Conceptos
de Hardware
Todos los sistemas distribuidos constan
de varias CPU organizadas de
diversas formas. De acuerdo a
Tanenbaum se pueden analizar conforme a:
- La forma de interconectarlas entre sí.
- Los esquemas de comunicación utilizados.
Existen diversos esquemas
de clasificación para los sistemas de cómputo con varias CPU:
- Uno de los mas conocidos es la “Taxonomía de Flynn”:
- Considera como características esenciales el número
de flujo de instrucciones y el número de flujos de datos.
- La clasificación incluye equipos SISD, SIMD,
MISD y MIMD.
SISD (Single Instruction Single Data: un flujo de
instrucciones y un flujo de datos):
- Poseen un único procesador.
SIMD (Single Instruction Multiple Data: un flujo de
instrucciones y varios flujos de datos):
- Se refiere a ordenar procesadores con una unidad de instrucción
que:
- Busca una instrucción.
- Instruye a varias unidades de datos para que la
lleven a cabo en paralelo, cada una con sus propios datos.
- Son útiles para los cómputos que repiten los mismos cálculos en
varios conjuntos de datos.
MISD (Multiple Instruction Single Data: un flujo de
varias instrucciones y un solo flujo de datos):
- No se presenta en la práctica.
MIMD (Multiple Instruction Multiple Data: un grupo de
computadoras independientes, cada una con su propio contador del programa,
programa y datos):
- Todos los sistemas distribuidos son de este tipo.
Un avance sobre la
clasificación de Flynn incluye la división de las computadoras MIMD en
dos grupos:
- Multiprocesadores: poseen memoria compartida:
- Los distintos procesadores comparten el mismo
espacio de direcciones virtuales.
- Multicomputadoras: no poseen memoria compartida:
- Ej.: grupo de PC conectadas mediante una red.
Cada una de las categorías
indicadas se puede clasificar según la arquitectura de la red de
interconexión en:
- Esquema de bus:
- Existe una sola red, bus, cable u otro medio
que conecta todas las máquinas:
- Ej.: la televisión por cable.
- Esquema con conmutador:
- No existe una sola columna vertebral de
conexión:
- Hay múltiples conexiones y varios patrones de
conexionado.
- Los mensajes de mueven a través de los medios
de conexión.
- Se decide explícitamente la conmutación en
cada etapa para dirigir el mensaje a lo largo de uno de los cables de
salida.
- Ej.: el sistema mundial telefónico público.
- Otro aspecto de la clasificación considera el acoplamiento entre
los equipos:
- Sistemas fuertemente acoplados:
- El retraso al enviar un mensaje de una
computadora a otra es corto y la tasa de transmisión es alta.
- Generalmente se los utiliza como sistemas
paralelos.
- Sistemas débilmente acoplados:
- El retraso de los mensajes entre las máquinas
es grande y la tasa de transmisión es baja.
- Generalmente se los utiliza como sistemas
distribuidos.
Generalmente los
multiprocesadores están más fuertemente acoplados que las multicomputadoras.
Multiprocesadores
con Base en Buses
Constan de cierto número de CPU’s conectadas
a un bus común, junto con un módulo de memoria, de acuerdo a Tanenbaum:
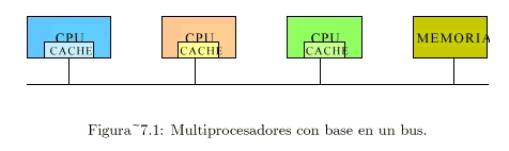
Un bus típico posee al menos:
- 32 líneas de direcciones.
- 32 líneas de datos.
- 30 líneas de control.
Todos los elementos
precedentes operan en paralelo.
Para leer una palabra de memoria, una
CPU:
- Coloca la dirección de la palabra deseada en las líneas de
direcciones del bus.
- Coloca una señal en las líneas de control adecuadas para indicar
que desea leer.
- La memoria responde y coloca el valor de la palabra en las líneas
de datos para permitir la lectura de esta por parte de la CPU solicitante.
Para grabar el
procedimiento es similar.
Solo existe una memoria, la cual presenta
la propiedad de la coherencia:
- Las modificaciones hechas por una CPU se reflejan de inmediato en
las subsiguientes lecturas de la misma o de otra CPU.
El problema de este esquema
es que el bus tiende a sobrecargarse y el rendimiento a disminuir
drásticamente; la solución es añadir una memoria caché de alta velocidad
entre la CPU y el bus:
- El caché guarda las palabras de acceso reciente.
- Todas las solicitudes de la memoria pasan a través del caché.
- Si la palabra solicitada se encuentra en el caché:
- El caché responde a la CPU.
- No se hace solicitud alguna al bus.
- Si el caché es lo bastante grande:
- La “tasa de encuentros” será alta y la cantidad
de tráfico en el bus por cada CPU disminuirá drásticamente.
- Permite incrementar el número de CPU.
Un importante problema
debido al uso de cachés es el de la “incoherencia de la memoria”:
- Supongamos que las CPU “A” y “B” leen la misma
palabra de memoria en sus respectivos cachés.
- “A” escribe sobre la
palabra.
- Cuando “B” lee esa palabra, obtiene un valor anterior y no
el valor recién actualizado por “A”.
Una solución consiste en lo
siguiente:
- Diseñar las caché de tal forma que cuando una palabra sea
escrita al caché, también sea escrita a la memoria.
- A esto se denomina “caché de escritura”.
- No causa tráfico en el bus el uso de “caché para la lectura”.
- Sí causa tráfico en el bus:
- El no uso de caché para la lectura.
- Toda la escritura.
Si todos los cachés
realizan un monitoreo constante del bus:
- Cada vez que un caché observa una escritura a una dirección de
memoria presente en él, puede eliminar ese dato o actualizarlo en el caché
con el nuevo valor.
- Estos cachés se denominan “cachés monitores”.
Un diseño con cachés
monitores y de escritura es coherente e invisible para el programador, por lo
que es muy utilizado en multiprocesadores basados en buses.
Multiprocesadores
con Conmutador
El esquema de multiprocesadores con base
en buses resulta apropiado para hasta aproximadamente 64 procesadores.
Para superar esta cifra es necesario un método
distinto de conexión entre procesadores (CPU) y memoria.
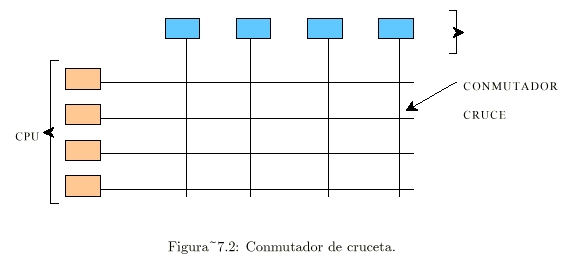
Una posibilidad es dividir la memoria en
módulos y conectarlos a las CPU con un “conmutador de cruceta” (cross-bar
switch):
- Cada CPU y cada memoria tiene una conexión que sale de él.
- En cada intersección está un “conmutador del punto de cruce”
(crosspoint switch) electrónico que el hardware puede abrir y
cerrar:
- Cuando una CPU desea tener acceso a una memoria
particular, el conmutador del punto de cruce que los conecta se cierra
momentáneamente.
- La virtud del conmutador de cruceta es que muchas CPU pueden
tener acceso a la memoria al mismo tiempo:
- Aunque no a la misma memoria simultáneamente.
- Lo negativo de este esquema es el alto número de
conmutadores:
- Para “n” CPU y “n” memorias se
necesitan “n” x “n” conmutadores.
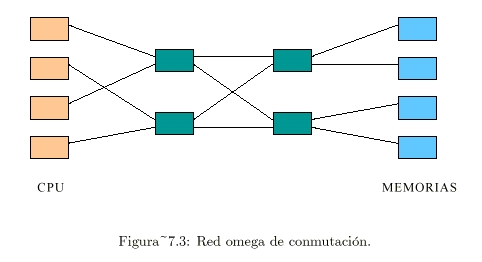
El número de conmutadores del esquema
anterior puede resultar prohibitivo:
- Otros esquemas precisan menos conmutadores,
por ej., la “red omega” (ver Figura 7.3 [Tanenbaum]):
- Posee conmutadores 2 x 2:
- Cada uno tiene 2 entradas y 2 salidas.
- Cada conmutador puede dirigir cualquiera de
las entradas en cualquiera de las salidas.
- Eligiendo los estados adecuados de los
conmutadores, cada CPU podrá tener acceso a cada memoria.
- Para “n” CPU y “n” memorias se
precisan:
- “n”
etapas de conmutación.
- Cada etapa tiene log 2 n
conmutadores para un total de n log 2 n conmutadores;
este número es menor que “n” x “n” del esquema anterior, pero sigue
siendo muy grande para “n” grande (ver Tabla 7.1 y Figura
7.4).
|
n |
log 2 n |
n * log 2 n |
n * n |
|
50 |
5,64385619 |
282 |
2.500 |
|
75 |
6,22881869 |
467 |
5.625 |
|
100 |
6,64385619 |
664 |
10.000 |
|
125 |
6,96578428 |
871 |
15.625 |
|
150 |
7,22881869 |
1.084 |
22.500 |
|
175 |
7,45121111 |
1.304 |
30.625 |
|
200 |
7,64385619 |
1.529 |
40.000 |
|
1.024 |
10 |
10.240 |
1.048.576 |
|
Tabla 7.1: Conmutador de cruceta versus red omega. |
|||
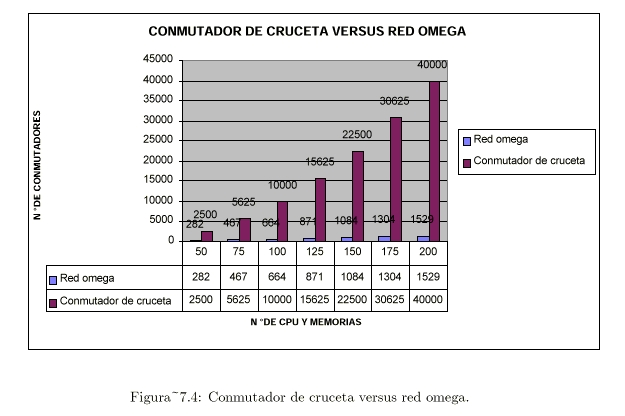
Un problema importante en la red omega
es el retraso:
- Ej.: si “n” = 1024 existen según la tabla anterior:
- 10 etapas de conmutación de la CPU a la
memoria.
- 10 etapas para que la palabra solicitada de la
memoria regrese.
- Si la CPU es de 50 Mhz., el tiempo de ejecución
de una instrucción es de 20 nseg.
- Si una solicitud de la memoria debe recorrer 20
etapas de conmutación (10 de ida y 10 de regreso) en 20 nseg:
- El tiempo de conmutación debe ser de 1 nseg.
- El multiprocesador de 1024 CPU necesitará
10240 conmutadores de 1 nseg.
- El costo será alto.
Otra posible solución
son los esquemas según sistemas jerárquicos:
- Cada CPU tiene asociada cierta memoria local.
- El acceso será muy rápido a la propia memoria local y más lento a
la memoria de las demás CPU.
- Esto se denomina esquema o “máquina NUMA” (Acceso No
Uniforme a la Memoria):
- Tienen un mejor tiempo promedio de acceso que
las máquinas basadas en redes omega.
- La colocación de los programas y datos en
memoria es crítica para lograr que la mayoría de los accesos sean a la
memoria local de cada CPU.
Multicomputadoras
con Base en Buses
Es un esquema sin memoria compartida.
Cada CPU tiene una conexión directa con
su propia memoria local.
Un problema importante es la forma en
que las CPU se comuniquen entre sí.
El tráfico es solo entre una CPU y otra; el
volumen de tráfico será varios órdenes de magnitud menor que si se utilizara la
red de interconexión para el tráfico CPU- memoria.
Topológicamente es un esquema similar al del
multiprocesador basado en un bus.
Consiste generalmente en una colección de
estaciones de trabajo en una LAN (red de área local) (ver Figura 7.5).
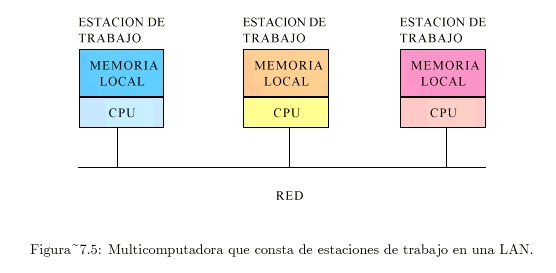
Multicomputadoras
con Conmutador
Cada CPU tiene acceso directo y exclusivo
a su propia memoria . Existen diversas
topologías, las más comunes son la retícula y el hipercubo.
Las principales características de las
retículas son:
- Son fáciles de comprender.
- Se basan en las tarjetas de circuitos impresos.
- Se adecúan a problemas con una naturaleza bidimensional inherente
(teoría de gráficas, visión artificial, etc.) (ver Figura 7.6).
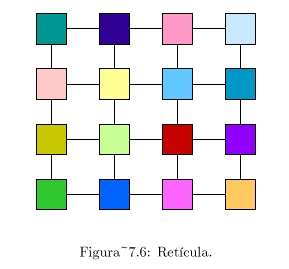
Las principales características del
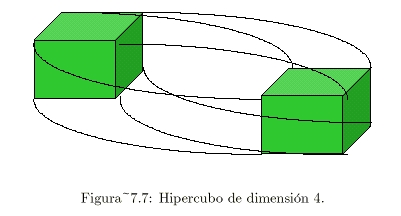
hipercubo son:
- Es un cubo “n” - dimensional.
- En un hipercubo de dimensión 4:
- Se puede considerar como dos cubos ordinarios,
cada uno de ellos con 8 vértices y 12 aristas.
- Cada vértice es un cubo.
- Cada arista es una conexión entre 2 CPU.
- Se conectan los vértices correspondientes de cada
uno de los cubos.
- En un hipercubo de dimensión 5:
- Se deberían añadir dos cubos conectados entre
sí y conectar las aristas correspondientes en las dos mitades, y así
sucesivamente.
- En un hipercubo de “n” dimensiones:
- Cada CPU tiene “n” conexiones con otras CPU.
- La complejidad del cableado aumenta en
proporción logarítmica con el tamaño.
- Solo se conectan los procesadores vecinos más
cercanos:
- Muchos mensajes deben realizar varios saltos
antes de llegar a su destino.
- La trayectoria más grande crece en forma
logarítmica con el tamaño:
- En la retícula crece como la raíz cuadrada
del número de CPU.
- Con la tecnología actual ya se pueden producir
hipercubos de 16.384 CPU(ver Figura 7.7 ).