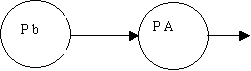
pop
pop
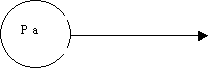
pop
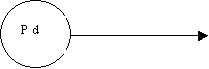
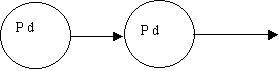
(4 transitions):
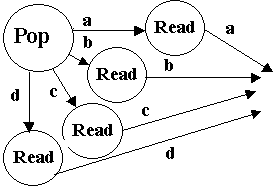
pop
(the rest):
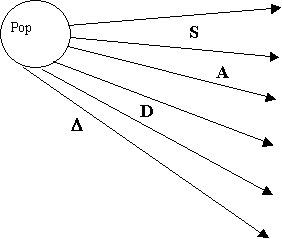
S ® Ab
S ® cD
A ® a
D ® d
D ® dd
end
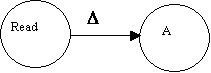
Theorem:
Part 1: Every context-free language is accepted by a PDA.
Part 2: The language accepted by any PDA is a context-free language.
This theorem says that PDA and CFG are equivalent notions: merely two different ways of defining the same kind of object. Both parts are proved by construction.
We will demonstrate the construction for Part 1. We will accept Part 2 (20 laborious pp. in the book) without proof to save time (and also there is a better way to do it: <2 pp. in Hopcroft and Ullman).
Consider the context-free grammar:
| directions | stacks |
| Any sentence has to be derived from S, the sentence
symbol
Place S on a stack, representing "derivation so far" |
1: S |
| Look at the stack(s), and find the first non-terminal, in this case S. (if there is none, we have a sentence and are done with that stack!). The only things that can be derived (in one step) from an S are Ab and Cd. Two ways to go, so we will make two identical copies of Stack 1 (call them Stack 1 and Stack 2) | 1: S
2: S |
| Replace S on Stack 1 by the first RHS Ab, from which we now must derive a sentence. Replace S on Stack 2 by the second RHS, cD. We now have two possible sentential forms on our stacks. | 1: Ab
2: cD |
| Continue the process with Stack 1, using the production A ® a for A, and Stack 2, using D ® d and D ® dd (which will cause Stack 2 to split) | 1: ab
2: cd 3: cdd |
| Since all stacks now have only terminals, we are done and have found all sentences of the language | |
You can see how this process would work for an arbitrary CFG, but note:
| directions | input | stacks |
| cdd has to be derived from S, the sentence symbol. Place S on a stack, representing "a nonterminal that must derive some leading portion of the string to the left (in this case, the whole string). | cdd | 1: S |
| We see a non-terminal at the top of Stack 1. That non-terminal must derive at least some initial portion of our target, by way of S ® Ab or S ® Cd. So Ab or Cd must derive at least some initial portion of our target. We need two stacks (and associated inputs) to keep track of both possibilities. | cdd
cdd |
1: Ab
2: cD |
| Stack 1: has a nonterminal at the top. Expand,
using A ® a.
Stack 2: has the terminal "c" at the top, and "c" is also the next symbol in the associated input. We "have a partial match", and can remove the c from the input and the stack, and continue with the rest of the match. |
cdd
dd |
1: ab
2: D |
| Stack 1: has a terminal at the top, but it doesnt
match the c. We have to abandon this stack as leading nowhere.
Stack 2: use D ® d and D ® dd (create Stack 3) |
dd
dd |
2: d
3: dd |
| Terminals are at top! And they match! Read and pop matching terminals. | d
d |
2:
3: d |
| Stack 2: empty, but there is more input. Abandon
ship!
Stack 3: a match! |
3: | |
| For stack 3, the input is used up, and the stack
is empty.
We have uncovered the (one-and-only) derivation: |
||
Note that if there were more than one derivation, we could have found more by keeping (input, stack) pairs alive as long as possible.
Using the idea just developed, lets make a PDA that recognizes sentences
from our grammar.
We will build it piecemeal, as "labeled parts", then integrate the
parts into a final machine:
| label | part | branch to label |
| S ® Ab: | |
pop |
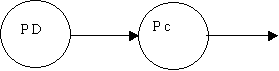
| S ® cD: | |
pop |
| A ® a: | |
pop |
| D ® d: | |
pop |
| D ® dd: | |
pop |
| pop part 1
(4 transitions): |
|
pop |
| Pop part 2
(the rest): |
|
S ® Ab S ® cD A ® a
D ® d D ® dd end |
| end: |
|
Heres the integrated PDA (dashed line not official!):
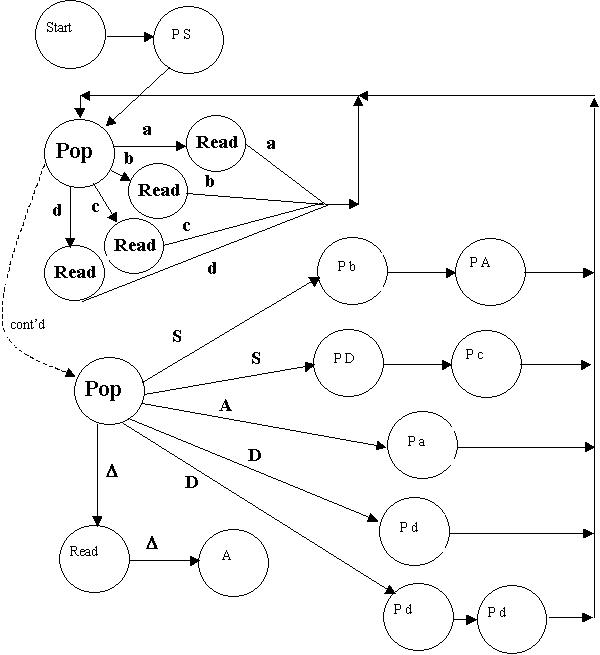
Notes: