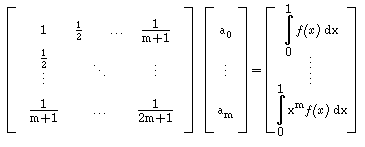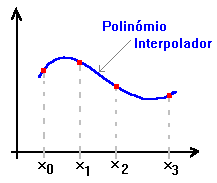
O polinómio de 3º grau interpola a função em 4 pontos
DESCRIÇÃO DA ÁREA DE MÉTODOS
NUMÉRICOS EM ESTUDO
Interpolação Polinomial
A interpolação consiste em
determinar uma função (iremos considerar polinómios), que assume valores
conhecidos em certos pontos (que chamaremos nós de interpolação). A
classe de funções escolhida para a interpolação é a priori arbitrária, e
deve ser adequada às caracteristicas que pretendemos que a função possua.
A interpolação polinomial
pode-se revelar desadequada se os nós de interpolação não forem escolhidos
convenientemente (o que leva ao uso de nós de Chebyshev...). De um modo geral,
o conjunto das funções interpoladoras é determinado por um número finito de
parâmetros (no caso dos polinómios, são os seus coeficientes...) que deverá
ser igual ao número de condições impostas (ou seja, ao número de nós), para
que haja apenas uma solução. Nos casos que veremos, a determinação dos parâmetros,
que definem a função interpoladora, irá levar-nos à resolução de um
sistema linear.
Se considerarmos a interpolação
polinomial, podemos evitar a resolução desse sistema, usando as fórmulas de
Lagrange ou de Newton, que reduzem significativamente o número de operações
envolvido.
Consideremos um conjunto de
pontos (designados nós de interpolação)
x0 , ... , xn , a que estão associados os valores de uma
função f0 , ... , fn, respectivamente.
Pretendemos encontrar
um polinómio p tal que
|
p ( xi ) = fi |
para i =
0, ..., n.
O polinómio de 3º grau interpola a função em 4 pontos
Escrevendo p( x ) = a0
+ a1 x + ... +
am xm, obtemos o sistema
|
a0 + a1 x0 + ... + am x0m = f0 |
|
... |
|
a0 + a1 xn + ... + am xnm = fn |
e para que
este sistema seja possível e determinado é pelo menos necessário que m=n.
Obtemos assim o sistema linear :
|
é |
|
ù |
é |
|
ù |
= |
é |
|
ù |
em que a matriz do sistema é
conhecida como Matriz de Vandermonde.
A existência e unicidade do polinómio interpolador é equivalente a assegurar
que o
sistema é possível e determinado para quaisquer x0 , ... , xn
distintos.
Teorema:
Dados n+1 nós, x0 , ... , xn e os respectivos valores f0
, ... , fn,
existe um e um só, polinómio interpolador de grau <n, para esses
valores.
dem:
Unicidade:
Supondo que existem dois polinómios interpoladores p e q de grau < n, então
o polinómio p(x) - q(x) tem grau < n e n+1 raízes, já que, sendo polinómios
interpoladores, verificam :
p
( xi ) = fi = q ( xi )
para i = 0,
..., n.
Consequentemente, como tem n+1 raízes e grau < n, o polinómio p(x)-q(x) terá
que ser nulo, logo p=q .
|
Polinómios de Lagrange |
|||||||
|
Dados
n+1 nós de interpolação x0 , ... , xn,
definimos para cada i = 0, ..., n o polinómio de Lagrange li(x)
de grau n tal que :
|
|||||||
|
Podemos
deduzir uma expressão explícita dos polinómios de Lagrange.
E a constante Ci
pode determinar-se, pois li(xi ) = 1, o que
implica
|
|||||||
para i = 0, ..., n . |
·
Agora, basta
considerar a Fórmula Interpoladora de Lagrange:
|
pn( x ) = f0 l0(x) + ... + fn ln(x) |
·
·
(a regra subjacente
é que no denominador vai ficar a diferença entre os nós, que não são comuns
às diferenças divididas do numerador).
·
Observação:
Qualquer permutação da ordem dos nós não altera o resultado.
Ou seja, por exemplo, f [ x1, x2 , x3 ] = f [ x2,
x3 , x1 ]
·
Nota:
Podemos considerar os valores fi como diferenças divididas de ordem
zero, e reparamos que isso é coerente com a definição da diferença de 1ª
ordem.
·
·
Resta determinar o
valor do coeficiente Cn .
Proposição: O coeficiente Cn , que é o coeficiente do termo
xn do polinómio interpolador pn
(nos nós x0 , ... , xn), é a diferença dividida f
[ x0 , ... , xn ].
dem:
Consideremos os polinómios interpoladores
pn-1 que interpola os nós x0 , ... , xn-1 com
coeficiente Cn-1
qn-1 que interpola os nós x1 , ... , xn com
coeficiente C*n-1
Reparamos que definindo
|
q(x) = |
(x - x0) qn-1(x) -(x
- xn) pn-1(x) (xn-x0) |
·
Fórmula de Newton
Portanto, podemos agora escrever
·
e podemos obter
sucessivamente, a partir do polinómio interpolador de grau zero p0(x)
= f0 :
|
p1(x) = f0 + f [ x0 , x1 ] ( x - x0) |
|
p2(x) = f0 + f [ x0 , x1 ] ( x - x0) + f [ x0 , x1, x2 ] ( x - x0) ( x - x1) |
|
... etc ... |
|
pn(x) = f0 + |
n |
f [x0 , ... , xk] (x - x0 ) ... (x - xk-1) |
·
Número de operacões:
Se resolvermos o sistema linear, como vimos no Capítulo II, é necessário
efectuar um total de ~2 n3/3 operações. Usando a Fórmula de
Lagrange ou a Fórmula de Newton reduzimos para ~3 n2/2. A F.
Lagrange usa mais multiplicações+divisões que a F. Newton, que, por sua vez,
usa mais somas+subtracções.
·
·
O erro de interpolação,
num certo ponto x, é :
·
É claro, que se x fôr
um dos nós, o erro é zero! Caso contrário, podemos considerar esse valor x
como um novo nó, e pensar no polinómio interpolador pn+1 . Já
vimos que
·
Considerando y = x, e
como x é um novo nó de interpolação, pn+1( x ) = f ( x ), e
obtemos :
·
f( x ) = pn(
x ) + f[ x0 , ... , xn, x ]( x - x0 ) ... ( x -
xn )
|
en
( x ) = f [ x0 , ... , xn, x ] ( x - x0
) ... ( x - xn ) |
·
Esta fórmula é útil
do ponto vista teórico, como também veremos mais tarde, no caso da integração.
Vamos, no entanto, aproveitar uma relação entre as diferenças divididas e as
derivadas, para estabelecer uma outra fórmula.
·
Teorema :
Consideremos n+1 nós de interpolação x0 , ... , xn
distintos entre si,
incluídos no intervalo [x0 , xn], onde a função f é de
classe Cn.
Então
|
$x em ]x0 , xn [ : f [x0 , ..., xn] = |
f(n)(x)
n! |
·
Este teorema pode ser
aplicado à fórmula do erro anterior, e obtemos o seguinte corolário:
·
Corolário :
Seja V um intervalo que contenha os nós x0 , ... , xn e
ainda o ponto x.
Se a função f fôr de classe Cn+1( V )
então temos a seguinte fórmula para o erro de interpolação:
|
$x em V : en(x) = |
f(n+1)(x)
(n+1)! |
n |
(x - xk ) |
·
Terminamos este parágrafo,
com um exemplo de uma função em que a aproximação, por interpolação
polinomial, pode conduzir a maus resultados.
Com efeito, se considerarmos a função f (x) = (1 + 25 x2 )-1,
e pensarmos em interpolá-la no intervalo [-1, 1], usando nós igualmente espaçados,
ao aumentarmos o número de nós, em vez de obtermos uma melhor aproximação,
vamos obter uma aproximação cada vez pior, nas extremidades do intervalo!
·
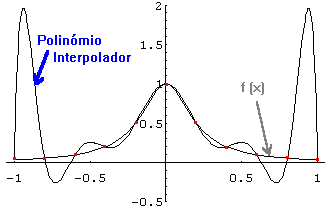
Exemplo de Runge: f(x) = (1 + 25 x2 )-1
usando 11 nós de interpolação igualmente espaçados
·
Este problema pode
ser resolvido, escolhendo nós de interpolação adequados (nós de Chebyshev).
·
·
Nós de Chebyshev
Como o erro de interpolação é dado por en ( x ) = f [ x0
, ... , xn, x ] ( x - x0 ) ... ( x - xn ), se a
parte relativa à diferença dividida varia com a função, e não pode ser
controlada a priori, a parte relativa ao produto dos termos, ou seja,
|w(x)| = |( x - x0 ) ... ( x - xn )|
poderá ser minimizada para certos nós x0,...,xn tendo
como objectivo a aproximação num intervalo específico.
·
Iremos considerar o
intervalo [-1,1].
A solução que minimiza o valor de w(x) é dada pelos nós de Chebyshev, que são
os zeros dos polinómios de Chebyshev:
·
Como |Tn+1(x)|
< 1, concluímos que
·
·
Informação retirada
do site: http://www.math.ist.utl.pt/~calves/cursos/Interpola.HTM
Método dos Mínimos Quadrados
Neste parágrafo vamos estudar a
aproximação de funções numa perspectiva diferente da interpolação. Por
exemplo, se tivermos apenas os valores da função em certos pontos, não vamos
exigir que a função aproximadora interpole a função dada nos pontos.
Exigimos apenas que essa função aproximadora tome valores (nesses pontos) de
forma a minimizar a distância aos valores dados... falamos em minimizar, no
sentido dos mínimos quadrados!
Isto é importante em termos de
aplicações, já que podemos ter valores obtidos, experimentalmente, com uma
certa incerteza. Ao tentar modelizar essa experiência, com uma certa classe de
funções, seria inadequado exigir que a função aproximadora interpolasse
esses pontos.
Um caso simples, em que se
aplica esta teoria é o caso da regressão linear, em que tentamos adaptar a um
conjunto de pontos e valores dados, a "melhor recta", que (neste caso)
será a recta que minimiza a soma quadrática das diferenças entre os valores
dados ao valores da recta, nesses pontos.
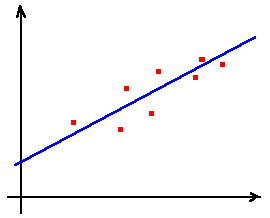
Regressão Linear: Neste caso pretendemos encontrar a função do tipo a + b x
(... ou seja, a recta) que "melhor se adapta" aos valores dados.
Esta é uma perspectiva discreta,
em que o conjunto de valores dados é finito.
Podemos também pensar num caso contínuo, em que apesar de conhecermos a
função, não apenas em certos pontos, mas em todo um intervalo, estamos
interessados em aproximar essa função (... no sentido dos mínimos quadrados)
por funções de uma outra classe, mais adequada ao problema que pretendemos
resolver. Por exemplo, podemos estar interessados em determinar qual a
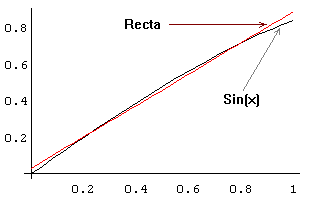
"melhor recta" que aproxima a função sin(x) no intervalo [0, 1] ...
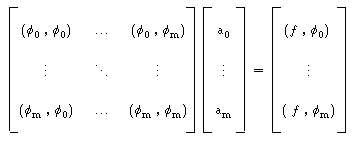
A recta que melhor aproxima sin(x) no intervalo [0,1],
no sentido dos mínimos quadrados
Caso
Discreto
Consideremos, de novo, um conjunto de pontos x0 , ... , xn
a que estão associados, respectivamente, os valores f(x0) , ... ,
f(xn) .
Temos que considerar agora uma
classe de funções, entre as quais vamos tentar encontrar a que "melhor
aproxima" aquele conjunto de valores, nos pontos dados.
Vamo-nos concentrar em funções
da forma:
g(x)
= a0f0(x) + ... + amfm(x)
em que f0
, ..., fm são funções
base (linearmente independentes), e são conhecidas.
Neste caso, apenas teremos que
determinar os parâmetros a0 , ... , an , de forma a que a
soma quadrática das diferenças entre os f( xi ) e os g( xi
) seja mínima.
Faz pois sentido
introduzir a distância || f - g || em que
|
|| u ||2 = |
n |
u( xi )2 |
a que está
associada o produto interno
|
( u, v ) = |
n |
u( xi ) v( xi ) |
A norma e o produto interno estão
bem definidos para funções que assumem quaisquer valores
nos pontos x0 , ... , xn. Convém-nos trabalhar com estas
noções, já que aquilo que iremos ver, de seguida, será exactamente igual no caso
contínuo, apenas a norma e o produto interno serão diferentes
(substituiremos o somatório por um integral...).
Pretende-se pois encontrar os
parâmetros a0 , ... , an que minimizem a distância entre
f e g , ou, o que é equivalente, minimizem :
Q
= || f - g ||2 = ( f - g , f - g )
Para obtermos esse mínimo, começamos
por procurar os valores a0 , ... , am tais que todas as
derivadas parciais de Q sejam nulas, isto é:
¶Q/¶aj
(a0 , ..., am) = 0, (para j = 0,..., m)
Calculamos a derivada parcial,
usando as propriedades da derivação do produto interno :
mq-12
Por outro lado
¶g/¶aj
= ¶/¶aj ( a0f0 + ... + amfm
) = f j
e assim
obtemos, para cada j de 0 até m :
(
f - g , fj
) = 0
Podemos ainda
substituir a expressão de g e obtemos um sistema linear :
|
designado por sistema
normal, que escrevemos matricialmente :
|
|
Teorema:
Se as funções base f0
, ... , fm forem
linearmente independentes, a matriz do sistema normal é definida positiva.
dem:
Seja S a matriz do sistema e v um vector não nulo.
Temos (Sv)i = (f0, fj
)v0 +...+(fm, fj
) vm = (f0
v0 +...+ fmvm , fj
) = (u , fj ),
definindo u = f0 v0
+...+ fm
vm , que é
uma função não nula, porque as funções fj
são linearmente independentes.
Assim, vTSv = (u , f0
)v0 +...+ (u , fm
) vm = (u , f0v0 +...+
fm
vm ) = (u,
u) = || u ||2 > 0,
e concluímos que S é definida positiva, e é obviamente simétrica (no
caso de ser considerado um produto interno nos números complexos, a matriz
seria hermitiana e ainda definida positiva).
Exemplo:
No caso de considerarmos a aproximação através de funções polinomiais,
temos como funções base, f0 = 1, ... ,fm
= xm, e assim obtemos:
Observações:
1) A matriz Hessiana de Q coincide justamente com a matriz do sistema
normal. Fica assim justificado que a solução do sistema normal, tratando-se de
um ponto crítico de Q, e como a matriz Hessiana é definida positiva, seja o mínimo
do funcional Q. 2) Como a matriz é simétrica e definida positiva, um método
apropriado para resolver o sistema normal é o método de Cholesky. 3) No
caso discreto, sendo os elementos da matriz do sistema normal
(fi , fj
) = fi (x0) fj
(x0)+ ... +
fi
(xn) fj
(xn)
podemos reparar que se trata de
um produto na forma XTX , em que X é a matriz (n+1) x (m+1) :
|
X = |
é |
|
ù |
No caso
polinomial, esta matriz X é a matriz de Vandermonde.
Caso Contínuo
Vamos considerar agora que conhecemos a função f não apenas em alguns pontos,
mas sim num determinado intervalo [a, b] . Mais uma vez estamos interessados em
aproximar f por funções da forma
g(x)
= a0f0(x) + ... + amfm(x)
ou seja, com
dependência linear dos parâmetros.
A única diferença existente,
face ao caso discreto, está na norma e no produto interno :
|
|| u ||2 = |
b |
u(x)2 dx |
a que está
associada o produto interno
|
( u, v ) = |
b |
u(x) v(x) dx |
Tudo se deduz de forma
semelhante, e obtemos também um sistema normal, cuja única diferença está no
significado dos produtos internos.
Exemplo:
No caso em que consideramos como funções base, os polinómios, f0(x)=
1, ... ,fm(x)= xm, obtemos agora o sistema normal
Esta matriz designa-se Matriz de
Hilbert, e é extremamente mal condicionada. Com efeito, já para m = 3 obtemos
Cond1 = 28375, e para m = 4 já atinge 943656, continuando a crescer
fortemente! Temos, assim, problemas de condicionamento e consequentemente de
instabilidade numérica, para este tipo de matrizes.
Observação (dependência não linear):
Quando não há dependência linear dos coeficientes, há duas possibilidades a
considerar:
(i) Método exacto. Efectuamos ainda a derivação ¶Q/¶aj
mas isso irá levar à resolução de um sistema não linear.
(ii) Método aproximado. Quando possível, por transformação de variável,
reduzimos a forma da função a aproximar ao caso linear, e aí usamos o método
linear descrito acima, regressando às variáveis anteriores por transformação
inversa.
Um exemplo habitual, é considerar g(x) = a ebx.
Assim, como queremos que f(x) ~ g(x), usamos log(f(x)) ~ log(g(x)) = log(a)+ b x.
Definindo F(x) = log(f(x)), A=log(a), B=b, procedemos à aproximação habitual
de F usando os mínimos quadrados (neste caso regressão linear) e tendo
encontrado os valores A e B, usamos transformação inversa para obter a= eA,
b=B.
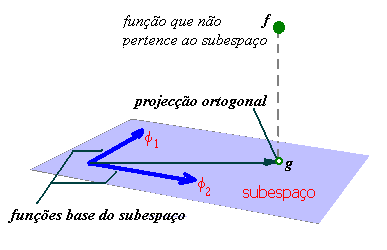
Observação: (interpretação geométrica):
Existe uma analogia geométrica entre o método dos mínimos quadrados e a
determinação do ponto de um plano que se encontra a menor distância de um
outro, exterior ao plano, como representamos na figura seguinte.
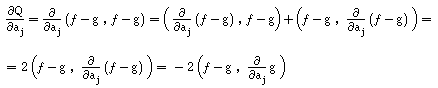
Através de um produto interno
podemos falar na projecção ortogonal, e relembramos que, exigir:
(
f - g , fj ) = 0
significa
exigir que f - g seja ortogonal a todos os fj .
Polinómios ortogonais
Consideramos uma situação um
pouco diferente, no caso contínuo, em que pretendemos minimizar uma distância
entre uma função f e uma função g, da forma g(x)=a1f1(x)+...+anfn(x), e em que essa distância é dada agora por
distância(f,
g) = || f - g||w
onde a norma
|| .||w é dada por
|
|| u ||w2 = |
ó |
b a |
w(x) u(x)2 dx |
e onde w>0
é uma função que representa um peso. Este peso pretende colocar em maior evidência
a aproximação numa certa parte do intervalo. Assim, por exemplo, se estivermos
interessados em aproximar uma função f no intervalo [-1,1] por funções g, de
forma a que nos interesse que a aproximação nas extremidades do intervalo seja
mais relevante do que a que é feita no interior, podemos considerar o peso de
Chebyshev,
w(x)
= 1 / Ö(1-x2)
que será
infinito nas extremidades no intervalo e mínimo no ponto médio.
Notamos que a norma || .||w
resulta do produto interno no intervalo [a, b] dado por
|
( u , v)w = |
ó |
b a |
w(x) u(x) v(x) dx . |
Toda a dedução efectuada para
o produto interno habitual (com w(x)=1) pode ser efectuada para este novo
produto interno, obtendo também um sistema normal. De seguida iremos ver como
podemos reduzir o sistema normal a um sistema com uma matriz diagonal, no caso
em que pretendemos aproximar f por polinómios, usando funções base que são polinómios
ortogonais.
Podemos obter os polinómios
ortogonais aplicando o processo de ortogonalização de Gram-Schmidt à base canónica
dos polinómios.
No entanto, podemos ver que há um processo mais simples, baseado na seguinte fórmula
de recorrência.
Teorema:
Dados dois polinómios q0 , q1 tais que (q0, q1)w
= 0, então a sucessão de polinómios definida pela fórmula de recorrência
|
qk+1 (x) = (x- |
(x qk , qk )w || qk ||w2 |
) qk(x) - |
|| qk ||w2 || qk-1 ||w2 |
qk-1(x) |
é uma base de
polinómios ortogonais para o produto interno (.,.)w .
Demonstração:
Por indução, admitimos que:
q0 , ... , qk são polinómios ortogonais, de grau 0, ...,
k (respectivamente),
e escrevemos qk+1 (x) = c0 q0(x)+
... + ck qk(x) + qk(x)x .
Pretendemos encontrar os ci tais que (qk+1 , qj )w
= 0, para qualquer j < k.
(i) Ora, para j=k, como admitimos que (qk , qi )w
= 0 para i < k-1, obtemos
0 = (qk+1 , qk )w = (x qk , qk )w
+ ck (qk , qk )w ,
o que implica ck = - (x qk , qk )w /
(qk , qk )w .
(ii) De forma semelhante, para j=k-1, temos
0 = (qk+1 , qk-1 )w = (x qk , qk-1
)w + ck-1 (qk-1 , qk-1 )w
e notamos que (x qk , qk-1 )w = (qk ,
x qk-1 )w = (qk , qk )w
porque qk (x) = x qk-1 (x)+pk-1(x), em que pk-1(x)
é um polinómio de grau < k-1,
e portanto (qk , qk )w - (qk , x qk-1
)w = (qk , pk-1 )w = 0.
Isto implica ck-1 = - (qk , qk )w /
(qk-1 , qk-1 )w .
(iii) Para quaisquer outros j< k-2, temos
0 = (qk+1 , qj )w = (x qk , qj )w
+ cj (qj , qj )w
Como (x qk , qj )w = (qk , x qj
)w = 0, pois x qj(x) tem grau < k-1,
e como (qj , qj )w= ||qj||w2
¹
0, concluímos que cj=0.
Obtemos assim, qk+1 (x) = ck-1 qk-1(x)+ ck
qk(x) + qk(x)x.
Observação:
Para simplificar, considerámos os polinómios na forma
qk+1 (x) = c0 q0(x)+ ... + ck
qk(x) + qk(x)x
o que condiciona a escolha da constante do monómio de grau k+1 a ser igual ao
valor considerado em q1.
Poderíamos ter considerado, mais geralmente,
qk+1 (x) = c0 q0(x)+ ... + ck
qk(x) + ck+1 qk(x)x
mas isso apenas altera o valor dos polinómios por uma constante, o que em nada
influi na ortogonalidade.
Exemplos:
1 - Polinómios de Legendre (w(x)=1,
no intervalo [-1,1])
Consideramos w(x)=1 e começando com
P0(x) = 1, P1(x) = x
temos (P0,P1) = 0, e como (P0,P0) =
2, (P1,P1) = 2/3, (x P1,P1) = 0,
obtemos
P2(x) = (x- 0)P1(x)-1/3 P0(x) = x2 -
1/3.
De forma semelhante, poderíamos obter P3(x) = x3 - (3/5)x,
etc...
Calculando (Pk , Pk) e (xPk , Pk)
obteríamos a fórmula de recorrência
Pn+1(x)
= x Pn(x) - n2 Pn-1(x) / (4n2-1).
Normalmente,
é comum aparecerem os polinómios de Legendre multiplicados por uma outra
constante. Essa constante pode ser escolhida de forma a que a sua norma seja
unitária, ou simplesmente por uma questão de convenção. É
habitual considerar-se
|
Pn+1(x) = |
(2n+1) x Pn(x) - n Pn-1(x) n+1 |
obtendo-se
a lista
|
P0(x) = 1, |
P1(x) = x, |
P2(x) = (3x2 - 1)/2, |
P3(x) = (5x3-3x)/2, ... |
notando que a
única diferença com os valores obtidos pela outra fórmula reside apenas em
multiplicar P2 por 3/2 e P3 por 5/2.
2 - Polinómios de Chebyshev (w(x)
= 1/ Ö(1-x2),
no intervalo [-1,1])
Consideramos agora w(x) = 1/ Ö(1-x2)
e começamos com T0(x) = 1, T1(x) = x.
Da mesma forma, com constantes apropriadas, podemos deduzir
|
Tn+1(x) = |
2 x Tn(x) - Tn-1(x) |
obtendo-se
a lista
|
T0(x) = 1, |
T1(x) = x, |
T2(x) = 2x2 - 1, |
T3(x) = 4x3-3x, ... |
Informação retirada do site: http://www.math.ist.utl.pt/~calves/cursos/mmq.htm