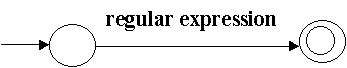
Topics
Introduction
Algorithm TG Þ RE:
create an equivalent RE from any TG
Algorithm RE Þ
NFA: create an equivalent NFA from any RE
Summary
We have studied:
Kleene's Theorem: Any language defined by one of the methods above can also be defined by any of the other two.
We will show:
(1) L defined by FA Þ L defined by
TG
(2) L defined by TG Þ L defined by
RE
(3) L defined by RE Þ L defined by
FA
This will complete the circle and prove the theorem.
Kleene Part 1: L defined by FA Þ L defined by TG
Proof: an FA is a TG. End of proof.
Kleene Part 2: L defined by TG Þ L defined by RE
The method of proof is constructive: we will show how to transform any TG, step-by-step, into an equivalent TG that has the following form:
This TG of course, defines the same language as the original TG, and also the language defined by the above regular expression, giving us the required result. The construction follows.
We show the construction via examples. But the methods shown will apply to any TG. We will start by considering our TG to be a Generalized Transition Graph (GTG; every TG is obviously a GTG, since a GTG is a generalization of a TG).
(1) if necessary, alter the GTG to have exactly one start state having
no incoming transitions:
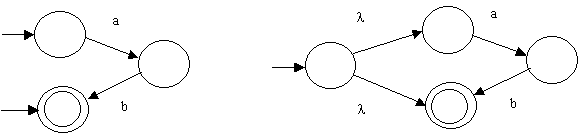
(2) if necessary, alter the GTG to have exactly one final state having
no outgoing transitions:
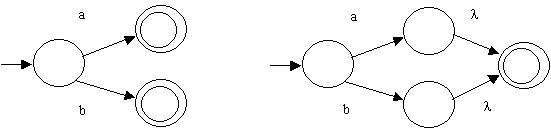
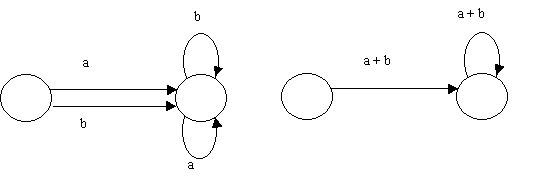
(3) consolidate multiple arrows in the same direction between states
into one:
(3) Eliminate each interior (non-start, non-final) state, one state
at a time. Here's how to eliminate a state (and still have a GTG that accepts
the same language).
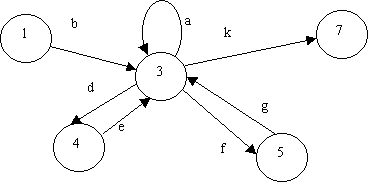
| We illustrate this with a fragment of a GTG; the state to be eliminated (here, state 3), and state 3's immediately adjacent states: | Here's what you do:
Make a list of all incoming-outgoing paths that pass through state 3, and the RE that describes that path: |
||||||||||||||||||||||||||||||
 |
|
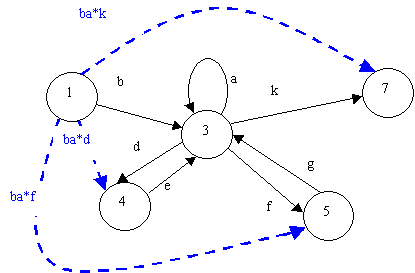
The argument: if we add the above transitions, then state 3 becomes
redundant, and we can eliminate it. For now, let's just show the new-from-state-1
transitions:
|
 |
With respect to these transitions, state 3 is entirely redundant, and we can remove the 1-3 transition:
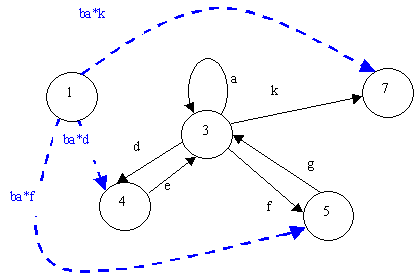
Similarly for the transitions from states 4 and 5. Now we will have no incoming transitions to state 3, hence we may eliminate it completely.
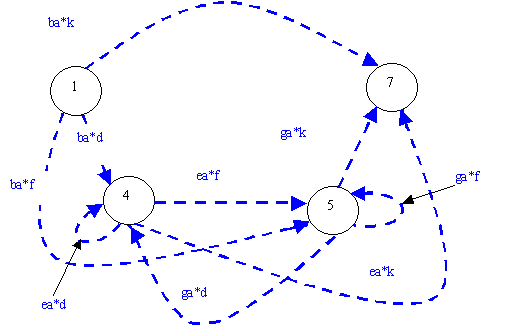
This process may create new multiple arrows; consolidate them according to step (3) above.
Eliminate each interior state as above, until you reach the following GTG:
The given regular expression is the regular expression sought.
Kleene Part 3: L defined by RE Þ L defined by FA
Here we show how to construct an NFA which will accept the language defined by a RE. By the considerations of Part I of this chapter, such an NFA has an equivalent deterministic FA, and we are done.
It's like wiring together a computer from basic parts. Note that the construction is defined recursively!
Let's assume our vocabulary is V = {a b}.
Basic parts list
| NFA to recognize the RE a: | NFA to recognize the RE b: |
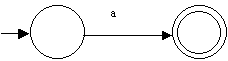 |
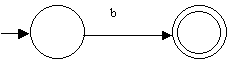 |
Now suppose we have already built NFA(r1) to recognize any given RE r1:
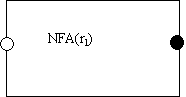
The left open dot represents the initial state and the right solid dot represents the final state (we know that any NFA can be represented with exactly one of each).
Suppose also that we have already built NFA(r2) to recognize RE r2:
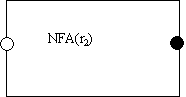
Can we wire these "subassemblies" together to create NFA(r1*),
NFA(r1r2), and NFA(r1 + r2)?
If so, our task is done, because those three operators are all we have
for creating regular expressions.
Here goes:
NFA(r1r2):
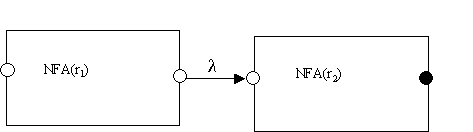
We have simply provided a transition from the final state of NFA(r1) to the initial state of NFA(r2), and made it non-final.
NFA(r1 + r2):
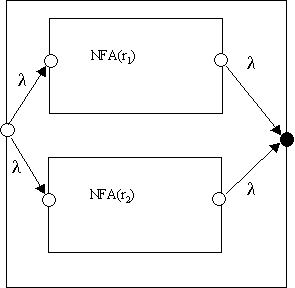
NFA(r1*):
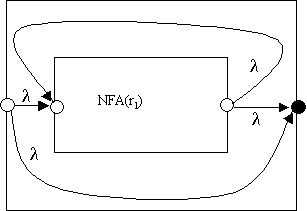
Let's see how these construction rules work for an example where we
are given 2 NFA, and required to wire them together according to the above
diagrams:
| NFA that recognizes RE a*b: | NFA that recognizes RE ac*: |
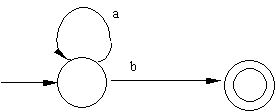 |
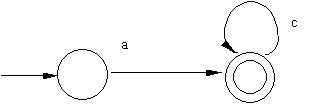 |
Now to construct NFA that recognizes (ac*)*, (a*b)(ac*), and (a*b) +
(ac*):
|
|
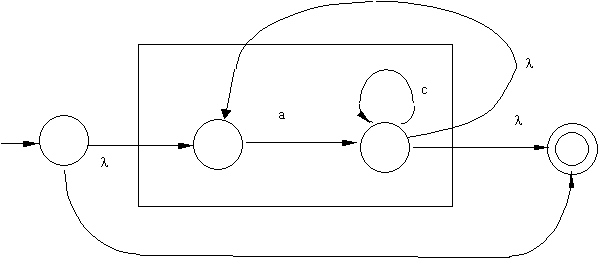 |
|
|
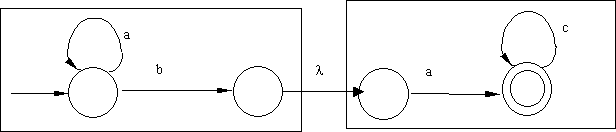 |
|
|
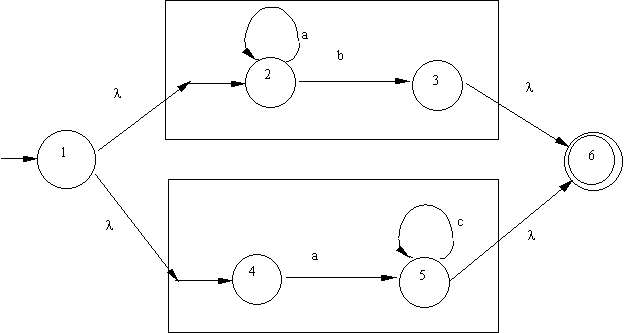 |
Part I showed that:
1. A NFA has an equivalent FA: Algorithm NFA
Þ FA
Part II showed that:
2. A FA has an equivalent TG (trivial): FA
Þ TG
3. A TG has an equivalent RE: Algorithm TG
Þ RE
4. A RE has an equivalent NFA: Algorithm RE
Þ NFA
Putting this all together, we have:
FA Þ TG Þ RE Þ NFA Þ FA
We have come full circle, and given any of the above representations of a language, we can find any of its other 4 representations by following the arrows.
The most important upshot of all this is that: