
Ho: There is no difference in the performance in English and Mathematics
and there would then be an alternative hypothesis:
Ha: There is a difference.
Now the simple computation of averages may highlight the fact that one average is higher than the other, but this is not sufficient proof that there is a difference. Thus, as it stands, there is no evidence to suggest that we should discount the Null hypothesis. If the analysis does reveal that there is a significant difference, then we can say that we have evidence to suggest that there is significant difference between the performance in English and Mathematics.
To apply the correct analysis, we need to unerstand the data. We have two scores for each of three students. Thus, we have "paired data". If this were not the case, we would have "independent" samples. Again, in this part of the research project, the creation of these test statistics is a bugbear. Again, we have tested methods which can be applied and you can do much of the data analysis in the very commonly available Microsoft Excel. Thus, there is no need to sit for hours and do these computations. There is also no need to understand the complexities of the statistical test for there are simple indicators which we can use to arrive at the conclusions we want. Once, I can make sense of the data in relation to the designof the experiment, I can perform the analysis in a matter of minutes on Minitab and supply the reults and the statistical interpretation of the results. It would be then up to you to come up with the interpretation and the reasoning for either discounting or supporting the hypotheses put forward and for making the required recopmmendations. The mathematical computational process is not an examinable part of a research project. it is just a matter of getting it done, and I can help in that regard.
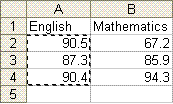
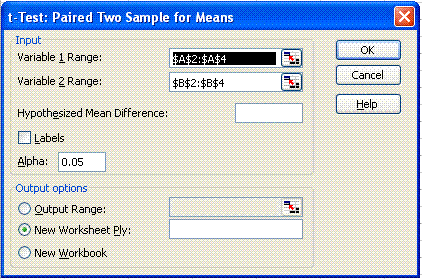
Consider the data we have at hand (Test Data 1), even though the averages give us: English = 89.40 and Mathematics = 82.47,and it is clear that the performance in English is "better" tahn that in Mathematics, we cannot conclude that the Null Hypothesis must be discounted as this may have been a fluke occasion. To see this, load the data into a Microsoft Excel spreadsheet as shown in Example 1. Now in the Data Analysis window, use Tools > Data Analysis > and from the Data Analysis box select "t-test: Paired Two Sample for Means". For variable 1 range enter $A$2:$A$4, and for variable 2 enter $B$2:$B$4 as shown in the diagram. Excel will then compute the statistics for you. All that is required is to know what to look for where. Examine the Data Analysis done for you by Microsoft Excel. The critical statistic here is that on line 13, which saya P(T<=t). This gives the P value for the two tailed test. Note the value 0.49. This means that there is a 49% chance or probability that these data will result based on the Null Hypothesis. Statistically, there is no evidence to suggest that we can discount the Null Hypothesis.
{kind=link}
{kind=link}
One of the ways of correcting this problem is to get a bigger sample. If we increased the sample size to say 26 (Test data 2), and repeated the test, then we just may get that result based on the paired t-test. Repeat the test using test data 2, and observe the results The P value is now less that .001. In this case we can conclude that there is evidence to suggest that Null Hypothesis should be discounted and that we should accept the alternative hypothesis. Thus, we conclude that there is a difference in the performance. Normally, 30 and above is a respectable sample size, without going through all the rigours of an optimal sample size from a statistical analysis). Now that you have an understanding of this type of design and analysis, you could look around to see what else you could subject to this type of analysis.
Clearly, the various design features of the experiments will necesitate different types of statistical analysis. I hope that I have manageed to convince you that data analysis is not raelly that hard after all. The programs do it all for you. The other design featured in the initial article necesitates a complex ANOVA analysis, bu again once this has been done, the researcher just needs to know whether there is sufficient evidence to support or reject the Null Hypothesis.
I will deal with the ANOVA analysis in the next article. Once the statististics reveals this, the experimenter then looks for reasons for this and trys to come up with some explanation. how does this now shed light on the original problem? At this point the experimenter must rely on his expertise in the fieldl to theorise on the problem and come up with recommendations and suggestions.