M ® aF | bS
F ® bb | bF | l
Topics
Regular grammars
l-production
removal
Unit production removal
Chomsky normal form
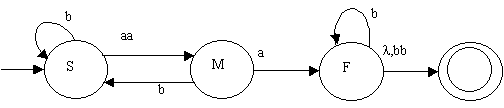
Think about the following grammar and transition graph:
| S ® aaM | bS
M ® aF | bS F ® bb | bF | l |
|
| corresponding to the grammar derivation:
S Þ bS Þ baaM Þ baaaF Þ baaabb of the string baaabb |
is the TG sequence of state-transitions:
S, b-S, aa-M, a-F, bbb-final accepting the string baaabb |
Notice:
Because such a CGF generates a regular language, it is called a regular grammar.
With a little study, you can see from the illustration:
(1) given a regular grammar, how to build a TG from it
(2) given a TG, how to build a regular grammar for it
We now have five equivalent representations for regular languages:
| regular expressions | finite automata | non-deterministic FA | transition diagrams | regular grammars |
Algorithm for removing l-productions
We will use the following grammar as an example:
Part 1: find all nullable nonterminalsS à BCD
B à C | l
C à aD | bD
D à BE
E à l
| step: | for our grammar: |
| 1. Let NN = {} | NN = {} |
| 2. if X à l is a production, add X to NN | NN = {B, E} |
| 3. If Y à A1A2
An is a production, and A1,A2,
An
are all in NN,
then add Y to NN |
NN = {B, E, D} |
| 4. Repeat 3 for all productions until nothing new can be added to NN | NN = {B, E, D} |
|
|
|
Part 2: eliminate l -productions from the grammar
1. Remove all l -productions
2. Examine each remaining production, focusing on the nullable nonterminals
on the RHS.
| production | nullable
nonterminals |
omit
subset |
add
production |
| S à BCD | B, D | B | S à CD |
| D | S à BC | ||
| B, D | S à C | ||
| B à C | none | ||
| C à aD | D | D | C à a |
| C à bD | D | D | C à b |
| D à BE | B, E | B | D à E |
| E | D à B | ||
| note: we dont omit based on the subset B, E because that would introduce D àl | |||
Note that for a given production:
| S à BCD
S à CD S à BC S à C B à C |
C à aD
| bD
C à a C à b D à BE D à B D à E |
Note:
| Original grammar | Revised grammar |
| S à BCD
B à C | l C à aD | bD D à BE E à l |
S à BCD
| CD | BC | C
B à C C à aD | bD | a | b D à B |
Assertion: the revised grammar will generate the same language as the original. Why?
Consider the original production S à BCD
In some contexts it is helpful to eliminate unit productions, those of the form
Nonterminal à Nonterminal
Lets illustrate the method on the following grammar:
Step 1: for each nonterminal X, find all other nonterminals Y such that X Þ* Y in one or more steps:S à A | bb
A à B | b
B à S | a
| S Þ* A | S Þ* B | A Þ* B | A Þ* S | B Þ* S | B Þ* A |
Step 2: if X Þ * Y, and Y à
s1 | s2 |
| sn are the non-unit productions
for Y, add X à s1 | s2
|
| sn to the productions.
| S Þ* A | S Þ* B | A Þ* B | A Þ* S | B Þ* S | B Þ* A |
| add S à b | add S à a | add A à a | add A à bb | B à bb | add B à b |
Step 3: remove the unit productions
Our final grammar:
Any CFG has an equivalent* CFG (Chomsky normal form) for which
all productions are one of two types:
| (1) | A à BC | B, C nonterminals |
| (2) | B à x | x terminal |
Step 1: eliminate l-productions and
unit productions
Step 2: illustrated here for the production:
A à AaBb
(part A) replace this production by:
A à AXBY, X à a, Y à b (X, Y new nonterminals)(part B) replace A à AXBY by:
A à AP, P à XQ, Q à BY (P, Q new nonterminals)