The JPEG Image Compression Decompression Algorithm
Omar Bashir
Abstract
Introduction
Digital Image Processing
Merits and De-merits of Processing Images Digitally
Stages in Digital Image Processing
Representation of a Digital Image
Colour Images
Image Compression
The JPEG Image Compression Decompression Algorithm
Stages in JPEG Image Compression and Decompression
Discrete Cosine Transform
Quantisation
Runlength Length Encoding
Entropy Encoding
Interchange Format
Compressing Colour Images
Image Quality Issues for JPEG Images
Summary
Bibliography
Abstract
Digitised images contain significant amount of data, which depend upon the resolution of the images as well as the potential applications for which these images have been acquired. Images, therefore, need to be compressed so that they may be efficiently communicated and archived. For certain applications, which can tolerate small differences in pixel values between the original (uncompressed) and reconstructed (decompressed) images, this compression may be inexact or lossy, thereby achieving higher compression ratios. Thus the reconstructed image is actually an approximation of the original image. The JPEG (Joint Photographic Experts Group) image compression mechanism is a lossy compression standard which is used widely for compressing full colour or gray-scale (monochrome) images of natural, real world scenes.
1.0 Introduction
Application of digital technology to the transmission, recording and processing of images is relatively recent and has, in a short time, revolutionised many aspects of image processing. For some applications, the digital mode has replaced the analog technology as it can perform functions that are difficult or impossible to accomplish in the conventional analog format.
Conventional analog signals are electrical analogues of scene brightness. They vary continuously and are described as having an analog format. At the receiver the eye responds to the continuous variations in luminous intensity generated by the analog displays. Video signals, therefore, are inherently analog, both when generated and when displayed. Between these end points there is an option of converting these signals in digital format.
Digitised images are represented as strings of numbers from which the original image can be reconstructed without visible degradation. However, the amount of data generated during the digitisation process is extremely high and compression of these data is important for increased channel capacity and reduced storage. In video applications, standard broadcast television requires 100 – 200 Mbps, while for low resolution applications, such as teleconferencing, remote surveillance etc., the data rate can be reduced to a few tens of kilobits by reducing the frame rate and the word size. Further compression may be achieved by applying image compression techniques at the source. This allows an optimal utilisation of the communication bandwidth. These compressed images are decompressed at the destination for viewing and analysis.
This lecture describes the JPEG image compression decompression algorithm. This algorithm is used widely to compress monochrome and colour images of real world scenes. The next section introduces basic concepts of digital image processing in detail. Image compression is then discussed in general before describing the JPEG image compression decompression algorithm in detail. The lecture is concluded after discussing the image quality issues for JPEG images.
2.0 Digital Image Processing
Image processing techniques consist of low level procedures that are used to acquire, store, manipulate and display images in a computer system. These procedures are different from those used in high level image understanding, where the algorithms attempt to imitate human cognition and make decisions according to the information contained in the image.
This section describes some of the basic concepts of digital image processing.
2.1 Merits and De-merits of Processing Images Digitally
Use of digital video signals may represent some significant advantages as well as disadvantages when compared with analog video signals. Some of these are described below.
- Digital signals inherently require more bandwidth. For example, 198.375 Mbps are required to transfer colour image frames of 575 lines, with each line containing 575 pixels, at a rate of 25 frames per second when 8 bits (256 quantisation levels) are used to represent each colour in a pixel.
(b) Digital signals are relatively invulnerable to the introduction of noise in transmission. Noise power is additive in analog systems and systems’ signal to noise ratio is the sum of the noise contribution from each stage. With the digital format, noise causes bit errors. With higher number of bits in error, the signal is lost altogether, whereas the signal to noise ratio in analog systems suffers a graceful degradation. The quality of signal in the latter gets steadily worse, although it remains useful as noise is added.
(c) Digital signals are relatively immune to distortions caused by the non-linear transfer functions of the transmission circuits.
(d) A digital image results from sampling in the vertical dimension by the scanning lines and in the horizontal dimension by the sampling intervals. Thus a digital signal has the potential for aliasing both horizontally and vertically.
(e) Digital format has the capability of performing signal conversion and processing functions that would be difficult or impossible to perform with analog signals. Some important signal processing functions that can be performed on digital signals are image enhancement, digital filtering, post-production editing and bandwidth reduction.
2.2 Stages in Digital Image Processing
Digital image processing may be divided into a number of stages, starting from image acquisition at the source of the image to its display to the user. Between these steps, images may be
- processed to improve their quality or to reduce their size,
- stored for subsequent use, and
- communicated to other components of the image processing system.
These stages are represented in figure – 1.
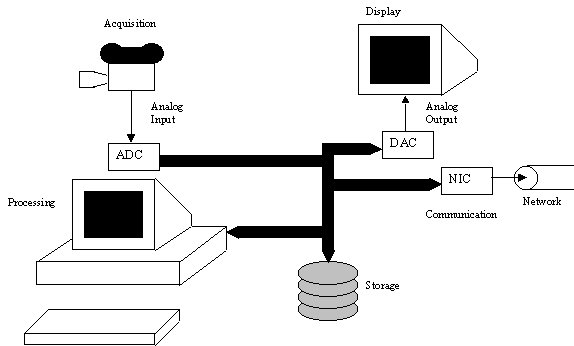
Figure – 1 : Stages in Digital Image Processing
Image acquisition is performed by an image sensor, which is expected to scan the entire image at a rate high enough to make it suitable for subsequent viewing by humans. Image acquisition is generally performed by a camera. These are inherently analog devices, i.e., their output is one or more analog signals. The camera scans the image by making a number of nearly horizontal passes across the image. With each pass across the image, the light reflected by the image is converted to an electrical signal. The instantaneous amplitude of this signal represents the reflected light energy. This analog signal is converted to digital by an analog to digital converter (ADC). Each digital word at the output of the ADC represents the amplitude of a sample from the analog video signal.
Computation and processing of digital images is generally performed by a set of algorithms that can be implemented in software. However, they can also be implemented as specialised image processing hardware. This implementation not only provides the speed in execution of these computationally expensive algorithms, but also overcomes some of the functional limitations of the host computer. It is, therefore, not unusual to find image processing equipment developed by integrating off the shelf computers and specialised image processing hardware. The operation of the entire equipment is coordinated and controlled by the software executing on the host computer.
The trend in image processing equipment is towards miniaturisation. Recently, image processing hardware in the form of single boards compatible with industry standard buses are commercially available. These boards are generally easily configurable and can plug into engineering workstations and personal computers. These boards contain digitiser and frame buffer combinations for image digitisation and temporary storage, arithmetic and logic units (ALUs) for performing arithmetic and logical operations at frame rates and one or more frame buffers for fast access to image data during processing. Mainframes and supercomputers are, however, still being used for solving large scale image processing problems.
Image processing software available commercially can interact with other applications like graphics software, word processors, spread sheets and databases, thus allowing users to develop extensive image analysis, storage and display systems with minimum efforts.
Digital representation of images may run over hundreds of thousands of bytes. The image processing systems must, therefore, be equipped with suitable storage sub-systems. These may be categorised into short term storage devices, on-line storage sub-systems and archival storage mechanisms.
Short term storage is basically used during processing. Although the host computer’s RAM can be used to provide short term storage, specialised buffers called frame buffers are also available. These frame buffers can store one or more image frames. These frames are accessible at video rates (30 complete images per second). Although frame buffers can provide features like virtually instantaneous image zoom, scroll (vertical shifts) and pans (horizontal shifts), they can store only a few frames. This is largely due to the limitations in the physical card sizes as well as the storage density of the memory chips used.
On-line storage provides a relatively fast recall, read/write capability and is used for frequent accesses to data. Conventionally magnetic disks have been used for this purpose. However, recent advances in the magneto-optical storage device technology have also brought them in line with their magnetic counterparts.
Archival storage is basically characterised by massive storage requirements but infrequent need for access. High density magnetic tapes (6400 bytes per inch) can store a megabyte of information in 13 feet of tape. But they suffer from the disadvantages of relatively short shelf life and the need for a controlled storage environment. WORM (Write Once Read Many) optical disks, however, provide extremely high storage capacities, a high shelf life and do not require special storage conditions. Their biggest disadvantage is reusability as they are not erasable. WORM disks can be stored in a jukebox where they can serve as on-line storage devices for applications in which read only operations are predominant.
Communication of image data can be categorised as local communication and remote communication. Local communication occurs within the image processing equipment when the data needs to be transferred between various modules.
Remote communication occurs when the image processing devices are physically dispersed. As a digital image contains extensive amount of data, its transmission from one point to another at speeds providing desirable results for the applications is a serious challenge. This problem can be addressed either by using high bandwidth communication equipment or by using image compression/decompression techniques to transmit only non-redundant data as it occurs. Redundant data may only be transmitted once.
Images are conventionally displayed on monitors in an analog format. Thus digital images need to be converted into analog format for display on these devices. Format conversion from digital to analog is accomplished by means of digital to analog converters (DAC).
2.3 Representation of a Digital Image
Low level image processing uses data which resembles the input image, for example, an input image captured by a TV camera is 2D in nature, described by an image function whose value is usually the brightness depending upon the coordinates of the location in the image. Consider the monochrome image shown in figure – 2.

Figure –2 : Representation of a Digital Image
It is a two dimensional light intensity function f(x,y), where x,y denote the spatial coordinates and the value of f at any point (x,y) is proportional to the brightness or the gray level of the image at that point. Thus when digitised, this image can be viewed as a matrix whose row and column indices identify a point on the image and the corresponding matrix element value identifies the gray level at that point. The elements of such an array are called image elements, picture elements or pixels.
A single matrix is generally used for a monochrome image. However, several matrices can contain information about one multi-spectral image. Each of these matrices contains one image corresponding to one spectral band.
2.4 Colour Images
White light is a mixture of several spectral colours that are distinctly seen by the eye as red, blue, green, orange, yellow, indigo and violet. The three spectral colours represented by red, green and blue (RGB) wavelengths are known as the primary colours as they can be combined or added together in different proportions to produce almost all other colours perceived by the eye. This additive property of the three colours is actually used to produce a coloured picture on a TV monitor.
Monochrome imaging systems were in use long before the development of colour imaging systems was initiated. By that time, a large number of monochrome TV sets were in use. Techniques were required to provide the colour TVs with 2 way compatibility with the monochrome TV systems. This meant that the colour image signals must be reproduced in black and white on a monochrome receiver, just as a colour receiver must be capable of displaying monochrome video in black and white. This goal was accomplished by converting the RGB signals into two signals. One signal would carry the luminance information in a manner identical to the monochrome transmission. The second signal would carry the chrominance information in such a way that it is sufficient for adequate colour reproduction, but easy to ignore by a monochrome receiver without causing interference to the luminance signal.
One of the relationships used to convert between the RGB and the luminance chrominance components is given in (1).
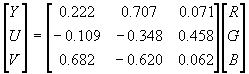 (1)
(1)
Other relationships have been defined by standards such as NTSC and PAL.
Processing a colour image in the RGB domain requires the sampling and quantisation of all the three primary colours, i.e., red, green and blue. However, experimentally it has been pointed out at numerous occasions that coding digital images in the luminance-chrominance domain is more appropriate. It is because the luminance signal carries the bulk of information in a picture. If the luminance content of a colour image is sampled and quantised to produce a decoded picture of a high quality, the chrominance components may be sampled at a relatively low rate and quantised fairly coarsely. As the chrominance signals carry relatively little information, their defects tend to be masked by the luminance signals. Experimental observations indicate that the chrominance signals together need occupy about 10-20% of the total digital channel capacity required for transmission.
3.0 Image Compression
Digital format is uniquely capable of performing signal processing necessary to accomplish bandwidth reduction with a minimum loss of picture quality. Signals, which are a number sequence, can be transformed to a band reduced format by a series of algorithms which are extremely powerful mathematical tools.
Image compression algorithms aim to remove redundancy in data in a way that makes image reconstruction possible. Compression is the main goal, i.e., the aim is to represent an image using a lower number of bits per pixel, without losing the ability to reconstruct the image. It is, therefore, necessary to find statistical properties of the image to design an appropriate compression transformation of the image. The more correlated the image data are, the more data items can be removed.
A general algorithm for data compression and image reconstruction is shown in figure –3. In the first step, the information redundancy, caused by high correlation of image data, is reduced. Several techniques, such as transform compression, predictive compression and hybrid approaches are used. The second step is coding of transformed data using a code of fixed or variable length. An advantage of variable length codes is the possibility of coding more frequent data by shorter codes and therefore increasing compression efficiency. Alternatively, fixed length coding techniques use standard code word length that offers easy handling. Compressed data are decoded after transmission or archiving and are reconstructed. No non-redundant data should be lost in the data compression process otherwise error free reconstruction is impossible.
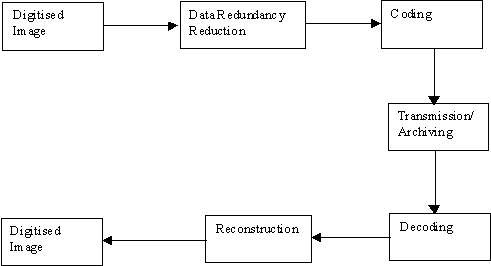
Figure – 3 : Image Data Compression (A Generic Algorithm)
Image data compression techniques are generally divided into two major groups. Information preserving or exact coding schemes permit error free data reconstruction. Thus the original digital image can be reproduced pixel for pixel at the decoder and, therefore, there is no degradation in image quality.
In image processing, a faithful reconstruction is often not necessary in practice. Here, the requirements are loose and image data compression must not cause significant changes in an image. Thus information lossy or inexact coding algorithms may be employed. These algorithms do not preserve the information completely. Compression is generally higher but the reconstructed image is actually an approximation of the original image as some information is lost. However, some applications may prohibit the use of lossy coding schemes. For example, diagnosis in medical imaging is often based on visual image inspection and no loss of information can be tolerated. Exact coding schemes must, therefore, be used for such applications.
Design of image data compression systems consists of two parts. Image data properties must be determined in the first step. An appropriate compression technique must then be designed on the basis of the measured image properties. Compression can be increased if a scheme can automatically adapt to non-stationary statistics and varying image content.
4.0 The JPEG Image Compression Decompression Algorithm
The acronym JPEG stands for Joint Photographic Experts Group. The word joint comes from the fact that it is a collaborative effort between two standards committees, the CCITT (International Telephone and Telegraph Consultative Committee) and ISO (International Standards Organisation).
There are four main kinds of JPEG compression algorithms
(a) Sequential Encoding : Each image component is encoded in a single, left to right, top to bottom scan.
(b) Progressive Encoding : The image is encoded in multiple scans for applications in which transmission time is long and the viewer prefers to watch the image buildup in multiple coarser to clearer passes.
(c) Lossless Encoding : The image is encoded to guarantee exact recovery of every source image sample value (even though the result is low compression as compared to the lossy modes). It is based on a simple predictive method that is wholly independent of the DCT based algorithms.
(d) Hierarchical Encoding : The image is encoded at multiple resolutions so that the lower resolution versions may be accessed without first having to decompress the image at its full resolution. This is useful in applications where a very high resolution image must be accessed by a lower resolution display.
The most widely implemented facet of the JPEG standards is the baseline DCT based sequential compression method. The algorithm is based on the fact that the sub-blocks of an image will generally contain either constant or gradually changing luminance, i.e. low frequency information. Only a few sub-blocks that are situated over sharp edges or regions of fine detail will contain any significant rapidly changing luminance, i.e. the high frequency information. JPEG compression algorithm aims to extract the significant low frequency information and discard the less important high frequency information. This significantly reduces the amount of information required to be coded.
4.1 Stage in JPEG Image Compression and Decompression
The JPEG compression involves the following process
(a) The image is broken into blocks of 8´ 8 pixels.
(b) Each block is transformed using the Forward Discrete Cosine Transform (FDCT).
(c) The resulting 64 coefficients are quantised to a finite set of values. The degree of rounding depends upon the specific coefficients.
(d) The DC coefficient (at location 0,0) is a measure of the average value of the 64 pixels within the specific image block. Because there is usually strong correlation between the DC coefficients of adjacent 8´ 8 blocks, the quantised DC coefficient is encoded as a difference from the DC term of the previous block in scan order.
(e) The remaining 63 quantised coefficients are scanned in zig zag sequence. This ordering helps to facilitate entropy encoding by placing the low frequency coefficients (which are more likely to be non zero) before the high frequency coefficients. This process is shown in figure-4.
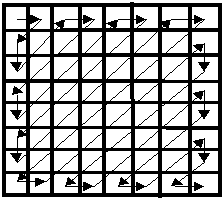
Figure – 4 : Zig Zag Scanning Sequence
(f) Ordered coefficients are runlength encoded.
(g) The data stream is entropy encoded by means of arithmetic or Huffman coding.
The block diagram of a JPEG encoder is shown in figure-5.
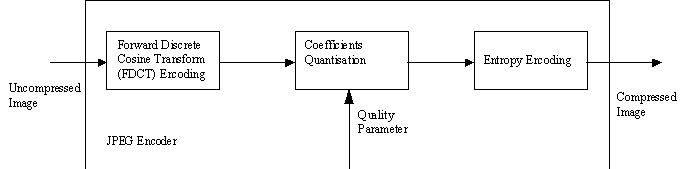
Figure – 5 : JPEG Encoder
Decompression is accomplished by applying the inverse of each of the preceding steps in opposite order. Thus, the decoding process starts with entropy decoding and proceeds to convert the runlengths to a sequence of zeros and coefficients. Coefficients are dequantised and Inverse Discrete Cosine Transform (IDCT) is performed to retrieve the decompressed image. The block diagram of a JPEG decoder is shown in figure–6.
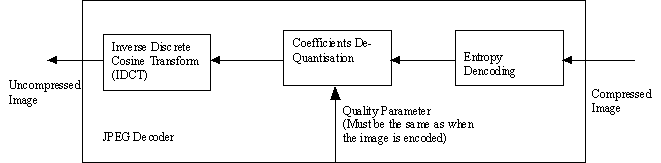
Figure – 6 : JPEG Decoder
4.2 Discrete Cosine Transforms
The Discrete Cosine Transform (DCT) is a variant of the Fourier Transform adapted to real as opposed to complex data. This transform is linear, i.e., the DCT can be completely specified by a matrix.
An 8´ 8 block of pixels can be viewed as a vector in a 64 dimensional space. Each of these blocks is transformed separately. The 64 pixel values, sxy, are transformed via the Forward Discrete Cosine Transform (FDCT) to 64 coordinates in a new basis, Suv. Prior to transformation, the pixel values are shifted to center them around zero. For 8 bit data, it means subtracting 128 from the pixel values. If the pixel data are expressed with 8 bits of precision, the transformed data are stored as signed integers with 11 bits of precision.
The FDCT is expressed in equation (2).
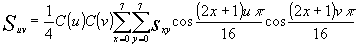 (2)
(2)
0 £ u, v £ 7
The IDCT is expressed by (3)
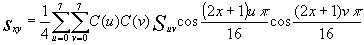 (3)
(3)
0 £ x, y £ 7
In both the equations, 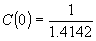
and 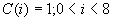 .
.
Because the pixel values typically vary slowly from point to point across an image block, the FDCT processing step lays the foundation for achieving data compression by concentrating most of the signal in the lower spatial frequencies. For a typical 8´ 8 sample block from a typical source image, most of the spatial frequencies have zero or near zero amplitude and need not be encoded.
In an implementation, the cosine terms are only computed once and taken from a look up table. Except for the possibility of rounding off errors, the DCT portion of the algorithm does not introduce any loss of data, i.e. the corresponding pixel values in the image reconstructed by performing an IDCT at this stage and the original image will be the same.
4.3 Quantisation
Quantiasation makes JPEG lossy. The purpose of quantisation is to achieve compression by representing DCT coefficients with no greater precision than is necessary to achieve the desired image quality. The goal of this processing step is to discard information that is not visibly significant.
In quantisation, each of the 64 DCT coefficients is uniformly quantised in conjunction with a 64 element quantisation table. The user or the application must specify this table as an input to the encoder. This division is followed by rounding to the nearest integer, as shown in (4).
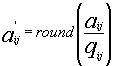 (4)
(4)
Each element of the quantisation table can be any integer value ranging from 1 to 255. This value specifies the step size of the quantiser for its corresponding DCT coefficient. A step size of 1 means no loss for the corresponding coefficient. The larger the value of an element of the quantisation table, fewer bits of precision are used in the corresponding coefficient.
The coefficients in the quantisation matrix are not uniform. The variation in the coefficients is based upon the relative visual impact of errors at the given frequencies. The eye is assumed to be less sensitive to errors for higher frequencies than lower frequencies.
4.4 Runlength Encoding
The final stage in the compression process is entropy encoding. Entropy encoding may be considered as a 2 step process. The first step converts the zig zag sequence of quantised coefficients into an intermediate sequence of symbols. The second step converts these symbols to a data stream in which the symbols no longer have externally identifiable boundaries.
The intermediate symbols are generated by runlength encoding the quantised DCT coefficients. Here, each non zero AC coefficient is represented in combination with the runlength (consecutive number) of zero valued AC coefficients which precede it in the zig zag sequence. Each such runlength/non zero coefficient combination is usually represented as a pair of symbols shown below
symbol 1
(RUNLENGTH,SIZE)
symbol 2
AMPLITUDE
RUNLENGTH is the number of consecutive zero valued AC coefficients in the zig zag sequence preceding non zero AC coefficient being represented. SIZE is the number of bits used to encode AMPLITUDE by the signed integer encoding used with JPEG’s particular method of Huffman coding (explained in entropy encoding).
The intermediate representation for an 8´ 8 sample block’s differential DC coefficient is structured similarly. Symbol 1, however, represents only SIZE information whereas symbol 2 represents AMPLITUDE information.
4.5 Entropy Encoding
Entropy encoding achieves additional compression losslessly by encoding the quantised DCT coefficients more compactly based on their statistical characteristics. The JPEG proposal specifies two entropy encoding methods, Huffman coding and arithmetic coding. Baseline codecs use Huffman coding, but codecs with both methods are specified for all modes of operation.
A Huffman code assigns a variable bit size word to each coefficient such that no code word forms the prefix to another legal code word. Huffman coding requires that one or more sets of Huffman code tables be specified by the application. The tables that are used to compress an image are needed to decompress it. Huffman tables may be pre-defined and used within an application as defaults, or computed specifically for a given image in an initial statistics gathering pass prior to compression.
The particular arithmetic coding method specified in the JPEG proposal requires no tables to be externally provided. It is able to adapt to the image statistics as it encodes the image. If desired, statistical conditioning tables can be used as inputs for slightly better efficiency. Arithmetic coding produces a smaller compressed file with no additional impact on image quality. However, arithmetic coding is considered to be more complex than Huffman coding for certain implementations. Moreover, the particular variant of arithmetic coding specified by the JPEG standard is subject to patents owned by IBM, AT&T and Mitsubishi. Thus it cannot be used without obtaining legal licenses from these companies.
If the only difference between the two JPEG codecs is the entropy encoding method, transcoding between the two is possible by simply entropy decoding with one method and entropy encoding with the other.
4.6 Interchange Format
One component of the JPEG recommendation is the interchange format. Within an application, many choices can be established internally. To share data, all arbitrary choices must be explicitly spelled out. In particular, the JPEG header contains information about image dimensions, type of coding, quantisation levels and a description of the entropy encoding scheme used.
The JPEG recommendation provides a set of quantisation levels. If the application stays within the defaults, they are not required to specify the tables. However, any set of coefficients can be used provided they are inserted into the header information before exchanging the image with another application.
The standard also provides a set of Huffman codes. The standard states that the Huffman codes must be described in the header information even if the defaults are used. Again, this only needs to be done for files being exported to other applications. Some implementations allow one to set a flag indicating whether a file is for internal or external use.
4.7 Compressing Colour Images
The compression and decompression procedure mentioned above is basically for monochrome images. However, the same algorithm can be used for compressing and decompressing colour images. The luminance-chrominance format is preferred because the image components are reasonably uncorrelated with each other. Thus, as a first step, the RGB image format is converted to the luminance-chrominance format. For visual purposes, it is possible to lose more colour information than gray scale information. The chrominance images are, therefore, usually sub-sampled both horizontally and vertically. The luminance and the sub-sampled chrominance images are then individually compressed by the process mentioned above. At the decoder, the chrominance images are interpolated after the Inverse Discrete Cosine Transformation. The resulting luminance and chrominance images are transformed back to the RGB format. These processes are shown in figures 7 and 8.
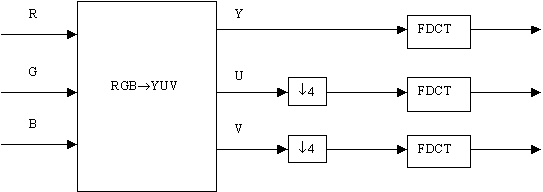
Figure – 7 : Encoding Colour Images
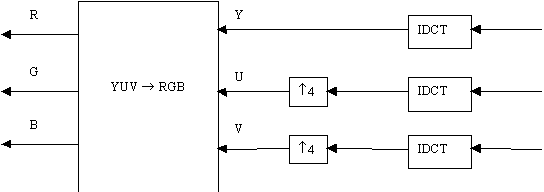
Figure-8 : Decoding Colour Images
5.0 Image Quality Issues for JPEG Images
Coding and data compression of digital images involves manipulations that are approximate and result in image degradation. Data compression results in an image representation to a format that is suitable for storage and/or transmission efficiently. In case of lossy data compression techniques, compression is achieved by deleting small magnitude coefficients. Moreover the quantisation process that is used is an additional source of error. Finally, the accuracy with which numerical operations are carried out is another source of error. Thus the compression and decompression process may also alter data in a manner so as to cause objectionable image defects in certain areas of the image. Defects that are easily perceived by humans are changes in sharpness or location of edges and changes in contrast across the boundaries.
The JPEG algorithm operates by dividing the image into blocks of 8´ 8 pixels each and then removing the high frequency details from these blocks. Thus, when a compressed image is decompressed, the pixel values in the reconstructed image are not the same as in the original image. As a result, blocks with a large amount of high frequency information generally suffer more degradation than those containing less amount of high frequency information. Moreover, these defects increase with higher compression ratios. This means that images that are compressed using high compression ratios, when reconstructed have a significant number of blocks in error. This effect is shown in figure-9.

(a)


(b) (c)
Figure - 9 : Effect of Compression on Image Quality
(Continued on next page)


(d) (e)
Figure - 9 : Effect of Image Compression on Image Quality
The original image is shown in figure - 9 (a). A small portion of the image is cropped and enlarged for analysis. This portion is shown in figure-9(b). It is compressed using the JPEG algorithm in Adobe Photoshop for various quality and file size factors. The images shown in figure-9(c), (d) and (e) were compressed using quality factors of 10 (large file sizes, 68 kilobytes), 5 (medium file sizes, 25 kilobytes) and 0 (small file sizes, 17 kilobytes) respectively. Degradations such as blockiness and blurring of edges may be observed in these images as the compression ratios are increased.
It is also not advisable to recompress a JPEG image after decompressing it and then editing it. Multiple compressions of the same image result in poor quality images. If an image needs to be edited, it should be stored as an uncompressed image. For best visual quality, the image should be compressed only once after it has been edited. Thus, JPEG is a useful format for compact storage and transmission of images, but it should not be used as an intermediate format for sequences of image manipulation steps. Lossless image formats such as PPM, TIFF etc. should be used for editing.
6.0 Summary
Digital images contain significantly large amount of data that need to be compressed for efficient storage and transmission. Over the past few years, several image compression techniques have been developed. These techniques aim to compress the images by transmitting only the non-redundant information as it occurs. The redundant data are transmitted only once. As images of natural scenes contain significant amount of redundant data, the actual amount of data transmitted or stored is reduced significantly.
Some of these compression techniques are information preserving or lossless in nature, i.e. the corresponding pixel values in the original and the reconstructed images are numerically the same. Other techniques are lossy in nature. Here, the reconstructed images are actually approximations of the original uncompressed images. The corresponding pixel values in the reconstructed and the original images are not the same. These techniques usually attempt to reduce image data by discarding the information that is not visibly significant. Thus compression may be achieved without having a major impact on the visual image quality.
JPEG standard defines a set of image compression mechanisms. The most widely used mechanism is the baseline sequential encoding algorithm. This is a lossy compression algorithm. It is based on the principle that small blocks of a natural image contain either constant or gradually changing luminance (low frequency information). Only a few sub-blocks situated over sharp edges or regions of fine detail have significant rapidly changing luminance (high frequency information). The significant low frequency information from each sub-block is retained while the high frequency information is discarded, thereby reducing the amount of information to be coded. Moreover, most of the JPEG compression software packages provide the users with a choice between image quality and the amount of compression.
Although JPEG was originally developed as a standard for still image compression, significant work has also been conducted on M-JPEG or Motion JPEG techniques for video. In M-JPEG, JPEG compression is applied to individual frames of a video sequence. However, in the absence of any specific standard, these implementations are generally vendor specific.
MPEG (Motion Pictures Expert Group) is the recognised standard for motion picture compression. It uses most of the techniques used in JPEG, but adds interframe compression to exploit the similarities that usually exist between the successive frames. Therefore, MPEG typically compresses a video sequence by about a factor of 3 more than M-JPEG techniques can for similar quality. The disadvantages of MPEG are
(a) it is extremely computationally intensive
(b) it is difficult to edit an MPEG sequence on a frame by frame basis as each frame is intimately tied to the ones around it
This latter problem has made M-JPEG methods popular for video editing products.
Bibliography
Barnsley M.F. & Hurd L.P., (1993), Fractal Image Compression, AK Peters Ltd.
Clarke R.J., (1985), Transform Coding of Images, Academic Press Inc. (London) Ltd.
Gonzalez R.C. & Woods R.E., (1992), Digital Image Processing, Addison Wesley Publishing Co. Inc.
Ingilis A.F, (1993), Video Engineering, McGraw Hill Inc.
Pearson D.E., (1975), Transmission and Display of Pictorial Information, Pentech Press London
Russ J.C., (1995), The Image Processing Handbook, CRC Press Inc.
Shalkoff R.J., (1989), Digital Image Processing and Computer Vision, John Wiley & Sons Inc.
Sharma S.P., (1983), Basic Radio and Television : Colour and Black & White, Tata McGraw Hill Publishing Co.
Sonka M., Hlavac V. & Boyle R. (1993), Image Processing, Analysis and Machine Vision, Chapman & Hall Computing
Wallace G.K., (1991), The JPEG Still Picture Compression Standard, Communications of the ACM, April 1991.