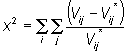 (6.1)
(6.1)As características de demanda e tipo de linhas diferem entre as duas cidades. Curitiba é uma cidade com cerca de um milhão e trezentos mil habitantes e tem uma demanda caracterizada por dois picos: manhã e tarde. As linhas referentes a Curitiba são diametrais, ligando dois bairros distintos passando pelo centro da cidade.
Paranaguá situa-se na faixa de cento e vinte mil habitantes e apresenta uma demanda com três picos: manhã, meio do dia e tarde. As linhas de Paranaguá são radiais ligando bairros ao centro da cidade.
Foram realizadas duas simulações para
cada conjunto de dados de uma linha. Primeiramente considerando pontos
de parada de forma desagregada e em seguida com pontos de parada agregados.
6.2 - Avaliação do desempenho do modelo
Existem diversos métodos estatísticos
para avaliar o desempenho de modelos gravitacionais que estimam matrizes
O/D (ver por exemplo SMITH & HUTCHINSON, 1981; WILSON, 1976; FURTH
& NAVICK, 1993a). Os testes estatísticos propostos são
medidas de similaridade e medem a proximidade da matriz observada com a
matriz estimada. Os testes estatísticos utilizados neste trabalho
são o Chi-quadrado, Phi-normalizado e o Índice de dissimilaridade.
Segundo WILSON (1976), o teste chi-quadrado é um teste estatístico padrão usado na avaliação de modelos de gravidade para testar as freqüências observadas (pesquisadas) e as freqüências esperadas (estimadas).
SMITH & HUTCHINSON (1981) consideram o chi-quadrado como uma estatística muito suscetível, porém segundo esses autores, existe algumas dificuldades em seu uso. Para esses autores, valores menores que seis requerem agregação de entrada de matrizes e não existe um método consistente para se fazer isto. COCHRAN6. apud CONOVER (1980) sugere que nenhum dos valores de entrada deveria ser menor que 1 e não mais que 20% deveria ser menor que 5. Estudos mais recentes indicam que esta regra pode ser ainda mais relaxada (CONOVER, 1980).
O chi-quadrado é definido como:
(6.1)Vij* = matriz O/D observada;
Vij = matriz O/D estimada;
V = número total de viagens.
6.2.2 - Índice de dissimilaridade
Segundo GONÇALVES e ULYSSÉA NETO (1993), o índice de dissimilaridade mede a porcentagem de viagens que podem ser realocadas entre pares (i, j), para que a matriz observada coincida com a matriz estimada. O índice de dissimilaridade é dado por:
6.2.3 - Estatística phi-normalizada
Esta estatística é baseada na Teoria da Informação e segundo SMITH e HUTCHINSON (1981), a estatística phi-normalizada mostra-se adequada para a avaliação de modelos de distribuição de viagens. GONÇALVES e ULYSSÉA NETO (1993) definem a estatística phi-normalizada por:
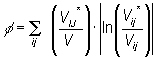 (6.3)
(6.3)As células das matrizes desagregadas observadas e simuladas representam o número de passageiros em cada par origem-destino, enquanto que, nas matrizes agregadas, cada célula da matriz representa a soma do conjunto de passageiros de diversos pontos de parada.
Devido ao elevado número de pontos de parada
em cada linha de transporte público urbano, as matrizes O/D apresentam
valores iguais a zero em grande parte de suas células. Isto ocorre
porque geralmente não existem mais que 120 embarques por viagem,
porém o número de pares origem-destino (O/D) por linha é
cerca de algumas dezenas. Para linhas onde existem 30 pontos de parada,
os números de pares O/D possíveis são
0,5 . 29 . 30 = 435. Como
resultado, o número de passageiros esperado para a maioria dos pares
O/D será muito baixo e, muitas das células da matriz conterão
zeros.
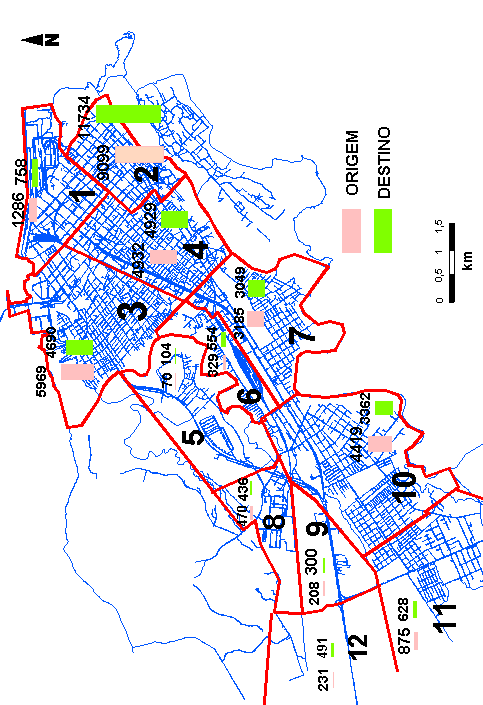
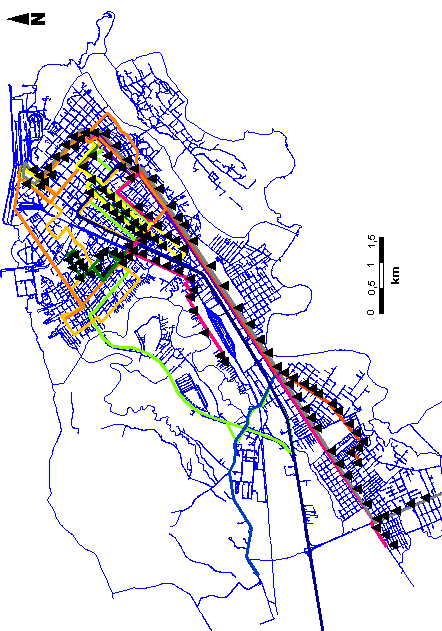
Cada linha analisada em Paranaguá teve seus pontos de parada agregados. A agregação de pontos levou em conta as características sócioeconômicas, zoneamento da cidade, total de viagens com origem e destino de cada zona, barreiras físicas e distância de caminhada entre pontos (figura 6.1). Levando em consideração as referências contidas no item 2.3.3, procurou-se agregar pontos de parada de modo que a soma das distâncias entre pontos fosse em torno de 800 metros.
A figura 6.2 mostra as linhas de transporte coletivo e os pontos de parada correspondentes a cada linha.
Na cidade de Paranaguá as distâncias entre pontos nas zonas coletoras (bairros) muitas vezes não excedem a 150 m e muitas vezes os itinerários são circulares dentro bairro. Desta forma, procurou-se agregar em média de 3 a 5 pontos de parada, sempre respeitando os zoneamentos, e características sócioeconômicas. O mesmo procedimento foi realizado para as zonas de penetração e de destino (centro da cidade).
Em Curitiba, onde as linhas simuladas são
diametrais, a agregação ocorreu da mesma forma como em Paranaguá.
Agregou-se os pontos de parada das zonas coletoras (bairro), zonas de penetração,
zona central (centro da cidade), zona de penetração e zona
de destino (bairro).
A tabela 6.2 apresenta os valores do teste estatístico x2 estimado e o valor crítico do x2 para as linhas de transporte público por ônibus de Curitiba e Paranaguá. São apresentados resultados para linhas de transporte sem agregação de pontos de parada e com agregação pontos de parada.
As linhas pertencentes a cidade de Curitiba são; Água Verde e Taboão. As demais linhas fazem parte do conjunto de linhas da cidade de Paranaguá. As matrizes referentes aos dados de pesquisa do tipo "Santinho", ou seja, as matrizes reais e as matrizes estimadas através do método proposto encontram-se no Apêndice.
Tabela 6.1 - Valores de f
, X2 e ID estimados com pontos de parada desagregados e agregados
| LINHA |
agregado |
desagregado |
agregado |
desagregado |
agregado |
desagregado |
| Água Verde |
|
|
|
|
|
|
| Água Verde 1 |
|
|
|
|
|
|
| Água Verde 2 |
|
|
|
|
|
|
| Água Verde 3 |
|
|
|
|
|
|
| Água Verde 4 |
|
|
|
|
|
|
| Água Verde 5 |
|
|
|
|
|
|
| Taboão |
|
|
|
|
|
|
| Taboão 1 |
|
|
|
|
|
|
| Taboão 2 |
|
|
|
|
|
|
| Taboão 3 |
|
|
|
|
|
|
| Taboão 4 |
|
|
|
|
|
|
| Samambaia |
|
|
|
|
|
|
| Samambaia 1 |
|
|
|
|
|
|
| Samambaia 2 |
|
|
|
|
|
|
| Divinéia |
|
|
|
|
|
|
| Divinéia 1 |
|
|
|
|
|
|
| Horizonte |
|
|
|
|
|
|
| Horizonte 1 |
|
|
|
|
|
|
| Horizonte 2 |
|
|
|
|
|
|
| Primavera |
|
|
|
|
|
|
| Primavera 1 |
|
|
|
|
|
|
| Populares |
|
|
|
|
|
|
| Populares 1 |
|
|
|
|
|
|
| Vila Garcia |
|
|
|
|
|
|
| Vila Garcia 1 |
|
|
|
|
|
|
| Vila Garcia 2 |
|
|
|
|
|
|
| Vila Garcia 3 |
|
|
|
|
|
|
Tabela 6.2 - Valores de X2 simulados e
tabelados a =(0,05)
| LINHA |
agregado |
agregado |
desagregado |
desagregado |
| Água Verde |
|
|
|
|
| Água Verde 1 |
|
|
|
|
| Água Verde 2 |
|
|
|
|
| Água Verde 3 |
|
|
|
|
| Água Verde 4 |
|
|
|
|
| Água Verde 5 |
|
|
|
|
| Taboão |
|
|
|
|
| Taboão 1 |
|
|
|
|
| Taboão 2 |
|
|
|
|
| Taboão 3 |
|
|
|
|
| Taboão 4 |
|
|
|
|
| Samambaia |
|
|
|
|
| Samambaia 1 |
|
|
|
|
| Samambaia 2 |
|
|
|
|
| Divinéia |
|
|
|
|
| Divinéia 1 |
|
|
|
|
| Horizonte |
|
|
|
|
| Horizonte 1 |
|
|
|
|
| Horizonte 2 |
|
|
|
|
| Primavera |
|
|
|
|
| Primavera 1 |
|
|
|
|
| Populares |
|
|
|
|
| Populares 1 |
|
|
|
|
| Vila Garcia |
|
|
|
|
| Vila Garcia 1 |
|
|
|
|
| Vila Garcia 2 |
|
|
|
|
| Vila Garcia 3 |
|
|
|
|
Os resultados da estatística x2 para simulações de matrizes com pontos de parada desagregados mostram que os valores são menores que os valores críticos em 26 das 27 simulações, ou seja, para o nível de significância desejado, as freqüências estimadas não diferem estatisticamente das freqüências observadas na grande maioria das simulações e, as diferenças entre as freqüências observadas e estimadas, nestes casos, podem ser atribuídas ao acaso.
Quando os pontos de parada são agregados, os valores da estatística x2 para todas as linhas simuladas são menores que os valores críticos, conseqüentemente as freqüências estimadas não diferem estatisticamente das freqüências observadas e, as diferenças entre os valores observados e estimados podem ser atribuídas ao acaso para todas as linhas simuladas.
Os resultados listados na tabela 6.1 apresentam os valores dos testes f e ID para linhas com pontos de parada agregados e pontos de parada desagregados. Os maiores valores de f e ID correspondem às piores estimativas e os menores valores correspondem as melhores estimativas, respectivamente.
Os valores extremos (máximos e mínimos) para o teste f para todas as simulações foram de 0,0 e 1,9 para pontos desagregados e 0,0 e 0,68 para pontos agregados, enquanto que o teste ID apresentou resultados de 0,0 e 86,8 para pontos desagregados e 0,0 e 57,9 para pontos agregados.
O valor 0,0 encontrado na linha Populares 1 para os testes x2, f e ID pode ser devido ao baixo número passageiros na amostra estimada (4 passageiros) e a ausência de pontos coincidentes de embarque e desembarque. A ausência de pontos de embarque e desembarque coincidentes faz com que os valores das somatórias para todas as linhas e colunas seja sempre igual a 0,0 ou 1,0.
A linha Vila Garcia 3 apresentou valor estimado de x2 maior que o valor crítico para pontos desagregados, porém esta linha não apresentou os maiores valores para as estatísticas f e ID quando comparado aos valores extremos da tabela 6.1. Apesar de ter apresentado o pior resultado na estatística x2 o mesmo não apresentou os piores resultados nos outros testes, os valores de f e ID para Vila Garcia 3 (1,4 e 59,7), são menores que os valores extremos simulados para esta mesma linha (f =1,9 e ID=85,6).
Das 27 linhas simuladas, 18 representam o período de pico (manhã, ao meio-dia e tarde) e 9 linhas representam o período de entre pico. Os resultados apresentados não permitem identificar a influência da utilização de dados amostrados nos períodos de pico e de entre pico.
O valor 0,0 para a estatística f
indica que a matriz estimada é igual a matriz observada. Este resultado
pode ser observado na linha Populares 1. Os dados de E/D utilizados nesta
simulação são referentes ao entre pico da manhã,
porém o maior valor encontrado para a estatística f
também ocorreu no entre pico (Vila Garcia = 1,9).
O modelo gravitacional utilizado para a obtenção de matrizes O/D a partir de dados E/D é de fácil aplicação, e as informações necessárias para a implementação do mesmo podem ser facilmente coletadas em campo de forma rápida e pouco dispendiosa em termos de tempo e recursos financeiros. As informações referentes às contagens de embarque-desembarque não necessitam de pessoal especializado para serem realizadas, e podem ser obtidas por pesquisadores sem grande experiência ou pelos próprios operadores no momento da operação. As distâncias entre pontos de parada podem ser obtidas durante a própria operação dos serviços de transporte.
A utilização do programa desenvolvido em Turbo Pascal é simples de ser realizada e não necessita de pessoal especializado. Este procedimento pode ser adaptado para planilhas eletrônicas do tipo EXCEL através da utilização de macros, tornando-o assim mais "atraente" visualmente.
Quando comparado aos outros modelos de obtenção de matrizes listados no capítulo 4, o modelo proposto mostrou-se de fácil entendimento e de operacionalização. Os modelos do fluido e o algoritmo SYNODM mostraram-se de fácil utilização, podendo ser implementados facilmente em planilhas eletrônicas, porém estes modelos não fazem uso da informação distância viajada, utilizam somente a probabilidade de desembarque de cada passageiro após percorrido um determinado número de pontos.
A diferença entre o modelo proposto e os demais modelos de gravidade, é que a grande maioria dos modelos de gravidade utilizam somente um valor de parâmetro de impedimento da função distância viajada para toda matriz. Enquanto que o modelo proposto utiliza n - 1 valores de parâmetros em função da distância viajada, buscando assim reproduzir o custo médio de distribuição de viagens de uma origem em relação aos seus diferentes destinos.
Alguns autores (WILSON, 1970; SOUTHWORH, 1978) comentam que a desagregação dos valores de parâmetros da função custo permitem aos analistas incorporar fatores de penalidade e ajuste aos parâmetros de custo, produzindo assim uma redução do erro médio de viagens. Na década de 70 Southworth considerava que o tempo computacional era um empecilho a utilização deste modelo. Como o problema do tempo computacional encontra-se praticamente resolvido, recomenda-se que sejam realizadas pesquisas a fim de aprofundar o conhecimento nesta área.
Seria interessante comparar o desempenho entre o modelo proposto com outros modelos de gravidade os quais contenham outros tipos de funções de impedância, como por exemplo a função exponencial negativa, comparar os modelos que utilizam outros métodos de calibração e os modelos que utilizam apenas um único valor de parâmetro em relação a função de impedimento distância viajada.
Antes de prosseguir com os estudos, no entanto, é fundamental que seja feita uma revisão no processo de calibração do modelo proposto, de forma a assegurar que os coeficientes de cada linha da matriz sejam calibrados separadamente. Isto requer, sem dúvida, um esforço considerável de programação, que não foi possível contemplar neste trabalho, mas que deve ser conduzido antes de qualquer análise comparativa.
Uma sugestão para trabalhos futuros seria a comparação entre desempenho dos diversos modelos de obtenção de matrizes a partir da utilização de dados de pesquisa E/D. Estas comparações poderiam permitir a identificação dos modelos que melhor se adaptariam aos diferentes padrões de comportamento da demanda, características sócioeconômicas, características de ocupação e uso do solo, etc.
O planejamento do sistema de transporte por ônibus
requer o conhecimento do padrão de deslocamento de seus usuários,
porém o método proposto não possibilita identificação
e estimativa do número de usuários que fazem uso da transferência
de ônibus, bem como de suas origens e destinos "reais" (a pesquisa
E/D não identifica os passageiros que realizam transferências
de linhas de ônibus). O conhecimento da rede de transporte pelo analista
poderia ser utilizado para identificar os pontos onde ocorrem as maiores
porcentagens de transferência no sistema. Nestes pontos poderiam
ser realizadas pesquisas de entrevista com os usuários identificando
seus verdadeiros pontos de origem e destino. Este procedimento poderia
permitir que parte do conhecimento dos totais de transferência fosse
incorporado a matriz O/D. O modelo proposto não contempla esta informação
adicional, é imperativa a realização de novos estudos
para a verificação dessa hipótese.
ANTP - ASSOCIAÇÃO NACIONAL DE TRANSPORTES PÚBLICOS (1995a). Pontos de parada de ônibus. São Paulo. Relatório de pesquisa ANTP.
ANTP - ASSOCIAÇÃO NACIONAL DE TRANSPORTES PÚBLICOS (1995b). Pontos de parada de ônibus urbano - Contribuição para a sua implantação. Caderno técnico n.º 2, São Paulo.
ANTP - ASSOCIAÇÃO NACIONAL DE TRANSPORTES PÚBLICOS (1997). Transporte Humano - Cidades com Qualidade de Vida. São Paulo.
BALASSIANO, B. (1997). Planejamento Estratégico de Transportes Considerando Sistemas de Média e Baixa Capacidade. In: Congresso de Pesquisa e Ensino em Transportes - ANPET, 11, Rio de Janeiro, 1997. Anais. v.1, p.203-216.
BELL, M. G. H. (1983). The estimation of an origin-destination matrix from traffic counts. Transportation Science, Vol. 17, n. 2, p. 198-217.
BELL, M. G. H. (1991).The estimation of origin-destination matrices by constrained generalized least squares. Transportation Research, 25B (1), p.13-22.
BEN-AKIVA, M.; MACKE, P. P; and HSU, P. S. (1985). Alternative methods to estimate route level trip tables and expand on-board surveys. Transportation Research Record, n.1037, p. 01-11.
BEN-AKIVA, M.; MORIKAWA, T. (1988). Data combination and updating methods for travel survey. Transportation Research Record, n.1203, p. 40-47.
BRUTON, M. J. (1979). Introdução ao planejamento dos transportes. 2. ed. Rio de Janeiro, Editora Interciência Ltda.
CASCETTA, E.; INUDI, D.; MARQUIS, G. (1993). Dynamic estimators of origin-destination matrices using traffic counts. Transportation Science, v. 27, p.363 -373.
CONOVER, W. J. (1980). Nonparametric statistics. 2º Ed. New York. John Wiley & Sons.
DI PIERRO, L. F. (1985). Determinação de matrizes de viagens de passageiros de ônibus a partir de uma pesquisa embarque/desembarque. Revista dos Transportes Públicos. 7(27), p.49-68. S. Paulo, SP.
DOMENCICH T. A.; MCFADDEN, D. (1975). Urban travel demand a behavioural analysis. North-Holland - Amsterdam.
EASA, S. M. (1993a). Urban trip distribution in practice. I: conventional analysis. Journal of Transportation Engineering, v. 119, n 6, p 793-815.
EASA, S. M. (1993b). Urban trip distribution in practice. II: quick response and special topics. Journal of Transportation Engineering, v. 119, n. 6, p. 816-834.
ERLANDER, S.; JÖRNSTEN, O. K.; LUNDGREN, J. T. (1985). On the estimation of trip matrices in the case of missing and uncertain data. Transportation Research, 19B (2), p.123-141.
ERLANDER, S.; Stewart, N. F. (1990). The gravity model in transportation analysis - theory and extensions. Ultrecht, Netherlands.
FERRAZ, A. C. P. (1998). Escritos sobre transporte, trânsito e urbanismo. São Carlos, SP. Projeto REENGE USP, 218 p.
FERRAZ, A. C. P. (1997). Transporte Público Urbano. Notas de Aula do Curso de pós graduação em Transportes. São Carlos. Escola de Engenharia de São Carlos, Universidade de São Paulo.
FERREIRA, E. A.; KAWAMOTO. E. (1998). Elaboração de matriz O/D das linhas de transporte público de passageiros usando dados de embarque-desembarque: análise comparativa de três métodos. In: IX Congreso Latino Americano del Transporte Público y Urbano. Guadalajara, México. Anais em CD ROM.
FISK, C. S. (1989). Trip matrix estimation from link traffic counts: The congested network case. Transportation Research. 23B (5): 331-336.
FLEMMING, D. M. (1993). Um método de alocação de contadores volumétricos de tráfego numa rede rodoviária para estimar matrizes origem - destino. Florianópolis, 201p. Tese (Doutorado) - Curso de Pós-Graduação em Engenharia de Produção - Universidade Federal de Santa Catarina.
FURTH, P. G. (1990). Model of turning movement propensity. Transportation Research Record, n. 1287, TRB, National Council, Washington, D. C. p.195-204.
FURTH, P.G.; NAVICK, D. S. (1993a). Bus route O-D matrix generation: relationship between biproportional and recursive methods. Transportation Research Record, n.1338. p.14-21.
FURTH, P.G.; NAVICK, D. S. (1993b). Distance-based model for estimating a bus route origin-destination matrix. Transportation Research Record, n.1433. p.16-23.
GEVA, I.; HAUER, E.; LANDAU, U. (1983). Maximum-Likelihood and Bayesian methods for the estimation of origin-destination flows. Transportation Research Record, n.944, p.101-105.
GONÇALVES, M. B.; ULYSSÉA NETO, I. (1993). Análise comparativa do desempenho de alguns modelos de distribuição de viagens usados para estimar fluxos intermunicipais de passageiros. In: Anais do VII Encontro Nacional da ANPET. São Paulo - SP, Vol. I, p.337-348.
GUR, Y. J.; BEN-SHABAT, E. (1997). Estimating bus boarding matrix using boarding counts in individual vehicles. Transportation Research Record, n.1607, p.81-86.
HALLEFJORD, A.; JÖRNSTEN, K. (1986). Gravity models with multiple objectives - theory and applications. Transportation Research, 20B (1), p. 19-39.
HENDRICKSON, C.; and MCNEIL, S. (1984). Estimation of origin-destination matrices with constrained regression. Transportation Research Record, n.976, p.25-32.
HUTCHINSON, B. G.; KUMAR, R. K. (1990). Modeling urban spatial evolution and transport demand. Journal of Transportation Engineering, v. 116, n. 4, p 550-571.
JANSON, B. N. (1993). Most likely origin-destination link uses from equilibrium assignment. Transportation Research, 27B (5), p.333-350.
KANAFANI, A. (1983). Transportation demand analysis. K. McGraw-Hill Book Company, 1983.
KAWAMOTO, E. (1994). Verificação da matriz ponto-de-origem / ponto-de-destino de uma linha de transporte coletivo obtida a partir de dados de embarque-desembarque. In: Anais do VIII Encontro Nacional da ANPET. Recife - PE, Vol. II, p.41-50.
KIKUCHI S.; PERINCHERRY V. (1992). Model to estimate passenger origin-destination pattern on a rail transit line. Transportation Research Record, 1349, p.54-61.
KUWAHARA M.; SULLIVAN. E. D. (1987). Estimating origin-destination matrices from roadside survey data. Transportation Research, 21B (3), p.233-248.
LAM, W. H. K.; LO. H. P. (1991). Estimation of an origin-destination matrix from traffic counts: a comparison of entropy maximizing and information minimizing models. Transportation Planning and Technology, n.16, p.85-104.
LAMOND, B.; STEWART, N. F. (1981). Bregmans balancing method. Transportation Research, 15B(4), p.239-248.
LIMA, L. C.; DA SILVA, M. C. T.; GRANJA, L. Z.; MORA-CAMINO, F. A. C. (1987). Otimização de um sistema de transporte público urbano: uma abordagem de equilíbrio. Revista dos Transportes Públicos - ANTP- ano 9, n 36.
LOGIE, M.; HYND, A. (1990). MVESTM matrix estimation. Traffic Engineering and Control. n. 8/9 p. 454-459 e n.10. p. 534-549.
MAHER, M. J. (1983). Inference on trip matrices from observations on link volumes: a Bayesian statistical approach. Transportation Research, 17B, p.435-447.
MANHEIN, M. L. (1979). Fundamentals of transportation system analysis: Volume 1 - Basic concepts. The MIT Press, Cambridge, Mass.
MERCEDES-BENZ DO BRASIL S.A. (1987). Manual de Sistemas de Transporte Coletivo Urbano por Ônibus Planejamento e Operação. Departamento de Sistemas de Trânsito e Transporte, São Bernardo do Campo, SP, 82 p.
MEURS, H. (1990). Trip generation models with permanent unobserved effects. Transportation Research, 24B (2), p.145-158.
MORLOK, E. K. (1978). Introduction to transportation engineering and planning. Ed. McGraw-Hill, New York, 767 p.
NAVICK, D. S.; FURTH, P. G. (1993). Distance based model for estimating a bus route Origin-Destination matrix. Transportation Research Record, n.1433, p.16-23.
NGUYEN, S. (1984). Estimating origin-destination matrices from observed flows. Proceedings of the AIRO Conference. Guida, Naples. p.363 - 368.
NIHAN, N.; DAVIS, G. A. (1989). Application of prediction-error minimization and maximum likelihood to estimate intersection O-D matrices from traffic counts. Transportation Science, vol. 23, n.2.
NOVAES, A. G. (1986). Sistemas de transporte. volume 1: análise da demanda. São Paulo, Edgard Blücher Ltda.
ORTÚZAR, J. D.; WILLUMSEN, L. G. (1994). Modelling transport. 2.ed. England, John Wiley & Sons.
PADILHA, E. (1998). Por uma Política de Transportes Urbanos. Folha de São Paulo, São Paulo, 31 mar. Caderno 1, p.3.
PARVATANEMI, R.; STOPHER, P.; BROWN, C. (1982). Origin-destination travel survey for southeast Michigan. Transportation Research Board, n 886.
PASCHETTO, A. et al. (1984). Critérios de escolha do modo de transporte segundo o planejamento urbano e as condições de operação. Revista dos Transportes Públicos ANTP, n.º 23, março/84.
RICHARDSON, A. J.; AMPT, E. S.; MEYBURG, A. H. (1995). Survey methods for transport planning. Melbourne, Eucalyptus Press.
ROBILLARD, P. (1975). Estimating the O-D Matrix From Observed Link Volumes. Transportation Research, vol. 9, p. 123-128.
ROSALEN, F. J. (1994). A influência da distância de viagem na escolha do local de trabalho em cidades pequenas e médias. São Carlos. 86p. Dissertação (Mestrado) Escola de Engenharia de São Carlos, Universidade de São Paulo.
SANCHES, S. P. (1988). Contribuição à análise operacional de redes de transporte coletivo em cidades de porte médio. 117p. Tese (Doutorado) - Escola de Engenharia de São Carlos, Universidade de São Paulo.
SMITH, D. P., HUTCHINSON, B. G. (1981). Goodness of fit statistics for trip distribution models. Transportation Research, 15A, p.295-303.
SOUTHWORTH, F. (1978). The calibration of a joint trip-distribution and modal-split model with origin-specific cost decay parameters. Area, nº 10, p.252-258.
SPIESS, H. A. (1987). Matricial likelihood model for estimating origin-destination matrices. Transportation Research, 21B (5), p.395-412.
STOKES, R. W.; MORRIS, D. E. (1980). Application of an algorithm for estimating freeway trip tables. Transportation Research Record, 976, p. 21-25.
STOPHER, P. R.; SHILLITO, L.; GROBER, D. T., STOPHER, H. M. (1985). On-Board Bus Surveys: No Question Asked Transportation Research Record, 1085, TRB, National Council, Washington, D. C., p. 50-57.
STOUFFER, S. A. (1940). Intervening opportunities: a theory relating mobility and distance. In: American Sociological Review. v.5, p. 845-867.
TAMIN, O. Z.; WILLUMSEN, L. G. (1989) .Transport demand model estimation from traffic counts. Transportation, n.16(1), p. 3-26.
ULYSSÉA NETO, I. (1991). Desenvolvimento de modelos de distribuição de viagens através do método da maximização da entropia. In: Anais do V Encontro Nacional da ANPET. Belo Horizonte - MG, Vol. I, p.233-248.
VAN ZUYLEN, H. J.; WILLUMSEN, L. G; EASA, S. M. (1980). The most likely trip matrix estimated from traffic counts. Transportation Research, 14B(3), p.281-294,
VUCHIC, V. R. (1981). Urban Public Transportation - Systems and Technology. New Jersey, Prentice Hall.
WATLING, D. (1994). Maximum-likelihood estimation of origin-destination matrix from a partial registration plate survey. Transportation Research, 28(B), n. 4, p.289-314.
WILSON, A. G. (1967). A statistical theory of spatial distribution models. Transportation Research, v.1, p. 235-269.
WILSON, A. G. (1970). Entropy in urban and regional modelling. London. Pion.
WILSON, A. G. (1976). Statistical notes on the evaluation of calibrated gravity models. Transportation Research, v. 10, p. 343-345.
YANG, H.; IIDA Y.; SASAKI, T. (1994). The equilibrium-based origin-destination matrix estimation problem. Transportation Research, 28B (1), 23-323.
YANG, H.; SASAKI, T.; IIDA, Y.; ASAKURA,
Y. (1992). Estimation of origin-destination matrices from line traffic
counts on congested networks. Transportation Research, 26(B), p.417-34.
PROGRAMA GRAVIDADE
Uses crt,
dos,
printer;
type matri = array [1..60,1..60] of double;
matrix2 = array [1..60,1..60] of double;
vetor = array [1..60] of double;
var O,D,A,B,alfa,F,Y,DE,p:vetor;
C,V:matri;
soma,erro,ttotal,teta,tempo,alfa0,r,errop:real;
n,i,j,L:integer;
arquivo,entrada: text;
resp,valor,count:integer;
{L numero de iteracoes,DE derivada , Y resolucao de teta em uma origem,}
PROCEDURE ESPACO (n:integer;var C1:matri);var i,j:integer;
begin
for i:=1 to n do
begin
for j:=1 to n do
begin
C1[i,j]:=0;
end;
end;
{ writeln;
writeln('Digite a matriz C');}
for i:=1 to n do
read (entrada,C1[i,i+1]);
for i:=1 to n do
begin
for j:=i+2 to n do
begin
C1[i,j]:=C1[i,j-1]+C1[j-1,j];
end;
end;
end;
begin
{ENTRADA DE DADOS}
ClrScr;
{resp:=2;}
assign(entrada,'c:\samamba.txt');
reset(entrada);
{while resp<>1 do
begin
writeln ('Digite a dimensao da matriz - N');}
readln(entrada,n);
{ writeln;
writeln('confirma entrada de dados sim=1 e nao=2');
readln(resp);
end; }
ClrScr;
{resp:=2;
while resp<>1 do
begin
writeln ('Digite a Matriz de Embarque');
writeln;}
for i:=1 to n do
begin
readln(entrada,O[i]);
end;
{ writeln('confirma entrada de dados sim=1 e nao=2');
readln(resp);
end;
ClrScr;}
{resp:=2;
while resp<>1 do
begin
writeln ('Digite a Matriz de Desembarque');
writeln;}
for i:=1 to n do
begin
readln(entrada,D[i]);
end;
{ writeln('confirma entrada de dados sim=1 e nao=2');
readln(resp);
end;
ClrScr; }
{resp:=2;
writeln;
while resp<>1 do
begin
writeln ('Digite o valor de teta');}
readln(entrada,teta);
{ writeln('confirma entrada de dados sim=1 e nao=2');
readln(resp);
end;
ClrScr; }
{resp:=2;
writeln;
while resp<>1 do
begin
writeln('digite o valor do tempo total real');}
readln (entrada,ttotal);
{ writeln('confirma entrada de dados sim=1 e nao=2');
readln(resp);
end;
ClrScr;}
{writeln;
writeln(' B inicial=1');}
for i:=1 to n do
begin
(B[i]):=1;
end;
{writeln;
writeln ('alfa inicial=0');}
for i:=1 to n do
begin
(alfa[i]):=0;
end;
{entrada da matriz Cij}
espaco(n,C);
close(entrada);
erro:=10;
L:=0;
errop:=10;
{valor:=0;
count:=0;}
While (errop>0.10) and (L<10) do
Begin
{ count:=0;
while count<10 do
begin}
For i:=1 to n do
Begin
soma:=0;
For j:=1 to n do
Begin
if C[i,j]=0 then
r:=0
else
r:=exp(alfa[i]*ln(C[i,j]));
soma:=soma+B[j]*D[j]*r;
end;
if soma<>0 then
A[i]:=1/soma
else
A[i]:=0.1;
End;
For j:=1 to n do
Begin
soma:=0;
For i:=1 to n do
Begin
if C[i,j]=0 then
r:=0
else
r:=exp(alfa[i]*ln(C[i,j]));
soma:=soma+A[i]*O[i]*r;
end;
if soma<>0 then
B[j]:=1/soma
else
B[j]:=0.1;
End;
soma:=0;
For i:=1 to n do
Begin
For j:=1 to n do
Begin
if C[i,j]=0 then
r:=0
else
r:=exp(alfa[i]*ln(C[i,j]));
V[i,j]:=A[i]*B[j]*O[i]*D[j]*r;
soma:=soma+V[i,j]*C[i,j];
End;
End;
tempo:=soma;
erro:=ttotal-tempo;
errop:=(abs(erro)/ttotal)*100;
If (abs(errop)>0.10) Then
Begin
For i:=1 to n-2 do
begin
soma:=0;
For j:=i+2 to n do
Begin
if C[i,j]=0 then
r:=0
else
r:=exp(alfa[i]*ln(C[i,j]));
soma:=soma+B[j]*D[j]*r;
end;
F[i]:=1-A[i]*soma;
Y[i]:=teta-F[i];
soma:=0;
For j:=i+2 to n do
Begin
if C[i,j]=0 then
r:=0
else
r:=exp(alfa[i]*ln(C[i,j]))*ln(C[i,j]);
soma:=soma+B[j]*D[j]*r;
end;
DE[i]:=-A[i]*soma;
if DE[i]<>0 then
p[i]:=Y[i]/DE[i]
else
begin
DE[i]:=1;
p[i]:=Y[i]/DE[i]
end;
alfa0:=alfa[i];
alfa[i]:=alfa0+p[i];
end;
j:=n;
i:=n-1;
if abs(C[i,j]) <> 0 then
Begin
F[i]:=1-A[i]*B[j]*D[j]*exp(alfa[i]*ln(C[i,j]));
{ if F[i]<>1 then}
Y[i]:=teta-F[i];
{else
begin
Y[i]:=teta
end;}
DE[i]:=-A[i]*B[j]*D[j]*exp(alfa[i]*ln(C[i,j]))*ln(C[i,j]);
if (abs(DE[i])<>0) then
p[i]:=Y[i]/DE[i]
else
p[i]:=0;
end
else
Begin
F[i]:=0;
Y[i]:=teta-F[i];
DE[i]:=0;
p[i]:=0;
end;
alfa0:=alfa[i];
alfa[i]:=alfa0+p[i];
{End do if}
end;
i:=n;
j:=n;
alfa[i]:=0;
L:=L+1;
{count:=L-valor;
end;
valor:=valor+10;}
writeln('tempo=',tempo:7:2);
writeln('Iteracao=',L);
writeln('erro=',erro:7:3);
writeln('errop=',errop:7:3);
writeln;
writeln;
{writeln('Deseja continuar com as iteracoes ? sim=1');
readln(resp);
if resp<>1
then L:=100;}
End;
assign( arquivo, 'c:\sam.txt' );
rewrite(arquivo);
For i:=1 to n do
Begin
for j:=1 to n do
write(arquivo,V[i,j]:11:5);
write(arquivo,alfa[i]:11:5);
write(arquivo,L:4);
writeln(arquivo);
end;
Writeln(arquivo);
writeln(arquivo);
writeln(arquivo,'tempo total');
write(arquivo,tempo:8:1);
writeln(arquivo);
writeln(arquivo);
{Write(arquivo,alfa[i]:3:2);}
writeln(arquivo);
write(L:4);
writeln(arquivo);
{For i:=1 to n do
Begin
for j:=1 to n do
write(arquivo,c[i,j]:8:1);
writeln(arquivo);
end;
Writeln(arquivo); }
close(arquivo);
end.
Exemplo de entrada por arquivo para uma matriz com 5 linhas e cinco colunas:
| 5 | Referente ao número de linhas e colunas |
| 25
15 12 5 0 |
Passageiro
embarcados
|
| 0
2 10 20 25 |
Passageiros desembarcados |
| 0.01 | Teta (coeficiente de probabilidade) |
| 55420 | Tempo total da matriz |
| 250
200 300 350 300 |
Distância entre pontos |
VOLTA