3.3 EXCLUSION MUTUA.
Con frecuencia, los sistemas con varios procesos se programan más fácil mediante las regiones críticas. Cuando un proceso debe leer o actualizar ciertas estructuras de datos compartidas, primero entra a una región crítica para lograr la exclusión mutua y garantizar que ningún otro proceso utilice las estructuras de datos al mismo tiempo. En los sistemas con un procesador, las regiones críticas se protegen mediante semáforos, monitores y construcciones similares. Analizaremos ahora algunos ejemplos de implantación de las regiones críticas y la exclusión mutua en los sistemas distribuidos.
Un algoritmo centralizado
La forma más directa de lograr la exclusión mutua en un sistema distribuido es similar a la forma en que se lleva a cabo en un sistema con un procesador. Se elige un proceso como el coordinador (por ejemplo, aquel que se ejecuta en la máquina con la máxima dirección en la red). Siempre que un proceso desea entrar a una región crítica, envía un mensaje de solicitud al coordinador, donde indica la región crítica a la que desea entrar y pide permiso. Si ningún otro proceso está por el momento en esa región crítica, el coordinador envía una respuesta otorgando el permiso, como se muestra en la siguiente figura (a). Cuando llega la respuesta, el proceso solicitante entra a la región crítica.
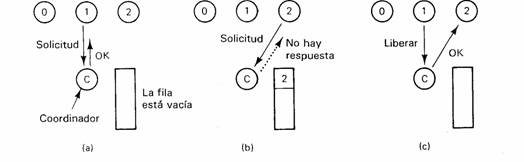
(a) El proceso 1 pide permiso al coordinador para entrar
en una región
crítica. El permiso es concedido. (b)
El proceso 2 pide entonces permiso para
entrar a la misma región crítica. El
coordinador no le responde. (c) Cuando el
proceso 1 sale de la región crítica,
se lo dice al coordinador, el cual responde
entonces a 2.
Supongamos ahora que otro proceso, 2 en la figura anterior (b), pide permiso para entrar a la misma región crítica. El coordinador sabe que un proceso distinto ya se encuentra en esta región, por lo que no puede otorgar el permiso. El método exacto utilizado para negar el permiso depende del sistema. En la figura anterior (b), el coordinador sólo se abstiene de responder, con lo cual se bloquea el proceso 2, que espera una respuesta. Otra alternativa consiste en enviar una respuesta que diga “permiso negado”. De cualquier manera, forma en una fila la solicitud de 2 por el momento.
Cuando el proceso 1 sale de la región crítica, envía un mensaje al coordinador para liberar su acceso exclusivo, como se muestra en la figura anterior(c). El coordinador extrae el primer elemento de la fila de solicitudes diferidas y envía a ese proceso un mensaje otorgando el permiso. Si el proceso estaba bloqueado (es decir, éste es el primer mensaje que se le envía), elimina el bloqueo y entra a la región crítica. Si ya se envió un mensaje explícito negando el permiso, entonces el proceso debe hacer un muestreo del tráfico recibido o bloquearse posteriormente. De cualquier forma, cuando ve el permiso, puede entrar a la región crítica.
Es fácil ver que el algoritmo garantiza la exclusión mutua: el coordinador deja que un proceso esté en cada región crítica a la vez. También es justo, puesto que las solicitudes se aprueban en el orden en que se reciben. Ningún proceso espera por siempre (no hay inanición). Este esquema también es fácil de implantar y sólo requiere tres mensajes por cada uso de una región crítica (solicitud, otorgamiento, liberación). También se puede utilizar para una asignación de recursos más general, en vez de usarlo sólo para el manejo de las regiones críticas.
El método centralizado también tiene limitaciones. El coordinador es un punto de falla, por lo que si se descompone, todo el sistema se puede venir abajo. Si los procesos se bloquean por lo general después de realizar una solicitud, no pueden distinguir entre un coordinador muerto de un “permiso negado”, puesto que en ambos casos no reciben respuesta. Además, en un sistema de gran tamaño, un coordinador puede convertirse en un cuello de botella para el desempeño.
Un algoritmo distribuido
Con frecuencia, el hecho de tener un punto de falla es inaceptable, por lo cual los investigadores han buscado algoritmos distribuidos de exclusión mutua. El artículo de 1978 de Lamport relativo a la sincronización de los relojes presentó el primero de ellos. Ricart y Agrawala (1981) lo hicieron más eficiente. En esta sección describiremos su método.
El algoritmo de Ricart y Agrawala requiere de la existencia de un orden total de todos los eventos en el sistema. Es decir, para cualquier pareja de eventos, como los mensajes, debe quedar claro cuál de ellos ocurrió primero. El algoritmo de Lamport es una forma de lograr este orden y se puede utilizar para proporcionar marcas de tiempo para la exclusión mutua distribuida.
El algoritmo funciona como sigue. Cuando un proceso desea entrar a una región crítica, construye un mensaje con el nombre de ésta, su número de proceso y la hora actual. Entonces envía el mensaje a todos los demás procesos y de manera conceptual a él mismo. Se supone que el envío de mensajes es confiable; es decir, cada mensaje tiene un reconocimiento. Si se dispone de una comunicación en grupo confiable, entonces ésta se puede utilizar en vez del envío de mensajes individuales.
Cuando un proceso recibe un mensaje de solicitud de otro proceso, la acción que realice depende de su estado con respecto de la región crítica nombrada en el mensaje. Hay que distinguir tres casos:
- Si el receptor no está en la región crítica y no desea entrar a ella, envía de regreso un mensaje OK al emisor.
- Si el receptor ya está en la región crítica, no responde, sino que forma la solicitud en una fila.
- Si el receptor desea entrar a la región crítica, pero no lo ha logrado todavía, compara la marca de tiempo en el mensaje recibido con la marca contenida en el mensaje que envió a cada uno. La menor de las marcas gana. Si el mensaje recibido es menor, el receptor envía de regreso un mensaje OK. Si su propio mensaje tiene una marca menor, el receptor forma la solicitud en una fila y no envía nada.
Después de enviar las solicitudes que piden permiso para entrar a una región crítica, un procesador espera hasta que alguien más obtiene el permiso. Tan pronto llegan todos los permisos, puede entrar a la región crítica. Cuando sale de ella, envía mensajes OK a todos los procesos en su fila y elimina a todos los elementos de la fila.
Intentemos comprender el funcionamiento del algoritmo. Sino existe conflicto, es claro que funciona. Sin embargo, supongamos que dos procesos intentan entrar a la misma región crítica en forma simultánea, como se muestra en la figura siguiente figura(a).
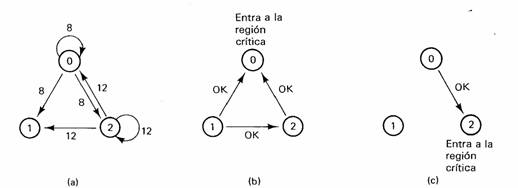
(a) Dos procesos desean entrar a la misma región crítica
en el mismo
momento. (b) El proceso O tiene una
marca de tiempo menor, por lo que gana. (e)
Cuando termina el proceso O, envía un OK, por lo que 2
puede ahora entrar en la
región crítica.
El proceso O envía a todos una solicitud con la marca de tiempo 8, mientras que al mismo tiempo, el proceso 2 envía a todos una solicitud con la marca de tiempo 12. Elproceso 1 no se interesa en entrar a la region critica, por lo que envia OK a ambos emisores Los procesos O y 2 ven el conflicto y comparan las marcas. El proceso 2 ve que ha perdido, por lo que otorga el permiso a O al enviar un mensaje OK. El proceso O forma ahora la solicitud de 2 en una fila para posterior procesamiento y entra a la región crítica, como se muestra en la figura anterior(b). Cuando termina, retira la solicitud de 2 de la fila y envía un mensaje OK al proceso 2, lo que permite a éste entrar a su región crítica, como se muestra en la figura (c). El algoritmo funciona, puesto que en caso de un conflicto, gana la menor de las marcas y todos coinciden en el orden de las marcas de tiempo.
Observe que la situación de la anterior sería en esencia distinta si el proceso 2 hubiese enviado un mensaje en un tiempo anterior, de modo que el proceso O lo haya recibido y otorgado permiso antes de hacer su propia solicitud. En este caso, 2 habría notado que él mismo estaba en una región crítica al momento de la solicitud y se formaría en una fila en vez de enviar una respuesta.
Corno en el caso del algoritmo centralizado ya analizado, la exclusión mutua queda garantizada sin bloqueo ni inanición. El numero de mensajes necesarios por entrada es ahora 2(n—l), donde n es el número total de procesos en el sistema. Lo mejor es que no existe un punto de falla.
Por desgracia, el único punto de falla es remplazado por n puntos de falla. Si cualquier proceso falla, no podrá responder a las solicitudes. Este silencio será interpretado (incorrectamente) como negación del permiso, con lo que se bloquearán los siguientes intentos de los demás procesos por entrar a todas las regiones críticas. Puesto que la probabilidad de que uno de los n procesos falle es n veces mayor que la probabilidad de que falle un coordinador, hemos trabajado para remplazar un algoritmo pobre con otro que es n veces peor y que requiere mayor tráfico en la red para funcionar.
El algoritmo se puede mejorar mediante el mismo truco propuesto antes. Al llegar una solicitud, el receptor siempre envía una respuesta, otorgando o negando el permiso. Siempre que pierda una solicitud o una respuesta, el emisor espera y sigue intentando hasta que regresa una respuesta o el emisor concluye que el destino está muerto. Después de negar una solicitud, el emisor debe bloquearse en espera de un mensaje OK posterior.
Otro problema con este algoritmo es que se debe utilizar una primitiva de comunicación en grupo; o bien, cada proceso debe mantener por sí mismo la lista de membresía del grupo, donde se incluyan los procesos que ingresan al grupo, los que salen de él y los que fallan. El método funciona mejor con grupos pequeños de procesos que nunca cambian sus membresías de grupo.
Por último, recordemos que uno de los problemas con el algoritmo centralizado es que al hacer que maneje todas las solicitudes, esto puede conducir a un cuello de botella. En el algoritmo distribuido, todos los procesos participan en todas las decisiones referentes a la entrada en las regiones críticas. Si un proceso no puede manejar esta tarea, es poco probable que obligar a todos a que realicen lo mismo en paralelo sea de mucha ayuda.
Un algoritmo de anillo de fichas
Un método por completo distinto para lograr la exclusión mutua en un sistema distribuido se muestra en la siguiente figura. Aquí tenemos una red basada en un bus, como se muestra en la figura (a) (por ejemplo, Ethernet), sin un orden inherente en los procesos. En software, se construye un anillo lógico y a cada proceso se le asigna una posición en el anillo, como se muestra en la figura (b). Las posiciones en el anillo se pueden asignar según el orden numérico de las direcciones de la red o mediante algún otro medio. No importa cómo sea el orden. Lo importante es que cada proceso sepa quién es el siguiente en la fila después de él.
Al iniciar el anillo, se le da al proceso O una ficha, la cual circula en todo el anillo. Se trasfiere del proceso k al proceso k+1 (módulo el tamaño del anillo) en mensajes puntuales. Cuando un proceso obtiene la ficha de su vecino, verifica si intenta entrar a una región crítica. En ese caso, el proceso entra a la región, hace todo el trabajo necesario y sale de la región. Después de salir, pasa la fícha a lo largo del anillo. No se permite entrar a una segunda región crítica con la misma ficha.
Si un proceso recibe la ficha de su vecino y no esta interesado en entrar a una región critica, solo la vuelve a pasar En consecuencia, cuando ninguno de los procesos desea entrar a una región critica, la ficha solo circula a gran velocidad en el anillo. Es evidente que el algoritmo es correcto. En un instante dado, sólo uno de los procesos tiene la ficha, por lo que solo un proceso puede estar en una región critica Puesto que las fichas circulan entre los procesos en orden bien definido, no puede existir la inanición. Una vez que un proceso decide entrar a una región crítica, lo peor que puede ocurrir es que deba esperar a que los demás procesos entren y salgan de ella.
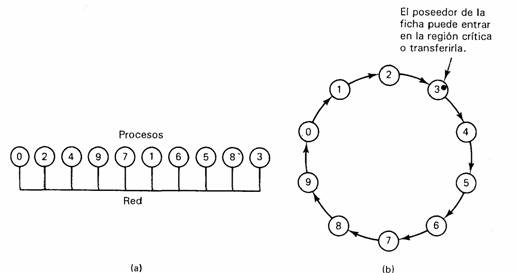
Como es usual, también este algoritmo tiene problemas. Si la ficha llega a perderse, debe ser regenerada. De hecho, es difícil detectar su pérdida, puesto que la cantidad de tiempo entre las apariciones sucesivas de la ficha en la red no está acotada. El hecho de que la ficha no se haya observado durante una hora no significa su pérdida; tal vez alguien la esté utilizando.
El algoritmo también tiene problemas si falla un proceso, pero la recuperación es más sencilla que en los demás casos. Si pedimos un reconocimiento a cada proceso que reciba la ficha, entonces se detectará un proceso muerto si su vecino intenta darle la ficha y fracasa en el intento. En ese momento, el proceso muerto se puede eliminar del grupo y el poseedor de la ficha puede enviar ésta por encima de la cabeza del proceso muerto al siguiente miembro, y así sucesivamente, en caso necesario. Por supuesto, esto requiere que todos mantengan la configuración actual del anillo.