
Spanish Banner: Intercambio de Enlaces.
| DISTRIBUCIONES DE FRECUENCIAS 2 : MEDIDAS DE RESUMEN |
| TEMAS RELACIONADOS | |||
|
|
|
| Para describir
un conjunto de datos, además de la tabulación y la representación
gráfica , se utilizan valores numéricos de funciones de la variable
llamadas medidas de resumen
Las medidas de resumen aportan la información acerca de valores centrales, la dispersión y la forma de la distribución |
| Aquellas medidas de resumen utilizadas para describir valores centrales se llaman Medidas de tendencia central |
| MEDIDAS
DE TENDENCIA CENTRAL Para saber cuál medida de tendencia central utilizar, se debe tener en cuenta: la escala de medida y la forma de la distribución |
||||
| MEDIA | MEDIANA | MODA | ||
| ARITMÉTICA | ARMÓNICA | GEOMÉTRICA |
Es
útil sobretodo cuando : |
La moda se
utiliza solamente cuando el investigador tenga interés en conocer el
valor más frecuente |
|
es
la más utilizada, por su facilidad de cálculo, en muestras grandes es
estable, fácil de entender y es de fácil uso en cálculos posteriores |
Es de poco uso en biología. No se va a ver aquí |
Es útil en en general en aquellos casos donde el logaritmo de la variable en estudio tiene distribución normal. |
||
| MEDIA ARITMÉTICA |
| Si consideramos las frecuencias relativas como pesos aplicados en el eje de las abscisas, el centro de gravedad es decir el punto de aplicación de la resultante de la distribución , se encontrará en la media aritmética o simplemente MEDIA |  |
||
| La Media de una muestra se define por la fórmula: | |||
|
|
|||
| En tablas de datos sin agrupar |
En tablas de datos agrupados |
||||||||||||||||||||||||||||||||
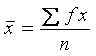 |
|
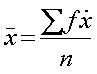 |
|
||||||||||||||||||||||||||||||
| En este caso se usa el punto medio o marca de clase | |||||||||||||||||||||||||||||||||
| media
= 3x1 + 6x8 + 9x15 + 12x4 = 8.35 28 |
media
= 3x2 + 5x9 + 7x10 + 9x1 = 5.90 22 |
||||||||||||||||||||||||||||||||
| Cuando
los datos están agrupados en clases se produce una pérdida de
información que puede traducirse en pequeños errores en el verdadero
valor de la media, por esa razón cuando es posible conviene
promediar los valores de la tabla de frecuencias sin agrupar , o
bien los valores individuales tomados de 1 en 1 .
Por ejemplo la media de { 5, 7, 8, 8, 9, 11 }
|
| MEDIANA |
| Otra medida de tendencia central utilizada comúnmente es la Mediana . |
| Recordemos que la mediana es el valor que deja por debajo y por encima de él el mismo número de observaciones , es el percentil 50 |
| En una lista estadística ordenada, con los datos sin agrupar : | |
| número de observaciones es impar, la mediana corresponde al valor central | el número de observaciones es par, la mediana corresponde al promedio entre los dos valores centrales |
|
|
|
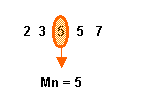
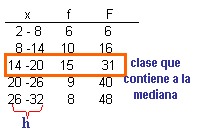
| Cuando los datos están agrupados, para calcular la mediana se requieren las frecuencias acumuladas | ||
| Pasos a seguir | ||
| a.-
Se determina la
clase que contiene la observación de orden (n+1)/2 que corresponde a la
clase mediana
(48+1)/2 = 24.5 (la mediana está entre los valores de las observaciones 24º y 25º) |
b.- la mediana se calcula de acuerdo a la fórmula | |
|
|
||
 |
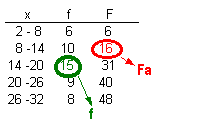 |
donde: li : límite inferior de la clase mediana ( en este caso li = 14) Fa : frecuencia acumulada de la clase anterior a la clase mediana (16) f : frecuencia absoluta de la clase mediana(15) h : amplitud o extensión del intervalo de clase (6) |
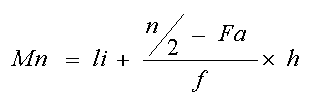
|
|
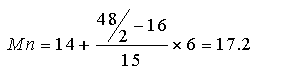
| Forma gráfica de calcular la mediana |
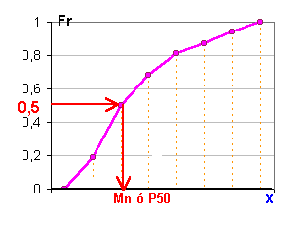 |
A partir de un gráfico de Fr (frecuencias relativas acumuladas), se traza a la altura de 0.5 (o 50%) una línea paralela al eje de la variable, en el punto de corte, se traza una perpendicular. El valor resultante en el eje de las x , ese será la mediana. |
| MODA |
| Una tercera medida es la Moda, o sea el valor más frecuente. |
| Cuando los datos están sin agrupar | ||||||||||
| La moda se determina por la simple inspección de la lista ordenada |
|
|||||||||
| Cuando los datos están agrupados una buena aproximación de la moda se consigue con la fórmula de Czuber |
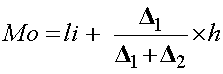 |
donde: li: límite inferior de la clase modal D1: diferencia entre la frecuencia de la clase modal y la clase anterior a ella D2:diferencia entre la clase modal y la clase siguiente a ella h: extensión del intervalo |
 |
|
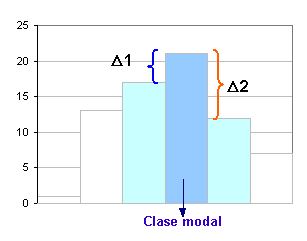
D1:
21 - 17 = 4 D2: 21 - 12 = 9 Mo = 15 +
4 x 5 = 16.54 |
| MEDIDAS DE DISPERSIÓN | ||||||
| AMPLITUD TOTAL A |
La
más inmediata medida de dispersión es la Amplitud total (rango,
recorrido o intervalo) La amplitud total (A) es la diferencia entre el límite real superior y el límite real inferior de la distribución ej: { 2, 5,
6, 6, 11 } en esta distribución la amplitud A = 11.5 -1.5 =10 |
|||||
| SEMIRRECORRIDO
INTERCUARTILICO
Q |
Semirrecorrido intercuartílico (Q) es la diferencia entre el percentil 75 (P75) y percentil 25 (P25) dividido 2. | 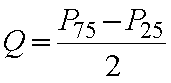 |
||||
Percentil
de orden r
es aquel valor que deja un r% de observaciones por debajo de él .
Por ejemplo la mediana, que deja el 50% de las observaciones por debajo de
el es el percentil 50 ( mediana)
|
||||||
| VARIANZA
Y DESVIACIÓN TÍPICA s2 s |
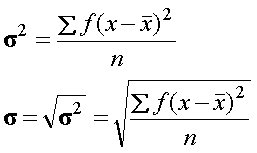
la varianza y la desviación típica también se designan, en muestras, con la letra s2 y s respectivamente |
La varianza es el promedio del cuadrado delos desvíos con respecto a la media |
||||
|
|
Como la varianza está expresada en cuadrados de las unidades empleadas en la distribución su interpretación se hace difícil, por lo tanto en la práctica se usa como medida de dispersión la raíz cuadrada positiva de la varianza, llamada desviación típica | |||||
| COEFICIENTE
DE VARIACIÓN
CV |
En algunas aplicaciones, más que la dispersión absoluta, interesa la dispersión relativa. En esos casos suele usarse el coeficiente de variación | |||||
| El
CV puede expresarse también en porcentaje
Ej: media = 3; |
|
|||||
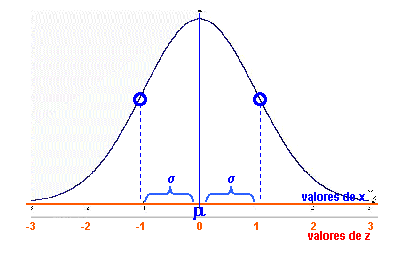
| DESVIO
TIPIFICADO
Z
ver distribución normal |
El desvío tipificado de un valor x se define como : | |||||
|
|
|
|||||
 |
||||||
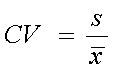
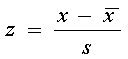
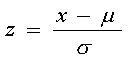
| CUAL MEDIDA DE DISPERSIÓN USAR | ||||||||
|
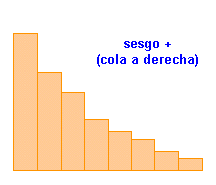
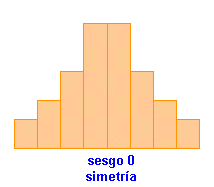
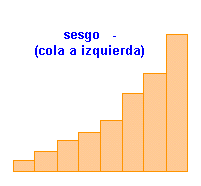
| MEDIDAS DE ASIMETRIA O SESGO | |||||||||
|
|||||||||
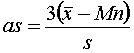
 |
 |
 |
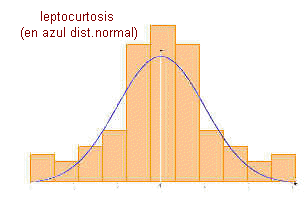
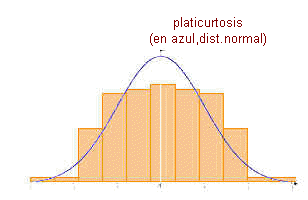
| MEDIDAS DE APUNTAMIENTO O KURTOSIS |
|
|||||||
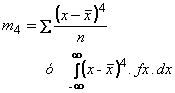
|
Tus sugerencias - Página principal -