamaño n, ![]() , de la hipótesis de normalidad se sigue que la densidad
condicionada en yi es
, de la hipótesis de normalidad se sigue que la densidad
condicionada en yi es
![]()
y, por tanto, la función de densidad conjunta de la muestra es,
![]()
Una
vez tomada la muestra y, por tanto, que se conocen los valores de ![]() i = 1n,
se define la función
de verosimilitud asociada a la muestra como
sigue
i = 1n,
se define la función
de verosimilitud asociada a la muestra como
sigue
esta función (con variables 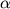 0, 1 y
0, 1 y 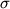 2) mide la verosimilitud
de los posibles valores de estas variables
en base a la muestra recogida.
2) mide la verosimilitud
de los posibles valores de estas variables
en base a la muestra recogida.
El
método de máxima verosimilitud se basa en calcular los valores de 0, 1 y 2 que maximizan la función (9.3) y, por tanto, hacen máxima la
probabilidad de ocurrencia de la muestra obtenida. Por ser la función de verosimilitud una función creciente, el problema es
más sencillo si se toman logaritmos y se maximiza la
función resultante, denominada función
soporte,
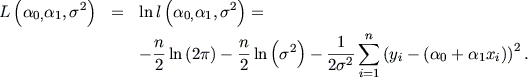
Maximizando la anterior se
obtienen los siguientes estimadores máximo verosímiles,
![]()
![]()
![]()
donde se ha denotado
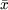 e
e 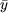 a las medias muestrales de X
e Y, respectivamente; sx2 es la varianza muestral de X
y sXY es
la covarianza muestral entre X
e Y. Estos valores se calculan de la siguiente forma:
a las medias muestrales de X
e Y, respectivamente; sx2 es la varianza muestral de X
y sXY es
la covarianza muestral entre X
e Y. Estos valores se calculan de la siguiente forma:
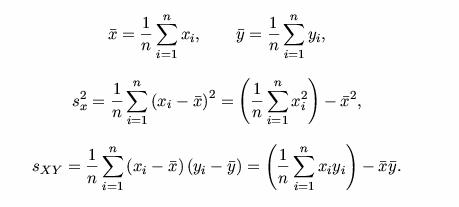
Método
de mínimos cuadrados.
A
partir de los estimadores: ![]() 0
y
0
y ![]() 1,
se pueden calcular las predicciones para las observaciones muestrales, dadas por,
1,
se pueden calcular las predicciones para las observaciones muestrales, dadas por,
![]()
o, en forma matricial,
![]()
donde ![]() t
=
t
= ![]() .
Ahora se definen los residuos como
.
Ahora se definen los residuos como
|
ei |
= yi - |
|
Residuo |
= Valor observado
-Valor previsto, |
en forma matricial,
![]()
Los
estimadores por mínimos cuadrados se obtienen minimizando la suma de los
cuadrados de los residuos, ésto es, minimizando la
siguiente función,
derivando e igualando a cero se obtienen las siguientes ecuaciones,
denominadas ecuaciones canónicas,
![]()
![]()
De donde se deducen los
siguientes estimadores mínimo cuadráticos de los parámetros de la recta
de regresión
![]()
![]()
Se
observa que los estimadores por máxima verosimilitud y los estimadores mínimos
cuadráticos de ![]() 0 y
0 y ![]() 1 son iguales. Esto es debido a
la hipótesis de normalidad y, en adelante, se denota
1 son iguales. Esto es debido a
la hipótesis de normalidad y, en adelante, se denota ![]() 0 =
0 = ![]() 0,MV =
0,MV =
![]() 0,mc y
0,mc y
![]() 1 =
1 = ![]() 1,MV =
1,MV =
![]() 1,mc.
1,mc.
- Varianza de la
regresión de la muestra
Es
un modo alternativo de hacer contrastes sobre el coeficiente a1.
Consiste en descomponer la variación de la variable Y de dos componentes: uno
la variación de Y alrededor de los valores predichos por la regresión y otro
con la variación de los valores predichos alrededor de la media. Si no existe
correlación ambos estimadores estimarían la varianza de Y y si la hay, no. Comparando ambos estimadores con la prueba
de la F se contrasta la existencia de correlación. Para el ejemplo:


A partir de una
muestra aleatoria, la teoría estadística permite:
i) estimar los coeficientes a i del modelo
(hay dos procedimientos: mínimos cuadrados y máxima verosimilitud que dan el
mismo resultado).
ii) estimar la varianza de las variables Y|xi
llamada cuadrados medios del error y representada por s2
o MSE. A su raíz cuadrada se le llama error estándar de la estimación.
iii) conocer la distribución muestral de los
coeficientes estimados, tanto su forma (t) como su error estándar, que
permite hacer estimación por intervalos como contrastes de hipótesis sobre
ellos.
Ejemplo 3 : Para el diseño del ejemplo
una muestra produce los siguientes datos:
|
X
(sal) |
Y
(Presión) |
|
1,8 |
100 |
|
2,2 |
98 |
|
3,5 |
110 |
|
4,0 |
110 |
|
4,3 |
112 |
|
5,0 |
120 |
La "salida"
de un paquete estadístico es:
86,371 presión
arterial media sin nada de sal.
6,335 aumento de presión por cada gr de sal; como es
distinto de 0 indica correlación. La pregunta es ¿podría ser 0 en la población?
En términos de contrastes de hipótesis
H0
: a1 =
0
H1 : a1 ¹ 0
según iii)

análisis de la regresión y análisis de la varianza
Desarrollo: Cualquiera que sea el
origen de los datos experimentales que deseamos analizar para extraer
conclusiones prácticas (p.ej., planillas de operación, ensayos preprogramados
intencionalmente, etc.) debemos recurrir a la estadística para que nos oriente
en la tarea. La forma más poderosa, quizás, de analizar estos datos es mediante
los dos tipos de análisis mencionados en el título. Ambos tipos están ligados
entre sí por una teoría coherente que permite transformar uno de los dos tipos
de análisis en el otro.
Empecemos
por el modelo más simple. Sea un modelo lineal y de un único factor X. Este
modelo lineal, llamado también de primer orden, resulta ser
OMEGA = b0 + b1X
Modelo
denominado de regresión, donde OMEGA es el criterio a maximizar, b0
es la ordenada al origen y b1 es la pendiente de la recta. Ya que
las incógnitas o parámetros b0 y b1 son solamente dos,
nos alcanzan dos niveles distintos para la variable X para identificarlos. Sin
embargo, habrá que repetirlos para no dejarnos confundir por el error
experimental.
Este
caso sencillo se puede mirar también desde otra óptica. Un modelo equivalente,
denominado de análisis de la varianza, es el de escribir
OMEGA = mu
+ alfai + e ij
Donde
mu = el valor medio del ensayo, alfa es la incidencia
sobre los resultados del factor X que estamos midiendo y e es el error
experimental.
Para
entender este modelo afirmemos que el resultado de una tentativa en el nivel i
durante la replicación j , es:
gammaij = gammaij
i = 1,2,.., n (niveles) y j = 1,2,... m (replicaciones)
Sumando
y restando a la igualdad tanto el promedio de todas las n.m
tentativas, gamman como el promedio de los
m ensayos realizados en el nivel i del único factor, gamma.,
llegamos a que
gammaij = gamma.. + (gamma. - gamma..) + (gammaij>
- gamma.)
Donde
los tres sumandos que han quedado explícitos son, respectivamente,
·
mu, la
media,
·
alfai, la
influencia del factor y
·
eij, el
error experimental.
Así como
está autorizado usar el modelo de regresión, es equivalente usar el modelo de
análisis de la varianza, que contrasta la incidencia del factor con respecto a
la incidencia del error experimental.
EJEMPLO
NUMÉRICO
Repitamos
tres veces un ensayo con un único factor, temperatura, en dos niveles,
·
0 (baja temperatura, digamos 105º) y
·
1 (alta temperatura, 110º)
Las
eficiencias ("OMEGA") obtenidas en las seis corridas (que se estiman
suficientes para conocer el error experimental), son:
|
----------- |
Nivel 0 |
Nivel 1 |
|
Réplica 1 |
79 |
90 |
|
Réplica 2 |
80 |
91 |
|
Réplica 3 |
81 |
89 |
Niveles i = 0, 1 Réplicas j = 0,1,2
A simple
vista ya se puede analizar este sencillo caso, donde no cabe duda que es
preferible usar 110º en lugar de 105º. Pero para aplicar las fórmulas previas,
podemos resolver el problema por análisis de la regresión y luego por análisis
de la varianza.
ANÁLISIS DE LA REGRESIÓN
|
---- |
fi |
xi |
yi = gammaij
|
Ki |
|
--- |
1 |
0 |
79 |
80 |
|
--- |
1 |
0 |
80 |
81 |
|
--- |
1 |
0 |
81 |
82 |
|
--- |
1 |
1 |
90 |
92 |
|
--- |
1 |
1 |
91 |
93 |
|
--- |
1 |
1 |
89 |
91 |
|
SIGMA |
6 |
3 |
510 |
519 |
Regresión Lineal Múltiple
Se trata de predecir el valor de una
variable respuesta (y) como función lineal de una familia de m
variables explicativas (x1, x2, ..., xm),
a partir de una muestra de tamaño n cuyas observaciones se
ordenan matricialmente:
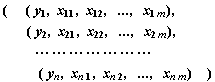
Siendo yi
la i-ésima variable respuesta y xi,j la j-ésima variable explicativa asociada a la observación i.
Así las cosas, se trata de ajustar los datos
a un modelo de la forma
![]()
bajo las siguientes hipótesis:
- Los residuos ei
son normales de media 0 y varianza común desconocida
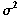 ;
además, estos residuos son independientes.
;
además, estos residuos son independientes. - El número de variables explicativas (m) es menor que
el de observaciones (n); esta hipótesis se conoce con el
nombre de rango completo.
- No existen relaciones lineales exactas entre las variables
explicativas.
El estimador del vector paramétrico
es
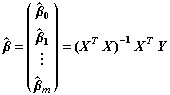
Siendo
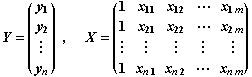
Habiéndose indicado la transposición
matricial mediante el superíndice T.
El estimador insesgado
de la varianza ![]() , conocido
con el nombre de varianza residual, tiene por expresión
, conocido
con el nombre de varianza residual, tiene por expresión
![]()
El coeficiente de determinación
corregido, definido como
![]()
Siendo
![]()
mide el ajuste del modelo, se interpreta como el
porcentaje de variación de la variable respuesta explicada por el modelo; así,
cuanto más se acerque R2 a 100, con más confianza se
podrá considerar el modelo lineal como válido.
El contraste de regresión es imperativo a la
hora de diagnosticar y validar el modelo que se está ajustando; consiste en
decidir si realmente la variable respuesta y es función lineal de
las explicativas x1, x2, ..., xm.
Formalmente, el contraste se plantea en los siguientes términos:
H0: "no existe dependencia
lineal: ![]() "
"
frente a la alternativa:
H1: "sí existe alguna
dependencia lineal: ![]() ".
".
El estadístico de contraste es
![]()
que se distribuye como una Fm,n-m-1
de Snedecor. El contraste se realiza con un nivel de
significación del 5%.
Inferencias acerca de los
coeficientes de regresión de la población
Regresión lineal simple y
correlación
El análisis de regresión se utiliza principalmente con el propósito de hacer
predicciones.
El análisis de correlación se utiliza para medir la intensidad de la asociación
entre las variables numéricas.
Diagrama de dispersión: cada valor es graficado en sus coordenadas particulares
X, Y.
Tipos de modelos de regresión. El modelo de línea recta puede representarse
como:
![]()
El
primer termino (B0), es la intersección Y para la población; B1 es la pendiente
de la población y E es el error aleatorio en Y para la observación i. En este
modelo, la pendiente de la recta B1 representa el cambio esperado en Y por
unidad de cambio en X; esto es, representa la cantidad que cambia la variable Y
con respecto a una unidad de cambio particular en X. B0 representa el valor
promedio de Y cuando X es igual a cero. El modelo matemático está influenciado
por la distribución de los valores X y Y en el
diagrama de dispersión.
Determinación de la ecuación de
regresión lineal simple. El método de mínimos cuadrados.
A b0 y b1 se los puede considerar
como estimaciones de B0 y B1. Por consiguiente, la ecuación de regresión de
muestra sería:
![]() Yi es el valor predicho de Y para la observación i, y Xi es el valor de X para la observación i.
Yi es el valor predicho de Y para la observación i, y Xi es el valor de X para la observación i.
El análisis de regresión lineal
simple tiene que ver con la búsqueda de la línea recta que mejor se ajusta a
los datos. El mejor ajuste significa que deseamos encontrar la línea recta para
la cual las diferencias entre los valores reales (Yi)
y los valores que serían predichos a partir de la línea ajustada de regresión (Yi estimada) sean lo más pequeñas posibles. Debido a que
tales diferencias serán positivas y negativas para las diferentes
observaciones, minimizamos matemáticamente la expresión:
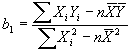
![]() Una técnica
matemática utilizada para determinar los valores de bo
y b1 que mejor se ajusten a los datos observados se conoce como método de
mínimos cuadrados. Al utilizar este método surgen dos ecuaciones normales:
Una técnica
matemática utilizada para determinar los valores de bo
y b1 que mejor se ajusten a los datos observados se conoce como método de
mínimos cuadrados. Al utilizar este método surgen dos ecuaciones normales:
![]()
![]() I.
I.
II.
![]()
El error estándar de estimación.
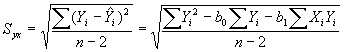
El error estándar de la estimación,
representado como Syx se define como:
Mediciones de variación en
regresión y correlación. Con el fin de examinar que tan bien una variable
independiente predice a la variable dependiente, necesitamos desarrollar
algunas medidas de variación. La primera: la suma total de cuadrados, esta
puede dividirse en dos partes: la variación explicada o suma de cuadrados
debida a la regresión (SSR) y la variación no explicada o suma de cuadrados de
error (SSE). La suma de cuadrados debida a la regresión.
SST = SSR + SSE
![]()
![]()
En la que SST =
![]()
Podemos ahora definir el
coeficiente de determinación r2: mide la porción de variación que es explicada
por la variable independiente del modelo de regresión:
![]()
![]() Algunos
investigadores sugieren que se calcule un coeficiente r2 ajustado para reflejar
tanto el número de variables explicatorias del modelo
como el tamaño de la muestra. El coeficiente r2 ajustado se calcula de la
siguiente manera:
Algunos
investigadores sugieren que se calcule un coeficiente r2 ajustado para reflejar
tanto el número de variables explicatorias del modelo
como el tamaño de la muestra. El coeficiente r2 ajustado se calcula de la
siguiente manera:
Correlación: medición de la
intensidad de la asociación
En el análisis de correlación estamos interesados en medir el grado de
asociación entre dos variables. La intensidad de la
relación se mide mediante el coeficiente de correlación
, cuyos valores van de –1 a +1. El coeficiente de correlación en casos
de regresión lineal simple toma el signo de b1.
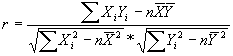
Suposiciones
de regresión y correlación. Las cuatro principales suposiciones acerca de la
regresión son: 1.Normalidad. 2. Homoscedasticidad. 3.
Independencia de error. 4. Linealidad.
La primera suposición, normalidad, requiere que los valores de Y estén
distribuidos normalmente en cada valor de X. Siempre y cuando la distribución de
los valores de Yi alrededor de cada nivel de X no sea
extremadamente diferente de una distribución normal, las inferencias acerca de
la línea de regresión y de los coeficientes de regresión no se verán seriamente
afectadas. La segunda suposición, homoscedasticidad,
requiere que la variación alrededor de la línea de regresión sea constante para
todos los valores de X. La tercera suposición, independencia de error, requiere
que el error sea independiente de cada valor de X. Por último, la linealidad
establece que la relación entre las variables es lineal.
Estimación del intervalo de
confianza para predecir yx.
![]()
![]()
Intervalo de predicción para
una respuesta individual Yi
![]()
Inferencias respecto a los
parámetros de población en regresión y correlación
Ho= β1=0 (No hay relación)
H1= β1 ≠ 0 (Hay
relación)
Y la estadística de prueba para
probar la hipótesis está dada por:
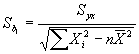
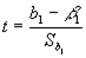
La estadística de prueba sigue una
distribución t con n-2 grados de libertad.
Un segundo método equivalente para
probar la existencia de una relación lineal entre las variables consiste en
establecer una estimación de intervalo de confianza de β1 y determinar si
el valor supuesto está incluido en el intervalo. La estimación del intervalo de
confianza se obtendría de la siguiente manera:
![]()
Un tercer método para examinar la
existencia de una relación lineal entre dos variables implica al coeficiente de
correlación de la muestra, r. Para ello se realiza lo siguiente:
Ho: ρ = 0 (No hay relación)
H1: ρ ≠ 0 (Hay relación)
La estadística de prueba para
determinar la existencia de una correlación esta dada por:
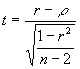
La estadística de prueba sigue una
distribución t con n-2 grados de libertad.
Dificultades de la regresión y
cuestiones éticas
Las dificultades que surgen con frecuencia son:
- Falta de conciencia sobre las suposiciones de la regresión de
mínimos cuadrados.
- Conocimiento de cómo evaluar las suposiciones de la regresión de
mínimos cuadrados.
- Conocimientos de cuáles son las alternativas de la regresión de
mínimos cuadrados si no se cumple alguna suposición individual.
- La creencia de que la correlación implica causalidad.
El uso del modelo
de regresión sin conocer de qué se trata.
Predicción y Pronosticación
Los términos predicción, probabilidad y pronosticación están íntimamente
relacionados, debido a que prácticamente todos son codependientes,
en sus respectivas definiciones son prácticamente una misma cosa.
Según el diccionario de
Pronosticación,
según el RAE: Acción y efecto de pronosticar
Probabilidad:
Verosimilitud o fundada apariencia de verdad. Cualidad de probable, que puede
suceder. En un proceso aleatorio, razón entre el número de casos favorables y
el número de casos posibles.
Se aplican las técnicas de probabilidad para llegar
a una predicción o pronostico.
Dichas
técnicas son de gran importancia, debido a su aplicación a distintos ámbitos de
la vida, en la cual se hace necesario conocer científicamente una serie de
resultados claves en la toma de decisiones.
La teoría de probabilidad
es la teoría matemática que modela los fenómenos aleatorios. Estos deben
contraponerse a los fenómenos determinísticos, en los
cuales el resultado de un experimento, realizado bajo condiciones determinadas,
produce un resultado único o previsible: por ejemplo, el agua calentada a 100
grados centígrados, a presión normal, se transforma en vapor.
Un
fenómeno aleatorio es aquel que, a pesar de realizarse el experimento bajo las
mismas condiciones determinadas, tiene como resultados posibles un conjunto de
alternativas: por ejemplo, arrojar una moneda o un dado.
Si una moneda se lanza al aire,
esta puede caer en cara o en sello, pero no sabemos cual de éstas ocurrirá en
un solo lanzamiento. Sin embargo, supongamos que se repite el experimento de
lanzar la moneda; se s el número de
aciertos es decir que aparezca una cara, y sea n el número de lanzamientos. Entonces se ha observado empíricamente
que la razón f = s/n, denominada frecuencia relativa del resultado, resulta estable en largo plazo, es decir,
la razón f = s/n, se acerca a su
limite. Si la moneda esta perfectamente equilibrada, entonces se espera que la
moneda caiga en cara aproximadamente el 50% de las veces o, en otras palabras,
la frecuencia relativa llegará a 1/2 en forma deductiva. Es decir, la
probabilidad de que la moneda caiga
hacia un lado es igual a la posibilidad de que caiga del otro, de donde la
probabilidad de obtener cara es una en dos lo cual significa que la
probabilidad de obtener una cara es 1/2. Aunque el resultado especifico en
cualquier lanzamiento no se conoce, el comportamiento a largo plazo sí está
determinado. Este comportamiento estable a largo plazo del fenómeno aleatorio
constituye la base de la teoría de probabilidad.
La teoría de probabilidad es la teoría
matemática que modela los fenómenos aleatorios. Estos deben contraponerse a los
fenómenos determinísticos, en los cuales el resultado
de un experimento, realizado bajo condiciones determinadas, produce un
resultado único o previsible: por ejemplo, el agua calentada a 100 grados
centígrados, a presión normal, se transforma en vapor.
Un
fenómeno aleatorio es aquel que, a pesar de realizarse el experimento bajo las
mismas condiciones determinadas, tiene como resultados posibles un conjunto de
alternativas: por ejemplo, arrojar una moneda o un dado.
Esta
aproximación axiomática que generaliza el marco clásico de la probabilidad, la
cual obedece a la regla de cálculo de casos favorables sobre casos posibles,
permitió la modelación matemática de sofisticados fenómenos aleatorios.
Actualmente, estos fenómenos encuentran aplicación en las más variadas ramas
del conocimiento, como puede ser la física (donde corresponde mencionar el
desarrollo de las difusiones y el movimiento Browniano), o las finanzas (donde
destaca el modelo de Black y Scholes
para la valuación de acciones).
Según Spiegel (1) la definición clásica de la probabilidad se
define en base a sí misma (igualmente factible es sinónimo de igualmente
probable) se define la probabilidad estimada o empírica basada en la frecuencia
relativa de aparición de un suceso S cuando Ω
es muy grande. La probabilidad de un suceso es una medida se escribe como
![]() ,
,
y mide con qué frecuencia ocurre algún suceso
si se hace algún experimento indefinidamente.
La
definición anterior es complicada de representar matemáticamente ya que Ω debiera ser infinito. Otra manera de definir la
probabilidad es de forma axiomática esto estableciendo las relaciones o
propiedades que existen entre los conceptos y operaciones que la componen. La
probabilidad tiene muchas propiedades importantes, que se muestra en la página
axiomas de probabilidad.
Probabilidad discreta
Discreta porque la variable sólo
puede tomar valores de un conjunto ya sea finito o infinito pero contable.
[Probabilidad continua
Una variable aleatoria es una
función
![]()
Que da un valor numérico a cada
suceso en Ω.
Función de densidad
La
función de densidad, o densidad de probabilidad de una variable aleatoria, es
una función a partir de la cual se obtiene la probabilidad de cada valor que
toma la variable. Su integral en el caso de variables aleatorias continuas es
la distribución de probabilidad. En el caso de variables aleatorias discretas
la distribución de probabilidad se obtiene a través del sumatorio
de la función de densidad.
Probabilidad condicional
Se llama probabilidad condicional a
la probabilidad de que un suceso se cumpla habiéndose cumplido ya otro. Se nota
"probabilidad de A sabiendo que B se ha cumplido" de la siguiente
manera:
|
pB(A) ó p(A\B) |
Dicha probabilidad se calculará de
la siguiente forma:
|
|
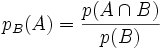
Tres
tipos de probabilidad.
Existen
tres maneras básicas de clasificar la probabilidad. Estas tres formas presentan
planteamientos conceptuales bastante diferentes:
- Planteamiento clásico.
- Planteamiento de frecuencia relativa.
- Planteamiento subjetivo.
Probabilidad
clásica.
Se
define la probabilidad de que un evento ocurra como:
Número
de resultados en los que se presenta el evento / número total de resultados
posibles
Cada uno
de los resultados posibles debe ser igualmente posible.
La
probabilidad clásica, a menudo, se le conoce como probabilidad a priori, debido
a que si utilizamos ejemplos previsibles como monedas no alteradas, dados no
cargados y mazos de barajas normales, entonces podemos establecer la respuesta
de antemano, sin necesidad de lanzar una moneda, un dado o tomar una carta. No
tenemos que efectuar experimentos para poder llegar a conclusiones.
Este
planteamiento de la probabilidad tiene serios problemas cuando intentamos
aplicarlo a los problemas de toma de decisiones menos previsibles. El
planteamiento clásico supone un mundo que no existe, supone que no existen
situaciones que son bastante improbables pero que podemos concebir como reales.
La probabilidad clásica supone también una especie de simetría en el mundo.
Frecuencia
relativa de presentación.
En
el siglo XIX, los estadísticos británicos, interesados en la fundamentación teórica del cálculo del riesgo de pérdidas
en las pólizas de seguros de vida y comerciales, empezaron a recoger datos
sobre nacimientos y defunciones. En la actualidad, a este planteamiento se le
llama frecuencia relativa de presentación de un evento y define la
probabilidad como:
- La frecuencia relativa observada de un
evento durante un gran número de intentos, o
- La fracción de veces que un evento se
presenta a la larga, cuando las condiciones son estables.
Este
método utiliza la frecuencia relativa de las presentaciones pasadas de un
evento como una probabilidad. Determinamos qué tan frecuente ha sucedido algo
en el pasado y usamos esa cifra para predecir la probabilidad de que suceda de
nuevo en el futuro.
Cuando
utilizamos el planteamiento de frecuencia relativa para establecer
probabilidades, el número que obtenemos como probabilidad adquirirá mayor
precisión a medida que aumentan las observaciones.
Una
dificultad presente con este planteamiento es que la gente lo utiliza a menudo
sin evaluar el número suficiente de resultados.
Probabilidades
subjetivas.
Las
probabilidades subjetivas están basadas en las creencias de las personas que
efectúan la estimación de probabilidad. La probabilidad subjetiva se puede
definir como la probabilidad asignada a un evento por parte de un individuo,
basada en la evidencia que se tenga disponible. Esa evidencia puede presentarse
en forma de frecuencia relativa de presentación de eventos pasados o puede
tratarse simplemente de una creencia meditada.
Las
valoraciones subjetivas de la probabilidad permiten una más amplia flexibilidad
que los otros dos planteamientos. Los tomadores de decisiones puede hacer uso de cualquier evidencia que tengan a mano y
mezclarlas con los sentimientos personales sobre la situación.
Las
asignaciones de probabilidad subjetiva se dan con más frecuencia cuando los
eventos se presentan sólo una vez o un número muy reducido de veces.
Como
casi todas las decisiones sociales y administrativas de alto nivel se refieren
a situaciones específicas y únicas, los responsables de tomar decisiones hacen
un uso considerable de la probabilidad subjetiva.
Análisis de Correlación.
Es el conjunto de técnicas
estadísticas empleado para medir la intensidad de la asociación entre dos
variables.
El principal objetivo del análisis de correlación consiste en determinar que
tan intensa es la relación entre dos variables. Normalmente, el primer paso es
mostrar los datos en un diagrama de dispersión.
Al ajustar un modelo de regresión múltiple a
una nube de observaciones es importante disponer de alguna medida que permita
medir la bondad del ajuste. Esto se consigue con los coeficientes de
correlación múltiple.
Coeficiente de correlación
múltiple.
En el estudio de la recta de regresión se ha
definido el coeficiente de
correlación lineal simple (o de Pearson)
entre dos variables X
e Y, como
donde s![]() es la covarianza muestral entre las variables X e Y ; sX
y sY son las
desviaciones típicas muestrales de X e Y
, respectivamente.
es la covarianza muestral entre las variables X e Y ; sX
y sY son las
desviaciones típicas muestrales de X e Y
, respectivamente.
El
coeficiente de correlación lineal simple es una medida de la relación lineal existente entre las variables X
e Y.
En
general cuando se ajusta un modelo estadístico a una nube de puntos, una medida
de la bondad del ajuste es el coeficiente de
determinación, definido por
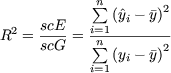
Si el modelo que se ajusta es un modelo de
regresión lineal múltiple, a R se le denomina coeficiente de
correlación múltiple y representa el
porcentaje de variabilidad de
Como scE < scG, se verifica que 0 < R2 <
1. Si R2
= 1 la relación lineal es exacta y si
R2 = 0 no existe relación lineal entre la
variable respuesta y las variables regresoras.
El coeficiente de correlación múltiple R es igual al coeficiente de correlación
lineal simple entre el vector variable
respuesta ![]() y el vector de predicciones
y el vector de predicciones ![]() ,
,
![]()
El coeficiente de correlación múltiple R presenta el inconveniente de aumentar
siempre que aumenta el número de variables regresoras, ya
que al aumentar k (número
de variables regresoras) disminuye la variabilidad no explicada, algunas veces de forma artificial lo
que puede ocasionar problemas de multicolinealidad. Si el número de observaciones n es pequeño, el coeficiente R2 es muy sensible a los
valores de n y k. En
particular, si n = k
+ 1 el modelo se
ajusta exactamente a las observaciones. Por ello y
con el fin de penalizar el número de variables regresoras
que se incluyen en el modelo de regresión, es
conveniente utilizar el coeficiente de determinación corregido por el
número de grados de libertad, ![]() 2. Este
coeficiente es similar al anterior, pero utiliza el cociente de varianzas en lugar del cociente de sumas de cuadrados. Para su
definición se tiene en cuenta que
2. Este
coeficiente es similar al anterior, pero utiliza el cociente de varianzas en lugar del cociente de sumas de cuadrados. Para su
definición se tiene en cuenta que
![]()
Cambiando
las sumas de cuadrados por varianzas se obtiene el coeficiente de determinación
corregido por el número de grados de libertad, ![]() 2, definido
como sigue
2, definido
como sigue
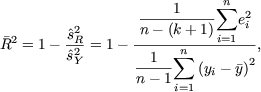
Ahora
es fácil deducir la siguiente relación entre los dos coeficientes de
determinación
También
es fácil relacionar el estadístico del contraste de regresión múltiple con el
coeficiente de determinación, obteniendo
Correlación Parcial
Sea
![]() un conjunto de variables aleatorias, el coeficiente de
correlación parcial entre Xi y Xj
es una medida de la relación lineal entre las variables Xi
y Xj una vez que se ha eliminado en ambas variables los efectos debidos al resto de
las variables del conjunto
un conjunto de variables aleatorias, el coeficiente de
correlación parcial entre Xi y Xj
es una medida de la relación lineal entre las variables Xi
y Xj una vez que se ha eliminado en ambas variables los efectos debidos al resto de
las variables del conjunto ![]() .
Al coeficiente de correlación parcial entre X1 y X2 se le denotará por r12·3...k·
.
Al coeficiente de correlación parcial entre X1 y X2 se le denotará por r12·3...k·
Para
una mejor interpretación de este concepto, considérese el conjunto de cuatro
variables ![]() , se desea
calcular el coeficiente de correlación parcial entre las variables X1 y X2. Para
ello, se procede de la siguiente forma,
, se desea
calcular el coeficiente de correlación parcial entre las variables X1 y X2. Para
ello, se procede de la siguiente forma,
- Se calcula la regresión lineal de X1 respecto de X3 y X4
![]()
donde e1·34 son los residuos del
ajuste lineal realizado.
- Se calcula la regresión lineal de X2 respecto de X3 y X4
X2![]()
donde e2.34 son los residuos del
ajuste lineal realizado.
- El coeficiente de correlación parcial
entre X1 y X2 es el coeficiente de correlación lineal simple entre las variables e1.34
y e2.34,
![]()
Por
tanto, el coeficiente de correlación lineal se define siempre dentro de un
conjunto de variables y no
tiene interpretación ni sentido si no se indica este
conjunto de variables.
Relación entre los
coeficientes de correlación.
Sea
el conjunto de variables ![]() ,
entonces se verifica la siguiente relación
entre los coeficientes de correlación lineal simple
y el coeficiente de correlación parcial,
,
entonces se verifica la siguiente relación
entre los coeficientes de correlación lineal simple
y el coeficiente de correlación parcial,
Cálculo del coeficiente
de correlación parcial.
En
un modelo de regresión múltiple
![]()
se puede calcular fácilmente el coeficiente de correlación parcial entre
la variable respuesta Y y una variable regresora Xi
controlado por el resto de variables regresoras.
Para ello se utiliza el estadístico del contraste
individual de la t respecto
a la variable Xi y que se definió
anteriormente como
![]()
obteniéndose la siguiente relación
donde C = ![]() el conjunto de índices de todas las variables regresoras
excepto el índice i.
el conjunto de índices de todas las variables regresoras
excepto el índice i.
- Coeficiente de
correlación de la muestra
Coeficiente de Correlación.-
Describe la intensidad de la relación entre
dos conjuntos de variables de nivel de intervalo. Es la medida de la intensidad
de la relación lineal entre dos variables.
El valor del coeficiente de correlación puede tomar valores desde menos uno
hasta uno, indicando que mientras más cercano a uno sea el valor del
coeficiente de correlación, en cualquier dirección, más fuerte será la
asociación lineal entre las dos variables. Mientras más cercano a cero sea el
coeficiente de correlación indicará que más débil es la asociación entre ambas
variables. Si es igual a cero se concluirá que no existe relación lineal alguna
entre ambas variables.
El
coeficiente de correlación (r) es una medida de la intensidad de la relación
entre dos variables.
Requiere datos con escala de intervalo o de razón (variables).
Puede tomar valores entre -1.00 y 1.00.
Valores de -1.00 o 1.00 indican correlación fuerte y perfecta.
Valores cercanos a 0.0 indican correlación débil.
Valores negativos indican una relación inversa y valores positivos indican una
relación directa.
Propiedades
del coeficiente de correlación
i) número sin dimensiones entre
-1 y 1.
ii) si las variables son independientes r=0. La inversa no es necesariamente
cierta, aunque si las variables son normales bivariantes
sí.
iii) si las variables estuvieran relacionadas linealmente r=1
Un
contraste que interesa realizar en un modelo II es H0: r=0. Como
![]()
este contraste es totalmente equivalente al realizado sobre dicho
coeficiente, aunque también hay tablas basadas en que una cierta transformación
(de Fisher) de r se distribuye aproximadamente
como una normal.
¿Qué
mide r?
Se
puede demostrar una relación algebraica entre r y el análisis de la
varianza de la regresión de tal modo que su cuadrado (coeficiente de
determinación) es la proporción de variación de la variable Y debida a
la regresión. En este sentido, r2 mide el poder
explicatorio del modelo lineal.
¿Qué
no mide r?
- no
mide la magnitud de la pendiente ("fuerza de la asociación")
-
tampoco mide lo apropiado del modelo lineal
- Coeficiente de
determinación y análisis de varianza en regresión lineal
Coeficiente de determinación. Coeficiente de correlación.
Una
vez ajustada la recta de regresión a la nube de observaciones es importante
disponer de una medida que mida la bondad del ajuste realizado y que permita
decidir si el ajuste lineal es suficiente o se deben buscar modelos
alternativos. Como medida de bondad del ajuste se utiliza el coeficiente de
determinación, definido como sigue
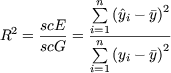
o bien
![]()
Como scE < scG, se verifica que 0 < R2
< 1.
El
coeficiente de determinación mide la proporción de variabilidad total de la
variable dependiente ![]() respecto
a su media que es explicada por el modelo de regresión. Es usual expresar esta
medida en tanto por ciento, multiplicándola por cien.
respecto
a su media que es explicada por el modelo de regresión. Es usual expresar esta
medida en tanto por ciento, multiplicándola por cien.
Análisis de varianza
El análisis de varianza (en
inglés ANOVA, ANalysis Of VAriance)
examina dos o más conjuntos de mediciones, especialmente sus varianzas, e
intenta detectar diferencias estadísticamente representativas entre los
conjuntos. Estos conjuntos podrían ser, por ejemplo, reacciones medidas para
dos grupos experimentales, y el investigador quiere examinar si hay una
diferencia en las reacciones, tal vez causada por los distintos estímulos a los
grupos.
El método de análisis de varianza se basa en el hecho matemáticamente probado
de que hay una diferencia entre los grupos sólo si la varianza inter-grupos es mayor que la varianza intra-grupo.
El
análisis se inicia calculando la varianza intra-grupo
para cada grupo, y la media de todas estas varianzas de grupo.
El siguiente paso es calcular la media para cada grupo, y entonces la varianza
de estas medias. Esa es la varianza inter-grupos.
Entonces calculamos la proporción de las dos cifras que acabamos de obtener,
que es llamada F. En otras palabras, = (varianza de las medias de grupo) /
(media de las varianzas de grupo).
Análisis de regresión
El investigador suele tener razones teóricas
o prácticas para creer que determinada variable es causalmente dependiente de
una o más variables distintas. Si hay bastantes datos empíricos sobre estas
variables, el análisis de regresión es un método apropiado para desvelar el
patrón exacto de esta asociación.
El algoritmo de análisis de regresión construye una ecuación, que tiene el
siguiente patrón. Además, da los parámetros a1, a2 etc. y b valores tales que
la ecuación corresponde a los valores empíricos con tanta precisión como es
posible.
y = a1x1 + a2x2 + a3x3 + ... + b
En la ecuación,
y = la variable dependiente
x1 , x2 etc. = variables independientes
a1 , a2 etc. = parámetros
b = coeficiente.
Si tenemos amplios datos con muchas variables, al principio del análisis no
estaremos tal vez seguros de qué variables están mutuamente conectadas y cuales
debieran así ser incluidas en la ecuación. Podríamos primero estudiar esto con
el análisis de correlación, o podemos dejar al programa de análisis de
regresión elegir las variables "correctas" (x1, x2 etc.) para la
ecuación. "Correctas" son aquellas variables que mejoran la exactitud
del ajuste entre la ecuación y los valores empíricos.
Modelo de regresión variable lineal
En el modelo de regresión variable lineal, una variable Y dependiente,
o “explicada, se relaciona con una variable X independiente, o “explicativa”, por la siguiente
expresión:
yi = α + βxi + ui,
donde α
y β son los parámetros de regresión desconocidos llamados coeficientes de regresión de población, y ui es el “trastorno”
al azar o residual.
Se designan las variables como dependientes o independientes, esto
se refiere al significado matemático o funcional de dependencia; no
implica dependencia estadística ni causa y efecto. Pero, finalmente, las tres
interpretaciones de dependencia serán abarcadas en el análisis de regresión.
La relación de dependencia lineal definida por yi = α + βxi + ui, consta de dos partes: la parte sistemática identificada por α + βxi y la parte estocástica identificada por ui. Esto recuerda que es un modelo probabilista,
en vez de determinista.
La naturaleza estocástica del modelo de regresión implica que el valor
de Y nunca puede ser predicho
exactamente como un caso determinista. La incertidumbre relativa a Y es atribuible a la presencia de ui, que, siendo una
variable aleatoria, imparte aleatoriedad a Y.
Ejemplo:
No se puede esperar que robles de la
misma edad (xi)
tengan la misma altura (yi),
debido a la influencia de fuerzas “causales”. Además de esta interpretación del
término casual como una aleatoriedad inherente a la conducta, tienen
mérito otros dos puntos de vista. A veces, surge ui por
la exclusión de otras variables explicativas importantes y relevantes en
el modelo. Esto conduce al análisis de regresión múltiple. En ocasiones,
el error de medición en Y es
la causa de ui.
En una aplicación particular del análisis de regresión, cualquiera de estas
razones podría ser la interpretación razonable de ui, o
cualquier par de estas razones, o las tres razones juntas.
Como una digresión, podría preguntarse cómo
se maneja el error de medición en X,
ahora que el error de medición en Y
ya se ha mencionado. La respuesta es que yi = α + βxi + ui, no permite error de medición en X. Pero hay otros modelos que lo permiten. A
pesar de esta limitación en yi = α + βxi + ui, sigue siendo un modelo muy útil.
Cualquiera que sea la forma en que se
interprete ui,
está claro que la completa especificación del modelo de regresión incluye
no solo la forma de la ecuación de regresión, sino también una expresión de
cómo son determinados los valores de la variable independiente y una especificación
de la distribución de ui,
por probabilidades. La especificación completa de lo que se llama modelo clásico de regresión lineal simple la hace el
siguiente conjunto de supuestos:
La variable independiente X es fija. El termino "fijo" está en contraste directo con la
noción de “estocástico". La expresión "valores fijos de X" significa que X tiene valores que son fijados (es decir,
escogidos o predeterminados) por el investigador. El supuesto
independiente-variable-fijo implica que para cada valor fijo de X, xi,
hay una distribución de valores Y
por probabilidades, llamada subpoblación
de Y.
El
termino "error" ui, asociado
con cada valor de X, xi es una variable
aleatoria cuya distribución de probabilidades se supone que es normal con E (ui) = 0. Este
supuesto implica que, en promedio, la parte sistemática de yi en la gráfica es α + βxi. En realidad, la expectativa condicional de yi dada xi
es simplemente
E(yi │xi) =
µyx = E(α + βxi + ui)
= α + e (xi) + 0
= α + βxi.
El resultado nuevamente obtenido se llama ecuación de regresión de población de Y
sobre X, que nos da el valor
medio de Y dado un valor fijo de X, y de ahí la notación µyx. En esta expresión, α es el valor media de Y cuando X = 0; β mide el cambio en el valor media de Y por cambio
unitario en el valor de X. En
E(yi
│xi) = µyx
= E(α
+ βxi + ui)
=
α
+ e (xi) + 0
=
α
+ βxi.
La variancia condicional de Y dada X se llama variancia de la regresión, representada
por σ2yx, Se
supone que esta medida es constante, cualquiera que sea el valor de X, y es
igual a la variancia de ui,
es decir, σu2.
Esto se puede comprobar. Ver gráfico (arriba), y para cualquier valor de X, tenemos
V = e[yi
– E(yi)]2
= E[α
+ βxi
+ ui – E (α + βxi
+ ui)]2
= E(α
+ βxi
+ ui – α
- βxi)2
= E(ui2)
= σ2ui =
σ2
El
supuesto de constancia de la variancia condicional es:
E(yi │xi) = µyx = E(α + βxi +
= α + e (xi) + 0
= α + βxi.
donde cada xi corresponde a una subpoblación de yi y donde V(yi │xi)
= σ2 para cualquiera i.
La variancia constante se representa por el ancho constante entre las
líneas de trazos. Esta propiedad se llama a veces homoscedasticidad,
cuyo significado se comprende mejor por la noción de heteroscedasticidad
cuando V(yi │xi) varía
según la escala de valores de X. Heteroscedasticidad es observada a menudo en datos en los
que, por ejemplo, las variaciones en las alturas de árboles podrían disminuir
con aumentos en las edades de los árboles E(yi │xi) = µyx = E(α + βxi + ui)
= α + e (xi) + 0
= α
+ βxi.
o donde las variaciones en el gasto para
consumo son mayores al aumentar el nivel del ingreso (figura c)
ui es estadísticamente independiente de xi ,
como podría esperarse, porque cada valor de ui
es una muestra al azar simple de tamaño uno y de una población normal con media
cero y desviación estándar σ. El subíndice de ui
puede eliminarse si se desea.
Con los supuestos anteriores,
pueden derivarse estimadores para los parámetros de regresión desconocidos y
pueden hacerse inferencias con estos estimadores. Pero debe subrayarse aquí que
uno o más de estos supuestos básicos son a menudo violados en la práctica. En
particular, el incumplimiento del primer supuesto de que X sea no
estocástica no es crucial; pueden obtenerse aun útiles resultados cuando X es una variable aleatoria. Si ui no es
independiente de si misma, se dice que los términos de error están autocorrelacionados. Si el supuesto de variancia constante
es violado, se dice que los términos de error son heteroscedásticos.
Si E (ui) ≠ 0 para algunos valores de X, tenemos realmente regresión no lineal, porque
entonces la línea de regresión de la población no es una línea recta, sino una
línea curva o una línea recta cortada o algo diferente de una línea recta
ordinaria. Si ui
no está normalmente distribuida, los estimadores derivados del supuesto de
normalidad no tendrán necesariamente las propiedades que tienen cuando ui, esta
normalmente distribuida, y puede ser muy difícil descubrir qué propiedades
tienen los estimadores cuando ui
no es normal. Las faltas leves en satisfacer todos estos supuestos no son
particularmente importantes, pero las faltas fuertes si lo son. Es buena
práctica comprobar los datos de la muestra por lo menos rápidamente para ver si
cada uno de los supuestos es razonable para dicha muestra. Una porción
importante de la teoría econométrica se relaciona con problemas de estimación
de coeficientes de regresión cuando uno o mas de estos
supuestos es violado.
Técnicas de regresión: Regresión Lineal Múltiple
La
mayoría de los estudios clínicos conllevan la obtención de datos en un número
más o menos extenso de variables. En algunos casos el análisis de dicha
información se lleva a cabo centrando la atención en pequeños subconjuntos de
las variables recogidas utilizando para ello análisis sencillos que involucran
únicamente técnicas bivariadas. Un análisis
apropiado, sin embargo, debe tener en consideración toda la información
recogida o de interés para el clínico y requiere de técnicas estadísticas multivariantes más complejas. En particular, hemos visto
como el modelo de regresión lineal simple es un método sencillo para analizar
la relación lineal entre dos variables cuantitativas. Sin embargo, en la
mayoría de los casos lo que se pretende es predecir una respuesta en función de
un conjunto más amplio de variables, siendo necesario considerar el modelo de
regresión lineal múltiple como una extensión de la recta de regresión que
permite la inclusión de un número mayor de variables.
ESTIMACIÓN DE PARÁMETROS Y BONDAD DE AJUSTE.
Generalizando
la notación usada para el modelo de regresión lineal simple, disponemos en n
individuos de los datos ![]() de una
variable respuesta Y y de p variables explicativas X1,X2,...,Xp. La situación más sencilla
que extiende el caso de una única variable regresora
es aquella en la que se dispone de información en dos variables adicionales.
Como ejemplo, tomemos la medida de la tensión arterial diastólica en setenta
individuos de los que se conoce además su edad, colesterol e índice de masa
corporal (Tabla
1). Es bien conocido que el valor de la tensión arterial diastólica varía
en función del colesterol e índice de masa corporal de cada sujeto. Al igual
que ocurría en el caso bidimensional, se puede visualizar la relación entre las
tres variables en un gráfico de dispersión, de modo que la técnica de regresión
lineal múltiple proporcionaría el plano que mejor ajusta a la nube de puntos
resultante (Figura
1).
de una
variable respuesta Y y de p variables explicativas X1,X2,...,Xp. La situación más sencilla
que extiende el caso de una única variable regresora
es aquella en la que se dispone de información en dos variables adicionales.
Como ejemplo, tomemos la medida de la tensión arterial diastólica en setenta
individuos de los que se conoce además su edad, colesterol e índice de masa
corporal (Tabla
1). Es bien conocido que el valor de la tensión arterial diastólica varía
en función del colesterol e índice de masa corporal de cada sujeto. Al igual
que ocurría en el caso bidimensional, se puede visualizar la relación entre las
tres variables en un gráfico de dispersión, de modo que la técnica de regresión
lineal múltiple proporcionaría el plano que mejor ajusta a la nube de puntos
resultante (Figura
1).
|
Figura 1. Plano de regresión
para la Tensión Arterial Diastólica ajuntando por Colesterol e Índice de Masa
Corporal |
|
|

Del
gráfico se deduce fácilmente que los pacientes con tensión arterial diastólica
más alta son aquellos con valores mayores de colesterol e índice de masa
corporal. Si el número de variables explicativas aumenta (p>2) la
representación gráfica ya no es factible, pero el resultado de la regresión se
generaliza al caso del mejor hiperplano que ajusta a
los datos en el espacio (p+1)-dimensional correspondiente.
- Prueba F sobre Beta
Es propósito de
todo investigador que realiza un análisis de variancia de un experimento en
particular, realizar la prueba sobre el efecto de los tratamientos en estudio,
para ello hace uso de la prueba F el
cual indicará si los efectos de todos los tratamientos son iguales o
diferentes; en caso de aceptar la hipótesis de que todos los tratamientos no
tienen el mismo efecto, entonces es necesario realizar pruebas de comparación
de promedios a fin de saber entre que tratamientos hay diferencias, y para esto
es necesario realizar pruebas de comparación múltiple como la siguiente:
Diferencia
Significativa Mínima (DLS): Es una prueba para comparar dos medias y su uso en
comparaciones simultáneas se justifica sólo en las siguientes condiciones:
a. La prueba F
resulta significativa.
b. Las
comparaciones fueron planeadas antes de ejecutar el experimento.
La distribución Beta
Distribución que permite generar una gran variedad de perfiles. Se ha
utilizado para representar variables físicas cuyos valores se encuentran
restringidos a un intervalo de longitud finita y para encontrar ciertas
cantidades conocen como límites de tolerancia sin necesidad de la hipótesis de
una distribución normal, Además, la distribución beta juega un gran papel en la
estadística.
Se dice que una variable aleatoria X posee una distribución beta si su
función de densidad de probabilidad está dada por:
{r(a + {3) x"-l(l -X)13-1 O
< x <
f(x; a, {3) = r(a)r({3) , , , (5.31)
o. para cualquier otro valor
s cantidades a y {3 de la distribución beta son, ambas, parámetros de
perfil. es distintos de a y {3 darán distintos perfiles para la función de
densidad beta.
to a como {3 son menores que uno, la
distribución beta tiene un perfil en for- u. Si a < I y {3 ~ I, la
distribución ti~ne un perfil de J transpuesta, y si
I ya ~ 1, el perfil es una J. Cuando tanto a y {3 son ambos mayores que
uno, Jibución presenta un pico en x = (a -I)/(a
+ {3 -2), Finalmente, la ución beta es simétrica
cuando a = {3. En la figura 5.6 se encuentran ilustra- tos perfiles para
valores específicos de a y {3. Nótese que si en (5,31) x se reem- por x -I, se obtiene la siguiente relación de
simetría
f(1 -x; {3, a) = f(x; a, {3) (5.32) nombre de esta distribución proviene
de su asociación con la función beta que entra definida por B(a, {3) = Jol x"-l(l -x)13-1dx, (5.33) Demostrarse que
las funciones beta y gama se encuentran relacionadas por la expresión B(a, {3)
= ~. (534) r(a +{3}
- Coeficiente de correlación
por calificación
“Coeficiente de
correlación de los rangos de Spearman x Coeficiente de correlación por calificación.*
Este coeficiente
es una medida de asociación lineal que utiliza los rangos, números de orden, de
cada grupo de sujetos y compara dichos rangos. Existen dos métodos para
calcular el coeficiente de correlación de los rangos uno señalado por Spearman y otro por Kendall (8).
El r de Spearman llamado también rho
de Spearman es más fácil de calcular que el de Kendall. El coeficiente de correlación de Spearman es exactamente el mismo que el coeficiente de
correlación de Pearson calculado sobre el rango de
observaciones. En definitiva la correlación estimada entre X e Y se halla
calculado el coeficiente de correlación de Pearson
para el conjunto de rangos apareados. El coeficiente de correlación de Spearman es recomendable utilizarlo cuando los datos
presentan valores externos ya que dichos valores afectan mucho el coeficiente
de correlación de Pearson, o ante distribuciones no
normales.
El cálculo del
coeficiente viene dado por:
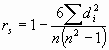
en donde di = rxi
– ryi es la diferencia entre
los rangos de X e Y.
Los valores de los
rangos se colocan según el orden numérico de los datos de la variable.
Ejemplo: Se
realiza un estudio para determinar la asociación entre la concentración de
nicotina en sangre de un individuo y el contenido en nicotina de un cigarrillo
(los valores de los rangos están entre paréntesis)
(2).
|
X |
Y |
|
Concentración
de Nicotina en sangre |
Contenido de
Nicotina por cigarrillo |
|
185.7 (2) |
1.51 (8) |
|
197.3 (5) |
0.96 (3) |
|
204.2 (8) |
1.21 (6) |
|
199.9 (7) |
1.66 (10) |
|
199.1 (6) |
1.11 (4) |
|
192.8 (6) |
0.84 (2) |
|
207.4 (9) |
1.14 (5) |
|
183.0 (1) |
1.28 (7) |
|
234.1 (10) |
1.53 (9) |
|
196.5 (4) |
0.76 (1) |
Si existiesen
valores coincidentes se pondría el promedio de los rangos que hubiesen sido
asignado si no hubiese coincidencias. Por ejemplo si en una de las variables X
tenemos:
|
X (edad) |
(Los rangos
serían) |
|
23 |
1.5 |
|
23 |
1.5 |
|
27 |
3.5 |
|
27 |
3.5 |
|
39 |
5 |
|
41 |
6 |
|
45 |
7 |
|
... |
... |
Para el cálculo
del ejemplo anterior de nicotina (2) obtendríamos el siguiente resultado:
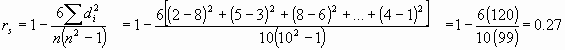
Si utilizamos la
fórmula para calcular el coeficiente de correlación de Pearson
de los rangos obtendríamos el mismo resultado
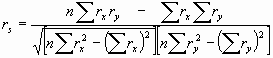
![]()
![]()
![]()
La interpretación
del coeficiente rs de Spearman es similar a ![]() tiene el
mismo significado que el coeficiente de determinación de r2.
tiene el
mismo significado que el coeficiente de determinación de r2.
La distribución de
rs es similar a la r por tanto el calculo
de los intervalos de confianza de rs se
pueden realizar utilizando la misma metodología previamente explicada para el
coeficiente de correlación de Pearson.
- Conclusiones
La estadística es comúnmente
considerada como una colección de hechos numéricos expresados en términos de
una relación sumisa, y que han sido recopilados a partir de otros datos numéricos.
El análisis
de correlación es el conjunto de técnicas estadísticas empleado para medir la
intensidad de la asociación entre dos variables. El principal objetivo del
análisis de correlación consiste en determinar que
tan intensa es la relación entre dos variables. Normalmente, el primer paso es
mostrar los datos en un diagrama
de dispersión. Diagrama de
Dispersión es aquel grafico que representa la relación entre dos
variables. Variable Dependiente.
es la variable que se predice o calcula. Cuya
representación es "Y" Variable
Independiente es la variable que proporciona las bases para el
calculo. Cuya representación es: X1,X2,X3.
Coeficiente de Correlación
describe la intensidad de la relación entre dos conjuntos de variables de nivel
de intervalo. Es la medida de la intensidad de la relación lineal entre dos
variables.
El valor del coeficiente de correlación puede tomar valores desde menos uno hasta uno,
indicando que mientras más cercano a uno sea el valor del coeficiente de correlación, en cualquier dirección,
más fuerte será la asociación lineal entre las dos variables. Mientras
más cercano a cero sea el coeficiente de correlación
indicará que más débil es la asociación entre ambas variables. Si es igual a
cero se concluirá que no existe relación lineal alguna entre ambas variables. Análisis de Correlación
es el conjunto de técnicas
estadísticas empleado para medir la intensidad de la asociación entre dos
variables. El principal objetivo del análisis de correlación
consiste en determinar que tan intensa es la relación entre dos variables.
Normalmente, el primer paso es mostrar los datos en un diagrama
de dispersión. Mientras más cercano a
cero sea el coeficiente de correlación indicará que
más débil es la asociación entre ambas variables. Si es igual a cero se
concluirá que no existe relación lineal alguna entre ambas variables
Infografía y Bibliografía.
http://www.eumed.net/cursecon/medir/estima.htm
http://www.monografias.com/trabajos30/regresion-correlacion/regresion-correlacion.shtml
http://www.udc.es/dep/mate/estadistica2/sec6_3.html
http://es.wikipedia.org/wiki/Probabilidad
http://ciberconta.unizar.es/LECCION/probabil/100.HTM
http://www.southlink.com.ar/vap/PROBABILIDAD.htm
http://e-stadistica.bio.ucm.es/mod_regresion/regresion_3.html
http://tarwi.lamolina.edu.pe/~ivans/aspgen.pdf
http://e-stadistica.bio.ucm.es/glosario/coef_corre.html
http://taller1.fisica.edu.uy/todo2006.pdf
http://www.fisterra.com/mbe/investiga/var_cuantitativas/var_cuantitativas.htm