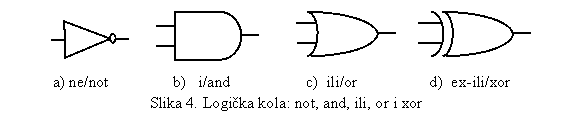UNIVERZITET U
SARAJEVU
Elektrotehnički
fakultet Sarajevo
Odsjek za računarstvo i informatiku
PROGRAMSKA ORGANIZACIJA RAČUNARA
Sarajevo, maj 2001. mr.
Idriz Fazlić
Sadržaj:
Uvod ..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 1
1. Predstavljanje
podataka. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 4
1.1 Brojni
sistemi. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 4
1.1.1 Konverzije
između brojnih sistema. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 5
1.1.2 Heksadecimalni
i oktalni sistemi.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 6
1.1.4 Formati
brojnih sistema.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 8
1.2 Organizacija
podataka. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 9
1.2.1 Biti. ..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. .. 9
1.2.2 Nibli. ..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 10
1.2.3 Bajti.. ..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 10
1.2.4 Riječi..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 10
1.2.5 Duple
riječi.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 11
1.3 Osnovne
operacije .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 10
1.3.1 Logičke
operacije .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 12
1.3.2 Operacije
nad bitima.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 13
1.4 Predstavljanje
negativnih brojeva. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 14
1.4.1 Predznak i
vrijednost .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 14
1.4.2 Komplement
jedan .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 15
1.4.3 Komplement
dva .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 15
1.5 Pomjeranje
i rotiranje bita. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 17
1.6 Realni
brojevi.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 18
2. Osnovni
elementi računarskih arhitektura. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 19
2.1 Bazne
komponente sistema.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 19
2.1.1 Sistemska
sabirnica.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 20
2.1.1.1 Podatkovna
sabirnica.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 20
2.1.1.2 Adresna
sabirnica.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 20
2.1.1.3 Kontrolna
sabirnica.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 21
2.1.1.4 U/I
sabirnica. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 21
2.1.2 Memorijski
podsistem. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 21
2.2 Sistemsko
vrijeme.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 23
2.2.1 Sistemski
sahat .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 23
2.2.2 Pristup
memoriji i sistemski sahat: .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 24
2.2.3 Stanja
čekanja.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 25
2.2.4 Keš
memorija.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 25
2.3 U/I
(Ulaz/Izlaz).. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 26
3 Instrukcije
naspram podataka.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 29
3.1 Instrukcije..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 29
3.1.1 Formati
aritmetičkih izraza.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 30
3.1.2 Veličine
instrukcija.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 31
3.1.3 Tipovi
adresnih mašina.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 32
3.1.3.1 Troadresne
mašine .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 32
3.1.3.2 Dvoadresne
mašine.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 32
3.1.3.3 Jednoadresne
mašine .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 32
3.1.3.4 Nuladresne
mašine .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 33
3.2 Adresiranje
i tipovi memorije. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 33
3.2.1 Skraćeno
referenciranje (registri). .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 33
3.2.2 Adresiranje
instrukcija .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 35
3.2.3 Adresiranje
poenterom .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 36
4 Centralna
obrađivačka jedinica - Procesor.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 38
4.1 Procesor.
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 38
4.1.1 Registri
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. 38
4.1.2 Aritmetičko-logička
jedinica – Alj. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 39
4.1.3 Jedinica
za upravljanje sabirnicama - JUS .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 39
4.1.4 Kontrolna
jedinica .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 39
4.2 Instrukcioni
set procesora hpx6. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 40
4.2.1 Instrukcija
za prebacivanje podataka - MOV.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 41
4.2.2 Aritmetičko-logičke
instrukcije.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
41
4.2.3 Instrukcija
kontrole toka programa.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 41
4.3 Načini
adresiranja procesora hpx6.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 42
4.4 Kodiranje
instrukcija za procesor hpx6 .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 43
4.5 Faze
izvršenja instrukciije .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 46
4.6 Unapređenja
hpx6 procesora. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 49
4.6.1 Procesor
hp6 - osnovni procesor.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 49
4.6.2 ProcProcesor
hp26 - spremnik za pribavljanje instrukcija.. .. .. .. .. .. .. .. .. 50
4.6.3 Procesor
hp46 - protočnost.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 53
4.6.4 Procesor
hp66 - superscalarni procesor. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 55
5 Memorija
- organizacija i prist.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 56
5.1 Programerov
pogled na CPU. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 56
5.1.1 Registri
opšte namjene.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 56
5.1.2 Virtuelna
memorija. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 57
5.1.3 Segmentni
registri .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 59
5.2 Programerov
pogled na memoriju .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 60
5.2.1 Registarsko
adresiranje. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 60
5.2.2 Memorijski
načini adresiranja.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 61
5.2.2.1 Adresiranje
memorije samo sa pomakom.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 61
5.2.2.2 Registarski
indirektni način adresiranja.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 61
5.2.2.3 Indeksni
način adresiranja.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 62
5.2.2.4 Bazni
indeksni način adresiranja. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 63
5.2.2.5 Bazno
indeksni način adresiranja sa pomakom .. .. .. .. .. .. .. .. .. .. .. .. .. ..
63
5.2.3 Šema za
jednostavno pamćenje načina adresiranja .. .. .. .. .. .. .. .. .. .. .. .. 64
6 Strukture
podataka.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 66
6.1 Instrukcije
za rad sa strukturama podataka. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
66
6.2 Veličina
operanada.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 67
6.3 Deklarisanje
varijabli u asemblerskome programu. .. .. .. .. .. .. .. .. .. .. .. .. 67
6.4 Deklarisanje
i pristup skalarnim varijablama. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 68
6.4.1 Deklarisanje
i korištenje BYTE varijable. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
69
6.4.2 Deklarisanje
i korištenje WORD varijable.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 71
6.4.3 Deklarisanje
i korištenje DWORD varijable .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 72
6.4.4 Deklarisanje
varijabli realnih brojeva REAL4, REAL8 i REAL10.. .. .. .. .. 72
6.5 Deklarisanje
konstanti u asemblerskome programu .. .. .. .. .. .. .. .. .. .. .. .. 74
6.6 Kreiranje
sopstvenih tipova direktivom TYPEDEF.. .. .. .. .. .. .. .. .. .. .. .. 74
6.7 Pokazivački
tipovi podataka.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 74
6.8 Složeni
tipovi podataka. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 77
6.8.1 Nizovi. ..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 77
6.8.1.1 Deklarisanje
jednodimenzionalnog niza .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 78
6.8.1.2 Pristup
elementima u jednodimenzionalnome nizu. .. .. .. .. .. .. .. .. .. .. .. .. 79
6.8.2 Višedimenzionalni
nizovi. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 80
6.8.2.1 Preslikavanje
po redovima.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 81
6.8.2.2 Preslikavanje
po kolonama. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 84
6.8.2.3 Određivanje
prostora za višedimenzionalne nizove .. .. .. .. .. .. .. .. .. .. .. .. 84
6.8.2.4 Pristup
elementima višedimenzionalnih nizova .. .. .. .. .. .. .. .. .. .. .. .. .. .. 85
6.9 Kontrolne
strukture. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 86
6.9.1 Kontrolne
strukture grananja. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 86
6.9.1.1 Uslovno
grananje. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 87
6.9.1.2 Bezuslovno
grananje. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 87
6.9.1.3 Emuliranje
uslovnih iskaza jezika visokog nivoa .. .. .. .. .. .. .. .. .. .. .. .. .. 88
6.9.2 Procedure
i interapti.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 89
6.9.2.1 Procedure..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 89
6.9.2.2 Interapti.
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. 91
6.9.2.2.1
Interaptna tabela vekotra.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 93
6.9.2.2.2
Interaptna uslužna rutina.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 93
6.9.2.2.3 Prekidi
toka izvršenja programa.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. 94
7 Programsko
okruženje .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 96
7.1 Konstrukcije
asemblera.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 96
7.1.1 Dvoprolazni
asembler .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 97
7.1.2 Jednoprolazni
asembler .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 98
7.1.3 Izlaz iz
asemblera – objektni kod.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 100
7.2 Povezivanje
modula programa - linkeri. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 102
7.3 Punjenje
programa u memoriju - loaderi.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 104
7.3.1 Loaderi
‘kompajliraj-i-kreni’. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 105
7.3.2 Opšta šema
loadera.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 105
7.3.3 Relocirajući
loaderi. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. 106
Dodatak A: Kodiranje
informacija. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. 107
A1: Kodiranje informacija kroz historiju. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 107
A2: ASCII tabela.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. .. .. .. .. 110
Dodatak B:
Instrukcijski skup - procesor 8088.. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. 113
Dodatak C: Slika
operativnog sistema i programa u memoriji .. .. .. .. .. .. .. .. .. .. 165
C1: Zauzeće memorije po iniciranju operativnog sistema MS-DOS. .. .. .. 165
C2: Format izvršnog modula (.EXE). .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. 166
C3: Izgled koda programa sa slike 64. U memoriji po sekcijama.. .. .. .. .. 167
Dodatak D:
Interapti arhitekture 8088 .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. 169
D1:
Interni hardverski interapti. .. .. .. .. .. .. .. .. .. .. .. . .. .. .. .. ..
.. .. .. .. .. 169
D2:
Eksterni hardverski interapti. .. .. .. .. .. .. .. .. .. .. . .. .. .. .. ..
.. .. .. .. .. 169
D3:
Softverski interapti .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. . .. .. ..
.. .. .. .. .. .. .. 170
Literatura .. .. ..
.. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..
.. .. .. .. .. .. .. 173
Predgovor
Zahtjevi za pojavu ovog materijale leže u
nedostatku materijala na fakultetima u BiH koji se bave ovom problematikom.
Kako je razvoj računarske tehnologije enormno brz, a time se i arhitekture
računara mijenjaju, to se poslije rata ukazala potreba za udžbenikom koji
pokriva ovu materiju na bosanskome jeziku (i/ili ostalim srodnim jezicima
ex-Yu). Kako studenti na našim fakultetima slušaju nastavu na našem jeziku, to
se ne može od njih zahtjevati da materiju vezanu za arhitekturu računara traže
na Internetu na engleskome jeziku. To su glavni razlozi što sam se prihvatio
ovog posla.
Kako su arhitekture računara vezane za
konkretnu mašinu, to je cilj ovoga materijala nije da predstavi ni jednu
partikularnu arhitekturu, već principe na kojima se baziraju arhitektura
računara. Da bi se cilj što uspješnije ostvario, koristile su se apstrakne
arhitekture hipotetičke mašine, na kojoj su prikazani opšti principi rada.
Razumijevanje programske organizacije računara se bazira na dualizmu softvera i
hardvera. Zato se ovaj materijal bavi problematikom koja dodiruje obije
oblasti, ali se i trudi da ne prevagne na ni jednu stranu previše. Ako se
definiše funkcija cilja ovog rada, onda ona nije da student nauči
programirati u asembleru i/ili konstrukciju hardverskih sklopova, već da
savlada principe rada računarske opreme i to na onoj tački gde granica između
softvera i hardvera nestaje. Funkcija cilja će biti zadovoljena, ako student
uspije da sagleda izvršenje Pascalskog iskaz a:=5; na nižim nivoima, sve dok
ne dođe do nivoa kontrolnih signala i stanja na logičkim sklopovima, prilikom
realizacije navedenog iskaza. Posebna pažnja je posvećena definisanju
primitivnih operacija, kako kod softvera tako i kod hardvera, iz kojih se mogu
realizovati ostale.
Materijal počinje sa načinima kodiranja
informacija i brojevima, te osnovnih logičkih sklopaova za manipulisanje tim informacijama.
U sljedećim poglavljima se nazmjenično smjenjuju 'softveraški' i 'hardveraški'
pogled na realizaciju računarske mašine. Pored definisanja virtuelne mašine,
definisan je i mašinski jezik sa minimalnim skupom instrukcija. Na ovakvom
modelu je moguće presdstaviti sve bitne elemente koji su vezani za moderne
računarske arhitekture. Kako bi se omogućilo razumjevanje struktuiranog
programiranja i strukture podataka, to su dati načini zapisa istih u realnom
asembleru 8086. Da bi se slika izvršenja zadatka na računarau kompletirala, u
zadnjoj glavi su obrađeni procesi prevođenja programa, linkovanja i punjenja,
te izvršenja, što već zalazi u domen operativnih sistema. U ovome materijalu
nisu obrađene asemblerske instrukcije pojedinačno, što je u knjigama ovog tipa
obično urađeno. Razlog leži u tome što je funkcijom cilja definisano da je
bitan princip rada, pa su ovi detalji ostavljeni eventualno za sljedeću
verziju. Kako bi se naglasio model udžbenika, to su na krajevima poglavlja data
pitanja vezana za problematiku datog poglavlja kao i dodatna razmišljanja.
Posebno bih naglasio jezičke probleme koji su
neizbježni kada je u pitanju računarska tehnologija, jer je većina problema
izvorno definisana na engleskome jeziku. Nisu uvijek mogući adekvatni prijevodi
na bosanski jezik. Nekada i kada postoji dobar prijevod, kao što je prihvatnik
za buffer, ljudi su ipak navikli i radije koriste izvorni oblik. Trudio sam se
koliko je moguće da prevedem pojmove, mada ima dosta nedosljednosti. Recimo
pojam prefatch queue je preveden opisno kao spremnik za pribavljanje
instrukcija i pod upitnikom je adekvatnost prijevoda.
Koristim priliku da se posebno zahvalim na
sugestijama prof. dr. Ahmetu Mandžiću, dugogodišnjem predavaču ove materije na
Elektrotehničkome fakultetu u Sarajevu, osnivaču Informatike kao posebnog
Odsjeka. Takođe se želim zahvaliti na korekcijama kolegi Samiru Ribiću, te
Nedžli Fazlić koja je uporno radila na unošenju ovog materijala na računaru.
Sarajevo: septembar 2001.
godine mr. Idriz Fazlić dipl.el.inž
Uvod
Računarske nauke, koje se baziraju na
računarskoj tehnologiji nemaju za primarni zadatak ono što se nalazi u
njihoveme imenu - računanje. Cilj računarskih nauka je obrada informacija, tj primjena
algoritama na strukturama podataka. Algoritmi predstavljaju niz
uzastopnih koraka (radnji) koje je potrebno primjeniti pri rješavanju nekog
problema. Strukture podataka su definisane tipom, što podrazumijeva kako
karakteristike objekata koje predstavljaju, tako i operacije koje se nad njima
mogu primjeniti. Wirth je definisao programe formulom:
Algoritmi
+ Strukture
podataka
= Programi
Kako je svaki od pomenutih pojmova veoma
kompleksan (neki programi, odnosno programski paketi se mjere desetinama
inženjer godina), to je potrebno definisati apstrakcije. Apstrakcije
predstavljaju pojednostavljenje pojedinih pojmova na važne informacije o njima,
koji se odnose na one dijelove pojma koji su bitni za domen interesovanja, dok
su nebitni detalji zanemareni. Time se istraživač pojma može usredsrijediti na
za njega, bitne detalje pojma, zanemarujući sve nebitne elemente koji mogu
zamagliti sliku pojma. Često se pojmu dodaju i novi koncepti koji su bitni za
namjeru, ne vodeći pri tome računa o brojnim nebitnim karakteristikama. Takav
način abstrakcije definiše se kao model.
U toku analize ili korištenja modela, korisnik
se usmjerava na podmodele. Time se koristi osbina abstrakcije da se može
promatrati hijrarhijski. Definišu se nivoi modela, gdje se svaki
nivo sastoji od više podmodela. U daljem radu korisnik modela se usmjerava prema podmodelu koji je
domen njegovog interosavanja.
Primjer nivovske absrakcije kod softverskih
dizajnera predstavlja koncept procedure i/ili funkcije, koji
dozvoljava programeru kreiranje operacija proizvoljne složenosti. Procedura se
poziva sa minimalnim brojem informacija (i povratnih podataka), što omogućava
njeno razumijevanje, ali u samoj njoj (niži nivo apstrakcije), kompleksni
pojmovi se mogu definisati novim procedurama. Nivoi apstrakcije se spuštaju do primitivnih
elemenata na kojima se bazira model.
Jezici visokog nivoa (High-level Languages)
daju finu prezentaciju abstrakcije primjene algoritama nad podacima. Primitivne
operacije jezika visokog nivoa, koje predstavljaju jednu instrukciju, često na
modelima nižeg nivoa zahtjevaju puno koraka za svoje izvršenje. Pascalski iskaz
napisan u jednoj liniji:
y:=ax+b
sastoji se od više
primitivnih operacija:
·
množenje konstante a sa varijablom x;
·
dodavanje konstante b proizvodu;
·
pridruživanje vrijednosti varijabli y.
Svaki od navedenih
koraka predstavlja barem po jednu liniju (instrukciju) u asemblerskome jeziku.
Prva linija se prevodi u
mul a,x
U zavisnosti od
arhitekture procesora, navedena instrukcija se prevodi kod:
·
troadresnih mašina: mul a,a,x
·
dvoadresnih mašina: mul a,x
·
jednoadresnih mašina: load a
mul x
sto a
Sljedeći nivo je mašinski kôd gdje su
mnemonici i operandi binarno kodirani. Kod daljnjih nivoa apstrakcije prelazi
se na hardver i microkod izvršavanja pojedinih operacija.
Navedeni nivoi se mogu predstaviti šematski kao na slici 1.
Programski jezici visokog nivoa su prilagođeni
programerima za što jednostavniju realizaciju algoritama nad podacima kako bi
se zadovoljila željena funkcija (obrada). Program koji prevodi kod napisan u
jeziku visokog nivoa u jezik razumljiv za određenu računarsku arhitekturu naziva
se kompajler. Kod koji se dobije iz kompajlera za svaku operaciju nad
podacima definiše neki simbol, pa se nazva simbolički jezik ili asembler. Kako
on implicitno odražava arhitekturu računara, to on predstavlja međuvezu između
računarskog hardvera i softvera i precizno definiše šta računarske instrukcije
rade i kako se specificiraju. Sljedeća faza je prevođenje asemblerskog programa
posredstvom asemblera u mašinski program, u kome je svaka instrukcija
direktno razumljiva hardveru.
Ovo je tačka gdje prestaje softver a počinje
hardver, čije granice nisu jasne. Često mikrokod iste instrukcije jedni
definišu kao softver a drugi kao hardver, u zavisnosti da li se posmatra sa
softverske ili hardverske strane apstrakcije. Dok neki dijelovi programa (u
mašinskome jeziku) za izvršavaje pozivaju hardverske sklopove, na drugoj
mašini, za isti dio postoji podprogram (softverska emulacija) koja to obrađuje.
Program se sastoji od kolekcije varijabli,
skupa instrukcija (rečenica) koje djeluju nad tim varijablama, i pravila koja
definišu redosljed primjene (izvršavanja) instrukcija. Ako za svaku instrukciju
postoji jedinstven identifikator (labela) i svaka ima implicitno definisane
varijable, inicijalno se definiše i implicitna varijabla za labelu
prve instrukcije koja će se izvršiti. Kada program starta, izvrši se prva
instrukcija i modifikuje jedna ili više varijabli. Implicitnoj varijabli koja
označava instrukciju koja treba da se izvrši, dodjeljuje se labela sljedeće
instrukcije za izvršenje. Ovaj se proces nastavlja sve dok računar ne dobije
instrukciju koja mu kaže da se zaustvi. Na taj način, izvršavanje programa
predstavlja sekvencu promjena stanja skupa varijabli. Skup varijabli,
uključujući i varijablu koja označava sljedeću instrukciju za izvršenje
definiše stanje programa. Instrukcija predstavlja način na koji se
manipuliše varijablama. Pravila kojima su definisane instrukcije predstavljaju programsku
organizaciju računara - POR. Interfejs glavnih računarskih komponenti
baziran na POR'u predstavlja arhitekturu računara.
Materijal se sastoji iz šest poglavlja. U
prvome poglavlju se razmatraju kodiranja informacija, gdje je posebna pažnja
posvećena binarnim brojevima. Dati su i osnovni logički sklopovi za realizaciju
primitivnih operacija kao što su logičke funkcije i sabiranje.
Druga glava je posvećena osnovnim elementima
Von Neummann'ove arhitekture.
Odnosu instrukcija i podataka u obradi
informacija posvećena je treća glava. Na osnovu poljske notacije i parametara
instrukcije prikazane su podjele računarskih arhitektura.
Kako se ne bi vezali za određenu arhitekturu,
to je u sljedećoj, četvrtoj glavi, uvedena definicija virtuelne mašine. Ovo je
poglavlje srž za razumijevanje arhitekture, pa njemu i treba posebno posvetiti
pažnju. Definisan je hipotetički procesor koji se bazira na 16'to
bitnoj riječi, pša je nazvan hp16. Da bi se sagledale napredne računarske
arhitekture, to je bazni procesor proširen sa keš memorijom i nazvan je hp26.
Sljedeće naprednije arhitekture sadrže koncepte protočnosti – hp46; te skalarne
elemente – hp66. Zato je opšti naziv hipotetičke mašine hpx6. U ovome poglavlju
je izvršena analiza izvršenja instrukcija kao i kodiranje.
Virtuelnom konceptu memorije je posvećena peta
glava. U ovome poglavlju su dati načini adresinja, što u stvari predstavlja
osnove programske organizacije računara.
U šestome poglavlju su date strukture
podataka. Pošlo se od primitivnih elemenata skalarnog tipa, pa do složenih
struktura kao što su višedimenzionalni nizovi. Izneseni su i algoritmi pristupa
pojedinim elementima niza. Glava se završava razmatranjem tipova prekida toka
programa, gdje je posebna pažnja posvećena interaptima.
Da bi stekla slika kompletnog programa u
računarskome okruženju, u sedmoj glavi su obrađeni procesi prevođenja,
povezivanja, punjenjea u memoriju i izvršenja programa.
U ovome materijalu nisu obrađene instrukcije
posebno, što će možda biti urađeno u sljedećoj verziji. Razlog je tome, da je
cilj da čitaac shvati principe rada arhitekture, a ne da ulazi u detalje
programiranja. No, da ne bi bili uskraćeni oni koji žele detalje programiranja
u asembleru, u prilogu su prikazani detalji pojedinih instrukcija. Takođe je
dat istorijat kodiranja znakova o Feničana, preko Morzeovog kôda do ASCII
tabele, za koji više smatram da je interesantan nego neophodan. U prilozima su
dati i detalji koji se odnose na interapte i povezivanje, koji izlaze izvan
okvira glava u kojima je tretirana navedena materija.
Cilj ove knjige je da uz pomoć određenih
apstrakcija pojasniti principe računarske arhitekture. Odmah navodimo i da nije
cilj savladanje tehnike asemblerskog programiranja. Ali jeste cilj savladiti
principe asemblera koji su neophodni za razumijevanje računarske arhitekture. U
toj namjeri prvo će biti prezentovan brojni sistem koji koriste računari. Bez
razumijevanja tog poglavlja, sva ostala priča nije svrsishodna. Kako bi se
približila arhitektura računara, to će biti definisan pojednostavljen model
apstraktnog računara (u čijoj se do duše osnovi može prepoznati arhitektura PC
kompatibilnih računara). Pošto je kod apstrakcije definisanja modela bio cilj
pokazati primitivne instrukcije, to je on ogranoičavajući za razvoj programa.
Zato je u narednim poglavljima proširen skup instrukcija i osnovni principi
definsanja varijabli skupom instrukcija iz PC računarske arhitekture.
1. Predstavljanje podataka
Napredak i usavršavanje svih sistema se
temelji na komuniciranju. Preko komuniciranja je omogućeno dogovaranje i
usavršavanje postojećih sistema, kako bi se stvorili napredniji i/ili novi. Da
bi se savladao neki sistem, prvo se moraju definisati njegovi primitivni
elementi iz kojih se sastoje ostali. Tako se narodi dogovaraju na jezicima koji
se baziraju na 25 do 35 primitivnih glasova koji se grafički zapisuju kao
slova. Specijalnom opremom se snimaju znakovi komuniciranja ostalih živih bića,
traže primitivni elementi, kako bi se uspostavila komunikacija. Danas su u
svijetu razvijeni fonetski zapisi komunikacija (alfabeti), dok slikoviti nisu
našli veliku primjenu, jer sadrže previše primitivnih elemenata (Dodatak A1).
Najjednostavnije gramatike su one koje su uspostavile prislikavanje 1:1, tj.
jedan glas jedan znak. No, ako se želi minimizirati broj znakova, onda se broj znakova može
smanjiti na 2. Prvi uspješan takav sistem je Morse'ova azbuka. Ona se bazira na
dva primitivna simbola: tačku - što znači kratak zvuk; crtu - koja je tri puta
duža (zapravo postoji i treći znak - nikakav zvuk, što predstavlja razmak
između znakova). Sistem sa dva stanja, koji praktično prelazi u vođstvo što se
tiče upotrebe je binarni. Ljudi nisu ni svjesni koliko je on u upotrebi, jer se
čak i sve slike sa interneta baziraju na njemu: postojanje ili nepostojanje
signala, odnosno 1 i 0. To su primitivni znaci svekolike računarske tehnologije
preko kojih se izražavaju sva htjenja. Zato je njihovo razumijevanje osnovno
za sve one koji žele da i najmanje shvate arhitekturu računarske
tehnologije.
1.1 Brojni sistemi
Često se za računarsku tehnologiju kaže
digitalna, jer se zasniva na ciframa - digitima. Šta brojevi predstavljaju, pa
je moguće sve izraziti preko njih? Šta znači broj petnaest? Za
matematiku on uvijek znači jedno te isto, ali se može predstaviti na
neograničeno puno načina, pa navedimo neke:
|
15
7+8
1×101+5×100
15dec
XV
IIII IIII IIII
|
15.0
11 x 1.36363636
15×160
fhex
Петнаест
17oct
|
3×5
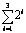
1×81+7×80
0xf
|
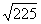
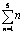
23+22+21+20
1111bin
24+20
|
Tabela
1. Različite tehnike zapisa broja petnaest.
Jedna od osnovnih namjera numeričke
prezentacije broja je mogućnost manipulisanja ciframa. Ako neko pokuša da
sabira ili množe, ili ne daj bože bazira ozbiljniji račun na rimskim
brojevima, koji su još uvijek u upotrebi, naići će na neočekivane probleme.
Mongi će pak pomisliti kada vide heksadecimalne brojeve, da je to nešto užasno
komplikovano.
Mada, poslije
boljeg sagledavanja njihove strukture, da se zaključiti da su čak podesniji od
decimalnih. Razvoj matematike u Evropi je krenio tek pošto su se upoznali sa
arapskim decimalnim brojnim sistemom. Ono što je epohalno u ovome sistemu jeste
radix, odnosno baza. Za sve brojeve manje od radixa, definišu se simboli
i oni idu od prezentacija za ništa (0dec), pa do r-1 (r
je radix). Koristi se osobina, da svaki broj stepenovan sa 0 daje 1,
tako da brojevi manji od r-1 su zapravo bi× r0. Ovi brojevi predstavljaju prvi razred
numeracije, što se kod dekadnih brojeva zove jedinice, odnosno jednocifreni
brojevi. Ovo se pravilo primjenjuje na brojeve sa dvije cifre (dvocifrene),
tako da se dvocifreni broj piše kao bibj, a u
stvari je bi× r1+ bj× r0. Odnosno opšti oblik broja N u
radix notaciji je:
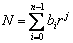 j Î
Z, b Î [0 .. r-1] (1)
j Î
Z, b Î [0 .. r-1] (1)
Ako je r = 10, onda
je to dobro poznati arapski dekadni sistem, a n se računa kao logrN.
Tako, broj petnaest iz prethodnog primjera za radix 2, 8, 10 i 16
izgleda ovako:
|
2 - binarni
bÎ{0,1}
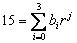 = =
1×20+1×21+1×22+1×23= 11112
|
8 - oktalni
bÎ{0,1,2,3,4,5,6,7}
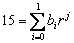
=7×80+1×81
= 178
|
10 - dekadni
bÎ{0,1,2,3,4,5,6,
7,8,9}
=5×100+1×101= 1510
|
16 - hexadecimalni
bÎ{0,1,2,3,4,5,6,7,8, 9,a,b,c,d,e,f}
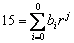
=f×160= f16
|
 Tabela 2. Predstavljanje broja 15 (tabela 1) u brojnim sistemima sa
radixom.
Tabela 2. Predstavljanje broja 15 (tabela 1) u brojnim sistemima sa
radixom.
1.1.1 Konverzije između brojnih sistema
Jedan brojni sistem je definisan radixom, što
implicira da je on i relevantan parametar kod prelaska sa jednog brojnog
sistema na drugi, što se zove konverzija. Kako je prema formuli (1), broj
predstavljen sumom proizvoda cifre (digita) i njoj odgovarajućeg eksponenta, to
je za prelazak na drugi brojni sistem (sa drugim radixom) dovoljno izvršiti
dijeljenje broja sa željenim radixom. Sljedeći algoritam upravo ovo
formalizuje.
Neka se broj N
radixa ra - (Na), konvertuje u broj radixa rb
- (Nb) :
i.
Broj Na se dijeli sa radixom rb.
Ostatak dijeljenja predstavlja cifru broja Nb pomnoženu sa
korakom dijeljanja umanjenim za 1 (korak dijeljenja predstavlja broj
ponavaljanja algoritma, odnosno za prvi je r1-1 Þ r0);
ii.
Količnik dijeljenja uzima se kao broj za
dijeljenje, korak dijeljenja se uvećava za 1, a parcijalna suma je proizvod
cifre i radixa;
iii.
Ide se na korak i, sve dok količnik ne bude 0.
Primjer: Broj 125410 konvertuje se
sistem sa bazom 5 na sljedeći način:
Korak
i: 1254: 5 Þ količnik 250, ostatak 4, cifra je 4×50 à 4;
Korak
ii: broj za dijeljenje 250, korak je 2;
Korak
iii: 250: 5 Þ količnik 50, ostatak 0, cifra je 0×51 à 0;
Korak
iv: broj za dijeljenje 50, korak je 3;
Korak
v: 50: 5 Þ količnik 10, ostatak 0, cifra je 0×52 à 0;
Korak
vi: broj za dijeljenje 10, korak je 4;
Korak
vii: 10: 5 Þ količnik 2, ostatak 0, cifra je 0×53 à 0;
Korak
viii: broj za dijeljenje 2, korak je 4;
Korak
ix: 2: 5 Þ količnik 0, ostatak 2, cifra je 2×54 à 2;
Korak
x: broj za dijeljenje 0, korak je 5;
Korak xi: kako je količnik 0, tj. nema broja za dijeljenje, te je
konverzija završena, a broj je: 2×54+0×53+0×52+0×51+4×50, tj
200045
Ovaj algoritam je efikasan kod konverzije u
binarne brojeve, jer je dijeljenje sa 2 jednostavno.
1.1.2 Hexadecimalni i oktalni sistem
Svima su poznata pravila algebre za dekadni
sistem. Uz malo truda može se naučiti tablica množenja i dijeljanja. Za
korištenje navedenih brojnih sistema prvo treba savladiti tehnike konverzija
između njih. Ovdje treba primjetiti da su binarni oktalni i hexadecimalni
sistemi vezani: radix 2 se nalazi u radixima 8 i 16, odnosno 8 je 23,
a 16 je 24, što znači da jedna oktalna cifra sadrži 3 binarne,
odnosno hexadecimalna 4 binarne. Time su pravila konverzije između binarnog i
oktalnog, te binarnog i hexadecimalnog veoma jednostavna:
·
Konvezija binarnog broja u oktalni
(heksadecimalni): Odvajaju se grupe po 3 cifre (kod
heksadecimalnog 4), i prema tabeli 3 upisuje se odgovarajući oktalni
(heksadecimalni) broj.
Primjer: Broj 0110100110112 grupiše
se oktalno 011 010 011 011 što predstavlja brojeve (tabela 3) 3 2 3 3, odnosno
32338. Heksadecimalno grupisanje cifara je: 0110 1001 1011 što
predstavlja broj 6 9 b, odnosno 69b16.
·
Konvezija oktalnog (heksadecimalnog) broja u
binarni: Ova je konverzija još jednostavnija: uzima se
cifra oktalnog (hexadecimalnog) broja i na njeno mjesto upisuje njen binarni
ekvivalent.
Primjer: Broj 2578 prevodi se: 28
je binarno 0×20+1×21+0×21, odnosno 010, 58 je 101, i 78 je
111, pa je binarni zapis 010 101 111, odnosno 101011112. Isti broj
257 ali hexadecimalno, tj. 25716 prevodi se binarno u 0010 0101
0111, odnosno 10010101112.
Konverzija između oktalnog i hekasadecimalnog
sistema se vrši tako što se konvertuje prvo u binarni sistem, a onda iz
binarnog u željeni.
|
0
1
10
11
100
101
110
111
1000
1001
1010
1011
1100
1101
1110
1111
10000
|
|
0
1
2
3
4
5
6
7
10
11
12
13
14
15
16
17
20
|
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
|
0
1
2
3
4
5
6
7
8
9
a
b
c
d
e
f
10
|
|
Tabela 3. Predstavljanje brojeva od 0 do 2010 binarno,
oktalno, dekadno i hexadecimalno
Radix dekadnog sistema, broj 10, ne
predstavlja eksponent broja 2, te su konverzije malo komplikovanije, to je
algoritam konverzije obrađen u sljedećem poglavlju.
1.1.3 Binarni sistem
Poput dekadnog sistema koji se udomaćio u
svakodnevnoj upotrebi, tako je u računarskom svijetu uobičajen binarni sistem.
Kao što smo vidjeli, on se bazira na istim principima kao i dekadni sa dva
izuzetka: binarni sistem dozvoljava samo dvije cifre 0 i 1 (za razliku od
decimalnog koji koristi 0-9) i stepen je od broja 2 za razliku od 10 (što
proizilazi i iz definicije radixa). Binarni sistem veoma fino podržava stanja
koja se mogu predstaviti u logičkom kolima: 1 odgovara postojanju naponskog
nivoa, a 0 znači da ga nema. Konverzija iz binarnog broja u dekadni je veoma
jednostavna. Za svaku cifru '1' koja se pojavi u binarnome nizu treba dodati 2n,
pri konverziji gdje n označava redni broj cifre počevši od 0 s desna u
lijevo. Tako binarni broj 110010102 predstavlja: 0×20+1×21+0×22 +1×23 +0×24+0×25+1×26+1×27=2+8+64+128
= 20210.
Za konverziju dekadnog u binarni može se
koristiti sljedeći algoritam, koji ćemo prikazati preko konverzije broja 1359.
Kod ovog algoritma se počinje od najvećeg stepena 2n koji nije veći
od broja koji se konvertuje. Taj se broj oduzima od broja koji se konvertuje i
razlika, koja je barem za jedan manja od 2n (inače je kraj
konverzije i treba dodati još n-1 znakova '0'), predstavlja ostatak
broja koji treba konvertovati. Ovaj se postupak ponavlja dok se ne dođe do 20:
i.
210=1024, a 211=2048. To
znači da 1024 najveći stepen broja 2 manji od 1359. Oduzima se 1024 od 1359 i
počinje ispisivati binarni niz sa '1' na lijevoj strani niza. Binarni niz =
'1', dekadna razlika 1359-1024=335;
ii.
Sljedeći manji stepen od 210 je 29=512,
što je više od 335, tako da se upisuje binarni niz = '10', dekadni rezultat
ostaje 335;
iii.
Sljedeći je 28=256, pa se
dodaje nizu '1' i oduzima dekadno 335-256=79, odnosno binarni niz = '101', a
dekadni ostatak 79;
iv.
128 (27) je veće od 79 pa se radi kao u
koraku ii: binarni niz = '1010', a dekadni 79;
v.
Sljedeći, 26=64 može se oduzeti, pa je:
binarni niz = '10101', a dekadni ostatak 15;
vi.
Sljedeća dva stepena 25=32 i 24=16
su veća od 15, te se dodaju dvije '0', tako da je: binarni niz = '1010100', a
ostatak još uvijek 15;
vii.
23=8, pa se dodaje '1' te je: binarni
niz = '10101001', a dekadni 7;
viii.
Takođe, 22=4, je manje od 7: binarni niz
= '101010011', a dekadni 3;
ix.
I 21 je manje od 3 te se dodajeje '1':
binarni niz = '1010100111', a dekadni 1;
x.
Najzad dolazi se do 20 čime se okončava
algoritam, a kako postoji ostatak to se nizu dodaje '1' a ne '0': binarni niz =
'10101001111' i nema dekadnog dijela.
1.1.4 Formati brojnih sistema
Iz definicije broja, da se primjetiti da cifra
sa vrijednošću 0, ne povećavaju vrijednost broja u parcijalnim sumama (samo se
stepen radixa povećava). To implicira da se poslije zadnje lijeve cifre broja
koja je različita od 0, može dodati neograničen broj 0. Tako se broj 15 može
napisati dekadno kao 15, 015, 000015.
Ovaj način pisanja je bitan kod binarnih
brojeva. Kao što će se vidjeti iz sljedećeg poglavlja, brojevi se u računarama
predstavljaju u bajtima i riječima. Zato se binarni broj skoro uvijek piše u
fixnom broju cifara. Prezentacija broja 15 binarno je: 1111 u formatu četiri
cifre (bita), 00001111 za osam cifara, 0000000000001111 za šesnaest cifara.
Često se i kod ostalih formata cifre grupišu.
Tako se decimalni brojevi grupišu od po tri cifre, pa se broj 1523703722
grupiše kao 1.523.703.722. Binarni brojevi se obično grupišu po četiri, što
odgovara jednoj hexadecimalnoj cifri (24=16). Binarni broj
0110110000001111 se grupiše kao 0110.1100.0000.1111, što odgovara
hexadecimalnome broju 6c0f16. Normalno, za oktalne brojeve odgovara
grupisanje od 3 binarne cifre, pa prethodni broj izgleda ovako
0.110.110.000.001.111, odnosno 660178.
Da bi se razlikovali brojevi u različitim
radixima, postoje dogovori oko načina pisanja. Radi lakšeg identifikovanja,
obično se poslije napisanog broja, kao sufix piše radix. Ako napišemo broj 1,
on ima istu vrijednost u svim sistemima. Međutim, za broj 11 trebamo dodati
sufix, broj 112 ima dekadni ekvivalent 3, 118 je 9, 1110
je 11 (difoltno) i 1116 je 17 dekadno. Kako su dekadni brojevi u
širokoj uptrebi, to ako se ne stavi nikakav sufiks zanači da je broj u
dekadnome zapisu. Za ostale brojeve se iza zadnje cifre dodaje sufix radixa. To
nije uvijek praktično, pa su kod pisanja programa primjenjuju druga pravila.
Binarni se brojevi predstavljaju tako što se poslije broja doda slovo b (nije
bitno veliko ili malo). Tako se 112 može napisati i kao 11b ili 11B.
Isto se pravilo primjenjuje za oktalne i hexadecimalne brojeve. Zato se broj 118
može napisati 11O, a 1116 kao 11h. Za hexadecimalne brojeve postoje
dodatna pravila: ako je prva cifra iz slovnog skupa {a,b,c,d,e,f}, onda
se prije broja mora dodati znak '0', kako bi se znalo da se ne radi o labeli
već o broju.
Kod binarnih brojeva postoje konvencije o
položaju bita unutar samog broja. Svakoj binarnoj cifri, koja se još zove i
bit, pridružuje se redni broj koji određuje poziciju u broju:
i.
krajni desni bit u binarnome broju ima bit poziciju
nula;
ii.
svaki sljedeći bit u lijevo dobija bit poziciju
uvećanu za 1.
Tako, peti bit (s
desna u lijevo) ima bit poziciju četiri. Osmobitni binarni broj ima pozicije od
nula do sedam:
x7 x6 x5 x4 x3 x2 x1 x0,
dok šesnaestobitni ima
pozicije od nula do petnaest:
x15 x14 x13 x12 x11 x10 x9 x8 x7 x6 x5 x4 x3 x2 x1 x0.
Bit nula se često označava (naj)Manje
Značajan (M.Z.) bit, dok se krajnji lijevi bit označava (naj)Više
značajan (V.Z.) bit. Ostali biti se označavaju prem poziciji koju zauzimaju
unutar niza cifara.
1.2 Organizacija podataka
Veličina koju broj predstavlja je osnovna
karakteristika koja interesuje matematiku i uopšte nije bitno koliko je
potrebno cifara da bi se taj broj napisao. U sferi računarskih nauka
interesantan je broj bita sa kojima se predstavlja broj (binarni). Tako se
pored jednog bita kriste grupe od po 4 bita (nibl), 8 bita (bajt), 16 bita
(riječ), itd.
1.2.1 Biti
Na početku je rečeno, da će se pri svim
razmatranjima poći od primitivnih elemenata, koji su gradivni materijal
složenih struktura. Osnovni, primitivni elemenat u predstavljanju informacija
je bit. On je poput atoma osnova, koja ulazi u sastav svih tipova podataka i sastoji se od dva
stanja: 1 i 0.
Naravno, ovo je brojna prezentacija. Kako informacije
mogu biti vezane za različite pojmove, to bit predstavlja dva stanja koja su
definisana pogledom na informaciju. Tako se kod bôja bitom mogu
definisati crvena i zelena. Ta definicija (bit koji predstavlja
crveno i zeleno), u slučaju semafora ima drugo značenje. Zato se treba zadržati
koegzistentnost kod definicija: pojam koji je definisan za jedan objekat, ne
smije se u programu koristiti za neki drugi objekat. Ovo se odnosi i na logičku
definiciju bita koji definiše dva stanja: tačno i netačno. Ako je
tačno definisano sa binarnom vrijednošću 1 a netačno
0, onda se ne smije na drugome mjestu za tačno koristiti 0, a netačno 1
(odnosno kod intedžera 0 i -1 ).
Ovo ne znači da se sa bitima mogu predstaviti
samo dva stanja. Dva stanja se predstavljaju sa 1 bitom. Udruživanjem dva bita
mogu se predstaviti četiri stanja (22 = 4). Matematika nam kaže da
se sa bitima može ustvari, predstaviti proizvoljno puno stanja, jer broj 2n
raste prema ¥. Da se primjetiti, da se udruživanjem 10 bita može predstaviti 210
stanja, što iznosi 1024. Ova veličina se označava kao 1k (naglašavamo, kod
binarnih brojeva k nije 1000 nego 1024). Ako se iskoristi osobina
stepena da je 2a+b = 2a×2b
to se da zaključiti da se recimo sa 32 bita može predstaviti (232
= 210×210×210×22 = 1k×1k×1k×4 = 1G×4 = 4G) četiri gige stanje (preciznije 4.294.967.296, jer je k=1024).
1.2.2 Nibli
Nibl (nibble) predstavlja grupisanje četiri
biti radi jednostavnijeg predstavljanja informacija. Da se zaključiti, da oni u
stvari predstavljaju jednu hexadecimalnu cifru. Druga
primjena nibla je kod BCD (binary coded decimal) koda. Njime se predstavljaju
dekadne cifre 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a preostalih šest stanja ostaje
neiskorišteno.
1.2.3 Bajti
Bajt predstavlja najmanju adresibilnu grupu
u memoriji koja se i sastoji od osam bita. Ako se želi operisati ssa manje od 8
bita, odnosno jednog bajta, to se moraju maskirati nepotrebni biti, kako bi se
pristupilo željenoj grupi bita ili samo jednome bitu. Ovo se odnosi i na nibl,
jer on nije adresibilan i arhitekture računara ne podržavaju direktan pristup
ničemu što je manje od bajta. To znači da je u programskom smislu bajt
primitivna gradivna jedinica za strukture podataka.
U početku razvoja računarstva, kada su se
koristili papirni mediji za ulaz (bušene kartice i trake), informacije su se
predstavljale sa velikim slovima, brojevima i specijalnim znacima, što je
činilo 32 znaka. Zato je za njihovo binarno kodiranje bilo dovoljno 6 bita. Kako se pojavila potreba i za
malim slovima, to je trebao još jedan bit. No logično je onda uzeti za osnovnu
jedinicu 8 bita jer se sastoje od dva nibla. Tako su organizovani kodovi za
specijalne karaktere, brojeve, mala i velika slova, što ukupno čini 128 kodova.
Preostalih 128 kodova (do 256) čine grafički karakteri. Tabela koja sadrži u
sebi sve ove kodove je poznata pod nazivom ASCII (American Standard Code for
Information Interchange) tabela u Dodatku A2.
7 6 5 4 3 2 1
0 7 6 5 4 3 2 1 0
 a) b)
a) b)
V.Z.
bit M.Z. bit V.Z.
nibl M.Z. nibl
Slika
1. Položaj bita (a) i nibla (b) u bajtu
Na adresi od bajta najčešće se bazira i
organizacija memorije. Bajt je osnovna skupina bita za zapis informacija. Tako
se sa bajtom mogu predstaviti neoznačeni brojevi od 0..255, odnosno označeni
od -127..+127. Kao što se vidi na slici 1. bajt se satoji od 2 nibla, odnosno
dvije
hexadecimalne
cifre. Kako bit 0 predstavlja M.Z. bit, a bit 7 V.Z.
bit, to i nibl 0 predstavlja M.Z. nibl, a nibl 1
V.Z. nibl.
1.2.4 Riječi
Udruživanjem dva bajta dobija se riječ. To
znači da se ona sastoji od šesnaest bita, odnosno četiri nibla (slika 2). Najčešća
njena primjena u jezicima visokog nivoa je za predstavljanje intedžera. Pošto
se sastoji od dva bajta, efikasniji način njenog korištenja je, ako se kod
adresiranja vodi računa, da se M.Z. bajt nalazi na parnoj adresi.
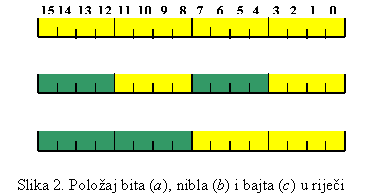 a)
a)
V.Z.
bit M.Z.
bit
b)
Nibl 3 Nibl
2 Nibl 1 Nibl 0
V.Z.
nibl M.Z. nibl
c)
V.Z.
bajt M.Z. bajt
Sa šesnaest bita (216) može se
predstaviti 65.536 stanja: neoznačeni brojevi 0..65536, označeni brojevi
-32768..32767, ili pak dva ascii znaka.
Bit 15 je V.Z. bit, a bit 0 M.Z. bit, a kod bajta, desni bajt je V.Z. a lijevi
M.Z. bajt.
1.2.5 Duple riječi
Kao što se da iz imena zaključiti, dupla
riječ predstavlja skup od dvije riječi ili četiri bajta ili osam nibla ili 32
bita (slika 3). Sa njom se može dosegnuti broj (ili adresa) do 4.294.967.295,
odnosno označeni brojevi od -2.147.483.648.. 2.147.483.647. Duple riječi (a često
četvoroduple) se koriste za predstavljanje realnih brojeva.
31
23 15 7
0
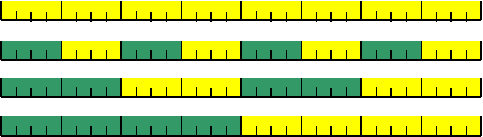 a)
a)
V.Z.
bit
M.Z. bit
b)
Nibl 7 6
5 4 3 2 1
0
c)
Bajt 3
2 1 0
d)
Riječ
1 0
Slika
3. Položaj bita (a), nibla (b), bajta (c), i riječi (d) u
duploj riječi
1.3 Osnovne operacije
Osnovne logičke operacije sa binarnim
brojevima su: i/and, ili/or, ekskluzivni-ili/xor kao diadične, ne/not kao monadična, čija su
pravila definisana Boolean'ovom algebrom. Ovo su primitivne operacije i imaju
svoj ekvivalent u računarskom hardveru. Dat je prikaz i grupe operacija koje se
baziraju na pomjeranju. Na kraju je definisana i osnova aritmetička operacija:
sabiranje kao primitivna, dok se ostale aritmetičke operacije mogu dobiti
kombinovanjem prethodnih, uz definisanje negativnih brojeva i oduzmanja kao
sabiranje sa komplementom.
1.3.1 Logičke operacije
Monadična logička operacija je negacija,
odnosno ne/not. Ona varijabli pridružuje komplementarnu vrijednost (jer se radi
o binarnome sistemu), tj. ako je vrijednost 1 zamjenjuje je sa 0 i obratno.
Logičko not kolo je prikazano na slici 4(a).
Tabela istine za
diadične logičke operacije je data u tabeli 4. Rečenice za pojedine logičke
operacije (za tačnu vrijednost koristi se oznaka '1') su:
·
i/and: Ako je prvi operand jedan i drugi operand
jedan, onda je i rezultat jedan, inače je rezultat nula;
·
ili/or: Ako je prvi operand, ili drugi operand,
ili oba jedan, onda je i rezultat jedan (tačno), inače je rezultat nula
(netačno);
·
exluzivni-ili/xor: Ako su operandi isti onda je
rezultat nula (netačno), inače ako operandi imaju različite vrijednosti, onda
je rezuktat jedan (tačno);
|
p
|
q
|
pÙq
|
pÚq
|
pÄq
|
|
0
0
1
1
|
0
1
0
1
|
0
0
0
1
|
0
1
1
1
|
0
1
1
0
|
Tabela
4. Tabela istine za and, or i xor
 Da se zaključiti za and, ako je jedan operand nula,
onda nije bitan drugi operand, rezultata je uvijek nula, za razliku od or'a,
ako je jedan operand '1', onda šta god bio drugi, rezultat je jedan. Ova se
osobina koristi za setovanje ('postavljanje') i brisanje ('skidanje') bita. Xor
se pak može iskoristiti da se ustanovi da li se operandi razlikuju, jer on daje
jedan samo kada su operandi različiti.
Da se zaključiti za and, ako je jedan operand nula,
onda nije bitan drugi operand, rezultata je uvijek nula, za razliku od or'a,
ako je jedan operand '1', onda šta god bio drugi, rezultat je jedan. Ova se
osobina koristi za setovanje ('postavljanje') i brisanje ('skidanje') bita. Xor
se pak može iskoristiti da se ustanovi da li se operandi razlikuju, jer on daje
jedan samo kada su operandi različiti.
1.3.2 Operacije nad bitima
Prethodno razmatranje logičkih operacija odnosilo se na
operande sa jednim bitom. U praksi se najčešće susreću operacije nad skupinama
bita kao što su bajti ili riječi. Ako želimo 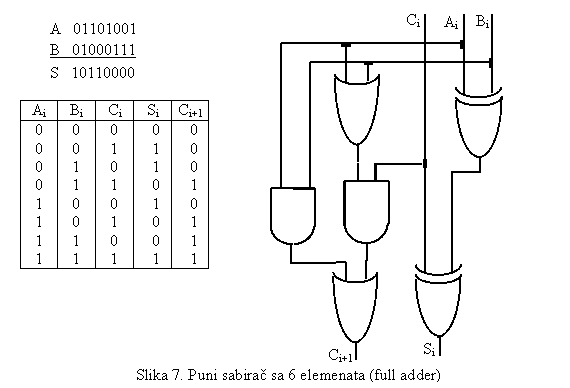 da poredimo dva
bajta onda će to izgledati kao na slici 5.
da poredimo dva
bajta onda će to izgledati kao na slici 5.
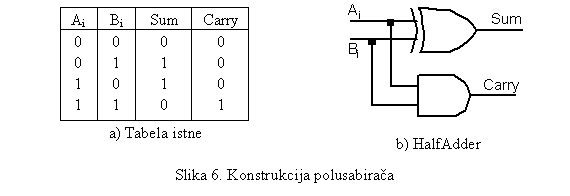
Razmotrimo sabiranje binarnih brojeva A i B
(lijevo). Može se primjetiti da kod zbira, kombinacije '0' i '0', i '1' i '1'
uvijek daju '0', dok '0' i '1' (važi pravilo komutacije) daju '1'. To upravo
odgovara definiciji xor'a. Međutim, kada se imaju u zbiru dvije jedinice, onda
se ima i jedan bit prijenosa (carry). No, kako za ulaz od dvije jednice, izlaz
jedinicu daje and funkcija, to se sabirač (adder) može realizovati sa jednim
xor i jednim and elementom (slika 6). Pošto se prijenos pojavljuje kao treća
varijabla u sabiranju, to elemenat sabiranja mora imati tri ulazne varijable
(brojevi koji se sabiraju i prijenos) i dvije izlazne (rezultat sabiranja i
prijenos za sljedeći razred). Tako, elementi za sabiranje se sastoje od dva
sklopa: polusabirač - koji se koristi za M.Z. bit (jer nema prijenosa kao ulaz)
i puni sabirač, koji se koristi za ostale bite, kao što je i prikazano na slici
7. Odnosno, njihovom kombinacijom dobija se sklop za
|
|
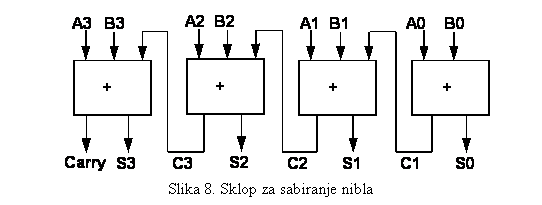 |
sabiranje dva sabirka od po četiri bita (jedan nibl) kao na slici
8.
U ovome poglavlju
su definisana dva primitivna sklopa: poređenje brojeva i sabiranje brojeva.
1.4 Predstavljanje negativnih brojeva
Matematički govoreći, do sada smo se bavili
skupom prirodnih brojeva N. To znači da je sada na redu proširenje skupa N na
skup Z (cijelih brojeva).
U dekadnome sistemu, negativni brojevi se
predstavljaju kao i pozitivni, s tim što ispred cifara upisuje oznaku da su
negativi, znak '-' (u stvari i pozitivni brojevi imaju znak '+', ali to je
difoltni znak pa se ne piše). Kako binarni sistem ima samo dva znaka: '0' i
'1', to se mora naći način da se preko ova dva znaka proširi skup N na Z. Radi
pojednostavljenja, u ovome poglavlju ćemo posmatrati brojeve na jednome niblu,
sa šesnaest različitih vrijednosti, i na njemu pokazati predstavljanje
pozitivnih i negativnih brojeva.
1.4.1 Predznak i vrijednost
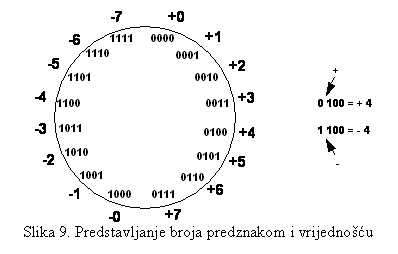 Najednostavniji način predstavljanja negativnih
brojeva je ako jedan bit V.Z. (krajnji lijevi) predefinišemo sasmo za predznak.
Tako, ako V.Z. bit ima znak '0' onda je pozitivan broj, a znak '1' negativan (
ne postoji difoltna vrijednost ). Ostali biti predstavljaju vrijednost broja.
grafičku Sljedeća slika (slika 9) predstavlja prezentaciju navedenog na
kružnici. Sa n bita može se predstaviti broj +/- 2n-1. Ovakav
način je zadržao sve karakteristike dekadnog predstavljanja brojeva. Međutim za
aritmetičke operacije je nepraktičan, pa ćemo razmotriti druge načine za
predstavljanje skupa Z u binarnome sistemu.
Najednostavniji način predstavljanja negativnih
brojeva je ako jedan bit V.Z. (krajnji lijevi) predefinišemo sasmo za predznak.
Tako, ako V.Z. bit ima znak '0' onda je pozitivan broj, a znak '1' negativan (
ne postoji difoltna vrijednost ). Ostali biti predstavljaju vrijednost broja.
grafičku Sljedeća slika (slika 9) predstavlja prezentaciju navedenog na
kružnici. Sa n bita može se predstaviti broj +/- 2n-1. Ovakav
način je zadržao sve karakteristike dekadnog predstavljanja brojeva. Međutim za
aritmetičke operacije je nepraktičan, pa ćemo razmotriti druge načine za
predstavljanje skupa Z u binarnome sistemu.
1.4.2 Komplement jedan
Razmotrimo model dekadnog brojača (radi
jednostavnosti neka ima smo dvije cifre). Neka to bude recimo brojač na
benzinskoj pumpi. Neka brojač pokazuje cifre 7 i 6 i neka korisnik 'natoči' 35 l
goriva. Šta će brojač pokazivati? Pokazivati će 11 (a ne 111, jer ima samo dva
mjesta). Neka (po definiciji komplementa) komplement svakog broja bude njegova
dopuna do njegovog punog opsega. Pokušajmo sada oduzeti broj 35 od 76. Broj 35
u dekadnome komplementu će predstavljati broj 75 (00 - 35, na brojčaniku ne
postoji znak '-'). Sabiranjem broja 76 i 75 (komplement od 35) dobija se broj
41 (broj stotica se ne vidi), što je u stvari 76 -35. To znači da je natočeno
76-41=35 l goriva.
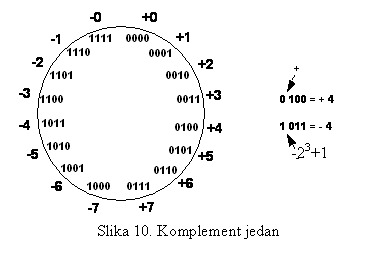 Ista pravila možemo primjeniti za binarni sistem.
Kod binarnih brojeva imamo jednu pogodnost: nalaženje komplementa je
nevjerovatno jednostavno - samo se zamijene '0' i '1' (doda se not kolo ispred
broja). Oduzimanje brojeva se sada svodi na sabiranje. Međutim, ovdje se
pojavljuje problem 'dvije nule' (vidi sliku 10). To zadaje probleme pri
računanju, jer kod prekoračenja (carry bit), zbog ove druge nule treba
rezultatu dodati još carry bit. V.Z. bit ne znači samo znak '-' broja, već -2n+1,
dok se ostatak broja dodaje ovoj vrijednosti. Tako se broj -4 (slika 10), piše
1011b, gdje je V.Z. bit (-23+1) -7, i doda se još preostali dio broja
(011b), tj. 3, tako da se dobije -4.
Ista pravila možemo primjeniti za binarni sistem.
Kod binarnih brojeva imamo jednu pogodnost: nalaženje komplementa je
nevjerovatno jednostavno - samo se zamijene '0' i '1' (doda se not kolo ispred
broja). Oduzimanje brojeva se sada svodi na sabiranje. Međutim, ovdje se
pojavljuje problem 'dvije nule' (vidi sliku 10). To zadaje probleme pri
računanju, jer kod prekoračenja (carry bit), zbog ove druge nule treba
rezultatu dodati još carry bit. V.Z. bit ne znači samo znak '-' broja, već -2n+1,
dok se ostatak broja dodaje ovoj vrijednosti. Tako se broj -4 (slika 10), piše
1011b, gdje je V.Z. bit (-23+1) -7, i doda se još preostali dio broja
(011b), tj. 3, tako da se dobije -4.
1.4.3 Komplement dva
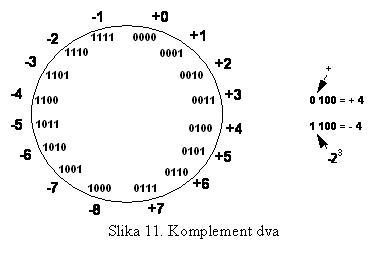 Poznato je da se sa n bita može predstaviti 2n
stanja, odnosno maksimalni broj 2n-1 (jer i za broj 0 treba
odvojiti jedno stanje). Ako želimo predstaviti i negativne brojeve, onda se
jedan bit odvaja za predznak, tako da za vrijednost ostaje 2n-1
bita. Tako broj ima 2n-1-1 (plus '0') pozitivnih i 2n-1
negativnih stanja:
Poznato je da se sa n bita može predstaviti 2n
stanja, odnosno maksimalni broj 2n-1 (jer i za broj 0 treba
odvojiti jedno stanje). Ako želimo predstaviti i negativne brojeve, onda se
jedan bit odvaja za predznak, tako da za vrijednost ostaje 2n-1
bita. Tako broj ima 2n-1-1 (plus '0') pozitivnih i 2n-1
negativnih stanja:
2n
=2×2n-1=2n-1+2n-1
(2)
Ovdje se da primjetiti da izbacivanjem
jedne nule, primjer sa slike 10 prelazi kao na slici 11, gdje se ima osam
negativnih brojeva (24-1), sedam pozitivnih (24-1-1) i još '0'. Ovaj način
prezentacije se praktično dobija iz komplementa jedan kada se broju doda još
jedan, te se zato zove komplement dva. Algoritam za dobijanje broja u
komplementu dva se svodi na dva koraka: invetuju se svi biti (1) i doda borj 1
(2). Iz ovako dobijenog broja se može dobiti polazni broj ako se još jednom
primijeni isto pravilo, a zadovoljena su i sva pravila aritmetičkih operacija
nad brojevima, pa se ovaj komplement zove i potpuni komplement. Na ovaj način
se operacija oduzimanja kod binarnih brojeva može tretirati kao specijalni
oblik sabiranja (što se vidi iz navedenih primjera).
Ako se sa N* označi komplement
dva broja N, onda je N*=2n-N. Tako, ako je N=7
dobija se:
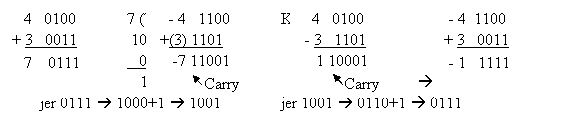
To potvrđuje i sljedeći primjer zbira svih kombinacija brojeva
4 i 3:
Ova razmatranja su se odnosila na 4 bita
(nibl), zbog jednostavnosti. Ništa se ne mijenja za 8, 16 ili proizvoljan broj
bita. Treba još jednom podvući da prvi bit ne znači '-' (kod negativnih
binarnih brojeva), već -2n, a preostali biti se dodaju na
ovaj broj. Tako, broj sa 10 bita 1000000000b je -512, a ako je M.Z. bit 1, tj.
1000000001b onda je -512+1 što daje 511.
 Kako V.Z. bit znači
predznak, to se mora voditi računa kod proširenja broja da se zadrži predznak,
što se susreće pod pojmom proširenje predznaka. Tako, ako se bajt
proširuje na riječ (slika 2), onda se kompletan V.Z. bajt ispunjava sa bitom
predznaka. To znači, ako je broj bio negativan, V.Z. bit je '1', onda se i V.Z.
bajt puni sa jedinicama (vrijednost -1), inače se puni sa nulom. Broj -3 na
niblu se piše kao 1101b, na bajtu kao 1111 1101b, na riječi kao 1111 1111 1111
1101b, odnosno heksadecimalno kao 0dh, 0fdh i 0fffdh. Ovdje se može izvući
pravilo za pojednostavljenje određivanja vrijednosti negativnog broja ako ima
više jedinica sa lijeve strane: ide se do prvog bita koji je '0'; uzima se bit
lijevo i nalazi njegova vrijednost kao -2m, gdje je m
redni broj bita sa desna u lijevo (brojeći od 0); tome broju se doda vrijednost
zbira preostalih bita. Po ovome
pravilu, broj -9 napisan na jednoj riječi se računa: 1111 1111 1111 0111b,
zadnji znak '1', poslije zadnje '0' je četvrta cifra; m=4, pa je -24
=-16; preostali dio broja je 7; -16+7=-9.
Kako V.Z. bit znači
predznak, to se mora voditi računa kod proširenja broja da se zadrži predznak,
što se susreće pod pojmom proširenje predznaka. Tako, ako se bajt
proširuje na riječ (slika 2), onda se kompletan V.Z. bajt ispunjava sa bitom
predznaka. To znači, ako je broj bio negativan, V.Z. bit je '1', onda se i V.Z.
bajt puni sa jedinicama (vrijednost -1), inače se puni sa nulom. Broj -3 na
niblu se piše kao 1101b, na bajtu kao 1111 1101b, na riječi kao 1111 1111 1111
1101b, odnosno heksadecimalno kao 0dh, 0fdh i 0fffdh. Ovdje se može izvući
pravilo za pojednostavljenje određivanja vrijednosti negativnog broja ako ima
više jedinica sa lijeve strane: ide se do prvog bita koji je '0'; uzima se bit
lijevo i nalazi njegova vrijednost kao -2m, gdje je m
redni broj bita sa desna u lijevo (brojeći od 0); tome broju se doda vrijednost
zbira preostalih bita. Po ovome
pravilu, broj -9 napisan na jednoj riječi se računa: 1111 1111 1111 0111b,
zadnji znak '1', poslije zadnje '0' je četvrta cifra; m=4, pa je -24
=-16; preostali dio broja je 7; -16+7=-9.
 1.5 Pomjeranje i rotiranje bita
1.5 Pomjeranje i rotiranje bita
Poznato je kod dekadnih brojeva da je
množenje i dijeljenje sa 10 (radixom) veoma jednostavno. Zapravo, broj ostaje
(znakovno) isti, samo se na M.Z. poziciji dodaje '0' kod množenja, a otkida ta
cifra kod dijeljenja. Tako množenje broja 123 sa radixom daje 1230, a
dijeljenje daje 12 (skup cijelih brojeva).
Kod binarnih brojeva radix je 2. To znači
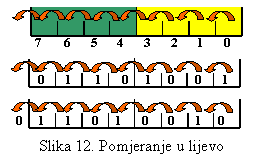
da pomjeranje svih bita za jedno mjesto ulijevo zapravo znači monženje sa 2.
Ova operacija se zove pomjeranje ili šiftovanje. Naravno, pomjeranje može biti
za jedno ili više mjesta, odnosno množenje sa 2n. Kako je
binarni broj fiksan, to kod pomjeranja u lijevo V.Z. bit 'napušta' broj i ide u
carry, a na mjesto M.Z. bita dolazi broj 0.
 Kombinovanjem sabiranja i pomjeranja u lijevo (množenje sa dva) može
se realizovati operacija množenja. Tako se broj 5 može pomnožiti sa brojem 10
na slljdeći način: 10 se može rastaviti na faktore 2 i 5. Broj 5 se može
ostvariti pomjeranjem za dva mjesta u lijevo (množenje sa 22)
i dodavanje samog broja. Ovako dobijeni broj se pomjeri još jednom u lijevo i
to je množenje sa 10.
Kombinovanjem sabiranja i pomjeranja u lijevo (množenje sa dva) može
se realizovati operacija množenja. Tako se broj 5 može pomnožiti sa brojem 10
na slljdeći način: 10 se može rastaviti na faktore 2 i 5. Broj 5 se može
ostvariti pomjeranjem za dva mjesta u lijevo (množenje sa 22)
i dodavanje samog broja. Ovako dobijeni broj se pomjeri još jednom u lijevo i
to je množenje sa 10.
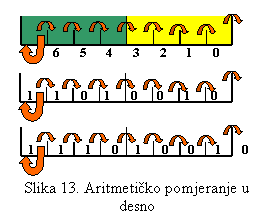 Pomjeranje u desno znači zapravo dijeljenje sa 2
(odnosno pomjeranje za n mjesta dijeljenje sa 2n). Ako se
primjene ista pravila kao i kod pomijeranja u lijevo, M.Z. bit će ići u carry,
dok će se V.Z. bit puniti sa 0. Ovdje se pojavljuje problem kod negativnih
brojeva; ako je broj negativan, V.Z. bit sadrži 1, i ako se tu ubaci 0, broj
postaje pozitivan. Zato su za pomjeranje u desno definisana dva tipa pomjeranja: logičko pomjeranje u desno i
aritmetičko pomjeranje u desno. Kod aritmetičkog pomjeranja V.Z. bit se pored
toga što se pomjera, istovremeno i kopira u samoga sebe (kao na slici 13). Kako
ova operacija omogućava dijeljenje, to se kombinovanjem definisanih primitivnih
operacija mogu obaviti većina aritmetičkih radnji: sabiranje, oduzimanje,
množenje, dijeljenje …
Pomjeranje u desno znači zapravo dijeljenje sa 2
(odnosno pomjeranje za n mjesta dijeljenje sa 2n). Ako se
primjene ista pravila kao i kod pomijeranja u lijevo, M.Z. bit će ići u carry,
dok će se V.Z. bit puniti sa 0. Ovdje se pojavljuje problem kod negativnih
brojeva; ako je broj negativan, V.Z. bit sadrži 1, i ako se tu ubaci 0, broj
postaje pozitivan. Zato su za pomjeranje u desno definisana dva tipa pomjeranja: logičko pomjeranje u desno i
aritmetičko pomjeranje u desno. Kod aritmetičkog pomjeranja V.Z. bit se pored
toga što se pomjera, istovremeno i kopira u samoga sebe (kao na slici 13). Kako
ova operacija omogućava dijeljenje, to se kombinovanjem definisanih primitivnih
operacija mogu obaviti većina aritmetičkih radnji: sabiranje, oduzimanje,
množenje, dijeljenje …
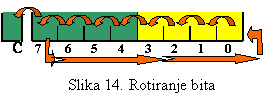 Kod pomjeranja (lijevo ili desno) zadnji bit se
prebacuje u carry fleg i onda kod sljedeće operacije nestaje. Nekada je korisno
zadržati sve bite, pa se takvo pomjeranje naziva rotiranje bita. Kao i kod
pomjeranja i ovdje postoji rotiranje lijevo i desno. Kod rotiranja lijevo, V.Z.
bit pored toga što se kopira u carry, kopira se i u M.Z. bit (kao na slici 14).
Tako se povezivanjem V.Z. bita i M.Z. bita, svi biti zatvaraju u krug. Nema
razlike između logičkog i aritmetičkog rotiranja bita.
Kod pomjeranja (lijevo ili desno) zadnji bit se
prebacuje u carry fleg i onda kod sljedeće operacije nestaje. Nekada je korisno
zadržati sve bite, pa se takvo pomjeranje naziva rotiranje bita. Kao i kod
pomjeranja i ovdje postoji rotiranje lijevo i desno. Kod rotiranja lijevo, V.Z.
bit pored toga što se kopira u carry, kopira se i u M.Z. bit (kao na slici 14).
Tako se povezivanjem V.Z. bita i M.Z. bita, svi biti zatvaraju u krug. Nema
razlike između logičkog i aritmetičkog rotiranja bita.
1.6 Realni brojevi
Realni binarni brojevi se mogu predstaviti
na isti način kao i realni decimalni. Prema definicije predstavljanja brojeva
(1) broj 123,45 je 1×102+2×101+3×100+4×10-1+ 5×10-2. Kod realnih binarnih brojeva ne postoji zarez koji
razdvaja pozitivne i negativne exponente, već je to definisano formatom,
odnosno definisan je broj bita za pozitivne, kao i broj bita za negativne
eksponente. Tako se binarni broj 0110,0111b piše kao 01100111b, s time što se
zna da su 4 zadnja bita sa negativnim eksponentima (format je 8:4). Dekadno to
je broj 6,4375, jer je 01100111 = 0×23+1×22+1×21+0×20+0×2-1+1×2-2+1×2-3+1×2-4 .
Predstavljanje realnih brojeva sa 'zamišljenim zarezom’, osim
teoretske, nema nikakvu drugu primjenu, jer se u praksi ne koristi. Realni
binarni brojevi se predstavljaju u 'e' formatu. Dakle koristi se osobina da se
broj predstavi iz dva dijela: mantoise koja je normalizirana (tj. 0 <
decimalni broj £ 1) i eksponenta. Iz ove se osobine da zaključiti da je prva cifra
mantise u binarnom obliku uvijek 1. To se ne pisanjem ovog broja da uštedeti
jedno mjesto i zove se skriveni bit. Broj se predstavlja sa duplom ili
četvoroduplom riječju. V.Z. bit se koristi kao predznak mantise, a sljedeći bit
do njega je predznak eksponenta. Preostali biti su raspoređeni tako, što je 1/3
bita rezervisana za eksponent, a ostatak, tj. 2/3 za mantisu. Broj 17,15 u 'e'
formatu prikazan je na slici 15. Cijeli dio broja 17 zauzima 4 cifre (10001 sa
skrivenim bitom), pa je eksponent 4. S obzirom da se eksponent (po dogovoru) 1
piše kao V.Z. bit 1 ostalo nule (za bajt je to broj 10000000 -128), to se broj
4 predstavlja kao 131, odnosno binarano 10000011. Cijeli dio mantise je već rečeno
da je 17, odnosno (1)0001. Decimalni dio je ond 0011001100110011001.
1.7 Pitanja i zadaci
1.
Kakav je odnos nivoa apstrakcije između
procedure i instrukcije?
2.
Kôd množenja dva realna broja može da bude
realizovan hardverski ili softverski. Zašto se dizajneri računara odlučuju za
jednu ili drugu varijantu?
3.
Je li dekadni brojni sistem upravo ono što je
najpogodnije. Koji biste Vi sistem predložili čovječanstvu za upotrebu i zašto?
4.
Zašto se niz znakova fba tretira kao
labela, a 0fba kao cifra?
5.
Kakva je razlika kod multipla k (kilo)
kod računarskih nauka, i u ostaloj upotrebi?
6.
Koji je primitivni elemenat za predstavljanje
informacije kod struktura podataka?
7.
Koje su primitivne logičko-aritmetičke
instrukcije u računarskim arhitekturama i kako se mogu realizovati osnovne
aritmetičke operacije?
8.
Ako negativni broj ima puno zanakova ‘1’ sa lijeve strane, koliko se tih
znakova može izbrisati, a ad se vrijednost broja ne promijeni?
2. Osnovni elementi računarskih arhitektura
Da bi se napisao program u asembleru,
neophodno je poznavanje mašine za koju se piše. Da bi se napisao dobar program
u asembleru, mora se dobro znati arhitektura mašine, do pojedinosti. Međutim,
ako se taj program treba izvršavati na nekoj drugoj mašini, onda se prije
prilagođenja programa, mora 'savladati' arhitektura te druge mašine. Kako nam
nije cilj savladavanje tehnike programiranja u asembleru, već principa, to nije
ni potrebno detaljno znanje arhitekture ni jednog računara, već principa
programske organizacije računara. Da bi to zadovoljili, u ovome poglavlju će
biti definisan model virtuelne mašine, koji će nam omogućiti sagledavanje
principa rada računara.
U ovome poglavlju su date bazne komponente
koje čine računar: centralna procesorska jedinica – CPJ (Central Processing
Unit – CPU), memorija, ulaz/izlaz U/I (Input/Output I/O) i sabirnica koja
povezuje navedene komponente. U zavisnosti da li se arhitektura procesorske
jedinice bazira na kompleksnosti instrukcija, ili brzini dekodiranja i obrade,
razvile su se dvije arhitekture: CISC (Complex Instruction Set Computers) i
RISC (Reduce Instruction Set Computers).
2.1 Bazne komponente sistema
Arhitektura je bazni dizajn operativnih
elemenata računarskog sistema. Današnji računari se bazirajuna teoretskim
postavkama Turingove mašine definisane kao automat sa konačnim stanjima.
Tipična arhitektura je VNA (Von Neumann Architecture), koja se bazira na tri
glavne komponente: CPJ, memoriju i U/I jedinice. Način na koji dizajner
kombinuje ove komponente daje performanse sistema (slika 16).
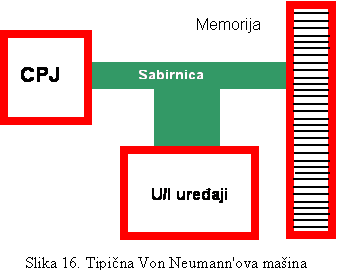 CPJ predstavlja srž VNA arhitekture, gdje se
odvijaju sve obrade, pa često u praksi procesor predstavlja sinonim za računar.
Podaci i instrukcije (koji definišu šta raditi sa podacima) nalaze se u
memoriji. Komunikacija sa vanjskim svijetom obavlja se preko U/I jedinica. U/I
jedinice zapravo predstavljaju specijalni oblik memorije, jer su na njima mogu
pohranjivati podaci kao i čitati iz njih. Glavna razlika je u tome, što su U/I
lokacije povezane sa jedinicama koje predstavljaju vezu sa vanjskim svijetom.
CPJ predstavlja srž VNA arhitekture, gdje se
odvijaju sve obrade, pa često u praksi procesor predstavlja sinonim za računar.
Podaci i instrukcije (koji definišu šta raditi sa podacima) nalaze se u
memoriji. Komunikacija sa vanjskim svijetom obavlja se preko U/I jedinica. U/I
jedinice zapravo predstavljaju specijalni oblik memorije, jer su na njima mogu
pohranjivati podaci kao i čitati iz njih. Glavna razlika je u tome, što su U/I
lokacije povezane sa jedinicama koje predstavljaju vezu sa vanjskim svijetom.
2.1.1 Sistemska sabirnica
Sistemska sabirnica varira u implementaciji
kod različitih tipova VNA mašina, ali se skoro uvijek sastoji od tri glavne
komponente: podatkovna sabirnica (data bus), adresna sabirnica (address bus) i
kontrolna sabirnica (control bus). Fizički, sabirnica predstavlja skup žica,
preko kojih se električnim signalima prenose informacije (podatkovna sabirnica)
između elemenata sistema. U različitim izvedbama nivo signala varira, tako, ako
se radi o TTL logici na 5V, nivo signala od 0,0 - 0,8V predstavlja logičku
nulu, dok od 2,4 - 5,0V predstavlja logičku jedinicu, a ostala stanja su
nedefinisana. Zbog različitih implementacija, ubuduće se neće koristiti izraz
naponski nivo, već logičko stanje.
2.1.1.1 Podatkovna sabirnica
Podaci predstavljeni bitima, između
različitih komponenti mašine, prenose se preko podatkovne sabirnice paraleno.
To znači, da je količina prenesenih podataka direktno zavisna od 'širine'
sabirnice, odnosno broja žica na sabirnici. Tako susrećemo sabirnice od 8, 16,
32, 64 i više bita (žica). Širina sabirnice ne mora da znači i 'veličinu'
procesora, jer recimo 16'to bitni procesor može prenositi podatke dva puta po 8
bita. Normalno, da se zaključiti da je 32'vo bitni procesor jači od 16'to
bitnog, jer može u istoj jedinici vremena prenijeti više podataka.
Često se prema sabirnici i procesori zovu
osmo, 16'to, 32'vo ili 64'ro bitni procesori. Širina sabirnice se podešava da
bude umnožak bajta, odnosno riječi. Ako bi bila 24'ro bitna sabirnica (3
bajta), onda bi 32'vo bitni procesor morao dva puta da pristupi memoriji za
prijenos jedne njegove riječi. Naravno da procesori mogu pristupiti podacima
preko sabirnice, koja odgovaraja njihovoj veličini, ali i tada oni mogu
pristupiti i manjim skupinama podataka, što znači da jači procesor može uraditi
sve što može i slabiji.
2.1.1.2 Adresna sabirnica
Da bi podatkovna sabirnica izvršila
prijenos podataka između procesora i neke memorijske lokacije ili U/I uređaja,
mora se odgovriti na jedno pitanje: 'Na koju lokaciju', ili 'Sa koje lokacije'
se vrši prebacivanje podataka. Odgovor na ovo pitanje daje adresna sabirnica.
Kako bi se obezbijedila razlika između pojedinih memorijskih lokacija i U/I
uređaja, sistem dizajner svakoj lokaciji pridružije jedinstven identifikator -
memorijsku adresu. Skup svih memorijskih adresa predstavlja adresni prostor. Sa
jednim elementom adresne sabirnice (bitom) može se pristupiti dvijema
lokacijama: 0 i 1. Sa adresnom sabirnicom od n elemenata može se
adresirati 2n lokacija. Tako se sa sabirnicom od 20 elemenata
može adresirati prostor 2x210, odnosno k×k, što daje 1Mb. Treba još
jednom napomenuti da je najmanja adresibilna jedinca bajt. Sada se koriste
sabirnice od 32 bita (4 Gb), mada su u uptrebi i od 48 bita.
Kada procesor želi pristupiti nakoj
memorijskoj lokaciji ili U/I uređaju, predaje adresu adresnoj sabirnici.
Logička kola pridružena memorijskoj lokaciji ili U/I uređaju prepoznaju ovu
adresu i daju instrukciju uređaju da smjesti podatke na, ili učita sa
podatkovne sabirnice. U svakom slučaju, svi ostali uređaji ignorišu ovaj
zahtjev, osim uređaja čija memorijska adresa odgovara vrijednosti postavljenoj
na adresnoj sabirnici.
2.1.1.3 Kontrolna sabirnica
Skup elektrinčnih signala koji kontroliše
kako procesor komunicira sa ostlim dijelovima mašine predstavlja kontrolnu
sabirnicu. Razmotrimo slanje i prijem podataka u i iz memeorije preko
podatkovne sabirnice. Mora se odgovoriti na pitanje 'da li se podaci pišu u,
ili čitaju iz memorije'. Zato postoje dvije linije na kontrolnoj sabirnici, čitanje
(read) i pisanje (write), koje specificiraju smjer kretanja
podataka. Postoje takođe linije za sistemski sahat (clock), interapte, statuse
itd. Tipovi linija zavise od procesora do procesara, ali postoji skupina koja
ima zajedničke karakteristike u svim arhitekturama.
Read/write kontrolne linije regulišu smjer
kretanja podataka na podatkovnoj sabirnici. Ako obije imaju logičku vrijednost
jedan, onda nema komuniciranja između procesora i memorijskih U/I. Ako je read
signal nizak (logička nula), onda se podaci kreću od memorijskih lokacija prema
procesoru. Ako je pak write signal nula, onda sistem šalje podatke od procesora
prema memorijskim lokacijama.
Ako je veličina procesora veća od riječi
(16, 32 ili 64 bita) onda se koristi bajt enable signal kako bi se moglo
raditi sa manjim skupom podataka (bajtom). Adresni prostor U/I uređaja zavisi
od dizajna mašne. Negdje je on riješen kao podskup ukupnog adresnog prostora, a
negdje je jedinstven.
2.1.1.4 U/I sabirnica
Kod većine arhitektura U/I (I/O) sabirnica
predstavlja specijalni dio (podskup) opšte sabirnice. Tako, kod Intelove
arhitekture U/I adresna sabirnica, predstavlja specijalni dio adresne
sabirnice, čija je širina 16 linija, za razliku od 20, 24 ili 32 linije kod
adresne sabirnice. Linije kontrolne sabirnice vrše odvajanje (prepoznavanje)
linija adresnoe sabirnice od U/I sabirnice. Izuzev kontrolnih linija i adresne
sabirnice, ostali dio sabirnica je identičan kao i kod memeorije, tj. dijeli
istu podatkovnu sabirnicu kao i dio kontrolnih signala.
2.1.2 Memorijski podsistem
Maksimalni adresni prostor koji se može
adresirati je 2n, gdje je n veličina adrsne sabirnice.
Najmanja adresabilna jedinica je bajt. Zato se memorija može zamisliti kao
linearni niz bajta od početne (nulte adrese) pa do krajnje, 2n-1.
Za sabirnicu od 20 bita Pascalska prezentacija memorije je:
Memorija
: array [0..1048575] of byte;
 Šta se dešava ako
želimo da na neku memorijsku lokaciju upišemo neku vrijednost? Za očekivati je
da treba na neki način koristiti sve tri sabirnice. Razmotrimo izvršavanje
Pascalske instrukcije 'Memorija[125] := 15' (slika 17):
Šta se dešava ako
želimo da na neku memorijsku lokaciju upišemo neku vrijednost? Za očekivati je
da treba na neki način koristiti sve tri sabirnice. Razmotrimo izvršavanje
Pascalske instrukcije 'Memorija[125] := 15' (slika 17):
·
podatkovna sabirnica: CPJ smješta vrijednost 15
na podatkovnu sabirnicu;
·
adresna sabirnica: adresa 125 se smješta na
adresnu sabirnicu;
·
kontrolna sabirnica: pošto podaci idu od procesora
prema memoriji, signal write se postavlja na nulu;
Za suprotnu radnju, da se pročita sadržaj
memorijske lokacije, odnosno Pascalski
'CPJ := Memorija[125]' bit će kao na slici 18:
·
adresna sabirnica: CPJ postavlja adresu 125 na
adresnu sabirnicu;
·
kontrolna sabirnica: sada podaci idu od memorije
prema procesoru, signal read se postavlja na nulu;
·
podatkovna sabirnica: u CPJ se ‘pokupi’
vrijednost sa podatkovne sabirnice;
 U navedenome primjeru operacije su bile nad jednim
bajtom. Kako je poznato, memorija može da bude organizovana i po riječima, ili
duplim riječima. Različite računarske arhitekture imaju različit pristup. Tako,
DEC na primjer, traži da adresa riječi bude parna, odnosno duplih riječi
djeljiva sa 4. Mi ćemo koristiti pristup koji dozvoljava da se adrese
preklapaju. To znači, ako se bajt nalazi na adresi 125, onda on zauzima samo tu
lokaciju. Ako je 125 adresa riječi, onda je M.Z. bajt na adresi 125, a V.Z.
bajt na adresi 126. Kada se radi o duploj riječi na istoj adresi, onda je M.Z.
bajt na adresi 125, a V.Z. bajt na adresi 125+3, tj. 128.
U navedenome primjeru operacije su bile nad jednim
bajtom. Kako je poznato, memorija može da bude organizovana i po riječima, ili
duplim riječima. Različite računarske arhitekture imaju različit pristup. Tako,
DEC na primjer, traži da adresa riječi bude parna, odnosno duplih riječi
djeljiva sa 4. Mi ćemo koristiti pristup koji dozvoljava da se adrese
preklapaju. To znači, ako se bajt nalazi na adresi 125, onda on zauzima samo tu
lokaciju. Ako je 125 adresa riječi, onda je M.Z. bajt na adresi 125, a V.Z.
bajt na adresi 126. Kada se radi o duploj riječi na istoj adresi, onda je M.Z.
bajt na adresi 125, a V.Z. bajt na adresi 125+3, tj. 128.
|
|
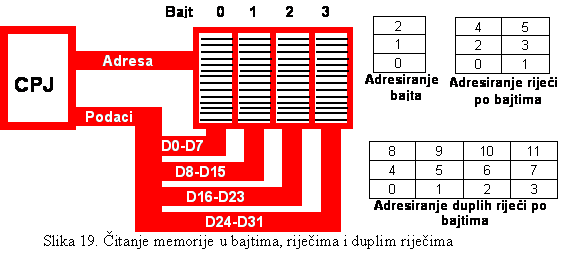 |
Bajt adresibilna memorija znači da se podaci mogu čitati u
bajtima kao najmanjoj adresibilnij jedinici, ali i u duplim riječima. Očekivati
je, da se čitanje u duplim riječima izvrši u istom vremenskom intervalu kao i u
bajtima, što efektivno daje, da je čitanje 'grupe' od 4 bajta (dupla riječ),
četiri puta brže? Ovo nije baš tačno. Ako se želi pročitati riječ na adresi
125, onda se na adresnu sabirnicu šalje adresa 124 i čita riječ. Time je
zapravo pročitan bajt sa adrese 125, a onda se u sljedećem ciklusu čita riječ
sa 126. Logička kola odrade automatsko povezivanje, tako što se V.Z. bajt iz
prvog čitanja stavlja kao M.Z. bajt tražene riječi (sa adrese 125), a M.Z. bajt
iz drugog čitanja se stavlja kao V.Z. bajt tražene riječi. Slično se dešava i
kod čitanja dvostruke riječi, ali je za njeno učitavanje dovoljno dva čitanja
(ne četiri). Zato je korisno kod pisanja programa, podešavati adrese riječi
(riječi na parnim adresama, a duple riječi na adresama djeljivim sa 4) kako bi
se ubrzao pristup.
Jasno je sa slike 19, da osmobitna
arhitektura može uraditi sve i što 32'vo bitana, ali ona u jednome ciklusu čita
jedan bajt (D0-D7), pa joj je potrebno četiri ciklusa za čitanje sadržaja od D0
do D31. Ovdje postoji dodatno gubljenje vremena ako adresa nije podešena, jer
se mora izvršiti 'swaping' (zamjena) V.Z. bajta sa M.Z. bajtom.
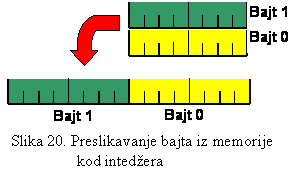 Posebno treba
obratiti pažnju kod prikazivanja intedžera na veličinu bajta ili duple riječi.
Kako se vidi na slici 18, kod preslikavanja bajta na riječi, bajt sa neparnom
adresom nalazi se na desnoj strani, odnosno na poziciji M.Z. bajta, dok se V.Z.
bajt nalazi na lijevoj strani. Kako kod intedžera poslije V.Z. bita od M.Z.
bajta mora doći M.Z. bit V.Z. bajta (osmi bit intedžera je zapravo prvi bit
neparnog bajta), to neparni bajt mora ići lijevo, kao što se vidi na slici 20.
Posebno treba
obratiti pažnju kod prikazivanja intedžera na veličinu bajta ili duple riječi.
Kako se vidi na slici 18, kod preslikavanja bajta na riječi, bajt sa neparnom
adresom nalazi se na desnoj strani, odnosno na poziciji M.Z. bajta, dok se V.Z.
bajt nalazi na lijevoj strani. Kako kod intedžera poslije V.Z. bita od M.Z.
bajta mora doći M.Z. bit V.Z. bajta (osmi bit intedžera je zapravo prvi bit
neparnog bajta), to neparni bajt mora ići lijevo, kao što se vidi na slici 20.
Treba još jednom napomenuti da podešavanja
bajta kod neparnih adresa (ili ne djeljivih sa 4) vrši CPJ automatski. Međutim,
gubi se na vremenu. Zato je preporuka, da se pazi kod organizacije podataka,
jer se na taj način program može znatno ubrzati.
2.2 Sistemsko vrijeme
Osnovna odlika VNA arhitekture je serijsko
izvršavanje instrukcija. Mašina je definisana kao automat sa konačnim brojem
stanja, gdje instrukcije definišu prelazke iz jednog stanje u drugo po tačno
određenom redosljedu. Tako će se Pascalska rečenica i:=i*5+j uvijek izvršiti
poslije rečenice i:=j, ako su definisane sekvencom koda:
i:=j;
i:=i*5+3;
Ništa se ne izvršava momentalno, već traje određeno vrijeme.
Naravno, da je prvi izraz 'brži' od drugog (brže se izvršava). Postavlja se
pitanje kako da mjerimo vrijeme izvršavanja rečenica i kako ih procesor
izvršava. Jasno je da ovako komplikovani sistem mora biti veoma precizno
koordiniran, sa potpunom definicijom stanja u kojima se može naći procesor koji
izvršava program kao i sam program koji se izvršava.
2.2.1 Sistemski sahat
Sve radnje u sistemu i sinhronizacije između komponenti vrše
se preko sistemskog sahata, koji daje takt sistemu kako da radi. Fizički,
sistemski sahat predstavlja signal na kontrolnoj sabirnici, čija se vrijednost
mijenja između 0 i 1 (logički), definisanom brzinom (slika 21). Sisitemski
sahat je zapravo mehanizam pomoću kojega CPJ direguje sistemom i 'otvara
geitove' logičkih kola, te omogućava sinhroni rad sistema.
Brzina promjene stanja sistemskog sahata
između 1 i 0 predstavlja učestanost, odnosno sistemsku frekvenciju.
Vrijeme koje je potrebno da signal promijeni stanje između 0 i 1 i vrati se
nazad, predstavlja period sahata, odnosno clock period. Puni period se
takođe zove i ciklus sahata. Frekvenca sahata predstavlja broj perioda u
sekundi. Tako period često predstavlja ciklus izvršenja neke operacije. Prva
serija Intelovih 80x86 procesora je krenula sa 4.7MHz, da bi serija Pentium III
prešla 1GHz. Kod procesora čiji je period 100MHz, vrijeme ciklusa je 10ns.
Najpodesnija tačka sinhronizacije poslova je momenat kada ivica clocka 'pada'
sa 1 na 0, ili obratno, 'diže' se sa 0 na 1.
Procesi se ne mogu odvijati, brže nego što
to diktira takt sistemskog sahata. Pa čak, i kada se raznim tehnikama napravi
paralelizam, da se neki proces izvršava duplo brže, onda se umnožak bazira na
frekvenciji sistemskog sahata. Ono što se najčešće dešava ,jeste, da se zbog
sporosti uređaja, ne može pratiti brzina sistemskog sahata, pa se uvode stanja
'čekanja'. Na taj način se operacija izvrši u više ciklusa, umjesto u jednome.
2.2.2 Pristup memoriji i sistemski sahat
 Tipičan uređaj, čiji se rad bazira na taktovima
sistemskog sahata je memorija. Vrijeme pristupa memoriji
je definisano kao broj ciklusa sistemskog sahata, da bi se podatak pročitao,
ili upisao u memoriju i iznosi jeda ili više ciklusa Dva glavna parametra
memorije su njen kapacitet i vrijeme pristupa. Klasična memorija koja se može
naći na tržištu ima vrijeme pristupa reda 10 ns, što u ciklusima odgovara
frekvenciji od 100MHz. Sam proces čitanja i pisanja je predstavljen na slici
22. Treba naglasiti da, CPJ ne čeka na memoriju da podatak bude spreman za
čitanje ili pisanje, već u momentu koji diktira sahat, sa podatkovne sabirnic
pokupu ono što se tamo nalazi. To znači, ako podatak nije bio na raspolaganju,
da će se pokupiti to što se tamo nalazi (smeće). Tako i kod pisanja, ako
podatak nije upisan, preko njega će se prepisati drugi. Šta se onda desi sa
podacima, ako je vrijeme pristupa memoriji 10 ns, a CPJ radi na taktu od 333MHz
i više (što zahtjeva memoriju bržu od 3ns)?
Tipičan uređaj, čiji se rad bazira na taktovima
sistemskog sahata je memorija. Vrijeme pristupa memoriji
je definisano kao broj ciklusa sistemskog sahata, da bi se podatak pročitao,
ili upisao u memoriju i iznosi jeda ili više ciklusa Dva glavna parametra
memorije su njen kapacitet i vrijeme pristupa. Klasična memorija koja se može
naći na tržištu ima vrijeme pristupa reda 10 ns, što u ciklusima odgovara
frekvenciji od 100MHz. Sam proces čitanja i pisanja je predstavljen na slici
22. Treba naglasiti da, CPJ ne čeka na memoriju da podatak bude spreman za
čitanje ili pisanje, već u momentu koji diktira sahat, sa podatkovne sabirnic
pokupu ono što se tamo nalazi. To znači, ako podatak nije bio na raspolaganju,
da će se pokupiti to što se tamo nalazi (smeće). Tako i kod pisanja, ako
podatak nije upisan, preko njega će se prepisati drugi. Šta se onda desi sa
podacima, ako je vrijeme pristupa memoriji 10 ns, a CPJ radi na taktu od 333MHz
i više (što zahtjeva memoriju bržu od 3ns)?
2.2.3 Stanja čekanja
Stanje čekanja je odgovor na pitanje iz
prethodnog poglavlja: kada se operacija ne može završiti u jednome ciklusu,
onda se dodaju još jedan ili više ciklusa kako bi se operacija kompletirala.
Razmotrimo rad memeorije čije je vrijeme pristupa 10ns sa procesorom od 333MHz.
Dakle, period sahata traje 3ns, a brzina memorije je 10ns. Vrijeme pristupa se
povećava i zbog kašnjenja u dodatnim logičkim kolkolima kod pristupa memoriji:
za dekodiranje i baferovanje (slika 23), što povećava vrijeme pristupa za još
po 1ns. Povećanjem vremena pristupa CPJ'a na dva ciklusa ne rješava problem. Za
pristup memoriji brzine 10ns i sa 1ns dekodiranja/bufferovanja, potrebno je
11ns. To znači, da su pored osnovnog ciklusa sistemskog sahata, potrebna još
tri ciklusa čekanja, što vrijeme potrebno CPJ'u za čitanje ili pisanje povećava
na 12ns. Što znači, da za čitanje u jednome ciklusu (sa stanjem čekanja nula),
potrebna nam je memorija brzine pristupa od 2ns (još 1ns se izgubi u dekoderu i
bufferu). Time bi se izbjeglo degradiranje performansi mašine. Očigledno je
pitanje, zašto se onda odmah ne ugradi memorija odgovarjućih karakteristika (sa
stanjem čekanja nula)? Odgovor je - pare! Takva memorija je veoma skupa (što
znači da postoje i neki tehnički problemi).
2.2.5 Keš memorija
Analiza izvršavanja nekog programa, upućuje
na to da se izvršava 10% do 20% rečenica tog programa. Ovo je posljedica
repititivnosti programa, to jest da se najveći dio vremena izvršavanja programa
provede u izvršavanju različitih vrsta petlji. Efektivno se koristi jedan mali skup varijabli, što je definisano kao
lokalnost referenciranja varijabli.
 Ovakvo razmatranje, kada se uzme još u obzir
prethodni paragraf navodi na zaključak: dobro bi bilo imati neku malu količinu
memorije sa stanjem čekanja nula, odnosno dovoljno brzu da se operacije
izvrašavaju u jednome taktu. Takvo rješenje se zove keš memorija.
Procesoru se doda veoma brza memorija, a da bi se izbjegao negativan
komercijalni efekat, to bude obično 'mala' količina memorije. Kada program
počne da se izvršava, on se smješta u glavnu memoriju, a instrukcije koje
dolaze na red za izvršavanje se prebacuju u keš memoriju. Na taj način se
izvrši inicijalno punjenje keš memorije. Razrađeni su posebni algoritmi, koji
omogućavaju da se u keš memoriji nalaze upravo oni podaci koji se najčešće
koriste. Kada se god zatraži nova instrukcija ili podatak, provjerava se da li
se već nalazi u keš memoriji. Ako je podatak tu, onda je to 'pogodak', i
program ide dalje sa po jednim ciklusom za memorijske operacije. Ako podatka
nema, onda se pokreće algoritam, koji će izbaciti manje korištene podatke
(lokalna referentnost varijabli), a učitati u keš memoriju one koji su trenutno
potrebni.
Ovakvo razmatranje, kada se uzme još u obzir
prethodni paragraf navodi na zaključak: dobro bi bilo imati neku malu količinu
memorije sa stanjem čekanja nula, odnosno dovoljno brzu da se operacije
izvrašavaju u jednome taktu. Takvo rješenje se zove keš memorija.
Procesoru se doda veoma brza memorija, a da bi se izbjegao negativan
komercijalni efekat, to bude obično 'mala' količina memorije. Kada program
počne da se izvršava, on se smješta u glavnu memoriju, a instrukcije koje
dolaze na red za izvršavanje se prebacuju u keš memoriju. Na taj način se
izvrši inicijalno punjenje keš memorije. Razrađeni su posebni algoritmi, koji
omogućavaju da se u keš memoriji nalaze upravo oni podaci koji se najčešće
koriste. Kada se god zatraži nova instrukcija ili podatak, provjerava se da li
se već nalazi u keš memoriji. Ako je podatak tu, onda je to 'pogodak', i
program ide dalje sa po jednim ciklusom za memorijske operacije. Ako podatka
nema, onda se pokreće algoritam, koji će izbaciti manje korištene podatke
(lokalna referentnost varijabli), a učitati u keš memoriju one koji su trenutno
potrebni.
Normalno, učitavanje podataka za keš
memoriju može da dovede do smanjenja performansi. To je pogotovu izraženo, ako
program sekvencijalno čita nove instrukcije, nema vrćenja u petljama, ili ima
slučajan pristup različitim lokacijama. Neki dizajneri računarskih arhitektura
za taj slučaj ubacuju još jedan keš, malo sporiji, ali sa više memorije, recimo
kome su potrebna dva ciklusa za pristup. Takav se keš zove sekundarni keš
(slika 23), obično se nalazi između procesora i klasične memorije.
2.3 U/I (Ulaz/Izlaz) uređaji
Računari komuniciraju preko ulazno/izlaznih
uređaja sa okruženjem na tri načina:
·
U/I-mapirani ulaz/izlaz: za prijenos podatataka između računarskog sistema i vanjskog svijeta
koriste se za tu svrhu specijalne instrukcije;
·
Memorijski-mapirani ulaz/izlaz: CPJ koristi specijalne memorijske lokacije iz normalnog adresnog
prostora za pristup uređajima koji komuniciraju sa vanjskim svijetom;
·
Direktni memorijski pristup (Direct Memory
Access - DMA): DMA je specijalni oblik
memorijski-mapiranog pristupa, gdje se razmjena podataka između ulazno/izlaznih
uređaja i memorije odvija bez posredstva CPJ'a.
Svaki od ovih mehanizama ima svoje
prednosti i mahane. Da bi se podaci poslali u vanjski svijet, CPJ jednostavno
smjesti podatke na specijalne lokacije (na U/I adresni prostor [U/I sabirnica
2.1.1.4] ako se radi o U/I-mapiranome sistemu, ili na memorijski adresni
prostor ako se rad i o memorijski-mapiranome U/I). Kod čitanja, CPJ jednostavno
prebaci podatke sa adrese (U/I ili memorija) određenog uređaja. Operacije
čitanja i pisanja sa U/I uređaja su veoma slične radu sa memorijom, izuzev što
ima puno više stanja čekanja kod sinhronizacije.
|
|
 |
Ćelija U/I uređaja, je slična memorijskoj ćeliji, sadrži
konekciju prema vanjskome svijetu i zove se U/I port. Kada se podaci
smještaju u U/I port, on ih prihvata kao i memorijska lokacija, ali ima pored
signala prema CPJ i ekstrne signale prema vanjskome sistemu. Port može biti
read-only, write-only i red/write (kakav je na slici 24). Slično kao i kod
pristupa memoriji, za pisanje podataka na U/I port potrebno je da bude aktivna
kontrolna linija za pisanje i dekodiranje; a kod čitanja su aktivne linije za
dekodiranje i čitanje. Obično U/I uređaji imaju tri registra koji omogućavaju
kontrolu, upis i čitanje podataka: CSR (Control Status Register) - registar
koji sadrži statuse mogućnosti upisa/čitanja podataka sa U/I uređaja, kao i
raspoloživost uređaja; te ulazni i izlazni registar za čitanje i ispis podataka.
Tako se recimo, preko CSR registra može znati da li je printer spreman za
prijem podataka, kako bi se poslao novi karakter za štampu. Po istoj anologiji se može 'saznati' da li
na tastaturi postoji neki karakter koji treba učitati. Primjer memorijski
mapiranog U/I je video memorija. Video kartice imaju i po nekoliko Mb memorije,
što je očigledno više od U/I prostora, tako da se problem razriješio mapiranjem
na adresni prostor klasične memorije.
U/I-mapirani i memorijski mapirani U/I sav
posao ulaza/izlaza obavljavaju uz posredovanje CPJ'a. Tako recimo, za
učitavanje 10 bajta, CPJ mora 10 puta učitati bajt (preko U/I porta ili
mapirane memorije) i 10 puta smjestiti taj bajt u memoriju. Ovaj proces
usporava čitrav sistem ako treba učitati nekolioko kb ili Mb. Problem je
razriješen preko direktnog memorijskog pristupa, gdje je CPJ isključena iz
procesa primanja/slanja poadataka. DMA ima direktnu vezu na sabirnice tako da
je u mogućnosti da direktno smjesti podatke u adresni prostor, ili uzme ih iz
njega, dok za to vrijeme CPJ može raditi nešto drugo. Jedino DMA i CPJ ne mogu
istovremeno pristupati podatkovnoj i adresnoj sabirnici. Zato, dok DMA koristi
sabirnice, CPJ može izvršavati recimo neke instrukcije drugog tipa, čime se
povećavaju performanse sistema.
Prijem i slanje podataka mora biti na neki
način sinhrinizirano, ili pod kontrolom bez obzira kada će se desiti U/I
zahtjev. Recimo računar u sekundi može poslati na hiljade karaktera printeru,
ali printer nije u mogućnosti da ih obradi (odštampa). Problem se razrješava
preko CSR registra. Konkretno, ako se šalju podaci na printer, onda u CSR’u
postoji bit koji indicira da je printer on-line i da je spreman za prijem
znaka. U tome slučaju se šalje znak, i ponovo ide na provjeru u CSR’a da li je
spreman za novi znak. Ovaj se postupak ponavlja dok se ne pošalje cijela poruka
(u slučaju printera ne odštampa željeni dokument). Naravno, postoje i kontrole
da li su poslani znaci uspješno primljeni, pa u slučaju da nisu, šalju se
ponovo. Slično se dešava ako se želi učitati neki karakter sa tastature:
provjerava se u CSR’u da li postoji spreman karakter za učitavanje. Program
stoji na ovoj provjeri, sve dok ne bude pritisnut karakter na tastaturi, kada
se on i prebaci u memoriju. Na ovaj način su radile prve verzije računara,
recmo Aple II.
Ovakav način ulaza/izlaza, gdje CPJ stalno
proziva port da vidi da li je spreman, naziva se prozivanje porta (polling).
Normalno, ovo je veoma neefikasan način, jer kada program dođe na U/I zahtjev,
on dalje ništa drugo ne radi, dok njega ne razriješi. To praktično znači, da se
u jednom momentu na mašini može izvršavati samo jedan program i nema procesa u
pozadini.
Razrješavanje ovog problema je omogućilo
široku primjenu računara. Zapravo, upotreba računara za regulisanje 'real-time'
sistema bi bila praktično nemoguća, a pogotovu mreža računara. Rješenje se zove
interapt ili prekid u čijoj je pozadini sljedeća priča:
U pravljenju dobrih tehničkih rješenja čovjek
pokušava da ih razriješi tako što će ugraditi rješenje koje se negdje pokazalo
praktičnim. U ovome slučaju radi se o rješenju koje je ugrađeno u samome
čovjeku (od njegovog Kreatora). Naime, dok čovjek radi neki posao, recimo
fizički, uvijek ga može neko 'prekinuti' u tome poslu sa 'Imam nešto da ti
kažem'. Ovo je zapravo obavijest (o interaptu), da ima još jedan proces, koji
on počinje izvršavati dok nastavlja stari posao. Nema problema ako su poslovi
različitog tipa i koriste različite resurse (manuelni rad i prča). Ali čovjek
može slušati nečiju priču, i gledati na TV'u neke interesantne sekvence. Da se
desiti, kod ljudi koji počinju zaboravljati, da im je teže pratiti dvije priče,
ili kada počne pratiti drugu, ne može se više vratiti na prvu (zaboravi gdje je
stao). On zapravo, čestim prebacivanjem pažnje (svičovanjem) prati oba procesa.
Zanimljiv je sljedeći slučaj: čovjek se kreće stazom gdje ima drveća. Neka u
jednome momentu slučajno zakači za neku granu. Međutim, u istome momentu ugleda
zmiju na putu! Neće osjetiti udarac grane, već riješiti bitniji problem - zmiju.
Kada završi, recimo uspješno izbjegne problem zmije, tek onda osjeti bol od
udarca grane i počinje rješavati taj problem. Ovo su zapravo primjeri primjene
interupta kod čovjeka.
Interupt signal se prima preko kontrolne
sabirnice, koji dolazi CPJ'u od vanjskog U/I uređaja. CPJ na momenat prekida
tekući posao, obradi interapt, koji je definisan kodom u za njega određenoj
uslužnoj rutini (Interrupt Sevice Routine - ISR). Prije nego starta ISR,
spašava se kompletno stanje tekućeg procesa (registri i statusna stanja), da bi
se po završetku ISR program vratio prethodnome procesu. Jedna od glavnih
karakteristika interaptne rutine, jest da bude kratka, kako bi se brzo
završila. Svaka računarska arhitektura mora obezbijedit mehanizam pozivanja
interapta i vraćanja iz njega (više detalja se nalazi u poglavlju 6.9.2).
No, kako je posao koji se dešava u
interaptnoj rutini brz, a time vremenski i kratak (manje od jedne sekunde, a
najčešće par milisekundi), to se ima utisak da se izvršava paralelno (kao u
priči). Tako će recimo, dok se izvršava neka obrada, kada god je printer
slobodan moći da se pošalju novi znakovi na štampu, a istovremeno kada se god
pritisne neki taster na tastaturi, karakter će biti učitan istovremeno (veza u
priči praćenje okoline i TV'a). Svakako, interapti imaju definisane prioritete,
pa ako se dese dva interapta istovremeno, onaj sa većim prioritetom istiskuje
onaj sa manjim (priča o zmiji). Međutim, ako se ne sačuvaju dobro parametri
prethodnog procesa, onda se iz ISR'a ne može vratiti na prethodni proces (što
je definisano sa senilnošću u priči).
2.4 Pitanja i zadaci
1.
Ako se računar posmatra kao automat sa konačnim
stanjima, šta ga prebacuje iz jednog stanja u drugo i kako se zove skup svih
tih elemenata koji kontrolišu promjene stanja računara?
2.
Koje su osnovne komponente VNA arhitekture?
3.
Koji je skup radnji potreban da bi se upisao
podatak u memoriju?
4.
Neka se na adresi 100 nalazi dupli intedžer.
Zašto je potrebno da bajti budu organizovani po adresama 100, 101, 102 i 103 (s
desna u lijevo kada je logična organizacija 103, 102, 101, 100 za 32'vo bitnu
arhitekturu, a 101, 100 i 103, 102 za 16'to bitnu?
5.
Neka procesor radi 333 MHz sa memorijom od 10
ns. Prodavač tvrdi da računar radi bez stanja čekanja. Kako?
6.
Zašto se na matičnu ploču ne stavi kompletna
memorija karakteristika keš memorije?
7.
Koja je razlika kod upisivanja na U/I port i
memorijsku lokaciju?
8.
U čemu je prednost direktnog memorijskog
pristupa na mapiranim?
3 Instrukcije naspram podataka
U ovome radu postoje dva osnovna pogleda na
računarske arhitekture, pa na osnovu toga i modeli koji ih zastupaju. U
prethodnome poglavlju je eksploatisan pogled dizajnera, dok će se u ovome
poglavlju malo više pažnje posvetiti programerskome pogledu. Razmotrit ćemo
odnos između instrukcija i njihovog tretiranja kao podataka. Neće se ulaziti u
strukture podataka kojima se bave programeri (nizovi, slogovi, liste …), a ni
spuštati na primitivne elemente tipa bita i bajta. Model u ovome poglavlju je
riječ (i to dupla riječ), koja može sadržavati različite podelemente, ali mi
ćemo je posmatrati kao instrukciju sljedećih karakteristika:
·
Sve instrukcije su smještene u memoriji, sa
ćelijama fiksne dužine. Formati informacija i značenje podataka smještenih u
instrukcijama su od bitnog značaja za performanse arhitekture;
·
Većina računara ima više tipova memorije, koji se razlikuju kako u
veličini, tako i u brzini, a time i u načinu njihova korištenja. Za razliku od
jezika višeg nivoa, asembler zahtjeva od programera korištenje ovih tipova
memorije, na koji način on postaje odgovoran za efikasnost sistema. Ovo znači,
da moraju postojati dodatne instrukcije, recimo za prebacivanje vrijednosti iz
jednog tipa memorije u drugi;
·
Asemblerski jezik u suštini ne tretira tipove
podataka, što znači da se na osnovu podataka u memoriji ne može zaključiti šta
su oni. Ne može se znati šta predstavljaju biti u memoriji izvan konteksta u
kome se trenutno nalaze, odnosno, zavise od načina kako ih instrukcije
tretiraju. Riječ u memoriji, pored toga što može da bude instrukcija, može biti
i intedžer, ili broj sa pokretnim zarezom, ili niz karaktera.
Asembler daje
programeru načine kako će manipulisati detaljima podataka. Eksterni elemenati,
koji su uključeni u sve ovo su programski brojač (PC) i statusna riječ (SW),
koji omogućavaju da računarska arhitektura radi kao automat sa konačnim brojem
satanja. Pprogramer treba reći u pojedinim stanjima da li su sabirci intedžeri
ili floating point brojevi, a da ih ne pomoiješa sa instrukcijama, koje trebaju
prebaciti izvršenje programa u sljedeće stanje.
3.1 Instrukcije
Rečenica
asemblerskog jezika se prevodi u instrukciju mašini, koju ta ista mašina treba
da izvrši. Ako program posmatramao kao skup konačnih stanja (po analogiji da
računar predstavlja automat sa konačnim stanjima), onda svaka instrukcija
dovodi program u jedno od stanja. Prelazak iz jednog stanja u drugo mora biti
jednoznačan, inače program ne bi bio koegzistentan. Neophodni parametri za
prevođenje u novo stanje su: stanje u kome se program trenutno nalazi
(instrukcija koja se izvršava) i nova instrukcija koja treba da se izvrši. Kako
je CPJ izvršni organ koji se 'hrani' instrukcijama i prevodi program u nova
stanja, to i u samoj obrađivačkoj jedinici postoji minimalni skup sklopova koji
definišu sadašnje i sljedeće stanje. Dva osnovna elementa u CPJ'u iz čijeg
stanja se može izvesti novo su:
·
Procesorska statusna riječ PSW (Processor Status
Word), koja u sebi sadrži indikatore (zastavice), na osnovu rezultata
aritmetičko-logičkih operacija, te drugih aktivnosti procesa (interapti);
·
Programski brojač PC (Programm Counter),
implicitna varijabla koja uvijek pokazuje na sljedeću instrukciju koja se treba
izvršiti, pa se kod nekih proizvođača zove IP (Instruction Poenter).
Kao i podaci,
instrukcije se nalaze u nizu koji je smješten u memoriji. Prije izvršenja
instrukcije, procesor mora imati sve relevantne podatke potrebne za njeno
izvršenje, koje je definisano statusnom riječju o trenutnome stanju i
programskim brojačem o sljedećoj instrukciji. Izuzetak nastaje onda kada treba
izvršiti skok na neku drugu lokaciju u programu. Ovoj skok je definisan tekućom
instrukcijom, koja zamjenjuje sadržaj PC'a adresom instrukcije na koju treba
skočiti. Instrukcija predstavlja niz bita, i tek kod izvršenja instrukcije,
njenim dekodiranjem, procesor saznaje šta ona predstavlja: aritmetičko-logičku
operaciju, instrukciju grananja (skoka), ulazno/izlaznu instrukciju ili
podatak. Kako asembler ne razlikuje tipove podataka, to programer preuzima na
sebe (ili kompajler kod jezika višeg nivoa) da kodira program tako, da kod
sabiranja, recimo dva broja, aritmetička jedinica zna da li se radi o
intedžerima ili o brojevima u pokretnome zarezu.
3.1.1 Formati aritmetičkih izraza
Uobičajeni zapis aritmetičkih izraza se
pokazao nepraktičnim za asemblerski jezik. Stoga je za obradu aritmetičkih
izraza uzeta poljska notacija.
Analizom zapisa aritmetičkih izraza dolazi se do tri forme:
·
Infiks notacija:
je uobičajeni način zapisa aritmetičkih izraza. Kod ove forme izraz se piše u
obliku operand-operator-operand. Sabiranje dva broja a i b u
infix notaciji će biti zapisano kao a+b;
·
Prefiks notacija:
susreće se još pod nazivom sufix notacija. Kod ove forme prvo se piše operator
pa onda operandi, tj operator-operand-operand. Primjer sabiranja dva broja u
prrefix formi će biti +ab;
·
Postfiks notacija: kod ove forme operand se nalazi na kraju zapisa, tj u obliku
operand-operand-operator. Aritmetički izraz sabranja dva broja u postfiks
notaciji će biti: ab+.
Da se primjetiti da je asemblerskom jeziku
najbliža prefiks notacija. Operand se pojavljuje kao prvi, na osnovu čega se da
zaključiti broj operatora da bi se kompletirao aritmetički izraz. Ovaj pristup
ima još jednu prednost. Razmotrimo malo složeniji izraz: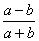 . Ovaj izraz u infix notaciji
bi izgledao na sljedeći način: a-b/a+b, što očigledno nije tačno
(jer su definisana pravila prioriteta operacija). Ispravan zapis se može
postići pomoću zagrada: (a-b)/(a+b). Međutim za ovaj zapis
u prefiks notaciji nisu potrebne zagrade: /-ab+ab. Kod ove forme pravila
su postavljena na sljedeći način: prvo se dolazi do operatora; prema operatoru
se zna koliko će biti operanada, koji slijede iza njega; ako je sljedeći
parametar operator a ne operand, onda se radi o podizrazu; u tom slučaju se
razrješava podizraz (koji se programskidefiniše kao funkcija), i njegov
rezultat predstavlja operand za izraz u okviru koga je ukomponovan podizraz.
. Ovaj izraz u infix notaciji
bi izgledao na sljedeći način: a-b/a+b, što očigledno nije tačno
(jer su definisana pravila prioriteta operacija). Ispravan zapis se može
postići pomoću zagrada: (a-b)/(a+b). Međutim za ovaj zapis
u prefiks notaciji nisu potrebne zagrade: /-ab+ab. Kod ove forme pravila
su postavljena na sljedeći način: prvo se dolazi do operatora; prema operatoru
se zna koliko će biti operanada, koji slijede iza njega; ako je sljedeći
parametar operator a ne operand, onda se radi o podizrazu; u tom slučaju se
razrješava podizraz (koji se programskidefiniše kao funkcija), i njegov
rezultat predstavlja operand za izraz u okviru koga je ukomponovan podizraz.
3.1.2 Veličine instrukcija
Na početku je
rečeno da će svaka instrukcija biti jedna riječ. Ovo daje veliku prednost kod
učitavanja, jer se jednim memorijskim čitanjem zahvata jedna instrukcija. Time
se ostvaruje i drugi značajniji efekat: programski brojač se može automatski
podesiti da pokazuje na sljedeću instrukciju (riječ). Iako je kod nekih
instrukcija moguće kodirati dvije ili više instrukcija u jednoj riječi, to se
ne radi. Takav način bi veoma komplikovao ažuriranje brojača instrukcija.
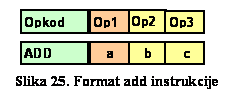 Generalno govreći,
bolje je da se instrukcije pakuju u što manje riječi, jer velike instrukcije ne
da samo zauzimaju više memorije, već zahtjevaju i više vremena za pristup.
Razmotrimo koliko je memorije potrebno za asemblersku instrukciju za sabiranje
(slici 25). Instrukcija se sastoje od skupine bita koji čine cjeline ili polja.
Kako se instrukcije predstavljaju u prefiks notaciji, kao što je prikazano na
slici 25. Aritmetički izraz a=b+c se u obliku instrukcije
predstavlja na četiri polja:
Generalno govreći,
bolje je da se instrukcije pakuju u što manje riječi, jer velike instrukcije ne
da samo zauzimaju više memorije, već zahtjevaju i više vremena za pristup.
Razmotrimo koliko je memorije potrebno za asemblersku instrukciju za sabiranje
(slici 25). Instrukcija se sastoje od skupine bita koji čine cjeline ili polja.
Kako se instrukcije predstavljaju u prefiks notaciji, kao što je prikazano na
slici 25. Aritmetički izraz a=b+c se u obliku instrukcije
predstavlja na četiri polja:
·
Opkod ili
operacioni kod je prvo polje (prefiks notacija) i obavezno je za svaku
instrukciju. Koristeći osobine RPN forme, zna se tačno koliko je riječi duga
instrukcija, tako da PC može pokazivati na sljedeću instrukciju. U ovome
slučaju radi se o instrukciji sabiranja, koja ima tri parametra;
·
Operandi zapravo
predstavljaju parametre. Njihov broj zavisi od tipa operatora i može da bude
čak bez operanada, ili da ih pak ima više. U ovome slučaju postoje tri
operanda: dva sabirka b i c, te a za smještanje rezultata.
Veličina opkoda
varira od arhitekture do arhitekture. Veličina polja opkoda određuje broj
instrukcija. Ako je opkod osmobitni, onda se može kodirati 256 različitih
instrukcija. Ako se smanji veličina opkoda na pet bita, onda se mogu
specificirati samo 32 instrukcije. Varijable a, b, c zahtjevaju svaka po
jednu memorijsku lokaciju. Kako se radi o riječima od 32 bita, kompletna
instrukcija sa opkodom i operandima treba 4 riječi, odnosno 128 bita za
učitavanje. Dohvatanje 124 bita iz memorije za izvršenje jedne instrukcije
traži puno memorijskog vremena. Imajući u vidu da je potrebno i vrijeme za
smještanje rezultata, dolazi se do zaključka da je za neke instrukcije potrebno
više vremena za njihovo dohvatanje nego samo izvršavanje. Ovo nas navodi na to,
da instrukcije/riječi trebaju biti što je moguće manje. S druge strane, sa
malim riječima se adresira ograničen prostor, a i broj instrukcija je sužen.
Može se uštedeti time što će se pakovati instrukcije sa manje operanada na
jednu riječ, ali se onda gubi na brzini dekodiranja, a i ne zna se kraj
instrukcije kako bi PC automatski pokazivao na sljedeću instrukciju. To su
problemi koji su se našli pred dizajnerima računarskih arhitektura, pa su oni
krenuli u dva pravca: CISC i RISC arhitekture.
3.1.3 Tipovi adresnih mašina
Često se ista operacija može predstaviti u
više formi. Aritmetička operacija a=b+c, znači da trba sabrati sadržaj druge i
treće varijable i rezultat pridružiti prvoj. Radi pogodnosti, operacija
sabiranja se može predstaviti u prefiks notaciji +b,c,a. No ona može imati i
dva parametra ako se definiše kao +a,b. U zavisnosti kako se adrsiraju
parametri, postoji i podjela arhitekture mašina prema njihovome broju.
3.1.3.1 Troadresne mašine
Format troadresnih mašina zahtijeva tri
parametra kod adresiranja: dva operanda koji učestvuju u operaciji i odredišni
operand, gdje se smješta rezultat. Ovo je najopštiji način adresiranja (slika
25). Pascalska rečenica a:=b+c, u ovome formatu se predstavlja kao:
add a, b, c
Glavni nedostatak ovog načina adresiranja
je taj, što zahtjeva praviše memorijskih pristupa, kako za učitavanje
parametara, tako i za smještanje rezultata.
3.1.3.2 Dvoadresne mašine
Često se rezultat neke opearacije koristi
kao međurezultat, odnosno parametar u sljedećoj operaciji. Tada je gubljenje
vremena i razbacivanje sa prostorom, ako se rezultat vraća u glavnu memoriju da
bi se ponovo učitao. Prethodna Pascalska rečenica se može napisati i na
sljedeći način: a := c; a := a + b. U asembleru ona se može zamijeniti
sljedećim kodom:
move a, c
add a, b
Druga instrukcija sabira a sa b
i rezultat ustavlja u a. Stoga joj treći parametar nije ni potreban.
Ovakav metod adresiranja se koristi kod dvoadresnih mašina. Ako je zbir a
sa b potreban kao međurezultat, onda se prva instrukcija (move a,c) ne
mora ni izvršavati. Nekada je čak potrebno i manje koda da bi se napisala
dvoadresna instrukcija. Tako Pascalska rečenica a := a + b + c, u troadresnoj
mašini se predstavlja kao:
add a, a, b
add a, a, c
dok je u dvoadresnoj mašini:
add a, b
add a, c
Prednost dvoadresne mašine je u kraćim
instrukcijama, koje pored toga što zahtijevaju manje prostora, i izvršavaju se
brže.
3.1.3.3 Jednoadresne mašine
Nekim instrukcijama je dovoljan samo jedan
parametar. Takve su recimo instrukcije skoka. Međutim moguće je dvoadresne
instrukcije pretvoriti u jednoadresne. U tu svrhu je potrebno definisati
posebnu implicitnu varijablu u kojoj se nalazi drugi parametar. Ta varijabla se
obično naziva akumulator (accumulator) i fizički se nalazi u procesoru.
Instrukcija sabiranja u Pascalu sa akumulatorom bi bila: Akumulator :=
Akumulator + x, što je u asembleru:
add x
jer se zna da je drugi sabirak (difoltno) u
akumulatoru, gdje se smješta i rezultat. Troadresno sabiranje (add a,b,c) se
može predstaviti jednoadresnim:
Akumulator := b;
Akumulator := Akumulator + c;
a :=Akumulator;
Kako move instrukcija zahtjeva dva
parametra, onda ona zahtjeva specijalno prilagođenje. Razdvaja se u dvije
instrukcija: jedna za uzimanje varijable iz memorije i smještanje 'punjenje' u
akumulator - lda, a druga za smještanje sadržaja iz akumulatora u
memoriju - sta. Njihova sintakas je: lda varijabla (LoaD
Accumulator) i sta varijabla (STore Accumulator). Sada imamo sve
elemente za kodiranje zbira brojeva u jednoadresnoj mašini:
lda c
add b
sta a
3.1.3.4 Nuladresne mašine
Kod nula adresnih mašina praktično 'ne
postoje' operandi, već samo operatori. To znači da su operandi negdje ipak
smješteni. Najčešće se oni nalaze na steku. Primjer nula adresnih mašina su FP
procesori (procesori za rad u pokretnome zarezu) i digitroni (džepni
kalkulatori).
Mnoge mašine podržavaju sve tipove
arhitektura (sva četiri). U praksi najširu primjenu našla je dvoadresna
arhitektura mašina.
3.2 Adresiranje i tipovi memorije
Osnovni parametri memorije su brzina
pristupa i kapacitet, koji su komercijalno obrnuto proporcijalni. Tako se, tako
zvana mas memorija, ili eksterna (na diskovima i drugim eksternim uređajima),
sa vremenom pristupa u milisekundama, može naći u Gb za relativno nisku cijenu.
Za sličnu cijenu, u Mb se nalazi glavna memorija sa vremenom pristupa u ns.
Ranije smo se sreli i sa keš memorijom, koja omogućava vrijeme pristupa u
jednome clocku, za nešto više para. Postoji još jedan vid memorije, koji je
sastavni dio procesora i koji se ne može posebno dograđivati, to je registarska
memorija ili jednostavno registri.
3.2.1 Skraćeno referenciranje (registri)
Kao što se vidjelo u prethodnome poglavlju,
kod izvršenje instrukcije, često treba više vremena za dohvat parametara, nego
njeno samo izvršenje. Glavni je problem preveliki broj bita za adresiranje.
Kako se zbog efekta lokalnog referenciranja često koristi mali broj varijabli,
to znači da bismo ih mogli smjestiti u neku memoriju, za čije je referenciranje
potreban mali broj bita. U tom slučaju, možemo tim lokacijama dati specijalna imena,
poput zamjenica ili nadimaka u govornome jeziku.
Registri se mogu definisati Pascalskim
tipom kao skup: registri=($1,$2..$n), gdje je n veličina memorije rezervisane
za registre. Analogno tome memorija se definiše kao memorija=array[1.. maxmem]
of byte. Ako bi registarska memorija sadržavala 64 riječi, onda je za njeno
adrsiranje dovoljno 8 bita ili jedan bajt. U tome slučaju bi se sa riječju od
16 bita mogle adresirati dvije lokacije u toj specijalnoj memoriji. Pascalski
koncept referenciranja varijabli iz memorije preko njihovih adresa je M[i],
gdje je i redni broj (adresa) riječi iz adresnog prostora glavne
memorije. Po toj analogijei riječi iz specijalno definisane male memorije bi se
mogle referencirati sa r[i] za lokaciju riječi i. Kako je definisano
samo 256 riječi, to najveća vrijednost za i, a da se ne adresira izvan
niza r je 255. Tako se može adresirati na specijalni način niz r[i] sa indeksom
i predstavljenim intedžerom bez predznaka na bajtu. Sada bi troadresna
mašina za adresiranje trebala samo 24 bita, tako da 32-bitna instrukcija može
sadržavati 8-bitni opkod i tri operanda. Tako će instrukcija sabiranja biti:
add r[a],r[b],r[c]
sa istim efektom
kao i add a,b,c. Razlika je u tome, što operandi dolaze iz specijalne memorije
koja se zove registarska memorija, a njeni pojedini elementi, riječi,
zovu se registri.
Koncept registara se u programiranju
pojavljuje samo u asemblerskome jeziku, a jezici visokog nivoa ga nemaju. U preksi, registri su
dizajnirani kao dio CPJ, a ne memorije. Time je reduciran broj memorijskih
pristupa za instrukcije koje svoje varijable drže u registrima.
Sa softverskog stanovišta ima nekoliko
razlika između M[i] i r[i]. Prvo, M[i] je specifiična varijabla i u zavisnosti
od poziva dozvoljava pristup različitim lokacijama. Zato se operand specificira
indirektno, koristeći međuvarijablu i koja definiše operand. Varijabla i
je tipa intedžer koji predstavlja adresu, čija se vrijednost izračunava.
Konstrukcija r[i] ne pristupa različitim lokacijama. Varijabla i je konstantna,
specificira se prilikom pisanja programa i identificira određeni registar gdje
se drže podaci.
Druga razlika je da r[i], kao registar predstavlja adresu riječi, mada postoje
specijalne konstrukcije kada se može pristupiti bajtu.
Ovaj koncept omogućava da mnoge privremene
varijable uopšte nemaju svoju adresu u glavnoj memoriji. Sve operacije, gdje se
pojavljuju samo međurezultati, se vrše u, i sa registrima. Zbog dobrih efekata
jednoadresnih mašina, u mnogim arhitekturama, nekome od registara se dodijeli
funkcija akumulatora. Postoje i druge specijalne funkcije. Tako se često
rezerviše registar koji će biti samo PC, ili SP (Stack Pointer). Često su
dizajnirane posebne instrukcije za razmjenu podataka izmiđu registara i
memorije. Koncept load/store se može iskoristiti za razmjenu podataka između
glavne memorije i registara. Međutim, češće se za tu svrhu koristi specijalni
oblik move instrukcija. Tako se load instrukcija emulira preko move
instrukcije formom
move r[i], varijabla
koja puni registar r[i] ssadržajem varijable,
dok forma
move varijabla, r[i]
stroira sadržaj registra u memorijsku
lokaciju.
3.2.2 Adresiranje instrukcija
Load/store arhitektura koristi registre za
izvorne operande ili smještanje rezultatata instrukcija. Izuzetak su Load/Store
instrukcije, koje pored registara koriste i memorijske lokacije. Ova
arhitektura omogućuje aritmetičkim i logičkim instrukcijama da budu veoma
kratke, jer za identifikaciju ulaza i izlaza trebaju samo registre. To ne znači
eliminaciju potrebe za glavnom memorijom, jer ako aritmetičke instrukcije i ne
specificiraju glavnu memoriju, load/store instrukcije moraju razmjenjivati
operande između registara i glavne memorije. Razmotrimo šta je neophodno
specificirati za jednu load instrukciju. Pored operacionog koda, moraju se
specificirati i podaci koje treba učitati, kao i registar u koji se podaci
učitavaju. Dok se operacioni kod i registar mogu specificirati na nekoliko
bita, adresa podatka za učitavanje mora biti čitava riječ. Kako je adresa na čitavoj
instrukciji od 32 bita, to kada bi registar i opkod bili na bilo koliko bita
(više od jedan), instrukcija ne može stati na jednoj riječi. Sličan je slučaj
sa instrukcijom grananja, gdje pored operacionog koda treba navesti adresu
grananja, koja je u opštem slučaju 32 bita.
Memorijska lokacija ili registar može da
sadrži varijable i konstante. Njima se direktno pristupa. No, na memorijkoj
lokaciji (ili u registru), može se nalaziti poenter na neku drugu lokaciju,
gdje se nalazi lista podataka. Za svaki slučaj postoji poseban način
označavanja kod simboličkog programiranja. Tako je uobičajeno da se u slučaju
direktne varijable ili registra navodi samo ime. Kada se radi o poenteru
(adresi koja ukazuje na položaj podatka na nekome drugome mjestu u memoriji),
onda se ime navodi u zagradama.
U zavisnosti od tipa instrukcije adrese se
mogu specificirati na sljedeće načine:
·
Instrukcija može sadržavati opkod i operande u
registrima. Ovo je najednostavniji i najefikasniji način.
·
Instrukcija može sadržavati opkod i obije adrese
u registrima, s time što adrese u registarima ukazuju na adrese varijabli u
glavnoj memoriji. Jedna od adresa ukazuje na izvorni operand, dok druga na
odredišni. U ovome slučaju nije potrebno dodatno podešavanje PC.
·
Instrukcija se sastoji od dvije riječi: prva
sadrži opkod i odredišni registar; dok druga riječ sadrži izvorni operand.
Sadržaj druge riječi može se posmatrati kao konstanta adrese na 32 bita, koja
je smještena odmah iza prve instrukcije. CPJ kod obrade ovakve instrukcije mora
prepoznati na osnovu koda instrukcije, kada je učita, da slijedi još riječ
adrese, kako bi se PC ispravno podesio da pokazuje na sljedeću instrukciju za
izvršenje.
·
Instrukcija može da sadrži za adresu neku malu
konstantu i registar. U ovome slučaju efektivna adresa se dobija sabiranjem
sadržaja registra i konstante. Za slučaj da je konstanta nula, ima se prvi
slučaj.
·
Adresa se može nalaziti u dva registra koji su
specificirani instrukcijom. U ovome slučaju efektivna adresa se dobija kao zbir
ova dva registra. Ova je mogućnost fina kod nizova, jer jedan registar sadrži
baznu adresu niza, dok drugi sadrži ofset elementa u nizu kome se pristupa.
3.2.3 Adresiranje poenterom
Jedan od ključnih koncepata u
programiranju, koji je ekskluzivno vezan za asembler je koncept steka. Njegov
fundamentalni značaj je u čuvanju stanja programa u kome se nalazio u momentu
prekida, na osnovu čega je mogući kasniji nastavak izvršenja programa, po
povratku iz prekida. Ovo se odnosi na sinhrone i asinhrone prekide, te
procedure. Pored programskog brojača i statusne riječi, često se spašava na
steku i sadržaj svih registara.
Struktura steka se može porediti sa
strukturom tanjira koji su naslagani jedni na druge. Za potrebe, tanjiri se
uzimaju sa vrha steka (u ovome slučaju tanjire poredane jedan iznad drugog
zovemo stek), onoliko koliko ih treba (ili dok se stek ne isprazni, ako ih
treba previše). Poslije upotrebe i pranja, tanjiri se ponovo vraćaju na stek.
Ovaj model je iskorišten i za stek u računarskome svijetu. Rezerviše se dio memorije
koji će biti potreban za potrebe koje će se pojaviti prilikom rada programa.
Taj dio memorije je definisan na Pascalski način:
stek : array [1..steksize] of word;
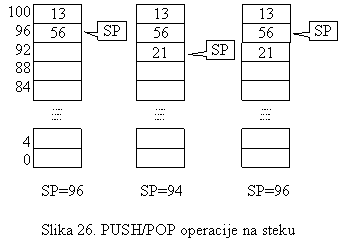 gdje steksize
predstavlja veličinu steka u riječima, odnono broj tanjira iz primjera. Nulta
adresa steka predstavlja tanjir na dnu strukture. Za nas je interesantan tanjir
sa vrha, i na njega će ukazivati posebna varijabla SP (Stack Poenter), u koji
se inicijalno postavlja adresa vrha stak'a. Kako se skupina tanjira u toku
korištenja smanjuje, to će i svaka lokacija na steku, na koju se stavi neka
vrijednost, smanjiti sadržaj SP za jednu riječ (2 ako se radi o 16'bitnoj
arhitekturi, 4 za 32.bitnu). Time stek pokazuje na sljedeću slobodnu lkaciju.
Novim korištenjem steka, dolazi do postavljanja vrijednosti koja se želi
koristiti tamo gdje ukazuje SP, i novim ažuriranjem poentera, da ukazuje na
sljedeću novu lokaciju (čisti tanjir). Kada se varijabla uzima sa steka, onda
je to vraćanje opranog tanjira. Potrebno je SP uvećati. Dakle čišćenje steka
(vraćanje opranog tanjira), se satoji u vraćanju SP prema vrhu steka. Na slici
26 je prikazano 'spašavanje' vrijednosti 21 na stek i ponovno uzimanje (stek je
100 riječi, i dvije su već zauzete). Kao što se vidi sa slike, nije bitno što
vrijednost 21 (odnosno njena kopija), ostaje tamo gdje je bila (na adrsi steka
92), ta lokacija je proglašena slobodnom za novu vrijednost.
gdje steksize
predstavlja veličinu steka u riječima, odnono broj tanjira iz primjera. Nulta
adresa steka predstavlja tanjir na dnu strukture. Za nas je interesantan tanjir
sa vrha, i na njega će ukazivati posebna varijabla SP (Stack Poenter), u koji
se inicijalno postavlja adresa vrha stak'a. Kako se skupina tanjira u toku
korištenja smanjuje, to će i svaka lokacija na steku, na koju se stavi neka
vrijednost, smanjiti sadržaj SP za jednu riječ (2 ako se radi o 16'bitnoj
arhitekturi, 4 za 32.bitnu). Time stek pokazuje na sljedeću slobodnu lkaciju.
Novim korištenjem steka, dolazi do postavljanja vrijednosti koja se želi
koristiti tamo gdje ukazuje SP, i novim ažuriranjem poentera, da ukazuje na
sljedeću novu lokaciju (čisti tanjir). Kada se varijabla uzima sa steka, onda
je to vraćanje opranog tanjira. Potrebno je SP uvećati. Dakle čišćenje steka
(vraćanje opranog tanjira), se satoji u vraćanju SP prema vrhu steka. Na slici
26 je prikazano 'spašavanje' vrijednosti 21 na stek i ponovno uzimanje (stek je
100 riječi, i dvije su već zauzete). Kao što se vidi sa slike, nije bitno što
vrijednost 21 (odnosno njena kopija), ostaje tamo gdje je bila (na adrsi steka
92), ta lokacija je proglašena slobodnom za novu vrijednost.
Strategija operacija sa stekom je LIFO
(Last In First Out). Dakle, elemenat koji je zadnji stavljen na stek (kao i
tanjir koji je zadnji vraćen), prvi će biti izbačen sa steka. Operacija
stavljanja elemenata na stek je PUSH. Uzimanje elementa sa streka je POP. Ovo
su operacije, koje se zapravo sastoje od po dvije elementarne operacije.
Naredba PUSH stavlja vrijednost na stek tamo gdje trenutno pokazuje SP. Kako SP
uvijek treba pokazivati na sljedeću slobodnu lokaciju, to se sadržaj SP'a
umanjuje za 2 (kod 16'bitne arhitekture), odnosno 4 (kod 32'vo bitne
arhitekture). Naredba POP radi obratno. Kako SP pokazuje na slobodnu lokaciju (nema
ništa), to se prvo SP inkrementira, a onda uzima vrijednost na koju ukazuje.
Posle ove operacije, lokacija na koju ukazuje SP se smatra slobodnom. Ako
arhitektura u svome skupu instrukcija nema POP i PUSH instrukcije onda ih je
moguće realizovati za stek veličine hiljadu riječi na sljedeći način (pogledati
definisanje struktura podataka u poglavlju 6.7):
stekvel=1024
stek word stekvel
dup (?)
SP intptr stek
U ovome slučaju će
SP ukazivati na dno steka. Ako se želi da pokazuje na vrh (početak steka), onda
se treba dodati još instrukcija:
ADD SP,stekvel
Sada su
instrrukcije za manipulisanje stekom emuliraju:
·
PUSH
MOV (SP), varijabla
ADD SP,2
·
POP
SUB SP,2
MOV varijabla,(SP)
3.4 Pitanja i zadaci
1.
Napišite aritmetički izraz 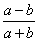 u prefix, infix i postfix
notaciji.
u prefix, infix i postfix
notaciji.
2.
Pokazati kako se izraz a=b+c, realizuje na
troadresnim, dvoadresnim i tro adresnim mašinama.
3.
Koje su prednosti a koje mahane dugih/kratkih
instrukcija i koje se računarske arhitekture zasnivaju na njima?
4.
Koja je to karakteristika asemblera, koja se ne
pojavljuje kod jezika HLL, te ga čini drugojačijim za programiranje?
5.
Kako kontrolni mehanizam u CPJ otkriva koliko
riječi treba učitati da bi se mogla aktivirati i zvršiti instrukcija?
6.
Zašto su računarske arhitekture kompatibilne prema
dolje (starim verzijama), a ne prema gore (prema novim verzijama)?
4 Centralna obrađivačka jedinica - Procesor
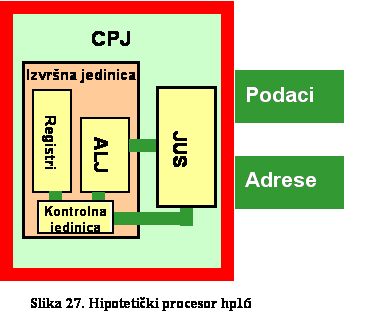 U prethodnim poglavljima, definišući različite
modele, 'kružili' smo oko srži problema, zvannog procesor. Iako je procesor
ključ snage računara, on je samo jedna od komponenata. To ima za posljedicu,
ukoliko se ne ukomponuju svi elementi da funkcionišu bez gubljenja ciklusa,
snaga procesora, pa čak ni takt iznad jednog GHz, neće mongo pomoći. Kako je
procesor veoma kompleksan, kako po svojoj konstrukciji, tako i funkcijama, u
ovome poglavlju ćemo definisati model hipotetičkog procesora. On će biti veoma
reduciran hardverski, a softverski će izvršavati ograničeni skup instrukcija.
To su već definisane primitivne instrukcije (prebacivanje, sabiranje,
šiftovanje i prekidi), uz proširenje manjim skupom instrukcija koje su
neophodne za izvršenje jednostavnijih programa.
U prethodnim poglavljima, definišući različite
modele, 'kružili' smo oko srži problema, zvannog procesor. Iako je procesor
ključ snage računara, on je samo jedna od komponenata. To ima za posljedicu,
ukoliko se ne ukomponuju svi elementi da funkcionišu bez gubljenja ciklusa,
snaga procesora, pa čak ni takt iznad jednog GHz, neće mongo pomoći. Kako je
procesor veoma kompleksan, kako po svojoj konstrukciji, tako i funkcijama, u
ovome poglavlju ćemo definisati model hipotetičkog procesora. On će biti veoma
reduciran hardverski, a softverski će izvršavati ograničeni skup instrukcija.
To su već definisane primitivne instrukcije (prebacivanje, sabiranje,
šiftovanje i prekidi), uz proširenje manjim skupom instrukcija koje su
neophodne za izvršenje jednostavnijih programa.
Naziv hipotetičkg procesora će biti hp16,
jer je njegova riječ 16 bita (dva bajta). Kako bi zadovoljio rješenja koja se
implementiraju u računarskim arhitekturama, osnovne funkcije procesora hp16 će
se proširivati. Tako dodavanjem spremnika za prihvatanje instrukcija procesor
će dobiti ime hp26. Proširenjem sa protočnošću (pipeline) dobit će ime hp46, a
dodavanjem elemenata skalarnih mašina dobija ime hp66. Zato se ovaj hipotetički
procesor može nazvati hpx6 .
4.1 Procesor
Na bazi
hipotetičkog procesora hp16 (slika 27) razmotrit ćemo osnovne elemente
arhitekture procesora: registre, aritmetičko-logičku jedinicu, jedinicu za povezivanje
sabirnica i kontrolnu jedinicu.
4.1.1 Registri
U poglavlju 3.2
registri su definisani kao specijalni dio memorije. Oni su konstruisani od
flip-flopova, nisu dio glavne memorije, već su izvedeni na čipu unutar samog
procesora. Veličini registra (u bitima) odgovara i veličina riječi glavne
memorije, pa se po njima deklariše i procesor. Familija procesora hpx6 ima
četiri 16'to bitna registra u kojima se dešavaju sve aritmetičko logičke
radnje. Kako registri predstavljaju ograničen skup lokacija, kako je ranije već
rečeno, oni se ne adresiraju sukcesivno (kao glavna memorija), već svaki ima
svoje ime. U arhitekturi hpx6 registri imaju sljedeća imena:
·
AX - akumulatorski registar (accumulator
register);
·
BX - bazno adresni registar (base
register);
·
CX - brojački registar (count register);
·
DX - podatkovni registar (data
register).
Pored navedenih
registara koji su vidljivi za programera hpx6 ima još i specijalne registre,
od kojih ćemo pomenuti:
·
PC - programski brojač (Programm Counter), koji
ukazuje na sljedeću instrukciju koja se treba izvršiti, pa se iz tog razloga
često naziva i IP (Instruction Poenter);
·
PSW - procesorska stausna riječ (Processor
Status Word), koja sadrži indikatore ili zastavice (flags) kao rezultat
prethodne operacije. U njoj se takođe nalaze i indikacije nekih linija
kontrolne sabirnice.
Kako su registri
na čipu i pristupa im se direktno preko CPJ'a, to su puno operativniji od
memorije. Tako, za pristup podacima u memoriji treba jedan ili više ciklusa,
dok za pristup podacima u registrima ne treba ni jedan ciklus (jer su već u
procesoru). Zato je poželjno, kada je god to moguće, varijable držati u
registrima. No, kako je broj registatara ograničen, a imaju i specijalnu
namjenu, to je njihovo korištenje za varijable veoma ograničeno. Ipak, mogu se
fino iskoristiti za smještanje privremenih varijabli (međurezultata).
4.1.2 Aritmetičko-logička jedinica - ALJ
Aritmetičko-logička jedinica
(Arithmetic&Logic Unit) je mjesto na kojeme se izvršavju većina događaja
unutar CPJ'a. Tako, ako se želi dodati broj deset u AX registar, CPJ će
(pogledati slike 7 i 8):
·
Iskopirati sadržaj AX registra u ALJ (broj A, sa
slike);
·
Staviti broj deset u ALJ (broj B);
·
Izdati instrukciju ALJ'u da sabere ta dva broja;
·
Vratiti rezultat operacije iz ALJ'a (broj S) u
AX.
4.1.3 Jedinica za upravljanje sabirnicama - JUS
Kontrolu pristupa memoriji (uz pomoć
podatkovne i adresne sabirnice) vrši jedinica za upravljanje sabirnicama - JUS
(Bus Interchange Unit - BIU). Ako arhitektura podržava keš memoriju, onda je
JUS odgovoran i za pristup podacima u keš memoriji.
4.1.4 Kontrolna jedinica - KU
Ograniočeni skup komandi koje procesor
prepoznaje i zna koje akcije da poduzme kada ih dobije čini instrukcioni set,
a komande se zovu instrukcije. Uvijek treba imati na umu da je procesor
dizajniran iz logičkih kola (gate’ova), sa konačnim brojem stanja, koja se
definisana instrukcoijama. Da bi se brij stanja i kola držao u razumno
shvatljivo malom broju (desetine ili stotine hiljada), to se dizajneri trude da
smanje koliko je god moguće, broj komandi koje procesor prepoznaje. Tako
dobijeni minimalni skup komandi predstavlja CPJ instukcijski skup (set).
Arhitektura VNA računara podržava koncept
pohranjenog programa. Time je prevaziđen problem arhitektura koje su prethodile
VNA arihtekturi: računari su imali program fiksno ukodiran i nije se mogao
mijenjati. Svakako ključ u prevazilaženju tog problema leži u kontrolnij
jedinici - KU (Control Unit - CU). Kontrolna jedinica uzima (učitava) iz
memorijski storiranog programa instrukciju po instrukciju u registar za
dekodiranje (decoding register). Registar za dekodiranje je specijalno
dizajnira za ovu funkciju i povezan sa logičkim krugovima za dekodiranje u
CPJ'u. Kako je već rečeno, da bi se smanjio broj kola, poželjno je imati manje
instrukcija. Broj instrukcija je definisan brojem bita rezervisanih za njihovu
identifikaciju, odnosno operacioni kod. Instrukcija hpx6 procesora će biti na
jednome bajtu. To bi značilo da se može definisati 256 instrukcija, no nije baš
tako. U instrukciji su, kako je navedeno u 3.1, sadržani i parametri
instrukcije. Zato ćemo za sada uzeti da razmatramo hpx6 kao arhitekturu
dvo adrsne mašine. To znači, da pored operacionog koda, u instrukciji se mora
predvidjeti i mjesto za operande. Zato će se generalno rezervisati tri bita za
opkod, po dva bita za odredišni i izvorni operand i jedan bit za specijalnu
namjenu kod izvornog operanda (Slika 28).
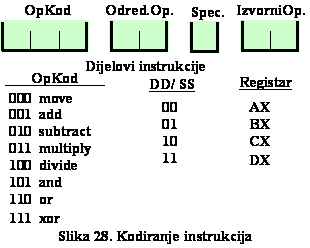 Kada dizjniraju instrukcioni set, dizajneri CPJ'a
uglavnom dizajniraju opkod da bude multipl bajta, Kako
bi CPJ jednostavno mogla da dobavi čitave instrukcije iz memorije. Cilj
dizajnera je da obezbijede dovoljno bita za polje opkoda (move, add, subtract
itd.) i za polja operanada. Rezervisanjem više bita za polje operanda omogućava
da se ima više instrukcija, a rezervisanjem više bita za operande omogućava da
se može odabrati više operanada (tj. memorijskih lokacija ili registara).
Postoje i dodatne komplikacije. Neke instrukcije imaju samo jedan operand, ili
nemaju operanada uopšte. Umjesto da se razbucuje sa bitima, uz mali dodatak logičkih krugova, može se CPJ
dizajnirati da ta slobodna mjesta prepozna kao dodatne operacione kodove. I
ponovo se surećemo sa pričom o mostu i ćupriji: imati kompleksan i moćan CPJ
ili jednostavan i siromašan. Normalno hpx6 je odabran da bude jednostavan i
siromašan, kako bi se uspjeli shvatiti principi rada.
Kada dizjniraju instrukcioni set, dizajneri CPJ'a
uglavnom dizajniraju opkod da bude multipl bajta, Kako
bi CPJ jednostavno mogla da dobavi čitave instrukcije iz memorije. Cilj
dizajnera je da obezbijede dovoljno bita za polje opkoda (move, add, subtract
itd.) i za polja operanada. Rezervisanjem više bita za polje operanda omogućava
da se ima više instrukcija, a rezervisanjem više bita za operande omogućava da
se može odabrati više operanada (tj. memorijskih lokacija ili registara).
Postoje i dodatne komplikacije. Neke instrukcije imaju samo jedan operand, ili
nemaju operanada uopšte. Umjesto da se razbucuje sa bitima, uz mali dodatak logičkih krugova, može se CPJ
dizajnirati da ta slobodna mjesta prepozna kao dodatne operacione kodove. I
ponovo se surećemo sa pričom o mostu i ćupriji: imati kompleksan i moćan CPJ
ili jednostavan i siromašan. Normalno hpx6 je odabran da bude jednostavan i
siromašan, kako bi se uspjeli shvatiti principi rada.
Kontrolna jedinica dohvata instrukciju, na
koju ukazuje PC i smješta je u registar za dekodiranje i izvršavanje. Poslije
izvršenja instrukcije, kontrolna jedinica inkrementira PC za sljedeću
instrukciju, dohvata je, izvršava, i tako redom.
4.2 Instrukcioni set procesora hpx6
Arhitektura hpx6 podržava instrukcioni set
od 20 instrukcija: 7 sa dva operanda; 8 sa jednim operandom; i 5 instrukcija
nema operanda uošte. To su: mov (dvije forme), add, sub, cmp,
and, or, not, je, jne, jb, jbe, ja, jae, jmp, brk, iret, halt, get i put.
U sljedećem paragrafu bit će razmotrene pojedine instrukcije.
Sintaksa instrukcija sa dva operanada je
definisana zapravo tako, da je odredišni operand prvi operand koji se navodi u
polju za operanade, odmah poslije opkoda instrukcije. Treći parametar u
instrukciji (i zadnji) je izvorni operand, mjesto sa kojeg se uzima operand nad
kojim se vrši operacija definisana opkodom. Radi efikasnosti programa, preporučuje
se da odredišni operand bude u registru (međurezultat), dok je izvorni obično
neka lokacija iz memorije, definisana načinom adresiranja.
4.2.1 Instrukcija za prebacivanje podataka -
MOV
Instrukcija za prebacivanje podataka između
memorije i procesora se sastoji iz dvije forme:
·
Punjenje podataka iz memorije u procesor,
odnosno registre (Load instrukcija) ima formu:
mov reg,reg/memorija/konstanta;
·
Smještanje podataka iz procesora u memoriju,
odnosno registre (Store instrukcija) ima formu:
mov memorija,reg;
gdje je reg
jedan od registara ax, bx, cx ili dx; memorija je operand koji
specificira memorijsku lokaciju; a konstanta predstavlja numeričku konstantu (u
hekadecimalnoj notaciji). Oblik operanda 'reg/memorija/konstanta' znači da
dati operand može da bude registar ili memorijska lokacija ili konstanta.
4.2.2 Aritmetičko-logičke instrukcije
Aritmetičko-logičke instrukcije imaju
sljedeće forme:
·
add reg,reg/memorija/konstanta;
·
sub reg,reg/memorija/konstanta;
·
cmp reg,reg/memorija/konstanta;
·
and reg,reg/memorija/konstanta;
·
or reg,reg/memorija/konstanta;
·
not reg/memorija;
Instrukcija add dodaje vrijednost
drugog (izvornog) operanda, prvome (koji mora biti registar) i ostavlja sumu u
njemu (odredišnji operand). Instrukcija sub oduzima izvorni od
odredišnjeg operanda i razliku ostavlja u odredišnjemu. Instrukcija poređenja cmp,
poredi sadržaj operanada (izvrši oduzimanje kao i instrukcija sub), bez
promjene sadržaja operanada, a rezultat poređenja se nalazi u obliku flegova u
statusnoj riječi. Logičke instrukcije and i or vrše logičke
operacije nad operandima između bita i rezultat se nalazi u odredšnjemu
operandu. Instrukcija not ima samo jedan operand (u registru ili
memoriji) i izvrši samo inverziju bita.
4.2.3 Instrukcija kontrole toka programa
Instrukcije kontrole toka programa vrše
prekid sekvencijalnog izvršenja programa, uslovno ili bezuslovno, na osnovu
testiranja bita statusne riječi posle neke instrukcije poređenja. To su
sljedeće instrukcije (kako bi se videlo porijeklo mnemonika instrukcija,
objašnjenje je dato na engleskome jeziku):
·
ja dest -
jump if above (>);
·
jae dest -
jump if above or equal (³);
·
jb dest -
jump if below (<);
·
jbe dest -
jump if below or equal (£);
·
je dest -
jump if equal (=);
·
jne dest -
jump if not equal (¹);
·
jmp dest -
bezuslovni jump;
·
iret -
return from interupt;
Prvih šest instrukcija iz ove klase se
izvršavaju na osnovu flegova u statusnoj riječi, kao posljedica prethodne
instrukcije za: veće od, veće ili jednako, manje od, manje ili jednako, jednako
i različito. Instrukcija jmp vrši bezuslovan skok na dio programa
označen operandom dest. Kako se adresa sljedeće instrukcije za izvršenje
uvijek nalazi u PC'u, to instrukcije grananja, zapravo 'pune' registar PC sa
adresom koja se nalazi u dest. Instrukcija povratka iz interupta je malo
komplikovanija i o njoj će biti kasnije (mada se principi interupt dati u 2.3).
Instrukcije ulaza/izlaza get i put
zaustavljaju program i vrše:
·
get učitavanje sa
tastature hexadecimalnog broja u ax;
·
put ispis
sadržaja ax hexadecimalno.
Preostale instrukcije su bez parametara.
BRK prekida izvršenje programa, sa mogućnošću da se nastavi, a HALT ga
terminira.
4.3 Načini adresiranja procesora hpx6
Instrukcije se generišu tako što se
kombinuju opkodovi i operandi. Tako, prema slici 28, možemo generisati
instrukciju za sabiranje sadržaja prvog (po redu) i drugog registra kao: ADD
AX,BX; što se može kodirati kao 001 00 0 01 ili 21h. Međutim, navedena šema ne
daje jednostavan odgovor kako kodirati instrukciju za dodavanje broja 100
registru AX. Zapravo, kodirana instrukcija treba biti veličine bajta, a sama
konstanta 100 zauzima jedan bajt. U ovome slučaju se konstanta (varijabla)
smješta u riječ koja slijedi neposredno iza bajta instrukcije. Ovo zapravo
predstavlja metod, kako se kodira fraza 'reg/memorija/konstanta'. Isti problem
se javlja kod instrukcije: JMP dest. Kako dest traži riječ, a
tri bita treba rezervisati za opkod, to su neophodna tri bajta. Metoda
adresiranja operanada da bi se pristupilo njihovim lokacijama zove se način
adresiranja (Addressing Modes). Hipotetički procesor hpx6 podržava
sljedeće načine (modove) adresiranja:
·
 Registarsko adresiranje: operandi se nalaze u registrima. Za
kodiranje instrukcije dovoljan je jedan bajt i veoma je jednostavna za razumijevanje.
Registarsko adresiranje: operandi se nalaze u registrima. Za
kodiranje instrukcije dovoljan je jedan bajt i veoma je jednostavna za razumijevanje.
mov ax,ax
mov ax,bx
mov ax,cx
mov ax,dx
 Prva
instrukcija (čiji je kod 00000000B) zapravo ne radi ništa: kopira sadržaj
registra ax u samoga sebe. Ostale instrukcije kopiraju sadržaj izvornih
registara (bx, cx, dx respektivno) u odredišni registar ax.
Naravno, kao što može izvorni registar biti bili koji, tako ni za odredišni ne
postoji nikakvo ograničenje.
Prva
instrukcija (čiji je kod 00000000B) zapravo ne radi ništa: kopira sadržaj
registra ax u samoga sebe. Ostale instrukcije kopiraju sadržaj izvornih
registara (bx, cx, dx respektivno) u odredišni registar ax.
Naravno, kao što može izvorni registar biti bili koji, tako ni za odredišni ne
postoji nikakvo ograničenje.
·
Neposredno adresiranje: za operand se koristi neposredna
vrijednost (konstanta) kao u sljedećem primjeru:
mov ax,25
mov bx,195
mov cx,2056
mov dx,1000
instrukcije
pune registre sa heksadecimalnim
konstantama.
·
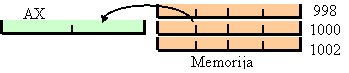 Direktno adresiranje: operandu se direktno pristupa na
specificiranoj adresi. Tako, za slučaj da se želi u dx smjestiti sadržaj
varijable sa memorijske lokacije 1000, kod instrukcije će biti:
Direktno adresiranje: operandu se direktno pristupa na
specificiranoj adresi. Tako, za slučaj da se želi u dx smjestiti sadržaj
varijable sa memorijske lokacije 1000, kod instrukcije će biti:
mov ax,[1000].
·
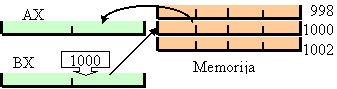 Indirektno adresiranje: adresa operanda se nalazi u nekome od
registara. Tako, slučaj primjera iz direktnog adresiranja, koristeći registar bx
za indirektni pristup biti će:
Indirektno adresiranje: adresa operanda se nalazi u nekome od
registara. Tako, slučaj primjera iz direktnog adresiranja, koristeći registar bx
za indirektni pristup biti će:
mov bx,1000
mov ax,[bx]
·
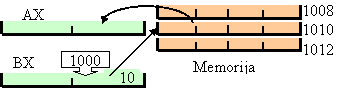 Indexno adresiranje: adresa operanda se dobija koa zbir
sadržaja nekog od registara i konstante. Ovaj način se posebno primjenjuje za
pristup podacima u strukturama (nizovima, slogovima i sl.). Ako niz počinje na
adresi 1000, a registar bx pokazuje na jedanaesti elemenat niza koji je
trenutno na redu za obradu, onda će se tome elementu pristupiti sljedećom
instrukcijom:
Indexno adresiranje: adresa operanda se dobija koa zbir
sadržaja nekog od registara i konstante. Ovaj način se posebno primjenjuje za
pristup podacima u strukturama (nizovima, slogovima i sl.). Ako niz počinje na
adresi 1000, a registar bx pokazuje na jedanaesti elemenat niza koji je
trenutno na redu za obradu, onda će se tome elementu pristupiti sljedećom
instrukcijom:
mov ax,[bx+1000]
4.4 Kodiranje instrukcija za procesor hpx6
Kako se dekoidaranje instrukcija vrši u
registru za dekodiranje, koji je napravljen od logičkih kola, to znači da i
kodiranje instrukcija zahtjeva određenu logiku. Dati
opkod se nalazi na određenome broju bita, i na osnovu njega se zna broj
operanada. Analizom (dekodiranjem) načina adresiranja operanada, ustanovljava
se dužina instrukcija, što ima za posljedicu inkremientiranje PC, kako bi se
došlo do sljedeće instrukcije. Pošto se broj riječi utvrđuje tek dekodiranjem
opkoda i operanada, to znači da arhitektura hpx6 pripada CISC arhitekturi, i
podržava dvoadresne, jednoadresne i nuladresne mašine.
|
|
 |
Tipične dvoadresne instrukcije hpx6 imaju formu kao na slici
29. Instrukcije mogu biti duge jedan dva ili tri bajta. Opkod se nalazi u
prvome bajtu koji se sastoji od tri polja. Prvo polje, koje se nalazi na tri
V.Z. bita definiše klasu instrukcije i omogućava osam kombinacija. Kao što je
poznato postoji 20 instrukcija. Kako je nemoguće kodirati 20 instrukcija sa tri
bita, to se moraju primjeniti neki 'trikovi' (zato i jeste CISC mašina). Sa
slike se vidi da postoje dvije klase mov instrukcije (za load je rr
odredište a mmm izvor dok je kod store obratno), te add, sub,
cmp, and i or instrukcije. Postoji i jedna specijalna klasa
instrukcija. Ova specijalna klasa omogućava da se proširi broj instrukcija koje
se mogu kodirati.
Kodiranje instrukcije se sastoji u
pravilnome odabiru iii rr i mmm polja. Za kodiranje instrukcije: mov
ax,bx odabrat će se za iii=110 (mov reg,reg), rr=00
(ax) i mmm=001 (bx). Time se generiše jednobajtna
instrukcija 11000001B, odnosno 0C1h. neke instrukcij hpx6 zahtjevaju više od
jednog bajta. Tako recimo instrukcija mov ax,1000, puni registar
ax sa memorijske lokacije 1000. Kodiranjem ove instrukcije, polje mmm=110
([xxxx]), što generiše 11000110B, ili hexadecimalno 0C6h. međutim i za
instrukciju mov ax,2000 kod je isti, mada radi drugu stvar:
umjesto sa lokacije 1000 u ax smješta sadržaj sa lokacije 2000? Za
kodiranje adresa [xxxx] ili [xxxx+bx] načina adresiranja
(direktno ili indexno adresiranje), te za kodiranje konstante za neposredni
način, treba se kodirati još jedna riječ koja slijedi opkod i sadrži adresu ili
konstantu. Navedene instrukcije će se kodirati: mov ax,[1000]
sa 0C6h, 00h 10h;
a mov ax,[2000] sa 0C6h, 00h 20h.
Kao što je rečeno, specijalni
opkod omogućava proširenje broja instrukcija koje se mogu kodirati sa tri bita
(slika 30). Postoje četiri jednoadresne instrukcije. Prva klasa sa kodom 00
predstavlja instrukcije bez operanada i koristi se za proširenje kodiranja
adresiranja, kao specijalni kôd kod dvoadresnih instrukcija (slika 32). Druga
klasa, sa kôdom 01, takođe se koristi za proširenje kodiranja instrukcija
grananja (slika 31). Treća je logička instrukcija not. Ona vrši logičku
operaciju nad bitima u registru ili memorijskoj lokaciji. Četvrtoj klasi nije
za sada pridružen opkod ni jedne instrukcije i njeno izvršenje izaziva grešku i
zaustavljanje procesora.
Procesor hpx6 podržava sedam instrukcija
grananja čiji je opšti oblik:
jxx adresa.
Instrukcija grananja kopira 16 bitnu vrijednost iz riječi koja
slijedi opkod u PC, što uzrokuje da to bude sljedeća instrukcija za izvršenje.
Tako, procesor izvršava sljedeću instrukciju sa odrdišne adrese, a zapravo
program 'skače' sa tačke gdje se nalazi instrukcija skoka na mjesto u programu
označeno adresom.
Instrukcija jmp je instrukcija bezuislovnog
skoka. Ona uvijek puni PC adresom instrukcije na koju se treba skočiti.
Preostalih šest instrukcija su instrukcije uslovnog grananja: one testiraju
odgovarajuće bite u statusnoj riječi i ako je uslov zadovoljen doći do skoka,
inače će program nastaviti da se izvršava sljedećom instrukcijom. Ovde je bitno
napomenuti razliku kod izračunavanja adrese skoka između instrukcija uslovnog i
bezuslovnog grananja.
·
Uslovno grananje:
do uslovnog skoka će doći samo ako je zadovoljen uslov za grananje koji je
postavljen neposredno prije ove instrukcije. Adresa grananja se izračunava u
fazi asembliranja tako što se tekuća adresa (koja se nalazi u PC i predstavlja
adresu sljedeće instrukcije ako ne bi bilo grananja) oduzima od adrese
instrukije na koju treba izvršiti granjanje (skok). Ovdje se da primjetiti, ako
se grana na adresu koja se nalazi prije tekuće adrese (unazad) pomak za grannje
će biti negativan broj. U fazi izvršenja instrukcije, vrijednost pomaka se
dodaje sadržaju PC, čime se dobija adresa instrukcije na koju treba skočiti.
Naravno, ako uslov grananja nije zadovoljen onda će u PC'u ostati stara
vrijednost i neće doći do grananja. Ovaj tip instrukcija se sastoji od dva
bajta, gde drugi bajt predstavlja pomak, što znači da je 'domet' skoka ±128 bajta.
·
Bezuslovno granjanje: do ovog skoka će doći uvijek i izračunava se na sljedeći način:
adresom instrukcije na koju se grana se jednostavno zamijeni sadržaj PC, tako
da se ova instrukcija zapravo može emulirati instrukcijom mov. Ova
instrukcija je duga tri bajta, što znači da se za adresiranje koristi riječ, pa
je domet skoka ±32768 bajta.
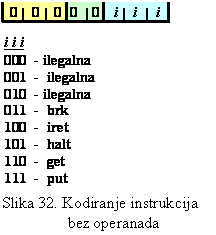 Instrukcije uslovnog skoka (grananja), je, jne,
jb, jbe, ja i jae vrše testiranje da li je jednak, različit, manji,
manji ili jednaki, veći, veći ili jednak uslov. Ovaj test se vrši obično
poslije instrukcije cmp, mada ne mora uvijek da znači (i neke druge
instrukcije vrše postavljanje zastavica).
Instrukcije uslovnog skoka (grananja), je, jne,
jb, jbe, ja i jae vrše testiranje da li je jednak, različit, manji,
manji ili jednaki, veći, veći ili jednak uslov. Ovaj test se vrši obično
poslije instrukcije cmp, mada ne mora uvijek da znači (i neke druge
instrukcije vrše postavljanje zastavica).
Zadnja grupa instrukcija, instrukcije bez
operanada, je prikazana na slici 32. Prve tri instrukcije iz ove grupe su
ilegalne. Četvrta instrukcija, brk (break), zaustavlja procesor sve dok
ga korisnik ne resetuje. Može se koristiti da napravi prekid programa radi
pregleda međurezultata. Instrukcija iret (interupt return), vraća
kontrolu korisnikovome programu iz ISR (interupt service routine). Halt
instrukcija zaustavlja (terminira) izvršenje programa. Instrukcija get
(instrukcija čitanja) učitava jedan bajt (hexadecimalno) sa tastature i smješta
ga u ax. Ispis se vrši instrukcijom put, koja sadržaj registra ax
(hexadecimalno) prikazuje na ekranu.
4.5 Faze izvršenja instrukciije
Izvršenje instrukcije ne traje u jednome
ciklusu, tj. ona nije primitivna operacija. Pored toga, što je instrukcija
vremenski sastavljena iz više ciklusa, za njeno izvršenje angažovano je više
logičkih sklopova (koji pripadaju različitim računarski elementima). Kako CPJ
troši više ciklusa za izvršenje jedne instrukcije, razmotrimo faze izvršenja
instrukcije mov reg,reg/memorija/konstanta:
·
Dohvati bajt instrukcije iz memorije - 1 ciklus;
·
Ažuriraj (uvećaj za 1) PC registar da pokazuje
na sljedeću instrukciju - 1 ciklus;
·
Dekodoiraj instrukciju kako bi se ustanovilo
koja je - 1 ciklus;
·
Ako je potrebno, dohvati 16 bitnu riječ iz
memorije - 2/1/0 ciklusa;
·
Ako je uzeta 16 bitna riječ iz memorije, podesi
PC (uvećaj ga za 2), kako bi pokazivao na sljedeću instrukciju - 1/0 ciklusa;
·
Izračunaj adresu operanda ako je potrebno (u
slučaju xxxx+bx) - 2/1/0 ciklusa;
·
Dohvati operand - 3/2/1/0 ciklusa;
·
Smjesti dohvaćenu vrijednost u odredišni
registar - 1 ciklus.
Analiza izvršenja instrukcije korak po
korak, pokazuje pojedine faze izvršenja instrukcije. U prvome koraku, CPJ uzima
instrukciju iz memorije i smješta u registar za dekodiranje. Da bi izvršio ovu
fazu (poglavlje 2.1.2), vrijednost PC'a se postavlja (kopira) na adresnoj
sabirnici, postavlja se signal Read=0 na kontrolnoj sabirnici i sa podatkovne
sbirnice se učitava bajt. Ova operacije traje jedan ciklus sistemskog sahata.
Kako PC treba uvijek da pokazuje na
sljedeću instrukciju za izvršenje (učitavanje), to se u koraku 2, ažurira PC.
Pošto je učitan jedan bajt, vrijednost PC se povećava za jedan. Ako se bude
radilo o instrukciji od više bajta, onda će PC pokazivati na operand, inače na
sljedeću instrukciju koja se treba izvršiti. Ovo takođe traje jedan ciklus
sistemskog sahata.
Šta instrukcija znači, otkriva se tek u
ovoj fazi - fazi dekodiranja. Poslije dekodiranja, CPJ će znati, između
ostalog, da li treba dohvatiti operand iz memorije ili ne. Ovaj korak takođe
zahtjeva jedan ciklus.
Za vrijeme dekodiranja instrukcije određuje
se tip operanda koji zahtjeva instrukcija. Ako instrukcija zahtjeva 16 bitnu
konstantu za operand (tj. mmm polje je 101, 110 ili 111) CPJ dobavlja
konstantu iz memorije. Ovaj korak može trajati nula, jeadn ili dva ciklusa. Ako
ne treba 16 bitna konstanta, onda i ne radi ništa, pa ovaj korak traje nula
ciklusa. U slučaju da je potrebna konstanta i da je podešena po riječima
(nalazi se na parnoj adresi), CPJ troši jedan ciklus. Ako se konstanta ne
nalazi na parnoj adresi, onda se čita riječ sa neparne adrese, a onda sa parne,
pa se vrši podešavanje, što zahtjeva dva ciklusa sahata.
Ako je bila potrebna 16 bitna konstanta,
onda se u sljedećem koraku vrši podešavanje PC (uvećavanje za 2), za što se
troši jedan ciklus; u slučaju da nije bilo 16 bitne konstante, ne troši se
nikakav dodatni ciklus.
Sljedeće je izračunavanje adrese
memorijskog operanda. Ovaj se korak izvršava pod uslovom da je polje mmm u
bajtu instrukcije 100 ili 101. Ako mmm sadrži 101, onda CPJ izračunava
sumu sadržaja registra bx i 16 bitne konstante. Za ovo se troše dva
ciklusa: jedan za dohvat vrijednosti bx, a drugi za izrčunavanje sume (bx+xxxx).
Ako pak mmm sadrži 100, onda je potreban jedan ciklus. U slučaju da mmm
ne sadrži ni 100 ni 101, onda za ovu fazu ne trba ni jedan ciklus.
Za dohvatanje operanda treba nula, jedan,
dva ili tri ciklusa u zavisnosti od samog operanda. Ako je operand konstanta (mmm=111),
ne treba ni jedan ciklus, jer je ova konstanta već dohvaćena u prethodnoj fazi.
Kakda je operand registar (mmm=000, 001, 010 ili 011), onda ovaj korak
troši jedan ciklus. Ako je adresno podešen operand (mmm=100, 101 ili
110), tada trebaju dva ciklusa; a za slučaj da nije na parnoj adresi, onda ovaj
korak troši tri ciklusa.
Zadnji korak mov instrukcije je storiranje
vrijednosti u odredišnji registar. Kako je odredište uvijek registar, to ovaj
korak troši jedan ciklus.
Što znači da mov instrukcija (load
forma), troši, u zavisnosti od operanda i podešenosti adrese, između pet i
dvanaest ciklusa sistemskog sahata.
Drugi oblik mov instrukcije, za smještanje
sadržaja u memoriju, mov memorija,reg izvršava se u sljecdećim
fazama:
·
Dohvati bajt instrukcije iz memorije (jedan
ciklus za izvršenje);
·
Ažuriraj PC registar da pokazuje na sljedeću
instrukciju (jedan ciklus);
·
Dekodoiraj instrukciju kako bi se ustanovilo
koja je (jedan ciklus);
·
Ako je potrebno, dohvati operand iz memorije
(nula ciklusa ako je [bx] način adresiranja, jedan ciklus ako je [xxxx],
[xxxx+bx] ili xxxx vrijednost koja slijedi opkod počinje
na parnoj adresi, a dva ciklusa ako vrijednost počinje na neparnoj adresi) ;
·
Ako je potrebno podesi PC (nula ciklusa ako nema
operanda u memoriji, a jedan ako ima);
·
Izračunaj adresu operanda ako je potrebno (nula
ciklusa ako mod nije [bx] ili [xxxx+bx], jedan ako je [bx],
a dva ako je [xxxx+bx]);
·
Dobavi vrijednost iz registra za storiranje
(jedan ciklus);
·
Smjesti dohvaćenu vrijednost u odredišnu
lokaciju: jedan ciklus ako je u registru; dva ciklusa ako je riječ na parnoj
adresi; tri ciklusa ako je riječ u memoriji na neparnoj adresi.
Instrukcije add, sub, cmp, and i or
se izvršavaju na sljedeći način:
·
Dohvati bajt instrukcije iz memorije (jedan
ciklus za izvršenje);
·
Ažuriraj PC registar da pokazuje na sljedeću
instrukciju (jedan ciklus);
·
Dekodoiraj instrukciju (jedan ciklus);
·
Ako je potrebno, dohvati operand iz memorije
(nula ciklusa ako je [bx] način adresiranja, jedan ciklus ako je [xxxx],
[xxxx+bx] ili xxxx vrijednost koja slijedi opkod počinje
na parnoj adresi, a dva ciklusa ako vrijednost počinje na neparnoj adresi) ;
·
Ako je potrebno podesi PC (nula ili jedan
ciklus);
·
Izračunaj adresu operanda ako je potrebno (nula
ciklusa ako mod nije [bx] ili [xxxx+bx], jedan ako je [bx],
a dva ako je [xxxx+bx]);
·
Dohvati operand i smjesti ga u ALJ (nula ciklusa
za konstantu, jedan ciklus ako je u registru, dva ciklusa za operand iz
memorije parno podešen i tri ciklusa ako je na neparnoj adrsi);
·
Dobavi vrijednost prvog operanda (iz registra) u
smjesti ga u ALJ (jedan ciklus);
·
Instrukcija ALJ'u šta da uradi: sabere, oduzme,
poredi ili izvrši logičku operaciju (jedan ciklus);
·
Smjesti rezultat nazad, na mjesto prvog operanda
u registru (jedan ciklus).
Za izvršenje ovih instrukcija potrebno je
između osam i sedamnaest ciklusa.
Naredba not je slična, ali brža jer
zahtjeva samo jedan operand. Ona troši između šest i petnaest ciklusa:
·
Dohvati bajt instrukcije iz memorije (jedan
ciklus za izvršenje);
·
Ažuriraj PC registar da pokazuje na sljedeću
instrukciju (jedan ciklus);
·
Dekodoiraj instrukciju (jedan ciklus);
·
Ako je potrebno, dohvati operand iz memorije
(nula ciklusa ako je [bx] način adresiranja, jedan ciklus ako je [xxxx],
[xxxx+bx] ili xxxx vrijednost koja slijedi opkod počinje
na parnoj adresi, a dva ciklusa ako vrijednost počinje na neparnoj adresi) ;
·
Ako je potrebno podesi PC (nula ili jedan
ciklus);
·
Izračunaj adresu operanda ako je potrebno (nula
ciklusa ako mod nije [bx] ili [xxxx+bx], jedan ako je [bx],
a dva ako je [xxxx+bx]);
·
Dohvati operand i smjesti ga u ALJ (nula ciklusa
za konstantu, jedan ciklus ako je u registru, dva ciklusa za operand iz memorije
parno podešen i tri ciklusa ako je na neparnoj adrsi);
·
Instrukcija ALJ'u da izvrši logičku not
operaciju (jedan ciklus);
·
Smjesti rezultat nazad, na mjesto mjesto
operanda udakle je i uzet (jedan ciklus).
Instrukcije uslovnog skoka se izvršavaju na
sljedeći način:
·
Dohvati bajt instrukcije iz memorije (jedan
ciklus za izvršenje);
·
Ažuriraj PC registar da pokazuje na sljedeću
instrukciju (jedan ciklus);
·
Dekodoiraj instrukciju (jedan ciklus);
·
Dohvati ciljnu adresu operanda iz memorije
(jedan ciklus ako adresa xxxx počinje na parnoj, a dva na neparnoj
adresi);
·
Ažuriraj PC (jedan ciklus);
·
Testiraj odgovarajući bit u statusnoj riječi za
skook (jedan ciklus);
·
Ako je zadovoljen uslov za skok, onda se kopira
16 bitna adresa u PC(nula ciklusa ako nema skoka, jedan za skok);
Naredba bezuslovnog skoka je identična
naredbi mov reg,memorija, izuzev što je odredišni registar
uvijek PC.
4.6 Unapređenja hpx6 procesora
Osnovni razlog, što nije u srtartu
prezentiran hp66 procesor, je pojednostavljenje konfiguracije radi lakšeg
poimanja. Poslije prezentiranja osnovnog modela hpx6, uvode se 'naprednije'
arhitekture: hp26 sa spremnikom za pribavljanje instrukcija; sa hp46 uvodi se
protočnost (pipeline); da bi se serija završila superskalarnim hipotetičkim
procesorom hp66.
4.6.1 Procesor hp16 - osnovni procesor
Hp16 je prvi iz familije hipotetičkih
procesora hpx6. Na njega se odnosi sve što je do sada rečeno. U tabeli su
prikazana vremena (tajminzi) izvršenja pojedinih instrukcija (koja se lahko
dobiju sabiranjem ciklusa u poglavlju 4.5).
|
Instrukcija Þ
ßNačin
adresiranja
|
mov
(obije)
|
add,sub, cmp,and,or
|
Not
|
Jmp
|
jxx
|
|
reg,reg
|
5
|
7
|
|
|
|
|
reg,xxxx
|
6-7
|
8-9
|
|
|
|
|
reg,[bx]
|
7-8
|
9-10
|
|
|
|
|
reg,[xxxx]
|
8-10
|
10-12
|
|
|
|
|
reg,[xxxx+bx]
|
10-12
|
12-14
|
|
|
|
|
[bx],reg
|
7-8
|
|
|
|
|
|
[xxxx],reg
|
8-10
|
|
|
|
|
|
[xxxx+bx],reg
|
10-12
|
|
|
|
|
|
reg
|
|
|
6
|
|
|
|
[bx]
|
|
|
9-11
|
|
|
|
[xxxx]
|
|
|
10-13
|
|
|
|
[xxxx+bx]
|
|
|
12-15
|
|
|
|
xxxx
|
|
|
|
6-7
|
6-8
|
Tabela
5. Vrijeme izvršenja za instrukcije hp16
Iz navedenog da se zaključiti:
·
Duge instrukcije traže puno više vremena za
izvršenje;
·
Instrukcije koje se ne referenciraju na memoriju
generalno se izvršavaju brže; pogotovu ako je memorija sa stanjima čekanja, jer
se navedena tabela odnosi na nula wait stanja;
·
Instrukcije sa kompleksnim načinima adresiranja
izvršavaju se sporije.
Instrukcije sa operandima u registrima su
kraće, jer ne koriste operande u memoriji i kompleksne načine adresiranja. Zato
je ovo dovoljan razlog da se varijable drže u registrima kada je god to
moguće.
4.6.2 Procesor hp26 - spremnik za pribavljanje
instrukcija
Najjednostavniji način ubrzanja nekog
procesa, jeste eleminisati čekanja. Ovo se može realizovati tako, dok se čeka
na neku operaciju da se izvršava neka druga, što znači uvođenjem paralelizma.
Na taj način bi se instrukcije izvršavale duplo brže pri istom otkucaju
sistemskog sahata. U tu svrhu treba odabrati operacije koje se izvršavaju
istovremeno na različitim funkcionalnim jedinicima kao što su ALJ i CU.
Treba odabrati operacije koje se ne izvršavaju istovremeno na istoj
funkcionalnoj jedinici. Zapravo, svaka operacija se izvršava u sekvencama. Ne
može se smjestiti suma operanda u prvome operandu, prije nego što se oni
saberu. Odatle i objašnjenje da Pascalski izraz i:=i+1; ne znači
izjednačavanje, već pridruživanje sa pomakom od barem jednog clocka. Drugo
ograničenje je da se CPJ ne može koristiti kada faze izvršenja traže iste
resurse. Tako, ne može se istovremeno čitati i pisati operand, odnosno
rezultat, jer koristi zajedničku podatkovnu sabirnicu. Da bi se realizovao
paralelizam, potrebno je CPJ tako dizajnirati da može izvršiti nekoliko koraka
paralelno, tako što će se ovi koraci predefinisati kako bi se izbjegli
konflikti. Takođe, potrebno je realizovati dodatna logičkih kola, kako bi se
operacije izvršile simultano na različitim funkcionalnim jedinicama.
Razmotrimo sada ponovo mov reg,reg/memorija/konstanta
instrukciju u namjeri da pronađemo dijelove koji se moraju izvršavati
paralelno:
1.
Dohvati bajt instrukcije iz memorije;
2.
Ažuriraj PC registar da pokazuje na sljedeću
instrukciju;
3.
Dekodoiraj instrukciju kako bi se ustanovilo
koja je;
4.
Ako je potrebno, dohvati 16 bitnu riječ iz
memorije;
5.
Ako je potrebno, uvećaj PC da pokazuje na
sljedeću instrukciju;
6.
Izračunaj adresu operanda ako je potrebno (u
slučaju xxxx+bx);
7.
Dohvati operand;
8.
Smjesti dohvaćenu vrijednost u odredišni registar.
Prvi korak koristi vrijednost PC'a da bi se
dohvatila instrukcija, tako da se ne može izvršiti preklapanje sa sljedećom
instrukcijom. Takođe, svi koraci koji slijede zavisni su od opkoda, pa se ovaj
korak ne može preklopiti sa ni jednim drugim korakom.
Drugi i treći korak ne koriste ni jednu
zajedničku funkcionalnu jedinicu, niti PC zavisi od dekodera. Zato, KU se može
malo modifikovati da izvrši inkrementiranje PC istovremeno dok se dekodira
instrukcija. Time se štedi jedan ciklus sistemskog sahata.
Treći i četvrti korak na izgled se ne mogu
preklapati: da bi se odlučilo da li je poteban korak četiri, prvo treba
dekodirati instrukciju. Međutim, kako je podatkovna sabirnica slobodna, CPJ se
može dizajnirati da učita novu riječ bez obzira da li ona treba ili ne. No,
postoji problem, sa koje adrese učitati instrukciju. Ako se PC ažurira zajedno
sa dekodiranjem, onda se tek u narednome ciklusu može izvršiti učitavanje
sljedće riječi. Kako su sljedeća tri koraka, 4, 5 i 6 opcionalni, to postoji
više varijanti koje se mogu pojaviti pri izvršenju instrukcije:
#1 (korak 4,
korak 5, korak 6 i korak 7) - mov ax,[1000+bx]
#2 (korak 4,
korak 5 i korak 7) - mov ax,[1000]
#3 (korak 6 i
korak 7) - mov ax,[bx]
#4 (korak 7) -
mov ax,bx
Korak 7 se uvijek nalazi na kraju i ne može
se dijeliti ni sa jednim prije njega. Korak 6 se može izvršiti odmah poslije
koraka 4. Korak 5 se ne može izvršavati zajedno sa korakom 4, jer korak 4
koristi vrijednost PC'a. Stoga se u prva dva slučaja može uštedeti po jedan
ciklus:
#1 (korak 4,
korak 5/6 i korak 7) - mov ax,[1000+bx]
#2 (korak 4,
korak 5/7) - mov ax,[1000]
#3 (korak 6 i
korak 7) - mov ax,[bx]
#4 (korak 7) -
mov ax,bx
Naravno, kako korak 8 smješta vrijednost,
to se on ne može kombinovati ni sa jednim. Time se štede dva koraka Na osnovu
ovoga, izvršenje instrukcije može teći na sljedeći način:
|
Novi korak
|
Operacije
|
Stari koraci
|
|
1.
|
Dohvati bajt
instrukcije iz memorije
|
1
|
|
2.
|
Dekodoiraj
instrukciju i ažuriraj PC registar
|
2/3
|
|
3.
|
Ako je potrebno,
dohvati 16 bitnu riječ iz memorije
|
4
|
|
4.
|
Izračunaj adresu
operanda, ako treba (xxxx+bx)
|
5
|
|
5.
|
Dohvati operand,
ako treba ažuriraj PC (xxxx)
|
6/7
|
|
6.
|
Smjesti dohvaćenu
vrijednost u odredišni registar
|
8
|
Na ovaj način, uz malu modifikaciju CPJ'a,
može se uštedeti jedan do dva ciklusa sistemskog sahata kod mov instrukcije.
Ovakvim načinom se mogu napraviti uštede i kod drugih instrukcija.
Drugi problem se javlja ako se operand
nalazi na neparnoj adresi. Neka se instrukcija mov ax,[1000]
nalazi na adresi 100. Opkod se učitava sa adrese 100, a za 16 bitni operand
trebaju dva ciklusa jer se nalazi na adresama 101 i 102. Kako je hpx6 16 bitni
procesor, to se u startu učita sadržaj dva bajta: sa adrese 100 opkod i sa 101
M.Z. bajt 16 bitne riječi. Ako se ovaj M.Z. bajt sačuva, onda je potreban
dodatni ciklus samo za V.Z. bajt sa adrese 102.
Da bi se ovo realizovalo potrebno je dodati registar veličine jednog bajta, u
kome se čuva rezultat 'viška' učitanog. Normalno da se isplati prilagoditi CPJ
ovome i uštedeti ciklus.
Zašto da se rezerviše samo jedan bajt?
Razmotrimo malo detaljnije izvršenje instrukcije. Kod čitanja opkoda uvijek se
učita jedan bajt više. To znači, da sa dva čitanja, opkoda i operanda, ustvari
učitaju se četiri bajta, a ne tri. Četvrti bajt je bajt opkoda sljedeće
instrukcije. Kako je taj bajt zapravo opkod naredne instrukcije, to se može
dodatno uštedeti: dok se izvršava tekuća instrukcija, može se dekodirati
naredna.
Može li se još nešto uraditi da se još malo
uštedi? Naravno da može. Svaka instrukcija nema operande u memoriji. Dok se
izvršava operacija u ALJ'u i rezultat smješta u registar, podatkovna sabirnica
je slobodna, pa se može pribaviti sljedeća instrukcija sa operandima i
pospremiti u spremnik koji je veći od jednog bajta.
Prihvatanje instrukcija iz spremnika za
pribavljanje predstavlja glavno unapređenje procesora hp26 u odnosu na hp16.
Kad god JUS (Jedinica za povezivanje sabirnica)), nije zauzeta i podatkovna
sabirnica je slobodna, on dohvata instrukcije iz memorije (opkodove i operande)
i smješta ih u spremnik za pribavljanje instrukcija. S drige strane, CPJ kada
god zatreba opkod ili operand, uzima ga iz spremnika za pribavljanje, ako nije
prazan.
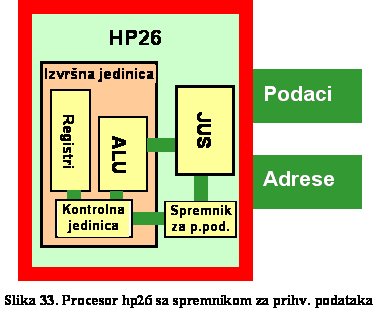 Ovakav pristup je efikasan sve dok se instrukcije
izvršavaju sekvencijalno. Međutim, problem se pojavljuje onog momenta kada se
pojave instrukcije prekida, odnosno skoka. Recimo, ako se u PC'u nalazi
vrijednost 400 i u spremniku 400, 401, 402 itd., a sljedeća instrukcija je jmp
1000. Sistem će se malo usporiti dok se dohvati sadržaj sa lokacije 1000, i
nastavlja se izvršavanje programa. Donekle se ova situacije može prevazići na
sljedeći način: dok se izvršava zadnja faza instrukcije (drugi operand),
započne se sa dekodiranjem naredne instrukcije, koja se nalazi u sljedećem
bajtu, kako bi se predvidjela sljedeća operacija. Naravno, ako ta sljedeća
operacija modifikuje PC, onda ovaj posao nije bio od koristi, ali se svakako
izvršavao paralelno.
Ovakav pristup je efikasan sve dok se instrukcije
izvršavaju sekvencijalno. Međutim, problem se pojavljuje onog momenta kada se
pojave instrukcije prekida, odnosno skoka. Recimo, ako se u PC'u nalazi
vrijednost 400 i u spremniku 400, 401, 402 itd., a sljedeća instrukcija je jmp
1000. Sistem će se malo usporiti dok se dohvati sadržaj sa lokacije 1000, i
nastavlja se izvršavanje programa. Donekle se ova situacije može prevazići na
sljedeći način: dok se izvršava zadnja faza instrukcije (drugi operand),
započne se sa dekodiranjem naredne instrukcije, koja se nalazi u sljedećem
bajtu, kako bi se predvidjela sljedeća operacija. Naravno, ako ta sljedeća
operacija modifikuje PC, onda ovaj posao nije bio od koristi, ali se svakako
izvršavao paralelno.
Ova unapređenja zahtjevaju male dodatke u
hardveru. Tako, blok diagram sa slike 27 će sada biti kao na slici 33.
Instrukcije će se izvršavati uz pretpostavku da se sljedeće stvari dešavaju u
pozadini:
·
Ako je JUS slobodna u tekućem ciklu i ako
spremnik za prihvatanje instrukcija (prefatch queue) nije pun (u zavisnosti od
konstrukcije to je obično između 8 i 32 bajta), dohvati sljedeću instrukciju sa
adrese koju pokazuje PC u momentu koji određuje sistemski sahat;
·
Ako je dekoder instrukcija slobodan i ako
instrukcija nema operanada, onda treba početi dekodiranje sljedećeg bajta iz
spremnika (ako ima podataka), inače (ako ima operande), onda treba početi
dekodiranje trećeg bajta iz spremnika. Ako nema podataka u spremniku, onda se
ništa i ne radi.
Ako se podaci naredne instrukcija već
nalaze u spremniku za pribavljanje, onda je instrukcija najčešće već
dekodorana. Koraci kod hp26 arhitekture će sada biti:
mov reg,reg/memorija/konstanta:
1. Ako je potrebno izračunaj sumu [xxxx+bx] (1 ciklus ako
je potrebno);
2. Dohvati izvorni operand. Nema ciklusa ako je konstanta (pretpostavlja
se da je već u spremniku za pribavljanje), jedan ciklus ako je registar, dva
ciklisa ako je adresa parana, tri ako je neparna;
3. Smjesti rezultat u odredišni registar - jedan ciklus.
mov
mem,reg:
1.
Ako je potrebno izračunaj sumu [xxxx+bx]
(1 ciklus ako je potrebno);
2. Dohvati izvorni operand, registar - jedan ciklus;
4. Smjesti rezultat u odredišni operand. Dva ciklisa ako je adresa
parana, tri ako je neparna.
instr reg,reg/memorija/konstanta (instr=add,sub,cmp,and,or)
1.
Ako je potrebno izračunaj sumu [xxxx+bx]
(1 ciklus ako je potrebno);
2. Dohvati izvorni operand. Nema ciklusa ako je konstanta
(pretpostavlja se da je već u spremniku za pribavljanje), jedan ciklus ako je
registar, dva ciklisa ako je adresa parana, tri ako je neparna;
3. Dohvati vrijednost odredišnjeg operanda, registar - jedan ciklus;
4. Izračunaj sumu, razliku … jedan ciklus;
5. Smjesti rezultat u odredišni registar - jedan ciklus.
not reg/memorija:
1. Ako je potrebno izračunaj sumu [xxxx+bx] (1 ciklus ako
je potrebno);
2. Dohvati izvorni operand. Nema ciklusa ako je konstanta
(pretpostavlja se da je već u spremniku za pribavljanje), jedan ciklus ako je
registar, dva ciklisa ako je adresa parana, tri ako je neparna;
3. Logičko negiranje operanda - jedan ciklus;
4. Smjesti rezultat. Jedan ciklus ako je registar, dva ciklisa ako je
adresa parana, tri ako je neparna;
jcc xxxx: (uslov cc=a,ae,b,be,e,ne)
1.
Testiraj flegove u statusnoj riječi za uslov,
jedan ciklus;
2. Ako je uslov za skok zadovoljen, CPJ kopira sadržaj 16'bitne adrese
u PC, jedan ciklus.
jmp xxxx:
3. CPJ kopira sadržaj 16'bitne adrese u PC, jedan ciklus.
Izgleda da se instrukcije skoka veoma brzo
izvršavaju, što zapravo nije baš tako. Instrukcije bezuslovnog skoka prebacuju
kontrolu na drugi dio koda koji se ne nalazi u spremniku za pribavljanje. Time
spremnik postaje nevalidan i mora se izvršiti novo pribavljanje instrukcija u
narednih nekoliko ciklusa. Da se zaključiti, da se kod može ubrzati, ako se
izbjegavaju nepotrebna (pogotovu bezuslovna) prekidanja programa.
4.6.3 Procesor hp46 - protočnost
Unapređenje hipotetičkog procesora hp26 se
odnosi na uvođenje spreminka za pribavljanje instrukcija. Na taj način se, broj
ciklusa jedne instrukcije može skratiti time, što se izvrši preklapanje između
dobavljanja instrukcija i dekodiranja sa izvršenjem. Postavlja se pitanje: može
li se jedna instrukcija izvršiti u jednome ciklusu? Može. Treba dodati još malo
hardvera kako bi se instrukcije izvršavale paralelno čime bi se povećala protočnost,
odnosno pipeline.
Razmotrimo korake potrebne za izvršenje
instrukcije (kod hp26):
1.
Dohvati operacioni kod;
2.
Dekodoiraj opkod i (paralelno) uzmi iz spremnika
mogući 16'bitni operand;
3.
Izračunaj kompleksni adresni mod (tj. [xxxx+bx])
ako je primjenjivo;
4.
Dohvati izvornu vrijednost iz memorije (ako je
memorijski operand) i vrijednost iz odredišnjeg registra (ako se traži);
5.
Izračunaj rezultat;
6.
Smjesti rezultat u odredišni registar.
Uz hardverske dodatke (i malo novčano
uvećanje), može se konstruisati mali 'mini-procesor' koji će prihvatiti svaki od navedenih koraka. Organizacija
je kao na slici 34. Za svaki korak se može dizajnirati poseban dio hardvera,
što predstavlja stepen u protočnosti kakva je prikazana na slici 34. Naravno,
ne može se jedna instrukcija istovremeno dohvatati i dekodirati. Zato je moguće
dohvatati jedan opkod, dokle se u drugome stepenu dekodira prethodna
instrukcija. Teoretski, ako se konstruiše mašina sa n-stepeni, u jednome
momentu može se izvršavati n instrukcija. Hipotetički protočni procesor hp46 je
šestostepeni, tako da u jednome momentu može izvršavati šest instrukcija. Kada
se pogledaju faze izvršenja instrukcije, da se zaključiti da njegova protočnost
efektivno 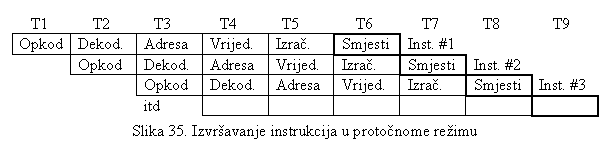
omogućava izvršenje jedne instrukcije u jednome ciklusu.
Izvršavanje instrukcija u protočnome
režimau (pipeline) je predstavljeno na slici 35. Vremenski intervali T1, T2,
T3… predstavljanju momente kada sistemski sahat diktira novi ciklus. Razmotrimo
punjenje protočne strukture i izvršenje tri prve instrukcije:
Za T=T1: CPJ dobavlja opkod bajt prve instrukcije.
Za T=T2: CPJ započinje dekodiranje opkoda prve instrukcije.
Paralelno dohvata 16'bitni operand prve instrukcije iz spremnika za
pribavljanje, u slučaju da operand postoji. Kako opkod prve instrukcije više ne
treba, to CPJ daje nalog da se počne sa dohvatanjem opkoda sljedeće instrukcije,
paralelno dok dekodira prvu instrukciju.
Za T=T3: Ako postoji operand (mod [xxxx+bx]) CPJ izračunava
njegovu adresu, inače ne radi ništa za prvu instrukciju. Za vrijeme ove faze,
CPJ takođe dekodira opkod druge instrukcije i dohvata operand ako postoji. I na
kraju, za treću instrukciju, CPJ dobavlja opkod.
Za T=T4… CPJ dobavlja novu instrukciju i za svaki naredni klok
nastavlja poslove na dovršavanju prethodnih instrukcija. Kako se poslije T5
završava prva instrukcija (arhitektura procesora hp46 ima šest protočnih
elemenata), to su na dalje svi elementi zaposleni. Zato razmotrimo još 6.
korak.
Za T=T6: CPJ kompletira izvršenje prve instrukcije (smješta
rezultat), izračunava vrijednost za drugu instrukciju … i dohvata opkod za
šestu instrukciju, čime je protočna struktura 'puna'.
Na ovaj način, dodavanje broja stepena
protočne strukture procesora koji odgovara broju faza izvršenja instrukcije,
obezbjeđuje se izvršenje instrukcije u jednome ciklusu sistemskog sahata.
4.6.4 Procesor hp66 -
superscalarni procesor
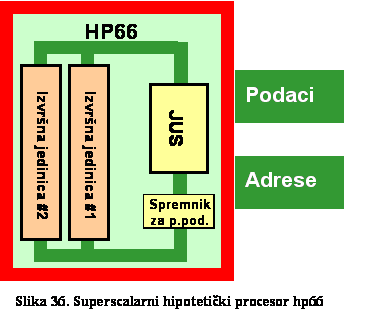 Analizom instrukcija, ustanovili smo da jedna
instrukcija nije jedna operacija. Dodavanjem spremnika za pribavljanje
instrukcija, te izvršavnjem dijelova instrukcije konkurentno, dobili smo hp26.
Onda smo dodali malo hardvera za svaki korak instrukcije i dobili hp46 koji
izvršava jednu instrukciju po ciklusu CPI (Clock Per Instruction). Je li ovo
maksimum. Na prvi pogled jeste, jer se postiglo da se izvrši instrukcija po
taktu sahata. Ako je instrukcija šest do osam operacija i ako se umjesto osam
elemenata u protočnu strukturu doda šesnaest, hoćemo li dobiti pola CPI?
Odgovor je potvrdan. Hipotetički procesor hp66 sa dodatkom hardvera za više
izvršnih jedinica, omogućava izvršavanje više od jedne instrukcije po ciklusu.
Naravno zadržan je i spremnik za pribavljanje instrukcija, koji je zajednički
za sve izvršne jedinice (slika 36).
Analizom instrukcija, ustanovili smo da jedna
instrukcija nije jedna operacija. Dodavanjem spremnika za pribavljanje
instrukcija, te izvršavnjem dijelova instrukcije konkurentno, dobili smo hp26.
Onda smo dodali malo hardvera za svaki korak instrukcije i dobili hp46 koji
izvršava jednu instrukciju po ciklusu CPI (Clock Per Instruction). Je li ovo
maksimum. Na prvi pogled jeste, jer se postiglo da se izvrši instrukcija po
taktu sahata. Ako je instrukcija šest do osam operacija i ako se umjesto osam
elemenata u protočnu strukturu doda šesnaest, hoćemo li dobiti pola CPI?
Odgovor je potvrdan. Hipotetički procesor hp66 sa dodatkom hardvera za više
izvršnih jedinica, omogućava izvršavanje više od jedne instrukcije po ciklusu.
Naravno zadržan je i spremnik za pribavljanje instrukcija, koji je zajednički
za sve izvršne jedinice (slika 36).
Arhitektura hp66 ima višestruke izvršne
jedinice u procesori sa šest stepeni protočnosti. To znači da će se instrukcije
tipa:
mov ax,1000
mov bx,2000
izvršit za jedan
ciklus (obiije instrukcije), jer imaju po šest koraka. Generalno, komplikovane
instrukcije se ne izvršavaju u jednome ciklusu. Zato je potrebno još jednom
naglasiti da je kod pisanje asemblerskog koda, veoma bitno koristiti kratke
instrukcije sa jednostvnim načinima adresiranja. Mnoge arhitekture nemaju
višestruke kompletne izvršne jedinice, već njihove dijelove. Tako se susreću
arhitekture sa višestrukim ALJ'ima ili FPU'ima (Floating Point Unit).
4.7 Pitanja i zadaci
1.
U kojem logičkome sklopu procesora se nalaze PC i
PSW?
2.
Ako se skup svih komandi procesora zove
instrukcijskiskup, čime je definisana njegova veličina?
3.
Pokazati kako se instrukcija jmp može
realizovati instrukcijom mov. Koje su instrukcije potrebne za emuliranje
uslovnog skoka?
4.
Hpx6 sa tri bita kodira 20 instrukcija, jer je CISC
arhitektura. Koliko bi se instrukcija kodiralo da je RISC i koliko je potrebno
bita za 20 RISC instrukcija?
5.
Analizirajte uslovno grananje u fazi asembliranja i
fazi izvršenja. Šta je karakteristično?
6.
Zašto je kod dohvatanja operanda nekada potreban
jedan ciklus a nekada dva i kada?
7.
Postoji problem kod pipeline arhitektura, tzv
hazard pipeline, kao u sljedećem primjeru:
mov bx,[1000]
mov ax,bx
kada se ove dvije instrukcije izvršavaju u pipeline'u, jasno je da će u bx
kod izvršenja druge instrukcije biti nešto drugo, an 1000. Kako prevazići
problem?
8.
Kodirajte dati kôd u asembleru u mašinski kôd:
halt
5 Memorija - organizacija i pristup
Ovo poglavlje je posvećeno razjašnjenju
programerovog pogleda na memoriju. Kao u prethodnim poglavljima, i u ovome se
smjenjuju softverski i hardverski model za razmatranje problematike koja je u
žiži. Da bi se naglasile pojedinosti programerovog viđenje memorijske
organizacije, koristi se model realnog računarskog sistema baziranog na
procesoru 8088.
Poglavlje počinje sa organizacijom memorije i registrima procesora 8088. U
sljedećem dijelu je posvećena pažnja segmentiranju memorije odnosnu virtuelnoj
memoriji. Na kraju su date tehnike pristupa podacima u memoriji koje su poznate
kao načini adresiranja memorije.
5.1 Programerov pogled na CPJ
U prethodnome poglavlju, preko modela
hipotetičkog procesora, dati su detalji pojedinih dijelova procesora. Sa
stanovišta asemblerskog programera, procesor se vidi preko modela skupa
registara. Generalno, kod svih procesora, registri se hardverski realizuju kao
čip na procesoru. Što se tiče programera, za njega registri predstavljaju memorijske
lokacije. Za razliku od glavne memorije, kojoj se pristupa preko adresa
pojedinih lokacija, registrima se pristupa na osnovu njihovoih imena. Kako
svaki registar ima svoje ime, ili bolje rečeno nadimak, to oni imaju i
različite namjene.
Za model hpx6 su uvedene određene
apstrakcije kako bi se naglasile neke specifičnosti. U ovome poglavlju težište
je na korištenju registra za pristup podacima. Kako treba dati realnu sliku
programerovog pogleda na memoriju, to je neophodno prikazati kompletan skup registara
arhitekture 8088. Programer vidi tri grupe registara: registri opšte namjene,
registri za pristup virtuelnoj memoriji i sprecijalne registre.
5.1.1 Registri opšte namjene
U Intelovoj arhitekturi je definisano osam
registara opšte namjene. Pored opšte namjene, svaki od njih ima i specijalnu
namjenu. Pod pojmom opšta namjena podrazumijeva se da se u svkome od njih mogu
vršiti aritmetičko-logičke operacije. U zavisnosti od specijalne namjene
registri su i dobili svoja imena:
Akumulator: (Accumulator register)
nadimak ovog registra je AX i u njemu se dešava većina
aritmetičko-logočkih operacija. Iako se mnoge operacije mogu izvršiti u nekome
drugome registru, treba forsirati ax, jer ako ništa drugo, ono su barem
za jedan ciklus sistemskog sahata u njemu neke operacije brže. Kako je njegova
funkcija akumulatoraska, to jednoadresne instrukcije njga koristi kao difoltni
registar.
Bazni: (Base register) predstavlja
registar u kome se drži bazni dio adrese kod indeksnih adresiranja. Nadimak mu
je BX.
Brojač: (Count register) kao što se
vidi iz imena, osnavna namjena mu je da se njemu drže brojači, kao što je broj
ponavljanja u petlji ili elemenata nekog niza. Pogodan je i kao pomoćni
registar za aritmetičke operacije. Njegov nadimak je CX.
Podatkovni: (Data register) čiji je
nadimak DX ima dvostruku namjenu: da drži drugi dio rezultata kod
računanja sa brojevima koji ne mogu da stanu u jednoj riječ; i da drži baznu
adresu kada se pristupa U/I sabirnici.
Indeksni registri: su SI
(Source index) i DI (Destination index). Njihova namjena je da drže,
indekse odnosno poentere kada se pristupa strukturama podataka. Tako, si
sadrži poenter na strukturu elementa koji se obrađuje (izvorni), a di pokazuje
na elemente obrađene strukture, gdje se smještaju rezultati.
Pokazivački registri: su
BP (Base poenter) i SP (Stack poenter). BP ima sličnu funkciju BX
registru i generalno služi za pristup strukturama podataka unutar procedure.
Stek poenter ima sasvim specijalnu namjenu, i često se efikasnost programa
bazira na njegovom dobrom korištenju. Preko njega se upravlja sa programskim
stekom na kojem se pohranjuju međurezultati.
Pored ovih registara, opšti registri ax.bx.cx
i dx imaju i svoje podregistre. Veličina podregistara je 8 bita, i
osim ove razlike, po svim drugim karakteristikama se ponašaju kao i registri.
Međutim, hardverski oni su dijelovi navedenih registara. Tako se registar ax
sastoji od dva podregistra: al i ah. Zapravo, al sadrži
M.Z bajt registar ax (accumulator low byte), a ah V.Z. bajt
(accumulator high byte). Promjenom sadržaja al, mijenja se i sadržaj
donje polovine ax registra. Takođe registri bx, cx i dx
imaju odgovarajuće podregistre: bh, bl, ch, cl, dh i dl, kao je
prikazano i na slici 37. Indeksni i pokazivački registri nemaju svoje
podregistre i oni su uvijek 16'bitni.
5.1.2 Virtuelna memorija
Već je rečeno da je bajt najmanja
adresibilna jedinica i da je moguće adresirati 2n bajta
memorije, gdje n predstavlja veličinu adresne sabirnice. Ovaj broj je
diktiran veličinom riječi računarske arhitekture. Kako razmatramo arhitekturu
16'to bitnog procesora, to je znači moguće adrsirati do 216, odnosno
65.536 bajta. Zar ovo nije prejako ograničenje?
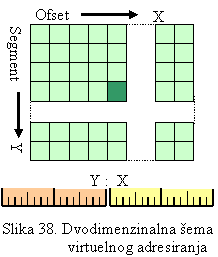 Rješenje ovog problema se nalazi u virtuelnoj
memoriji. Dakle, memorije može biti puno više nego što je 64 kB. Zapravo
memorija je izdijeljena na 64 kB segmente. Fizički je moguće pristupiti
direktno prvom segmentu, čija je adresa od 0 do 64 kB. Preostali segmenti
predstavljaju virtuelnu memoriju. Virtuelna memorija predstavlja moćan koncept
upravljanja memorijom, bez obzira na veličinu adresnih registara. U čemu se
sastoji koncept virtuelne memorije?
Rješenje ovog problema se nalazi u virtuelnoj
memoriji. Dakle, memorije može biti puno više nego što je 64 kB. Zapravo
memorija je izdijeljena na 64 kB segmente. Fizički je moguće pristupiti
direktno prvom segmentu, čija je adresa od 0 do 64 kB. Preostali segmenti
predstavljaju virtuelnu memoriju. Virtuelna memorija predstavlja moćan koncept
upravljanja memorijom, bez obzira na veličinu adresnih registara. U čemu se
sastoji koncept virtuelne memorije?
Posmatrajmo memoriju kao linerni niz bajta,
kako je već ranije rečeno. Sa jednom adresom možemo pristupi bajtu u tome nizu
(ako ne prelazi granicu od 64k). No, ako posmatramo memoriju dvodimenzijalno:
prva dimenzija su linearni segmenti ne veći od 64k; a druga je niz tih
segmenata. U ovome slučaju se može pristupiti virtuelnim lokacijama koje
prevazilaze granicu od 64k sa dvije komponente, koje specificiraju adrsu: vrijednost
segmenta (redni broj niza od 64k memorije); i ofsetom unutar segmenta. Zapravo,
segmentna vrijednost i ofset su dva nezavisna broja i mogu se nalaziti u
različitim registrima, pa je i adresiranje dvodimenzionalno. Dakle, kod
virtuelnog adresiranja, ofset adrese u nizu se nalazi u registru X, a adresa
segmenta se nalazi u specijalnom registru za segmentiranje Y (slika 38).
No, bez obzira na segmentiranje, memorija
fizički predstavlja niz uzastopnih lokacija. Virtuelne adrese, koje su
predstavljene parom segmenta i ofseta su logičke adrese. Stvarna
lokacija memorijske ćelije je predstavljena jednim brojem i predstavlja fizičku
adresu. U prvim verzijama virtuelnih arhitektura, kod PDP'a, adresni
prostor je proširen sa 16 na 18 bita. Time je bilo moguće adresirati do 256 kb.
Intel je u arhitekturi 8088 koristio 4 bita segmentnog registra, kako bi adresa
bila 20'to bitna. Time je omogućeno pristupanje adresnome prostoru do 1 Mb.
Dakle, segmentni registar je mogao da ukazuje na 16 nizova od po 64kb. Funkcija
preslikavanja logičke adrese u fizučku u ovome slučaju je veoma jednostavna.
CPJ množi vrijednost iz segmentnog registra sa 10h, čime proširuje
veličinu adresnog prostora sa 16 na 20 bita. Tako dobijenoj vrijednosti se
dodaje ofset, i to predstavlja fizičku adresu, kao što se vidi na slici 39.
5.1.3 Segmentni registri
Arhitektura procesora 8088 za adresiranje
koristi četiri segmentna registra: cs (Code Segment), ds (Data
Segment), es (Extra Segment), i ss (Stack Segment). Svi segmentni
registri su po 16 bita i odnose se na odgovarajuće blokove glavne memorije.
Segmentni registri pokazuju na početak segmenta u memoriji.
Kako je već rečeno, ograničenja segmenta su
na blokove od 64k memrije.
Kode segmnet: ukazuje na memoriju u
kojoj se izvršava tekući program (kôd). Pored ograničenja segmenta memorije na
64k, program može biti duži. Potrebno je samo promijeniti sadržaj cs,
kako bi se pristupilo drugome segmentu u memoriji.
Podatkovni segment: registar ds
ukazuje na globalne varijable u programu. Kao i kod kôdnog segmenta i data
segment može pokazivati na više od jednog segmenta. Kako se program sastoji od
instrukcija i podataka, to je samom podjelom programa na komponente moguće
imati program veći od 64k.
Ekstra segment: es, kao i što se
vidi iz imena, koristi se za pristup podacima, kada je teško pristupiti nekom
drugim registrom. Najčešće se koristi u paru sa ds registrom kako bi se
prebacio blok podataka između dva dijela memorije koji se logički nalaze u
različitim segmentima memorije.
Stek egment: ukazuje na segment
koji sadrži 8088 stek. Na steku se drže podaci o mašini, procedurama,
inrteraptima i lokalnim varijablama. Generalno, SS segment se ne smije
modifikovoti, jer mnoge stvari ovise o njemu.
Teoretski je moguće u segmentnim registrima
držati i podatke, no ovo treba obavezno izbjegavati.
5.1.4 Specijalni registri
Postoje dva registra sa specijalnom namjenom: PC (Program
Counter ili IP - Instruction Pointer) i PSW (Processor Status Word). Njima se
ne može pristupiti kao ostalim registrima direktno i CPJ ih koristi na
specijalni način.
Programski brojač: za programera,
PC je implicitna varijabla, koja sadrži labelu instrukcije koja je
sljedeća za izvršenje. Procesor ga inkrementira poslije svake učitane riječi,
kako bi bio ažuran. PC je 16'to bitni registar, što znači da mu je adresni
domet do 64k. Zato se koristi u paru sa CS registrom kako bi omogućio pristup
bilo kojoj lokaciji u fizičkoj memoriji.
Processorka statusna riječ: često se
zove i registar zastavica, odnosno flegova. On se u potpunosti razlikuje od
ostalih registara. PSW zapravo predstavlja kolekciju signala kojima su
definisani različiti statusi u procesoru za vrijeme rada. Ne koriste se svi
biti, pa je moguće buduće proširenje. Najčešće su korištene zastavice: nule,
predznaka, prekoračenja i prijenosa. U njemu se nalaze statusi nekih signala
kontrolne sabirnice.
5.2 Programerov pogled na memoriju
Programer želi jednostavan i efikasan
pristup memoriji, odnnosno varijablima koje su smještene u memoriji. Kako je
već rečeno, kod procesora hpx6, pristup varijablama u memoriji realizuje se
preko različitih načina adresiranja, što predstavlja programerov pogled na
memoriju. Pet osnovnih načina adresiranja, koji se susreću kod procesora hpx6,
predstavljaju osnov programerovog pogleda na memoriju i kod ostalih
arhitektura. Normalno, naprednije arhitekture imaju bogatiji skup registara, a
time i bogatiji skup načina adrsiranja. Bez obzira koliko koja arhitektura ima
bogat skup registara, svi načini se baziraju na kombinaciji adresiranja koja se
susreću kod hpx6 procesora: registarsko, neposredno, direktno, indirektno i
indeksno. Kako je primarni cilj ovog materijali shvatiti vezu između
programiranja i hardvera na kome se taj program izvršava, to ćemo sada
razmotriti načine adresiranja kod bazne Intelove arhitekture 8088.
Odmah ćemo napomenuti ključnu razliku u
načinu adresiranja kod procesora hpx6 i 8088: arhitektura 8088 pored 16'bitnih
registara ima i 8'bitne - što znači da se susreću instrukcije koje rade sa 16 i
sa 8 bita; druga bitna razlika je u postojanju specijalnih indeksnih
(pokazivačkih) registara - SI i DI, čime je skup instrukcija značajno obogaćen.
Osnovna instrukcija kod procesora 8088 je 16'bitna, a ne 8'bitna kao kod hpx6.
5.2.1 Registarsko adresiranje
Sve što važi za registarsko adresiranje
hipotetičkog procesora hpx6, važi i za Intelovu arhitekturu, dok obratno ne
važi. Opšti oblik naredbe za registarsko adresiranje je opkod regodr,regizv,
gdje su i izvorni i odredišnji operandi registri. Ograničenje je da registri po
veličini moraju biti isti: 8'bitini registri sa 8'bitnim; 16'bitni sa
16'bitnim. Tako mov naredba (kod registara se gubi varijanta load i store) za
registarsko adresiranje će biti:
mov ax,bx ;
Kopiraj vrijednost iz BX u AX
mov dl,al ;
Kopiraj vrijednost iz AL (M.Z. dijela AX), u DL (M.Z. dio DX)
mov sp,bp ;
Kopiraj vrijednost iz BP u SP
mov dh,cl ;
Kopiraj vrijednost iz CL (M.Z. dijela CX), u DH (V.Z. dio DX)
Postoje dva ograničenja kod registarskog
adresiranja:
· CS registar ne može biti odredišnji operand;
· Segmentni registri se mogu pojaviti samo kao jedan operand. Ne mogu
se prebaciti podaci direktno iz jednog segmentnog registra u drugi. Za tu svrhu
se koristi akumulator kao međukorak:
mov ax,cs ; Kopiraj segmentnu adresu iz kôd
segmenta u akumulator
mov ds,ax ; i prebaci je u data segment
Nikada se ne treba koristiti segmentni
registar za proizvoljne podatke; u njima se uvijek trebaju držati adrese
segmenata.
5.2.2 Memorijski načini adresiranja
Koncept hipotetičkog procesoraje uveden da
bi se naglasile osnovne karakteristike računarske arhitekture. Srž problematike
ovog materijala su načini adresiranja, odnosno programerov pogled na podatke u
memoriji. Zato se u ovome poglavlju na 'realnoj' arhitekturi procesora 8088,
pnavljaju razmatranja načina adrsiranja, kako bi se sagledale neke nijanse.
Arhitektura 8088 podržava 17 načina
memorijskog adresiranja. Na prvi pogled, to izgleda previše, ali nije baš tako.
I treba ih savladiti, da bi se razumjela problematiaka manipulisanja podacima u
memoriji. Ovih 17 načina adrsiranja, bazira se na pet osnovnih memorijskih
načina adresiranja: samo sa pomakom, bazni, sa pomakom plus bazni, bazni plus
indexni i sa pomakom plus bazni plus indeksni. Zapravo i ovih pet se baziraju na
tri memorijska načina definisana kod hpx6 arhitekture: bazni, indeksni u
kombinaciji sa pomakom ([xxxx], [bx], [bx+xxxx]).
5.2.2.1 Adresiranje memorije samo sa pomakom
 Adresiranje memorije sa pomakom
(displacement-only), ili kako se često još zove direktno adresiranje, je način
koji je najčešće u uptrebi. U ovome modu operand se direktno adresira, tako što
se u 16'bitnoj riječi (konstanti) navede direktno adresa ciljanog operanda.
Instrukcija mov al,ds:[8088], smješta bajt sa lokacije 8088 u
registar al, dok instrukcija mov ds:[1234],dx smješta
16'bitnu riječ iz registra dx na adresi 1234. (slika 41).
Adresiranje memorije sa pomakom
(displacement-only), ili kako se često još zove direktno adresiranje, je način
koji je najčešće u uptrebi. U ovome modu operand se direktno adresira, tako što
se u 16'bitnoj riječi (konstanti) navede direktno adresa ciljanog operanda.
Instrukcija mov al,ds:[8088], smješta bajt sa lokacije 8088 u
registar al, dok instrukcija mov ds:[1234],dx smješta
16'bitnu riječ iz registra dx na adresi 1234. (slika 41).
Ovaj način je veoma sličan direktnom
adresiranju kod procesora hpx6. Vrijednost pomaka slijedi samu instrukciju. Mod
se zove sa pomakom zato što vrijednost predstavlja pomak u odnosu na adresu od
početne adrese koja sadrži odgovarajući segmentni registar. Ako se želi fizička
adresa lokacije iz memorije, onda se mora prvo izračunati vrijednost adrese
koja će se staviti u segmentni registar, a onda slijedi pomak u odnosu na baznu
vrijednost segmentnog registra. U navedenome primjeru se ne mora koristiti
oznaka za ds segment, jer se ona podrazumijeva (difooltna je kada se
radi o podacima).
5.2.2.2 Registarski indirektni način
adresiranja
Memorijskim lokacijama je moguće pristupiti
indirektno preko registara. Dok hpx6 koristi samo jedan način indirektnog
adresiranja (preko registra bx), ovde se mogu iskoristiti četiri registra: si,
di, bp i bx. Kao što se vidi u sljedećem primjeru, zato i postoje
četiri načina indirektnog adresiranja:
mov al,[bx]
mov al,[bp]
mov al,[si]
mov al,[di]
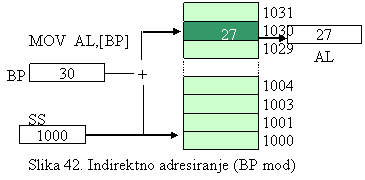 Kod ovog načina adresiranja pomak (offset) se
nalazi u nekome od registara za indirektno adresiranje. Odredišnji registar
definiše da li se operacija izvršava nad bajtima ili riječima. Ako drugojačije
nije rečeno segmentni registar je uvijek ds za registre bx, si i di.
Za registar bp je difoltni registar ss (kao i za sp). Ako
se želi pristupiti podacima na koje pokazuje drugi segmentni registar, onda se
to mora eksplicitno i naglasiti:
Kod ovog načina adresiranja pomak (offset) se
nalazi u nekome od registara za indirektno adresiranje. Odredišnji registar
definiše da li se operacija izvršava nad bajtima ili riječima. Ako drugojačije
nije rečeno segmentni registar je uvijek ds za registre bx, si i di.
Za registar bp je difoltni registar ss (kao i za sp). Ako
se želi pristupiti podacima na koje pokazuje drugi segmentni registar, onda se
to mora eksplicitno i naglasiti:
mov ax,cs:[bx]
mov ax,ds:[bp]
mov ax,es:[si]
mov ax,ss:[di]
Kada se pristupa preko bx i bp
registara, onda se to naziva bazni adresni način, a sami registri bazni
registri. Pristup preko si i di registara se naziva indeksni
način adresiranja, a sami registri su indeksni registri. Kako se
tehnički radi o potpuno istome načinu adresiranja, to se radi koegzistentnosti
ovaj mod zove indirektno adresiranje.
5.2.2.3 Indeksni način adresiranja
 Dodavanjem pomaka sadržaju baznog ili indeksnog
registra dobija se indeksno adresiranje. Sintaksa indeksnog adresiranja je
sljedeća:
Dodavanjem pomaka sadržaju baznog ili indeksnog
registra dobija se indeksno adresiranje. Sintaksa indeksnog adresiranja je
sljedeća:
mov al,pom[bx]
mov al,pom[bp]
mov al,pom[si]
mov al,pom[di]
 Ako bi bx sadržavao vrijednost 1000, onda bi
instrukcija mov cl,20[bx] smjestila u cl sadržaj
sa memorijske lokacije ds:[1020]. Slično, ako bi bp sadržavao
vrijednost 2020, instrukcija mov dx,1000[bp] smjestila bi
u dx sadržaj sa memorijske lokacije ds:[3020].
Ako bi bx sadržavao vrijednost 1000, onda bi
instrukcija mov cl,20[bx] smjestila u cl sadržaj
sa memorijske lokacije ds:[1020]. Slično, ako bi bp sadržavao
vrijednost 2020, instrukcija mov dx,1000[bp] smjestila bi
u dx sadržaj sa memorijske lokacije ds:[3020].
Adresa operanda u memoriji dobija se kao
suma pomaka i specificiranog registra. Modovi koji za indeksno adresiranje
koriste registre bx, si i di, adresu segmenta drže difoltno u ds
registru (slika 43), dok registar bp koristi ss registar
(slika 43). Ako se želi koristiti neki drugi segmentni registar, onda se to mora
eksplicitno specificirati. Takođe, parametar za pomak se može potpisivati
unutar uglastih zagrada, zajedno sa registrom:
mov al,
ss:[bx+pom]
mov al,
es:[si+pom]
U literaturi se ne nalazi neka bitna
razlika između Intelovog indirektnog i indeksnog načina adresiranja. Što se
tiče hardvera, tu je bitna razlika, jer je za indeksni način neophodno
sabiranje pomaka i registra, da bi se dobio ofset.
5.2.2.4 Bazni indeksni način adresiranja
Bazni indeksni način adresiranja
predstavlja kombinaciju registarskog indeksnog adresiranja. Ofset se dobija
tako što se sabiraju sadržaji baznih (bx i bp) i indeksnih (si
i di) registara. Dozvoljene forme baznog indeksnog adresiranja su:
mov al,[bx]
[si]
mov al,[bx]
[di]
mov al,[bp]
[si]
mov al,[bp]
[di]
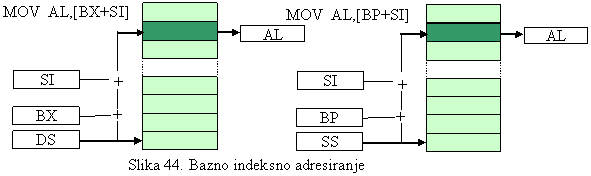
Ako bi registar bx sadržavao vrijednost 1000, a
registar si 800, onda bi instrukcija mov al,[bx][si]
smjestila u al sadržaj sa lokacije ds:[1800]. Kao i kod
prethodnih načina adresiranja, načini koji ne sadrže u sebi registar bp
koriste ds za segmentni ragistar. Mogući je i način potpisivanja oba
registra u zagradi sa znakom '+' između, tj: mov ax,[bp+si].
Na slici 44 su grafički prikazani bazni indeksni načini adresiranja.
5.2.2.5 Bazno
indeksni način adresiranja sa pomakom
Ovaj mod predstavlja moduifikaciju prethodnog,
bazno indeksnog, u tome što se zbiru sadržaja registara dodaje još i pomak u
obliku konstante. Tako će forme bazno indeksnog
adresiranja sa pomakom biti:
mov al,pom[bx]
[si]
mov al,pom[bx]
[di]
mov al,pom[bp]
[si]
mov al,pom[bp]
[di]
I kod ovog načina su moguće različite
kombincije potpisivanja: sva tri dijela adrese u zagradama ( [bx+di+pom]
) ili svaka zasebno ( pom[bp] [di]. Ista pravila važe i za
segmentne registre: ako se koristi bp registar, onda se za segmentnu
adresu koristi ss, inače se segmentna adresa nalazi u ds. U
slučaju potrebe korištenja nekog drugog 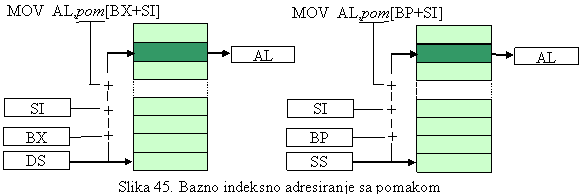
segmentnog registra, onda se to mora i eksplicitno reći.
5.2.3 Šema za jednostavno pamćenje načina
adresiranja
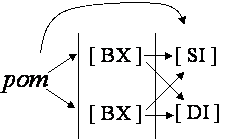

 Na početku ovog poglavlja je rečeno da je poželjno zapamtiti sve načine
adresiranja. Ova arhitektura podržava 17 načina adresiranja: pom, [bp],
[bx], [si], [di], pom[bp], pom[bx],
pom[si], pom[di], [bp][si], [bp][di],
[bx][si], [bx][di], pom[bp][si],
pom[bp][di], pom[bx][si], pom[bx][di].
Važno ih je zapamtiti ne samo da bi se znalo koje su forme ispravne, već i koje
su neispravne.
Na početku ovog poglavlja je rečeno da je poželjno zapamtiti sve načine
adresiranja. Ova arhitektura podržava 17 načina adresiranja: pom, [bp],
[bx], [si], [di], pom[bp], pom[bx],
pom[si], pom[di], [bp][si], [bp][di],
[bx][si], [bx][di], pom[bp][si],
pom[bp][di], pom[bx][si], pom[bx][di].
Važno ih je zapamtiti ne samo da bi se znalo koje su forme ispravne, već i koje
su neispravne.
Postoji jednostavan način pamćenja ako se
koristi šema sa slike 46. Dakle, uzima se iz prve kolone jedini parametar ili
ni jedan i onda se kombinuje sa jednim ili ni jdnim parametrom iz preostale
dvije kolene. To znači, iz neke kolone se može izostaviti parametar, ali se ne
mogu uzeti dva. Tako se mogu imati recimo sljedeći slučajevi:
· Uzme se parametar iz prve kolone (pom), ne uzme iz druge i uzme drugi iz treće ([di]), tako se dobije
pom[di];
· Uzeti iz prve (jedini), prvi iz druge i treće, dobija se pom[bp][si];
· Preskočiti kolonu 1 i 2, uzeti drugi iz treće: [di];
· Preskoči kolonu 1, uzmi drugi iz 2., prvi iz 3.: [bx][si].
S toga, ako se pojavi način adresiranja
koji ne zadovoljava navedena pravila, on je nevažeći. Tako je pom[dx][si] nevažćeći, jer se dx
nigdje ne pojavljuje u navedenoj šemi.
Krajnji rezultat načina adresiranja je
ofset kojim se dobija efektivna adresa. Tako, ako registar bx sadrži
vrijednost 10, onda 10[bx] daje efektivnu adresu 20. Efektivna adresa je
ključna za dobijanje pozicije varijable u memoriji, tako da postoji specijalna
naredba LEA (Load Effective Address).
Adresni modovi se različito kreiraju. Zato za
različite modove treba i različito vrijeme da bi se dobila efektivna adresa.
Što je kompleksniji način adresiranja, to je i teže dobiti efektivnu adresu.
5.3 Pitanja i zadaci
Ako je poznato je difoltno segmentna adresa u ds'u
za si, di i bx, a u u ss'u za bp i sp, da li
je moguće da se zamijeni segmentni registar za pokazi
Oznake registara r[i] sreće se kod
arhitektura pod različitim simboličkim imenama: ri (R1, R2, R3, … ); $i
($1, $2 …), ili jednostavno slovne oznake A, B, C itd.