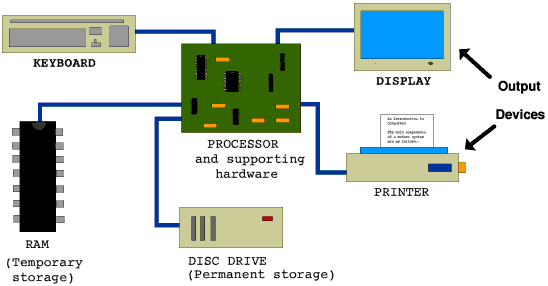
General Overview of Computer OperationWhen a computer is operating it takes in information, from a keyboard, an existing list stored on a disk, or some other external source. It then processes this information by following a set of instructions which are held in the temporary storage, having been transferred there from permanent storage. The temporary store is also used to keep intermediate results. Finally the results are sent to an output device such as a television type screen or printer, or they may be put back into the permanent store. The physical parts of the computer are known as the hardware and the list of instructions as the software. |
| Back to Contents |
Input DevicesDespite the advances in computer electronics, the main way of interacting with a computer is still a keyboard, using a key layout inherited from the early mechanical typewriters. Once information has been typed in it can of course be stored for future use, in which case a disk drive acts as an input device. Each character typed on the keyboard is assigned a number between 0 and 255, since all a computer can understand is numbers. When results are displayed on e.g. a printer the computer sends these numbers to the printer which then converts them to the actual characters to be printed. The 256 different possible numbers permit all the letters, digits and punctuation marks to be stored as well as a range of foreign letters and mathematical symbols and various 'control codes' such as marking the end of a line. For more specialised applications computers may also take information from electrical sensors such as thermocouples or electronic balances but the electrical signals must still be converted to numbers before they are fed to the computer. |
| Back to Contents |
Digression:Binary NumbersWe are accustomed to using the decimal system of numbering which needs ten symbols, 0 to 9. Computers have to handle digits in the form of electrical voltages and it has not proved practical to build a computer which can recognise ten different voltage levels because electrical resistance in the circuits will lower the voltage, causing digits to change. It is much simpler to use just two voltages, typically zero and around five volts, there then being little chance of the two voltages being mistaken. This means that computers have just two digits in their numbering system, 0 and 1, i.e. it is a binary system. Binary numbers work in the same way as decimal except that instead of digit values increasing by a factor of ten when moving one place to the left they increase by a factor of only two. This means that whereas decimal numbers are made up of units, tens, hundreds, thousands etc., binary numbers consist of units, twos, fours, eights etc. For example, 14 = 8+4+2 and in binary would be written as 01110 representing
Binary numbers are longer than their decimal equivalents but the arithmetic is actually simpler (the multiplication table stops at 1x1=1).
Any carries in binary addition are of two rather than ten. (There are never any carries in multiplication.) The information stored in a computer, whatever it may represent in the real world, is held in the form of binary numbers.
When decimal numbers are to be stored there are two ways to do it. The decimal digits can be stored in the form of their ASCII codes or the numbers can be stored in pure binary form. The binary form is more compact and numbers must be converted to this form if they are to be used in calculations. If numbers are stored in binary they will need to be converted back to decimal when they are displayed and there is no guarantee they will be displayed in the format the user expects. (e.g. the fraction ¾ could be written as 0.75, .75, 0.750, 7.5E-1 etc. ) A common problem which often puzzles newcomers arises when comparing numbers which should be equal, such as 5000 x 0.1 and 1000/2. A computer will often report that they differ by a tiny amount. This is because computers only use a fixed number of digits for their arithmetic and just as there are fractions such as 1/3 which cannot be written exactly in decimal, there are fractions which cannot be written exactly in binary, so that there is a slight error in the stored form of the number. Unfortunately the common fractions 1/10 and 1/100 are among these. This produces small errors in any calculations using these fractions, just as in decimal 0.33333 x 6 = 1.99998 instead of 2. e.g. 26 + 47 = 73
Binary coded decimal is useful if results must not contain any errors, e.g. financial calculations, but is slower than binary because of the corrections. |
| Back to Contents |
Temporary StorageThis is used to store the information that the computer is currently working on and the list of instructions that it is currently following. The key features are that the processor can get at the information very quickly, in less than a millionth of a second with current designs, and that the information can just as easily be changed by the processor. It is often called Random Access Memory (RAM) because any part of it can be reached as easily as any other. In modern computers it consists of either transistor type circuits which act as electronic switches which can be either on or off (i.e. binary) or of capacitors which can be charged or discharged (known as Static RAM and Dynamic RAM respectively), packed at one million or more per silicon chip. Computers also usually contain a small amount of memory whose contents are fixed, known as Read Only Memory (ROM). This is used to start the computer when it is first switched on and contains instructions (often called the BIOS or Basic Input Output System) tailored to the particular hardware in that computer. ROM is necessary because RAM loses its memory if the power is disconnected for even a fraction of a second. (There may also be a very small amount of RAM which is powered by an internal battery to store hardware settings such as the screen resolution - CMOS RAM.) A further type of memory which is usually present in newer machines is cache RAM. Since the first microprocessors appeared in the early 1970s they have become several thousand times faster. This means that they need to access memory very quickly, but there is a limit to how fast the memory can be read, known as its access time in nanoseconds. The access time of conventional RAM has only decreased from around 300ns to at best 60ns despite the vast increase in speed of processors over the same period. Even 60ns memory cannot be read from quickly enough to keep up with modern processors which means the processor would need to pause frequently to wait for the memory. Other types of memory which may be encountered are:-
The memory is usually divided into blocks of eight binary digits or the multiples of eight - 16, 32, and 64 - which are handled as a unit. There is no special significance to eight except that it is a power of two and is therefore convenient to use in a binary system. In general the more bytes of memory a computer has the better it performs. In the early 1980s RAM was expensive and computers had only a few thousand (kilobyte or K) to a few tens of thousands of bytes. However since 1980 the price of memory has dropped by a factor of several thousand and a desktop computer normally has at least several tens of millions of bytes (megabyte or M). The next unit up is the gigabyte, which is a thousand megabytes. Each byte of memory can store one character of text or about two and a half digits worth of a decimal number. |
| Back to Contents |
Permanent StorageSince the contents of random access memory are lost when the computer is switched off it is necessary to have some way of storing information in machine readable form so that it can easily be put back into RAM the next time the computer is used. Early computers used punched paper tape, the presence or absence of holes representing the binary digits, but modern computers normally use some form of magnetic recording. One of the first was magnetic tape but this has the disadvantage that to reach something near the end of the tape it is necessary to fast forward through all the preceding tape - a slow process and hence tapes are not random access. However tapes are still sometimes used to make back-up copies because although they are slow they are also reliable. |
| Back to Contents |
Disk Drives (sometimes spelled disc)Disk drives store information on a disk coated with the same type of magnetic particles as magnetic tape uses. The disk rotates at high speed and a read/write head moves radially across it. The advantage of a disk is that the recording head can reach any part of it quickly. Externally the only difference between a low density and a high density 3½ inch disk is an extra hole in the high density one, through which an actuator on a switch passes when it is in the drive, so that the drive can tell which it is. In the early days the high density disks were quite expensive and some people actually went to the trouble of drilling holes in low density ones to fool the drive into using them as high density. This was not a good idea because although the disk often worked initially the recording tended to fade with time and become unreadable. (Due, for example, to the lower coercivity of the coating on low density disks.) The process of setting out the pattern of tracks and sectors on a blank disk is called formatting. Hard disks operate in the same way but use a rigid aluminium or glass (which are non-magnetic) disk with a magnetic coating. (Hence hard disk). In practice they normally have a stack of disks on a single spindle, with read/write heads in between. Floppy disks can be removed from the computer and different ones inserted whereas hard disks are a complete unit with the drive mechanism and are therefore sometimes called fixed disks. However hard disks can store much more information (typically several hundred megabytes to over 100 gigabytes) than a floppy disk which is limited to around 1 megabyte. A 1973 IBM design had two 30Mb disks and was known as the '30-30'. It then became known as a 'Winchester' disk after a Winchester rifle where one 30 is the calibre and the other is the grain weight, and hard disks are still occasionally called Winchester drives. A more recent development in mass storage is the optical disk or CDROM which is similar to an audio CD and can store six hundred megabytes. They can be used in multi media devices to include sound and television playback with computing facilities. Some optical disks are read only but writable disks are also available and have largely replaced floppy disks for transferring data about, mainly because of the much greater capacity of CD ROMs. At present though compact discs are slower to access and read than hard disks, and have lower capacity, so are not likely to oust magnetic hard disks in the near future. Data is sometimes copied from the CD to the magnetic disk before use to speed up access. When a computer is operating it is often working on more information than will fit into its RAM and it may then transfer blocks of memory to and from disk as needed. The use of disk storage in this way is called virtual memory. A hard disk is needed here because of its extra speed although it is still slower than if everything would fit into RAM. |
| Back to Contents |
Output DevicesA television type display (VDU - Visual Display Unit) is now almost universally used for interactive purposes. True computer monitors give a better image than domestic televisions. Until recently most monitors used cathode ray tube (CRT) technology and were heavy and bulky. Portable computers and most new desktop computers use a liquid crystal type of display. The number of bits used to store each pixel determines how many colours or shades of grey can be produced. If only one bit is used then only two colours are possible (the bit can be 0 or 1) and the display is monochrome. Images intended to be as realistic as photographs can use 24 bits, in 3 groups of 8, to allow 256 intensities for each of the primary colours red, green and blue which gives a total of over 16 million different colours. However this uses a lot of memory and processing time and many systems compromise by allowing a smaller number (e.g. 256 or 32,000) of different colours on the screen at once, and sometimes the smaller number of colours can be chosen from a larger palette of several thousand. Displays are also referred to as interlaced or non interlaced. A television picture is made up of 625 lines but is produced by first scanning all the odd numbered lines and then 1/50th of a second later scanning all the even numbered ones. Hence the picture is made up of two interlaced half pictures, repeated 25 times a second. (This is done to reduce the amount of information which needs to be broadcast whilst maintaining good picture resolution.) One result of this is that any one scan line is only refreshed on every alternate scan, i.e. every 1/25th of a second. This can be a problem with graphic displays if the vertical resolution is one television line since it will flicker at 25 times a second - producing a shimmering image. |
| Back to Contents |
PrintersPrinters come in several varieties depending on exactly how the ink is deposited on the paper. A dot matrix printer has a print head containing fine pins (9 or 24) which press onto the paper through an inked ribbon to form characters as a pattern of dots in the same way as a VDU. (Strictly speaking nearly all printers print characters in the form of a grid of dots but the term 'dot matrix printer' normally only refers to the type just described.) The printing tends to be of a poorer quality than that produced by other designs since the dots are visible but these printers are cheap, fairly fast and are capable of printing in a variety of typefaces and of printing simple graphics. They are also the only common printers which can be used with carbon paper. Colour dot matrix printers were made, which used a banded ribbon, but they could only really cope with simple illustrations and did not give good results when printing photographic pictures. The hammering of the pins onto the paper is noisy and the more popular, now almost universally used, alternative is the ink jet (or bubble jet) which squirts droplets of ink directly onto the paper and is almost silent. Ink-jet printers produce clearer type than dot-matrix printers and do not suffer from steadily lightening print as the ribbon is used up. With suitable paper they can produce coloured prints almost as good as photographs but the downside is that the ink cartridges tend to be phenomenally expensive for the volume of ink they contain, and can dry up if not used regularly. The now obsolete daisywheel printers had pre-formed letters as on a typewriter, arranged like petals around a hub, and gave the same quality of output as an electric typewriter. They could not print pictures but it was possible to change the typeface by swapping the print wheel. Laser printers deposit ink powder (toner) electrostatically on a coated metal drum and then roll it on to the paper in a similar manner to photocopiers. They can print quickly since they print a full page at a time, give good quality results and are fairly cheap to run. Colour laser printers are now available and the price is falling so that they are a good alternative to ink-jet types for anyone who does a large amount of printing. The computer either tells the printer which characters to print by sending their ASCII code numbers which are then converted into dot patterns or whatever by the printer or else it sends the dot patterns directly. The former method restricts the typefaces (fonts) to those which the printer knows about whereas the latter allows any style of text or pictures to be printed but at a slower speed because much more information needs to be processed and sent to the printer. The baud rate which is quoted for RS-232C interfaces is a measure of how fast information can be sent along it, being roughly equivalent to bits per second. (The term baud has nothing to do with binary digits but is derived from a name, Baudot.) Since the computer can send characters quicker than the printer can print them the printer often contains its own memory (a buffer) to store them until they can be printed, freeing the computer to do something else. (Storing items to be printed in an intermediate memory is also called print spooling, either from the days when the memory would have been a spool of magnetic tape or standing for Simultaneous Peripheral Operation OnLine.) |
| Back to Contents |
The ProcessorThe processor or Central Processing Unit (CPU) is the 'intelligence' of the computer. It performs arithmetic, makes decisions on what to do next based on the result, and generally controls the flow of information to and from the memory, disk drives etc. When the computer is operating the CPU follows a list of instructions stored in RAM - the program (not programme). The general order of events for each instruction is:-
The instructions themselves are quite simple, such as adding together two binary numbers, transferring bytes to and from memory and jumping to a different part of the program depending on the result of a calculation. One difference between large mainframe computers and desktop models is in the complexity of the processor. Mainframe CPUs can usually handle large numbers with fractional parts (floating point numbers) whereas the simpler microprocessors in early desktops could only handle small whole numbers. (To do calculations on larger numbers a microprocessor has to perform several instructions and build up the answer in stages, similar to long multiplication by hand.) The power of a processor comes from the speed and accuracy with which it operates. The number of 'bits' of a processor is the number of binary digits it can handle as one unit. More bits means the computer does more work with each instruction and operates faster. Sixteen or 32 bits is typical for a desktop computer at present, while mainframes are sixty four bit or more. Microprocessors are usually known by numbers such as 6502, Z80, 8086, 80286, 68000, ARM9 etc. Many computers have an optional or built in maths coprocessor. This is specifically designed for doing arithmetic and works alongside the main processor. It can speed up calculations, but not unless the program that the computer is using has been written to use a coprocessor. |
| Back to Contents |
The History of Computer DevelopmentA computer is essentially a general purpose, programmable machine, though usually specialised for arithmetic. The earliest programmable machine was the Jacquard Loom, using punched cards to control the movement of needles to weave patterns automatically. The first machine specifically designed for complex calculations was Charles Babbage's Analytical Engine, begun in 1836. It used a mechanical system of gear wheels and levers to follow a program on punched cards. However the precision manufacturing technology of the time was insufficient and the machine was never completed, though a fully working version has recently been built to the original design. Several electro-mechanical numerical computers, using relays as switches, were built but they suffered from being slow and unreliable. Completely electronic computers, using valves, could operate more quickly and the best known example was the Electronic Numerical Integrator And Computer, ENIAC, used by the American military during the second world war for calculating missile trajectories. ENIAC however had two serious shortcomings. Firstly it was 'hard wired', meaning that to change the calculations it performed it was necessary to change the wiring with a soldering iron. Secondly, because it used vacuum tubes it was very big (30 tonnes) and the large number of tubes, 19000, made it unreliable - the average time between breakdowns was seven minutes. Later computers stored the instructions in an easily changed memory which allowed them to perform any type of calculation just by changing these instructions. (This was a system first suggested by John von Neuman. Alan Turing had proved that any problem which could be solved by following a finite list of instructions could be solved by such a stored program machine.) The memory at this time was often a magnetic system using tape or magnetically coated drums for bulk storage and a smaller but faster type for working storage. One design used a mercury delay line which stored binary digits as pulses of sound travelling around a circular tube of mercury. This was a serial memory since it was necessary to wait for the information to circulate round to the detecting point before it could be read, in contrast to modern random access memory. Another design of memory around this time used a modified cathode ray tube (known as a storage tube) which had a metal plate over the front surface. Data was written to the memory as a pattern of illumination on the tube and could be read back by detecting the change in capacitance between the tube and the metal plate as the beam was scanned back over it. A later type of memory had a grid of criss-crossed wires with a tiny ferrite ring or 'core' over each intersection. Each one stored one bit of data by way of the direction of magnetisation of the ferrite. Main memory in a computer is still sometimes called 'core' memory for this reason. Arguably the first true stored program computer was built at Manchester University in 1948 (unimaginatively called the Manchester Mk1) and Manchester remained among the leaders in computer innovation for some time. During the 1950s and 60s computers became more complex and faster because of the use of transistors in place of valves. The circuitry was built on small boards which connected together by being plugged into a framework, hence they became known as mainframes. Because computers were being virtually hand built the cost was high and to make full use of them it was necessary for several people, each using a separate terminal, to share one computer. This was possible because it generally takes far longer for a user to type commands into the computer than it takes for the computer to process them. There are also delays with slower devices like the magnetic tape stores used at this time. The computer was set to switch its attention from one person to another rapidly so that each appeared to be using it continuously. This is an example of a multi user system. It was also multi tasking since it could spend a fraction of a second running each of several programs in turn and thus appeared to be running all of them at the same time, albeit more slowly. In practice few people used computers directly. The usual system was to write out the program and any fixed data, which was typed into a machine that converted it into punched cards. These were then fed into a card reader so that they could be entered into the computer's memory rapidly when processing time was available. Direct human input was kept to a minimum to avoid slowing down the computer and to make best use of it as an expensive resource. Using pre-prepared programs and data was known as batch processing. |
| Back to Contents |
The PCThings began to change more rapidly in the early 1970s when integrated circuits became available to replace individual transistors. Mainframe computers continued to be built and have become steadily faster with more memory. Mini computers which were scaled down and cheaper versions of mainframes but still multi user also appeared. The big growth area though has been in small, 'personal computers', PCs, designed to be used by only one person at a time. One of the earliest was the Altair of 1975 but this had to be programmed by setting switches on the front panel and gave its results by illuminating a row of lights. From 1980 the 'home' computer market took off, in the UK largely thanks to the low cost Sinclair ZX80 and ZX81. Numerous other manufacturers joined the market so that by 1984 there was a bewildering number of different home computers, e.g. Sinclair ZX Spectrum, Commodore 64 and VIC 20 (versions of the PET with colour displays), Apple II, Acorn Electron and BBC model B, Tandy TRS-80, Video Genie, Tangerine, Dragon 32, Atari 800, Oric, Sharp MZ 80 and many others. |
| Back to Contents |
Business ComputersNone of the home computers was really successful outside home use. They tended to be of poor mechanical construction and had limited storage capacity which could not easily be increased. The biggest problem though was incompatibility. Every make of computer, and often even different models from the same manufacturer, differed in its internal design and general operation. This meant that a program written for one model had to be almost entirely rewritten to work on another, and it was difficult to even swap information on disk. (Compare this to, for example, audio cassette tapes which can be played on any machine.) The Japanese manufacturers tried to introduce standardisation into the home computer world with the MSX range but they entered the market too late, when other computers had already sold in very large numbers and created their own pseudo standards, and for once they were unsuccessful. Around 1982 though, a new range of computers began to appear based on 16 bit processors which gave faster operation and much more memory capacity. They also had built in disk drives and tended to be of better quality construction. The IBM was well made and reliable and largely due to the size and marketing power of IBM it established itself as the nearest thing the computer industry had to a standard. |
| Back to Contents |
ProblemsAlthough the IBM PC looked like introducing standardisation things were not so simple. (As Samuel Johnson might have said, there are standards, broad standards and computer standards.) There have been numerous versions of the microprocessor used in the PC (Intel 8088, 8086, 80286, 80386, 80486, Pentium, K6, Pentium Pro, Celeron...) and a program written to use the extra features of the newer models may not work on the older ones. They have different clock speeds (8, 16, 25, 33, 50, 133MHz ... up to over 2GHz) which means that programs operate at different speeds, occasionally causing problems. The floppy disk drives can have various capacities (180K, 360K, 720K, 1.2M & 1.44M) and came in two sizes (3½" & 5¼"). The display can be monochrome, Video Graphics Array (VGA), Enhanced Graphics Adapter (EGA), Super Video Graphics Array (SVGA) or others, each with different resolutions and different colour capabilities. Programs sometimes have to be told which display adaptor and other hardware is in use before they will work properly (and it is not always easy to find out on an unknown PC). There were six versions of the disk operating system (DOS), each with several sub versions. There are subtle differences between them (some even contain serious mistakes) and some programs refuse to work with early versions. In use the operating system required a large number of obscure commands which are very fussy about the way they are typed (a missed space will give an error message) and was entirely command line based, not making use of the computer's visual abilities. However most programs manage to adapt themselves to the specific hardware and there are utilities to hide the complexity so that PCs work well if properly set up. Hence despite its shortcomings the IBM "standard" remained popular due to the vast range of software available and the open design of the hardware which allows extra features to be grafted on. 'Clones' of the IBM type, made by various other companies, are now more numerous and usually cheaper than the original. |
| Back to Contents |
Rivals to IBMAnother computer which has some popularity in business and the home is the Apple Macintosh. This originally used what was usually considered to be a better processor than that in the IBM (a Motorola 68000 series) but was therefore incompatible since the two processors use a different machine code language. (In fact the differences are not too great and there are programs called emulators which will translate one microprocessor's instructions into the other's so that programs can be run. Emulators are slower than the genuine machine and there are such differences in the rest of the hardware that they are seldom really successful.) Later Apple and IBM cooperated to design a new processor (the Power PC) which was faster than either the Intel or Motorola types but was capable of running their programs through a form of emulator. From the start the main selling point of the Macintosh was its use of a graphical operating system (otherwise called a Graphical User Interface or GUI. Nearly everything in the computer world has a TLA, Three Letter Abbreviation.) where commands are issued by pointing to an on-screen menu or object and pressing a button. The normal pointing device is a mouse, a small box which is moved over the surface of a desk and moves a corresponding pointer on the screen. With this type of operating system the screen is set out as a picture of a real 'desk top' with drawings (Icons) representing the disk drives and programs available. There is a menu bar across the top of the screen and when an item is selected it may produce a 'drop down' menu below it of further choices. When a disk drive is selected it opens a 'window' on top of the desktop showing the contents of the disk. The window can be changed in size and moved around the screen if desired and can be closed to remove it from view. This type of operating system removes the need to remember the exact commands since they are in the menu or in many cases are not needed because of the ability to point to and move objects using the mouse. Programs written for the Macintosh also used this system which introduced a uniformity in the operation of programs and made it much easier to learn to use new ones. Such a user interface is called a WIMP (Windows, Icons, Menus and Pointers) and the idea was copied by several other manufacturers. E.g. the Atari ST range used GEM or Graphical Environment Manager and the Acorn range used RISCOS). There tends to be better compatibility between different versions of computers using WIMPs because commands to access the screen and other hardware normally go through a Virtual Device Interface (yes, VDI) which converts the command into a form suitable for the particular computer in use. There is a theory that by using pictures rather than words the operating system is understood by the left hand side of the brain rather than the right hand and is more intuitive as a result. IBM though was sluggish in bringing out a graphical operating system to compete with Apple's. IBM is a large bureaucratic company which responds too slowly to changes in the market and as a result sometimes gets left behind. In 1992 IBM achieved the distinction of making the biggest corporate loss in history, $3.3billion, although their finances have since improved. |
| Back to Contents |
Windows ©®TMIn the early 1990s Microsoft produced a window-based GUI for IBM compatibles called Windows (much thought obviously went into that name) which thanks to marketing hype rather than merit became the most commonly used operating system. It is not quite as simple or intuitive to use as the Apple system, partly because Apple threatened to sue Microsoft if Windows copied any of the Apple's patented features too closely. There have been numerous versions of Windows. Version 1 was no more than a vaguely graphical menu system for starting programs, version 2 introduced a limited form of windowing environment, version 3 was the first which was actually usable and version 4, Windows 95 (which was originally intended for launch in 1994 and almost ended up as Windows 96), rivalled the Apple system for features. It was followed by Windows 98, Windows Millennium, Windows XP and Vista, together with several versions of Windows NT and Windows 2000 which were intended for business rather than home users. |
| Back to Contents |
PortablesMuch of the growth in the conventional PC market recently has been in portable, 'laptop', computers. These can do almost anything a full size one can but run on batteries and have a built in flat screen. The main disadvantages of laptops are that the screen can be difficult to see and battery life is very short, usually only a few hours. They can be used to enter information 'in the field' which is then transferred to a full size PC back at base, or can be run off the mains as a replacement for a full-size desktop model (though since portables are more expensive to buy and maintain than non-portables this seems pointless.) |
| Back to Contents |
The FutureThere has been little qualitative change in computer hardware since the mid 1980s. Processor speeds have increased, memories are bigger and graphics have improved but the basic design has remained the same. Two new designs which have appeared are:-
It seems almost certain that in the short term computers will continue to evolve along their current lines. Processor speeds will increase and hardware prices will drop. It is possible that cheap and very high capacity permanent electronic memory will be developed, which does not lose its contents when the power is switched off, like flash RAM but with an unlimited number of rewrite cycles. This could replace hard disk drives. Further ahead, much has been made of the possibilities of optical computing, using beams of laser light instead of electric currents and opaque/transparent windows as switches. Such systems are theoretically capable of operating at very high speeds but are still a long way from even the prototype stage. A possible total change in the design of computers is the use of networks which consist of nodes or neurons, each having the ability to both store and process information rather than these two functions being separated. Each node on its own would have very limited capability but a system of billions of them all interlinked would form a very powerful processing machine. This of course is exactly how the brain works. It is largely a philosophical question whether such a machine could think and be considered intelligent or whether intelligence is specific to chemical brains. The main difference between human (or animal) and machine intelligence is probably that current computers are digital whereas brains are analogue devices, rather like the difference between a calculator and a slide rule. Further ahead, it may prove possible to build quantum computers. Whereas in a conventional computer a bit can be either 0 or 1 and a byte just holds a single number, in a quantum computer a 'qubit' can be both a 0 and a 1 at the same time, and a 'qubyte' could hold all possible values at once. Theoretically it is possible for a quantum computer to carry out a huge number of calculations simultaneously and at the end select the one which is needed. One application is in decrypting encoded messages. Some encryption systems would take thousands of years to break with the fastest conventional computers, but could be decoded almost instantly with a quantum computer. |
| Back to Contents |
Computer ReliabilityConsidering that they are performing millions of operations per second, modern computers are very reliable. However there are three main causes of errors.
An example of a further problem which can creep in even if the program is totally correct is that most microprocessors are not designed from scratch to perform all their functions, such as division and other operations, because to design it all from simple logic gates would be extremely time consuming and error prone. Instead a very basic processor is designed which can only do the simplest of functions such as setting and resetting bits and logical operations. The more complex functions are then built up from these using a programming language called a microcode, built in to the processor. If there are any mistakes in the microcode they may only manifest themselves rarely and cause inexplicable faults in any program running on that microprocessor. (There was an instruction for the Motorola M6800 microprocessor, included for test purposes, which caused it to toggle some of its outputs between 0 and 1 as fast as it could. This dissipated heat and in some designs could damage the circuitry - the legendary Halt and Catch Fire instruction.) |
| Back to Contents |
Data Reliability, Archiving and BackupsA modern desktop PC will contain many hundreds of megabytes or even gigabytes of the user's own information on its hard disk, in addition to installed commercial software. This information will include such things as word processor documents, personal photographs in digital form, music files, etc, which cannot be easily replaced. A computer used in business may well have data which is essential to the running of the business. In either case it would be at best extremely inconvenient and at worst disastrous if this information were to be lost. Unfortunately hard disks do go wrong and can become unusable. Their average life expectancy is equivalent to several years of continuous use but that is no guarantee that yours will not fail after a few months. It is therefore essential to have back up copies of all important information, together with the original installation disks for the operating system and application programs, so that when a new hard disk is fitted it can be loaded with the contents of the old disk. (There is often some warning that the disk is failing as it may give occasional error messages or begin making a lot of noise. It is then possible to temporarily fit a new disk as well as the original and copy data directly between them.) There are several options for making back-ups. A second hard disk drive can be fitted, either internally or externally, and the contents of the main drive regularly copied to the spare one. This is quite quick and easy so long as you remember to do it, but there is always the risk that both drives will be lost at the same time, e.g. if the PC were stolen. Nearly all new desktop and laptop computers come with a DVD writer drive. This allows data to be copied from the hard disk onto compact disk (CD) or digital versatile disk (DVD). DVDs are particularly useful because of their high capacity, over 4 gigabytes, which means there is less need to split backups over several disks than would be the case if using CDs. If the data on the PC is changing rapidly, such as stock and sales records in a business environment, then backups need to be done frequently, ideally daily. If you only use the computer to write the occasional letter then backups can be less frequent, monthly say. The rewritable disks are best for information which is changing whereas write-once disks are better for 'archive' data such as the previous year's transactions, which are not going to change again. The backing-up process can be a little time consuming, though specialised software can partly automate it, and it should be noted that writable disks of any kind seem to have a high failure rate while they are being written to (though not once this is completed). For this reason you should never make a new backup onto your only copy of the previous backup or you may lose it. Instead, if using rewritable disks then have at least two and use them in a cycle, so that the last backup is still intact if the current one fails. With the move to high-speed internet connections over the past few years an alternative form of backup has become feasible. This is to copy your files over the internet onto a server operated by the internet service provider (ISP). Some ISPs offer a certain amount of storage space as part of a broadband package.
Long-Term Storage of DataThere may be some information on your computer which you want to keep for a long time, such as digital photographs. Conventional photographic prints from several decades ago are still perfectly viewable and can be of considerable historic interest, especially if they are of your own ancestors. Will digital photographs last so long? This is the field of data archiving and the answer depends on many factors, not just the medium used to store the pictures. As previously described you should not rely on a magnetic hard disk for storage of more than a few years because it will eventually wear out, and even if it is not used the magnetic patterns will fade over time. The data needs to be copied to some other medium, but which is best? It is not just the reliability of the storage medium itself which matters. The hardware needed to read it would also have to be available in the future, in working order and not just in a museum. For example, until CD-writers became common around the year 2000, magnetic tape cartridges (similar to a large audio cassette) were often the backup medium of choice. Just a few years later they are now seldom seen, and to make matters worse there were several incompatible designs so that it would be tricky now to read a cartridge from just ten years ago. You might think of keeping the reading hardware (e.g. tape drive, 5¼ inch floppy drive) as well as the medium, but there is no guarantee that future computers will be able to interface to obsolete drives. For example, until recently hard disk drives mostly used a parallel ATA (PATA) interface, but as of 2008 many are switching to serial ATA (SATA) connections, with a different design of plug and fewer wires. In five years time it may be impossible to attach a PATA drive to the latest PCs. Secondly you need to consider whether any specialised software needed to make sense of the stored data will still be available. Twenty years ago the most popular spreadsheet was Lotus 123, but this is no longer produced and whilst current spreadsheets will often import 123 files, this will not be the case indefinitely. An 'open' data format such as Adobe Acrobat, details of which are freely published, is more likely to remain readable in the future than a 'closed' proprietary format like Microsoft Word. If the documentation on how the information in a file is laid out is not available then it may be very difficult to write new software to decode and display it, even if the file itself can still be read. For this reason a very simple format such as plain ASCII text is preferable to the highly complex formats used by many word processors. Lifetimes of Storage MediaThe lifetime of most media decreases in a fairly regular way with increased storage temperature. This means that by storing it at a high temperature for a short time its life expectancy at normal temperatures can be estimated.
ConclusionsAt the moment the best option for archiving data seems to be recordable DVDs, but make sure that no special software is needed to read them. For this reason it is best not to use compression programs to squeeze more onto each DVD since the decompression program may not work on future hardware. Despite technological advances, it may well be that the safest backups for crucial data in the long term are paper printouts, since they do not require any specialised hardware or software to read. Similarly if you have a collection of photographs taken with a digital camera it is worth having the best ones commercially made into prints and keeping them in a good quality album (with acid-free paper), rather than relying on versions which are only readable by a machine. Once you have your archived data, in whatever physical form, it ought to be stored at a low and constant temperature and relative humidity. Also keep it away from direct sunlight, especially optical disks which are inevitably light-sensitive. Magnetic disks need to be kept away from strong magnetic fields such as are found near speakers and cathode ray tube type televisions. For ultimate security it is worth keeping multiple copies in different locations. This applies for example to business users. There is no point keeping the only backup copy in the office next to the computer because in the event of a fire they would both be destroyed. Keep a spare copy at home as well. BBC DomesdayA good example of the perils of computer data storage is provided by the BBC Domesday Project. The original Domesday Book, containing a census of Britain, was written in the year 1086 on sheepskin parchment. Several copies still exist in museums and can be read, with care. The project was just about completed and all the data was stored on laserdisks. These had been invented by Phillips as a means of distributing films to watch at home. Laserdisks resembled a large CD and were read by laser, but the data was stored as an 'analogue' (continuously varying signal) signal rather than as a digital pattern of 0s and 1s. In the event of course video cassettes became the preferred medium for watching films and few laserdisk players were sold for home use. For the BBC Domesday a specially modified laserdisk player was connected to an Acorn BBC Master home computer via a new interface (actually an early form of SCSI) so that textual information could be read by the computer using custom-written software while pictures were fed directly to a monitor. A video mixer allowed the pictures to be overlaid by the computer's text display. The system worked and contained a vast amount of survey data, but the complete package of laserdisk player, interface, computer and software cost £4000 and only a small number of systems were sold, to large libraries or well-off educational establishments. However, the laserdisks can deteriorate over the years, the players are mechanical devices and wear out, and the BBC Model B has long been obsolete (though there are probably plenty still in the backs of cupboards.)
It is quite likely that had another ten years elapsed before starting project CAMiLEON the task would have proved impossible. Therefore the 'hi-tech' Domesday Book would have lasted no more than 30 years whereas the original, written by hand on the dried skin of sheep, should easily pass the 1000 year mark. |
| Back to Contents |
Application ProgramsThe first home computers sold mostly to the hobbyist market where the interest was in persuading the computer to actually do something, irrespective of whether it was anything useful. Commercial software was virtually non-existent and so programs, mostly simple games or mathematically based, were written by the owners using the built-in BASIC language. However for the machines to sell to a wider market and to people who were not interested in computers per se programs had to be produced which were genuinely of use and which could be used without any expert knowledge. Such programs are generally referred to as applications. There is a relatively small number of classes of application but usually a very wide choice of competing versions, although recently the trend has been for a few programs to take most of the market. Some of the different classes will now be considered. |
| Back to Contents |
SpreadsheetsA spreadsheet is essentially a large table of boxes which can be filled with numbers or with equations, which can refer to the contents of other boxes that may themselves be calculated from still more boxes. Spreadsheets are based on a system which was used for financial planning which had the boxes drawn on a blackboard and filled in by hand. The problem with the manual version was that because of the links between boxes, a change to one of the input values could result in many other values having to be recalculated which was obviously error prone. |
| Back to Contents |
Word ProcessorsWord processors are probably the most common application. They are in essence a typewriter which allows typing errors to be corrected and text moved around before it is printed. A word processing system obviously needs a good printer if the output is not to look 'computerish'. The first word processors displayed a blank screen on which text could be typed, edited and moved around and it was also possible to include special codes to control the printer to produce effects such as underlining or bold. There was however little attempt to make the screen display resemble the final printed version, resulting in wasted paper to check the appearance before going back to modify it. When PCs began to appear in business there was much talk about the 'paperless office', the idea being that records would be stored on computer disc rather than in printed form. It is ironic that the ease with which (maybe multiple copies of) pages can be printed from a PC has in fact resulted in far more paper being used. (It is a strange fact that it is much easier to read and check a document printed on paper than when it is displayed on the computer screen. Even Bill Gates has admitted that if he has a lot of text to read he prints it out.) Whereas the first popular word processor, Wordstar, worked on a computer with only 64K bytes of memory the modern versions tend to take up many megabytes of disk space.
The latest word processors now have so many functions that few people will ever use or even understand all of them. Lotus AmiPro came with a 600 page printed manual - who ever needed a manual to use a typewriter? |
| Back to Contents |
Desktop PublishingA desktop publishing program is similar to a word processor but gives fuller control over the layout of the text, for example printing in columns and around pictures. Such programs make publishing small circulation magazines and booklets much cheaper since it is not necessary to send the copy to a publishing bureau to be laid out and typeset. The program can produce an output which is ready to be printed directly on a Linotype printer by a commercial printer, including the pictures. The Apple Macintosh is the preferred computer for this sort of work, mainly because it had a head start over the PC with its graphical display and ability to use different fonts which meant it could show pages on the screen exactly as they would be printed. |
| Back to Contents |
DatabasesA database is used to store information in a form such that it can easily be retrieved by the computer. This requires that some order be enforced on the information and also usually limits what can be stored. Most databases use the concept of records each of which is made up of fields of data. For example an address database may have fields for name, address and telephone number and each group of a name, an address and a telephone number constitutes one record. It is usually necessary to assign a type to each field, that specifies what sort of information the field is going to hold, whether numbers, text or dates for example. The database restricts what can be entered into each field to data of the correct type. There is also often a limit on the size of each field, i.e. the maximum number of characters. Newer databases may also allow pictures or sounds to be stored in addition to text. The biggest advantage of storing information on a computer rather than in a card file is that it can be searched much more easily. Databases of any kind use a key which is the field on which the data is sorted into order, for example the names in an address file. This makes it easy to look up a telephone number given the name but it is very difficult to find a name given only the number. A computer is able to do the equivalent of searching through all the cards very quickly so that this reverse searching becomes feasible. It is also possible to link databases together so that information looked up in one can be used as a cross reference to another. Many commercial systems rely on these links. The information in a large commercial database can be very valuable since it would be time consuming to reenter it and often the original source may no longer be available. It is therefore vital to make regular backups and not rely on a single copy on a hard disk. |
| Back to Contents |
Drawing and Painting ProgramsThese allow the user to produce pictures on the screen, perhaps for use in other programs or as illustrations in a word processor document. There is a distinction between drawing and painting programs which is that a painting program generally works by setting individual pixels on the computer's screen to make up an image whereas a drawing program remembers the picture as a series of lines and shapes to be drawn. A painting program would be used to produce a realistic looking image on the screen but has the limitation that the picture is only stored with the same amount of detail as it is displayed so that if part of the image is magnified it becomes grainy. A drawing program on the other hand tends to produce simpler looking pictures (similar to hand-drawn illustrations) but they can be rescaled at will without losing detail. Drawing programs are used to produce technical type drawings rather than photographic quality pictures. A painting program will have tools which simulate paint brushes of various widths together with spray gun effects to build up a colour gradually, all controlled by the mouse. Unlike a genuine painting a computer image can be invisibly modified as much as desired, including tricks such as changing all occurrences of one colour for another or applying a sepia tint to the whole image. |
| Back to Contents |
Programming and Programming LanguagesAs previously stated, a computer needs a set of instructions telling it in complete detail how to perform each task it is meant to do, i.e. a program. There are some so-called 'program generators' which will automatically write some of the more common parts of a program, such as displaying output in a standard way, but most programming is still done by hand. Since the price of computer hardware has dropped drastically over the last 40 years but the time taken to write a program has only decreased moderately this means that very often the software costs of a computer system far outweigh the hardware costs. A typical largish program running on a PC may take several person-years of work to produce and may therefore cost in the region of £100,000 to produce. It is only because it costs very little to duplicate a program once written and because of the large number of potential customers that it is possible to sell programs for a reasonable price of up to a few hundred pounds. The microprocessor in a computer can only understand very simple instructions in binary language. However, since it is very difficult for humans to understand binary, programs are normally written in a language which more or less resembles English and is then translated into binary by various means. (Because the early computers were designed in Britain and America, English is the usual language for programming. It is of course possible to use any other language and as long ago as 1984 a replacement ROM was available for the Sinclair ZX81 which enabled it to be programmed in Arabic.) It is probably now worthwhile looking at the range of programming languages in existence and their evolution over time. |
| Back to Contents |
Low Level LanguagesMachine Code and Assembly LanguageEach instruction that a processor understands is given a binary number called the machine code and the first computers had to be programmed directly in binary, so that for example a program to calculate the average of four numbers might look like this:-00111011 00000000 01111000 10110011 01111000 10110100 01111000 10110101 01111000 10110110 11000111 11000111 which is not exactly easy to read. A slight improvement on this was to use the hexadecimal system to write down the numbers. Hexadecimal means using 16 as the number base so that the digits 0 to 9 are as in the decimal system then A=10, B=11, C=12, D=13, E=14, F=15. Digits to the left of the units column then represent powers of 16 rather than powers of 10. A program written purely as a sequence of numbers is known as machine code. It is obviously very difficult to remember the meaning of each of the (possibly several hundred) different instructions written as a number and an additional problem is that the way a number is interpreted often depends on the previous instruction. For these reasons machine code was soon replaced by assembly language. In assembly language each instruction is given an abbreviated name, called a mnemonic or opcode, which describes what the instruction does. Examples are LD to mean load (i.e. put a number into a given location), ADD to add numbers together, and SRA which stands for Shift Right Arithmetically (i.e. move each binary digit one place to the right, which has the effect of dividing a number by two). The above program written in assembly language might look like this:-
Put zero in the Accumulator (part of the processor) Add in the contents of memory locations B3 - B6 Shift the result right twice to divide by four and hence calculate the average. Such a program is easier to write and for another programmer to understand than one written in machine code, at least for small programs. However it is important to remember that the computer can only understand the original binary version and a program written in assembly language must be translated into numbers either manually or using another program called an assembler. (Since there is a direct correspondence between assembly language and machine code the translation process is simple and the programmer knows exactly which instructions the assembly language will be turned into.) |
| Back to Contents |
High Level LanguagesFrom the late 1950s onwards the move has been towards high level languages which tend to use a combination of English and mathematical notation. The idea behind them is that the programmer can concentrate more on what the program has to do and less on precisely how it is achieved. For example to print the letter A on the ninth row and 15th column of the screen using assembly language would usually require the programmer to know the address in memory where the screen image is stored (the base address), to multiply the row number by the number of columns per line and the height of characters in pixels, add the column number multiplied by the number of bytes per column and add the total to the base address. The bit patterns for the character A would then be loaded into memory starting at this address. The assembly language might look like this:-
LD R1, 9 ;the line number
LD R2, 15 ;the column number
LD R3, 80 ;the number of columns per line
LD R4, 16384 ;the start of screen memory
MUL R1, R3, R6 ;9x80 and store in R6
MUL R6, 8, R6 ;8 bytes per character
ADD R6, R2, R6 ;add the column number
;(assume 1 byte per column)
ADD R6, R4, R6 ;add the base address
LD R5, %00011000 ;bit pattern for top line of A
LD (R6), R5 ;put 'A' into the calculated address
. . . ;continue with the rest of
. . . ;the bit patterns
When writing a section of program such as this it is very easy to get bogged down in the details and lose one's thread of thought about the program as a whole. By contrast the same instructions in a high level language could be as simple as:-
Whatever high level language is used, a computer only understands machine code and so the high level language must be translated into machine code before the program can be run. This is sometimes done with a program (which is itself running as machine code) called an interpreter. When an interpreted language is running the interpreter takes each statement in turn, checks the syntax for errors, and decides what it means using a table of commands. Other parameters of the command, such as the line and column numbers in the above example, are also read in and then one of the pre-written machine code routines contained in the interpreter is called to carry out the instruction. The solution to this slowness is to use a compiler. A compiler reads through the entire program and converts it into machine code instructions which are stored in memory or on disk. When the program is run these instructions can be understood directly by the processor, resulting in a large speed increase compared to an interpreter. Since a compiler has to store extra information in the compiled version of a program to allow errors to be related to the original high level language version and because compilers cannot usually produce machine code which is quite as good as if it were hand written, compiled programs tend to take up more memory than ones written directly in assembly language and do not run quite as fast. Typically they are a few times slower than assembly language, but much faster than interpreters. |
| Back to Contents |
BASIC- Beginners All-purpose Symbolic Instruction CodeOriginally devised at Dartmouth College in the USA in 1964 to teach programming to students. BASIC was usually interpreted to make debugging of programs easier and was therefore very slow. Now however compilers are available and BASIC can run quite fast. Most of the early home computers, from 1980 onwards, had BASIC built in (frequently a Microsoft version) and it was still often supplied as the 'free' programming language with home computers until the PC became ubiquitous. In fact PCs were until quite recently supplied with Microsoft's QBASIC, though few owners used it. More recently Visual BASIC has become a common way to develop small programs. This allows full and relatively easy use of the graphical interface of Windows PCs and has many advanced features, but bears little resemblance to the old-style BASICs. As a result BASIC is now one of the most widely used programming languages.
Example:
|
| Back to Contents |
ALGOL- ALGOrithmic Language.An algorithm is a step by step procedure for solving a problem, named after the Arabian mathematician Alkarismi.
ALGOL went through several versions starting with ALGOL 58 in 1958, but is usually ALGOL 68. ALGOL is always compiled. |
| Back to Contents |
Pascal- Named after the French mathematician Blaise PascalDesigned by Niklaus Wirth in 1968 as a derivative of ALGOL, Pascal was designed to be easy to compile and as a result programs written in it tend to be fast. ("Pascal runs like Blaises.") |
| Back to Contents |
Modula 2- Uses MODULAr programmingDerived from Pascal by Niklaus Wirth. A compiled language. Although Pascal allows a program to be broken down into separate operations, known as procedures, all the procedures used in a program must be part of that program. Modula 2 allows completely separate subprograms to be written which can be compiled individually before being slotted together. Each subprogram or module contains a definition of the input it requires and the output it produces but what happens within the module is hidden. This approach to programming is useful for large programs written by a team of programmers and can produce reliable programs. It was only in the late 1980s that implementations of Modula 2 became widely available but they tended to be difficult to use. If it had been developed it could have become a popular language but at the moment it has fallen out of favour. |
| Back to Contents |
ADANamed after Ada Lovelace, the close assistant of Charles Babbage and daughter of Lord Byron and his half sister. |
| Back to Contents |
COBOL- COmmon Business Oriented LanguageDesigned for writing business programs such as record keeping and stock control programs. COBOL is very verbose in written form and not very clear. It is well equipped with features for defining how information is to be inputted and displayed but has only limited ability to process the information. COBOL is the only common language to use binary coded decimal arithmetic. COBOL seems to have been largely superseded but many 'legacy' systems in business still use it and some specialised database languages have their roots in it.
|
| Back to Contents |
FORTRAN- FORmula TRANslationThe two best known versions are FORTRAN 66 and FORTRAN 77 (as in 1977), although FORTRAN 92 has appeared. A compiled language.
|
| Back to Contents |
LOGO- From the word for a drawing.Designed by Dr Seymour Papert at MIT. Always interpreted. |
| Back to Contents |
LISP- LISt Processing language (or alternatively Lots of Irritating Superfluous Parentheses)Invented by John McCarthy at MIT in the late 1950s. LISP is based on the idea of variable length lists of 'objects' and trees (which are lists linked together in a specified way) as the fundamental data type. There is no real distinction between variables and commands in that each command returns a value and lists may contain commands which are carried out when the list is used. LISP is mainly used for 'Artificial Intelligence' programming because it allows items of information to be linked together. |
| Back to Contents |
PROLOG- PROgramming in LOGicAnother language used in artificial intelligence. The classic example of artificial intelligence is expert systems such as those used for medical diagnosis. In this case a highly experienced consultant enters his accumulated wisdom into a computer system which produces a series of rules and conclusions. This can then be used by a less experienced doctor who will enter the symptoms of the illness together with any test results. The program will apply the rules which it has 'learnt' and list the possible diagnoses, perhaps including suggestions for further tests. It is important to remember that the expert system has no intelligence of its own and is only as good, or bad, as the information that was fed into it. At present such systems tend to be more artificial than intelligent. |
| Back to Contents |
FORTH- Possibly from 'fourth'Originally designed in the late 1960s for the control of radio telescopes. Interpreted. : run fast 9249 x ! 9339 y ! 9479 z ! 0 a ! 6 k ! b 3 9249 c ! begin m z @ w ! g w @ z ! y @ w ! g w @ y ! x @ dup y @ = swap z @ = or until slow 999 999 beep ;This section of FORTH program is the main control loop for a pacman-type game, which is certainly not obvious from reading it! Forth was not a particularly easy language to learn programming in. |
| Back to Contents |
C- So named because it was derived from a language called B which itself derived from BCPLDevised by Dennis Ritchie in the early 1970s. Always compiled. |
| Back to Contents |
C++- Named after the increment operator in CInspired by a 1960s language called SIMULA which was written for real time simulation uses. (Also derived from SIMULA was Smalltalk, produced by Xerox Parc in the 1970s, which was the first language to use windows and mice.) |
| Back to Contents |
Intercal- Short for Computer Language With No Readily Pronounceable AcronymIntercal was designed on the morning of 26th May 1972 at Princeton University by Donald R Woods and James M Lyon. The only current implementation is C-Intercal, a compiler written in C by Eric S. Raymond.
The format of input data to Intercal is numbers, the digits of which are spelt out in English, and the output is also numbers, printed as Roman numerals. Many academic programming experts believe that the GOTO statement, as used in BASIC, is harmful and leads to 'spaghetti code' which jumps around and is impossible to follow. Intercal avoids this criticism by not using the GOTO command. Instead C-Intercal uses the COME FROM statement. COME FROM specifies a line number from which the program will jump to the COME FROM statement, i.e. the opposite of a GOTO. |
|