 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ORACLE 8: BACKUP &RECOVERY |
|
|
| GOALS & STRATEG |
|
|
| GOALS |
|
|
|
Protecting database from failures. |
|
|
|
Reducing the Mean Time to Recover (MMTR) |
|
|
|
Increasing the Mean Time Between Failures (MTBF) |
|
|
|
Minimizing the data loss. |
|
|
| DEFINING BACKUP & RECOVERY STRATEGY |
|
|
|
Business Requirements: |
|
|
|
MTTR: Try to decrease |
|
|
|
MTBF: Try to decrease |
|
|
|
Operational Requirements: |
|
|
|
Continuos Operations: Database availability. |
|
|
|
Database Volatility: Degree of structural changes at pieces of the database. |
|
|
|
Technical Requirements: |
|
|
|
Database Configuration : System Resources |
|
|
|
Transaction Volumes: Scheduled Jobs effects the load on the system. |
|
|
|
Types of Failures: Determine what type of failures might occur. |
|
|
|
Management Concurrence: Reviewing strategies the more the requirements change. |
|
|
| BACKUP & RECOVERY ARCHITECTUR |
|
|
| USER & SERVER PROCESSES |
|
|
| USER PROCESSES |
|
|
|
Created when an application or a tool is started. |
|
|
|
Resides on the client or the server. |
|
|
|
Provides the User Program Interface (UPI). |
|
|
|
Terminates when the user exits or is forced to discontinue. |
|
|
| SERVER PROCESS |
|
|
|
Created when a valid connection is established with the server. |
|
|
|
Resides on the system that runs the Oracle Instance. |
|
|
|
Uses the ORACLE Program Interface (OPI) to process user requests. |
|
|
|
Terminates when the user disconnects. |
|
|
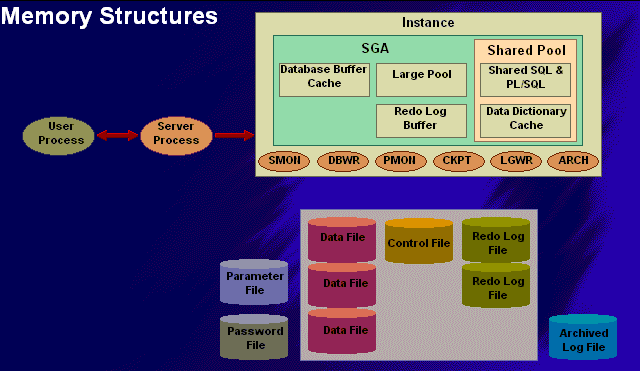
| MEMORY STRUCTURES: |
|
|
| When an oracle instance is started, SGA and five or more background processes are stared. |
|
|
 |
|
| 1. BACKGROUND PROCESSES: |
|
|
| PMON: |
|
|
|
Releases the SGA resources. Allocated to a Failed Process. |
|
|
|
Cleans the abnormally terminated connections. |
|
|
|
Rollback uncommitted transactions. |
|
|
|
Checks other processes such as the shared server or dispatcher processes. It respartes the processes if they have failed. If PMON fails the instance is shutdown and needs to be restarted. |
|
|
| SMON: |
|
|
|
Performs automatic Instance Recovery at Instance Startup. |
|
|
|
Recover the space used by the Temporary Segments those are no longer in use. |
|
|
|
Merges contiguous areas of free space in data files. |
|
|
| LGWR: |
|
|
|
Manages the redolog buffers for the Instance |
|
|
|
Record changes Registered in the Redolog Buffers to a Database. |
|
|
| LGWR process writes the redo log entries to disk: |
|
|
|
When DBWR finishes cleaning the buffer blocks at a checkpoint. |
|
|
|
When a commit occurs. |
|
|
|
When the redo log buffer becomes one third full. |
|
|
|
When a LGWR time-out occurs. |
|
|
| DBWR: These processes can be set by DBWR_IO_SLAVES at init.ora if sysrem hardware doesn?t support asynchronous IO. It writes dirty buffers to disk : |
|
|
|
When a database time-out occurs. |
|
|
|
When the number of free buffers become less than a specified number. |
|
|
|
When a checkpoint occurs. |
|
|
|
At a log switch. |
|
|
|
When a tablespace or a datafile is taken offline. |
|
|
| ARCH: |
|
|
|
Operates only when a log switch occurs. |
|
|
|
Archives any member of redo log group after the groups. |
|
|
|
If a redo log group member is inaccessible the ARCH process automatically tries the another member of the group to archive. |
|
|
|
While archiving member of a group, if ACH process detects a disk failure or the member is invalid, it automatically switches to another group member. |
|
|
|
ARCH process must finish copying the redo log files before the LGWR process can write again to the redo log file. |
|
|
| CKPT: It is an event that synchronizes the write operation between the LGWR and DBWR processes. At a checkpoint all modified buffers in the buffer cache and the redo log buffers in the buffer cache are written to a disk by DBWR and LGWR respectively. |
|
|
| Checkpoint occurs: |
|
|
|
When a tablespace is taken offline or an online backup is started. |
|
|
|
When forced by a dba |
|
|
|
At a log switch |
|
|
|
A specified number of seconds after the last database checkpoint. |
|
|
|
At instance shutdown.(Not aborted) |
|
|
|
When a specified number of blocks (OS) have been written to the redo log files since the last checkpoint. |
|
|
|
Help to synchronize datafiles and redo log files. |
|
|
|
Updates the file headers at checkpoint completion.(Checkpoint sequence number is recorded in the control file. |
|
|
| Control file confirms that all the files are at the same checkpoint number during a database startup. If not, recovery is needed. |
|
|
| FILE STRUCTURES: |
|
|
| Datafiles: They are both system and user data on the disk. A datafile may contain committed or uncommitted data. If database buffer cache is full a datafile might contain uncommitted data. If a failure occurs, the redo logs are used to remove any uncommitted data on the disk. |
|
|
| Redolog files: They store all changes made to a database. If a failure occurs, the rollback segments are unused to ensure that the committed transactions are written to disk and the uncommitted data is rolled back. |
|