


Equipo de Trabajo:
Ingrid Chávez Moira Soto Shirley Alarcón
Rafael Rada Luis Omar Sánchez
Investigado por: Luis Omar Sánchez
|
|
|
|
- Obtener
una impresión general e intuitiva sobre el cometido de la estadística
descriptiva en particular y sobre la estadística en general
|
ESTADISTICA DESCRIPTIVA |
ESTADISTICA
Es
La estadística cuenta con
procedimientos para recoger, organizar y presentar información acerca de un
problema determinado, y con métodos para establecer la validez de las
conclusiones obtenidas a partir de la información recogida.
![]() Descriptiva
Descriptiva
La estadística se
clasifica en:
Inferencial
La descriptiva presenta la información en forma cómoda, utilizable y comprensible.
La inferencial se ocupa de
la generalización de esa información haciendo deducciones acerca de las poblaciones
basándose en muestras tomadas de ellas.
Estadística Descriptiva:
Tienen por objeto fundamental describir
y analizar las características de un conjunto de datos, obteniéndose de esa manera
conclusiones sobre las características de dicho conjunto y sobre las relaciones
existentes con otras poblaciones, a fin de compararlas. No obstante puede no
solo referirse a la observación de todos los elementos de una población
(observación exhaustiva) sino también a la descripción de los elementos de una muestra
(observación parcial).
En relación a la estadística
descriptiva, Ernesto Rivas Gonzáles dice; "Para el estudio de estas muestras,
la estadística descriptiva nos provee de todos sus
medidas; medidas que cuando quieran ser aplicadas al universo total, no tendrán la misma exactitud
que tienen para la muestra, es decir al estimarse para el universo vendrá dada con cierto margen de
error; esto significa que el valor de la medida calculada para la muestra, en
el oscilará dentro de cierto límite de confianza, que casi siempre es de un
|
VARIABLES |
Una variable es una
característica observable que varía entre los diferentes individuos de una
población. La información que disponemos de cada individuo es resumida en
variables.
La naturaleza de las observaciones será
de gran importancia a la hora de elegir el método estadístico más apropiado
para abordar su análisis. Con este fin, clasificaremos las variables, a grandes
rasgos, en dos tipos variables cuantitativas o variables cualitativas.
- Variables cuantitativas. Son las variables que pueden medirse,
cuantificarse o expresarse numéricamente. Las variables cuantitativas
pueden ser de dos tipos:
- Variables
cuantitativas continuas, si
admiten tomar cualquier valor dentro de un rango numérico determinado
(edad, peso, talla).
- Variables
cuantitativas discretas, si no
admiten todos los valores intermedios en un rango. Suelen tomar solamente
valores enteros (número de hijos, número de partos, número de hermanos,
etc).
- Variables cualitativas. Este tipo de variables representan una cualidad
o atributo que clasifica a cada caso en una de varias categorías. La
situación más sencilla es aquella en la que se clasifica cada caso en uno
de dos grupos (hombre/mujer, enfermo/sano, fumador/no fumador). Son datos
dicotómicos o binarios. Como resulta obvio, en muchas ocasiones este tipo
de clasificación no es suficiente y se requiere de un mayor número de categorías
(color de los ojos, grupo sanguíneo, profesión, etcétera).
En el proceso de medición de estas variables, se
pueden utilizar dos escalas:
- Escalas nominales: ésta es una forma de observar o medir en la que
los datos se ajustan por categorías que no mantienen una relación de
orden entre sí (color de los ojos, sexo, profesión, presencia o ausencia
de un factor de riesgo o enfermedad, etcétera).
- Escalas ordinales: en las escalas utilizadas, existe un cierto
orden o jerarquía entre las categorías (grados de disnea, estadiaje de un
tumor, etcétera).
|
DISTRIBUCION DE
FRECUENCIAS |
Es comúnmente llamada tabla de
frecuencias, se utiliza para hacer la presentación de datos provenientes de las
observaciones realizadas en el estudio, estableciendo un orden mediante la
división en clases y registro de la cantidad de observaciones correspondientes
a cada clase. Lo anterior facilita la realización de un mejor análisis e
interpretación de las características que describen y que no son evidentes en
el conjunto de datos brutos o sin procesar. Una distribución de frecuencias
constituye una tabla en el ámbito de investigación.
La distribución de frecuencias puede ser simple o agrupada.
Es una serie de datos agrupados en categorías, en las cuales se muestra el número de observaciones que contiene cada categoría. Una distribución de frecuencias es una herramienta estadística muy útil para organizar un grupo de observaciones.
Los pasos para la construcción de una distribución de frecuencias son mejor explicados con un ejemplo:
Ejemplo:
Los siguientes datos son el número de meses de duración de una muestra de 40 baterías para un automóvil:
|
22 |
41 |
35 |
45 |
32 |
37 |
30 |
26 |
|
34 |
16 |
31 |
33 |
38 |
31 |
47 |
37 |
|
25 |
43 |
34 |
36 |
29 |
33 |
39 |
31 |
|
33 |
31 |
37 |
44 |
32 |
41 |
19 |
34 |
|
47 |
38 |
32 |
26 |
39 |
30 |
42 |
35 |
El rango
Rango = Dato mayor – Dato menor = 47 – 16 = 31
Número tentativo de los intervalos de clase
El
número de intervalos (nic) puede ser como mínimo 5 y como máximo 15 de acuerdo
a la fórmula 2 nic £
n
|
Número de intervalos (nic) |
Número
máximo de datos |
|
5 |
32 |
|
6 |
64 |
|
7 |
128 |
|
8 |
256 |
|
9 |
512 |
|
10 |
1024 |
Tamaño de los Intervalos de Clase (tic)
|
TIC = |
Rango |
= |
31 |
=
5.16 se redondea a 5 |
|
NIC |
|
6 |
Para facilitar la clasificación de los datos, el Tic
se redondea a una cifra mas o menos cerrada.
Primer límite inferior: Usualmente, el límite inferior del primer
intervalo de clase es un múltiplo del tamaño del intervalo (tic), en este
problema el tic es de 5, entonces el primer límite inferior será el mayor
múltiplo de 5 pero inferior o igual al dato menor, el 15.
Límite inferior y superior de cada
intervalo: Se comienza en el
primer límite inferior al que se le va sumando el tic, hasta llegar a un valor
máximo antes de superar el valor del dato mayor. Los límites superiores se
calculan con la siguiente fórmula:
LS
= LI + TIC – 1
|
LI |
LS |
|
15 |
19 |
|
20 |
24 |
|
25 |
29 |
|
30 |
34 |
|
35 |
39 |
|
40 |
44 |
|
45 |
49 |
Límites
Reales
Los límites anteriores son llamados límites “oficiales” pero no son los reales. Los límites reales son el punto medio entre el límite superior y el límite inferior del siguiente intervalo.
|
LI |
LS |
LSR |
|
LSR = |
LS + LIsig |
|
15 |
19 |
19.5 |
|
|
2 |
|
20 |
24 |
24.5 |
|
|
|
|
25 |
29 |
29.5 |
|
|
|
|
30 |
34 |
34.5 |
|
|
|
|
35 |
39 |
39.5 |
|
|
|
|
40 |
44 |
44.5 |
|
|
|
|
45 |
49 |
49.5 |
|
|
|
Marca de clase (x)
La marca de clase, también llamada
punto medio del intervalo es la mitad de la distancia entre los límites inferior
y superior de cada intervalo. La marca de clase es el valor más representativo
de los valores del intervalo.
|
LI |
LS |
LSR |
X |
|
X = |
LI + LS |
|
15 |
19 |
19.5 |
17 |
|
|
2 |
|
20 |
24 |
24.5 |
22 |
|
|
|
|
25 |
29 |
29.5 |
27 |
|
|
|
|
30 |
34 |
34.5 |
32 |
|
|
|
|
35 |
39 |
39.5 |
37 |
|
|
|
|
40 |
44 |
44.5 |
42 |
|
|
|
|
45 |
49 |
49.5 |
47 |
|
|
|
Clasificación
de los datos y conteo de frecuencias
Clasificar las observaciones en los intervalos.
La práctica usual es marcar con una línea ( / ) que representa una observación. En el ejemplo la
observación 22 se clasifica en el intervalo
20 – 24 porque se encuentra entre el 20 y el 24 inclusive. Una vez
clasificados todos los datos se cuentan las líneas de cada intervalo y el
resultado es la frecuencia de cada intervalo de clase.
|
LI |
LS |
cuenta |
F |
|
15 |
19 |
// |
2 |
|
20 |
24 |
/ |
1 |
|
25 |
29 |
//// |
4 |
|
30 |
34 |
/////
///// ///// |
15 |
|
35 |
39 |
/////
///// |
10 |
|
40 |
44 |
///// |
5 |
|
45 |
49 |
/// |
3 |
Distribución
de frecuencia relativa
Se pueden convertir las frecuencias de
clase en frecuencias relativas de clase
para mostrar los porcentajes de observaciones en cada intervalo de clase. Para convertir
una distribución de frecuencia en una distribución de frecuencia relativa cada
una de las frecuencias de clase se dividen entre el número total de
observaciones.
|
LI |
LS |
LSR |
X |
F |
FR |
|
15 |
19 |
19.5 |
17 |
2 |
2 / 40 = .05 |
|
20 |
24 |
24.5 |
22 |
1 |
1 /
40 = .025 |
|
25 |
29 |
29.5 |
27 |
4 |
4 /
40 = .1 |
|
30 |
34 |
34.5 |
32 |
15 |
15 / 40 = .375 |
|
35 |
39 |
39.5 |
37 |
10 |
10 / 40 = .25 |
|
40 |
44 |
44.5 |
42 |
5 |
5 / 40 = .125 |
|
45 |
49 |
49.5 |
47 |
3 |
3 / 40 = .075 |
|
N = |
40 |
|
|||
Distribuciones
de frecuencia acumulada
Si queremos responder preguntas como ¿cuántas
observaciones (baterías) están por debajo de 40?, o ¿qué porcentaje de
observaciones (baterías) caen por debajo de 30?. Las respuestas
a estas preguntas pueden ser contestadas con una distribución de frecuencia
acumulada o por una distribución de frecuencia relativa acumulada.
Las distribuciones de frecuencia acumulada se usan cuando queremos determinar cuantas
observaciones, o que porcentaje de observaciones están debajo de cierto valor.
La distribución de frecuencia acumulada de cierto
intervalo se calcula sumando las frecuencias de clase desde el primer intervalo
hasta la frecuencia de clase del intervalo de interés. Si queremos la
frecuencia acumulada del intervalo 25 – 29, sumamos las frecuencias de clase 2
+ 1 + 4 = 7.
La distribución de
frecuencia relativa acumulada de cierto intervalo se calcula dividiendo la
frecuencia acumulada entre el número total de observaciones
|
LI |
LS |
LSR |
X |
F |
FR |
FA |
FRA |
|
15 |
19 |
19.5 |
17 |
2 |
.05 |
2 |
.05 |
|
20 |
24 |
24.5 |
22 |
1 |
.025 |
3 |
.075 |
|
25 |
29 |
29.5 |
27 |
4 |
.1 |
7 |
.175 |
|
30 |
34 |
34.5 |
32 |
15 |
.375 |
22 |
.55 |
|
35 |
39 |
39.5 |
37 |
10 |
.25 |
32 |
.8 |
|
40 |
44 |
44.5 |
42 |
5 |
.125 |
37 |
.925 |
|
45 |
49 |
49.5 |
47 |
3 |
.075 |
40 |
1 |
|
N = |
40 |
|
|||||
La distribución de frecuencias
simple es una tabla que se construye con base en los siguientes datos: clase
o variable (valores numéricos) en orden descendente o ascendente, tabulaciones
o marcas de recuento y frecuencia.
Cuando se pretende “... determinar el
número de observaciones que son mayores o menores que determinada cantidad,” (Webster, 1998, p. 27) se utiliza la distribución de
frecuencias agrupadas también conocida como distribución de frecuencias
acumuladas. La distribución de frecuencias agrupadas es una tabla que contiene
las columnas siguientes: intervalo de clase, puntos medios, tabulación frecuencias
y frecuencias agrupadas. Los pasos para diseñarla son:
Se localizan el computo mas alto y el
mas bajo de la serie de datos.
Se encuentra la diferencia entre esos
dos cómputos.
La diferencia obtenida se divide entre
números nones tratando de encontrar un cociente cercano a 15 pero no mayor. Lo
anterior indica cuantas clases va a tener la distribución de frecuencias
agrupadas y cuál va a ser la magnitud del intervalo de clase.
Se determina el primer intervalo de clase y
posteriormente se van disminuyendo los límites del intervalo de clase de
acuerdo al valor de la magnitud establecida previamente.
El ejemplo planteado en la distribución
de frecuencias simples se utilizará tanto para efectos de ejemplificación de la
distribución de frecuencias agrupadas como para el diseño de gráficas tipo
polígono de frecuencias, histograma y ojiva.
Los cómputos mayor y menor son las
puntuaciones 88 y 65, la diferencia es 88-65=23 y el número de intervalos de
clase es 23/3= 7.68.
Representación Gráfica. A partir de la
distribución de frecuencias se procede a presentar los datos por medio de
gráficas. La información puede describirse por medio de gráficos a fin de
facilitar la lectura e interpretación de las variables medidas. Los actuales
sistemas computacionales como Excel, Lotus Smart Suite, Minitab, SAS-PC, Stath
Graph, entre otros permiten obtener representaciones gráficas de diversos
conjuntos de datos. Las gráficas pueden ser tipo histograma, polígono de
frecuencias, gráfica de series de tiempo, etc,
Investigado por: Ingrid Chávez
MEDIDAS DE DISPERSIÓN
Las medidas de
tendencia central tienen como objetivo
el sintetizar los datos en un valor representativo, las medidas de dispersión
nos dicen hasta que punto estas
medidas de tendencia central son representativas como síntesis de la
información. Las medidas de dispersión cuantifican la separación, la
dispersión, la variabilidad de los valores de la distribución respecto al valor
central. Distinguimos entre
medidas de dispersión absolutas, que no son comparables entre diferentes
muestras y las relativas que nos permitirán comparar varias muestras.
MEDIDAS DE DISPERSIÓN ABSOLUTAS
VARIANZA ( s2 ): es el promedio del cuadrado de las distancias entre
cada observación y la media aritmética del conjunto de observaciones.
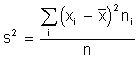
Haciendo operaciones en la fórmula anterior obtenemos otra fórmula para
calcular la varianza:
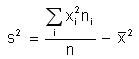
Si los datos están agrupados utilizamos las marcas de
clase en lugar de Xi.
EJEMPLO:
Hallar la desviación estándar
y la varianza de la siguiente serie de datos.
10, 18, 15, 12, 3,6,5,7
SOLUCION:
![]()
|
|
|
(10-9.5) = 0.25 (18-9.5) = 72.25
(15-9.5) = 30.25 (12-9.5) =
6.25 (3-9.5) = 42.25 (6-9.5) = 12.25 (5-9.5) = 20.25 (7-9.5) = 6.25 (x – x) = 190
S = 4.87 S = 23.75 |
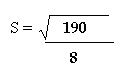
DESVIACIÓN
TÍPICA (S): La varianza viene dada por las mismas unidades que la variable pero
al cuadrado, para evitar este problema podemos usar como medida de dispersión
la desviación típica que se define como la raíz cuadrada positiva de la
varianza
![]()
Para estimar la desviación típica de una población a
partir de los datos de una muestra se utiliza la fórmula (cuasi desviación
típica):
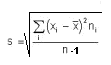
RECORRIDO
O RANGO MUESTRAL (Re). Es la
diferencia entre el valor de las observaciones mayor y el menor. Re
= xmax - xmin
MEDIDAS DE DISPERSIÓN RELATIVAS
COEFICIENTE
DE VARIACIÓN DE PEARSON: Cuando se quiere comparar el
grado de dispersión de dos distribuciones que no vienen dadas en las mismas
unidades o que las medias no son iguales se utiliza el coeficiente de variación
de Pearson que se define como el cociente entre la desviación típica y el valor
absoluto de la media aritmética
![]()
CV representa el
número de veces que la desviación típica contiene a la media aritmética y por
lo tanto cuanto mayor es CV mayor es la dispersión y menor la
representatividad de la media.
MEDIDAS DE FORMA
Comparan la
forma que tiene la representación gráfica, bien sea el histograma o el diagrama
de barras de la distribución, con la distribución normal. Las medidas de forma, permiten conocer
que forma tiene la curva que representa la serie de datos de la muestra.
CONCENTRACIÓN
Para medir el nivel de concentración de una distribución de
frecuencia se pueden utilizar distintos indicadores, entre ellos el Indice de Gini.
Este
índice se calcula aplicando la siguiente fórmula:
|
IG = |
S (pi - qi) |
|
---------------------------- |
|
|
S pi |
|
|
(i
toma valores entre 1 y n-1) |
|
En
donde pi mide el porcentaje de individuos de la
muestra que presentan un valor igual o inferior al de xi.
|
pi = |
n1 + n2 + n3 + ... + ni |
|
|
---------------------------- |
x 100 |
|
|
n |
|
Mientras
que qi se calcula aplicando la siguiente
fórmula:
|
qi = |
(X1*n1) + (X2*n2) + ... + (Xi*ni) |
|
|
----------------------------------------------------- |
x 100 |
|
|
(X1*n1) + (X2*n2) + ... + (Xn*nn) |
|
El Índice
Gini (IG) puede tomar valores entre 0 y 1:
IG
= 0 : concentración
mínima. La muestra está uniformemente repartida a lo largo de todo su rango.
IG
= 1 : concentración máxima.
Un sólo valor de la muestra acumula el 100% de los resultados.
Ejemplo: vamos a calcular el Índice Gini de una
serie de datos con los sueldos de los empleados de una empresa (millones
pesetas).
|
Sueldos |
Empleados (Frecuencias absolutas) |
Frecuencias relativas |
||
|
(Millones) |
Simple |
Acumulada |
Simple |
Acumulada |
|
x |
X |
x |
x |
x |
|
3,5 |
10 |
10 |
25,0% |
25,0% |
|
4,5 |
12 |
22 |
30,0% |
55,0% |
|
6,0 |
8 |
30 |
20,0% |
75,0% |
|
8,0 |
5 |
35 |
12,5% |
87,5% |
|
10,0 |
3 |
38 |
7,5% |
95,0% |
|
15,0 |
1 |
39 |
2,5% |
97,5% |
|
20,0 |
1 |
40 |
2,5% |
100,0% |
Calculamos
los valores que necesitamos para aplicar la fórmula del Indice
de Gini:
|
Xi |
ni |
S ni |
pi |
Xi * ni |
S Xi * ni |
qi |
pi - qi |
|
x |
x |
X |
x |
x |
x |
x |
x |
|
3,5 |
10 |
10 |
25,0 |
35,0 |
35,0 |
13,6 |
10,83 |
|
4,5 |
12 |
22 |
55,0 |
54,0 |
89,0 |
34,6 |
18,97 |
|
6,0 |
8 |
30 |
75,0 |
48,0 |
147,0 |
57,2 |
19,53 |
|
8,0 |
5 |
35 |
87,5 |
40,0 |
187,0 |
72,8 |
15,84 |
|
10,0 |
3 |
38 |
95,0 |
30,0 |
217,0 |
84,4 |
11,19 |
|
15,0 |
1 |
39 |
97,5 |
15,0 |
232,0 |
90,3 |
7,62 |
|
25,0 |
1 |
40 |
100,0 |
25,0 |
257,0 |
100,0 |
0 |
|
x |
x |
X |
x |
x |
x |
x |
x |
|
S pi (entre 1 y
n-1) = |
435,0 |
x |
S (pi - qi)
(entre 1 y n-1 ) = |
83,99 |
|||
Por lo
tanto:
|
IG = 83,99 /
435,0 = 0,19 |
Un
Índice Gini de 0,19
indica que la muestra está bastante uniformemente repartida, es decir, su nivel
de concentración no es excesivamente alto.
Investigado por: Moira Soto.
Las medidas de posición son aquellos valores
numéricos que permiten o bien dar alguna
medida de tendencia central, dividiendo el recorrido de la variable en dos, o
bien fragmentar la cantidad de datos en partes iguales.
Medidas de
localización (posición): Son
coeficientes de tipo promedio que tratan de representar una determinada
distribución, pueden ser de dos tipos:
1.-Centrales:
Informan sobre los valores medios de la serie de datos.
-Medias:
§
Aritmética
§
Geométrica
§
Armónica
-Medianas
-Moda
2.-No centrales: Informan
de como se distribuye el resto de los valores de la serie.
-Cuantiles:
§
Cuartiles
§
Deciles
§
Centiles o percentiles
Medidas de Posición:
Cuantiles
Los cuantiles son valores de la distribución que la
dividen en partes iguales, es decir, en intervalos, que comprenden el mismo
número de valores. Los más usados son los cuartiles, los deciles y los
percentiles.
![]() PERCENTILES: son 99 valores que dividen en cien partes iguales el
conjunto de datos ordenados. Ejemplo, el
percentil de orden 15 deja por debajo al 15% de las observaciones, y por encima
queda el 85%
PERCENTILES: son 99 valores que dividen en cien partes iguales el
conjunto de datos ordenados. Ejemplo, el
percentil de orden 15 deja por debajo al 15% de las observaciones, y por encima
queda el 85%
![]() CUARTILES: son los tres valores que dividen al conjunto de datos
ordenados en cuatro partes iguales, son un caso particular de los percentiles:
CUARTILES: son los tres valores que dividen al conjunto de datos
ordenados en cuatro partes iguales, son un caso particular de los percentiles:
- El primer cuartil Q 1 es el
menor valor que es mayor que una cuarta parte de los datos
- El segundo cuartil Q 2 (la mediana), ess el menor valor que es mayor que la
mitad de los datos
- El tercer cuartil Q 3 es el menor valorr que es mayor que tres cuartas partes
de los datos
![]() DECILES: son los nueve
valores que dividen al conjunto de datos ordenados en diez partes iguales, son
también un caso particular de los percentiles.
DECILES: son los nueve
valores que dividen al conjunto de datos ordenados en diez partes iguales, son
también un caso particular de los percentiles.
Ejemplo:
Dada la siguiente distribución en el número de hijos (Xi) de cien familias, calcular sus cuartiles.
|
xi |
ni |
Ni |
|
0 |
14 |
14 |
|
1 |
10 |
24 |
|
2 |
15 |
39 |
|
3 |
26 |
65 |
|
4 |
20 |
85 |
|
5 |
15 |
100 |
|
|
n=100 |
|
Solución:
1. Primer cuartil: ![]()
2. Segundo cuartil:
![]()
3.
Tercer
cuartil:
![]()
Medidas de
Centralización
Nos dan un
centro de la distribución de frecuencias, es un valor que se puede tomar como
representativo de todos los datos. Hay diferentes modos para definir el
"centro" de las observaciones en un conjunto de datos. Por orden de
importancia, son:
![]() MEDIA : (media aritmética o simplemente media). es el
promedio aritmético de las observaciones, es decir, el cociente entre la suma
de todos los datos y el numero de ellos.
Si xi es el valor de la variable y ni su frecuencia,
tenemos que:
MEDIA : (media aritmética o simplemente media). es el
promedio aritmético de las observaciones, es decir, el cociente entre la suma
de todos los datos y el numero de ellos.
Si xi es el valor de la variable y ni su frecuencia,
tenemos que:
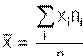
Si los datos están agrupados utilizamos las marcas de clase, es decir ci en vez de xi.
![]() MEDIANA (Me):es el valor que separa por la mitad las observaciones
ordenadas de menor a mayor, de tal forma que el 50% de estas son menores que la
mediana y el otro 50% son mayores. Si el número de datos es impar la
mediana será el valor central, si es par tomaremos como mediana la media
aritmética de los dos valores centrales.
MEDIANA (Me):es el valor que separa por la mitad las observaciones
ordenadas de menor a mayor, de tal forma que el 50% de estas son menores que la
mediana y el otro 50% son mayores. Si el número de datos es impar la
mediana será el valor central, si es par tomaremos como mediana la media
aritmética de los dos valores centrales.
![]() MODA (M0):
es el valor de la variable que más veces se repite, es decir, aquella cuya
frecuencia absoluta es mayor. No tiene porque ser única.
MODA (M0):
es el valor de la variable que más veces se repite, es decir, aquella cuya
frecuencia absoluta es mayor. No tiene porque ser única.

Investigado por: Rafael Rada.
MEDIDAS DE FORMA
Comparan la
forma que tiene la representación gráfica, bien sea el histograma o el diagrama
de barras de la distribución, con la distribución normal.
MEDIDA DE ASIMETRÍA
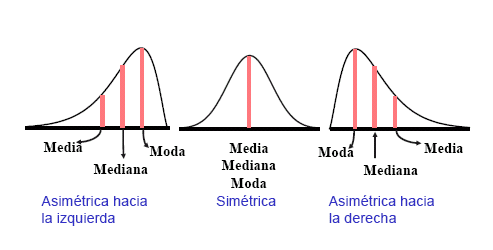
Diremos que una distribución es simétrica cuando su
mediana, su moda y su media aritmética coinciden.
Diremos que una distribución es asimétrica a la
derecha si las frecuencias (absolutas o relativas) descienden más
lentamente por la derecha que por la izquierda.
Si las frecuencias descienden más lentamente por la
izquierda que por la derecha diremos que la distribución es asimétrica a la
izquierda.
Existen varias medidas de la asimetría de una
distribución de frecuencias. Una de ellas es el Coeficiente de Asimetría de
Pearson:
![]()
Su valor es cero cuando la distribución es simétrica, positivo cuando existe asimetría a la derecha y negativo cuando existe asimetría a la izquierda.
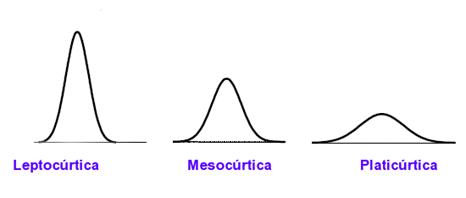
MEDIDA DE APUNTAMIENTO O CURTOSIS
Miden
la mayor o menor cantidad de datos que se agrupan en torno a la moda. Se definen 3 tipos de distribuciones según su grado de
curtosis:
Distribución mesocúrtica: presenta un grado de concentración medio alrededor
de los valores centrales de la variable (el mismo que presenta una distribución
normal).
Distribución leptocúrtica:
presenta un elevado grado de concentración alrededor de los valores centrales
de la variable.
Distribución platicúrtica: presenta un reducido grado de concentración
alrededor de los valores centrales de la variable.
EJEMPLO 1
El número de días necesarios por 10 equipos de trabajadores para terminar 10 instalaciones de iguales características han sido: 21, 32, 15, 59, 60, 61, 64, 60, 71, y 80 días. Calcular la media, mediana, moda, varianza y desviación típica.
SOLUCIÓN:
La media: suma de todos los valores de una variable dividida
entre el número total de datos de los que se dispone:
![]()
La mediana: es el valor
que deja a la mitad de los datos por encima de dicho valor y a la otra mitad
por debajo. Si ordenamos los datos de mayor a menor observamos la secuencia:
15, 21, 32, 59, 60, 60,61, 64, 71, 80.
Como
quiera que en este ejemplo el número de observaciones es par (10 individuos), los dos valores que se
encuentran en el medio son 60 y 60. Si realizamos el cálculo de la media de
estos dos valores nos dará a su vez 60, que es el valor de la mediana.
La moda: el valor de la variable que presenta una mayor
frecuencia es 60
La varianza S2: Es
la media de los cuadrados de las diferencias entre cada valor de la variable y
la media aritmética de la distribución.
|
Sx2= |
|
La
desviación típica S: es la raíz
cuadrada de la varianza.
![]()
S = √ 427,61 = 20.67
El rango: diferencia
entre el valor de las observaciones mayor y el menor
80 - 15 = 65 días
El coeficiente de variación: cociente entre la
desviación típica y el valor absoluto de la media aritmética
CV = 20,67/52,3 = 0,39
El precio de un interruptor magentotérmico en 10 comercios de electricidad de una ciudad son : 25, 25, 26, 24, 30, 25, 29, 28, 26, y 27 Euros. Hallar la media, moda, mediana, (abrir la calculadora estadística, más abajo) diagrama de barras y el diagrama de caja.
SOLUCIÓN:
(Utilizar la calculadora de debajo)
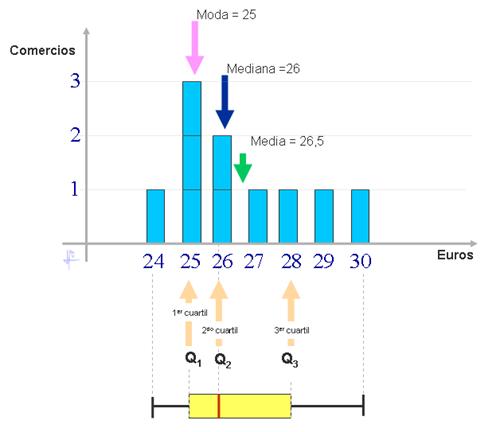
Investigado por : Shirley Alarcón
DISTRIBUCIONES BIDIMENSIONALES. CONCEPTO. REPRESENTACIÓN DE LOS DATOS.
FORMULAS. EJEMPLOS.
DISTRIBUCIONES BIDIMENSIONALES
Cuando sobre
una población estudiamos simultáneamente los valores de dos variables
estadísticas, el conjunto de los pares de valores correspondientes a cada
individuo se denomina distribución bidimensional.
Ejemplo 1:
Las notas de 10 alumnos en Matemáticas y en Lengua vienen dadas en
la siguiente tabla:
|
MATEMÁTICAS |
2 |
4 |
5 |
5 |
6 |
6 |
7 |
7 |
8 |
9 |
|
LENGUA |
2 |
2 |
5 |
6 |
5 |
7 |
5 |
8 |
7 |
10 |
Los pares de valores {(2,2),(4,2),(5,5),...;(8,7),(9,10)}, forman
la distribución bidimensional.
DISTRIBUCIONES MARGINALES
CONCEPTO
Es
posible determinar varias distribuciones marginales para cualquier distribución
de probabilidad que contenga más de dos variables aleatorias.
FORMULAS.
Sean
X y Y dos variables aleatorias discretas con una
función de probabilidad conjunta p(x, y). Las funciones marginales de
probabilidad de X y de Y están dadas por:
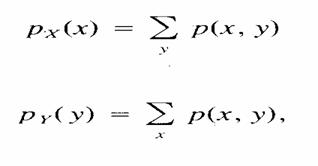
Respectivamente.
Sean
X y Y dos variables aleatorias continuas con una
función de densidad de probabilidad conjunta f(x, y). Las funciones de densidad
de probabilidad de X y de Y están dadas por
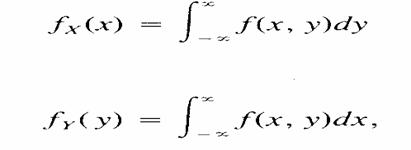
Respectivamente.
Para
variables aleatorias continuas conjuntas, si se conoce la función de
distribución acumulativa F(x, y), las distribuciones acumulativas marginales de
X y Y se obtienen de la siguiente forma:
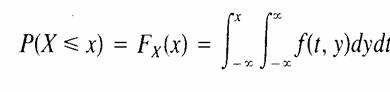
y
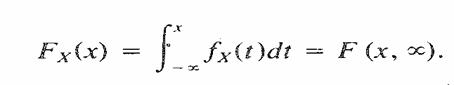
De manera similar
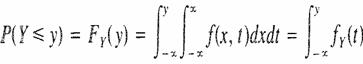
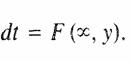
Así puede determinarse la
distribución acumulativa marginal de X dejando que Y tome un valor igual al
límite superior de la función de distribución conjunta de X y Y.
EJEMPLOS.
si
X y Y son variables aleatorias discretas, la suma de
la función de probabilidad bivariada sobre todos los valores posibles de Y dará
origen a la función de probabilidad univariada de X. Por otro lado, si X y Y son variables aleatorias continuas, la integración de la
función de densidad de probabilidad bivariada sobre el intervalo completo de
variación de Y generará la función de densidad de probabilidad univariada de X.
Sean X y Y dos variables aleatorias continuas con una
función de de probabilidad
conjunta:
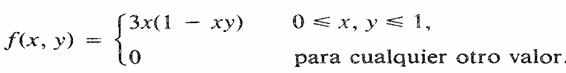
Para cualquier otro valor.
Obtener las distribuciones de densidad marginal y acumulativa de X y Y, La función de densidad marginal de X es
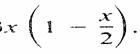
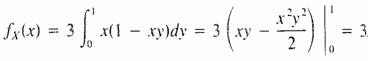
De manera similar para Y
![]()
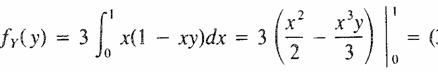
La distribución acumulativa
conjunta de X y Y es
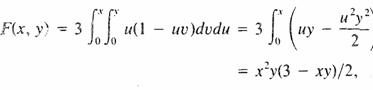
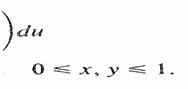
Por lo tanto, las
distribuciones acumulativas marginales de X y Y están dadas por:
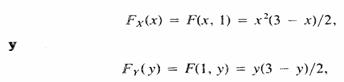

|
CONCLUSIÓN |
De acuerdo a lo estudiado anteriormente
podemos concluir que, la estadística
descriptiva es una ciencia que analiza series de datos (por ejemplo,
edad de una población, altura de los estudiantes de una escuela, temperatura en
los meses de verano, etc) y trata de extraer conclusiones sobre el
comportamiento de estas variable, dedicándose a los métodos de recolección,
descripción, visualización y resumen de datos originados a partir de los
fenómenos en estudio. Los datos pueden ser resumidos numérica o gráficamente.
Ejemplos básicos de descriptores numéricos son la media y la desviación
estándar. Resúmenes gráficos incluyen varios tipos de figuras y gráficos.
La variable es una característica
(magnitud, vector o número) que puede ser medida, adoptando diferentes valores
en cada uno de los casos de un estudio. Existe una gama muy diferenciada de variables
de las cuales se pude extrapolar diferentes escalas para ser medibles, la
aplicación de la bioestadística para medir característica y valores tanto
cualitativos como cuantitativos a través de la utilización de escalas que
permitan medir de mejor manera un resultado obtenido. Podemos deducir que
existen diferentes formas de medir variables, algunas se las puede medir
directamente por ejemplo la temperatura, la tensión arterial, la inteligencia,
y otros en forma indirecta, como el grado de aprovechamiento de una determinada
asignatura, la eficiencia, eficacia, el amor , ser romántico, ser buen ò mal
estudiante, etc.
La distribución
de frecuencia es la representación estructurada, en forma de tabla, de
toda la información que se ha recogido sobre la variable que se estudia.
Las medidas descriptivas se dividen en:
Medidas de Dispersión, que estudia la
distribución de los valores de la serie, analizando si estos se encuentran más
o menos concentrados, o más o menos disperso. Las medidas de forma, que permiten conocer que forma tiene la curva
que representa la serie de datos de la muestra. Las medidas de posición, que
son aquellos valores numéricos que nos permiten o bien dar alguna medida de
tendencia central, dividiendo el recorrido de la variable en dos, o bien
fragmentar la cantidad de datos en partes iguales. Las medidas de
centralización, que indican valores con respecto a los que los datos parecen
agruparse
Cuando sobre una población estudiamos
simultáneamente los valores de dos variables estadísticas, el conjunto de los
pares de valores correspondientes a cada individuo se denomina distribución
bidimensional.
Dada la distribución bidimensional (xi ; yj
; nij),
se llaman distribuciones marginales a cada una de las dos distribuciones unidimensionales
que se pueden obtener, de forma que en
cada una de ellas no se tenga en cuenta la otra.
|
INFOGRAFIA |
- NTRODUCCIÓN A
http://www.monografias.com/trabajos19/la-estadistica/la-estadistica.shtml
- INTRODUCCIÓN
A
La estadística
descriptiva es una ciencia que analiza series de datos (por ejemplo,
edad de una población, altura de los estudiantes de una escuela. Las variables
pueden ser de dos tipos: Variables cualitativas o atributos: no se pueden medir
numéricamente, representan características de las variables (por ejemplo:
nacionalidad, color de la piel, sexo). Variables cuantitativas: tienen valor
numérico (edad, precio de un producto, ingresos anuales).
http://nutriserver.com/Cursos/Bioestadistica/Estadistica_Descriptiva.html
- VARIABLES: TIPOS
Una distribución de los datos en categorías que ha
demostrado ser útil al organizar los procedimientos estadísticos, es la
distinción entre variables discretas y variables continuas. Una variable
discreta es sencillamente una variable para la que se dan de modo inherente
separaciones entre valores observables sucesivos. Una variable continua tiene
la propiedad de que entre 2 cualesquiera valores observables (potencialmente),
hay otro valor observable (potencialmente)...
http://calidadbioquimica.com.ar/stats.htm#marcador6
- ESTADÍSTICA
DESCRIPTIVA
Una de las ramas de
http://www.uaq.mx/matematicas/estadisticas/xu3.html
- DISTRIBUCIÓN DE
FRECUENCIAS
Frecuencias
acumuladas.- la suma de cada frecuencia con la frecuencia de la clase contigua
superior. Frecuencias relativas.- Dividiendo cada frecuencia entre el número
total de observaciones y multiplicándolas por l00 para tenerlas en forma de
porcentaje. Frecuencias relativas acumuladas.- La suma de cada frecuencia
relativa con la frecuencia relativa de la clase contigua superior. También se
pueden obtener dividiendo cada frecuencia acumulada entre el total de
frecuencias por l00.
http://www.universidadabierta.edu.mx/SerEst/MAP/METODOS%20CUANTITATIVOS/Pye/tema_11.htm
- DISTRIBUCIONES UNIDIMENSIONALES DE FRECUENCIAS
La representación gráfica de una distribución de frecuencias depende del tipo de datos que la constituya. La representación gráfica de este tipo de datos está basada en la proporcionalidad de las áreas a las frecuencias absolutas o relativas. Veremos dos tipos de representaciones....
http://thales.cica.es/rd/Recursos/rd99/ed99-0278-01/est_des4.html
- DISTRIBUCIÓN DE FRECUENCIAS
Una distribución de frecuencias es una herramienta
estadística muy útil para organizar un grupo de observaciones. Es una serie de datos
agrupados en categorías, Es una serie de datos agrupados en categorías, en las cuales se muestra el número de
observaciones que contiene cada categoría.
http://mx.geocities.com/fracosta11/dfrec.html
- MEDIDAS DESCRIPTIVAS
Las medidas descriptivas son valores numéricos calculados a partir de la muestra y que nos resumen la información contenida en ella...
http://miro.h3m.com/~s04be433/estadistica/estadistica02.htm
- MEDIDAS DE POSICIÓN NO
CENTRAL
son aquellos valores de la variable, que ordenados de menor a
mayor, dividen a la distribución en partes, de tal manera que cada una de
ellas contiene el mismo número de frecuencias. Los cuantiles más conocidos....
http://www.eumed.net/cursecon/dic/oc/Cuantiles.htm
10. MEDIDAS DE CENTRALIZACIÓN
En este tema y los dos siguientes vamos a obtener
unos números que cuantifiquen las propiedades fundamentales de la distribución
de frecuencias. Estos números podemos clasificarlos en: Medidas de localización (posición). Son coeficientes de tipo
promedio que tratan de representar una determinada distribución, pueden
ser.....
http://www3.uji.es/~mateu/Tema2-D37.doc
|
BIBLIOGRAFIA |
Ø
http://www.monografias.com/trabajos19/la-estadistica/la-estadistica.shtml
Ø
http://nutriserver.com/Cursos/Bioestadistica/Estadistica_Descriptiva.html
Ø
http://calidadbioquimica.com.ar/stats.htm#marcador6
Ø
http://www.uaq.mx/matematicas/estadisticas/xu3.html
Ø
http://www.universidadabierta.edu.mx/SerEst/MAP/METODOS%20CUANTITATIVOS/Pye/tema_11.htm
Ø
http://thales.cica.es/rd/Recursos/rd99/ed99-0278-01/est_des4.html
Ø
http://mx.geocities.com/fracosta11/dfrec.html
Ø
http://miro.h3m.com/~s04be433/estadistica/estadistica02.htm
Ø
http://www.eumed.net/cursecon/dic/oc/Cuantiles.htm
Ø
http://www3.uji.es/~mateu/Tema2-D37.doc