A continuación se presenta el
esquema tentativo del Marco Teórico que sustentará la presente investigación.
Primera sección
Antecedentes
Antecedentes
de la investigación.
Antecedentes
de la Investigación dentro de la Organización.
La
organización
Reseña
histórica de la organización
Visión
Misión
Estructura
Organizativa
Segunda sección
Plataforma Informática
Arquitectura genérica
Tercera
sección
Arquitectura de Software
Arquitectura de referencia
básica
Los
Grupos funcionales
Oficina
Correo
Agenda
y trabajo en grupo (Groupware )
Servicios y acceso Web
Administración
de documento (Document
Management)
Base
de datos
Grupos Subsidiarios
Cuarta sección
Sistemas
Operativos
Funciones o Parámetros de Control de Software
Sistema Operativo Linux
Características y estructura de LINUX
Quinta sección
Licencias
de uso de software
Antecedentes
Antecedentes de la
investigación
Los siguientes trabajos de grado y proyectos forman parte de los antecedentes
de la investigación.
En la
Universidad de Nariño – Pasto en Colombia, Facultad de Ciencias Naturales y Matemáticas para el
Programa de Licenciatura en Informática fue presentado el 14 de julio de 1999,
por Pablo Chamorro Constaín su trabajo de grado titulado “Recopilación,
Evaluación y Propuesta de Utilización de Software Libre y Parcialmente Libre,
como Alternativa al Software Propietario, para los Establecimientos de
Educación Básica Secundaria y Media Vocacional de San Juan de Pasto”. Cuyo objetivo
general radica en recopilar, evaluar y presentar una propuesta de utilización
de software libre, de utilidad particular para la comunidad educativa. Sus
objetivos específicos son:
- Explorar
y localizar sitios que ofrecen software libre.
- Establecer
una metodología para la búsqueda y obtención eficiente de software libre.
- Recolectar
software libre y documentación relacionada.
- Conocer
el funcionamiento del software libre obtenido.
- Evaluar
y emitir conceptos del software libre obtenido.
- Elaborar
instructivos básicos de instalación y utilización del software libre
seleccionado.
- Presentar
una propuesta de utilización del software libre, considerando al software
herramienta de trabajo, así como, medio de enseñanza-aprendizaje.
- Organizar
y entregar una copia del software libre y documentación relacionada que se
obtengan.
- Publicar
en Internet el documento resultante del presente trabajo.
Con este trabajo se enfatizó en difundir
la labor de entidades como la Free Software Foundation (FSF) y la de cientos de voluntarios unidos a
través de Internet, que desarrollan y comparten el software libre. Este
documento quizá sea una de los pocos trabajos elaborados en la región, que
abordan el tema del software libre dirigido a la comunidad educativa.
Saúl López Santoyo y
Víctor Manuel Jáquez Leal, dos estudiantes del Instituto Tecnológico de Celaya
en México, del área de Ingeniería en Sistemas Computacionales. Presentaron su
trabajo final el 09 septiembre del 2001 titulado “Desarrollo de
Aplicaciones Web utilizando Software Libre”. Cuyo objetivo general fue
documentar la estructura en el desarrollo de aplicaciones Web utilizando
software libre, más específicamente Perl, Apache y PostgreSQL. La importancia
de este trabajo radica en la determinación de las herramientas que ofrece el
Software Libre para implementar las aplicaciones basadas en tecnologías
Web.
Proyectos y experiencias
en la implementación de Software Libre en el Estado Argentino publicados en www.softwarelibre.gov.ar. Dados los
desarrollos que desde hace tiempo se realizan en forma independiente en
diferentes áreas, y el alcance que el Software Libre va ganando día a día en
herramientas, proyectos, e implementaciones, los responsables de dirigir, administrar y optimizar los
recursos informáticos en Argentina se vieron necesitados de intercambiar conocimientos, experiencias y
proyectos, con el fin de aunar
esfuerzos, reducir tiempos y difundir el trabajo a la sociedad.
Zabre
Borgaro Eric, estudiante del Instituto tecnológico y de estudios superiores de
Monterrey optando al título de Maestro en Ciencias, presentó su trabajo final
en Noviembre de 1988 titulado “Análisis de confiabilidad de software tolerante
a fallas”. Cuyo objetivo general fue hacer una evaluación de modelos de
análisis de confiabilidad de software tolerante a fallas en base a una rigurosa
selección y clasificación de los mismos para finalmente optar por al menos de
los mejores para aplicaciones relevantes que requieran de análisis de
confiabilidad. La importancia de este trabajo se fundamenta en permitir
establecer metodologías para evaluar software.
Antecedente de la Investigación dentro de
la Organización
La
Contraloría General de la República (CGR) ha tenido que ir avanzando en la
implantación de los avances tecnológicos que apoye a las funciones del
organismo. Fue en 1994 cuando se genera el primer plan informático de la
Contraloría General de la República, el cual diagnosticaba la situación en
aquel tiempo con la “[1]Disponibilidad
de hardware, desintegrado e independiente, tanto en el ámbito de micro
computación como del equipo central AS/400 y una red de procesamiento de
palabras orientada a satisfacer primordialmente a una dirección”. Este plan estimaba la sustitución del equipo
central AS/400, modelo B70 (arquitectura cerrada), por un equipo menos
dependiente de las decisiones de los fabricantes y migrar los sistemas a una
plataforma de arquitectura abierta que permita comunicar transparentemente los
datos y aplicaciones, además se estableció como principales objetivos lo
siguiente:
·
Implantar manejadores de base de datos
relacionales estándares con el mercado.
·
Alta disponibilidad de datos y procesos que
aseguren la permanencia de las operaciones críticas durante la caída de los
sistemas, fallas de los equipos y mantenimientos de los mismos.
·
Potencial crecimiento de la Plataforma, que
minimicen los reemplazos de las configuraciones de hardware y software.
·
Garantizar la vigencia de la plataforma
Informática dentro del mercado, así como el soporte técnico adecuado.
Gran parte de estos objetivos se lograron en el transcurso de dos años basados en una plataforma informática que en 1996 era de tecnología de punta, con una red institucional la cual cumplió las siguientes premisas:
Satisfacer
los requerimientos de interconexión de seis redes físicas. [2]
Satisfacer los
posteriores requerimientos de interconexión surgidos con la revisión general de
la estructura y funcionamiento de este organismo contralor.
Estas soluciones se basaron en la instalación de la tecnología implementada en los equipos 3COM por medio de los estándares de sistemas del cableado estructurado de AT&T.
Básicamente
la infraestructura de la red constaba de cuarenta y dos (42) concentradores
FMS-II, Linkbuilder, Stack tack II (tecnología para red ethernet), seis (6)
switchs Lanplex 2500 (tecnología de switching) y un (1) concentrador
Linkbuilder FDDI los cuales están distribuidos en seis (6) redes físicas que se
interconectan por medio de un backbone FDDI.
Para
el año de 1997 se adquiere un gran parque de computadores con un total de
trescientos cincuenta (350) y se implanta un servidor que contendrá la base de
datos de los sistemas mas críticos de la CGR desplazando definitivamente al
sistema AS/400 modelo B-70, modelo para ese entonces ya descontinuado por IBM.
Adicionalmente, contaba con las siguientes licencias de conexión:
Quinientos
cinco (505) licencias del sistema operativo de red Novell Netware versión 3.12.
Cien
(100) licencias del sistema operativo SCO Openserver Enterprise System versión
5.0.2c.
Posteriormente,
los usuarios de la Red fueron conociendo las bondades de la misma y con ello
requiriendo estar interconectados, de la misma manera surgieron necesidades
organizacionales, lo cual implicó el crecimiento sostenido y significativo de
la demanda de equipos (computadores personales e impresoras), aplicaciones y en
consecuencia de puntos de conexión a la red institucional. Para el año 2000, el
parque informático de la (CGR) contaba con:
·
Novecientos diecinueve (919) estaciones de
trabajo.
·
Ciento setenta y tres (173) impresoras (de
las cuales ochenta (80) son de tipo láser con conexión a la red).
·
Quince (15) servidores.
·
Mil cien (1100) puntos de red.
·
Seiscientos veinticinco (625) licencias de
Novell Netware versión 4.11.
El
parque informático anterior, funcionaba sobre la misma infraestructura de Red
instalada en 1995. (ver gráfico N°1.)
Gráfico N°
1
Infraestructura de Red instalada en la CGR en 1995

Fuente:
Plan informático CGR 1994.
Para
el año 2002 se concreta los planes de migración de Novell Netware 4.11 a Novell
Netware 5. Estableciendo cinco (5) servidores, como servidores de producción y
servicios de ofimática. Un servidor de correo bajo el sistema de mensajería de
Novell, Groupwise 5 y adicionalmente tres (3) Servidores bajo el Sistema
Operativo SCO Openserver Enterprise System, los cuales prestan servicio al
manejador de base de datos que en este caso es Oracle 7.
Adicionalmente
en este mismo año 2002 se culminó el proyecto del nuevo esquema de
interconexión de la red de área local de la (CGR), básicamente es una
infraestructura bajo la marca del fabricante CISCO SYSTEMS, la cual consta de
un switch Catalyst 4006, tres (3) switches Catalyst 4003, veintiún (21)
Catalyst 3548, siete (7) Catalyst 3524 y cinco (5) Catalyst 3512.
Esta
tecnología es la base de la infraestructura de los servicios informáticos que
apoyan a la organización en sus funciones.
La organización
La (CGR) es el órgano de control, vigilancia y fiscalización de los ingresos, gastos, bienes públicos y bienes nacionales, así como, de las operaciones relativas a los mismos. Goza de autonomía funcional, administrativa y organizativa, y orienta su actuación a las funciones de inspección de los organismos y entidades sujetas a su control. (Artículo 287 de la Constitución de la República Bolivariana de Venezuela)
Reseña histórica
de la organización
A partir de 1936 se configura un conjunto de iniciativas que dan lugar dos años más tarde al comienzo de las labores del máximo organismo contralor del país. El estudio de las instancias de control fiscal existentes en otros países del continente americano, el encargo de informes técnicos que recomendasen una fórmula contralora ajustada a la realidad venezolana y la elaboración de una novísima Ley Orgánica de la Hacienda Nacional son, entre otros, los primeros pasos que se adelantan en la creación de la Contraloría de la Nación, hoy, Contraloría General de la República.
Es así como en el año 1938 se crea la Contraloría de
la Nación, por la Ley Orgánica de la Hacienda Pública Nacional ostentando el
rango constitucional a partir del año 1947.
Con la promulgación de la Constitución de 1961 se le
denominó Contraloría General de la
República. En el año de 1975 se promulgó la primera Ley Orgánica de
Contraloría y la segunda entró en vigencia el 1° de febrero de 1996.
Visión
Consolidarse
como fuerza y referencia moral de la República e instrumento eficaz de la
sociedad venezolana, en el ejercicio de su derecho a controlar la
Administración Pública, contribuyendo efectivamente a la revitalización y
reordenamiento del poder público, así como, al fortalecimiento del Estado
democrático, social, de derecho y de justicia.
Misión
La
Contraloría General de la República es el organismo constitucionalmente
autónomo, al servicio del estado democrático y de la sociedad venezolana, cuyo
fin primordial es velar por la correcta y transparente administración del
patrimonio público y luchar contra la corrupción.
Estructura
Organizativa
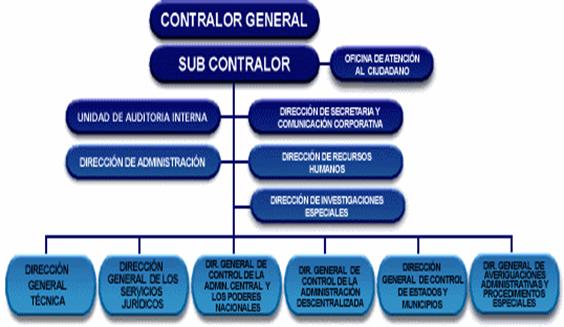
Base
Teórica
Plataforma Informática
La plataforma informática esta conformada por una infraestructura
técnica de sistemas de información y tecnología de información. Entendiendo por
Sistema de Información los componentes interrelacionados que capturan, procesan
almacenan y diseminan información para dar soporte a la toma de decisiones,
control, análisis y visión en una organización y por Tecnología de Información el tratamiento de la información con medios
físicos y software, incluyendo la comunicación de la información de una
localidad a otra. Es dentro de la tecnología de información donde se ubica el
objeto de estudio. La
tecnología de información se desarrolla por los avances tecnológicos en
redes y comunicación, sistemas operativos entre otros.
Las redes
son un conjunto de elementos físicos y lógicos los cuales permiten la
interconexión de equipos para satisfacer las necesidades y requerimientos de
comunicación de datos entre los mismos. Existen varia modalidades de redes, el
presente trabajo de grado se basará en el campo de las redes de área local
(LAN).
Según
Forouzon (2002) señalan que “Una red es un el conjunto de dispositivos (a menudo
denominados nodos) conectados por enlaces de un medio físico. Un nodo puede ser
una computadora, una impresora o cualquier otro dispositivo capaz de enviar y/o
recibir datos generados por otros nodos de la red. Los enlaces conectados con
los dispositivos se denominan a menudo canales de comunicación.” (p. 04)
A principios de los años 70 surgieron las primeras
redes de transmisión de datos destinadas exclusivamente a este propósito, como
respuesta al aumento de la demanda del acceso a redes a través de terminales
para poder satisfacer las necesidades de funcionalidad, flexibilidad y
economía. Se comenzaron a considerar las ventajas de permitir la comunicación
entre computadoras y entre grupos de terminales, ya que dependiendo del grado
de similitud entre computadoras es posible permitir que compartan recursos en
mayor o menor grado.
En la actualidad el uso de las redes se ha
incrementado en un alto nivel a tal punto que forma parte esencial de las
organizaciones, por ella fluyen las informaciones indispensables para el logro
de los objetivos de la empresa, es por ello que la fiabilidad, la seguridad son
los aspectos mas importantes a la hora de realizar el diseño de una red. La
fiabilidad de la red se mide por la frecuencia de fallo, el tiempo que le cuesta
recuperarse del fallo, y la robustez de la red dentro de una catástrofe. Los
aspectos de seguridad de la red incluyen proteger los datos contra accesos no
autorizados y contra virus. Estos dos elementos dependen básicamente de la
arquitectura de software que permite manejar y administrar las redes.
Arquitectura genérica
Una de los modos para
describir la arquitectura del computador es el modelo de tres bloques.
Este modelo separa tres grandes
funciones que una aplicación generalmente realiza cuando es usada por un humano
(esto no se aplica para aplicaciones en batch o aplicaciones que se ejecutan
únicamente en el servidor).
Como demuestra en el
diagrama (ver gráfico N° 2) siguiente:
Gráfico
N° 2
Modelo
de Arquitectura Genérica

Las flechas indican el
paso de la información entre los tres bloques. Este es el flujo ideal del
definido Standard. Significando que solo algunas aplicaciones tiene problemas
acerca de su funcionamiento lógico de negocio apartando las otras dos funciones
que compone el Standard.
Esto trae como
beneficio que el código de la aplicación puede ser simple y puede ser mas
sencillo ejecutarlo en diferentes ambientes por lo que esta dependencia en
acceso especifico de máquinas es reducido.
El modelo de los tres
bloques había sido generalizado para n-bloques, donde los componentes son aun
mas refinados y es típicamente realizado usando objeto o componentes
tecnológicos.
Muchas aplicaciones
cliente servidor en el pasado desafortunadamente solo usaban el segundo bloque
del modelo, donde el código de la aplicación y la interfaz con el usuario son
asociadas conjuntamente. Esto significa que la migración de tales aplicaciones
es a menudo considerada muy dificultosa que con tres bloques únicamente. Esto
es debido a que la interfaz de usuario requiera probablemente cambios y el
segundo bloque.
La interfaz del usuario
probablemente requiera cambios y la aplicación del segundo bloque tenga lo más
probable un código mezclado con la lógica del negocio.
La comunicación entre
la tercera parte de un tercer bloque normalmente las aplicaciones usan
protocolos con lo cual permite que cada parte, si es requerido, ejecutarlo en
diferentes máquinas desde las otras dos. Algunas veces las partes pueden cruzar
de una máquina a otra. La selección de la localización de cada una de estas
partes contribuye al crecimiento para diversas arquitecturas genéricas.
Los extremos desde el punto de
vista del desktop, dónde al menos alguna porción del código de la interfaz del
usuario se debe ejecutar, son:
1. Cliente sencillo:
Este es el caso donde el desktop
solo tiene el código de interfaz de usuario. Típicamente no tiene un
dispositivo de almacenamiento como disco duro o un floppy. El código de la
aplicación y el acceso a los datos son ejecutados remotamente. Ejemplo un X
terminal, un VT100 pantalla verde o un dispositivo con un browser.
2. Cliente robusto
Este es el caso donde todo el
código y los datos son contenidos en el desktop por no tener una conexión a la
red. Los clientes varían entre estos dos extremos sencillo y robusto.
Una variante de estas arquitecturas
es donde el código de la aplicación es almacenado en el servidor y es bajado al
desktop para ejecutarlo cuando lo necesiten. Esta es la manera de trabajo de
los Java applets. Otro método que existe comprende almacenar el código de la
aplicación en un servidor y tener acceso al mismo desde el desktop, dando la
impresión que fue almacenado localmente. Estos métodos requieren el uso de una
conexión a una red con sistema de archivo tal como es el NFS y esto también
significa que todo los desktops deben ser de la misma arquitectura.
La selección de la arquitectura de
una aplicación particular dependerá de:
1. El ancho de banda de la red para los servidores y que ancho
de banda dispondría para la conexión. Si el desktop no es robusto
entonces la red tendría un tráfico aumentado por los controles de la interfaz
del usuario, los datos o las descargas del código de la aplicación. En algunas
circunstancias el tamaño de estas descargas generadas por cualquier desktop
sencillo o un número de añadido de peticiones puede incrementar la capacidad de
la red.
2. La latencia que es aceptable en el uso de la aplicación. Cuando la interfaz del
usuario en el desktop presenta una lentitud en el movimiento del mouse o en las
teclas de la aplicación, generando retardo y efecto de dibujo en la pantalla es
conocido como latencia. Para algunas aplicaciones como una simple entrada de
datos, la latencia alta puede ser aceptable pero para una aplicación interactiva
no lo es.
3. La política de seguridad: Si la
administración de los datos residen en máquinas desktop distribuidos a lo largo
de la red, esto significa que si algunas máquinas es robada o si se encuentran
en un ambiente inseguro donde los datos puedan perderse o divulgarse a terceros
o a personas no autorizados. Esto no podría ser un problema si existen
apropiados respaldo, pero de otra manera esto puede contravenir las políticas
de seguridad de los administradores los cuales les conciernen quienes pueden acceder
los datos. Alternativamente considerando la transmisión de los datos sobre una
red sin criptación. Puede causar el mismo problema.
4. La política de respaldo: Si los
datos residen en máquinas desktop distribuidas es necesario que los
administradores centralizan los respaldos o la responsabilidad de los respaldos
tiene que ser distribuida entre muchas personas, probablemente sea el mismo
usuario. Un esquema de respaldo centralizado podría requerir un mayor ancho de
banda y la cooperación con los usuarios finales.
5. El diseño de la aplicación: si la
aplicación tiene un código incluido en la interfaz del usuario, entonces
necesita ser ejecutado en el desktop o el servidor con el código de la
interfaz. Para instancias, un IBM 3270 o un terminal VT100 tiene todos el
despliegue del código en el desktop, como lo hace un terminal basado en browser
. Citrix, Windows Terminal Server y el X
Windows, todo despliegan el código entre el servidor y el cliente.
6. La capacidad de las máquina desktop para
ejecutar el código: Cuanto más máquinas desktop tenga que
hacerlo, mas poderosa deben ser.
7. La capacidad del desktop para almacenar los
datos: Algunas aplicaciones necesitan acceder enormes cantidades
de datos almacenados, por lo cual solo puede ser ayudados en servidores especializados.
8. El potencial de los servidores disponibles.
Si la aplicación se ejecuta en un servidor en vez de el desktop,
entonces el servidor tiene la suficiente capacidad para correr todas las
instancias requeridas de la aplicación, cuando el número máximo son utilizados,
esto puede significar que el servidor debería tener una gran capacidad de
procesamiento y memoria para manejar el caso de peor condición.
9. El costo total de la implementación. Como es un
problema de ingeniería pretender aplicar la solución en todas las situaciones y
un desktop particular podría operar en una forma una aplicación y otra para una
aplicación diferente.
Arquitectura
de Software
La arquitectura de la mayoría de las computadoras puede ser
considerada como un número de capas de estructura jerárquica. En la base inferior de la jerarquía esta el
hardware de la computadora que incluye algunas instrucciones embebidas en el
Hardware (Firmware). El siguiente nivel
hacia arriba en la jerarquía comprende las funciones centrales o del núcleo. Por encima del núcleo hay diversos procesos
del sistema operativo que dan soporte a los usuarios. Según ISACA (2002):“El
software del sistema es una colección de programas de computo usados en el
diseño, procesamiento y control de todas las aplicaciones de computadora.
Asegura la integridad del sistema, controla el flujo de los programas y de
eventos en la computadora y administra las interfaces con la
computadora.”(p.03)
El software desarrollado para la
computadora debe ser compatible con su sistema operativo. El software de
sistema incluye:
·
Sistema Operativo
·
Software de control de acceso
·
Software de comunicación de datos
·
Software de administración de la
base de datos (DBMS)
·
Software de administración de
bibliotecas de programas
·
Software de administración de
cintas y de discos
·
Facilidades de programación en
línea (ambiente integrado de desarrollo)
·
Software de administración de la
red
·
Software de programación del
trabajo (Job scheduling)
·
Programas utilitarios
·
Middleware
Arquitectura de referencia básica
La arquitectura de referencia básica (ARB) utilizada en este documento
fue elegida de tal forma que sea relevante a la mayor parte de situaciones.
Puede ser extendida en mayor o menor grado de acuerdo a la necesidad especifica
de una aplicación.
En realidad la arquitectura utilizada por la Administración es
probablemente una combinación, de varias arquitecturas cada una elegida para
aplicaciones especificas.
La ARB se puede caracterizar como “stateless desktop” (computador sin
estado) en el que:
1. Todas
las aplicaciones corren en el computador siempre que sea posible y son
almacenadas en el computador.
2. Los
datos persistentes no son almacenados en el computador.
3. Todos
los accesos y autorizaciones son controlados por servidores centrales.
4. La
administración de sistemas es centralizada.
5. El
objetivo es que los computadores son “plug and play” y no requieren soporte
local.
Las aplicaciones se ejecutan localmente para facilitar cualquier
problema de retardo, que pueda presentarse cuando son ejecutadas en forma
centralizada y la ARB asume que existe el suficiente ancho de banda para que
los datos sean manejados de manara centralizada. Además establece la premisa
que todos los computadores serán esencialmente idénticos, permitiéndole a
cualquier persona hacer logon (conectarse) ha alguna máquina sobre la que tiene
el permiso respectivo de uso. Debe existir un sistema de administración con un
conjunto de reglas bien definidas y lo suficientemente fuertes para mantener a
tono la instalación de software en los computadores.
La ARB tiene una configuración y administración central, la cual
simplificará la administración de sistemas, concentrando toda la data
importante en los servidores centrales para un fácil proceso de respaldo
(backup) y administración, e inhabilitando las aplicaciones de clientes
individuales, con el objeto de reducir el impacto de fallas en esas estaciones.
Cuando la data se almacena localmente, significa que hay, de alguna
manera un proceso de identificación de la máquina con el usuario. Esto se convierte
en un problema cuando el usuario cambia de localidad o deja la
organización. Esto ata al lugar de
trabajo del usuario.
Los Grupos funcionales
El modelo referencial es basado en los grupos funcionales, definiendo
los tipos típicos de actividades no especializadas de la computación en una
administración. Esto significa que actividades como la dirección del proyecto o
sistemas de información geográficos no se consideran. Las actividades no
consideradas se deben en general porque el uso de ellas se realiza por sólo una
proporción pequeña de la población de usuarios.
Los grupos funcionales son divididos en Principal y los grupos
Subsidiarios. Los grupos Principales representan funcionalidad que se define en
las condiciones de proceso de negocio. Los grupos Subsidiarios proporcionan el
apoyo los servicios a los grupos Principales y por consiguiente normalmente no
se llevaría a cabo solo.
Oficina
Es la creación, modificación e impresión de archivos que contienen los
datos no estructurados del negocio como son las cartas e informes. También la
creación, modificación e impresión de hojas de cálculo y presentaciones. Debe
haber utilidades para manejar estos archivos. El formato de los archivos por
defecto de Microsoft son los formatos *. doc, *.xls y los *.ppt. En los
formatos abiertos como PDF, ambos deben permitir la creación y modificación de
forma exacta.
Correo
Es la creación, recepción y visualización del correo electrónico
incluso el soporte a la seguridad del correo como S/MIME.
Agenda
y trabajo en grupo (Groupware)
Es la creación y dirección de agendas personales, trabajo en grupo y
libretas de direcciones. Las agendas deben permitir colocar las reuniones y el
registro de la actividades con sus responsadles con el seguimiento de las
actividades.
Servicios y acceso Web
Esta es la habilidad para acceder los servicio de Internet. Esto se
realiza normalmente con un navegador. Además la habilidad de crear contenidos
de información y hacerlo disponible tanto internamente y externamente.
Administración de documento (Document Management)
Es el almacenamiento centralizado de documentos con efectivos
mecanismos de recuperación.
Base de datos
Es una colección almacenada de datos relacionados que necesitan las
organizaciones y las personas para satisfacer sus requerimientos de
procesamientos y recuperación de información, permite la manipulación de datos
estructurados personales y bases de datos centrales. Los sistemas de
administración de base de datos son sistemas que dan asistencia para organizar,
controlar y usar los datos que necesitan los programas de aplicación, provee la
facilidad de crear y de mantener una base de datos bien organizada.
Grupos Subsidiarios
Estos grupos son generalmente definidos por los servicios técnicos y no
son por la implementación de estos. Entre ellos se encuentran:
Sistema operativo
Servidor de archivos
Administración de usuarios,
autentificación y autorización
Detección de virus y correo basura
(spam)
Respaldo y recuperación
Administración de impresoras
Sistemas Operativos
El
sistema operativo, el componente más importante de la categoría de software de
sistemas, contiene programas que intercomunican entre el usuario, el programa y
el software de aplicaciones. Permite compartir y usar los recursos de la computadora
tales como los procesadores, la memoria real, la memoria auxiliar y los
dispositivos de entrada / salida. Según Milenkovic (1998) “Un sistema operativo
puede ser contemplado como una colección organizada de extensiones software del
hardware, consistente en rutinas de control que hacen funcionar un computador y
proporcionar un entorno para la ejecución de los programas” (p.03).
Las
funciones que ofrece un sistema operativo incluye desde definir las interfaces
del usuario; permitir que los usuarios compartan el hardware; permitir que los
usuarios compartan datos; programa los recursos entre los usuarios; informar a
los usuarios sobre cualquier error que ocurra con el procesador, con los
dispositivos de I/O o con los programas; recuperación de los errores del
sistema; comunicaciones entre el sistema operativo y los programas de
aplicación, asignando memoria a los procesadores y poniendo memoria a
disposición al terminarse un procesos; administración de archivo de sistema y
administración de contabilidad de sistema.
Uno de los
roles de los sistemas operativos es administrar los recursos y el procesamiento
de la computadora. Los recursos incluyen:
·
Dispositivos de entrada y salida–impresoras, unidades de
discos, teclados, unidades de cintas, CD-ROMs, scanners, pantallas terminales,
etc.
·
Memoria el almacenamiento interno conectado directamente a
la CPU y/o a una parte de la CPU
·
Tiempo de CPU el tiempo disponible para el procesamiento de
instrucciones en la CPU
·
Redes los canales de comunicación que conectan los
dispositivos de entrada / salida con los
procesadores de computadora
Estos
requerimientos operativos básicos son expandidos mas por la mayoría de los
sistemas operativos para incluir facilidades para asistir en la operación de la
computadora y para desarrollar los sistemas de aplicación. Por ejemplo, todos
los sistemas operativos modernos pueden establecer una capacidad virtual de
memoria de almacenamiento que permite a los programas dar como referencia
direcciones que no necesitan corresponder al conjunto limitado de direcciones
en memoria.
Los sistemas operativos varían en los recursos administrados, la comprensión de la administración y de las técnicas usadas para administrar los recursos. El tipo de computadora, el uso que se pretende darle, y los dispositivos y las redes que se espera que se encuentren conectados influyen en los requerimientos, las características y la complejidad del sistema operativo. Por ejemplo, un solo usuario que opera una microcomputadora que trabaja independientemente, o stand-alone, necesita un sistema operativo capaz de catalogar archivos y de cargar programas para ser efectiva.
Por lo contrario en el caso de un ambiente de red es necesario contar con el sistema operativo que gestione los recursos del mismo y que ofrezca un soporte para la programación de aplicaciones distribuidas, los sistemas operativos: de red, provee un conjunto de funciones para controlar y mantener la red. Provee información detallada sobre la situación de todos los componentes en la red tales como la situación de la línea, la terminal activa, la longitud de las colas de mensajes, la tasa de errores en una línea y el tráfico en una línea. Permite a las computadoras compartir información y recursos dentro de una red y provee fiabilidad a la red. También suministra al operador una señal de advertencia temprana de problemas de red antes de que las mismas afecten la fiabilidad de la red, permitiendo que el operador emprenda las acciones preventivas o correctivas oportunamente.
Funciones
o Parámetros de Control de Software
Diferentes productos de software de sistema operativo proveen parámetros y opciones para el ajuste del sistema a la medida y para la activación de funciones tales como registro de actividad. Los parámetros son importantes para determinar como un sistema funciona permitiendo que una parte estándar de software sea adaptada a diferentes ambientes.
Los
parámetros de control de software tienen
que ver con:
· Administración de datos
· Administración de
recursos
· Administración de
trabajos
· Determinación de
prioridades
Las
selecciones de parámetros deben ser las adecuadas para la carga de trabajo y la
estructura de control del ambiente de la organización. El medio más efectivo de determinar como
están funcionando los controles dentro de un sistema operativo es revisar las
funciones y/o los parámetros de control del software.
El código de programa del sistema operativo puede ser almacenado en diferentes tipos de Memorias de lectura solamente (ROMs sigla de los términos en ingles) y almacenamiento de control de muy alta velocidad, llamado firmware, en lugar de ser cargado y ejecutado en la memoria principal de la computadora. El almacenamiento de software provee una mayor velocidad de procesamiento para las funciones usadas con frecuencia así como también la capacidad de ser cambiado con mas facilidad que los circuitos de computadora diseñados especialmente para las misma.
La implementación y/o el monitoreo indebido de los sistemas operativo puede tener como consecuencia errores no detectados y corrupción de los datos que estén siendo procesados, así como también puede conducir a un acceso no autorizado y al registro incorrecto de uso del sistema.
Sistema Operativo Linux
El origen de Linux se encuentra en el sistema operativo MINIX, que fue desarrollado por Andrew S. Tanenbaum con el objetivo de que sirviera de apoyo para la enseñanza de sistemas operativos. De hecho, Tanenbaum (1987) señala que, “se utilizaba este sistema operativo para explicar los diferentes conceptos de esta materia, incluyéndose además en un apéndice un listado completo de su código escrito en lenguaje C”.
Además de por su carácter pedagógico, MINIX se caracterizaba por tener una estructura basada en un microkernel. El autor intentaba demostrar al crear MINIX que se podía construir un sistema operativo más sencillo y fiable, pero a la vez eficiente, usando este tipo de organización que era novedosa en aquel momento. Algunas otras características positivas de MINIX eran las siguientes:
Ofrecía una interfaz basada en la de UNIX versión 7.0 el grupo de trabajo de POSIX todavía no había terminado su labor en esa época tenía un tamaño relativamente pequeño, constaba de aproximadamente 12.000 líneas de código.
Podía trabajar en equipos que disponían de unos recursos hardware muy limitados, de hecho, incluso podía usarse en máquinas que no disponían de disco duro.
Sin embargo, también presentaba algunas deficiencias y limitaciones. La gestión de memoria era muy primitiva. No había ni memoria virtual ni intercambio, además no se aprovechaba adecuadamente el mecanismo de paginación del procesador, el autor justificaba esta limitación argumentando que la inclusión de estos mecanismos complicaría considerablemente el código del sistema operativo. Aunque esta opción es razonable desde el punto de vista pedagógico, tenía como consecuencia que MINIX no se utilizará como un sistema para el desarrollo de aplicaciones de cierta entidad.
Por simplicidad, algunas partes del sistema operativo, como ejemplo el sistema de archivos, no eran concurrentes, lo que limitaba considerablemente el rendimiento del sistema.
A pesar de estos defectos, MINIX atrajo la atención de muchos usuarios de todo el mundo que usaban el grupo de noticias como un punto de encuentro. Algunos de estos usuarios se ofrecían a mejorar partes del sistema o a incluir nuevas funciones al mismo. Sin embargo, el autor siempre fue bastante reacio a estas ofertas. Entre los interesados en MINIX se encontraba un estudiante finlandés llamado Linus Tovards. Fue el año 1990 cuando este estudiante envió un mensaje a este grupo de noticias comentando que por curiosidad y ganas de ampliar sus conocimientos estaba desarrollando un nuevo sistema operativo tomando como base MINIX. Se estaba produciendo el humilde nacimiento de LINUX, cuya primera versión (numerada 0.01) vio la luz a mediados del año 1991.
Es importante recalcar que en su concepción inicial, Linux tomaba prestadas numerosas características de MINIX (por ejemplo el sistema de archivos). De hecho LINUX se desarrolló usando como plataforma de trabajo MINIX y las primeras versiones de LINUX no eran autónomas sino que tenían que arrancarse desde MINIX.
Sin embargo, a pesar de esta herencia inicial, MINIX y LINUX son radicalmente diferentes, por un lado LINUX solventa muchas de las deficiencias de MINIX como por ejemplo la carencia de memoria virtual. Estas mejoras permiten que se trate de un sistema adecuado para trabajar de manera profesional, no limitándose su uso a un entorno académico. Pero la diferencia más importante entre ellos está en su organización interna. Mientras que MINIX tiene una estructura moderna basada en micro kernel, LINUX posee una estructura monolítica más clásica. Este diseño conservador tuvo como consecuencia que el autor de MINIX no diera el visto bueno a LINUX ya que consideraba que este sistema suponía un paso atrás en la evolución de los sistemas operativos.
Desde su lanzamiento público en 1991, LINUX ha ido evolucionando e incorporando nuevas características, además se ha transportado a otros procesadores como SPARC, Alpha y MIPS. En la actualidad es un sistema con unas características y prestaciones comparables a las de cualquier sistema operativo comercial.
Para numerar las sucesivas versiones del sistema, se usas un número primario y una secundaria separados por un punto, por ejemplo versión 2.2. Un incremento en el número primario corresponde con una nueva versión que incluye cambios significativos en el sistema. En caso de una modificación de menor impacto solo se modifica el número de versión secundario. Además un número secundario de versión que sea impar como por ejemplo 2.1 indica que se trata de una versión inestable en la que se ha incluido nuevas características que todavía hay que probar y depurar. Evidentemente un usuario normal debería instalarse un versión con un número secundario par.
Características
y estructura de LINUX
Linux es un sistema de tipo UNIX y por tanto posee las características típicas de los sistemas UNIX. Se trata de un sistema multiusuario y multitarea de propósito general. Según Carretero (2001) señala que “algunas de sus características específicas más relevantes son las siguientes:
·
Proporciona una interfaz POSIX
·
Tiene un código independiente del procesador en la medida de
lo posible. Aunque inicialmente se
desarrolló para procesadores Intel, se ha transportado a otras arquitecturas
con un esfuerzo relativamente pequeño.
· Puede adaptarse a
máquinas de muy diversas características. Como el desarrollo inicial se realizó
en máquinas con recursos limitados, ha resultado un sistema que puede trabajar
en máquinas con prestaciones muy diferentes.
· Permite incluir de forma
dinámica nuevas funcionalidades al núcleo del sistema operativo gracias al
mecanismo de módulos.
· Proporciona soporte para
una extensa variedad de sistemas de archivos, entre los cuales se encuentran
los utilizados por Windows. También es capaz de manejar distintos formatos de
archivos ejecutables. Brindando una excelente ventaja para reutilizar los
archivos existentes.
En cuanto a la estructura de LINUX, el núcleo no es algo estático y cerrado sino que se puede añadir y quitar módulos de código en tiempo de ejecución. Se trata de un mecanismo similar al de las bibliotecas dinámicas pero aplicado al propio sistema operativo. Se pueden añadir módulos que correspondan con nuevos tipos de sistemas de archivos, nuevos manejadores de dispositivos o gestores de nuevos formatos de ejecutables.
Un sistema LINUX completo no sólo está formado por el núcleo sino también incluye programas del sistema (por ejemplo demonios) y bibliotecas del sistema.
Debido a las dificultades que hay para instalar y configurar el sistema existen diversas distribuciones de Linux que incluyen el núcleo, los programas y bibliotecas del sistema, así como un conjunto de herramientas de instalación y configuración que facilitan considerablemente esta ardua labor. Hay distribuciones tanto de carácter comercial como gratuita. Algunas de las distribuciones más populares son:
·
MandrakeSoft fue creado en 1998 con el propósito de hacer
Linux más fácil de usar para cualquiera. Nació como una distribución basada en
RedHat, añadiendo algunas características que no estaban integradas, como el
entorno gráfico KDE y un instalador gráfico
simple y sencillo de usar. Mandrake es ideal para usuarios nuevos que no desean
involucrarse con profundos conocimientos técnicos, debido a su facilidad de
uso.
·
RedHat es la distribución más conocida y usada en el mundo,
la compañía fue fundada en 1994 y además de dedicarse a la producción de la distribución
ofrece otros servicios como lo son la Red Hat
Network o las certificaciones como RHCE (Red Hat Certified
Engineer). Es por esto que Red Hat es ampliamente aceptada en la industria
de la tecnología informática (TI).
·
LGIS GNU/Linux 9 es una versión modificada de RedHat 9 (Shrike).
LGIS GNU/Linux 9 es una distribución orgullosamente mexicana la cual surge de
la necesidad de contar con la última versión de la distribución más utilizada a
nivel mundial, con todas sus actualizaciones, además de la inclusión del
Escritorio Ximian Desktop 2
(XD2) con todos los productos libres (Evolution, RedCarpet, etc.) lo que
permite entre otras cosas mantener el sistema actualizado al 100% y manipular
toda la información personal con la mejor herramienta para ello (Evolution),
además, la versión Ximianizada de
OppenOffice.org la Suite de Oficina libre que está reemplazando a sus
contrapartes propietarias.
·
Linux PPP (Proyecto Personal de Pepe) es junto con LGIS Linux de las únicas
distribuciónes mexicanas. Fué una de las distribuciones de Linux más utilizadas
en México y la única con influencia en toda Latinoamérica y España. Actualmente
se encuentra en estado de desarrollo puesto que su última versión fue LinuxPPP
6.4 (basada en Redhat
6.2).
·
Knoppix
es una distribución basada en Debian que tiene una característica muy especial,
la cual es que se ejecuta directamente del CD sin necesidad de instalarlo en el
disco duro. Puede ser usado como una herramienta de recuperación o bien para observar
a Linux antes de instalarlo.
·
Gentoo Linux es una distribución de reciente creación basada
en código fuente, es decir provee, en conjunto con su sistema de paquetes, una
jerarquía de instrucciones que automatiza la descarga, compilación,
actualización y empaquetado de software en tu máquina. Esto te permite
optimizar, configurar y mantener al día tu computadora, a tu
manera y sin restricciones con las últimas versiones de software. Esta
distribución es ideal tanto para novatos que deseen conocer su sistema Linux a
fondo como administradores de red, programadores y usuarios de Slackware o Linux from Scratch.
·
Debian El proyecto Debian nació en 1993 como una
organización de individuos que tienen como causa común crear un sistema
operativo 100% libre. Debian Linux es una distribución completamente libre
alejada de todo tipo de asociación comercial y software propietario. Su
desarrollo por parte de programadores de todo el mundo es uno de los más
grandes llevados a acabo por la comunidad de software libre. Más allá del
aspecto técnico Debian es acerca de libertad.
·
Slackware fue la primera distribución de Linux como las
conocemos hoy en día. Su filosofía es mantener absolutamente todo sencillo (KISS)
tomando muchas ideas de los UNIX originales, tales como el sistema de arranque.
Muchos usuarios prefieren Slackware precisamente por esa sencillez, la
instalación es basada en texto y es tan sencilla que un columnista de la Linux Journal Magazine comentó que
podría completar una instalación de Slackware sin un monitor conectado a la
computadora. Parte de esta sencillez es la carencia de sistemas automatizados
de configuración, sin embargo incluye un sencillo sistema de paquetes.
Excelente como puente entre Linux y sistemas BSD
tanto para usuarios avanzados como para novatos.
·
SuSE se
enfoca al mercado de los escritorios, y es famoso por ser muy fácil de instalar
y por su herramienta de configuración llamada YaST. El desarrollo de SuSE es un
tanto cerrado ya que no proveen versiones beta de su distribución y además no
colocan imágenes ISO para descargar la distribución desde Internet.
·
Lycoris Desktop/LX Destkop/LX es un sistema operativo basado
en Linux hecho por la compañía Lycoris la cual proclama ser el proveedor líder
de Linux específicamente orientado al mercado del escritorio. Junto con #Lindows ha sido una de las
distribuciones que han sido preinstaladas en computadoras vendidas en WallMart.
·
Lindows
es una distribución dirigida al consumidor, con un look and feel al de Microsoft® Windows XP® o Apple® MacOS X®, lo
cual incluye soporte para ejecutar aplicaciones de Microsoft® Windows® como
Microsoft® Office®. Esta distribución no es de libre acceso, pues un costo por
licencia.
·
Xandros
es una distribución canadiense basada en Corel® Linux que se enfoca en crear
una solución de escritorio que combina lo mejor de las tecnologías de código
abierto con una atención corporativa hacia el soporte y usabilidad, así como
compatibilidad con software de Microsoft® Windows®.
·
Linux
From Scratch (LFS) es un proyecto que consiste en proveer los pasos necesarios
para construir desde cero tu propia distribución. Una de las mejores maneras de
conocer como funciona un sistema Linux por dentro, así como conocer la relación
entre los componentes del sistema.
Licencias de uso de software
El software
se rige por licencias de utilización, es decir, en ningún momento un usuario
compra un programa o se convierte en el propietario de éste, tan solo adquiere
el derecho de uso, incluso así haya pagado por éste. Las condiciones bajo las cuales se permite el
uso del software, es decir las licencias, son contratos suscritos entre los
productores de software de los usuarios. En general, las licencias corresponden
a derechos que se conceden a los usuarios, principalmente en el caso del
software libre y a restricciones de uso para el caso del software
propietario. Las licencias son de gran
importancia tanto para el software propietario como para el software libre,
igual que cualquier contrato.
Un caso
especial en lo que concierne a la propiedad sobre el software, lo constituyen
los programas denominados de dominio público porque sus creadores renuncian a
los derechos de autor.
Si bien cada
programa viene acompañado de una licencia de uso particular, existen diversos
aspectos en común entre las licencias que hacen posible su clasificación. De
acuerdo a ello es común encontrar términos tales como; software shareware,
freeware, de dominio público o de demostración, a estos se les agrega software
libre o de código abierto, propietario, así como, software semi-libre.
En términos
generales el software propietario es software cerrado, donde el dueño del
software controla su desarrollo y no divulga sus especificaciones, es producido
principalmente por las grandes empresas, tales como, Microsoft y muchas otras,
antes de poder utilizar este tipo de software se debe pagar por el, cuando se
adquiere una licencia de uso de software propietario, normalmente se tiene
derecho a utilizarlo en un solo computador y a realizar una copia de respaldo.
En este caso la redistribución o copia para otros propósitos no es permitida.
El software
tipo shareware es un tipo particular de software propietario, sin embargo, por
la diferencia en su forma de distribución y por los efectos que su uso
ocasiona, puede considerarse como una clase aparte. Se caracteriza porque es de
libre distribución o copia, de tal forma que se puede usar, contando con el
permiso del autor durante un período limitado de tiempo, después de esto se
debe pagar para continuar utilizándolo, aunque la obligación es únicamente de
tipo moral ya que los autores entregan los programas confiando en la honestidad
de los usuarios. Este tipo de software
es distribuido por autores individuales y pequeñas empresas que quieren dar a
conocer sus productos.
No hay que
confundir el software shareware con el software de demostración, que son
programas que de entrada no son 100% funcionales o dejan de trabajar al cabo de
cierto tiempo. También estos programas
son los que se consiguen en los quioscos o revistas, el software de
demostración o como se acostumbra a decir “software demo” es similar al
software shareware por la forma en que se distribuye pero en esencia es sólo
software propietario limitado que se distribuye con fines netamente
comerciales.
El software
libre es software que para cualquier propósito se puede usar, copiar,
distribuir y modificar libremente, es decir, es software que incluye archivos
fuentes. La denominación de software libre se debe a la Free Software
Foundation (FSF), entidad que promueve el uso y desarrollo de software de este
tipo. Cuando la FSF habla de software libre se refiere a una nueva filosofía
respecto al software, donde priman aspectos como especificaciones abiertas y
bien comunes, sobre software cerrado y ánimo de lucro.
El software
de dominio público (public domain software), es software libre que tiene como
particularidad la ausencia de copyright, es decir, es software libre sin
derechos de autor, en este caso los autores renuncian a todos los derechos que
les puedan corresponder.
El software
semi-libre es software que posee las libertades del software libre, pero sólo
se puede usar para fines sin ánimo de lucro por lo cual cataloga como software
no libre.
El software
freeware es software que se puede usar, copiar y distribuir libremente pero que
no incluye archivos fuentes, no es software libre, aunque tampoco lo califica
como semi-libre o propietario, se asemeja más al software libre porque no se
debe pagar para adquirirlo o usarlo.
El término
software de “fuente abierta” o “código abierto” es usado por algunas personas
para dar a entender más o menos lo mismo que software libre, sin embargo, hay
leves diferencias, he aquí la principal clave para diferenciar el software
libre del software de código abierto, éste último presupone la intervención de
una comunidad y el mejoramiento de la aplicación por medio de la colaboración.
Variables de estudio
Software
propietario, instalado en la plataforma de la Contraloría General de la República
(CGR).
Software
libre.
Cuadro N° 1
Operacionalización
de las Variables
|
Variable |
Dimensiones |
Indicadores |
Nivel
de Medición |
||
|
Software
propietario, instalado en la plataforma de la (CGR) |
Confiabilidad |
Cumplimiento
de los requerimientos y de los resultados reales. |
10 |
||
|
Escalabilidad |
Crecer sin
degradar parámetros del rendimiento global. |
10 |
|||
|
Estabilidad |
Capacidad
de recobrar una condición de equilibrio a causa de una perturbación o cambio
inesperado. |
10 |
|||
|
Adaptabilidad |
Ajustarse
a los cambios y actualizaciones |
10 |
|||
|
Variable |
Dimensiones |
Indicadores |
Nivel de Medición |
||
|
|
Necesidades y especificaciones del hardware |
Capacidad
de utilizar el hardware existente en la (CGR) |
10 |
||
|
Software
libre |
Seguridad |
Capacidad
de disminuir riesgos y vulnerabilidad |
10 |
||
|
Obsolescencia |
Tiempo vida útil |
10 |
|||
|
Compatibilidad con los sistemas existentes |
Impacto sobre los sistemas existentes. |
10 |
|||
|
Exigencias
al personal existente |
Grado de entrenamiento del personal para
incrementar la habilidad técnica |
10 |
|||
|
Impacto
sobre el desempeño de la red |
Rendimiento del sistema |
10 |
|||
|
Complejidad
en la implementación |
Grado de
complejidad en los procesos de instalación e implementación |
10 |
|||
|
|
Costos/
Beneficios |
Comparación de la inversión contra
beneficios |
10 |
||
Nivel de medición: 10 valor máximo.
0 valor mínimo.
Definición de Términos Básicos
Basado en la investigación se puede
construir la base teórica de nuestro Problema Objeto de Estudio de la siguiente
manera:
Cliente/Servidor: Modelo lógico de una forma de proceso cooperativo,
independiente de plataformas hardware y sistemas operativos. El concepto se
refiere más a una filosofía que a un conjunto determinado de productos, el
modelo se refiere a un puesto de trabajo o cliente que accede mediante una
combinación de hardware y software a los recursos situados en un ordenador
denominado servidor.
Código Ejecutable: Es el código del
lenguaje de máquina al que generalmente se hace referencia como el módulo de
objeto o de carga.
Código Fuente: Es el lenguaje en el
cual se escribe un programa. El código fuente se traduce al código objeto por
medio de ensambladores y de compiladores.
En algunos casos e código fuente puede ser automáticamente convertido en
otro lenguaje por medio de un programa de conversión. El código fuente no puede
ser ejecutado por la computadora directamente, debe primero ser convertido en
lenguaje de máquina.
Código Objeto: Las instrucciones
legibles de máquina producidas desde un programa compilador o emsamblador que
ha aceptado y traducido el código fuente.
Firmware: Son los chips de memoria
de código integrado de programa que retiene su contenido cuando se apaga. Parte del software de un ordenador que no puede
modificarse por encontrarse en la ROM o memoria de sólo lectura, «Read Only
Memory». Es una mezcla o híbrido entre
el hardware y el software, es decir tiene parte física y una parte de
programación consistente en programas internos implementados en memorias no
volátiles, Un ejemplo típico de Firmware lo constituye la BIOS.
Firma Digital: Datos cifrados de tal manera que el receptor pueda comprobar
la identidad del transmisor.
Freeware: Software de distribución gratuita. Programas que se
distribuyen a través de Internet de forma gratuita.
Hardware: Se relaciona con las
funciones técnicas y físicas de la computadora.
GNU: Es
un acrónimo recursivo para "Gnu no es Unix" comenzó en 1984 para
desarrollar un sistema operativo tipo Unix completo, que fuera Software Libre.
Las variantes del sistema operativo GNU, que utilizan el kernel Linux, son muy
utilizadas.
Hurd (Hird of Unix-Replacing Daemons) GNU es un reemplazo del
kernel Unix por parte del proyecto GNU. El Hurd está constituido por una
colección de servers que corren en un micro-kernel Mach para implementar
sistemas de archivos, protocolos de red, control de acceso a archivos, y otras
características que implementa el kernel Unix o similar (como Linux).
Instrucciones de
ejecución:
Son las instrucciones de operación de computadora que detallan los procesos
paso por paso que deben ocurrir para que un sistema de aplicación pueda ser
ejecutado debidamente. También identifica cómo tratar los problemas que surgen
en el curso del procesamiento.
Lenguaje de máquina: Es el lenguaje lógico
que entiende una computadora.
Middleware: Es otro término para
una interfaz de programados de aplicaciones (PI siglas de términos en inglés),
se refiere a las interfaces que permiten a los programadores tener acceso a los
servicios de nivel inferior y superior suministrando una capa intermedia que
incluye llamada de función de los servicios.
Migración: Traslado de una aplicación de un ordenador a otro en
condiciones de compatibilidad. Migrar es también elevar una versión de un
producto software a otra de más alto nivel, o bien el movimiento de una
arquitectura a otra, por ejemplo, de un sistema centralizado a otro con una
estructura basada en el modelo cliente/servidor.
Novell: Es
una de firma en el ámbito de las redes de área local en todo el mundo. La firma
es de origen norteamericano y su producto estrella es Netware.
Programas de Producción: Son usados para
procesar datos en vivo o reales que fueron recibidos como entrada en el
ambiente de producción.
Programas de Utilería: Es un software
especializado de sistema usado para ejecutar funciones computarizadas y rutinas
particulares que se requieren con frecuencia en el curso normal del
procesamiento. Los ejemplos incluyen
selección copias de seguridad y eliminación de datos.
SCO: (Santa
Cruz Operation). Se trata de una firma norteamericana especializada en sistemas
Unix.
Servidor:
Computadora
conectada a una red que pone sus recursos a disposición del resto de los
integrantes de la red. Suele utilizarse para mantener datos centralizados o
para gestionar recursos compartidos. Internet es en último término un conjunto
de servidores que proporcionan servicios de transferencia de ficheros, correo
electrónico o páginas WEB, entre otros.
Shareware: Las versiones de programas que reciben esta denominación
permiten probar sus capacidades sin realizar el desembolso mucho mayor que
representaría comprar el programa convencional completo.
Sistema de
Administración de datos (DBMS siglas de términos en inglés): es un conjunto complejo
de programas de software que controlan la organización, almacenamiento y recuperación
de datos en una base de datos, también controla la seguridad y la integridad de
la base de datos.
Sistema Abierto: Tal vez la mejor forma de definir los sistemas abiertos sea
por oposición al término «Sistemas Propietarios». De entre las varias definiciones
posibles, puede adaptarse ésta que se basa en la del ISO Joint Technical
Commitee: los sistemas abiertos son conjuntos de interfaces, servicios y
formatos de soporte, así como especificaciones, normas, etc., relacionadas con
la capacidad operativa de los usuarios, que permiten la interoperabilidad y la
portabilidad de aplicaciones, y datos, así como el establecimiento de criterios
de operación comunes para dichos usuarios, según se concreta en los estándares,
en cuya definición participan tanto los fabricantes como los repetidos usuarios
a través de organismos y comités internacionales creados al efecto. Son
característicos los trabajos de la UI o de la OSF.
Sistema Operativo: Es un programa de
control principal que opera la computadora y que actúa como un creador de
cronogramas y controlador de tráfico. Es el primer programa copiado a la
memoria de la computadora después de que la computadora es encendida y debe
residir en la memoria todo el tiempo. Fija las normas para los programas de
aplicación que se ejecutan en la misma.
Sistema Propietario: En informática se denomina así a un tipo de software o a una
plataforma hardware, o a ambos, que es propio de un fabricante concreto; es un
concepto opuesto al de «abierto» en el caso del software. Es decir, la
característica fundamental de los sistemas propietarios es su falta de
compatibilidad con arquitecturas de otros fabricantes.
Software: Son los programas y la
documentación que los soporta que permiten y que facilitan el uso de la
computadora. El software controla la operación del hardware.
Spam: es una palabra inglesa que hace referencia a una conserva
cárnica: el "Spiced Ham", literalmente "Jamón con
especias". Al no necesitar refrigeración, fue muy utilizada en todo el
mundo, sobre todo por el ejército americano, que ayudó mucho en su difusión.
Debido a esto (y a su baja calidad) se ha utilizado este termino para hacer
referencia a todos los mensajes basura que se reciben tanto en los grupos de
noticias como en los buzones particulares.
Unidad Central de
procesamiento (CPU siglas de términos en inglés): es un hardware de computadora que
aloja los circuitos electrónicos que controlan / dirigen todas las operaciones
en el sistema de computadora.